

Язык программирования Rust, начатый как хобби-проект, а впоследствии поддерживаемый корпорацией Mozilla, позволяет обычным программистам писать одновременно и безопасные и быстрые системы: от калькуляторов до высоконагруженных серверов.
За своё относительно короткое время существования данный язык уже успел обрасти стереотипами, четыре из которых я попытаюсь опровергнуть ниже. Я могу пропустить некоторые моменты, дискуссии в комментариях приветствуются.
- Rust — сложный язык программирования
- Rust — ещё один "убийца C/C++"
- Unsafe губит все гарантии, предоставляемые Rust
- Rust никогда не обгонит C/C++ по скорости
1. Rust — сложный язык программирования
Сложность языка программирования обуславливается наличием большого числа несовместимых между собой синтаксических конструкций. Яркий пример — C++ и C#, ведь для абсолютного большинства программистов C++ является сложнейшим языком, коим не является C#, несмотря на большое количество синтаксических элементов. Rust довольно однороден, т.к. изначально был спроектирован с оглядкой на ошибки прошлого, а все нововведения вводятся исключительно при условии согласования с уже имеющимися.
Данный стереотип восходит своими корнями к концепции времён жизни ссылок (lifetimes), позволяющей на уровне семантики языка описывать гарантии действительности используемых ссылок. Синтаксис лайфтаймов выглядит сперва странным:
struct R<'a>(&'a i32);
unsafe fn extend_lifetime<'b>(r: R<'b>) -> R<'static> {
std::mem::transmute::<R<'b>, R<'static>>(r)
}
unsafe fn shorten_invariant_lifetime<'b, 'c>(r: &'b mut R<'static>)
-> &'b mut R<'c> {
std::mem::transmute::<&'b mut R<'static>, &'b mut R<'c>>(r)
}Но на деле синтаксис объявления лайфтайма довольно прост — это всего лишь идентификатор, перед которым следует апостроф. Лайфтайм 'static означает, что ссылка является действительной на протяжении всего времени исполнения программы.
Что такое "действительность ссылки"? Если ссылка действительна, то она поддаётся разыменованию без паники, ошибки сегментации и прочих прелестей. Например, в функции main() указатель something становится недействительным, т.к. все автоматические переменные функции produce_something() очищаются после её вызова:
int *produce_something(void) {
int something = 483;
return &something;
}
int main(void) {
int *something = produce_something();
int dereferenced = *something; // Segmentation fault (core dumped)
}Семантически лайфтайм может быть задан посредством других лайфтаймов. Например, эта функция требует того, чтобы ссылка foo не стала недействительной до недействительности ссылки bar:
fn sum<'a, 'b: 'a>(foo: &'b i32, bar: &'a i32) -> i32 {
return foo + bar;
}Конструкция выше применяется крайне редко, чаще всего одного лишь указания лайфтайма достаточно. Лайфтаймы — это элегантная абстракция, дающая возможность программистам быть уверенными в действительности собственных ссылок как в контексте однопоточных, так и многопоточных систем. Сложность лайфтаймов сильно переоценена.
Изучающих Rust также пугают концепции заимствования и владения (которые существовали и до создания Rust). Как и с лайфтаймами, концепции заимствования и владения лаконично вписываются в общую картину: заимствование — это взятие ссылки на значение, а владение — это связь идентификатора переменной с её значением.
Рассмотрим на примере. В приведённом ниже коде переменная x владеет экземпляром структуры Foo, а переменная y заимствует значение, которым владеет переменная x:
struct Foo {
data: Vec<u8>,
}
fn main() {
let x = Foo { data: Vec::new() }; // Владение (owning)
let y = &x; // Заимствование (borrowing)
}Если один поток имеет иммутабельную ссылку на переменную, а другой поток имеет мутабельную, то второй может изменить значение, вызвав состояние гонки. Данная ситуация недопустима в безопасном языке, вследствие чего команда Rust определила два простых правила:
- Значение может быть заимствовано иммутабельными переменными множество раз и при этом не заимствовано мутабельной;
- Значение может быть заимствовано мутабельной переменной лишь один раз и при этом не быть заимствованным иммутабельными.
2. Rust — ещё один "убийца C/C++"
Ключевая фраза — "ещё один". На данный момент Rust — единственный язык программирования, обладающий одновременно активным сообществом и характеристиками, позволяющими ему решать задачи, решаемые языками C/C++. Синтаксис и семантика позволяют с лёгкостью изъясняться на разных уровнях абстракции — от инструкций SIMD до управления веб-серверами.
Данный стереотип возник вследствие языков Vala, Zig, Golang и подобных. Как я сказал выше, у этих языков либо слишком маленькое сообщество, либо они теоретически и практически не смогут работать на всех системах, на которых способны работать C/C++. У Vala и Zig маленькое сообщество, а Golang берёт курс на вытеснение интерпретируемых языков и не может работать на системах с критической нехваткой ресурсов, т.к. поставляется с дополнительной средой выполнения (например, сборщик мусора).
Очевидно, что языки C/C++ будут жить ещё очень много лет из-за накопленного за десятилетия кода и программистов, пишущих на них, но Rust имеет все шансы потеснить их, как это когда-то сделала Java.
3. Unsafe губит все гарантии, предоставляемые Rust
Unsafe — это конструкция языка, позволяющая совершать операции, способные привести к неопределённому поведению (UB). В действительности, unsafe позволяет делать лишь четыре операции, запрещённые в "безопасном" Rust:
- Вызов небезопасной функции;
- Реализация небезопасного трейта;
- Разыменование глобальной статической мутабельной переменной;
- Разыменование сырого указателя.
Во-вторых, потенциально небезопасный блок кода может быть инкапсулирован в безопасный блок, т.к. компилятор предполагает, что программист не сомневается в его правильности. Смысл потенциально небезопасного блока кода в том, что при его неправильном использовании поведение программы не определено.
fn safe_display() {
unsafe {
let x = 385;
let x_ref: *const i32 = &x;
println!("{}", *x_ref);
}
}Функция safe_display() полностью безопасна, т.к. правильность потенциально небезопасного блока формально доказуема. Пользователь может использовать эту функцию без боязни UB.
Данный стереотип можно встретить в несколько иной трактовке: "Rust станет популярным лишь тогда, когда его сделают полностью небезопасным". И снова неверно, т.к. не все гарантии, предоставляемые Rust, могут работать в полностью небезопасном коде. Концепция Rust теряется при отсутствии гарантий безопасности.
4. Rust никогда не обгонит C/C++ по скорости
Утверждение безосновательное. В теории, программа, написанная на языке Rust, может быть оптимизирована столь же хорошо, как и аналогичная программа на C/C++. В некоторых синтетических тестах производительности Rust даже обгоняет GCC C:
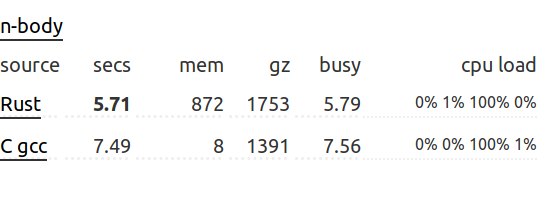
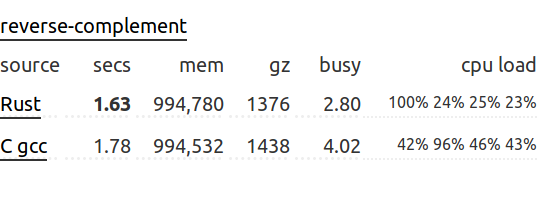

Что касается тестов производительности на реальных задачах, то можно отметить замеры производительности RapidJSON и serde_json. serde_json парсит DOM медленнее, чем это делает RapidJSON, но при сериализации/десериализации структур serde_json обогнал RapidJSON (DOM) как на GCC, так и на CLANG:

Также можно отметить библиотеку Rustls, обогнавшую знаменитую OpenSSL практически во всех тестах (на 10% быстрее при установке соединения на сервере и на 20%-40% быстрее на клиенте, на 10%-20% быстрее при восстановлении соединения на сервере и на 30%-70% быстрее на клиенте).
По сути, когда мы сравниваем производительность Rust, скомпилированного стандартным компилятором rustc, с производительностью C/C++ кода, скомпилированного посредством CLANG, то мы сравниваем качество сгенерированного LLVM IR. В один случаях он может быть более подвержен оптимизациям, в других — менее.
На данном этапе своего развития компилятор rustc ещё не научился генерировать минимальный набор инструкций в сравнении с GCC/CLANG, что, теоретически, может замедлить выполнение программы на пару процентов. Рассмотрим два аналогичных примера кода на Rust и на C CLANG:
Код:
[https://godbolt.org/z/7b46MD]
pub fn compute(input: &mut [i64; 8]) {
for i in 0..input.len() {
input[i] = (input[i] + 3254) * 3;
}
}<T as core::convert::From<T>>::from:
mov rax, rdi
ret
<T as core::convert::Into<U>>::into:
mov rax, rdi
ret
<T as core::convert::TryFrom<U>>::try_from:
mov rax, rdi
ret
<I as core::iter::traits::collect::IntoIterator>::into_iter:
mov rdx, rsi
mov rax, rdi
ret
example::compute:
xor eax, eax
jmp .LBB4_1
.LBB4_3:
mov rcx, qword ptr [rdi + 8*rax]
lea rcx, [rcx + 2*rcx]
add rcx, 9762
mov qword ptr [rdi + 8*rax], rcx
inc rax
.LBB4_1:
cmp rax, 8
jne .LBB4_3
retКод:
[https://godbolt.org/z/YOey3P]
#include <stdint.h>
void compute(int64_t *input) {
for (int i = 0; i < 8; i++) {
input[i] = (input[i] + 3254) * 3;
}
}compute: # @compute
xor eax, eax
.LBB0_1: # =>This Inner Loop Header: Depth=1
cmp rax, 8
je .LBB0_2
mov rcx, qword ptr [rdi + 8*rax]
lea rcx, [rcx + 2*rcx]
add rcx, 9762
mov qword ptr [rdi + 8*rax], rcx
inc rax
jmp .LBB0_1
.LBB0_2:
retrustc сгенерировал больше инструкций, чем CLANG, хотя под капотом одна технология — LLVM. Это недоработка компилятора rustc, но никак не ограничение самого языка Rust, т.к. нет никаких фундаментальных препятствий сгенерировать меньший набор инструкций (как это делает CLANG).
Заключение
Rust не лишён недостатков, таких как сложности реализации некоторых структур данных, временная сырость экосистемы (которая с каждым годом всё нивелируется) и так далее. Надеюсь, что язык займёт свою нишу в современном программировании. Обсуждения — в комментариях.
Комментарии (435)

red75prim
18.09.2019 16:54+6не умеет обрабатывать ошибки аллокации. Пока эту проблему не решат, он не может быть настоящим системным языком.
Хм, мне всегда казалось, что язык системный, если, в частности, на нём можно этот самый аллокатор написать (на Rust это можно сделать). std-часть стандартной библиотеки, которая использует существующий аллокатор и не позволяет обработать OOM, больше относится к прикладному программированию.
dkfrmmnt
18.09.2019 17:10Не понял, что такое «несовместимые между собой синтаксические конструкции». Можно увидеть примеры?
MikailBag
18.09.2019 17:47+4Ну например:
auto x = baz();
vs
decltype(auto) x = baz();
Многообразие синтаксических форм для инициализации
std::vector foo (s.begin(), s.end());
vs
std::vector foo {s.begin(), s.end()};
Более того, НЯП в одной строке создается вектор интов на основе двух итераторов, а в другой вектор итераторов.
Gymmasssorla Автор
18.09.2019 17:53Ещё добавить в этот список несовместимость синтаксисов Си и Си++. Например, разное значение слова
auto, функция с пустыми скобками и т.д., смотреть https://mcla.ug/blog/cpp-is-not-a-superset-of-c.html.


GrimMaple
18.09.2019 17:24+1На данный момент Rust — единственный язык программирования, обладающий одновременно активным сообществом и характеристиками, позволяющими ему решать задачи, решаемые языками C/C++.
А как же D? :'(
lega
18.09.2019 17:39+1Также можно отметить библиотеку Rustls, обогнавшую знаменитую OpenSSL практически во всех тестах
А вы уверены, что более быстрая скорость достингута именно из-за Rust, а не (например) более оптимальным алгоритмом?Gymmasssorla Автор
18.09.2019 17:50+5Скорее всего так, я тесты не профилировал. Но то, что библиотека, которая разрабатывается уже 21 год и написана на Си, оказывается медленнее трёхлетней Rustls уже о чём-то говорит.
Ещё может играть роль криптографическая библиотека ring, используемая в Rustls и частично написанная на Ассемблере.
lega
20.09.2019 12:44-3С учетом того, что раст использует llvm и «unsafe» для оптимизации — говорит о том, что сам раст не может быть быстрее чем С++, который тоже может быть собран с llvm и он всегда «unsafe». А если учесть то что llvm часто дает менее производительный код, стоит говорить о том на сколько раст медленее чем c/c++.
Впрочем по скорости он близок и более важный вопрос — какие фичи он дает за это все, и стоит ли оно того.

KanuTaH
20.09.2019 22:40+2Криптография — это очень сложная штука, и мерять производительность «в лоб» там — сомнительная практика. Например, есть такой класс атак, как timing attacks, когда некие представления о сути зашифрованных данных получаются атакующим исходя из времени, которое атакуемый тратит на их шифрование или дешифрование. Для борьбы с атаками такого рода алгоритмы специально реализуются так, чтобы время выполнения их на любых данных было константным (обычно это означает «наихудшим из возможных»). Так что я бы не стал сильно радоваться тому, что rustls «быстрее». Мало ли почему она быстрее — может, как раз потому, что делает всякие early exits тогда, когда этого бы не стоило делать.
mayorovp
18.09.2019 17:57+4Возможности по оптимизации алгоритма зависят от языка. Причём тут важны не только дешевизна абстракций, но и объём помощи со стороны компилятора.
Общеизвестно, что самые быстрые программы пишутся на ассемблере. Вот только "почему-то" OpenSSL так никто на ассемблер не переписал.

PsyHaSTe
18.09.2019 18:00+3Общеизвестно, что самые быстрые программы пишутся на ассемблере.
Citation needed
mayorovp
18.09.2019 18:06Тяжело искать цитаты для общеизвестных вещей — их редко говорят полностью, предпочитая подразумевать.
Но логика тут простая: любую программу можно преобразовать в ассемблерный листинг, следовательно ассемблер как минимум не хуже любого другого языка. А поскольку одинаковых языков не бывает, он — самый лучший! :-)
Если же вы решили возразить, что сложность написания и сопровождения кода тоже играет свою роль — пожалуйста, перечитайте мой исходный комментарий внимательно.
PsyHaSTe
18.09.2019 18:33+1Ну это "можно" из разряда "boggle sort это тоже алгоритм сортировки". Разве что чисто формально.

vitvakatu
18.09.2019 21:22+5Писать на ассемблере можно было 15 лет назад. Сейчас компиляторы поумнели, ассемблеры усложнились и в результате догнать по эффективности мало-мальски современный компилятор человек не может. Если не верите — зайдите на godbolt и почитайте ассемблер какой-нибудь простенькой программки, желательно с какими-нибудь математическими операциями (чтобы векторизация включилась).
Groramar
18.09.2019 21:37Да всё там пишется и с векторизацией, с учетом кэшей, конвееров и так всяко. Сложно и с нюансами, бесспорно. И мало кому нужно. Но если нужно — то пишется.
mayorovp
18.09.2019 22:30Если же вы решили возразить, что сложность написания и сопровождения кода тоже играет свою роль — пожалуйста, перечитайте мой исходный комментарий внимательно.
mkpankov
20.09.2019 09:28-1Ох уж эти оптимизаторы на ассемблере.
Вы пробовали когда-нибудь написать максимально быстрый на ваш взгляд код для функции на ассемблере, а потом сравнить с кодом, сгенерированным компилятором при хотя бы-O2? Попробуйте.mayorovp
20.09.2019 09:46Если же вы решили возразить, что сложность написания и сопровождения кода тоже играет свою роль — пожалуйста, перечитайте мой исходный комментарий внимательно.

