
Несколько месяцев назад я столкнулся с проблемой, моя модель построенная на алгоритмах машинного обучения просто на просто не работала. Я долго думал над тем, как решить эту проблему и в какой-то момент осознал что мои знания очень ограничены, а идеи скудны. Я знаю пару десятков моделей, и это очень малая часть тех работ которые могут быть очень полезны.
Первая мысль которая пришла в голову это то что, если я буду знать и пойму больше моделей, мои качества как исследователя и инженера в целом, возрастут. Эта идея подтолкнула меня к изучению статей с последних конференций по машинному обучению. Структурировать такую информацию довольно сложно, и необходимо записывать зависимости и связи между методами. Я не хотел представлять зависимости в виде таблицы или списка, а хотелось что-то более естественное. В итоге, я понял что иметь для себя трехмерный граф с ребрами между моделями и их компонентами, выглядит довольно интересно.
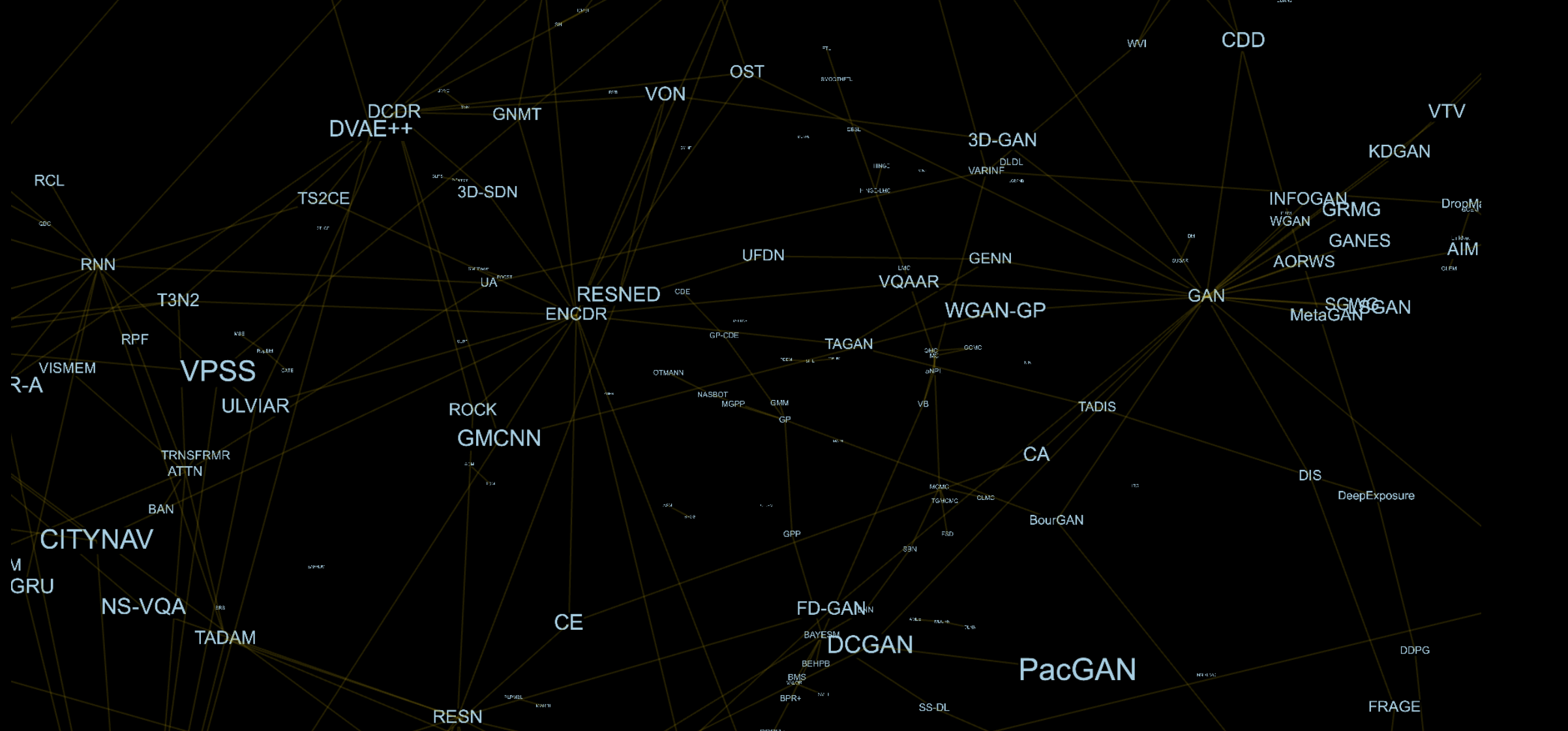
Например, архитектурно GAN [1] состоит из генератора (GEN) и дискриминатора (DIS), Состязательный Автокодировщик (AAE) [2] состоит из Автокодировщика (AE) [3] и DIS,. Каждый компонент является отдельной вершиной в данном графе, поэтому для AAE у нас будет ребро с AE и DIS.
