
Наткнулся на статью в блоге компании Школа Данных и решил проверить, на что способна библиотека Fast.ai на том же датасете, который упоминается в статье. Здесь вы не найдете рассуждений о том, как важно своевременно и правильно диагностировать пневмонию, будут ли нужны врачи-рентгенологи в условиях развития технологий, можно ли считать предсказание нейронной сети медицинским диагнозом и т.д. Основная цель — показать, что машинное обучение в современных библиотеках может быть довольно простым (буквально требует немного строчек кода) и дает отличные результаты. Запомним пока результат из статьи (precision = 0.84, recall = 0.96) и посмотрим, что получится у нас.
Берем данные для обучения отсюда. Данные представляют собой 5856 рентгеновских снимков, распределенных по двум классам — с признаками пневмонии и без. Задача нейронной сети — дать нам качественный бинарный классификатор рентгеновских снимков для определения признаков пневмонии.
Начинаем с импортирования библиотек и некоторых стандартных настроек:
Далее определяем batch size. При обучении на GPU важно его подобрать таким образом, чтобы у вас не переполнялась память. При необходимости его можно уменьшить в два раза.
Важный Update:
Как справедливо заметили в комментариях ниже, важно четко отслеживать данные, на которых модель будет обучаться и на которых мы будем проверять ее эффективность. Обучать модель будем по изображениям в папках train и val, а валидировать по изображениям в папке test, аналогично тому, как делалось здесь.
Определяем пути к нашим данным
и проверяем, что все папки на месте (папку val перенесли в train):
Готовим наши данные для «загрузки» в нейросеть. Важно отметить, что в Fast.ai есть несколько методов сопоставления изображения метке. Метод from_folder говорит нам о том, что метки нужно брать из имени папки, в которой находится изображение.
Параметр size означает, что мы ресайзим все изображения до размера 299х299 (наши алгоритмы работают с квадратными изображениями). Функция get_transforms дает нам аугментацию изображений для увеличения объема данных для обучения (мы оставляем здесь дефолтные настройки).
Заглянем в данные:
Для проверки смотрим, какие классы у нас получились и какое количественное распределение изображений между train и validation:
Определяем модель обучения на архитектуре Resnet50:
и начинаем обучение на 8 эпох, основываясь на One Cycle Policy:
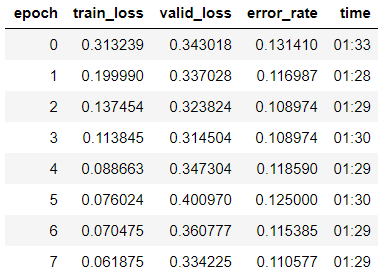
Видим, что мы уже получили точность в 89% на валидационной выборке. Запишем пока веса нашей модели и попробуем улучшить результат.
«Размораживаем» всю модель, т.к. до этого мы обучали модель только на последней группе слоев, а веса остальных были взяты из предобученной на Imagenet модели и «заморожены»:
Ищем оптимальный learning rate для продолжения обучения:
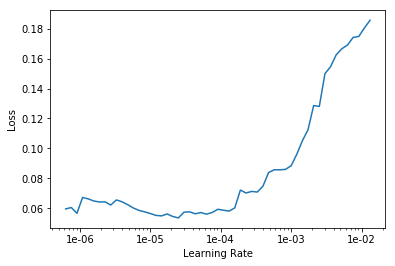
Запускаем обучение на 10 эпох с различными learning rate для каждой группы слоев.
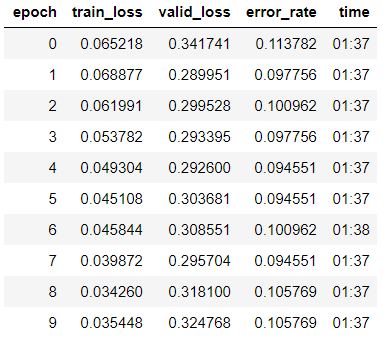
Видим, что точность нашей модели немного повысилась до 89,4% на валидационной выборке.
Запишем веса.