0xd34df00d
20.09.2019 16:25Попробовал. Правда, не на ассемблере, а на SIMD-интринсиках, но это по смыслу ближе к ассемблеру, а не к С (компилятору я оставляю только аллокацию регистров). Разницу в 10 раз спокойно так получал.
Groramar
18.09.2019 21:32Очевидно, что любая программа выполняется на ассемблере (ок, в машкодах). Какая-то из этих программ будет самой быстрой. Следовательно программы, выполняющиеся в ассемблере — самые быстрые. Вопрос только лишь в качестве кодинга.
PsyHaSTe
18.09.2019 22:00Ок, я знаю, в чем проблема. Между "самые быстрые программы пишутся на ассемблере" и "самая производительная программа на ассемблере будет не менее производительней самой производительной программы на любом другом языке" есть пропасть возможностей.
lega
18.09.2019 18:55Причём тут важны не только дешевизна абстракций, но и объём помощи со стороны компилятора.
Т.е. если я правильно понял, вы говорите, что Rust быстрее чем C++ потому что в С++ используют горы обвязок из умных указателей и прочего, а в Rust-е нет.? Справедливаое ли сравниение?, а как же C, там вроде с обвязками попроще?
Общеизвестно, что самые быстрые программы пишутся на ассемблере.
Да, но Rust не на столько более высокоуровневый чем C++, да и вообще более ли?mayorovp
18.09.2019 19:16Т.е. если я правильно понял, вы говорите, что Rust быстрее чем C++ потому что в С++ используют горы обвязок из умных указателей и прочего, а в Rust-е нет.? Справедливаое ли сравниение?, а как же C, там вроде с обвязками попроще?
Нет, я не утверждал ничего из этого, это вы додумали.
Да, но Rust не на столько более высокоуровневый чем C++, да и вообще более ли?
И этого я тоже не утверждал.
vitvakatu
18.09.2019 21:25+2Да, но Rust не на столько более высокоуровневый чем C++, да и вообще более ли?
В среднем более высокоуровневый, на уровне последних стандартов С++ (даже тех, которые еще только на этапе проработки).
Это не значит, что Rust быстрее.
Это не значит, что C++ быстрее.
Это не значит, что в Rust нельзя писать низкоуровневый код.
PsyHaSTe
18.09.2019 22:01Т.е. если я правильно понял, вы говорите, что Rust быстрее чем C++ потому что в С++ используют горы обвязок из умных указателей и прочего, а в Rust-е нет.? Справедливаое ли сравниение?, а как же C, там вроде с обвязками попроще?
Это один из примеров. Второй — в расте можно безопасно шарить данные, Которые в С++ разделять побоятся. Хорошая статья на тему.
tangro
19.09.2019 00:06+2Rust, я так думаю, займёт своё место в наиболее критических местах: прошивки автомобилей, софт для самолётов, код управления важными техпроцессами. Там, где можно позволить себе потратить лишнюю копейку на программиста, но получить в итоге и быструю программу и гарантию того, что она не навернётся на buffer overflow или dead lock.
Обычный код на С++ вытеснен Rust'ом не будет. А зачем?KanuTaH
19.09.2019 00:36+1Интересно, и как же Rust сам по себе гарантирует отсутствие deadlocks? Утрированный пример: есть два потока, один захватывает мутекс и осуществляет блокирующую запись, скажем, в пайп или сокет, второй должен захватывать этот же мутекс и читать из того же пайпа или сокета "с другой стороны". Первый захватил мутекс, начал писать в пайп и встал потому, что буфер у пайпа закончился, второй должен бы по-хорошему прочитать из пайпа и освободить немного буфера, но не может потому, что не может захватить мутекс — вот тебе и deadlock.
Тем, кто считает, что это пример искусственный, и "кто так пишет", рекомендую взглянуть на этот issue:
red75prim
19.09.2019 00:51+2tangro ошибается. Rust предотвращает data races, а не dead locks.
tangro
19.09.2019 10:29Да, верно. Rust не решает всех проблем, но некоторые решает. И если самим фактом его использования можно сразу, по-умолчанию, избежать, например, 50% типичных багов связанных с многопоточностью — это существенный аргумент в некоторых прикладных областях.
tangro
19.09.2019 13:02+1Вот, например, Firefox анализировал баги в своём движке (а точнее в его части, ответственной за парсинг CSS): hacks.mozilla.org/2019/02/rewriting-a-browser-component-in-rust
Насчитали 70 багов, из них 43 связанных с секьюрити, из них в 32 случаях Rust не дал бы даже скомпилироваться коду, который привёл к ошибке. Это много.KanuTaH
19.09.2019 13:10Знаете, языков, которые тем или иным образом предотвращают то, с чем пытается бороться Rust, а именно попытками записи/чтения туда/оттуда, откуда это делать нельзя, уже давно полно (любой managed язык — Java, C#, JS, прости господи, PHP), а багов, связанных с секьюрити, меньше не становится, а, я бы сказал, становится даже больше — особенно на веб-сайтах, на которых вообще никто не задумывается о ссылках, указателях и прочих низкоуровневых деталях в силу специфики средств разработки. Разруха — она не в клозетах, а в головах.
mayorovp
19.09.2019 13:29Много ли RCE найдено в сайтах на ASP.NET?
KanuTaH
19.09.2019 13:33mayorovp
19.09.2019 13:40+1Ну хорошо, одна есть, хоть авторам кода и пришлось постараться чтобы такое допустить (я вот не могу даже представить зачем мне бы понадобилось динамически формировать путь к компоненту на основе ввода пользователя). А ещё?
KanuTaH
19.09.2019 13:44+1Мои услуги по гуглению платные :) Согласитесь, что ошибки типа «можно залить и выполнить файлик» или «можно обойти аутентификацию через SQL injection, войти под админом, залить и выполнить файлик», и так далее, и тому подобное — отнюдь не редки.
PsyHaSTe
19.09.2019 13:45Это видимо один из 11 случаев, когда раст дал бы программе скомпилироваться. Все равно хорошо.
KanuTaH
19.09.2019 13:47Почему именно из 11? :) Довольно произвольная цифра :)
PsyHaSTe
19.09.2019 13:4743-32
KanuTaH
19.09.2019 13:54Это только из того, что было обнаружено конкретно данным анализом, причем анализом на баги конкретного типа — обращение к неинициализированным переменным, выход за границы массива, и проч. Баг, подобный «можно залить и выполнить файлик» вряд ли вообще был бы обнаружен в ходе анализа подобного рода.
mayorovp
19.09.2019 14:02Не редки, но от них очень просто защититься, нужно лишь немножечко внимательности. А более новый ASP.NET Core так и вовсе по умолчанию от этого класса ошибок полностью защищён.
Для сравнения, от переполнения буфера или там use after free в С++ без проседания производительности защититься куда труднее.
PsyHaSTe
19.09.2019 13:31+1Вот я за 6 лет продакшн разработки на сишарпе ни разу не видел выходы за границы буфера или поверждение памяти. Худшее, что может случится — NullRefException или KeyNotFoundException при неаккуратном поиске по словарю. Поэтому "да в ваших манагед языках проблем не меньше" — на порядки меньше проблем с ними.
KanuTaH
19.09.2019 13:34Remote Code Execution, вопреки мнению нашего коллеги, от этого, однако, никуда не делись. Я выше привел ссылку на одну такую от этого года — банально из гугла.
PsyHaSTe
19.09.2019 13:42RCE ортогонален проблемам с памятью, если что.
KanuTaH
19.09.2019 13:45Угу. Только мне тут попытались доказать, что RCE в отсутствие проблем с памятью не случаются, а это не так.
PsyHaSTe
19.09.2019 13:47Не знаю, зачем про RCE вообще вспомнили. Я говорил вполне четко — коррапт памяти, хартблиды и вот это все. На managed-языках такого не происходит, если люди только не отказываются от встроенного механизма работы с памятью (бывают оригиналы, которые выделяют гигабайтный массив в начале программы и начинают с ним работать). Но что поделать, от сумы не зарекайся.
KanuTaH
19.09.2019 13:49Да, но коррапт памяти и хартблиды — это средство, а конечная цель — хищение и/или повреждение данных, а также получение удаленного контроля. И я бы не сказал, что проблем с этим стало как-то кардинально меньше после появления managed языков.
red75prim
19.09.2019 13:39+2А что мешает и разрухой в головах заниматься и унитаз с гидрозатвором вместо дырки в полу поставить?
tangro
19.09.2019 18:39Странно говорить, что Java, C#, JS или, прости господи, PHP не решили никаких проблем, учитывая популярность и распространённость этих языков в современном мире. Они полностью исключили целый ряд проблем и типичных ошибок. Просто само наличие в них Garbage Collector делает их неприменимыми в некоторых классах задач, а Rust пытается решить те же проблемы, но без Garbage Collector. Поэтому я не вижу, почему бы ему в этом не преуспеть.
Gymmasssorla Автор
19.09.2019 19:25Rust не пытается решить те же проблемы, что решают Java/C#/PHP, он скорее разрабатывался для систем с быстрым откликом (высоконагруженные сервера, прошивки автомобилей). Всё-таки на C# программировать бизнес-логику куда проще, чем на Rust, т.к. не приходиться думать о всяких
RefCell/Cell/UnsafeCell/etc.
mkpankov
20.09.2019 09:32И ни один из этих языков не пересекается по нише с Rust.
Сравнивать rustls с openssl — нормально. Когда первая достигнет объёмов использования хотя бы в 10% от openssl, можно будет увидеть, что уязвимостей там правда меньше.
При этом не стоит забывать, что поиск уязвимостей тоже не стоит на месте. Благодаря ASLR, защите стека, DEP и другим прелестям, классическое переполнение буфера уже когда сложнее превратить в эксплуатируемую уязвимость — а значит внимание смещается на "менее технические" моменты, не связанные с конкретным языком программирования. Социальная инженерия, например, сильна как никогда.
Gymmasssorla Автор
19.09.2019 00:46Переписывать код с C++ на Rust затруднительно (переписывание с любого языка затруднительно), и, скорее всего, проекты, написанные на C++ на нём и останутся.
Писать новые проекты на Rust имеет смысл из-за более быстрой скорости разработки, т.к. меньше бойлерплейт-кода, библиотеки в целом эргономичнее, нет возни с системами сборки и поиском UB в коде.

Antervis
19.09.2019 19:45Писать новые проекты на Rust имеет смысл из-за более быстрой скорости разработки, т.к. меньше бойлерплейт-кода
В расте нет наследования -> тот код, который хорошо выражается наследованием, в расте создает очень много бойлерплейтаGymmasssorla Автор
19.09.2019 19:53Можете привести пример? Композиция в большинстве случаев работает хорошо, если она вообще нужна.
a1ien_n3t
19.09.2019 22:27Отличный пример например реализация парсера xml'е подобных сущностей.
Где есть бызовый элемент. И куча его спецификацей.
В расте это решается либо копипастой релизацией трейта. Либо нетривиальными макросами либо еще чемто. Тоесть да решить или написать это можно но требуется гораздо больше телодвижений.PsyHaSTe
19.09.2019 22:55+1Не вижу сложностей. Каждый узел дерева это просто энум из нескольких возможных значений. И мы с ними что-то делаем.
Вы что-то путаете. Наоборот, для обхода XML исторически используют визиторы, которые ни что иное как способ эмулировать ADT в ООП языках :)

technic93
19.09.2019 23:41Но почему то в serde там какой то условный бойлер-плейт из функций visit_abc вместо enum. Я пытался обернуть их апи на матч по енуму, но не получилось. И мне помнится проблема была в том что там навёрнут ещё полиморфизм с точки зрения разных парсеров (хмл жсон и т п).
Т.е. все visit_abc<xyz: parser> так устроено.
vitvakatu
20.09.2019 09:50+1Да, потому что serde — это не парсер, а инструмент для создания парсера (вернее, сериализатора и десериализатора). Enum'ы там применять нельзя, потому что у каждого формата свой Enum, а на этапе компиляции заменять их не получится. Вот и пришлось прикручивать Visitor. Но вот реализация самих сериализаторов, как например
serde_json— уже основана на использовании enum'ов.technic93
20.09.2019 10:51Парсер т.е. десиарелизатор джсона там тоже на этих визиторах. Да он может построить дерево из енумов на выходе, но это не всегда хороший вариант т.к. связано с аллокацией памяти для словаря и списка. А хочется прозрачный парсер на енумах. Т.е. чтобы вместо того чтобы переопределять visit_str, visit_vec и т п (а там из за дженериков эти определения длиной во всю строку) для каждой структуры, я мог сделать аналогичный match, который заявляется как одна из киллер фич раста.
Antervis
20.09.2019 11:37+1TristateCheckBox -> CheckBox -> Button -> Widget. У Widget'а есть метод show(), но его придется явно реализовывать для Button, CheckBox, и TristateCheckBox
vitvakatu
20.09.2019 11:42Ну вообще-то в вашем примере у всех этих классов разная реализация show должна быть и наследование тут никак не поможет. Могли бы привести в пример getBounds, например.
Antervis
20.09.2019 11:55+1Ну вообще-то в вашем примере у всех этих классов разная реализация show должна быть
inline void Widget::show() { set_visible(true); }
вместо
// Widget: fn show(&self) { self.set_visible(true); } // Button: fn show(&self) { self.widget.show(); } // CheckBox: fn show(&self) { self.button.show(); } // TristateCheckBox: fn show(&self) { self.checkbox.show(); }vitvakatu
20.09.2019 12:32А, пардон, я думал что show() отрисовывает виджет на экране непосредственно.
Чтобы скомпенсировать свою оплошность, привожу пример как это может выглядеть на расте:
pub trait Show: Visible { fn show(&self) { self.set_visible(true); } } impl Show for Button {} impl Show for CheckBox {} impl Show for TristateCheckBox {}
Но на практике конечно так весело редко получится.
Antervis
20.09.2019 12:59+1ну отлично. Вы написали 8 строк для абстрактного show(), но теперь нам для каждого из этих классов по-разному реализовывать set_visible(). Усугубили проблему, так сказать
vitvakatu
20.09.2019 13:20Почему же усугубил? Хитро переложил количество кода с show на set_visible, но усугубления тут нет, общее количество кода в общем то такое же.
Antervis
20.09.2019 13:42+3Именно что усугубили. Если в моём примере надо было один раз написать Widget::set_visible() и несколько версий show(), то в вашем получается 8 строк для трейта show(), но для каждого из классов придется писать свой set_visible() чтобы реализовать трейт Visible, который объявляется еще несколькими строками. Ваш подход наверно соответствует «rust way» и подходит для большинства случаев, но не помогает бороться с бойлерплейтом в конкретном.
По сути, у всех классов из примера должны отличаться:
а. методы paint(),
б. обработчик on_clicked()
в. свойства checkable/checked для Button и check_state для CheckBox/TristateCheckBox.
При этом они будут делить между собой очень много методов Widget'а, логика которых отличаться не должна. Те самые свойства visible/width/height/style/pallette/parent/children/… и их алиасы show()/hide()/geometry()/… В расте (как минимум пока что) нет удобного способа переиспользования такого вот кода без бойлерплейта. Кстати, в т.ч. поэтому переписывать с плюсов на раст столь болезненно.vitvakatu
20.09.2019 15:54Да, признаю свою ошибку. Что поделаешь, в Расте действительно нет наследования и действительно с плюсов код не переписать. Расстраивает тут разве что то, что без наследования никто не умеет рисовать интерфейсы нормально (впрочем, с наследованием нормально умеет только C++, похоже).
mayorovp
20.09.2019 16:37Расстраивает тут разве что то, что без наследования никто не умеет рисовать интерфейсы нормально
А это обусловлено предметной областью. Так уж получилось, что кнопка действительно является виджетом.
vitvakatu
20.09.2019 16:40Да, в терминах существующих GUI библиотек это так. Но что значит "обсуловлено предметной областью"? Вы же не станете утверждать, что "являтся виджетом", это неотчуждаемое свойство всех элементов графического интерфейса? Это абстракция, обсуловленная популярными GUI библиотеками, основанными на наследовании, не более.
math_coder
20.09.2019 16:59А зачем делать кнопку структурой? Пусть и кнопка, и виджет будут трейтами. У трейтов наследование есть.
mayorovp
20.09.2019 17:04Затем, что у неё свои поля есть.
0xd34df00d
20.09.2019 17:21А в чём проблема с таким подходом (пардон за синтаксис, я растовский не знаю)?
class Widget w where show :: w -> IO () hide :: w -> IO () paint :: w -> IO () class Widget l => TextInput l where setValue :: String -> l -> IO () getValue :: l -> IO String
Я гуи никогда на функциональщине не делал, поэтому не знаю, как это делать правильно, но сходу в таком подходе никаких проблем не вижу.
Ну и можно поиграться даже с более широкой иерархией классов, когда у вас будет
class Widget w where ... class HasText ht where setValue :: String -> l -> IO () getValue :: l -> IO String class (Widget tl, HastText tl) => TextLine tl class (Widget mte, HasText mte) => MultilineTextEdit mte
В ООП это начинает либо плохо пахнуть со множественным наследованием, либо начинается эмуляция трейтов на интерфейсах.
Надо бы ещё куда-нибудь multiparam type classes запихнуть...
mayorovp
20.09.2019 17:28Это вы только API определили. А теперь напишите реализацию этой радости.
0xd34df00d
20.09.2019 17:37-- где-то в библиотеке {-# LANGUAGE DataKinds, PolyKinds #-} data WindowType = TextLine | MultilineTextEdit -- за счёт PolyKinds пользователь библиотеки -- может объявлять свои типы окон и доопределять -- нужные классы newtype NativeWindow (wty :: k) = NativeWindow { wid :: Int } class Creatable (wty :: k) where createWid :: Proxy wty -> IO Int instance Creatable TextLine where createWid _ = underlyingCLibraryCreateTextLine instance Creatable MultilineTextEdit where createWid _ = underlyingCLibraryCreateMTE instance Creatable wty => Widget (NativeWindow wty) where show = underlyingCLibraryShow . wid hide = underlyingCLibraryHide . wid paint = genericPaint . wid -- забыл в том интерфейсе метод create :: IO w create = NativeWindow <$> createWid (Proxy :: Proxy wty) instance HasText (NativeWindow TextLine) where setValue str = cLibrarySetTextLineStr str . wid ...
Не уверен, что оно вот так сходу протайпчекается, писал из головы, но идея такая.
Можно ещё там обмазаться семействами типов, чтобы
create :: CreateParams w -> IO w, например, дописать type role для тега уNativeWindow(чтобы компилятор не выводил Coercible), короче, есть, как развернуться ещё.mayorovp
20.09.2019 17:40Вот это неинтересно:
setValue str = cLibrarySetTextLineStr str . wid
Такой подход для биндингов хорош, а интересует полноценная реализация своих контролов.
0xd34df00d
20.09.2019 17:41Ну так совершенно аналогично пишете свой код для контролов. Нет принципиальной разницы, дёргать там одну сишную функцию для биндингов или сто сишных функций для отрисовки чего надо через xcb.
mayorovp
20.09.2019 17:47Да не получится аналогично!
Вот есть у меня какой-нибудь
data MyControl = MyControl { parent :: NativeWindow TextLine, state :: IORef Int state }
Как мне делегировать show/hide/setValue/getValue (и ещё 100 разных функций) parent, а paint определить самому?
0xd34df00d
20.09.2019 18:04Так — никак. У меня там весь расчёт на то, что можно
data MyControlTag = MyControlTag netype MyControl = NativeWindow MyControlTag
Тогда можно переопределить только тот тайпкласс, которому принадлежит
paint(так что тайпклассы должны быть мелкими), а остальные будут выбираться как менее специфичные.
Если вам действительно охота таскать с собой свои данные, то можно вместо
newtypeсделатьNativeWindowтипом данных в стиле trees that grow:
type family WindowData (tag :: k) data NativeWindow tag = NativeWindow { wid :: Int , wdata :: WindowData tag }
Правда, тогда его лучше назвать
GenericWidgetили как-то так.
Норм, хорошее обсуждение, ща гуи-фреймворк так напишем.
math_coder
20.09.2019 18:08Понятно, что у кнопки свои поля есть. Не вижу как это мешает. https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=5c3b78efb712ccbfa84663ca4dc7c620
Единственно, чего не хватает — это языковой поддержки автоматической имплементации трейта через филд. Я думаю, это появится. Сейчас скорее всего можно выкрутиться макросами, но это надо подумать как сделать.
mayorovp
20.09.2019 18:23Ну так вот именно эту часть писать и не хочется:
impl Widget for ButtonRuntime { fn set_visible(&mut self, v: bool) { self.widget.set_visible(v); } fn show(&mut self) { self.widget.show(); } }
Собственно, это и есть тот бойлерплейт, которого неизбежно будет много.
math_coder
20.09.2019 18:25+1Да, это бойлерплейт. Он решается кострукцией а-ля
impl Widget for ButtonRuntime through self.widget;. Я думаю есть все шансы, что она появится.mayorovp
20.09.2019 18:27Я тоже так думаю, проблема в том что прямо сейчас её нет.
math_coder
20.09.2019 18:40Я как раз пишу сейчас нечто cхожее в этом плане с библиотекой виджетов и думаю попробовать соорудить что-то из макросов. Но это надо ещё думать как провернуть.
Antervis
20.09.2019 19:08+1можно попробовать определять методы в трейте IWidget через self.get_widget().foo(), а в «наследниках» переопределять уже только get_widget() -> &mut Widget. Так можно уменьшить число методов, которые придется переопределять «наследниках». Некоторое кол-во бойлерплейта всё равно будет, но оно уже будет линейно N классов, а не полиномиально от N классов и M их методов.
math_coder
20.09.2019 21:13Более того, это видимо и единственный вариант, так как наследования трейтов в расте тоже в существенной степени нет, это я стормозил.
math_coder
20.09.2019 22:01Вот что получается: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=a1594df0b51141a5bdbdb22bb9cdbb6c

