

Натолкнувшись на статью “Уничтожим монополию …”, автор, как человек пусть от EDA очень далёкий, но от природы любознательный, не поленился пройтись по ссылкам и невольно поймал себя на мысли, что одно из основных технических решений — использование рядов стандартных ячеек (standard cell layout) — выглядит довольно спорно.
Да, такое расположение интуитивно понятно, ведь мы пишем и читаем похожим образом, кроме того, технологически просто располагать ячейки именно рядами, так удобно стыковать шины VDD и GND. С другой стороны, при этом возникает непростая комбинаторная задача, требуется разрезать схему на линейные куски и расположить эти куски таким образом, чтобы (грубо) минимизировать общую длину соединений.
И конечно же возник вопрос, нет ли альтернативных решений, … вот что если …

Фиг.1 типичные ряды стандартных ячеек (отсюда)
А что если
С точки зрения уменьшения общей длины связей было бы полезно расположить стандартные ячейки вдоль какой-то из заметающих кривых ex: Пеано или Гильберта.
Эти кривые состоят из массы разнообразных “закоулков”, наверняка есть конфигурация в которой связанные стандартные ячейки в среднем окажутся недалеко друг от друга.
Или это может служить нулевой итерацией для дальнейшей оптимизации.
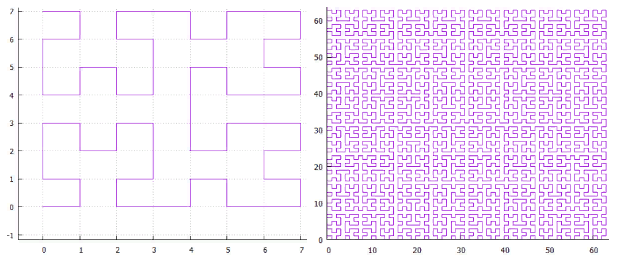
Фиг.2 Кривая Гильберта, поля 8X8 и 64X64
- Заметающие кривые самоподобны, что хорошо укладывается в общую концепцию.
- Они имеют высокую локальность т.е. точки, находящиеся где-то рядом на кривой скорее всего находятся недалеко и в пространстве.
- Содержат иерархически организованную сеть каналов.
- Для логической схемы можно подобрать подходящий квадрат или прямоугольник 1х2,2х1, в котором она размещается с избытком и «подвигать» ее вдоль заметающей кривой (см. Фиг.3) чтобы подобрать оптимальную геометрию, ведь это всего одна степень свободы с довольно дешевой функцией стоимости.
- Сохранится удобство стыковки шин (VDD/GND).
- …

Фиг.3 Три куска кривой Гильберта с разными сдвигами.
Итак:
- экспериментировать будем с кривой Гильберта
- экспериментировать будем в квадрате 64X64 (Фиг.3)
- в элементарном шаге кривой может быть несколько стандартных ячеек и пробелов — сколько именно и в каком порядке — параметр эксперимента
- все элементарные шаги устроены одинаково
- элементарные шаги идут с нахлёстом т.е. если шаг начинается со стандартной ячейки, в конце его должен быть пробел, и наоборот
- все пробелы и стандартные ячейки имеют один размер — 1X1
- все ячейки сериализованы в каком-то порядке, этот порядок тоже является параметром
- еще один параметр — сдвиг от начала кривой (точки (0,0)), начиная с которого мы будем располагать стандартные ячейки в определенном порядке
- длины связей между стандартными ячейками считаются по L1 (манхэттенское расстояние)
- сумма длин всех связей и является искомой величиной, определив минимальную сумму мы и найдем оптимальное расположение
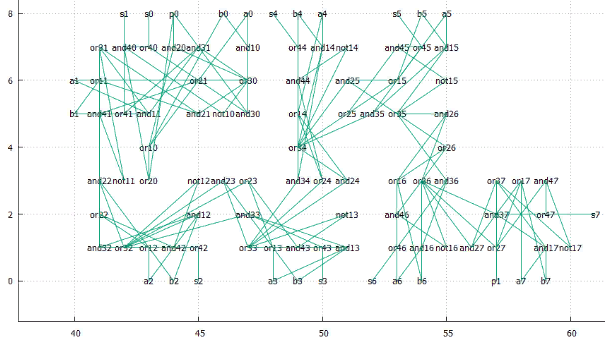
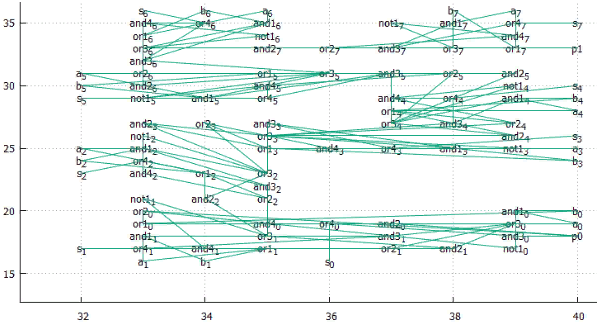
А в качестве подопытного кролика возьмём 8-разрядный сумматор. Он достаточно прост, но не тривиален. В нём достаточно много элементов и связей, чтобы почувствовать потенциальные плюсы и минусы. В тоже время их достаточно немного для того, чтобы можно было экспериментировать “на коленке”.
Сумматор