Строим Confusion Matrix:
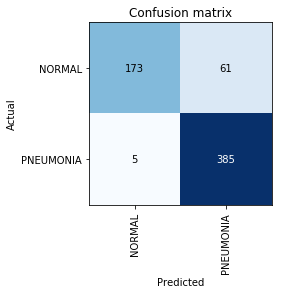
В этом месте мы вспомним, что сам по себе параметр точности (accuracy) недостаточен, особенно для несбалансированных классов. Например, если в реальной жизни пневмония будет встречаться только у 0,1% тех, кто проходит рентген исследование, система может просто выдавать отсутствие пневмонии во всех случаях и ее точность будет на уровне 99,9% с абсолютно нулевой полезностью.
Здесь и вступают в игру метрики Precision и Recall:
Видим, что полученный нами результат даже немного выше, чем тот, который был упомянут в статье. При дальнейшей работе над задачей стоит помнить, что Recall — крайне важный параметр в медицинских задачах, т.к. False Negative ошибки наиболее опасны с точки зрения диагностики (означает, что мы можем просто «проглядеть» опасный диагноз).
Берем данные для обучения отсюда. Данные представляют собой 5856 рентгеновских снимков, распределенных по двум классам — с признаками пневмонии и без. Задача нейронной сети — дать нам качественный бинарный классификатор рентгеновских снимков для определения признаков пневмонии.
Начинаем с импортирования библиотек и некоторых стандартных настроек:
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.vision import *
from fastai.metrics import error_rate
import osДалее определяем batch size. При обучении на GPU важно его подобрать таким образом, чтобы у вас не переполнялась память. При необходимости его можно уменьшить в два раза.
bs = 64Важный Update:
Как справедливо заметили в комментариях ниже, важно четко отслеживать данные, на которых модель будет обучаться и на которых мы будем проверять ее эффективность. Обучать модель будем по изображениям в папках train и val, а валидировать по изображениям в папке test, аналогично тому, как делалось здесь.
Определяем пути к нашим данным
path = Path('storage/chest_xray')
path.ls()и проверяем, что все папки на месте (папку val перенесли в train):
Out:
[PosixPath('storage/chest_xray/train'),
PosixPath('storage/chest_xray/test')]Готовим наши данные для «загрузки» в нейросеть. Важно отметить, что в Fast.ai есть несколько методов сопоставления изображения метке. Метод from_folder говорит нам о том, что метки нужно брать из имени папки, в которой находится изображение.
Параметр size означает, что мы ресайзим все изображения до размера 299х299 (наши алгоритмы работают с квадратными изображениями). Функция get_transforms дает нам аугментацию изображений для увеличения объема данных для обучения (мы оставляем здесь дефолтные настройки).
np.random.seed(5)
data = ImageDataBunch.from_folder(path, train = 'train', valid = 'test', size=299, bs=bs, ds_tfms=get_transforms()).normalize(imagenet_stats)Заглянем в данные:
data.show_batch(rows=3, figsize=(6,6))Для проверки смотрим, какие классы у нас получились и какое количественное распределение изображений между train и validation:
data.classes, data.c, len(data.train_ds), len(data.valid_ds)Out:
(['NORMAL', 'PNEUMONIA'], 2, 5232, 624)
Определяем модель обучения на архитектуре Resnet50:
learn = cnn_learner(data, models.resnet50, metrics=error_rate)и начинаем обучение на 8 эпох, основываясь на One Cycle Policy:
learn.fit_one_cycle(8)Видим, что мы уже получили точность в 89% на валидационной выборке. Запишем пока веса нашей модели и попробуем улучшить результат.
learn.save('step-1-50')«Размораживаем» всю модель, т.к. до этого мы обучали модель только на последней группе слоев, а веса остальных были взяты из предобученной на Imagenet модели и «заморожены»:
learn.unfreeze()Ищем оптимальный learning rate для продолжения обучения:
learn.lr_find()
learn.recorder.plot()Запускаем обучение на 10 эпох с различными learning rate для каждой группы слоев.
learn.fit_one_cycle(10, max_lr=slice(1e-6, 1e-4))Видим, что точность нашей модели немного повысилась до 89,4% на валидационной выборке.