lain8dono
21.09.2019 05:04
Если будете пихать это в свои макросы, то назовите его
awesome_fortran. А вообще эту фигню можно запилить через процедурные макросы. Возможно это даже есть уже.technic93
21.09.2019 12:12А с двумя типами получится через Deref, типа множественное наследование? Хотя это более редкий случай.
math_coder
21.09.2019 14:00Если будете пихать это в свои макросы
Нет, это обсуждение подтолкнуло меня к следующим выводам.
- Такой подход к построению библиотеки виджетов и аналогичных систем требует всей мощи "классического" (как в C++/Java/C#) ООП.
- Если вам нужно ООП целиком, а не отдельные его паттерны, хорошо выразимые другими средствами (ФП, АП и т. д.), вы что-то делаете неправильно.
- Я делаю неправильно, надо искать другие подходы.
Идеи есть, буду пробовать. Если получится, обещаю запилить статью про метод создания библиотеки виджетов без ООП.
lain8dono
21.09.2019 18:08Я делаю неправильно, надо искать другие подходы.
technic93
21.09.2019 18:49Там если глянуть на все эти
impl Abc for Widgetто будет примерно то что math_coder выше предлагал.
Groramar
21.09.2019 00:27(впрочем, с наследованием нормально умеет только C++, похоже).
Delphi отлично справляется. К слову, UB на нем вообще нет.
PsyHaSTe
19.09.2019 01:14+3Обычный код на С++ вытеснен Rust'ом не будет. А зачем?
Давно заметил, что плюсовики с опытом в расте почти никогда не получают ошибок компиляции. Просто потому что у них RAII уже встроен в голову :) Поэтому он их никак не замедляет, иногда только поправляет, они такие "хм, точно, тут же ссылка висячая" и быренько исправляют.
А вот новички так не умеют. Поэтому иметь язык, где новичок гарантированно не запишет вам мимо буфера и не разыменует нулл где не надо очень ценно. Не говоря о том, что компилятор очень хорошо объясняет, что не так => экономия времени сениора на вопрос "а почему я не могу тут в возвращаемой лямбде на локальную переменную сослаться".
tangro
19.09.2019 10:33Я имел в виду, что уже существующий прикладной код на С++ мало смысла переписывать на Rust (за исключением нескольких определённых областей, где никакого шанса улучшить надёжность нельзя упускать). А новые проекты или модули — да, весьма вероятно будут начинаться на Rust всё чаще.

Revertis
19.09.2019 12:34Firefox уже вовсю переписывается на Rust.
Недавно пробовал его собирать, так там просто дофигища растового кода.tangro
19.09.2019 12:56У Firefox свои причины, которые подойдут не всем:
1. Они переписывают на Rust в основном только то, что и так собирались переписывать по каким-то причинам (переход на новую архитектуру, разбиение на модули, убирание lagacy)
2. Они переписывают на Rust те компоненты, в которых у них была длинная история секьюрити-багов
3. Это всё-таки opensource и люди могут писать на Rust, ну, потому что им прикольно писать на Rust.
vvzvlad
20.09.2019 12:45Ну, третий пункт не совсем верен. Эти компоненты не стали бы переписывать на питоне, потому что им прикольно писать на питоне.
0xd34df00d
19.09.2019 02:57Раст всё-таки слабоват для таких вещей с точки зрения гарантий. Есть (и используются) более надёжные языки.
tangro
19.09.2019 10:31это какие?
0xd34df00d
19.09.2019 16:36Coq, Agda, Lean какой-нибудь. Потенциально тот же Idris.
mkpankov
20.09.2019 09:34Упоминать в этом разговоре суровую академию это даже неприлично.
0xd34df00d
20.09.2019 16:27Суровая академия — это папиры с описанием того, почему на самом деле эти языки дают какие-то там гарантии.
PsyHaSTe
19.09.2019 11:38Если вам нужен язык с гарантиями и без латентности и низким профилем потребляемой памяти то лучше языка не найти :dunno:
Когда тонна памяти и можно гхц/жвм поднять это другой вопрос.
0xd34df00d
19.09.2019 16:38Ну можно взять кок с экстракцией в окамл, для окамла есть совершенно адовые оптимизирующие компиляторы, дающие уровень сишечки. Про профиль потребляемой памяти не знаю, правда, но окамл строгий по умолчанию, так что должно быть норм.
Ну и да, терпеть не могу эти слова, но можно же просто взять железку побольше, если гарантии действительно важны.
Keynessian
19.09.2019 09:48Есть ли какая-нибудь библиотека для Rust позволяющая работать с ООП?
Rust — мне очень нравится, но очень смущает то как в нём обстоит с объектами.

skrimafonolog
19.09.2019 09:55Просто не тяните целиком концепции из одного языка в другой — и все у вас будет хорошо.
В Rust нет объектов, но есть вполне себе сходная по функционалу концепция широко известная по прочим языкам как «интерфейсы».
vitvakatu
19.09.2019 10:09Единственная часть ООП, которой нет в Расте — наследование. Его заменяет композиция. Есть случаи, когда оно в целом менее удобно, но в большинстве случаев краткость и понятность кода только увеличивается. К слову архитектуру с гифки на Расте можно воспроизвести, в этом нет проблемы.
Keynessian
19.09.2019 15:22А как с поддержкой Vulkan API в Rust?

(или хотя бы с поддержкой триады OpenGL/OpenAL/OpenML, если с поддержкой Вулкана вдруг не очень)vitvakatu
19.09.2019 15:37С этим очень круто, обратите внимание на проект gfx-rs: https://github.com/gfx-rs/gfx и на wgpu-rs: https://github.com/gfx-rs/wgpu
Если коротко — поддерживаются по факту все современные и не очень GAPI, у некоторых — несколько реализаций (как в случае с Vulkan, есть
gfxи естьvulkano). Раст также оказался на острие прогресса в современной Web-графике.
PsyHaSTe
19.09.2019 11:40Ну картину 1в1 можно перенести, все интерфейсы это трейты будут, а реализации — структуры.

NikitOS9
19.09.2019 12:04>4. Rust никогда не обгонит C/C++ по скорости
по сути сравнивается c llvm (opt и llc) же.
сейчас (может так и останется) rustc это фронт для llvm или это не так?Revertis
19.09.2019 12:37Да, типа того. Но rustc тоже может готовить немного оптимизированный для llvm промежуточный код.
eao197
19.09.2019 12:53После прочтения остался в недоумении: стереотип "Rust — ещё один "убийца C/C++"" таки был развеян или, напротив, подтвержден? Не понятно, то ли Rust не убийца, то ли убийца, но не ещё один.
Cerberuser
19.09.2019 12:57Я так понял, что в стереотипе слова "убийца C/C++" понимаются в ироническом ключе — типа "замахнулся на святое, а сам-то...", и "развеивание" заключается в том, что замахнуться он как раз вполне себе вправе, пусть и не сейчас, а на перспективу.
Gymmasssorla Автор
19.09.2019 14:36Ключевое слово — "ещё один". В статье я показал, что Rust — не "ещё один", а действительно способен вытеснить C++ в некоторых сферах.
embden
19.09.2019 13:16А как там дела у раста с кроссплатформенным GUI? Чтобы Linux, Windows, Android?
vitvakatu
19.09.2019 13:50Плохо. Как дела с этим у всех остальных языков, кроме C++, Java, JavaScript и C#? И кстати почему забыли iOS и Mac?
PsyHaSTe
19.09.2019 13:57У сишарпа тоже все плохо, и у джавы емнип. Только электрон и мб Qt. Всё.
KanuTaH
19.09.2019 13:58А у сишарпа плохо? Я вот пользуюсь Keepass2Android, он вроде на Mono, нет?
PsyHaSTe
19.09.2019 14:04Ну нет у дотнета кроссплатформенного UI. Какие-то надежды на авалонию, но оно все еще сыро до невозможности. Моно как платформу я в принципе не рассматриваю, мало того что там собственные классные баги (из-за чего я так понимаю моно-фреймворки нельзя просто перевести на кор), так еще и когда я делал экспериментальный винформ-проект под моно, он выглядел так, что я его закрыл и никогда больше не возвращался.
Groramar
21.09.2019 00:33У сишарпа тоже все плохо, и у джавы емнип. Только электрон и мб Qt. Всё.
Delphi/Lazarus еще.PsyHaSTe
21.09.2019 10:00Не знаю как у вас, а в моем представлении дельфи давно мертв. Очень уж он неудобный в 2019-то году. Писал на нем весь универ 6 лет, но пора бы и честь знать.
Groramar
21.09.2019 11:20Нормально всё с Делфи и у нас и у вас. В чем неудобство то? Отлично работает. Под все платформы уже и давно.
PsyHaSTe
21.09.2019 12:32Ну давайте далеко за примером ходить не будем. Вот допустим у нас есть дерево ID комментариев и мы хотим из него получить дерево самих комментариев. То есть
Tree<CommentID>->Tree<Comment>. Функция загрузки комментария с сервера асинхронная, по одному айди один комментарий (нет, нельзя просто передать список ID чтобы сервер их все сразу вернул).
Как это будет выглядеть на дельфи? На современных ЯП это 1-2 строчки с простым кодом.
eao197
21.09.2019 13:34На современных ЯП это 1-2 строчки с простым кодом.
Правда всего 2 строчки? Можно пример?
PsyHaSTe
21.09.2019 13:46Ну примерно так
get_tree_comments_async :: Tree CommentId -> Async Tree Comment get_tree_comments_async = traverse get_comment_by_id_async
или на скалке
def get_tree_comments_async(tree: Tree[CommentId]) : Async[Tree[Comment]] = tree.traverse(get_comment_by_id_async)
Дальше можно авейтить полученную футуру и получить дерево с комментами. Благодаря современным системам типов траверсы есть в стандартной поставке, и их не надо писать самому. Последний раз когда мне понадобилось в шарпах пофильтровать список по условию, которое прилетает в результате HTTP запроса очень пожалел, что там этого пока не завезли (но завезут).
embden
19.09.2019 13:57Мне просто необходимо было написать приложение для этих трёх платформ. Выбор был между C++ с Qt и rust с чем-то не очень пригодным к использованию. Rust отложен в долгий ящик — нету у него пока возможностей тягаться с C/C++ в интересной мне области.
TargetSan
19.09.2019 14:22Справедливости ради прикиньте, сколько человеколет и 20-футовых контейнеров денег вбухано в Qt — который начали разрабатывать в 91м, а первый релиз был в 95м. А для раста GUI сейчас пилится в основном энтузиастами по 1-2 человека.
lain8dono
19.09.2019 15:15Да с любым GUI у нас всё очень плохо. Не только с кроссплатформенным. Можете глянуть https://areweguiyet.com/. Чего не хватает для хорошего полноценного GUI? Нормальной обработки текста, вот чего. Н???е???л???????ь?з??я??????? ????п????????ро?с????т?????о???? ????????вз????я???????т??ь???? ??????и?? ???н???ари?с?????о????????в???а??ть????? ?????п?р??о??????и?зв????????ол???????ь??н????у????????ю?????? ???????п??о????????с??????л??е????????д????????о??????в??????ат???????е????л?????ь????н??о???с????т???????ь????? ???г??????л???и??ф??????о???????в??.???
Такие дела. Ждём новостей от https://github.com/linebender/skribo.

