
В предыдущей части «Тренировочные наборы из видео — быстро и качественно» речь шла о сложности применения нейронных сетей для любой задачи, связанной с редкими, необычными или попросту сложными объектами. Обязательно посмотрите примеры, они того стоят.
Классические алгоритмы компьютерного зрения, как оказалось, могут сильно помочь с получением качественных тренировочных наборов. Естественно, такой подход применим не во всех случаях, с чем и необходимо разобраться.
Как было показано в предыдущей части, детальная ручная разметка наборов является очень трудоемким процессом и, откровенно говоря, вообще не вариант для любого здравомыслящего человека. Автоматическая разметка, особенно если речь идет о контурах, выглядит куда интереснее, но как получить интересующий контур быстро и точно?
Начать, пожалуй, стоит с функции принадлежности. Предположим, интересующий нас объект характеризуется ярким цветом, который, к тому же, является уникальным для объекта в контексте конкретной сцены:
Учитывая специфику подхода (а именно необходимость в таких сценах, которые легко «разобрать») сформулировать правило отбора примеров для получения тренировочного набора достаточно легко: очень полезными будут такие сцены, для которых правило уникальности цвета искомого объекта будет выполнятся (помним, со всеми сложными случаями иметь дело буде уже нейросеть, успешно обученная с помощью сгенерированного набора).
Собственно, условие уникальности является необходимым минимумом, поскольку с цветом тоже можно и нужно работать:
Работа с цветом, в данном случае, является очень важной частью всего подхода. По сути, функция принадлежности может быть реализована как функция близости к заданному цвету с установленным пороговым значением:
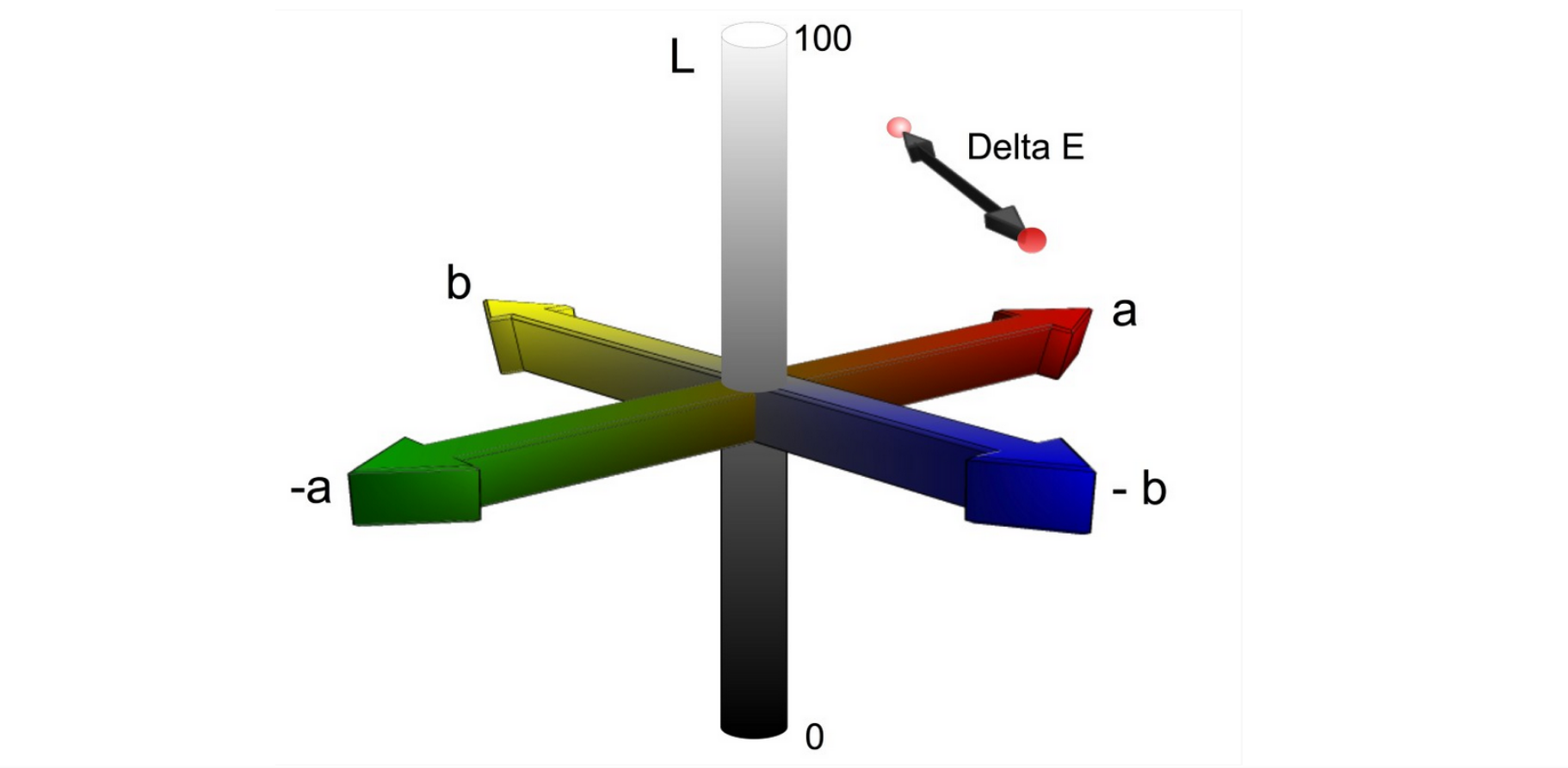
В существующем решении используется несколько реализаций Delta E, как наиболее точного стандарта. Например, CIE94 в цветовом пространстве LCH (L*C*h):
Слишком большой порог, для цветового расстояния, скорее всего «сломает» контур, захватив пиксели, которые не относятся к искомому объекту. Слишком маленький — выделит только часть искомого объекта. В связи с чем сложные сцены требуют внимания, например:

Кит на фото все еще различим для глаза (с трудом, конечно), но контур построен уже неверно. Пример целиком:
Предположим, с цветом все отлично, как получить искомый контур? Задача не является простой, поскольку результат, скорее всего, будет достаточно сложным, с полостями, второстепенными элементами и т.д. Какой из вариантов восстановленного контура для отдельно взятого объекта является правильным?
Освещение является сложным, тени, рефлексы являются неотъемлимой частью трехмерного мира и т.д. Используем более сложный пример:
Алгоритм для получения такого результата выглядит следующим образом:

Анализ пересечений позволяет легко локализовать отдельные, не связанные между собой, области. Включив режим отображения скан-линий можно легко увидеть как сам подход, так и влияние шага сканирования на финальный результат. Обратите внимание на очень простой трюк с границей, который существенно улучшает производимое впечатление:
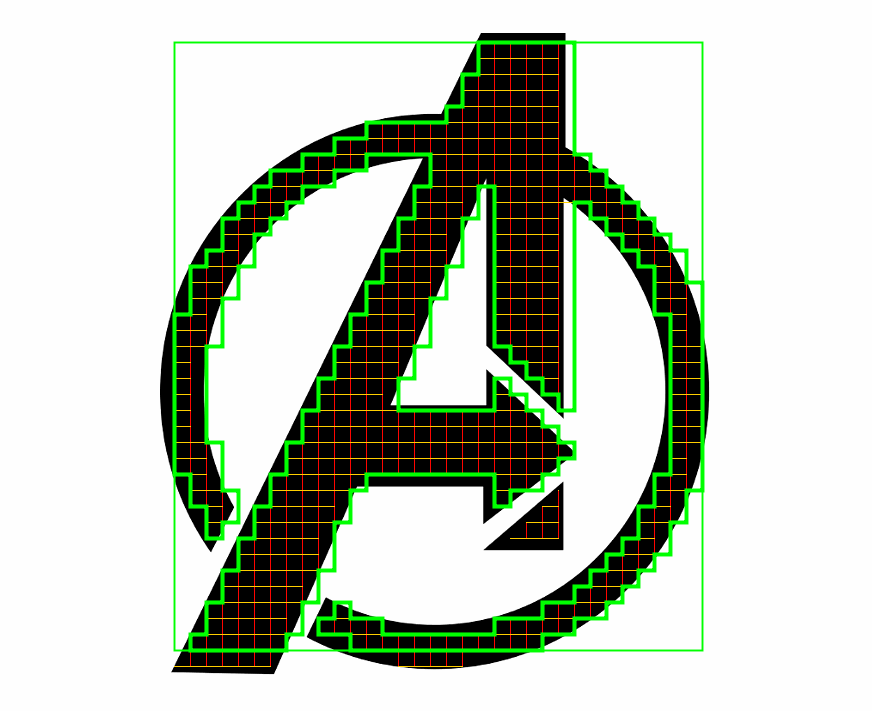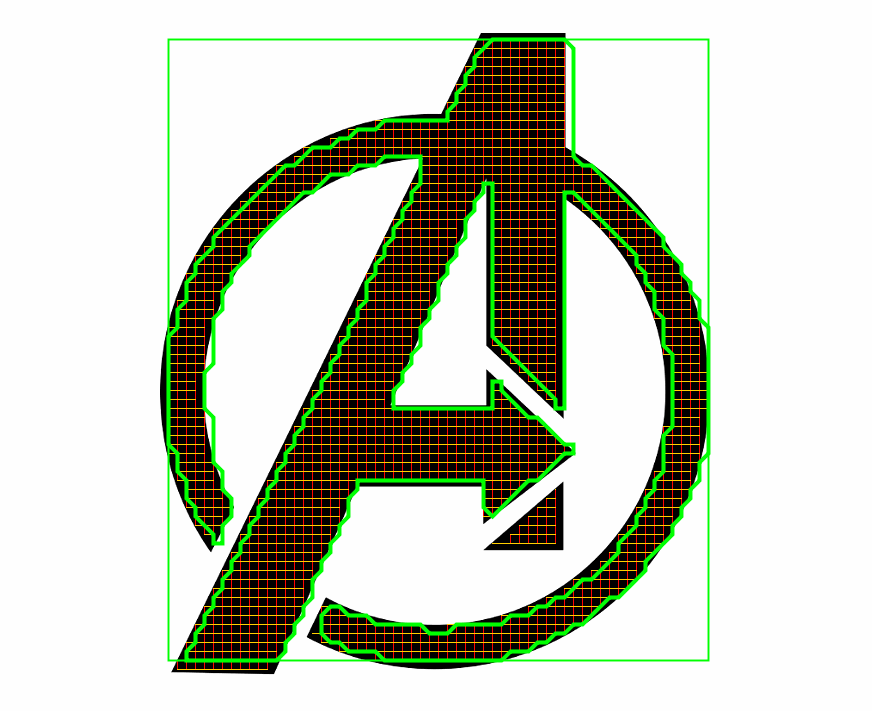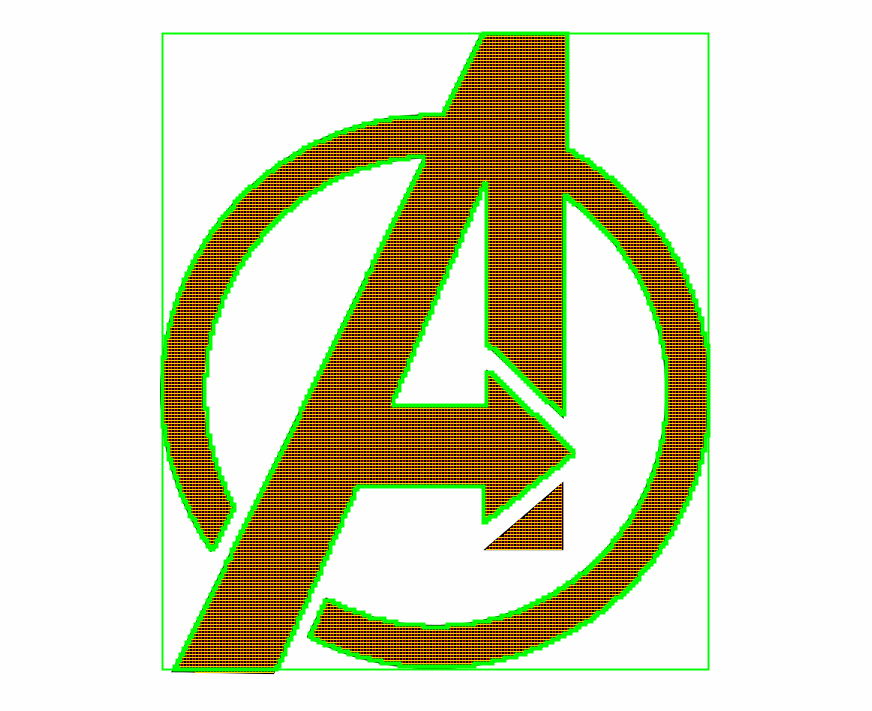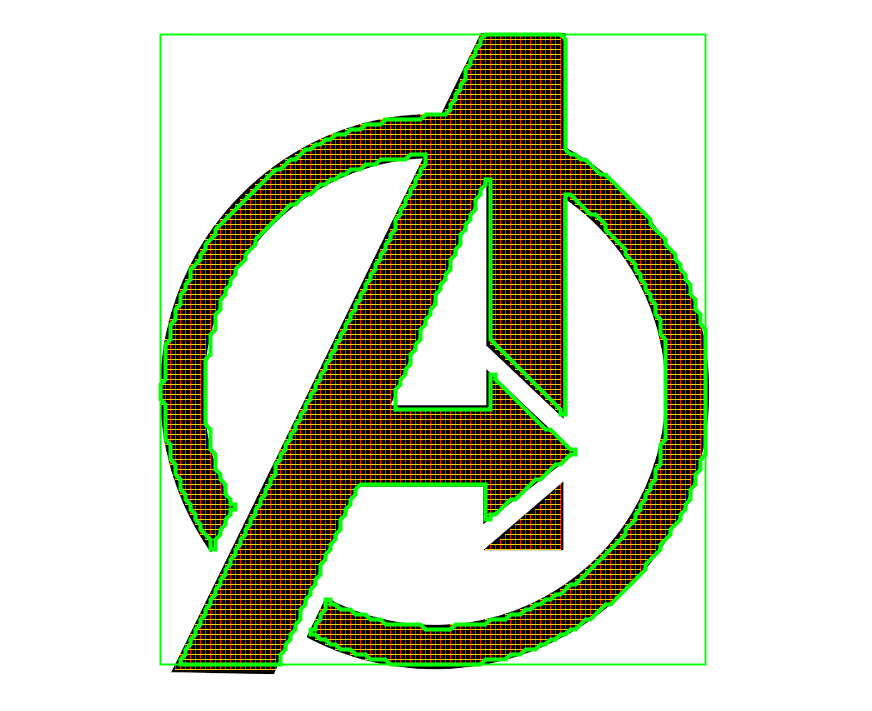
Точность восстанавливаемого контура легко оценить используя следующий пример:

Больше объектов, больше контуров, лучше точность, волосы и в 4К — уж если проверять свою реализацию, так с песнями и танцами.
До следующего раза и других, не менее интересных, деталей.
YouTube: RobotsCanSee
Telegram: RobotsCanSeeUs
Классические алгоритмы компьютерного зрения, как оказалось, могут сильно помочь с получением качественных тренировочных наборов. Естественно, такой подход применим не во всех случаях, с чем и необходимо разобраться.
В чем сложность?
Как было показано в предыдущей части, детальная ручная разметка наборов является очень трудоемким процессом и, откровенно говоря, вообще не вариант для любого здравомыслящего человека. Автоматическая разметка, особенно если речь идет о контурах, выглядит куда интереснее, но как получить интересующий контур быстро и точно?
Функция принадлежности
Начать, пожалуй, стоит с функции принадлежности. Предположим, интересующий нас объект характеризуется ярким цветом, который, к тому же, является уникальным для объекта в контексте конкретной сцены:
Учитывая специфику подхода (а именно необходимость в таких сценах, которые легко «разобрать») сформулировать правило отбора примеров для получения тренировочного набора достаточно легко: очень полезными будут такие сцены, для которых правило уникальности цвета искомого объекта будет выполнятся (помним, со всеми сложными случаями иметь дело буде уже нейросеть, успешно обученная с помощью сгенерированного набора).