Запишем веса.
learn.save('step-2-50')Строим Confusion Matrix:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()В этом месте мы вспомним, что сам по себе параметр точности (accuracy) недостаточен, особенно для несбалансированных классов. Например, если в реальной жизни пневмония будет встречаться только у 0,1% тех, кто проходит рентген исследование, система может просто выдавать отсутствие пневмонии во всех случаях и ее точность будет на уровне 99,9% с абсолютно нулевой полезностью.
Здесь и вступают в игру метрики Precision и Recall:
- TP — истино-положительное предсказание;
- TN — истино-отрицательное предсказание;
- FP — ложно-положительное предсказание;
- FN — ложно-отрицательное предсказание.
Видим, что полученный нами результат даже немного выше, чем тот, который был упомянут в статье. При дальнейшей работе над задачей стоит помнить, что Recall — крайне важный параметр в медицинских задачах, т.к. False Negative ошибки наиболее опасны с точки зрения диагностики (означает, что мы можем просто «проглядеть» опасный диагноз).
ZlodeiBaal
Как бы сказать.
Если вдруг в каком-то исследовании получается точность на порядок выше, чем все другие подходы, при этом ничего реально нового не сделано (политика обучения влияет лишь на сходимость, замораживание/размораживание вообще глобально не влияет), то вариантов лишь два:
1) Все кто делал это исследование до вас некомпетентны
2) У вас где-то ошибка
Учитывая что вы обучаете самый простой ResNet, при этом всё обучение идёт достаточно классическим способом, то я бы ставил на то что ошибка у вас (обучалось/оттьюнилось на тесте/на валидации). И, кстати, соседнее ядро с вашим на Каггле грешит именно этим — www.kaggle.com/yasserlatreche/pneumonia-99-accuracy-using-densenet121
И точности там примерно как у вас.
А, нашёл. Вы даже сами про это говорите.
Дальше надо объяснять почему всё что вы сделали — чушь?
— P.S.
В целом это и есть проблема использования любого deep learning. Он должен использоваться в первую очередь исходя из здравого смысла. Это лишь инструмент. И любая странность и неоднозначность — это лишь повод сказать себе «кажется я где-то накосячил». И начать искать этот косяк.
turegum Автор
Спасибо за ценное замечание, статью поправил :)
Давайте еще раз зафиксируем — проверять эффективность модели на результатах валидации некорректно. Действительно, перед тем, как начать, я зашел в 3-4 кернела и везде увидел что результат смотрят по валидации, поэтому сделал также.
Сейчас полностью отделил тестовую выборку и эффективность модели измеряю именно по ней. Тем не менее, результат все равно выше, чем указанные в начале таргеты.
ZlodeiBaal
Ещё раз. Вы не выучили урок. «У меня лучше» -> ищите ошибку.
Обучать надо на обучении а проверять на тесте. Никаких «При этом делить изображения на обучающую и валидационную выборки будем случайным образом 80/20».
У вас в трейне и в тесте много данных по одним и тем же людям. Люди из train и test — не пересекаются. Но как только хоть один человек попадает из test в train — у вас точность прыгает на порядок. Да, организаторы судя по всему не удосужились это написать. Но такие вещи всегда надо учитывать.
turegum Автор
Не совсем понял. У меня деление 80/20 идет только по папкам train и val. Папка test теперь ни в обучении, ни в валидации не участвует совсем никак — она полностью отделена. Это видно по логам. Каким образом у меня хоть кто-то может попасть из test в train?
ZlodeiBaal
Смотрите. Ещё раз.
У вас в примере неправильный ответ. С вероятностью 99%. Где вы получили — я не знаю. Но десять лет работы в computer vision как бы кричат об этом. Мне лень выкачивать ваш пример/искать в нём ошибки и тратить на это больше того полу часа который я потратил чтобы найти вашу первую ошибку.