rwscar
19.09.2019 14:31Я наверное ещё недостаточно хорошо понимаю в программировании, но всё же.
Может ли кто-нибудь, пожалуйста, пояснить, в чём профит использования минималистичных ключевых слов и прочих языковых элементов в дизайне ЯП?
Как по мне, так все эти fn, struct, mut, скобочки всех возможных видов и знаки пунктуации в огромных количествах делают язык очень похожим на Brainfuck и визуально сложным.Gymmasssorla Автор
19.09.2019 14:32+1Не могу сказать, что укороченные синтаксические конструкции делают язык сложным для восприятия. Может даже наоборот — меньше нужно глазами бегать по экрану чтобы понять что делает код.
TargetSan
19.09.2019 15:56+1Моё личное мнение как человека, пишущего в основном на С++.
Короткие ключевые слова никаких проблем не доставляют, вопрос скорее привычки.
Java для сравнения вызывает у меня чувство необходимости "писать поэмы".
Знаков пунктуации в реальном коде получается ставнительно немного. В том же Go мне например хотелось бы их чуть побольше. Ну а с С++ вообще не сравнить.
Siemargl
19.09.2019 18:43-2Проблема не в количестве знаков в ключевых словах, а в количестве идиом, которые можно всунуть в одну строку на расте.
Получается в итоге примерно как однострочники в С или обфусцированный JS
Например
macro_rules! with_handles { ([($handle_name: ident: $unhandle_name: block)] => $body: block) => { $unhandle_name.run(|$handle_name| { $body }) }; ([($handle_name1: ident: $unhandle_name1: block), ($handle_name2: ident: $unhandle_name2: block), $($rest: tt)*] => $body: block) => { $unhandle_name1.run(|$handle_name1| { with_handles!([($handle_name2: $unhandle_name2), $($rest)*] => $body) }).and_then(|n: $crate::utils::HandleResult<_>| n) }; ([($handle_name: ident: $unhandle_name: block), $($rest: tt)*] => $body: block) => { $unhandle_name.run(|$handle_name| { with_handles!([$($rest)*] => $body) }).and_then(|n: $crate::utils::HandleResult<_>| n) }; }
Или примеры попроще прямо из учебника
// парсинг массива строк { let strings = vec!["tofu", "93", "18"]; let (numbers, errors): (Vec<_>, Vec<_>) = strings .into_iter() .map(|s| s.parse::<i32>()) .partition(Result::is_ok); let numbers: Vec<_> = numbers.into_iter().map(Result::unwrap).collect(); } // безопасная с обработкой ошибок ф-ция sqrt(ln(x / y)) fn op(x: f64, y: f64) -> f64 { match checked::div(x, y) { Err(why) => panic!("{:?}", why), Ok(ratio) => match checked::ln(ratio) { Err(why) => panic!("{:?}", why), Ok(ln) => match checked::sqrt(ln) { Err(why) => panic!("{:?}", why), Ok(sqrt) => sqrt, }, }, } }PsyHaSTe
19.09.2019 20:24Ну с такими примерами конечно раст страшный.
А ведь если переписать нормально, то будет выглядеть так:
fn op(x: f64, y: f64) -> f64 { checked_div(x, y) .and_then(checked_ln) .and_then(checked_sqrt) .unwrap() }
Siemargl
19.09.2019 22:15-1Вы Меня попрекаете примерами из офсайтовского учебника с rust-lang ???
Вы в своем уме? Хотя вопрос риторический.red75prim
19.09.2019 22:40+1Там же на следующей странице приводится пример, как избавиться от этой пирамиды match'ей.
lain8dono
21.09.2019 05:22А ещё лучше вот так:
fn op(x: f64, y: f64) -> Result<f64, String> { use checked::{ln, div, sqrt}; sqrt(ln(div(x, y)?)?) }
БЕЗ ПАНИКИ!
Теперь откройте следующую страницу путеводителя по галактике.PsyHaSTe
21.09.2019 10:01Так там паника может наоборот нужна, а вы семантику поменяли. Понятное дело, что резалты нужно всегда использовать, но если это какой-нибудь build.rs то усложнять нет смысла.
math_coder
19.09.2019 17:18+3let mutable my_variable: Option<&mutable dynamic MyVerySpecificTrait> = &mutable some_variable.as_reference().lock().unwrap().as_reference();
и
let mut my_var: Option<&mut dyn MyTrait> = &mut some_var.as_ref().lock().unwrap().as_ref();
Или
function some_function(input: implements Function(implements IntoString) -> Box<dynamic SomeTrait>) -> implements Iter<Item=ReferenceCell<integer_16bit>>
и
fn some_fn(input: impl Function(impl IntoString) -> Box<dyn SomeTrait>) -> impl Iter<Item=RefCell<int16>>
Всё-таки несмотря на хорошо известные проблемы сокращений, второй вариант побеждает за счёт лучшей читаемости.

DreamingKitten
19.09.2019 18:59Это, к.м.к. некий разумный компромисс между слишком уж словоохотливыми языками типа Паскаля, со всеми этими begin-end, repeat-until, unit-interface-implementation-initialization-end и тому подобного. Даже с автокомплитом и копипастами набиваешь эти многотомники и чувствуешь как на каждой строчке у тебя крадётся по полсекунды времени; и языками, по которым проводится ежегодный International Obfuscated Code Contest.
Groramar
21.09.2019 00:40Паскаль сейчас в своих реализациях очень хорошо оптимизирован, что бы bloated code вообще не замечать при наборе. Например begin/end ставится просто хоткеем, удобно, всегда так и делаю. Читать конечно это всё сильно удобнее, чем плюсы и остальные птичьи языки.
PsyHaSTe
21.09.2019 10:02-1Нужно быть большим оригиналом чтобы паскаль был читаемым. Проблема не в том, что код на паскале трудно набирать (хотя в 7 дельфи фиг а не сниппеты), а в том, что читать это обычным людям невозможно.
Groramar
21.09.2019 10:32Читаемость Паскаля — один из краеугольных камней языка же :) О чем вы. Читаемость на уровне почти обычных предложений английского языка. И, на минуточку, после 7-ки 20 лет уже прошло :)
PsyHaSTe
21.09.2019 11:07Читаемость Паскаля — один из краеугольных камней языка же
Ну вот я её не ощущаю. После того как перешел на шарпы стало намного проще и читаемее. Особенно объявление пропертейв паскале было стремным. Хелсберг одобряе.
Groramar
21.09.2019 11:25А что не так с пропертями? Вроде прозрачно всё. Да и как-то я больше по коду — проперти записал и забыл. Я в них хорошо если 0.1% времени смотрю. Скорее меньше.
К слову — существую редакторы свойств, кому лень руками набирать. Свойства можно добавляють в один хоткей чаще всего (2 нажатия — хоткей + Enter).
Повторюсь: bloated сейчас максимально автоматизирован.
Alesh
19.09.2019 15:17Ага именно «элегантная абстракция» стало решающим в прекращении изучения Rust. На уровне хелоуворда вопросов нет, все красиво и логично. Но более сложные конструкции вызывают взрыв мозга. Темплейты С++ ничем не лучше конечно, но что бы «ощутить их мощь», надо серьезно заморочиться с кодом. Многие пишущие на Плюсах знают о темплейтах только верхушки и прекрасно пишут. А вот с Растом, шаг влево, шаг вправо от хелоуворда, и здравствуйте я ваша тетя :) Может конечно что изменилось за три года, но вроде как нет, только усугубилось.
vitvakatu
19.09.2019 15:47+1Чисто ради моего интереса — что конкретно имеете в виду? Насколько я понимаю, вы про лайфтаймы? Мне правда интересно увидеть примеры кода, который технически оправдан и при этом вызывает взрыв мозга.
Для читателей комментов: у меня вот тут сейчас есть проект, в котором более 100 тыс. строк кода исключительно на расте написаны. Точное количество лайфтаймов в этой кодовой базе — 152, за исключением
&'static. Если вместе с ним — 191. И почти во всех этих случаях использование абсолютно тривиально, я даже думаю от многих использований можно избавится в современных версиях компилятора.

rboots
19.09.2019 16:59+1Больше всего в Rust понравился единый репозиторий пакетов с удобным поиском, это пожалуй самое большое преимущество для практической разработки.
Antervis
19.09.2019 19:31-2Функция safe_display() полностью безопасна, т.к. правильность потенциально небезопасного блока формально доказуема
а если не доказуема?
В некоторых синтетических тестах производительности Rust даже обгоняет GCC C:
Когда кто-то сравнивает языки программирования замеряя перф разных библиотек:

А если взять все 100500 библиотек плюсов/си, сопоставить их с аналогами на расте и замерить, в скольки процентах случаев выиграет раст?
В расте надо выбирать написать код без unsafe или чуть более оптимальный внутри unsafe. Первый вариант предпочтителен в подавляющем большинстве сценариев. В плюсах такой диллемы перед программистом не стоит.Gymmasssorla Автор
19.09.2019 19:58+1а если не доказуема?
Значит программист неправильно написал Unsafe блок, который впоследствии породит UB.
А если взять все 100500 библиотек плюсов/си, сопоставить их с аналогами на расте и замерить, в скольки процентах случаев выиграет раст?
Я и не утверждал, что Rust всегда быстрее C/C++.
Antervis
20.09.2019 11:46Значит программист неправильно написал Unsafe блок, который впоследствии породит UB.
Как формально доказать, что использование функции из 3rdparty библиотеки всегда корректно? Особенно когда это проприетарная библиотека? Всё-таки «ошибка не в моём коде» != «моя программа работает корректно»
Я и не утверждал, что Rust всегда быстрее C/C++.
а смысл выбирать из всего множества только те пару библиотек где раст «даже обгоняет плюсы»?mkpankov
20.09.2019 12:29Проприетарные библиотеки в смысле "нам кто-то дал бинари, но не исходники" в экосистеме Rust пока не использует никто. Там и с распространением будут проблемы. С другой стороны, а чем это хуже проприетарной библиотеки на C или C++?
А на тему аудита экосистемы есть интересные инициативы: 1 2.Antervis
20.09.2019 13:48Проприетарные библиотеки в смысле «нам кто-то дал бинари, но не исходники» в экосистеме Rust пока не использует никто
Почему-то я уверен, что используется winapi, что используются библиотеки драйверов видеокарт/баз данных и черт сломит ногу сколько всего остального.
Интеграция проприетарных библиотек в любом случае должна быть простой, иначе у раста попросту не будет будущего в некоторых сферах.mkpankov
20.09.2019 14:12К winapi естественно используются биндинги, так что всё интересное там происходит на стороне C++-тулчейна, а не раста.
Gymmasssorla Автор
20.09.2019 14:57Как формально доказать, что использование функции из 3rdparty библиотеки всегда корректно? Особенно когда это проприетарная библиотека? Всё-таки «ошибка не в моём коде» != «моя программа работает корректно»
А никак, это делать должен создатель 3-rd party программного обеспечения, как и во всех других языках. Не понял что Вы хотите услышать. Unsafe блок либо может породить UB (если его с ошибкой написали), либо нет (если его написали правильно).
а смысл выбирать из всего множества только те пару библиотек где раст «даже обгоняет плюсы»?
Смысл в опровержении "Аналогичный код на Rust не может быть быстрее C/C++". Тут уже входят в дело бесплатные оптимизации о компилятора и zero-cost абстракции (что в синтетических тестах показано). Библиотеки были включены для более полного понимания картины.
Antervis
20.09.2019 15:41А никак, это делать должен создатель 3-rd party программного обеспечения, как и во всех других языках
Всё-таки «ошибка не в моём коде» != «моя программа работает корректно»
Смысл в опровержении «Аналогичный код на Rust не может быть быстрее C/C++»
На си/плюсах всегда можно написать код, аналогичный таковому на расте, с теми же самыми оптимизациями (llvm и пр.) и он будет эквивалентным. В обратном направлении это не работает, и найти пример несложноGymmasssorla Автор
20.09.2019 16:47Всё-таки «ошибка не в моём коде» != «моя программа работает корректно»
Это всем и так понятно.
На си/плюсах всегда можно написать код, аналогичный таковому на расте, с теми же самыми оптимизациями (llvm и пр.) и он будет эквивалентным. В обратном направлении это не работает, и найти пример несложно.
Это не ограничение Rust, а скорее недоработка компилятора rustc, т.к. такой же код на Rust можно скомпилировать в меньший набор инструкций, ничего не мешает это сделать.
PsyHaSTe
21.09.2019 10:07На си/плюсах всегда можно написать код, аналогичный таковому на расте, с теми же самыми оптимизациями (llvm и пр.) и он будет эквивалентным. В обратном направлении это не работает, и найти пример несложно
На видео показывают конкретное разложение конкретного кода одним и другим компилятором. Которое может меняться буквально от версии компилятора, и в следующей они будут полностью идентичны. Где тут "невозможность" написать аналогичный код, непонятно. Ну не все оптимизации в ллвм завезли, завтра будут.
А про принципиальную производительность например можно взять то что все ссылки noalias, поэтому возможны оптимизации "на местах" связанные с этим, включая приснопамятную копию строчки (s++ = x++). Программу на С где каждый указатель помечен через restrict я не встречал.
PsyHaSTe
21.09.2019 13:36Посмотрел доклад, там много к чему можно привязаться, но отмечу одну вещь:

Это прямая ложь. Unsafe "не выключает борровчекер", конкретно про это есть целая статья у клабника.
Во-вторых конечно же на ансейф абстракциях можно строить сейф язык. Точно так же вы можете пользоваться "интами" и "флоатами" в С++, а на нижнем уровне у вас только адреса в памяти, и можно случайно прочитать инт как флоат и наоборот. Все программирование про то, как инкапсулировать сложность, и выставить набор безопасных АПИшек над потенциально опасным ресурсом (который при неправильном использовании может взорваться).
Если человек говорит "написали ансейф — потеряли гарантии", то он просто не понимает о чем разоваривает.
KanuTaH
21.09.2019 14:51Ну так borrowchecker не распространяется на raw pointers, поэтому на слайде и написано «нет безопасности». А так-то да, абстракции стараются делать везде, но их ненулевая стоимость и протекаемость — это факт. Вот вы давеча писали про «бесплатный сыр» в виде тотального restrict, так ведь он не бесплатный, за него приходится платить использованием лишних абстракций типа того же RefCell, который не бесплатный. И что больше повлияет на эффективность конкретного кода — плюсы от тотального restrict или минусы от RefCell, который там в рантайме счётчики ссылок тусует — это большой вопрос, и зависит от специфики этого кода. Если у нас идёт интенсивная работа с большими мультисвязными структурами в куче, то, сдаётся мне, выигрыш от авторестрикта не покроет проигрыш от RefCell. Ну и, как я раньше уже говорил, сам по себе факт появления Cell означает, что основная абстракция borrowchecker'а «одной мутабельной ссылки в один момент времени всегда достаточно» УЖЕ протекла.
PsyHaSTe
21.09.2019 16:17Ну так borrowchecker не распространяется на raw pointers, поэтому на слайде и написано «нет безопасности».
99% кода это не raw pointers. В очередной раз в этом убедился, когда читал про разработку Midori. Люди писали на диалекте шарпов но пришли к тем же выводам, что и команда раста.
Вот вы давеча писали про «бесплатный сыр» в виде тотального restrict, так ведь он не бесплатный, за него приходится платить использованием лишних абстракций типа того же RefCell, который не бесплатный.
RefCell это зверь по частоте использования наверное сравнимый с reinterpret_cast в плюсах. Бывает только там, где надо, и в исчезающе малом количестве случаев. Зачем про него постоянно говорить? Мутабельный стейт на ссылках это ненормальная ситуация. В языках где он разрешен стараются делать фреймворки которые его запрещают. Посмотрите на ту же акку.
Если у нас идёт интенсивная работа с большими мультисвязными структурами в куче, то, сдаётся мне, выигрыш от авторестрикта не покроет проигрыш от RefCell.
Интенсивная гработа с мультисвязными структурами это что-то из плохого дизайна. И речь не про раст, а про когнитивную сложность и проблемы при рефакторинге/доработке подобного спагетти, на любом яызке.
KanuTaH
21.09.2019 16:21Бывает только там, где надо, и в исчезающе малом количестве случаев. Зачем про него постоянно говорить? Мутабельный стейт на ссылках это ненормальная ситуация.
Ну, например, практически любой GUI — это «мутабельный стейт на ссылках» с многосвязными отношениями child/parent/siblings. Вы тоже скажете, что это «из плохого дизайна»? Так ведь другого нет-с.PsyHaSTe
21.09.2019 16:21Посмотрите на реакт. Там нет мутабельного стейта на ссылках.
KanuTaH
21.09.2019 16:25Сам по себе DOM весь построен на ссылках. А то, что некоторые пытаются заметать этот факт под ковер и перегенерировать это ссылочное дерево каждый раз — ну, это такое, очень «быстрое» решение, ага.
PsyHaSTe
21.09.2019 17:32Сам по себе DOM весь построен на ссылках.
А в транзисторах нет никаких интов и флоатов, но мы с ними как-то работаем.
А то, что некоторые пытаются заметать этот факт под ковер и перегенерировать это ссылочное дерево каждый раз — ну, это такое, очень «быстрое» решение, ага.
Вы бенчмаркали? Емнип как раз с виртуальным деревом решение быстрее ручной перерисовки. Ну и да, мы говорили про реальность, а не про производительность. Даже если это решение медленнее, это все равно решение.
Джава до 10 раз медленне плюсов, но тем не менее её используют. ЖС медленнее джавы на те же порядки, и его тоже используют.
KanuTaH
21.09.2019 17:52Вы бенчмаркали? Емнип как раз с виртуальным деревом решение быстрее ручной перерисовки.
Смотря что вы подразумеваете под «ручной перерисовкой». Просто изменить напрямую в DOM пару значений НАМНОГО производительнее, чем сначала изменить их в VDOM, потом машинерия реакта там начнет шевелиться, вычислять diff'ы, вызывать там всякие render() и так далее. Вот кто-то бенчмаркал на мобилках:


Когда-то давно авторы react утверждали, что VDOM быстрее «реального» DOM:

Но, если вы сейчас зайдете на сайт реакта, вы не увидите там ничего подобного — потому, что это ложь.
Что касается «все используют» — ну да, используют. Но к месту жеж! Нельзя просто так говорить, что «мутабельный стейт на ссылках — ошибка дизайна». С точки зрения дремучего чистого FP это, может, и так, но есть же еще и реальный мир.PsyHaSTe
21.09.2019 17:58Судя по графикам реальная разница отрисовки возникает через после количества элементов на котором время отрисовки превышает 20 секунд. Могу согласиться по формальным признакам, но чисто практически что 30 что 45 секунд это неюзабельно.
А на количестве элементов меньше 1000 (так что время отрисовки меньше 20 секунд) разницы не наблюдается.
Впрочем, не буду спорить. Дейкстра про преждевременную оптимизацию когда-то писал, повторяться не вижу смысла.
KanuTaH
21.09.2019 18:12Судя по графикам реальная разница отрисовки возникает через после количества элементов на котором время отрисовки превышает 20 секунд.
Я в свое время мерял, но немного другое — меня интересовала RAM, так вот в Chrome на десктопе разница начинается где-то в полтора раза сразу (не в пользу реакта, само собой) там уже на сотне элементов, а дальше разница росла еще больше, могла и до трех раз доходить, когда счет элементов шел на тысячи. Короче, очередная дырявая абстракция, может, и без «мутабельного стейта на ссылках», но, как обычно, за определенную (и недешевую) цену.
Antervis
22.09.2019 02:46Если человек говорит «написали ансейф — потеряли гарантии», то он просто не понимает о чем разоваривает.
unsafe перекладывает ответственность за корректность вложенного кода с компилятора на программиста. Если программист тоже не в состоянии гарантировать корректность этого блока кода (как например в случае вызыва unsafe функции из 3rdparty библиотеки), значит, блок потенциально скомпрометирован, как и весь код, от него зависящий (рекурсивно).PsyHaSTe
22.09.2019 03:11Да нет, если функция не может проверить локально инварианты, то она сама unsafe. так и живем. Если вы сделали функцию которую вызывая из сейф раста можно поломать то это уб.
Antervis
22.09.2019 16:25то есть, формально, весь стек вызовов, содержащий обращение к 3rd party библиотеке, должен быть размечен как unsafe? И что, помечают?

An_Owl_or_not
20.09.2019 02:30В расте надо выбирать написать код без unsafe или чуть более оптимальный внутри unsafe.
Не раз слышал что unsafe-код заменяли на safe с выигрышем по производительности, так что не думаю что тут есть выбор между "написать код без unsafe или чуть более оптимальный внутри unsafe". Скорее есть возможность safe-код, скорость которого не устраивает, попытаться оптимизировать с помощью unsafe.
lain8dono
21.09.2019 06:42В расте надо выбирать написать код без unsafe или чуть более оптимальный внутри unsafe.
unsafeне для оптимизаций. Он для ручного доказательства корректности. А ещё для того, чтоб можно было сделатьgrep -rn unsafeвместо запуска отладчика.
А если взять все 100500 библиотек плюсов/си, сопоставить их с аналогами на расте и замерить, в скольки процентах случаев выиграет раст?
Давайте, мне тоже интересно. Топ можете взять отсюда https://crates.io/crates?sort=downloads
Gymmasssorla Автор
21.09.2019 17:06Одно из применений Unsafe — как-раз таки оптимизация.
Например, как Вы выполните некоторые SIMD инструкции, подсказки для компилятора, интринсики без использования
Unsafe? Посмотрите исходный код стандартной библиотеки — она кишит Unsafe, и разработчики в этом открыто признаются. Кое-где лишнее копирование не производят, кое-где лишние проверки устраняют.
Другой вопрос, что это далеко не всегда нужно (я о преждевременных оптимизациях). Просто есть части кода, где максимальная скорость таки нужна.
lain8dono
21.09.2019 19:27+1Само по себе использование
unsafeничего не говорит об оптимизациях. Наличие некой оптимизации в том же самом коде, который используетunsafe— это просто забавное совпадение.Antervis
22.09.2019 00:58Само по себе использование unsafe ничего не говорит об оптимизациях
тем не менее, некоторые оптимизации невозможны без unsafe

humbug
21.09.2019 20:23SIMD unsafe не из-за оптимизации, а из-за того, что компилятор не может гарантировать корректность доступа к данным (выравнивание и проч).