Фиг.4 принципиальная схема полного одноразрядного сумматора

Фиг.5 Так видит это граф утилита Neato из graphwiz

Фиг.6 8-разрядный знаковый сумматор, взято здесь
Но мы будем работать только с целыми числами, без флага ошибки W.
Фиг.7 Так 8-разрядный сумматор видит утилита dot из graphwiz.
Выглядит как танец маленьких лебедей.

Фиг.8 тот же граф после оптимизации с помощью neato.
a_0;
a_1;
a_2;
a_3;
a_4;
a_5;
a_6;
a_7;
b_0;
b_1;
b_2;
b_3;
b_4;
b_5;
b_6;
b_7;
s_0;
s_1;
s_2;
s_3;
s_4;
s_5;
s_6;
s_7;
p0;
p1;
and1_0;
and1_1;
and1_2;
and1_3;
and1_4;
and1_5;
and1_6;
and1_7;
and2_0;
and2_1;
and2_2;
and2_3;
and2_4;
and2_5;
and2_6;
and2_7;
and3_0;
and3_1;
and3_2;
and3_3;
and3_4;
and3_5;
and3_6;
and3_7;
and4_0;
and4_1;
and4_2;
and4_3;
and4_4;
and4_5;
and4_6;
and4_7;
or1_0;
or1_1;
or1_2;
or1_3;
or1_4;
or1_5;
or1_6;
or1_7;
or2_0;
or2_1;
or2_2;
or2_3;
or2_4;
or2_5;
or2_6;
or2_7;
or3_0;
or3_1;
or3_2;
or3_3;
or3_4;
or3_5;
or3_6;
or3_7;
or4_0;
or4_1;
or4_2;
or4_3;
or4_4;
or4_5;
or4_6;
or4_7;
not1_0;
not1_1;
not1_2;
not1_3;
not1_4;
not1_5;
not1_6;
not1_7;
a_0 -> and1_0;
a_1 -> and1_1;
a_2 -> and1_2;
a_3 -> and1_3;
a_4 -> and1_4;
a_5 -> and1_5;
a_6 -> and1_6;
a_7 -> and1_7;
b_0 -> and1_0;
b_1 -> and1_1;
b_2 -> and1_2;
b_3 -> and1_3;
b_4 -> and1_4;
b_5 -> and1_5;
b_6 -> and1_6;
b_7 -> and1_7;
a_0 -> or1_0;
a_1 -> or1_1;
a_2 -> or1_2;
a_3 -> or1_3;
a_4 -> or1_4;
a_5 -> or1_5;
a_6 -> or1_6;
a_7 -> or1_7;
b_0 -> or1_0;
b_1 -> or1_1;
b_2 -> or1_2;
b_3 -> or1_3;
b_4 -> or1_4;
b_5 -> or1_5;
b_6 -> or1_6;
b_7 -> or1_7;
and1_0 -> or3_0;
and1_1 -> or3_1;
and1_2 -> or3_2;
and1_3 -> or3_3;
and1_4 -> or3_4;
and1_5 -> or3_5;
and1_6 -> or3_6;
and1_7 -> or3_7;
and1_0 -> and3_0;
and1_1 -> and3_1;
and1_2 -> and3_2;
and1_3 -> and3_3;
and1_4 -> and3_4;
and1_5 -> and3_5;
and1_6 -> and3_6;
and1_7 -> and3_7;
or1_0 -> and2_0;
or1_1 -> and2_1;
or1_2 -> and2_2;
or1_3 -> and2_3;
or1_4 -> and2_4;
or1_5 -> and2_5;