Шаг за шагом, я анализировал статьи, выписывал из каких методов они состоят, в какой предметной области они применяются, на каких данных они тестировались, и так далее. В процессе работы я понял сколько очень интересных решений остаются неизвестными, и не находят своего применения.
Машинное обучение разделено на предметные области, где каждая область пытается решить конкретную проблему, используя определенные методы. В последние годы границы были почти стерты, и практически трудно выделить компоненты применяемые только в определенной области. Эта тенденция в целом приводит к улучшению результатов, но проблема в том, что с ростом количества статей, многие интересные методы остаются незамеченными. Причин на это много, и популяризация крупными компаниями лишь определенных направлений играет в этом немаловажную роль. Поняв это, граф, который ранее разрабатывался как нечто сугубо личное, стал публичным и открытым.
Естественно, я проводил исследования и пытался найти аналоги тому, что я делал. Существует достаточно сервисов, которые позволяют следить за появлением новых статей в данной области. Но все эти методы направлены в первую очередь на упрощение приобретения знаний, а не на помощь в создании новых идей. Креативность важнее опыта, и инструменты, которые могут помочь мыслить в различных направлениях, и видеть более цельную картину, как мне кажется должны стать неотъемлемой частью процесса исследования.
У нас есть инструменты которые облегчают проведение экспериментов, запуск и оценку моделей, но у нас нет методов, позволяющих нам быстро генерировать и оценивать идеи.
Всего за несколько месяцев я разобрал около 250 статей с последней конференции NeurIPS и около 250 других статей, на которых они основаны. Большинство областей были мне совершенно незнакомы, чтобы понять их потребовалось несколько дней. Иногда я просто не мог найти правильного описание для моделей, и того, из каких компонент они состоят. Исходя из этого, вторым логическим шагом было создание возможности авторам самим добавлять и изменять методы в графе, ведь никто, кроме авторов статьи, не знает, как наилучшим образом разобрать и описать свой метод.
Пример того что получилось по итогу представлен по ссылке.
Я надеюсь, что этот проект будет кому-нибудь полезен, хотя бы потому что он, возможно, позволит кому-то получить ассоциации, которые могут навести на новую интересную идею. Я был удивлен когда услышал как на чем основывается идея генеративных состязательных сетей. На MIT machine Intelligence podcast[4], Yan Goodfellow рассказал что идея состязательных сетей ассоциирована с «позитивной» и «негативной» фазой обучения Boltzman Machine[5].
Этот проект community-driven. Мне бы хотелось развивать его и мотивировать больше людей добавлять туда информацию о своих методах, или редактировать уже внесенную. Я верю что более точная информация о методах и лучшие технологии визуализации действительно помогут сделать это полезным инструментом.
Пространства для развития проекта очень много, начиная от улучшения самой визуализации, заканчивая возможностью построения индивидуального графа с возможностью получения рекомендаций методов для улучшения.
Некоторые технические подробности можно почитать по ссылке.
[1] Ian J.Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generative Adversarial Nets.
[2] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, Brendan Frey. Adversarial Autoencoders.
[3] Dana H. Ballard. Autoencoder.