Могу лишь предположить что это где-то:
1) В непонятном использовании деления train и val, которое в вашем случае использовать не надо
2) В том что вы обучаете на val который может совпадать с train
3) В не потёртых где-то сохранённых файлах, из-за которых вы грузите что-то не то для обучения вместо ImageNet весов
4) В ошибках вашего fast.ai который где-то что-то засвопил не то.
И прочее и прочее.
Смотрите. 95% работы нормального DS'а — это сбор данных и проверка корректности всего что он делает. Обучить модель — вечер. Почему ваше решение не корректно?
1) Если вы откроете конкурсы на kaggle, то сможете убедиться что точность ResNet от техники обучения может изменяться максимум на проценты (если не делать явных косяков).
2) Точность людей в определении паталогий по рентгенограммам ~85-95%. Это справедливо и для флюрограмм и для мамограмм. В целом, есть неплохое мета-исследование которое оценивает эти точности — www.sciencedirect.com/science/article/pii/S2589750019301232
К чему это я. К тому что в вашем датасете по которому вы учитесь минимум ~3-4% — это ошибки и неоднозначные классификации. Соответственно вы не можете получить точность выше.
Ну и прочее и прочее…
turegum Автор
Вы правы по всем пунктам. Снес все полностью, обучил заново. При этом модель обучалась на train и val, а валидировалась на test. При этом accuracy, precision и recall существенно снизились, но это все равно немного выше, чем например здесь.
turegum Автор
Ради интереса, попробовал перенести val в test, обучаясь только на train. Результаты не ухудшились, что говорит о том, что val и test похоже не пересекаются и утечек данных не происходит. Вот confusion matrix:

По итогу хочу сказать вам огромное спасибо за потраченное время. Скорость обучения в такие моменты возрастает в разы )
ZlodeiBaal
Это уже сильно ближе к реальности)
Но я бы посоветовал ещё раз всё проделать с нуля чтобы убедиться что всё ок и все файлы затёрлись везде.
turegum Автор
Это все уже сделал — вообще на другой машине, т.е. результат воспроизводимый.
В этом и была изначальная гипотеза, что PyTorch + FastAI почти на дефолтных настройках дадут результат лучше, чем большинство стандартных решений.
С первой попытки у меня не вышло :) Но в итоге по сути подтвердилось.
Кстати, раз уж все равно потратили столько времени, сможете ли сориентировать, откуда fastai/PyTorch/TensorFlow может взять веса для модели, если я их точно стёр из стандартных папок? Или что еще (если не веса) может быть такого сохранено локально, что повлияет на результат обучения, если потом переобучать с нуля? Понятно, transfer learning вроде весов ImageNet здесь не учитываем.
bashkanov
Хочу присоединиться к ZlodeiBaal.
Имхо, судить производительность системы по данным валидации не очень хорошая затея. Эта метрика может разве что сказать, как хорошо сблизилась модель, чтобы дать хорошую метрику на валидации, а не о том, на сколько модель способна к генерализации и готова к новым данным. Для этого и делают сплит train/val/test. Выводы делаются только на test датасете. А лучшая модель для тестирования уже выбирается базируясь на лучшей валидационной метрике. Т.е. при похожих моделях с одинаковой val метрикой, возможны сценарии когда test метрика будет значительно разниться.
turegum Автор
Насчет суждения эффективности по валидации — согласен. В идеале я бы и оставил все три датасета не смешивая их — train/val/test. Но исходный датасет включал только 16 изображений в папке val и в любом случае для валидации надо было что-то придумать. ZlodeiBaal указал на грубую ошибку с моей стороны — перемешивать train, val, test данные, разбивая их на train и validation было нельзя, т.к. в train попадаются по несколько изображений одного и того же человека. Таким образом система валидировалась на уже обученных данных, показывая неадекватные результаты. Можно было взять часть данных для валидации из test, но непонятно, насколько оставшаяся часть была бы генерализированной, т.к. подробного описания данных на kaggle нет. Авторы кернелов, с которыми я сравнивал свои результаты, в итоге просто поделили на train (включив туда и val) и валидировались на test, предъявляя результат как эффективность системы. Сейчас хотя бы яблоки сравниваем с яблоками.