or1_6 -> and2_6;
or1_7 -> and2_7;
or1_0 -> or2_0;
or1_1 -> or2_1;
or1_2 -> or2_2;
or1_3 -> or2_3;
or1_4 -> or2_4;
or1_5 -> or2_5;
or1_6 -> or2_6;
or1_7 -> or2_7;
and2_0 -> or3_0;
and2_1 -> or3_1;
and2_2 -> or3_2;
and2_3 -> or3_3;
and2_4 -> or3_4;
and2_5 -> or3_5;
and2_6 -> or3_6;
and2_7 -> or3_7;
or2_0 -> and4_0;
or2_1 -> and4_1;
or2_2 -> and4_2;
or2_3 -> and4_3;
or2_4 -> and4_4;
or2_5 -> and4_5;
or2_6 -> and4_6;
or2_7 -> and4_7;
and3_0 -> or4_0;
and3_1 -> or4_1;
and3_2 -> or4_2;
and3_3 -> or4_3;
and3_4 -> or4_4;
and3_5 -> or4_5;
and3_6 -> or4_6;
and3_7 -> or4_7;
or3_0 -> not1_0;
or3_1 -> not1_1;
or3_2 -> not1_2;
or3_3 -> not1_3;
or3_4 -> not1_4;
or3_5 -> not1_5;
or3_6 -> not1_6;
or3_7 -> not1_7;
not1_0 -> and4_0;
not1_1 -> and4_1;
not1_2 -> and4_2;
not1_3 -> and4_3;
not1_4 -> and4_4;
not1_5 -> and4_5;
not1_6 -> and4_6;
not1_7 -> and4_7;
and4_0 -> or4_0;
and4_1 -> or4_1;
and4_2 -> or4_2;
and4_3 -> or4_3;
and4_4 -> or4_4;
and4_5 -> or4_5;
and4_6 -> or4_6;
and4_7 -> or4_7;
or4_0 -> s_0;
or4_1 -> s_1;
or4_2 -> s_2;
or4_3 -> s_3;
or4_4 -> s_4;
or4_5 -> s_5;
or4_6 -> s_6;
or4_7 -> s_7;
p0 -> and2_0;
p0 -> or2_0;
p0 -> and3_0;
or3_0 -> and2_1;
or3_0 -> or2_1;
or3_0 -> and3_1;
or3_1 -> and2_2;
or3_1 -> or2_2;
or3_1 -> and3_2;
or3_2 -> and2_3;
or3_2 -> or2_3;
or3_2 -> and3_3;
or3_3 -> and2_4;
or3_3 -> or2_4;
or3_3 -> and3_4;
or3_4 -> and2_5;
or3_4 -> or2_5;
or3_4 -> and3_5;
or3_5 -> and2_6;
or3_5 -> or2_6;
or3_5 -> and3_6;
or3_6 -> and2_7;
or3_6 -> or2_7;
or3_6 -> and3_7;
or3_7 -> p1;
}
Эксперимент 1
- элементарный шаг кривой Гильберта — (пропуск, ячейка, ячейка, пропуск)
- вершины графа (элементарные ячейки) отсортированы по алфавиту
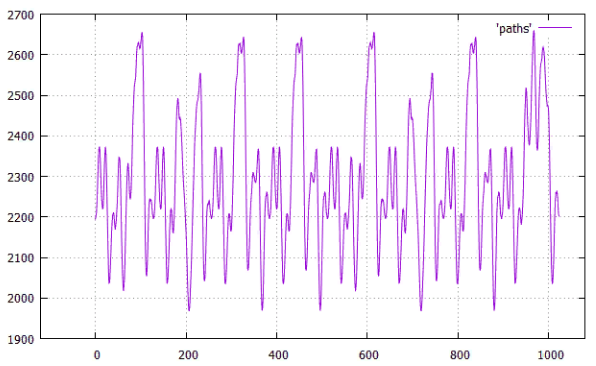
Фиг.9 по X — сдвиг от начала, по Y — длина всех путей
Минимальное расстояние (первое из) при сдвиге 207 (Общая длина всех связей — 1968), посмотрим как выглядит это оптимальное расположение.

