
Сравниение различных инструментов (RabbitMQ, Crossbar.io, Nats.io, Nginx и др.) для организации RPC между микросервисами.



1. Тесты
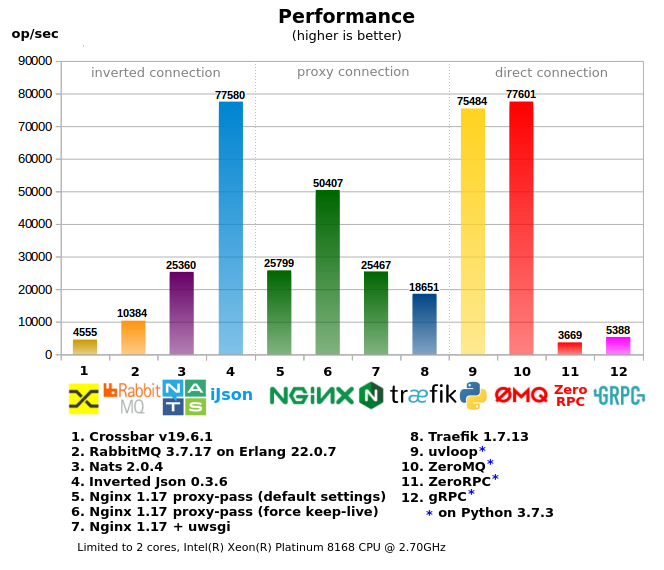
Все инструменты поделены на 3 группы:
- «Direct connection» — когда клиент напрямую обращается к воркеру, в проектах с многочисленным количеством воркеров/сервисов является самым сложным в конфигурировании, требует «умного клиента», т.е. клиент при вызове должен обладать информацией как и куда отпавлять запрос (либо нужен дополнительный локальный прокси), как правило производит наименьшую нагрузку на сеть.
- «Proxy connection» — вариант с единой входной точкой, простой клиент, но при этом сохраняются сложности на стороне воркеров/серисов — проброс и выделение портов, регистрация адресов на прокси, более сложная настройка фаервола, зачастую используются дополнительные иструменты для управления за всем этим хозяйством.
- «Inverted connection» — единая точка входа как для клиентов так и для воркеров (может рассматриваться как ESB), наиболее простая настройка сети.
- Использование памяти и процесора взято из `docker stats`
- В «2-core» тесте сервер и клиенты с ворерками разделены по разным ядрам, чтобы уменшить влияние друг на друга, поэтому сервер ограничен 2-мя ядрами через taskset (multi-core тест без ограничений)
2. MQ или RPC
Хоть эти 2 способа комуникации разные, иногда первый используется вместо второго и наоборот.
Если попробовать очертить границы, когда что использовать, то может получится что-то такое:
- RPC (вызов процедуры) — когда клиент требует ответ немедленно (в короткий отрезок времени), когда воркер должен ответить пока клиент ждет ответ, и если клиент ушел (по таймауту), то этот ответ уже не нужен (это почему не нужно сохранять «запрос», как это часто делается в MQ системах).
Например когда вы делаете некий запрос в БД — вы делаете RPC, вы не захотите использовать MQ для этого. - MQ — когда ответ не нужен (немедленно), когда нужно просто выполнить какую-то задачу в конечном итоге или просто передать данные.
Например для рассылки писем вы можете отправить задачу через MQ
3. RPC over RabbitMQ
RabbitMQ часто используется для организации RPC, но как и подобные MQ системы создает дополнительный оверхед, из-за чего его использование получается не очень производительным.
Если вы используете «очередь» для RPC, то вам необходимо чистить каналы, т.к. если воркер упал на какое-то время, то после перезапуска он может получить кучу неактуальных задач, т.к клиенты все это время слали запросы и кроме того, впустую ждали ответа т.к. воркер был не активен. Итого воркер получит задачу даже если клиент ушел до того, так же и с клиентом, если не чисить канал клиента, то он может забиться не принятыми ответами от воркера, хотя в RabbitMQ можно закрывать клиентский канал, но при этом катастрофически падает производительность.
Так же нужно делать пинг воркера, чтобы знать жив ли он.
