

Нейросети в компьютерном зрении активно развиваются, многие задачи ещё далеки от решения. Чтобы быть в тренде в своей области, достаточно подписаться на инфлюенсеров в Твиттере и читать релевантные статьи на arXiv.org. Но у нас появилась возможность съездить на International Conference on Computer Vision (ICCV) 2019. В этом году она проводится в Южной Корее. Теперь мы хотим поделиться с читателями Хабра тем, что мы увидели и узнали.
От Яндекса нас там было много: приехали разработчики беспилотного автомобиля, исследователи, те, кто занимается задачами CV в сервисах. Но сейчас мы хотим представить немного субъективную точку зрения нашей команды — лаборатории машинного интеллекта (Yandex MILAB). Другие ребята наверняка смотрели на конференцию под своим углом.
Чем занимается лаборатория
Мы делаем экспериментальные проекты, связанные с генерацией изображений и музыки для развлекательных целей. Особенно нам интересны нейросети, которые позволяют менять контент от пользователя (для фото такая задача называется image manipulation). Пример результата нашей работы с конференции YaC 2019.
Научных конференций очень много, но из них выделяются топовые, так называемые A* конференции, на которых обычно публикуются статьи о самых интересных и важных технологиях. Точного списка A* конференций нет, вот примерный и неполный: NeurIPS (ранее NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Последние три специализируются на теме CV.
ICCV at glance: постеры, туториалы, воркшопы, стенды
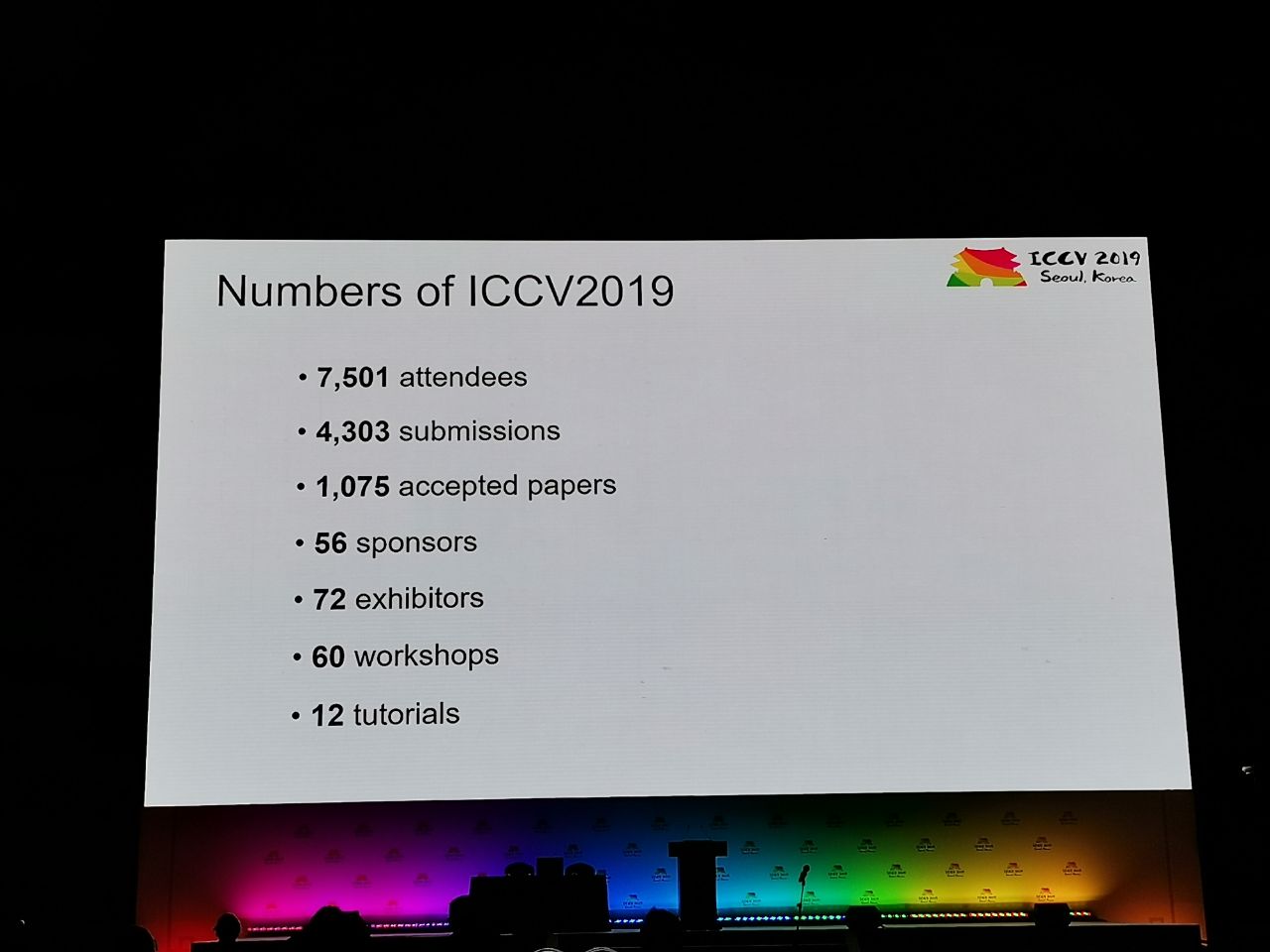
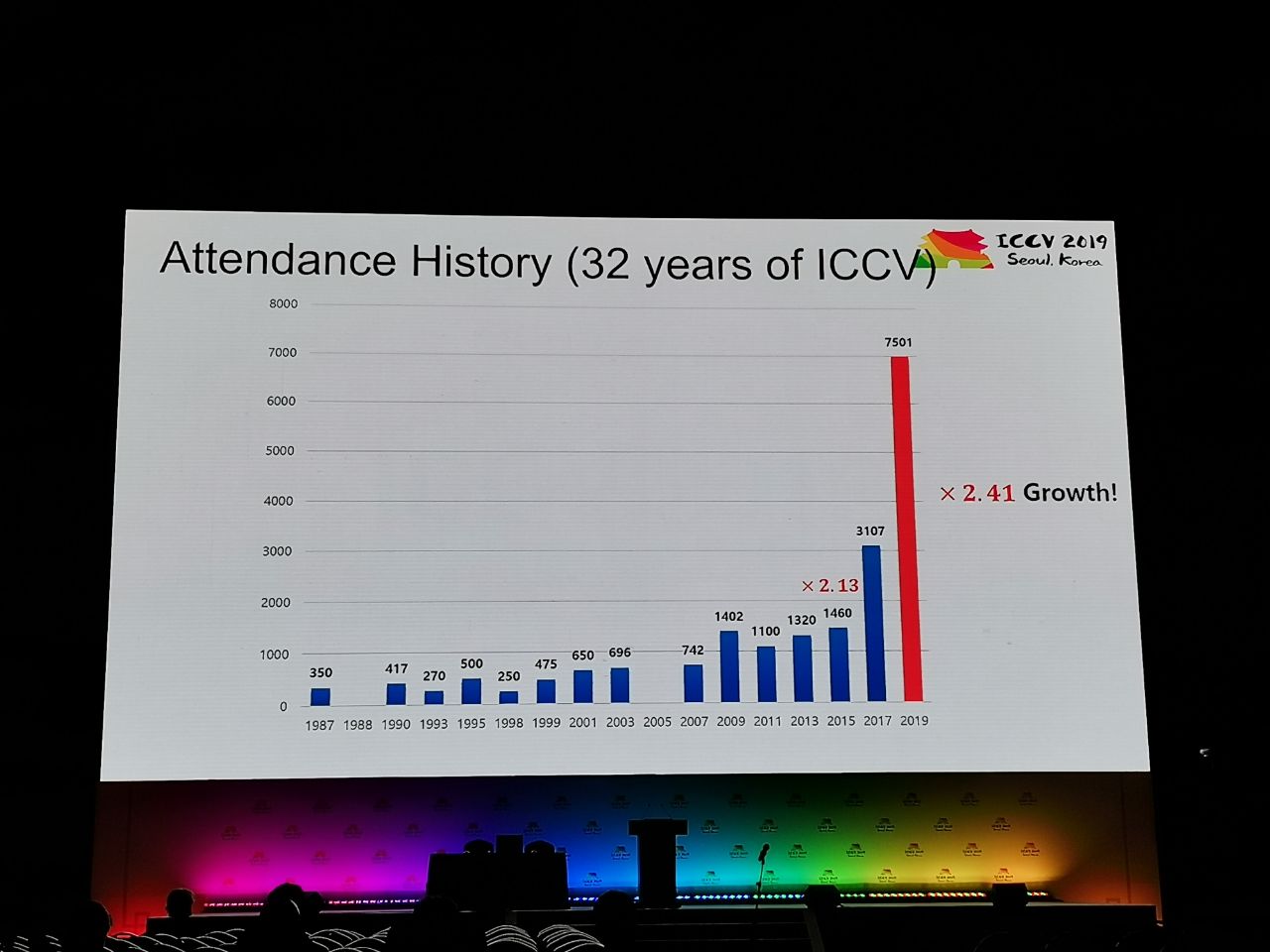
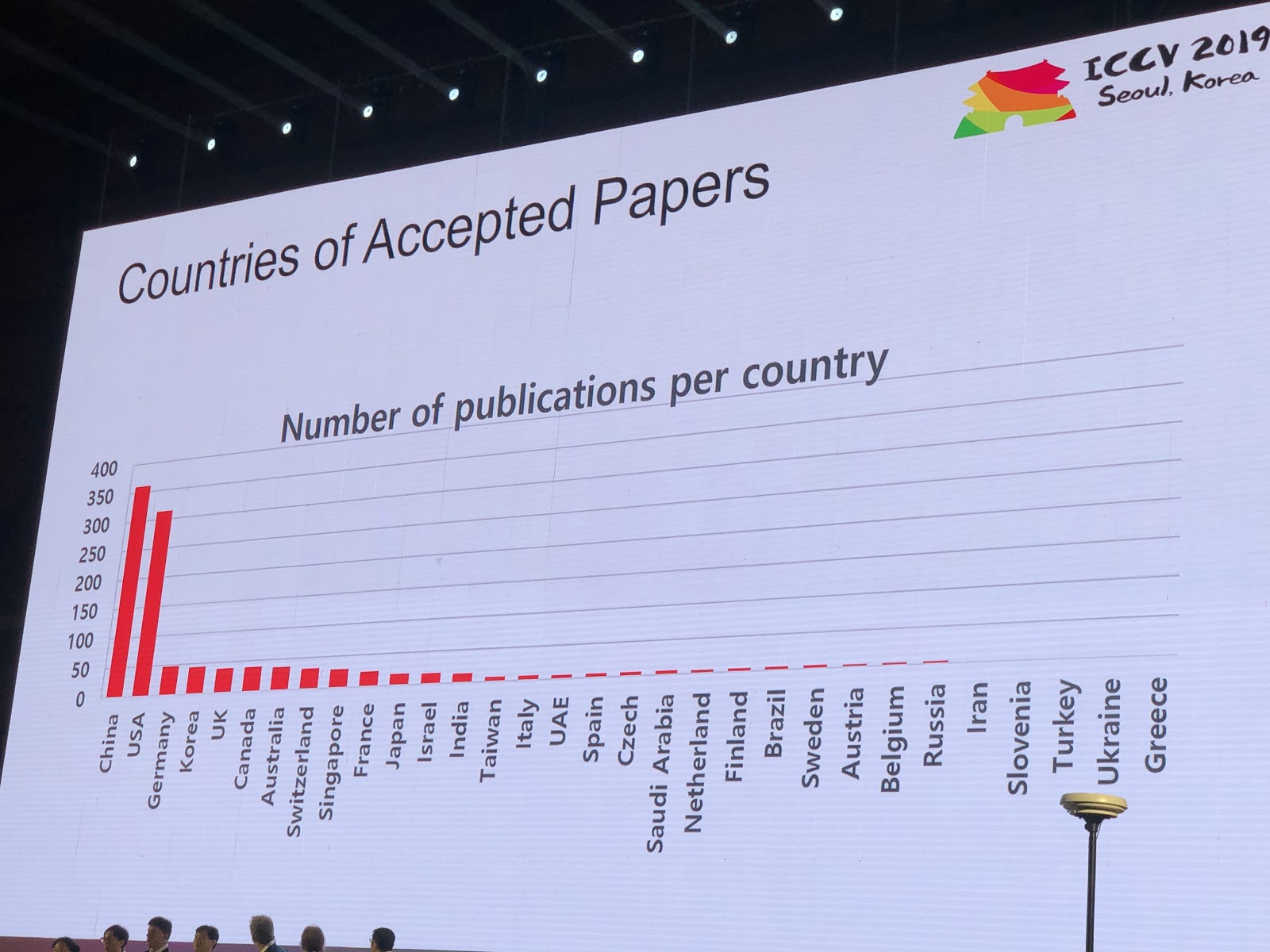
На конференцию приняли 1075 работ, участников было 7500. Из России приехало 103 человека, были статьи от сотрудников Яндекса, Сколтеха, Samsung AI Center Moscow и Самарского университета. В этом году ICCV посетило не так много топовых исследователей, но вот, например, Алексей (Алёша) Эфрос, который всегда собирает много народа:

Статистика 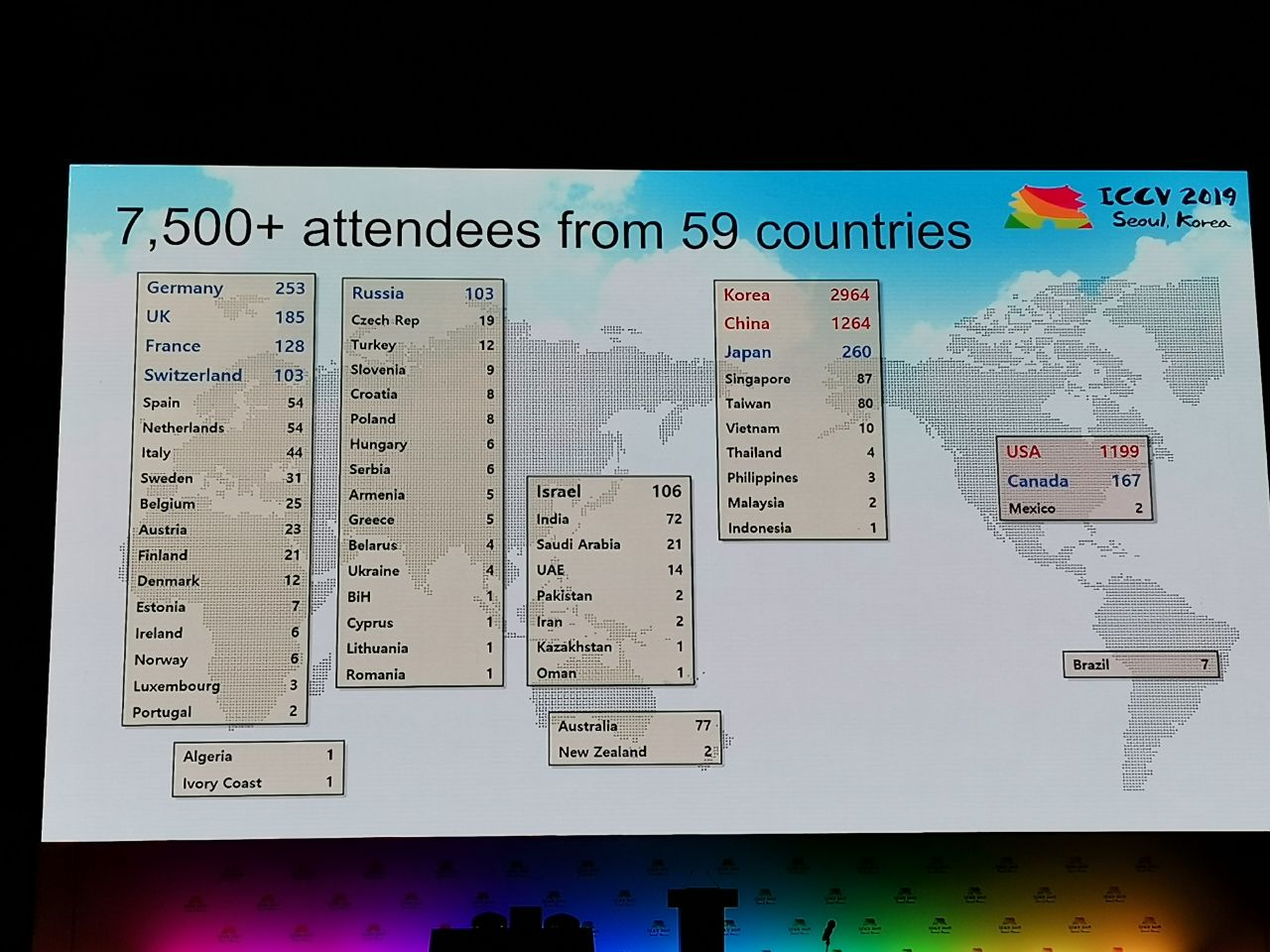

На всех подобных конференциях статьи представляют в виде постеров (подробнее о формате), а лучшие презентуют ещё и в виде коротких докладов.
Вот часть работ из России 


На туториалах можно погрузиться в какую-то предметную область, это напоминает лекцию в вузе. Её читает один человек, обычно не рассказывая о конкретных работах. Пример классного туториала (Michael Brown, Understanding Color and the In-Camera Image Processing Pipeline for Computer Vision):

На воркшопах, напротив, рассказывают про статьи. Обычно это работы в какой-то узкой теме, рассказы от руководителей лабораторий о всех последних работах студентов, либо статьи, которые не были приняты на основную конференцию.
Компании-спонсоры приезжают на ICCV со стендами. В этом году приехали Google, Facebook, Amazon и много других международных компаний, а также большое число стартапов — корейских и китайских. Особенно много было стартапов, которые специализируются на разметке данных. На стендах проходят свои выступления, можно брать мерч, задавать вопросы. Для хантинга у компаний-спонсоров бывают вечеринки. На них удаётся попасть, если убедить рекрутеров, что вам интересно и что вы потенциально можете пройти собеседования. Если вы опубликовали статью (или, тем более, выступили с ней), начали или заканчиваете PhD — это плюс, но порой можно договориться на стенде, задав интересные вопросы инженерам компании.
Тренды
Конференция позволяет окинуть взглядом всю область CV. По количеству постеров той или иной тематики можно оценить, насколько тема горячая. Какие-то выводы напрашиваются уже по ключевым словам:

Zero-shot, one-shot, few-shot, self-supervised и semi-supervised: новые подходы к давно изученным задачам
Люди учатся более эффективно использовать данные. Например, в FUNIT можно генерировать выражение лиц животных, которых не было в обучающей выборке (в применении подавая несколько референсных картинок). Идеи Deep Image Prior получили развитие, и теперь сети GAN удаётся обучать на одной картинке — мы ещё расскажем об этом ниже в хайлайтах. Можно использовать self-supervision для предобучения (решая задачу, для которой можно синтезировать выровненные данные, например предсказывать угол поворота картинки) или учиться одновременно на размеченных и неразмеченных данных. В этом смысле венцом творения можно считать статью S4L: Self-Supervised Semi-Supervised Learning. А вот предобучение на ImageNet не всегда помогает.

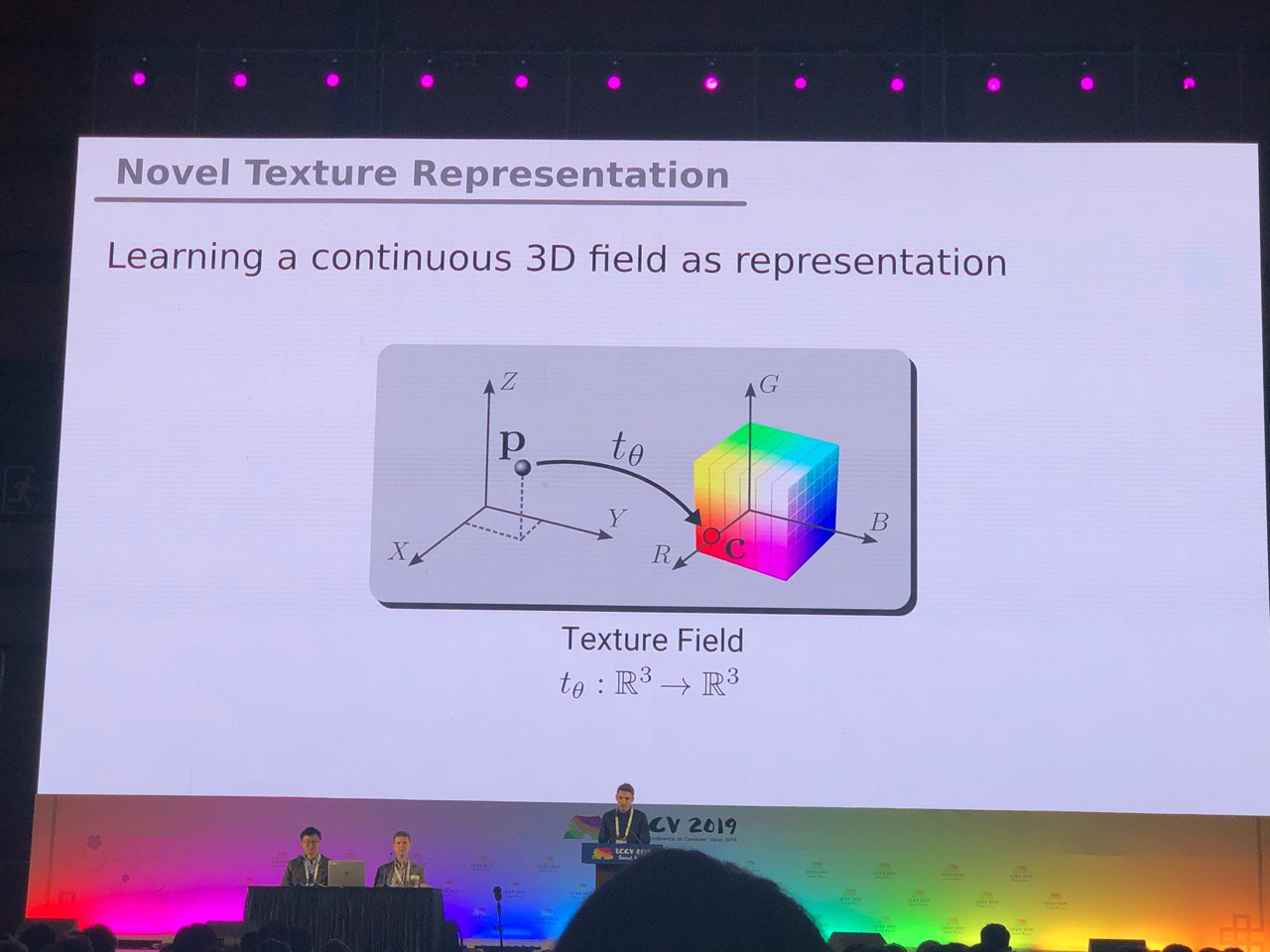
3D и 360°
Задачи, по большей части решённые для фото (сегментация, детекция), требуют дополнительного исследования для 3D-моделей и панорамных видео. Мы увидели много статей по преобразованию RGB и RGB-D в 3D. Некоторые задачи, например определение позы человека (pose estimation), решаются более естественно, если перейти к трёхмерным моделям. Но пока нет единого мнения, как именно представлять 3D-модели — в виде сетки, облака точек, вокселей или SDF. Вот ещё один вариант:
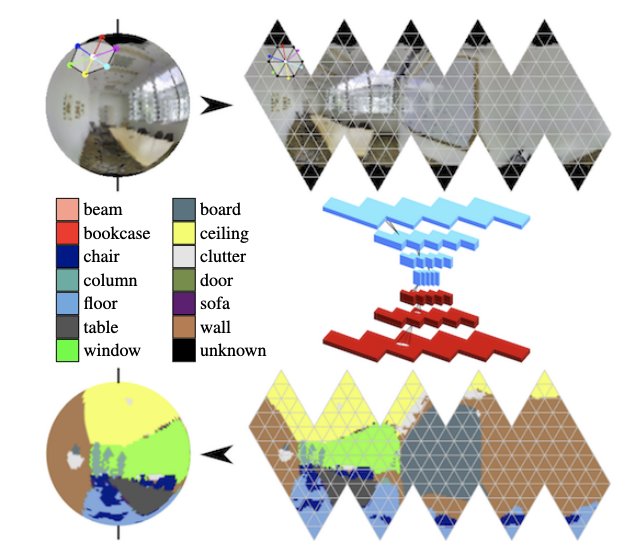
В панорамах активно развиваются свёртки на сфере (см. Orientation-aware Semantic Segmentation on Icosahedron Spheres) и поиск ключевых объектов в кадре.
Определение позы и предсказание движений человека
С тем, чтобы определять позу в 2D, уже есть успехи — теперь фокус сместился в сторону работы с несколькими камерами и в 3D. Ещё, например, можно определять скелет сквозь стену, отслеживая изменения в сигнале Wi-Fi при его прохождении сквозь тело человека.
Большая работа проделана в области детекции ключевых точек на руке (hand keypoint detection). Появились новые датасеты, в том числе на основе видео с диалогами двух людей — теперь можно предсказывать жесты рук по аудио или тексту разговора! Такой же прогресс — в задачах отслеживания взгляда (gaze estimation).