Фиг.10 оптимальный граф для сдвига 207, выглядит не очень красиво.
Эксперимент 2
- элементарный шаг кривой Гильберта — (пропуск, ячейка, ячейка, пропуск)
- вершины графа (элементарные ячейки) в естественном порядке (как пришло в описании графа, см. описание графа выше) -

Фиг.11 по X — сдвиг от начала, по Y — длина всех путей

Фиг.12 оптимальный граф для сдвига 11 длина 750
Эксперимент 3
- элементарный шаг кривой Гильберта — (пропуск, ячейка, ячейка, пропуск)
- порядок вершин определён обходом графа в ширину, вершины без ссылок в начале списка, выходные — в конце

Фиг.13 по X — сдвиг от начала, по Y — длина всех путей
Фиг.14 Оптимальное расположение — сдвиг 3, общая длина 1451
Расположить все input вершины в начале, а output — в конце было не очень хорошей
идеей.
Эксперимент 4
- элементарный шаг кривой Гильберта — (пропуск, ячейка, ячейка) Sic!
- порядок вершин естественный, как в эксперименте 2

Фиг.15 по X — сдвиг от начала, по Y — длина всех путей

Фиг.16 Оптимальное расположение — сдвиг 10, общая длина 503
Эксперимент 5
С IO надо что-то делать, определим их в пост-процессинге, т.е. для каждого сдвига
построим расположение без IO вершин, потом построим поглощающий экстент-рамку вокруг графа, нанесем IO вершины на ближайшую незанятую точку рамки и посчитаем финальную длину
- элементарный шаг кривой Гильберта — (пропуск, ячейка, ячейка)
- порядок вершин определяется просмотром в ширину, но без IO вершин

Фиг.17 по X — сдвиг от начала, по Y — длина всех путей
Фиг.18 Оптимальное расположение — сдвиг 607, общая длина 484, средняя 3.33793
Выглядит неплохо, а что если оптимизировать не общую длину путей, а её сумму с площадью занятого прямоугольника. У них размерность разная, поэтому будем считать, что подсчитываем не длину пути, а площадь под путями.
Эксперимент 6
Параметры те же что и в эксперименте 5, оптимизируем площадь.
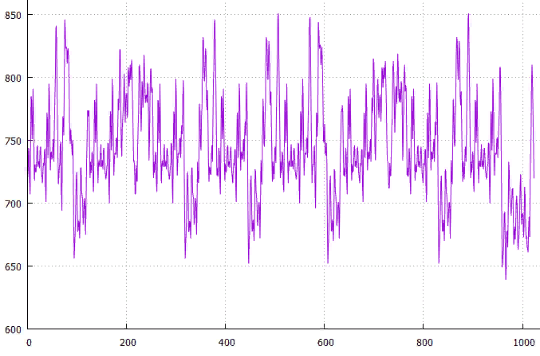
Фиг.19 по X — сдвиг от начала, по Y — длина всех путей
Фиг.20 Оптимальное расположение — сдвиг 966, общая длина 639, средняя 3.30345
Прямоугольник получился довольно вытянутым. А что если учитывать не площадь прямоугольника, а квадрат гипотенузы, подталкивая к более квадратным формам?
Эксперимент 7
Параметры те же что и в эксперименте 5, оптимизируем квадрат гипотенузы.