Кроме того ресурсы тратятся на работу с каналами, когда в RPC системах данные просто пересылаются воркеру и обратно.
4. Inverted Json
Сущесвтует множество различных MQ систем, но не так много Job-серверов (RPC), таких как Gearman/Crossbar.io — это очень маленький выбор, поэтому разрабочики часто берут MQ системы для RPC.
Поэтому был создан Inverted JSON (iJson) — прокси сервер с http интерфейсом, где клиенты и воркеры подключаются как сетевой клиент: [client] -> [Inverted Json] < — [worker], написан на C/C++, использует epoll, конечные автоматы для роутинга, потоковый парсер json, слайсы вместо строк* и пр. способы для лучшей производительности.
Преимущества Inverted JSON перед RabbitMQ:
- Не нужно чистить каналы клиента и воркера от не принятых сообщений
- Не обязательно пинговать воркер, клиент получит ошибку немедленно если воркер отключится (при keepalive соединении)
- Проще апи — просто http запрос (как правило уже поддерживается всеми языками и фреймворками)
- Быстрее работает и потребляет меньше памяти
- Более простой способ отправлять команды на конкретный воркер (например если в очереди несколько воркеров, а работать надо с одним конкретным)
Другая информация о Inverted Json
- Возможность передавать бинарные данные (не только json, как может показаться из названия)
- Не обязательно указывать id если воркер подключен как keep-alive, Inverted Json просто соединяет клиент и воркер напрямую.
- Возможность «подписки» на несколько комманд (каналов), подписка на паттерн (например command/*) без потери производительности.
- Docker образ всего 2.6 Мб (slim версия)
- Ядро Inverted Json всего ~1400 строк кода (v0.3), меньше кода — меньше багов ;)
- Inverted JSON не модифицирует тело запроса (body), а пересылает как есть.
5. Попробуйте Inverted Json за 3 минуты
Вы можете попробовать Inverted Json прямо сейчас если у вас есть Docker и curl:

Описание из картики:
1) Запуск docker образа Inverted Json на 80 порту (можете выбрать любой), --log 32 логирует входяшие запросы:
$ docker run -it -p 80:8001 lega911/ijson --log 32
2) Регестрируем воркер для задачи «calc/sum», и ждем задачу:
$ curl localhost/rpc/add -d '{"name": "calc/sum"}'
3) Клиент делает RPC запрос calc/sum:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) Воркер получает задачу `{«id»: 15, «data»: «2+3»}` — данные без изменения, теперь нужно отправить результат на тот же id:
$ curl localhost/rpc/result -d '{"id": 15, "result": 5}'
… и клиент получает результат как есть
`{"id": 15, "result": 5}`5.1. JsonRPC
JsonRPC 2 не поддерживается, но есть некоторые зачатки, например клиент может отправлять запросы наподобии (url /rpc/call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
5.2. Пример клиента и воркера на Python
# client.py
import requests
print(requests.post('http://127.0.0.1:8001/test/command', json={'id': 1, 'params': 'Hello'}).json())
# worker.py
import requests
while True:
request = requests.post('http://127.0.0.1:8001/rpc/add', json={'name': '/test/command'}).json()
response = {
'id': request['id'],
'result': request['params'] + ' world!'
}
requests.post('http://127.0.0.1:8001/rpc/result', json=response)
А тут вы можете найти пример в режиме «worker mode», который является более производительным и компактным.
6. Некоторые мысли о результате бенчмарка
- Crossbar.io: основан на python, поэтому он не так быстр и не может использовать несколько ядер из-за GIL.
- RabbitMQ: RPC поверх MQ, что накладывает дополнительный оверхед. Быстрое падение производительности при повышении нагрузки (в тесте не отражено).
- Nats: показал себя не плохо, хотя уступает Inverted Json, т.к. RPC over MQ, так же будет иметь те же проблемы.
- Inverted Json: достиг сетевого лимита (т.е. запуск нескольких копий тестов на разных ядрах, суммарно не дает больший результат), показал самое эффективное использование памяти и процессора относительно производительности.