Также можно выделить большой кластер работ, связанных с предсказанием движения человека (например, Human Motion Prediction via Spatio-Temporal Inpainting или Structured Prediction Helps 3D Human Motion Modelling). Задача важная и, исходя из разговоров с авторами, чаще всего применяется для анализа поведения пешеходов в autonomous driving.
Манипуляции с людьми на фото и видео, виртуальные примерочные
Основная тенденция — менять изображения лиц по интерпретируемым параметрам. Идеи: deepfake по одной картинке, изменение выражения по рендеру лица (PuppetGAN), feedforward-изменение параметров (например, возраста). Style transfers перешли из названия темы в применения работ. Отдельная история — виртуальные примерочные, они работают почти всегда плохо, вот пример демки.


Генерация по скетчам/графам
Развитием идеи «Пусть сетка что-нибудь сгенерирует исходя из предыдущего опыта» стала другая: «Давайте показывать сетке, какой вариант нас интересует».
SC-FEGAN позволяет делать guided inpaint: пользователь может дорисовать часть лица в стёртой области картинки и получить восстановленную картинку в зависимости от дорисовки.

В одной из 25 статей Adobe для ICCV объединены две GAN: одна дорисовывает скетч за пользователя, другая генерирует из скетча фотореалистичную картинку (страница проекта).

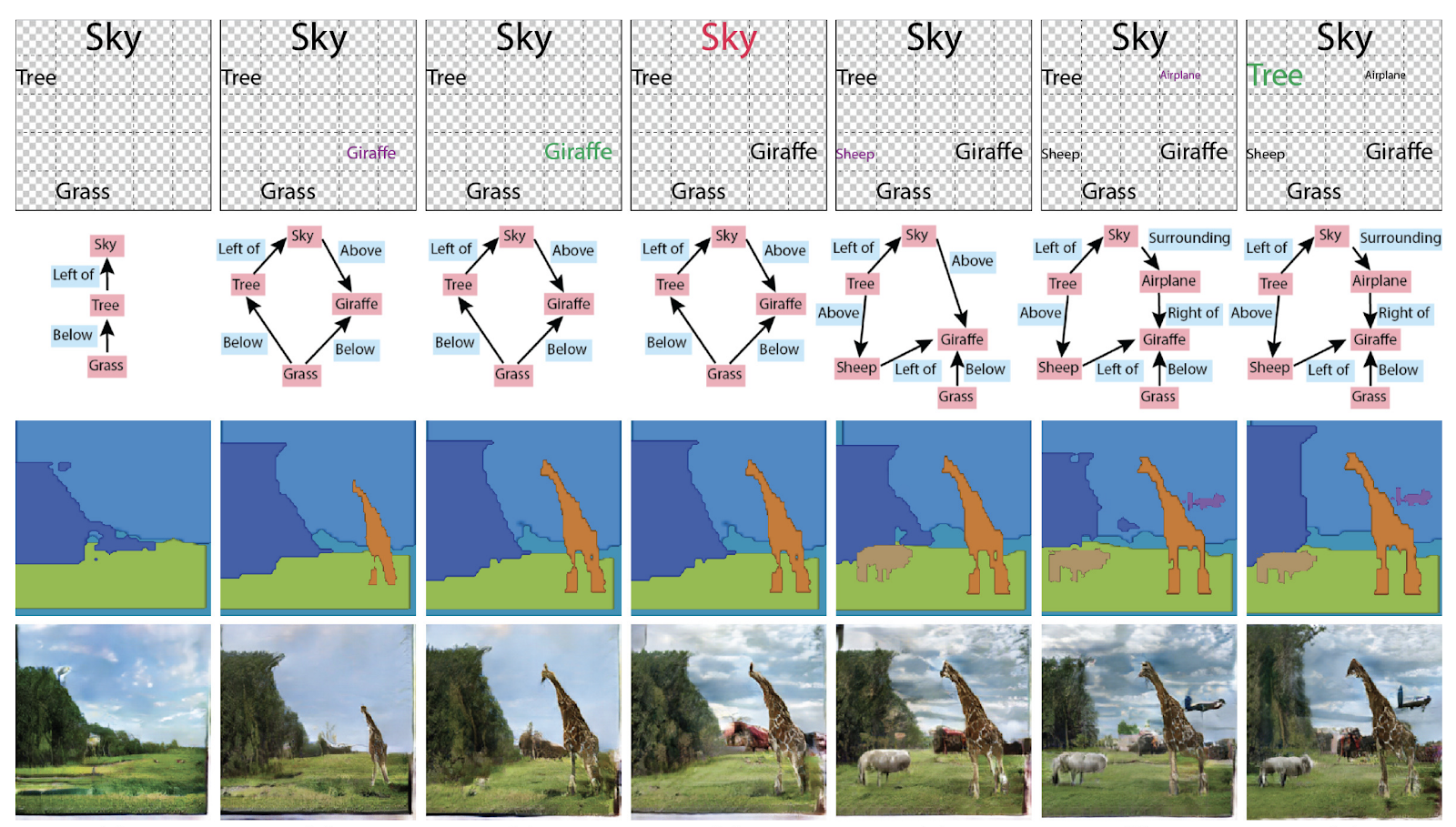
Раньше в генерации изображений были не нужны графы, а теперь их сделали контейнером знаний о сцене. Награду Best Paper Honorable Mentions по итогам ICCV завоевала в том числе статья Specifying Object Attributes and Relations in Interactive Scene Generation. Вообще, можно использовать их по-разному: генерировать графы из картинок, либо картинки и тексты из графов.
Реиндентификация людей и машин, подсчёт численности толпы (!)
Много статей посвящено трекингу людей и реидентификации людей и машин. Но что нас удивило, так это куча статей по подсчёту людей в толпе, и все из Китая.
Постеры 