[4] Ian J.Goodfellow: Artificial Intelligence podcast at MIT.
[5] Ruslan Salakhutdinov, Geoffrey Hinton. Deep Boltzmann Machines
Комментарии (15)

george3
11.08.2019 07:101. То что сразу вылезает окно о донейте — плохо. Нужно сначала понять хорошо там или нет.
2. Визуализация графа бесполезная. не видно связей. они должны быть по меньшей мере 2 х видов — 1. наследования и 2. использования общих компонентов.
3. когда выбирается вид сети граф показывает только ее и ее связи.
4. опция — русская версия)
Удачи!
iskateli
11.08.2019 13:47Трёхмерность это конечно эффектно, но не так удобно как в 2D. Если переделаете в двумерный вариант, да ещё и с глоссарием, то цены не будет такой схеме!

nikolay_karelin
12.08.2019 12:32Очень интересный проект!
Несколько замечаний:
- Очень странно, что граф отображается в маленьком фрейме. Я даже слегка обалдел, когда открыл на FullHD (даже не 4K) мониторе. И это при том, что страничка https://backronym.xyz/graph.html прекрасно смотрится.
- 2D действительно будет лучше. Советую посмотреть на проекты Cytoscape и Sigma
- Немного странно, что пропущенные данные отображаются, как NaN. Может лучше просто пробелы?
- Ссылки — просто текст, не кликабельны...
- Планируется ли где-то открыть код и данные проекта?

postmachines Автор
12.08.2019 17:21Приветствую, код доступен здесь: github.com/postmachines/INFORNOPOLITAN-BACKRONYM.
serhit
12.08.2019 22:54Классификация знаний по ML — это очень здорово! Хорошее начинание.
Мне кажется этот проект хорошо взлетит при условии, что в него будет просто контрибьютить (здесь я имею ввиду информацию о классах алгоритмов ML, а не о коде визуализации) и просто использовать.
К сожалению в данном формате и то, и другое — сложновато:
- монолитный файл data.js — не самый удобный формат чтобы добавлять и редактировать данные. В особенности это касается раздела связей — при таком виде они оторваны от "контекста" узлов. Человеку, который захочет добавить информацию, будет сложно.
- как уже упоминалось в других комментариях — представление информации может требоваться разное: 3-D, 2-D, список связей какой-нибудь...
- информацию из такого "хранилища" хорошо-бы уметь искать в поисковиках — это добавило-бы популярности.
Из всего этого вопрос. А не задумывались о том, чтобы представить информацию в виде Wiki, возможно с определенными формальными полями и/или гиперссылками? Или еще проще — в виде набора ссылающихся друг на друга .md файлов на том же GitHub.
Это решило бы вопрос удобного редактирования, поиска и использования информации.
А вопрос представления / визуализации связанных документов решить можно.
postmachines Автор
13.08.2019 13:46Благодарю за содержательный отзыв! Представление в виде Wiki, или .md выглядит очень интересно, однозначно над этим подумаю
george3
13.08.2019 14:02Я бы сказал взлетит если на нем(внутри) можно будет делать (AutoML) модели и скачивать их для коннекта с прогами. так сказать ML для чайников. причем для англоговорящей аудитории.
Griboks
А можно в статью про визуализацию вставить что-нибудь, кроме текста?
postmachines Автор
Добавлена ссылка на то что получилось. Спрашивайте, что интересует?
Griboks
10 минут загрузки + предупреждение, что бы я не заходил на сайт с телефона + облако тегов и больше ничего
postmachines Автор
Решил отключить с мобильной версии, так как получилось что очень долго прогружается
Balling
Бред какой-то. Я с планшета захожу, все норм. Правда это tab s4, так что он мощный и использую я хром. Но вообще-то, вам надо доработать сайт, а то блокировщик рекламы почему определяет 28 разлиных блокированных элементов и сайт не грузится. На компьютере)) три раза ха-ха… кстати интересно, буквально вчера смотрел вот этот ролик на youtube с таким же облаком… youtu.be/wvsE8jm1GzE
postmachines Автор
Дорабатывать безусловно надо, work in progress)