amarao
20.09.2019 14:14Кстати, сложность Rust можно понять, попытавшись реализовать свой тип данных со своим IntoIterator без использования итераторов других типов, только на замыканиях. Добавить lifetimes по вкусу.
bubukerrr
20.09.2019 19:42У раста самое главное инструментарий намного более современный.
Система пакетов по сравнению с тем что происходит в экосистеме плюсов — просто рай.
Плюс возможно дойдут до типов высших порядков — а там и функциональщики подтянутсяPsyHaSTe
21.09.2019 10:09Они уже подтянулись. Вместо сишных вставок в хачкель начинают вызывать раст, все же писать на нем сильно удобнее, хотя и не настолько, как на высокоуровневом ФП.
technic93
21.09.2019 12:20ОффтопВсегда было интересно сколько щупалец у существ которым "удобно на высокоуровневом ФП"
PsyHaSTe
21.09.2019 12:35Так ФП оно про то, как писать меньше, а получать больше, а не про башню из слоновой кости и "смотри как я могу физзбаззфпэдишн захреначить". За примерами далеко ходить не надо: генерики вместо темплейтов, паттерн матчинг вместо свича и ифчиков, АДТ вместо визиторов, лямбды вместо паттернов на каждый чих, итераторы с комбинаторами вместо ручных циклов… Это всё в мейнстрим из ФП пришло. Неужели это все иноплатеная хрень, и в циклах визиторы на ифчиках устраивать удобнее?
"Не ну это все удобные вещи, которые мейнстрим взял, а остальное в ФП какая-то хрень" — да нет, просто это парадок блаба. Штуки к которым привыкли начинают считаться удобными и полезными, а остальные воспринимаются в штыки. Вон, постепенно мейнстрим доползает до Option/Either монад (в расте вся стд на них построена), АДТ и тайпклассов (пропозалы в ближайшие версии всех популярных языков уже есть), а там глядишь и HKT подтянется. Просто ФП раньше других получает штуки, которые получают распространение лет через 10. Но ничего не мешает быть эффективным уже сегодня, а не ждать когда в любимые плюсы/шарпики/тайпскрипт завезут желаемое.
KanuTaH
21.09.2019 15:23Если бы ФП было таким идеальным, то на хаскеле писали бы абсолютно все, включая графические движки, прошивки для микроконтроллеров или операционные системы. Но вот что-то не пишут (нежизнеспособные эксперименты типа HOUSE в расчет не берем, я о мейнстриме). И ведь даже нельзя сказать «это потому, что он
черныйновый» — ведь он появился еще в начале 90-х, а сейчас доля на гитхабе у него где-то 0.2%, и падает. Как думаете, почему?PsyHaSTe
21.09.2019 16:21Ну во-первых потому что хачкель не так хорош в условиях ограниченных ресурсов, а до недавнего времени это было важно — мегагерцовые процессоры, считанные сотни мегабайт озу, вот это все. А во-вторых потому что гугл проплатил го, а не хачкель, который делают 1.5 энтузиаста. А так да, хачкель на обе лопатки уделывает го во всех сферах, в которых его рекламируют, в частности в многопоточных асинхронных веб серверах. И в бинарник собирается. И гц у него получше будет. Но вот беда, гугол занес бабла за го, а не за хачкель. А все потому, что разрабочтики те же люди, и продать им хреновую фигню под видом сильвер буллета легче легкого.
И ведь даже нельзя сказать «это потому, что он черный новый» — ведь он появился еще в начале 90-х, а сейчас доля на гитхабе у него где-то 0.2%, и падает.
Ну ведь миллионы не могут ошибаться, не так ли?)
KanuTaH
21.09.2019 16:29Ну во-первых потому что хачкель не так хорош в условиях ограниченных ресурсов
Вот-вот. Да и сейчас, знаете ли, производительность уже не удваивается каждые полтора года.
Ну ведь миллионы не могут ошибаться, не так ли?)
Ну, бывает и обратная ситуация — "я Д'Артаньян, я эффективен уже сегодня, а вы все..." :) Ну это я так, шучу, конечно.PsyHaSTe
21.09.2019 17:36+1Вот-вот. Да и сейчас, знаете ли, производительность уже не удваивается каждые полтора года.
Да, но наконец софт начал использовать больше 1 ядра не только в архиваторах.
Ну, бывает и обратная ситуация — "я Д'Артаньян, я эффективен уже сегодня, а вы все..." :) Ну это я так, шучу, конечно.
Это просто мой опыт. Я наблюдаю как развиваются крупные фреймворки в ООП языках и они следуют тем же путем, который пионерят ФП языки. Я по сути делюсь информацией, чтобы люди могли где-то более правильное решение найти. А то вот в расточате рассказал про code first и EF миграции, а оказывается что люди-то и не слышали, всё ручками скрипты пишут… Технология есть, многим бы пригодилась, но люди не в курсе, что их боль вполне себе необязательная.
Как-нибудь соберусь с силами написать про фп статейку. А то столько мифов про "математику", а по сути все тривиально про то, как сделать композабельными сложные системы. Впрочем, об этом в другой раз.
Gymmasssorla Автор
21.09.2019 17:44Напишите, с удовольствем почитаю. Сам начинаю потихоньку вкатываться в мир ФП.
PsyHaSTe
21.09.2019 22:29Очень оригинально, что кто-то поставил минус комменту (с моим плюсом это ноль). Получается, настолько некоторым людям тема неприятна, что даже такая нейтральная фраза штрафуется.
KanuTaH
21.09.2019 17:56Я наблюдаю как развиваются крупные фреймворки в ООП языках и они следуют тем же путем, который пионерят ФП языки.
Да, они берут из ФП кое-что. Но и о корнях не забывают, «чистый» ФП там сам по себе тоже не нужен.
DreamingKitten
21.09.2019 16:34А во-вторых потому что гугл проплатил го, а не хачкель, который делают 1.5 энтузиаста.
Ээээ, но ведь го это не ФП, как и зачем вы их сравниваете?
А так да, хачкель на обе лопатки уделывает го во всех сферах, в которых его рекламируют,
В микросервисах, например, да? Представил себе gRPC на хаскеле, брррррр…KanuTaH
21.09.2019 16:44Ээээ, но ведь го это не ФП, как и зачем вы их сравниваете?
Ну так видимо поинт в том, что вот мол фп-язык как-то где-то что-то выиграл у не-фп языка, поэтому фп-язык перенимает звание сильвер буллета у не-фп языка, а не-фп язык занимает почетное второе место с титулом «хреновая фигня».
PsyHaSTe
21.09.2019 17:38+2Ээээ, но ведь го это не ФП, как и зачем вы их сравниваете?
Потому что один объективно хороший язык, который не проплатили, а другой, скажем так, не очень хороший, но про который из каждого утюга, и подменяющий запросы поисковик. Результат немного предсказуем.
В микросервисах, например, да? Представил себе gRPC на хаскеле, брррррр…
А что не так-то? У нас есть такой сервис, на скале правда, но на хачкеле прототип показал себя в 10 раз перфоманснее и в 10 раз меньше памяти, при лучшей читаемости. Так на него бы и перешли, если б раст не показал себя еще лучше на той же нагрузки.
Но если у вас нет как у нас микросекундных требований к выполнению рест-запросов то хачкель отлично подойдет.
Сами себе придумали, что хачкель это что-то для математиков чтобы пудрить всем мозги, и отсюда сами делаете следствие что ничего из грешной земли нашей а-ля рест бек или там читалку реббита не реализовать. А все как раз наоборот.
amarao
Rust сложный язык. Дело не в lifetimes, а в логике предикатов, возникающих на generic'ах у трейтов (тайп-параметры). inner mutability добавляет веселья.
Любая попытка использовать Rust должна идти с точным пониманием, что вся восхитительность высокоуровневого кода и гарантий Rust достигается за счёт удовлетворения (программистом) кода, проверяющего lifetime и вычислимость функций на типах. Это сложно. Начать писать на rust просто, научиться писать на rust сложно. Не сложнее, чем на C++, конечно, но сложно.
В сравнении с С/С++ я могу сказать одно — Rust (стабильный) не умеет обрабатывать ошибки аллокации. Пока эту проблему не решат, он не может быть настоящим системным языком.
А вот насчёт unsafe… Ух, не трогайте эту гидру. Можно иметь такой unsafe-инваривант, который сделает UB в safe-коде, хотя сам unsafe блок совершенно невинный. Про это много говорили в курсе лекций по Rust на computer science center (https://www.youtube.com/playlist?list=PLlb7e2G7aSpTfhiECYNI2EZ1uAluUqE_e).
Gymmasssorla Автор
Ошибки аллокации можно попытаться отлавливать посредством своего хендлера паники или кастомного аллокатора. Это, конечно, очень дубовый подход, я бы предпочёл возвращать
Result<Vec, AllocError>из методовVec::new/Vec::with_capacity/etc.mayorovp
Поправка: выглядит невинным. UB всё равно при этом происходит в нём.
amarao
Нет. В этом и драма unsafe, он может что-то (очень даже defined) поменять в логике, в результате чего UB происходит в safe коде. Фигурные скобочки вокруг unsafe — это ложная идея, unsafe показывает места, где код что-то делает, но не места, где надо быть внимательным к UB. UB может происходить чёрти где, не имеющем никакого отношения в unsafe коду.
Я дал ссылку на плейлист, лекция 11, там много примеров.
PsyHaSTe
Да нет, все UB всегда в фигурных скобочках. Например, можно собрать строку из невалидного UTF8, и в сейф коде при попытке поработать с этой строкой будет паника. Однако проблема не в коде читающем невалидную строчку, а в том, который её сгенерировал.
Упасть может любая строчка, включая сейф. Но причина падения всегда будет обернута в
unsafe{}amarao
Давайте договоримся, что UB — это undefined behavior, а не "всё плохое". Например, если кто-то вам положит невалидный указатель в структуру, это не UB. UB — чтение по такому указателю.
a1ien_n3t
Вобщето нет. Факт чтения не обезателен для получения UB.
Например
Этот код UB
amarao
Да, вызов std::mem::uninitialized — undefined behavior. Однако, например, запись в указатель null — это не UB. А вот если какая-то редиска попытается это читать (вне unsafe блока, полагая, что там вменяемые данные), то получится "Dereferencing a null or dangling raw pointer." Писать можно — читать нельзя.
mayorovp
А с каких пор вы можете читать значения по сырому указателю за пределами unsafe-кода?
Если же вы имели в виду не сырой указатель, а нормальную ссылку — то она не может указывать на null. Создание ссылки на null как раз и нарушает языковой инвариант: "ссылка никогда не указывает на null".
Это, кстати, общий инвариант для Rust и C++.
technic93
но программа упадёт при чтении по ссылке а не при её создании
vitvakatu
Какая разница, когда программа упадет? Открою страшную тайну — она может упасть когда угодно, позвонить президенту, вызвать инопланетян или духа Чарльза Бэббиджа. Именно так работает UB и в Rust, и в С++. Если в ссылке оказался null — это уже UB, и если компилятор достаточно (не) умен, чтобы заставить программу падать при чтении, а не делать все вышеперечисленное — можете тихо порадоваться в душе и никогда больше не писать такой код.
technic93
Смотря как определяете UB, висячая ссылка это уже UB? Только в раст? А в С++ нет?
PsyHaSTe
https://doc.rust-lang.org/reference/behavior-considered-undefined.html
technic93
Мне выше пишут
А по ссылке
Про это разницу и говорю
Upd. Нет там таки стоит:
vitvakatu
Не пробовали дочитать до пункта "Dangling or null references and boxes."? И я уже не говорю что этот список не полный.
technic93
окей тогда в расте и в С++ официальные понятие UB отличаются. Т.е. согласно доке у них вернуть плохое из unsafe уже называется UB. Но в реальности ничего не будет пока мы к этому не начнем обращатся или как то взамодействовать из другой части кода.
Revertis
Поэтому Rust и считается более безопасным.
Aldrog
С моей точки зрения это наоборот, жирный минус к безопасности. UB именно тем и плох, что проявляется в неожиданные моменты и тяжело отлавливается.
Revertis
Так пишите без UB! Кто вас вообще заставляет писать используя unsafe?
Aldrog
Я вообще не пишу на Rust, только интересуюсь :)
Как мне кажется, выделение unsafe блоков — как раз очень полезная с точки зрения безопасности фича. А мой комментарий выше — контраргумент к Вашему утверждению, что Rust безопасен тем, что UB проявляется (не)определённым образом.
Aldrog
В C++ тоже сплошь и рядом UB проявляется гораздо позже, чем происходит. Например, у нас недавно был случай, когда приложение начинало зависать через пару часов работы после того, как объект был удалён по указателю на интерфейс, в котором не было виртуального деструктора.
technic93
такой варнинг вам любой компилятор выдает.
Aldrog
Во-первых, мне почему-то ни gcc -Wall -Wextra -Wpedantic, ни даже clang-tidy ничего не сказали, а во-вторых мой комментарий был вообще не об этом.
technic93
Я понял посыл вашего комментария, просто удивился что у вас такая ошибка скомпилировалась. Видел такие предупреждения в QtСreator в своём коде иногда (с настройками clang по умолчанию от Qt). Интересно или у Вас компилятор старый или у Вас какой то специфичный случай в коде что компилятор не отловил, тогда можно и баг зарепортить. Вроде -Wall -Wextra должно хватать для отловки delete, eщё есть -Wnon-virtual-dtor.
0xd34df00d
Компиляторы это стали репортить относительно недавно.
Aldrog
gcc 9.1.0
С -Wnon-virtual-dtor действительно ловит, -Wall -Wextra -Wpedantic оказывается недостаточно.
technic93
Есть ещё -Wdelete-non-virtual-dtor который входит в -Wall и он должен ругаться на строчку с delete.
Aldrog
У нас повсеместно используются смарт-поинтеры, а эта проверка видимо недостаточно умная, чтобы ругнуться на деструктор unique_ptr.
technic93
clang выдаёт, gcc нужен флаг -Wsystem-headers потому что ошибка по сути там возникает.
PsyHaSTe
Вы понимаете разницу между pointer и reference?
technic93
Да. Сразу не заметил что там про другое.
screwer
Падение при чтении по null это заслуга не компилятора, а ОС.
Siemargl
вообще то можно не падать… есть варианты с диагностикой
0xd34df00d
Не падать нельзя, упасть придётся (ну или экзепшон кинуть, который обработать принципиально умнее, чем в
mainчерезcatch (...), у вас не получится).Siemargl
В некоторых системах повышенной надежности вопрос решен.
Прекращается исполнение сбойного программного блока, остальные работают.
На следующем цикле опять запустятся снова все части программы.
mkpankov
Вообще это интересно, что вы коснулись
mem::uninitialized. Как раз с ним был связан недавний RFC — эта функция теперь deprecated.А почему? А как раз потому, что, как оказалось, факт создания значения определённого типа вне области определения этого типа — уже UB.
Это всё важно в первую очередь в контексте оптимизации. Если вы компилятор, и вам говорят, что вот тут
bool— допустимые значения0и1, то встретив код типавы можете соптимизировать этот код, основываясь на численном представлении
bool. Еслиboolне0или1, этот код будет работать неправильно. Но не только этот код. Возможно этотboolиспользуется уже скомпилированным кодом стандартной библиотеки, например.Поэтому да, странные эффекты могут начаться по всей программе. Но UB всё равно именно там, где нарушили инвариант — в unsafe.
DreamingKitten
Извините за возможно тупой вопрос, но разве true это не non-zero value именно в определении булевского типа?
vitvakatu
Нет, в Расте внутреннее представление bool не специфицировано. Но если скастовать его к integer, будет либо 0 либо 1:
DreamingKitten
а если скастовать 2 в bool, что будет?
vitvakatu
Undefined behavior, то есть все что угодно.
vitvakatu
Для тех, кто мне не верит, почитайте https://doc.rust-lang.org/reference/behavior-considered-undefined.html, конретно пункт "A value other than false (0) or true (1) in a bool."
mayorovp
Вроде бы ошибка компиляции. Нельзя целые числа в булев тип кастовать.
vitvakatu
А вы через
unsafe { std::mem::transmute(x) }попробуйте :)red75prim
В safe Rust в bool кастовать нельзя. Если скастовать с помощью
unsafe { mem::transmute(2) }, то будет UB. Оба соседних ответа частично правильны.PsyHaSTe
ИМХО "Можно, но вызовет UB" равноценно "нельзя".
PsyHaSTe
Сравнительно специфицированно:
lain8dono
std::mem::uninitialized— это не заполнение нулями, UB — это не только "заполнить чем угодно" даже в данном случае. UB — это "сделать что угодно и где угодно без каких либо гарантий вообще". Для заполнения нулями естьstd::mem::zeroed. Но вообще для этих целей естьstd::mem::MaybeUninit. Это более корректный вариант более ограниченного UB, но это всё хаки для оптимизаций. Для корректного zero value естьstd::default::Default.Вот вещи, которые теоретически могут произойти с UB на
uninitialized:Всё это верно для любого
unsafeблока в Rust, а также для всего C/C++ кода.PsyHaSTe
Код с UB просто не является программой на расте, вот и все. Любителей ускорить код через UB наверное с распростертыми объятиями ждут где-нибудь в линуксе.
MikailBag
PsyHaSTe
Нет, не означает. То же свойство UB у любого другого языка. Почитайте вот тут, особенно раздел shifting responsibility. Спека запрещает UB в любом виде, поэтому если в программе написанной на Си есть UB то оно не является программой на си в строго смысле этого слова. Тоже самое в случае раста.
red75prim
Не стоит запутывать. Нарушение правил написания unsafe кода может привести к UB, вот и всё. Нарушение инвариантов, на которые опирается safe код, — это, естественно, нарушение правил написания unsafe кода.
Если таких нарушений нет, safe код UB вызвать не может (если вызывает — это баг компилятора, и он будет исправлен).
amarao
Я, собственно, эту мысль и доносил — unsafe код может вызывать UB вне unsafe блока. Внутри unsafe всё будет правильно и с инвариантами, но будут нарушаться инварианты safe-кода.
PsyHaSTe
Не может. Ну или покажите пример, как сейф метод может вызвать уб. Заранее скажу, что чтение из какой-нибудь строчки в которую злой ансейф напихал невалидных байт не является УБ.
0xd34df00d
UB — оно в общем случае не в конкретной строке, это свойство всей программы целиком. Просто иногда везёт его достаточно локализовать.
mayorovp
UB — это то, чего никогда нельзя допускать в корректной программе, потому что в противном случае компилятор за корректность программы ответственности не несёт.
Нарушения языковых инвариантов нельзя допускать.
amarao
Тогда у меня для вас печальная новость, ваша программа не может делать IO. Любое IO — undefined behavior, и по понятным причинам может вызывать странные эффекты вне того кода, который его вызывал.
mayorovp
Нет. Любое IO не является UB, его поведение вполне определено. В частности, ввод-вывод не нарушает языковые инварианты.
PsyHaSTe
Мне начинает казаться, что вы не знаете, что такое UB.
technic93
Причина падения и UB это две разные вещи! Давайте на примере С++. Причина это удаление ресурса, а UB это разименование указателя на который ссылался на этот ресурс. Так и в расте можно наворотить в ансейф дичь (нарушив инварианты) и вернуть оттуда якобы правильную структуру но при первом обращении к структуре в сейф коде программа упадёт, т.е. банально ассемблер который сгенерировал шланг на основе сейф кода обратится например в битую память или ещё что то.
PsyHaSTe
Так в этом-же и фишка. УБ не в том месте, которое читает структуру, а в том, которое структуру создало в неправильно состоянии. А создать структуру в неправильном состоянии можно только через ансейф. В итоге если у вас что-то странное происходит в программе можно смело грепать по unsafe и в 100% случаях вы найдете, где что сломалось.
cpud36
В том примере unsafe не совсем корректен(в строгом смысле).
Поскольку unsafe помимо возможностей добавляет обязательства. А именно: какой бы странный safe код не был вокруг, он не должен вызывать UB[1].
В том примере было примерно так: если инварианты данной структуры данных выполнены, то данный unsafe блок не вызовет UB. Но инварианты структуры могли быть нарушены приватными методами. В некотором смысле там unsafe утёк за пределы блока.