А вот Facebook, наоборот, анонимизирует фото. Причём делает это интересным образом: обучает нейросеть генерировать лицо без уникальных деталей — похожее, но не настолько, чтобы его правильно определяли системы распознавания лиц.

Защита от adversarial-атак
С развитием применений компьютерного зрения в реальном мире (в беспилотных авто, в распознавании лиц) всё чаще встает вопрос о надёжности таких систем. Для полноценного использования CV нужна уверенность, что система устойчива к adversarial-атакам — поэтому статей про защиту от них было не меньше, чем про сами атаки. Много работ было про объяснение предсказаний сетей (saliency map) и измерение уверенности в результате.
Совмещённые задачи
В большинстве задач с одним таргетом возможности улучшения качества практически исчерпаны, одно из новых направлений дальнейшего прироста качества — учить нейросети решать несколько похожих задач одновременно. Примеры:
— предсказание действий + предсказание оптического потока,
— представление видео + представление языка (VideoBERT),
— super-resolution + HDR.
А ещё появились статьи по сегментации, определению позы и реидентификации животных!

Хайлайты
Почти все статьи были известны заранее, текст был доступен на arXiv.org. Поэтому представление таких работ, как Everybody Dance Now, FUNIT, Image2StyleGAN, кажется скорее странным — это очень полезные работы, но никак не новые. Похоже, классический процесс научных публикаций здесь даёт сбой — наука развивается слишком быстро.
Определить лучшие работы очень сложно — их много, тематики разные. Несколько статей получили награды и упоминания.
Мы хотим выделить работы, интересные с точки зрения манипуляции изображениями, так как это наша тема. Они оказались для нас достаточно свежими и интересными (мы не претендуем на объективность).
SinGAN (best paper award) и InGAN
SinGAN: страница проекта, arXiv, код.InGAN: страница проекта, arXiv, код.
Развитие идеи Deep Image Prior от Дмитрия Ульянова, Андреа Ведальди и Виктора Лемпицкого. Вместо обучения GAN на датасете, сети учатся на фрагментах одной и той же картинки, чтобы запомнить статистики внутри неё. Обученная сеть позволяет редактировать и анимировать фотографии (SinGAN) или генерировать новые изображения любого размера из текстур исходного изображения, сохраняя локальную структуру (InGAN).
SinGAN:

InGAN:

Seeing What a GAN Cannot Generate
Страница проекта.Нейросети, генерирующие изображения, часто принимают на вход вектор случайного шума. В обученной сети множество входных векторов образует пространство, небольшие перемещения по которому приводят к небольшим изменениям картинки. С помощью оптимизации можно решать обратную задачу: для картинки из реального мира находить подходящий входной вектор. Автор показывает, что найти в нейросети совпадающую полностью картинку невозможно почти никогда. Некоторые объекты на картинке не генерируются (видимо, из-за большой вариативности этих объектов).
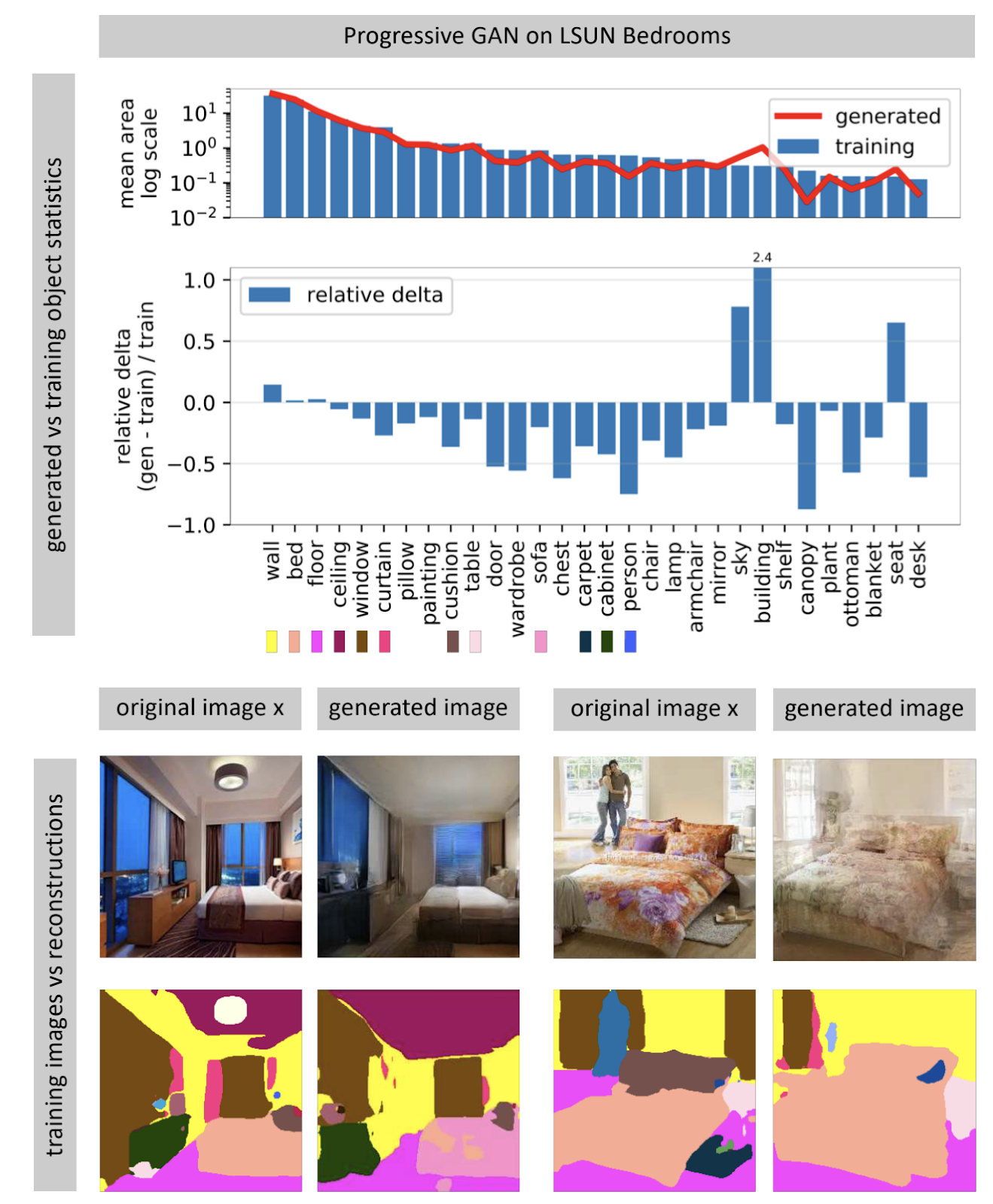
Автор выдвигает гипотезу, что GAN покрывает не всё пространство картинок, а только какое-то подмножество, напичканное дырами, как сыр. При попытке найти в нём фото из реального мира мы всегда будем терпеть неудачу, потому что GAN генерирует всё-таки не совсем реальные фотографии. Преодолеть отличия между реальными и сгенерированными картинками можно, только изменяя веса сети, то есть дообучая её под конкретное фото.