Фиг.21 по X — сдвиг от начала, по Y — длина всех путей

Фиг.22 Оптимальное расположение — сдвиг 70, общая длина 702, средняя 3.46207
Эксперимент 8
- элементарный шаг кривой Гильберта — (ячейка, пропуск) Sic!
- порядок вершин определяется просмотром в ширину, но без IO вершин
Будем считать что стоимость хождения по Y вдвое больше чем по X, это ближе к реальности.
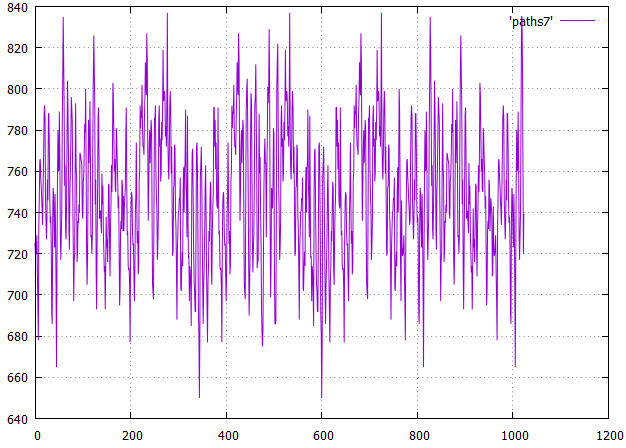
Фиг.23 по X — сдвиг от начала, по Y — длина всех путей

Фиг.24 Оптимальное расположение — сдвиг 344, общая длина 650, средняя 3.8
Выводы
Предварительный “выбор редакции” — эксперимент 6.
Было бы неплохо упорядочить IO-вершины, но для этого нужна подсказка со стороны,
где именно (направление) следует расположить данный класс вершин.
Но прежде хотелось бы услышать мнение специалистов.
P.S.: спасибо YuriPanchul и andy_p за отсутствие рефлекторной отрицательной реакции.
UPD( 02.11.2019): добавил «эксперимент 8», где стандартные ячейки находятся в узлах кривой Гильберта, т.е. строго на квадратной решетке. При этом они с одной стороны объединяются в традиционные ряды, а с другой стороны, расположены вдоль по кривой Гильберта.
Комментарии (14)