Вообще, поскольку unsafe кода мало, то способы его корректного написания развиваются медленнее, чем хотелось бы.
К примеру, можно было бы помечать некоторые safe типы, как unsafe, поскольку на них могут быть завязаны unsafe инварианты(к примеру, сделать доступ к длине в том примере unsafe, и тогда инварианты должны перестать утекать за пределы unsafe).
[1] UB может возникать в довольно неожиданных ситуациях. Так-то, создание невалидной ссылки уже вызывает UB. Тем не менее, если UB есть, то его проявления могут быть как после его возникновения, так и до.
humbug
Вы же понимаете, что в отличие от, стандартная библиотека не является неотъемлемой частью языка Rust? Это удобный набор функций, коллекций, структур и типажей в окружении, когда у тебя есть куча, фс, сокеты и прочая хипстота. И получить ошибку аллокации в таких приложениях весьма трудно.
Зато если хотите низкоуровщины, типа драйверов под линукс или писать под голое железо (Monotron под TM4C123 80MHz 256KiB flash 32KiB sram, человек реализовал софтовый VGA, в видосике показывает работу интерпретатора бейсика и игру змейка), попробуйте
#[no_std]. Там у вас не будет ошибок аллокаций, потому что аллокаций нет вообще (закадровый смех Джастаса Уолкера). И мейна у вас нет. Куда уж низкоуровневей и системней.Для вас этого достаточно, чтобы называть Rust "настоящим системным языком"?
JekaMas
Для меня основное препятствие для внедрения rust в прод — это цена написания кода и то, что если я могу взять программиста с php, python, java c# и дать ему даже сложный код на go, коль уж его тут упоминали, то закрытые задачи я получу через пару недель максимум. Да и переход с динамических яп на c#, java, golang намного проще, чем такой же переход на rust.
К сожалению, основная аудитория — это всё еще c++ разработчики. Но если мне нужна производительность, а rust может предложить 10-40% лучше в отдельных задачах, а в отдельных задачах хуже, то вопрос сводится к деньгам — какова цена внедрения rust, насколько замедлится после разработка, насколько усложнится найм, насколько затянется введение новых ребят в проекты? И что мы получаем взамен.
Я пока не смог дать однозначного ответа на эти вопросы и остановился на том, что в текущем состоянии rust очень интересный и очень неоднозначный.
mayorovp
Переход с c# на rust проще чем на go.
PsyHaSTe
Это факт. В расточате б0льшая часть растовиков, как ни странно шарписты и питонисты. Плюсовиков не так уж много.
skrimafonolog
Это связано не только с языком, а еще и с тем где ты его используешь, где работаешь.
amarao
Rust очень многообещающий, но всё ещё очень молодой. Достаточно сказать, что срок жизни релиза компилятора — 6 недель. А потом его перестают поддерживать.
Миграция с современной java и C#, я думаю, будет за разумные усилия. С php/python — уже сложнее, сильно сложнее.
В принципе, у Rust сейчас есть конкретное преимущество перед Java/C#/Go — это lifetimes, позволяющие чуть больше проверять компилятором для многопоточного кода.
JekaMas
С другой стороны lifetimes не отменяет необходимости тестов, в которых и другие языки могут те же гонки отловить.
Jouretz
В теории, rust как раз может позволить уменьшить количество тестов. Т.к. тестировать в итоге надо только бизнес-логику, а валидность данных статически гарантируется компилятором.
Ну и как отловить гонку тестом мне не особо понятно… Потоки могут 200 раз на тестах выполниться в одном порядке и потом один раз на проде чуть в другом.
vitvakatu
Тестировать многопоточный код в Расте тоже нужно. (вздыхает) Иногда даже больше, чем тебе бы хотелось.
Гонку данных невозможно предотвратить средствами языка, потому что это сугубо логическая ошибка программиста. Раст тут части помогает с borrow checker'ом, но это не панацея.
JekaMas
Ну у той же гошки есть race detector, у java тоже встречал инструменты.
E2e тесты всё равно нужны и на их уровне гонки и отлавливать.
Jouretz
Так, стоп. Race detector, как я понимаю, к тестам отношения не имеет, он лепится в рантайм и репортит сам факт возникновения состояния гонки, которого в тестах может и не произойти.
Так что какие-то гарантии оно даёт, но далеко не стопроцентные. Понятно что в зависимости от области применения этого может быть достаточно, но это таки не проверка гонки тестом…
JekaMas
В go он лепится и к тестам добавлением флага -race.
И собственно дальше любимый инженерный вопрос, что мы хотим и какую метрику оптимизируем: условно иметь разработку за 1 ед. времени и 97+% вероятности отсутствия гонки, или 100% уверенности в отсутствии гонки и цену в 5 ед.
Но для этих 97% не надо дополнительных усилий. E2e тесты писать надо на любом языке.
PsyHaSTe
Это из разряда "мы пишем на жс, а на то что в функу не придет строка вместо числа пишем тесты".
Ваше утверждение корректно, но в случае с растовыми типами для многопотока имеем скорее 1ед за 70% уверенности, и 1.1 ед за 100% уверенности.
JekaMas
Мы не знаем этих величин на практике. Может оказаться и 10 ед раста за 95% уверенности на 1 ед. другого языка за 90% уверенности.
Поэтому я и говорю «условно». Точный ответ надо получать с накоплением опыта разработки, желательно в больших компаниях, где одинаковые требования к разработчикам, одни бизнес-процессы, но разные сервисы живут на разных ЯП. AliBaba была бы прекрасна для подобного. До этого мы лишь уверенны в самой общей формулировке «раст стоит дороже в разработке и дает 100% уверенности насчет многопоточного кода; альтернативные языки чаще всего стоят дешевле и дают насколько-то меньше уверенности».
KanuTaH
Rust отнюдь не даёт "100% уверенности" насчёт многопоточного кода, он борется только с одним видом проблем в многопоточном коде — data races, и это comes for a price, а именно невозможность иметь более одной mutable reference на один объект в один момент времени.
red75prim
Точнее для этого обязательно требуется явная синхронизация: UnsafeCell + механизм синхронизации доступа, RefCell, Cell, Mutex, RwLock и т.п.
KanuTaH
Ну да, только через прослойку такого рода.
red75prim
Но и в других языках механизмы для исключения data races тоже come with a price. Явные/неявные memory barriers, атомики, те же мутексы.
KanuTaH
Да, но здесь мутексы тоже никуда не деваются, а невозможность иметь более одной mutable reference остается (unsafe в расчет не берем) даже если никаких потоков и в помине нет.
mayorovp
А это полезная (не)возможность.
KanuTaH
Ну да, «потребности в колбасе» вроде многосвязных графоподобных структур на сегодня нет. Для вас, может, и полезная, а для меня — не очень.
red75prim
Почему не деваются? Типы, предназначенные для использования в одном потоке (не реализующие трейт Sync), не могут использоваться с Mutex. Shared mutability для них реализуется через Cell и RefCell, которые не используют никаких примитивов межпоточной синхронизации.
Так что речь может идти только о цене для программиста. Использование
*mut— тоже один из вариантов, где цена для программиста не сильно выше, чем других языках (дополнительно нужно обеспечить отсутствия алиасинга с существующими ссылками, и не забывать про zero sized типы).Естественно, речь идёт про однопоточный вариант. Проблема shared mutability в многопоточном коде ещё не решена. Например: A Promising Semantics for Relaxed-Memory Concurrency
KanuTaH
Я имею в виду, что невозможность иметь более одной mutable reference в один момент времени без подпорок типа Cell никуда не девается даже в однопоточном коде. И накладные расходы с этими Cell, насколько я понимаю, тоже вполне себе есть — например, RefCell ведет подсчет «одалживаемых» ссылок в runtime, и в runtime же паникует, если вдруг ты пытаешься сделать больше одного borrow_mut() одновременно.
PsyHaSTe
Иметь больше одной mut ссылки — плохо, не надо так делать. То, что язык это запрещает — хорошо.
KanuTaH
Такое религиозное рвение, конечно, похвально, но, как кто-то сказал про тот же Cell, «this is necessary because of a frustrating implementation issue called „the real world“» :) То есть вот такой код в растике не скомпилируется:
а вот такой — скомпилируется и заработает:
Почему, спросите вы, они же по сути эквивалентны? А потому что чьи-то догмы не выдержали столкновения с реальным миром, и родил он
Иуду и братьев егоUnsafeCell, Cell и RefCell :)red75prim
А C родил restrict, чтобы догнать фортран.
KanuTaH
Ну, не знаю, ставилась ли цель именно «догнать и перегнать фортран», но то, что restrict увеличивает простор для оптимизаций компилятора — это факт :)
Gymmasssorla Автор
Си раньше соперничал с Fortran. Поэтому и были введены массивы переменной длины,
complex.hи, собственно,restrict.red75prim
Да, и
&mut T— это аналогT restrict *в C.Если убрать гарантию уникальности из
&mut, получаем потенциально меньшее быстродействие, инвалидированные итераторы, сломанныйи мало ли что ещё. Зато не надо писать Cell или unsafe.
KanuTaH
Ну я как-то не уверен, что restrict в C используют чаще, чем Cell в Rust. Я почему-то думаю, что все как раз наоборот. Но это лично мое мнение, не подтвержденное статистикой :)
red75prim
Дык. Шаг в сторону — UB, прыжок на месте — silent error.
PsyHaSTe
Ну так это так и есть. Раст когда начал использовать restrict на полную катушку LLVM посыпался, потому что ни одна плюсовая программа не использует их в таких количествах. Теперь кортима раста ждет, пока LLVM баги мискомпиляции зафиксят. Только это не преимущество плюсов, а как раз наоборот.
KanuTaH
Вообще-то именно в плюсах restrict нет, ни в одном стандарте. Это фишка чисто из C99, в плюсах есть только в составе расширений. А не используют потому, что это нужно относительно редко. А вот Cell в растике приходится использовать куда чаще, потому что вот без него реально «ни туды, ни сюды», несмотря на декларируемую некоторыми парадигму «одного mut ref ought to be enough for anybody».
PsyHaSTe
Нет, используют редко потому что боятся нарушить условие.
Написал бота для телеграмма без единого Cell. Чяднт?
В хачкелях с 0 мутабельными ссылками живут и полезные программы пишут как-то.
KanuTaH
Если это дает какой-то ощутимый выигрыш в данном месте, то используют.
Ну, раз лично вы написали целого бота для телеграма без единого Cell, значит, он не нужен, это же логично. Надо выкинуть его из std :)
Зачем тогда вообще раст, если все можно прекрасно писать на хаскелях? Или все-таки не все? :)
0xd34df00d
Я не использую UB (типа reinterpret_cast данных, вычитанных из сокета или mmap), ни при каком выигрыше вообще. Вещи, которые очень легко превратить в UB, я использую только при очень серьезных причинах. restrict — одна из таких вещей, потому что компилятор нихрена не гарантирует.
Тут, кстати, можно порассуждать о близости плюсов к железу, но то такое.
KanuTaH
Если использование restrict дает в данном месте серьезный выигрыш в плане производительности, то это вполне может сойти за «серьезную причину». Но используют его редко и при наличии серьезных оснований, это да. Еще Кнут говорил, что преждевременная оптимизация — корень всех зол, поэтому всерьез говорить, что всеобщий автоматический restrict — это хорошо (в обмен на костыли для куда более часто встречающихся случаев) — это такое себе.
0xd34df00d
Для того, чтобы понять, какой выигрыш даёт restrict в данном конкретном месте, мне надо
restrictвезде, что ли, и надеяться на духа Страуструпа.Все варианты какие-то ненадёжные.
PsyHaSTe
Если важна производительность и латентность, конечно же. А вообще посыл верный.
А часто ли кто-то вообще его бенчмаркает? Возможно он дал бы выигрыш, да только никто не замерял.
KanuTaH
Бенчмаркают. Обычно же как делается — пишется относительно «наивная» реализация, если она не устраивает по производительности (или перестает устраивать со временем), то делается профайлинг, выявляются узкие места, эти узкие места оптимизируются.
P.S. Все эти размышления о мегапользе от авторестрикта напоминают мне историю от какого-то товарища (не помню, где я читал, возможно, даже здесь, на Хабре), как он оптимизировал свой js-движок для своей игры. Без всякого профилинга он решил, что он сильно выиграет, если перейдет на некую библиотеку по «быстрой» работе с dense arrays (у него все массивы были dense), потому что вот мол он много работает с массивами. На синтетических тестах это давало выигрыш там чуть ли не в два раза, он радостно переписал кучу кода, потом переписал саму библиотеку, но… на выходе на реальных задачах выигрыша не получил. Отсюда мораль: преждевременная оптимизация, особенно с применением велосипедов — зло.
PsyHaSTe
Вполне вероятно, что расстановка restrict по всей программе ускорила бы её на 10-20%, но это не стоит миллионов человекочасов на реализацию… Если только оно не идет бесплатно от компилятора.
На самом деле это можно побенчмаркать. В расте есть флаг который позволяет как включать, так и выключать генерацию noalias для LLVM. Конечно, тогда могут поплыть баги, но чтобы просто замерить производительность этого хватит.
KanuTaH
Я тут постскриптум написал на тему :) «Вполне вероятно» — это не есть аргумент.
P.S. А, ну да, вот:
habr.com/ru/company/ruvds/blog/465809
:)
PsyHaSTe
Так это не преждевременная оптимизация, а бесплатный сыр от компилятора, вроде векторизации циклов
PsyHaSTe
Ну так это плохой код, и хорошо, что он не скомпилировался. В идеале нужно а-ля хачкель писать без изменяемого стейта вообще, тогда и проблем не будет.
math_coder
Для Rust такой подход неидеоматичен, если вообще возможен. Здесь другие способы добиваться тех же гарантий.
0xd34df00d
Если бы такой код компилировался, то код вида
оптимизировать в
let z = 2было бы очень нетривиально.Это короче как alias analysis, только на порядки мощнее.
А, выше что-то похожее уже написали, собственно.
mayorovp
Зачем спрашивать-то? Очевидно же, что во втором примере явно разрешено изменение значения по разным ссылкам, о чём и указано в его типе.
KanuTaH
Ну мне же пишут в зелотском стиле: «иметь больше одной mut ссылки — плохо, не надо так делать, то, что язык это запрещает — хорошо», а во втором примере оказывается, что это не только не «плохо», а даже частенько «необходимо» :) А поскольку это таки «необходимо», то и появились закономерные костыли типа Cell.
mayorovp
Необходимо разделение между уникальными и неуникальными ссылками. Для того, чтобы такое разделение могло существовать — в языке должны быть уникальные ссылки.
Siemargl
ну так они есть и в С++ и в Расте (по умолчанию)
а restrict [пока что] не дает никакого выигрыша
mkpankov
И заработает, да. Потому что тут у вас один поток исполнения.
Это хорошо, что вас заставляют специально извернуться, чтобы указать, что вы собираетесь работать с куском памяти однопоточно. Когда по умолчанию считается, что можно, получается небезопасно.
И да, тут у вас всё равно остаётся механизм защиты, который можно описать как "run-time borrowing". К
Cellэто не применимо, т.к. там толькоCopy-типы, ноRefCellпаникует, если вы таки взяли одновременно 2 ссылки на запись.PsyHaSTe
Понятное дело, это моя оценка на основе эмпирических данных, причем очень примерная, чтобы представлять порядок. Если переформулировать, то "цена поддержки такой гарантии дешевле чем её тестирование".
JekaMas
Если переформулировать, то все же будет «для меня в моём текущем проекте цена поддержки такой гарантии дешевле чем её тестирование, но я не считал».
PsyHaSTe
Ну мне есть с чем сравнивать. Это же обычное "динамика вс статика", просто на уровень типов вынесли не только "инт" и "стринг", но и многопоточные особенности. Утверждения что они замедляют абсолютно аналогичны скриптовикам, которых типы замедляют.
JekaMas
То есть считали?
PsyHaSTe
Я считал, насколько мне надо париться чтобы сделать многопоточную структуру на дотнете (много) — нужно помнить про volatile, как lock взаимодействует с async/await, вот это все, и на расте (мало). В итоге на расте я сделал быстрее аналогичный сервис, чем на сишарпе. И голову напрягал меньше — все несовместимые вещи мне компилятор подсказал.
JekaMas
Вы один? Команды не было?
PsyHaSTe
Нет, я писал свой маленький компонент.
JekaMas
Кстати, может вы знаете, не нашел пока ни у кого объяснения, но может мне со стороны его найти трудно: по графику LoC кода в Mozilla rust не меняется последний год, то есть его доля падает, поскольку объем кодовой базы растёт. Не знаете причин этого?
vitvakatu
А где можно увидеть этот график? Можно попробовать узнать у сотрудников Mozilla.
PsyHaSTe
У меня есть только такая статистика: https://4e6.github.io/firefox-lang-stats/
JekaMas
Выше ответил
JekaMas
https://www.openhub.net/p/firefox/analyses/latest/languages_summary
lain8dono
https://habr.com/ru/users/kvark/
Не благодарите. Он далеко не последнюю роль играл в появлении Firefox Quantum.
vitvakatu
Я часто сталкиваюсь с людьми, которые говорят о 6-недельном цикле релизов как о негативном факторе. Можно узнать, почему? Как мне кажется, это гораздо лучше многолетних циклов. Баг фиксы приходят быстрее, быстрее тестируются, быстрее появляются новые полезные фичи.
JekaMas
Я так понимаю, что вопрос не в скорости релизов, а во времени поддержки прошлых версий.
vitvakatu
Зачем поддерживать прошлые версии, если они все в общем случае обратно совместимы?
JekaMas
Всегда?
vitvakatu
После версии 1.0, на текущий момент, да.
defuz
А вы посмотрите на это с другой стороны. Rust 2015 edition вышел в далеком 2015 году и за 4 года вышло целых 37 патчей.
Rust 2018 edition уже stable, но компилятор поддерживает одновременно обе редакции языка, и будет поддерживать 2015 еще очень долго.
mkpankov
А у вас какие-то особые требования, по которым вам надо сидеть на одной заранее выбранной версии компилятора?
Такое бывает, например, при сертификации, но в обычном продакшене вы просто обновляетесь раз в 6 недель на новый компилятор. Максимум что он привнесёт — warning'и о deprecation чего-либо. Чините их, и на следующую версию опять обновляетесь без проблем.
Обратную совместимость уже 4 года как не ломают.
Siemargl
mayorovp
И что? С каких пор появление предупреждений при компиляции называется сломанной обратной совместимостью?
Cerberuser
Видимо, имелось в виду, что эти предупреждения планируется ещё через несколько версий превратить в ошибки.
vitvakatu
Времени на исправление более чем достаточно. mkpankov про это и писал в своем сообщении.
Siemargl
В кнопочку log стоит попробовать посмотреть. например
итдmayorovp
Но ведь это лог запуска с намеренно выключенной совместимостью, а не с настройками по умолчанию!
mkpankov
Нет, все вокруг сговорились и обманывают Siemargl!
Siemargl
где это видно из команды запуска?
ошибка явно не линта
ну и в любом случае новый NLL станет обязаловкой через пару версий
mayorovp
Это из комментариев на гитхабе видно. А в командной строке параметра нет потому что там вообще исходный код модифицировали. Обратите внимание на PR (закрытые без слияния!), на которые есть ссылки из того сообщения, на которое дали ссылку вы.
Siemargl
-сначала утверждалось, что это поведение потому что запуск не с настройками по умолчанию…
-теперь утверждается, что это модифицированная версия компилятора
а смотреть я должен в корове, которая в яйце, в доме который построил джек
растаманы, вы что там курите?
т.е поконкретней надо с утверждениями
mayorovp
Ну так, по сути, настройки по умолчанию в компиляторе и менялись. Зачем так делалось — видимо, CI у них так работает: каждый PR прогоняется с настройками по умолчанию на всех опубликованных крейтах в поисках регрессий.