Когда сеть дообучена под конкретное фото, можно пробовать проводить с этим изображением различные манипуляции. В примере ниже на фото добавили окно, и сеть дополнительно сгенерировала отблески на кухонном гарнитуре. Значит, сеть и после дообучения под фотографию не потеряла способность видеть связь между объектами сцены.

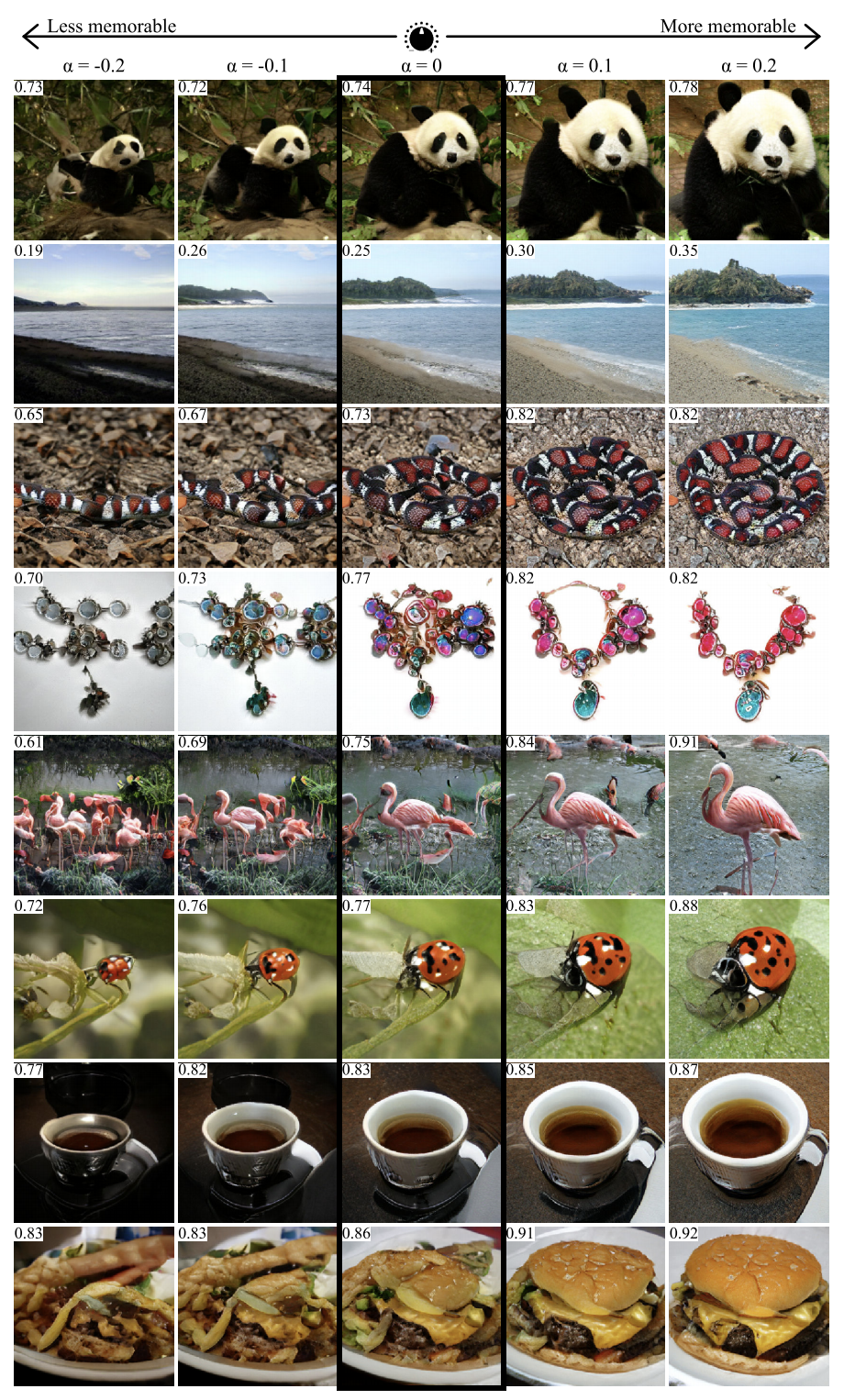
GANalyze: Toward Visual Definitions of Cognitive Image Properties
Страница проекта, arXiv.С помощью подхода из этой работы можно визуализировать и анализировать, что выучила нейросеть. Авторы предлагают обучить GAN создавать картинки, для которых сеть будет генерировать заданные предсказания. В качестве примеров в статье использовали несколько сетей, в том числе MemNet, предсказывающий запоминаемость фото. Выяснилось, что для лучшей запоминаемости объект на фото должен:
- быть ближе к центру,
- иметь более круглую или квадратную форму и простую структуру,
- находиться на однородном фоне,
- содержать выразительные глаза (по крайней мере, для фото собак),
- быть ярче, насыщеннее, в некоторых случаях — краснее.
Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis
Страница проекта, arXiv, код.Пайплайн для генерации фотографий людей по одной фотографии. Авторы показывают успешные примеры по переносу движения одного человека на другого, переносу одежды между людьми и генерации новых ракурсов человека — всё по одной фотографии. В отличие от предыдущих работ, здесь для создания условий используются не ключевые точки в 2D (поза), а 3D-сетка тела (поза + форма). Также авторы придумали, как перенести информацию с исходного изображения на сгенерированное (Liquid Warping Block). Результаты выглядят достойно, но разрешение полученной картинки — всего 256х256. Для сравнения, появившийся год назад vid2vid способен генерировать в разрешении 2048x1024, но ему нужно целых 10 минут видеосъёмки в качестве датасета.