Zl0briy
01.11.2019 12:18+2Вы видите результат, то есть стандартные ячейки, расставленные в ряды, и хотите это улучшить, используя те инструменты, которыми вы сами владеете. Но вы, похоже, смутно представляете как было сделано то, что вы видите, и почему именно так. Поэтому ваше предложение для специалистов в этой области выглядит странно. Хотя идея и интересная.
Смотрите. Плейсинг начинается с того, что в САПР создаются границы проекта, создаются ряды заданной высоты, доступные для расстановки стандартных ячеек, между рядами прокладываются линии земли и питания по первому металлу и ещё ряд действий, которые в рамках данного обсуждения неважны. Это называется создание Floorplan'а.
Все стандартные ячейки в рамках одной библиотеки имеют фиксированную высоту и фиксированный шаг ширины. В проекте может быть несколько библиотек с разной высотой и тогда потребуется создание рядов с разной высотой, но это мы сейчас тоже опустим.
Ряды делаются так, что в ряде номер N ячейки стоят так, что шина земли проходит снизу, а шина питания сверху; в ряде номер (N+1) — наоборот. То есть ячейки стыкуются друг с другом.
Короче говоря, плейсер может ставить ячейки только в фиксированные места (ряды). Единственная степень свободы, которая у него есть помимо выбора ряда — это поворот на 180 градусов.
При этом есть ещё один немаловажный момент. Большинство ячеек в современных и не очень технологиях типа 65 нм, 28 нм и ниже не имеют контактов к подложке и карману. Для обеспечения такого контакта используются специальные ячейки (tap'ы), которые разработчик расставляет с заданным шагом на этапе проектирования Floorplan в рядах, в соответствии с требованием технологии. Грубо говоря, у вас в каждом ряду должны стоять tap'ы с шагом 20 мкм или меньше.
Шины земли и питания существенно шире, чем сигнальные линии, поэтому разводить их будет сложно, если они уже не разведены способом описанным выше.
К тому же, границы проекта выбираются так, чтобы у вас после плейсинга утилизация была ~75%. Реально можно сделать как меньше, так и больше. Зависит от конкретного проекта. Утилизация — это сколько площади у вас занято. То есть на этапе плейсинга реально занимается порядка 3/4 площади. А зачем так делают? Так затем, что плейсинг — это только начало маршрута!
Дальше будет построение деревьев тактовых сигналов. Строится оно добавлением инверторов, буферов и, возможно, других элементов типа gate'ов. Это «съест» ещё площадь.
Дальше будет правка setup'ов и hold'ов (времена предустановки и удержания) с помощью добавления буферов уже в пути данных.
Потом будет этап разводки, после которого скорее всего будет опять правка setup'ов и hold'ов тем же способом. Возможно будет ещё «починка» деревьев тактовых сигналов после разводки.
Это то, что с ходу в голову приходит. Вероятно, есть ещё проблемы, которые на первый взгляд неочевидны, но которые тоже ставят крест на том, что вы предлагаете.
Это было длинное лирическое отступление. Теперь к сути.
Суть в том, что необходимость изменения плейсинга из-за добавления элементов на более поздних стадиях проектирования ставит крест на предлагаемом методе.
Теоретически, можно заложить «запчасти» ещё на этапе плейсинга (так, кстати, делают, но для других целей) и часть из них потом не использовать, но какова будет эффективность этого?
Ну, и скорость, конечно. Крупный проект на современном железе с применением современных САПР может собираться несколько недель. Боюсь, что таким методом он будет собираться пару лет.
Кстати, насчёт запчастей. Есть такой подход — ECO (Engineering Change Order). Это когда вам на поздних этапах проектирования, когда уже всё почти готово к отправке на фабрику, или даже уже отправлено, нужно провести какую-то корректировку.
Если фотошаблоны ещё не готовы, то всё вообще просто: у вас же утилизация не 100%, поэтому можно добавить необходимой логики и поменять металлическую разводку.
Если фотошаблоны уже изготовлены, но вы заранее заложили «запчасти» в виде рассыпухи логических вентилей, то вы можете обойтись переделыванием нескольких фотошаблонов слоёв металлизации: просто по-другому связать то, что у вас было заложен в чипе.
В вашем подходе такое можно предусмотреть? И если такое предусмотреть, то как это повлияет не его эффективность?
zzeng Автор
01.11.2019 14:41Спасибо за развёрнутый ответ.
Положение, которое вы описали, сложилось за десятки лет совместной эволюции технологии и САПР. И конечно, здесь всё явно и неявно пронизано этими рядами ячеек.
Просто отбросить их равносильно прохождению всего пути заново, что может быть и неплохо при определенных обстоятельствах.
Можно ли как-то встроить предложенный подход в существующую технологию?
А что если… :)
Давайте отбросим вертикальные отрезки кривой Гильберта, не будем их заполнять ячейками. Горизонтальные участки сдвинем, чтобы убрать промежутки (это нетривиальное дело).
Но заполнять их станем, как если бы они по-прежнему были на кривой Гильберта ( с учетом tap-ов, если требуется).
В результате сохранятся все прелести существующей технологии и основные преимущества предложенного подхода. В частности скорость.