- Nginx: при proxy-pass производительность быстро падает если не включен keep-alive режим (выключен по умолчанию), связано с тем что linux не дает открывать/закрывать много сокетов в короткий промежуток времени (в тесте это не отражено).
- Traefik: очень прожорлив, использовал 600% CPU в пике, по скорости уступет nginx
- uvloop (под asyncio) — дает очень хорошую производительность, т.к. большая часть написана на C/C++, для RPC является более предпочтительным чем ZeroMQ
- ZeroMQ — сам воркер написан на Python, поэтому он уперся в ядро, хотя многопроцессорный тест потребляет более 100% CPU, это за счет того что сам zeromq написан на C/C++ без захвата GIL. Дает большую производительность, но с другой сторны, если воркер будет делать не просто a+b, любое усложнение приведет к значительному снижению RPC, т.к. упрется в ядро ещё раньше.
- ZeroRPC: заявлено как легкая обертка над ZeroMQ, в реальности потеряно 95% производительности от ZeroMQ, похоже что она не такая уж и легкая.
- GRPC: вариант для питона производит много шаблонного питон кода, т.е. обрабочик получается тяжелым и быстро упирается в CPU, для компиллируемых языков вероятно такой проблемы нет.
- 2-core и multi-core тесты, в multi-core некоторые показатели снизились, потому что приходится конкурировать за CPU ресурсы с клиентским тестовым кодом, с другой стороны некоторые тесты дали большую производительность, например Traefik, который съел 600% CPU
7. Заключение
Если у вас большая компания и много сотрудников, тогда вы можете позволить себе поддерживать разные сложные инструменты для организации прямых соединиений между микросервисами, что может дать эффективную комуникацию.
А для маленьких компаний и стартапов, где небольшим колективом нужно решать задачи из разных сфер, Inverted Json может съэкономить время и ресурсы.
Для развития Inverted Json, в планах стоит поддержка pubsub, kubernetes, и другие интересные идеи.
Если вам интересен проект или просто хотите помочь автору, вы можете поставить звездочку на github проекте, спасибо.
PS:
- На создание этой статьи включая тесты ушло времени больше чем на создание самого Inverted Json
- Прототипы Inverted Json так же были написаны на 1. python + asyncio + uvloop, 2. на GoLang
- Тесты были просмотрены разными специалистами
- «слайсы вместо строк» — в большинстве случаев при парсинге http/json идет не копирование даннных в строки, а используется ссылка на исходные данные, таким образом не происходит лишнее выделение и копирование памяти.
- Если вы будете тестировать — не используйте requests в python, он очень медленный, лучше pycurl, в тестах используется этот врапер.
- Бенчмарк находится тут
- Исходники тут
Комментарии (13)

UnnamedUA
05.09.2019 08:20Не про скорость, а про оверхед, но удобство вопрос тем кто использует NATS: смотрели github.com/liftbridge-io/liftbridge?

sadko4u
05.09.2019 09:44Об rpc ещё писали в незнамо каких лохматых годах.
С самого начала создания первой сети, Святым Граалем сетевых вычислений было предоставления программных интерфейсов для доступа к удалённым сетевым ресурсам таким же образом, как к локальным. Сеть становится "прозрачной".
Один пример прозрачности сети — знаменитый RPC (удалённый вызов процедур, remote procedure call), система разработанная для того, чтобы вы могли вызывать процедуры (подпрограммы), выполняющиеся на другом компьютере, по сети точно так же, как если бы они выполнялись локально. На это угробили чёртову пропасть энергии.
Звучит логично, правильно?
Неправильно.
Заключение: В следующий раз, когда кто-то попытается продать вам программный продукт, который позволяет вам обращаться к сетевым ресурсам также как к локальным, убегайте как только можете в противоположном направлении.RPC поверх HTTP — ещё большее зло, которое, в принципе, могло придумать человечество.
Но практика показывает, что плохие вещи почему-то набирают бОльшую популярность, чем хорошие.nicholas_k
05.09.2019 10:08+4RPC поверх HTTP — ещё большее зло, которое, в принципе, могло придумать человечество
А разве на Хабре не принято обосновывать свою точку зрения фактами и логическими выводами?