Собственно, условие уникальности является необходимым минимумом, поскольку с цветом тоже можно и нужно работать:
Цветовое расстояние
Работа с цветом, в данном случае, является очень важной частью всего подхода. По сути, функция принадлежности может быть реализована как функция близости к заданному цвету с установленным пороговым значением:
В существующем решении используется несколько реализаций Delta E, как наиболее точного стандарта. Например, CIE94 в цветовом пространстве LCH (L*C*h):
Слишком большой порог, для цветового расстояния, скорее всего «сломает» контур, захватив пиксели, которые не относятся к искомому объекту. Слишком маленький — выделит только часть искомого объекта. В связи с чем сложные сцены требуют внимания, например:
Кит на фото все еще различим для глаза (с трудом, конечно), но контур построен уже неверно. Пример целиком:
Восстанавливаем контур
Предположим, с цветом все отлично, как получить искомый контур? Задача не является простой, поскольку результат, скорее всего, будет достаточно сложным, с полостями, второстепенными элементами и т.д. Какой из вариантов восстановленного контура для отдельно взятого объекта является правильным?
Освещение является сложным, тени, рефлексы являются неотъемлимой частью трехмерного мира и т.д. Используем более сложный пример:
Алгоритм для получения такого результата выглядит следующим образом:
- исходное изображение
- выбор шага сканирования (критично с точки зрения производительности)
- горизонтальное сканирование
- вертикальное сканирование и анализ пересечений для поиска обособленных «объектов»
- построение массива мета-пикселей (для идентификации как формы так и внутренних особенностей объекта) и пост-обработка (фильтрация, сглаживание и т.д.)
- «векторизация» восстановленной формы объекта
Анализ пересечений позволяет легко локализовать отдельные, не связанные между собой, области. Включив режим отображения скан-линий можно легко увидеть как сам подход, так и влияние шага сканирования на финальный результат. Обратите внимание на очень простой трюк с границей, который существенно улучшает производимое впечатление:
Точность восстанавливаемого контура легко оценить используя следующий пример:
Финальный тест
Больше объектов, больше контуров, лучше точность, волосы и в 4К — уж если проверять свою реализацию, так с песнями и танцами.
До следующего раза и других, не менее интересных, деталей.
Другие результаты
Следить за развитием проекта
YouTube: RobotsCanSee
Telegram: RobotsCanSeeUs
aarner Автор
Темы для следующих частей:
И еще много всего другого:
HobbitSam
статья ни о чём… как коэффициенты подбирать? вы вручную все правки вносите или у вас есть какой-то механизм, определяющий что фигура теряет целостность? почему нельзя оператор Собеля, например, использовать для поиска границ, а по ним выборку делать? Простите, за резкую оценку, но мне казалось, хабр для желающих более глубоко разобраться… а это демонстрация технологии… может быть интересно для бизнеса, но у вас нет бенчмарков… может эти видео по нескольку дней обрабатываются…
aarner Автор
Это действительно очень хорошее начало разговора :) Давайте по существу.
Можно, с оговорками и в некоторых случаях. Уверен, вы сами знаете насколько сложным будет результат для достаточно сложного объекта? Например для такого:
HobbitSam
это было заглавие) я не очень разбираюсь в компьютерном зрении. И да, я не знаю результат вызова оператора Собеля для парусника. И не знаю альтернатив Собелю, а ведь они, наверняка, есть. И я не говорю что это панацея, это дополнительная информация об изображении! Раз уж вы учите нейросеть на распознавание — почему бы это не учесть? Я бы, наверное, мимо прошел, но подумал: вдруг вы добавите деталей в следующих частях цикла… и всем будет лучше… Одна из лучших статей на хабре (объективно) — про расшифровку QR кодов… с картинками и деталями… а вы как будто хотите угодить широкому кругу, а не заинтересованным… вы не показываете, какой вы (или ваша команда) молодец потому что делаете сложные вещи вот так, а не вот так. вместо этого вы как бы говорите: о, гляньте как круто! ну да… а в чём ваш вклад? а что нового я узнал от вас?
поймите правильно, если это ваша цель — то комментарий скорее в положительном ключе: отличная статья, вы прекрасно достигли желаемого. но моё личное мнение: хабр для молодцов, которые делают сложное и рассказывают как) в любом случае, спасибо за адекватную реакцию.
aarner Автор
Благодарю за фидбек, это самое главное, на самом деле. Немного переформатирую подход, в угоду деталям и нюансам реализации. Напишу вам отдельно :)