У вас почему-то сложилось впечатление, что плэйсмент по кривой Гильберта требует бОльших вычислительных затрат, чем нынешняя технология.
Считаю что это не так. Впрочем, опыт критерий истины.Zl0briy
01.11.2019 14:59В результате сохранятся все прелести существующей технологии и основные преимущества предложенного подхода. В частности скорость.
Может быть так уже и сделано? :)
Я не разработчик САПР, а их пользователь. Выше я описывал то, как выглядит процесс с точки зрения разработчика. Как работает сам САПР, какие в него там алгоритмы заложены неизвестно (коммерческая тайна).
У вас почему-то сложилось впечатление, что плэйсмент по кривой Гильберта требует бОльших вычислительных затрат, чем нынешняя технология.
Если крутить ячейки в разные стороны, не пользоваться заранее заданным допустимым местом расположения ячеек (рядами), разводить первый металл, то так и будет.
Плюс, если для применения такого метода, требуются нестандартные элементы, как то квадратные ячейки, ячейки разной ориентации и т.п., то это не просто дольше, но и гораздо дороже. Типовая библиотека состоит из порядка 300-500 элементов. Бывают больше. В проекте используются от 1 и до нескольких десятков библиотек.
Разработка библиотеки достаточно трудоёмкая задача, сложность и время на её решение растут с увеличением количества элементов примерно линейно.
Впрочем, опыт критерий истины.
Согласен с вами.zzeng Автор
02.11.2019 10:38Добавил вырожденный случай, когда стандартные ячейки просто располагаются
в узлах кривой Гильберта, т.е. в прямоугольной решетке, естественным образом формируя ряды.
>> Может быть так уже и сделано? :)
>> Я не разработчик САПР, а их пользователь. Выше я описывал то,
>> как выглядит процесс с точки зрения разработчика.
>> Как работает сам САПР, какие в него там алгоритмы
>> заложены неизвестно (коммерческая тайна).
Есть такое мнение (andy_p):
«Вообще алгоритмов размещения достаточно много. Насколько мне известно, обычно делают так — размещают грубо ячейки по силовому алгоритму, а затем с помощью какого- либо другого алгоритма убирают получившиеся пересечения. Насчет заметающих кривых — не встречал такого, но, наверное, тоже может иметь место.
Силовой алгоритм — это просто размещение, при котором потенциальная энергия минимальна, если считать, что связь между парами ячеек является пружиной или чем-то типа того с жесткостью, зависящей от количества соединений (ряды при этом не учитываются). А в какой ряд ячейка встанет определяется близостью к этому ряду.»
amartology
03.11.2019 10:57Я ещё на всякий случай замечу, что пользователь имеет довольно много возможностей повлиять на результаты трассировки, например, вручную проставив минимальные или максимальные необходимые расстояния между отдельными блоками. Поэтому может иметь смысл применение максимально простых алгоритмов, чтобы учёт пожеланий пользователя не приводил к сильному усложнению расчетов.
В случае с кривой Гилберта все выглядит так, как будто дополнение алгоритма всеми разумными практическими ограничениями (не 100% заполнения, запасные части, отсутствие поворотов на 90 градусов и т.д.) в итоге приведет к тому, что решение получится очень сильно вырожденным и не имеющим больших преимуществ над более простыми алгоритмами.zzeng Автор
03.11.2019 11:41«Силовой» алгоритм имеет большое число степеней свободы и его еще надо суметь аккуратно "отжечь". Из-за локальных минимумов делать это надо многократно.
И даже найденное расположение пытаются улучшить перестановками ячеек с целью уменьшить число пересечений, насколько я понял.
В предложенной же конструкции одна степень свободы и глобальный минимум находится перебором всех вариантов. При этом «силовая» функция может быть той же самой. Это не гарантирует оптимальности решения, но это точно будет быстрее.
Zl0briy
01.11.2019 12:59+2Перечитал ещё раз. Хочу добавить, что у вас предпосылка неверная. Вы придумали метод, который позволит «минимизировать общую длину соединений». Этого не требуется.
Главное это, обычно, производительность/скорость, а не общая длина металлизации. Связь между ними есть, но не прямая.
У вас каждое соединение ячеек друг с другом должно удовлетворять заданным временным параметрам: грубо говоря, сигнал должен распространяться за время не более T и максимальный фронт должен быть не более S. В чипе существует огромное количество разных соединений. Какие-то должны обеспечивать минимальные T и S и такие ячейки надо ставить максимально близко друг к другу (иногда даже вручную задавать их месторасположение), а для некоторых предъявляются такие «расслабленные» ограничения, что их можно хоть в разных углах чипа ставить и вести между ними миллиметровые линии металлизации.
Современные САПРы это учитывают. Это timing-driven placement, о котором вам говорили в комментатариях выше.zzeng Автор
01.11.2019 13:30Это как раз относительно просто делается, настройкой атрибутов связи, как учитывать её стоимость.
amartology
Базовые ячейки имеют очень разную длину. Вот, например, несложный триггер:

У сложного триггера (с сетами-ресетами, входным мультиплексором для скан-цепи) длина будет ещё больше.
Для того, чтобы удобно вписать в кривую Гилберта множество ячеек с различающимися больше, чем на порядок длинами, надо очень постараться. Или иметь много вариантов топологии каждой ячейки.
И ещё есть мнение, что в топологии с кривой Гилберта у вас будут намного более серьезные проблемы с просадкой питания из-за намного большего сопротивления линий земли и питания.
И, кажется, ничего не мешает в технологии, где у вас достаточно металлов, располагать ячейки в каком угодно порядке поверх прямолинейной сетки земель и питаний.
zzeng Автор
Это всего-лишь идея, а не законченное решение.

Про питание: сейчас, насколько я понял, есть два варианта — условно, прогрессивное и чересстрочное
В данном случае придётся делать что-то вроде H-tree аналогично подводу синхроимпульса.
Повернуть стандартную ячейку или обернуть её через ось, насколько я понимаю, не проблема. Если это будет полезно, появятся и «угловые» ячейки.
Сложный триггер тянет на функциональный блок, который, впрочем можно «с'инлайнить», разбив на элементарные ячейки. Либо на следующем уровне иерархии можно использовать функциональные блоки в качестве элементов для размещения по высокоуровневой кривой Гильберта.
Здесь, похоже, есть где разгуляться пытливым умам.
amartology
Ну и повторяю, никто не захочет делать линии питания длиннее — это куча проблем, в том числе связанных с тем, что просадка питания зависит от расположения ячейки на кристалле. С нормальной сеткой (она кстати обычно именно сетка в двух металлах, а не набор линий) эта разница предсказуема и легко считается. С вашим подходом вы предлагаете взять одну из самых сложных задач — построение дерева тактовых сигналов — и усложнить ее ещё больше.
Опять же, что мешает расставить находящиеся в сетке питания ячейки вдоль линии Гилберта, чтобы получить минимальную сумму длин сигнальных линий, а не силовых?
P.S. Делать много вариантов топологии для библиотечных элементов — дорого и ещё больше запутает плейсер. А если разбивать большие ячейки на прямо маленькие примитивы, то накладные расходы площади на соединения мини-ячеек между собой сожрут всю выгоду от более продвинутого плейсмента.
zzeng Автор
Если вы считаете, что для питания проще использовать решетку, нежели дерево,
значит так и есть.
Большие библиотечные элементы можно делать квадратными а не линейными.
В этом случае они на общих основаниях встроятся в кривую Гильберта (вместо узда 2Х2, 4Х4, ...), дискретность только появится. И/или разрывы, если таких элементов несколько.
amartology
Библиотечные элементы делают фиксированной высоты для того, чтобы максимально упростить работу плейсера, потому что она и так крайне ресурсозатратна, даже на маленьких проектах.
А есть еще, например, timing-driven placement, где задача стоит не «оптимизировать», а «сделать достаточно хорошо для того, чтобы удовлетворить ТЗ». и, СЮРПРИЗ, в процессе итерационной разводки соединений в проекте могут появляться новые элементы, предназначенные для коррекции поехавших в разные стороны задержек.
Zl0briy