mkpankov
Суть в том, что crater — это внутренний гоняльщик тестов на всей экосистеме крейтов. Он использовался не только в этой ситуации, а вообще для любых экспериментов в финальной стадии.
Siemargl
И как это объясняет отсутствие заявленных опций «не по умолчанию» или «специальный» компилятор или прочую мистику, которую вы тут пытаетесь заявить?
У меня один простой ответ — вы сами ничего не понимаете в нахваливаемом языке и его инфраструктуре. Впрочем, я уже не в первый раз с этим сталкиваюсь у растолюбителей.
mkpankov
Описание PR из ваших же ссылок вы пробовали читать?
Что такое NLL migrate mode по вашему?
Смешно :D
Cerberuser
И всё же. Допустим, имеется старая библиотека, которая сейчас получает warning-и из-за этого самого режима миграции. Позже, соответственно, перестанет компилироваться, даже в 2015 редакции. Использовать старую версию компилятора — не вариант, ввиду требований бизнеса (к примеру, как говорилось выше, — найденная уязвимость в генерируемом коде). Обновить библиотеку — не вариант, также ввиду требований бизнеса. Какое решение должно считаться корректным? Ну, кроме очевидного — принять, что подобные требования бизнеса вредят самому бизнесу, и всё-таки обновиться.
Siemargl
Я уже мягко намекнул выше, что нужны пруфы. От вас _нет никакой конкретики_ — ни одной ссылки!.. А отделаться отмазками не получится. В форуме по PR идут разночтения и обсуждение минимум 3х вариантов, в скрипте компиляции, что я привел — ничего нет, в плане нестандартных опций компиляции, в логе только упоминание про strict проверки линтера
Да и собственно ветка началась, что раст пока нестабилен, и все отмазки, что временными ключами компиляции (даже если вдруг найдем) все лечится — в топку
ЗЫ, а что мне не понравилось, что теперь опасная (не компилирующаяся) программа выглядит так
mkpankov
Слышу звон, не знаю где он.
Siemargl
И где? См выше
mkpankov
В общедоступном выпущенном компиляторе никогда не было NLL в запрещающем режиме. Т.е. это делалось в рамках разработки очередной версии с целью проверки того, собственно, можно ли его сразу в запрещающем режиме включать.
Эти предупреждения ничем от deprecation warnings не отличаются.
Дыры в soundness надо же как-то чинить.
amarao
О, боже, у вас какое-то ужасное представление о продакшене. В продакшене бэкэнд-часть обновляют только когда нужно. Если у меня библиотека, которая была сделана в 2014 году, то почему мне надо бегать по её коду и фиксить депрекейшены? Нет, я хочу компилировать не залазя в чужую библиотеку, которая раньше работала.
Весь энтерпрайз на этом построен — старые версии должны работать.
vitvakatu
Кто вам мешает использовать старые версии компилятора и библиотек? Старые версии и продолжают работать.
amarao
Потому что в компиляторе может быть ошибка, в т.ч. уровня CVE. Новые библиотеки (которые нужны в проекте) могут хотеть новую версию компилятора. И нет, появление новой версии библиотеки, которая хочет новую версию компилятора не есть основание для исправления deprecation во всех остальных.
Это требования энтерпрайза.
mkpankov
А, вот оно что.
Так всё-таки, в чём именно проблема? Берите новый компилятор и новые библиотеки. Упомянутые депрекейшены на практике правятся за пару минут.
Это реально не страшная цена за прогресс языка и эта ситуация точно лучше, чем в мире C++.
Cerberuser
Депрекейшены в своём коде — да. Депрекейшены в давно не обновляющемся чужом коде — ой ли?
mkpankov
Если она давно не обновляется никем не надо на неё залезать изначально.
Иначе вы берёте её на свою поддержку.
KanuTaH
Проблема вот как раз в этих представлениях, что в большой кодовой базе, которая написана давно и неизвестно кем, любые правки можно внести «за пару минут». В «мире C++» так заботятся об обратной совместимости именно потому, что тут более реальные представления о стоимости правок старого кода.
Antervis
в мире с++ просто другое соотношение «старого» и «нового» кода
KanuTaH
Так о том и речь, что когда (и если) растик дорастет до ынтырпрайза, от этих пионерских замашек про «за пару минут» придется отказаться.
Antervis
существуют альтернативные варианты решения такой проблемы. Например, можно поддержать сборку разных модулей одного приложения разными версиями языка и линковку таких модулей между собой. Простые случаи можно покрыть тулзами для автозамены устаревших конструкций.
KanuTaH
Да, но если в старой версии компилятора обнаруживают критическую ошибку — например, в определенных случаях он может сгенерировать код, который либо сам по себе создает уязвимость, либо повышает вероятность эксплуатации сопутствующих уязвимостей — вот пример из недавнего:
www.cvedetails.com/cve/CVE-2018-12886
то «сборка разных модулей разными версиями компилятора» может быть вообще не вариантом. Ну, автозамена — это тоже такое себе во многих случаях.
Antervis
«разными версиями языка», а не «разными версиями компилятора».
KanuTaH
Так такого в растике как раз и нет. Выше вон предлагают разными версиями компилятора собирать. А если именно новые версии компилятора поддерживают старые версии языка (мейнстримные C компиляторы вон даже K&R поддерживают), то это и есть забота об обратной совместимости.
mayorovp
Но ведь именно так и есть, новые версии rustc поддерживают старые версии языка, за что отвечает опция командной строки
--editionKanuTaH
И вышеупомянутые deprecation warnings (которые со временем превратятся в errors) это починит?
mayorovp
Я очень сильно удивлюсь если нет.
KanuTaH
Просто в C я могу свободно написать например такое:
и все прекрасно соберется без единого предупреждения в -std=c99 -pedantic и с закономерным предупреждением про «ISO C90 forbids mixed declarations and code» в -std=c89 -pedantic (но все равно соберется). В Расте, я так понимаю, все же либо одно, либо другое — либо условный K&R, либо условный C99?
vitvakatu
Смешивать код разных edition в пределах одного крейта (библиотеки) не получится, но можно смешивать крейты с разными edition. Так что да, как в C мешать код в общем случае нельзя
0xd34df00d
Именно поэтому я прямо сейчас сижу и думаю, что мне делать с вендорской либой, которая имеет
throw-спецификации в хедерах, но клиентский код хочется собирать свежими C++17-компиляторами, права редактировать хедеры у меня нет по юридическим причинам, а делать новую версию вендор не хочет/не может.KanuTaH
Сделать перед их включением #define, который обнулит throw, а после сделать ему #undef? Ну в целом да, со throw «нехорошо получилось». К счастью, это скорее исключение, чем правило.
0xd34df00d
Я об этом думал. Выяснил (опытным путём, лол), что там есть инлайн-функции, которые на самом деле кидают экзепшоны, которые на самом деле неплохо бы ловить.
KanuTaH
У clang помогает сборка с "-std=c++17 -Wno-dynamic-exception-spec" (да, в c++17 это уже не warning, а error, но указание этого ключика все равно прокатывает). В gcc наверное тоже есть что-нибудь вроде этого.
0xd34df00d
Но это уже не стандартный C++ :)
mkpankov
Нет, это практика того, как это реально происходило в мире Rust за время существования стабильности.
Могу припомнить одну серьезную проблему — что-то там сделали то ли с ptr::copy, то ли с крейтом libc.
Сейчас вот намечается ещё одна волна потенциально серьёзных правок — когда старый unsound код принимался старым borrow checker'ом. Это не на пару минут.
mkpankov
Вы то ли специально передёргиваете, то ли в каком-то своём мире живёте.
Ну хотите использовать старый компилятор — используйте старый.
Хотите обновлять свой энтерпрайз когда надо — обновляйте когда надо.
В 2014 году библиотек на стабильном Rust не было — он вышел в 2015.
Бегать и фиксить депрекейшены за 4 года мне не приходилось ни разу — и зачем сразу бегать, если это warning? Если вы такие все консервативные, можете сидеть хоть на 1.0 до сих пор.
И у вас прекрасно продолжат компилироваться старые версии, даже если новым зачем-то понадобился более новый компилятор. В приложениях версии прибиты файлом с версиями.
amarao
Я не передёргиваю, я объясняю, почему Rust трудно попасть в энтерпрайз. Энтерпрайз не хочет переписывать что-либо. Он хочет делать новое и чтобы старое работало. Это означает, что в 2019 мы пишем библиотеку, и если нам не нужно туда новых фич, мы её не трогаем следующие 20 лет. Для Си это прокатывает — можно иметь сишную библиотеку, которая была написана в 1999 году, которую можно скомпилировать в 2019 году. (ANSI C, да). При этом мы постоянно хотим новые штуки в тот момент, когда захотелось, но не ценой переписывания старых.
Это энтерпрайз. Это то, что энтерпрайз хочет — не делать одну и ту же работу снова и снова без какой-либо выгоды от работы.
Вот когда Rust сможет пообещать не ломать ничего на годы (десятилетия) вперёд, вот тогда он станет enterprise ready.
PsyHaSTe
Так он ничего и не ломает. Компилируйте с флагом --2015 и он будет компилировать как и в 2015 году. Последней версии компилятора. В чем проблема-то?
MikailBag
Ну, проблема в том что вроде как в течение 3-4 месяцев AST borrowck должны полностью выпилить, и какой-то код все-таки сломается.
merhalak
По моему, ввод новых ребят все же будет дешевле: Rust не позволит выполнять простейшие ошибки и возьмёт на себя часть Code Review по части некорректной работы с временем жизни переменных. Да и сами времена жизни будут неплохой подсказкой по логике работы во время ввода в проект.
Останется лишь проверять логику решения.
Т.е. хорошо подойдет для больших и долгоживущих проектов. Маленькие лучше будет писать на Go или Python, если важен быстрый старт.
Но все же не без минусов: мало знающих ребят и мало обвязки у языка пока что: это долгий поиск спецов и много работы по написанию обвязки для своих задач (что сразу выкидывает Rust для задач, например с GUI, ибо свой фреймворк мало кто осилит по стоимости). Так что пока что рано брать язык за основной в проекте.
Получается некоторое противоречие: лучше всего писать большие проекты с очень долгой поддержкой, но большие проекты слишком дороги из-за отсутствия библиотек.
JekaMas
Моё мнение пока противоположное: лучше применять на уровне отдельного небольшого сервиса или библиотеки, где критична скорость и безопасность, и не переплачивать за ненужную в других частях проекта строгость и дорогую поддержку.
merhalak
Не, я понимаю, что ненужная строгость на большом проекте помешает попросить еще мешок на "поддержку и развитие". С этой точки зрения да, Rust обойдется несколько дороже, поскольку опыта монетизации проектов на нем почти ни у кого нет.
Но строгость всегда была положительным моментом для самих программистов — меньше времени писать тесты (да, бывает, что тесты пишут все же), ибо строгость языка часть проблем покрывает. Меньше нервов по поводу того, что: поменяю вот здесь, что сломаю? Особенно — для новичков в проекте.
Я видел достаточно, чтобы сказать: большие проекты часто пишут без тестов, а потом тратят месяцы и срывают сроки, когда проект выходит за рамки охватываемой сложности для команды и проект превращается в гонку: подопри костылями быстрее, чем он развалится.
JekaMas
И? С утверждением "каждой задаче свой инструмент" вы же не спорите?
merhalak
Ага. Маленьким, требующим скорость разработки, непродолжительным проектам — динамика, Python и аналоги.
Но именно "ненужную строгость" в больших проектах я бы хотел видеть. Потому что характеристика "ненужная строгость" обычно говорит о том, что человек не хочет поддерживать свой код долго, а просто нарабатывает репутацию/опыт и собирается сваливать.
JekaMas
Тогда почему не Haskell? Народ нормально в проде использует.
Но повторюсь, странно слышать, что любой задаче одно решение.
0xd34df00d
Потому что для некоторых вещей с точки зрения производительности его, при всей любви к языку, не хватает (или моих навыков, при всей любви к себе, не хватает). Да, раст послабее с точки зрения системы типов, но если нужно поковырять байтики эффективно, то стоит посмотреть на него.
JekaMas
А можете чуть подробнее о "видел достаточно" рассказать? Что за проекты, какие команды, почему пришли к тому, что rust именно для больших проектов? Очень любопытно! Если есть основания для подобного утверждения и цифры показали меньшую цену поддержки, то rust можно было бы сделать долгосрочным проектом на проде, учитывая время на обучение спецов.
merhalak
Я не говорю о том, что вводить надо сейчас и именно Rust. Я о том, что его строгость в большом — не излишняя. И то что привносит в Rust тоже со временем пригодится.
Понятное дело, сейчас Rust в прод не потащишь. Ни спецов, ни специальных библиотек. В мое случае даже наша платформа (Java) используется неполностью, ибо никто не хочет писать аннотации для FindBugs или аналогов. "Код загромождает". А потом носимся с багами, когда подавили NPE, а где подавили — хз.
Я как раз горю с того, что в больших проектах забивают даже на это.
JekaMas
То есть вывод основан на опыте в одном конкретном проекте, где применяют не лучшие практики?
merhalak
3 проекта из 4-х. Практически подряд. Не, у меня всё ещё начало карьеры (порядка 2.5 лет опыта работы), но тенденция пугает.
Может быть я просто свинья, которая везде грязь найдет.
Но пока что я вляпывался: очень низкое покрытие тестами (причем покрываются только конкретные реализации), слабое использование (фактически нет) статического анализа, собственные велосипеды, где документацию заменяют тесты. И да, тесты больше как «usage examples» нежели как тесты.
Хочу больше перфекционизма. В новом проекте у меня наконец то появилась возможность что-то поменять в подходах. Вопрос в том, что нормального опыта у меня маловато, за пару лет у меня code review был только 1 или 2 раза. Так что всё на собственных ошибках.
Так что я хочу сначала использовать всё, что предоставляет любимая жабка, а потом смотреть, готова ли инфраструктура Rust (например сейчас самая необходимая и «толстая» зависимость — Hazelcast или его аналог). Будет готова — буду агитировать за. Не будет готова — ну, спасибо Oracle и сообществу, жабка тоже на месте не стоит.
JekaMas
Уверены, что это не вопрос или необходимости, или уровня разработчиков?
merhalak
Уточни вопрос, пожалуйста.
0xd34df00d
Это совсем не по теме треда, но я вот очень часто вижу упоминание Python в контексте таких проектов, и не могу понять, почему. Я на нём ради интереса не далее чем неделю назад попытался что-то наваять (что-то очень тупое, логи распарсить и очень простую статистику по сообщениям подсчитать), и, ну, в общем, у меня не получилось, я очень быстро утонул.
Gymmasssorla Автор
Python всё-же хорош для простых проектов и прототипирования, т.к. позволяет программисту не думать о правильном построении архитектуры.
По своему опыту скажу, что со статически типизируемых языков на Python сложно перейти. Приходится постоянно думать "А совпадают ли типы?". Со статически типизированными языками эту работу делает компилятор/интерпретатор.
PsyHaSTe
Может я глупый, но я на питоне не могу ничего написать. Именно по этой причине.
0xd34df00d
Ну, для меня лично простота, где применим питон, заканчивается в тот момент, скрипт перестаёт быть тупой последовательностью действий (с чем уже прекрасно справляется шелл) и начинает иметь не совсем тривиальную логику.
Revertis
Да, скорость разработки на Rust страдает. Но не стоит забывать, что в сроки разработки добавляется срок выявления и фикса багов, который в программе на C/C++ вы будете фиксить годами.
JekaMas
Именно. Вот поэтому у меня и формируется постепенно мнение, что rust надо в отдельные критичные к производительности и безопасности сервисы или библиотеки выделать.
Revertis
А кто может достоверно определить критичность сервиса или библиотеки?
Если вдруг ваш скрипт, зависящий от «некритичной» библиотеки, на две минуты позже известит вас об освобождении туалета, это будет критичным или нет? ;)
Cerberuser
Всё зависит от того, успеют ли за эти две минуты его занять снова...
Revertis
Вот и я о том же. И некая безделушка может оказаться критичной.
PsyHaSTe
Обычно пишется прототип. Если выигрыш от него ощутим то им заменяют основной продукт.
У нас так и сделали. Текущая версия на джаве, новая на хачкеле, прототип на расте. В ближайший релиз будет переезд на хачкель (х10 первоманс и х10 меньше памяти), через полгода-год переезд на растовый вариант (еще столько же по сравнению с хачкелем).
0xd34df00d
О, а чего у вас за проект такой интересный?
PsyHaSTe
Искать маршруты на графе.
JekaMas
Если так идти, то зачем мне полумеры в лице Rust? Почему не брать что-то с ещё более мощной системой типов?
PsyHaSTe
Ничего более производительного и одновременно с более мощной системой типов не придумали.
0xd34df00d
Я тут вчера впервые попробовал запустить код на идрисе (раньше я его только тайпчекать пробовал, лол), и у него производительность уровня С (пусть и на очень простой задаче, типа алгоритма Евклида).
Правда, только если выкинуть доказательство завершимости алгоритма (если упрощать, а если не упрощать — доказательство, что рекурсивный вызов происходит на элементе фундированного множества, который меньше). Компилятор его почему-то не осиливает стереть и зачем-то вычисляет на каждой итерации. Это, впрочем, недоработка реализации, и для компилятора, разрабатываемого полутора человеками, ооочень неплохо ИМХО.
PsyHaSTe
Согласен, но если честно меня немного смущает строгость его тайпчекера. Морально уничтожить интервьювера разворотом списка на идрисе это всегда прикольно, но написать сколько-нибудь крупный проект… Плюс "для 1.5 человек неплхо", я согласен, но для решения задачи обычно смотрят на абсолютное качество инструмента, а не на удельное на количество человеколет. Надеюсь увидеть завтипы в распространенных языках, или идрис в массы (да, я наивный), но в 2019 году это пока просто игрушка.
0xd34df00d
Ну, вас же никто не заставляет этой всей строгостью пользоваться. Не пишете
%default total— и вам больше не нужно доказывать тотальность функций (или писать мозолящееpartialу каждой функции, где это делать лень). Пишетеeuclid : (m, n : Nat) -> Natвместоeuclid : (m, n : Nat) -> Either (0 `LT` m) (0 `LT` n) -> (d ** Gcd d m n)— тоже ничего доказывать не надо. Получается этакий строгий по умолчанию хаскель.Но вообще да, компилятор, конечно, к продакшену не готов, это экспериментальный язык. Ждём Idris 2.
mkpankov
Ошибки аллокации достаточно бесполезно ловить в пользовательской программе.
Во-первых, почти вся стандартная библиотека опирается на аллокатор, но если добавить тип ошибки в возвращаемые значения всех функций, которые выделяют память, пользоваться этим будет совершенно невозможно.
Во-вторых, как минимум на десктопных Linux по умолчанию включён overcommit, который делает невозможной локальную обработку ошибки выделения памяти.
В-третьих, если вы пишете прикладную программу, близкую к системной в плане управления ресурсами (веб-сервер, сервер БД), то у вас и так весьма особенные нужды в выделении памяти. Часто используются пулы, маппинг файлов/анонимной памяти прямо от системы. Куча в первую очередь интересна "совсем прикладным" программам, которым нехватка ресурсов неинтересна.
0xd34df00d
Собственно, даже в C++ всерьёз подумывают (были треды в мейллисте комитета) разделить выделение памяти на два класса — для «обычных объектов» типа строк, ошибки выделения памяти для которых никто не обрабатывает, и для больших объектов, типа каких-нибудь там матриц.