Не стоит нарушать монополию религии на нерациональную веру.sadko4u
06.09.2019 00:18-1Конкретные недостатки HTTP, применительно к версии 1.x:
— дикий оверхед по заголовкам и телу сообщения — неэффективное использование трафика;
— отуствие конвейеризации запросов: вы не можете по одному и тому же сокету отправить запросы 1 и 2 на сервер, а ответы получить в обратном порядке — сначала на 2, а потом на 1. Иными словами, сетевой сокет простаивает, когда мог бы заниматься полезной работой.
— На практике редко кто поддерживает персистентные соединения, отсюда имеем оверхед по времени на установление TCP-соединения (TCP handshake) и, если используется SSL, то ещё и на SSL handshake.
Да и, в принципе, всё тот же самый обмен сообщениями можно организовать напрямую через TCP-сокет, без привлечения протокола прикладного уровня, коим является HTTP.nicholas_k
06.09.2019 11:55+1Ну вообще то разговор был о недостатках RPC over HTTP, а не об HTTP как таковом. Ведь RPC так удобно ложится в концепцию «запрос-ответ» без состояния.
Что касается недостатков HTTP то видимо надо убить почти весь интернет. Ну и поубивать все языки более высокого уровня, чем С, потому что оверхэд.

maxim_ge
05.09.2019 10:07+1Интересная штуковина! Несколько вопросов возникло:
— Не совсем уловил, как прописываются правила, соединяющие клиентов и обработчиков>
— Может ли быть несколько обработчиков по одной теме?
— Как послать сообщение конкретному обработчику из нескольких?lega Автор
05.09.2019 11:39— Не совсем уловил, как прописываются правила, соединяющие клиентов и обработчиков>
Есть 2 варианта, один описан в 5 разделе — например если обработчик должен обрабатывать команду «start», обработчик отправляет серверу json:
'{"name": "start"}'и после того как клиент отправит запрос на url/start, клиент и обработчик будут «соединены» (но только на 1 команду т.к. вторая команда от клиента может быть другая на другой обработчик).
Для второго варианта пример тут, так же есть несколько примеров тут.
— Может ли быть несколько обработчиков по одной теме?
Да, множество обрабочтиков и множество клиентов на одни и теже «темы» (очереди) работают хорошо.
— Как послать сообщение конкретному обработчику из нескольких?
Для этого обрабочик может добавить список команд которые могут содержать идентификатор, например
'{"name": "start:15,start"}', таким образом обработчик одновременно обслуживает 2 команды «start:15» и «start» (где 15 — это идентификатор). А клиенты в свою очередь могут получить список всех обработчиков из "/rpc/details" и работать с выбраным (подобный подход так же используется и для MQ систем).
bat
05.09.2019 10:17странный тест, больше похоже на рекламу
Следовало бы так же протестировать все компоненты на разных хостах. В реальных системах редко все крутится на одном хосте, а при таком раскладе может сыграть эффективность протокола, особенно на мелких запросах.
Весьма непоказательный тест с grpc, если клиент на столько неэффективен, следовало бы его исключить.
зы
envoy не пробовали?lega Автор
05.09.2019 11:53Следовало бы так же протестировать все компоненты на разных хостах
Изначально тест и проводился на разных хостах (в Digital Ocean), но видимо там сеть была не быстрая и многие тесты показывали одинаковый* результат, но мы тестируем не скорость сети, а сервер/прокси, поэтому было решено тестировать без влияния сети (ведь у всех разные сети).
grpc, если клиент на столько неэффективен, следовало бы его исключить.
Мне кажется это может быть полезной информацией для питон разработчиков, чтобы потом не удивлятся когда GRPC будет уже внедрен.
envoy не пробовали?
Нет, но возможно в следующий тест будет включён.
bat
05.09.2019 12:26сделал тот же тест GRPC на Go
Intel® Core(TM) i5-4670 CPU @ 3.40GHz (ксеонов нема)
получилось от 9000 rps для одной клиентской горутины до 90000 rps для 50 горутин
supcry
> GRPS: вариант для питона
GRPC, исправьте, пожалуйста.