FSGAN: Subject Agnostic Face Swapping and Reenactment
Страница проекта, arXiv.Сначала кажется, что ничего необычного: deepfake с более-менее нормальным качеством. Но основное достижение работы — подстановка лиц по одной картинке. В отличие от предыдущих работах в требовалось обучение на множестве фотографий конкретного человека. Пайплайн получился громоздким (reenactment and segmentation, view interpolation, inpainting, blending) и с большим количеством технических хаков, но результат того стоит.

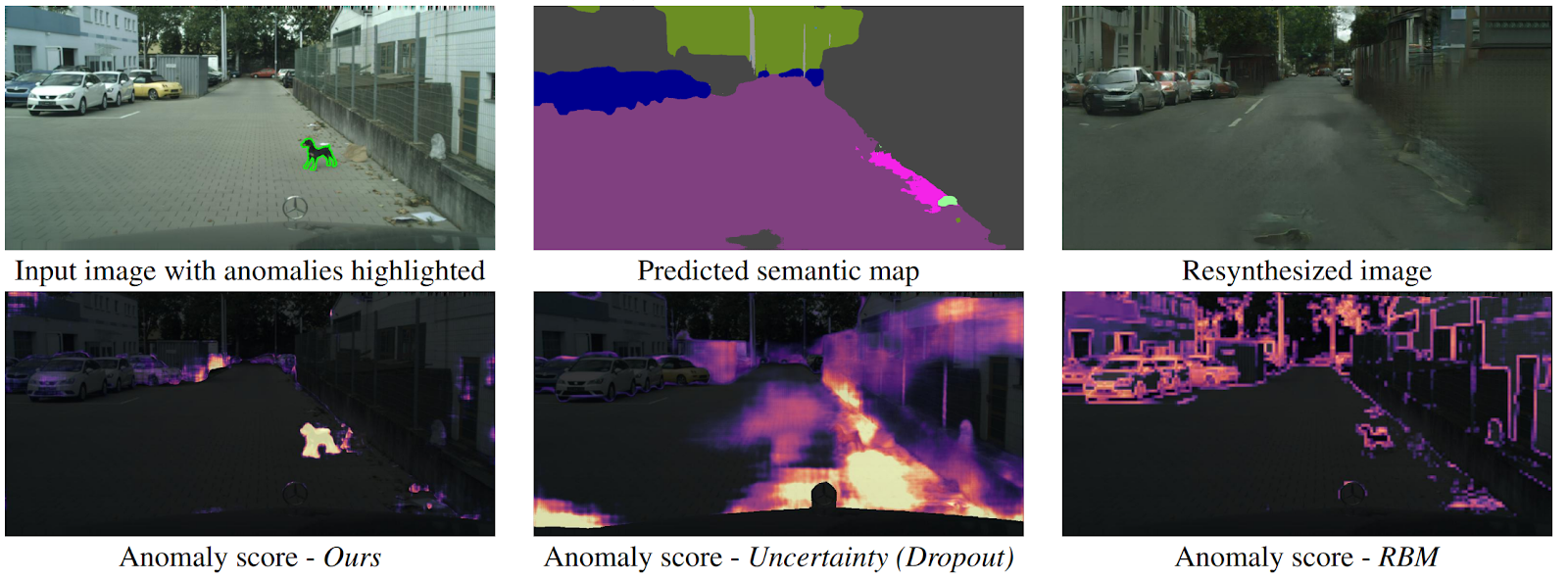
Detecting The Unexpected via Image Resynthesis
arXiv.Как беспилотнику понять, что перед ним неожиданно появился объект, который не попадает ни в один класс семантической сегментации? Существует несколько методов, но авторы предлагают новый, интуитивно понятный алгоритм, работающий лучше предшественников. По входному изображению дороги предсказывается семантическая сегментация. Она подаётся на вход в GAN (pix2pixHD), который пытается восстановить исходное изображение только по семантической карте. Аномалии, которые не попали ни в один из сегментов, будут значительно отличаться в исходом и сгенерированном изображении. Затем три изображения (исходное, сегментация и восстановленное) подаются в другую сеть, которая предсказывает аномалии. Датасет для этого генерировали из известного датасета Cityscapes, случайно изменяя классы на семантической сегментации. Что интересно, в такой постановке собака, стоящая посередине дороги, но правильно отсегментированная (значит, для неё есть класс), не является аномалией, поскольку система смогла её распознать.
Заключение
Перед конференцией важно знать, в чем твои научные интересы, на какие выступления хотелось бы попасть, с кем поговорить. Тогда всё пройдет гораздо продуктивнее.
ICCV — это прежде всего нетворкинг. Понимаешь, что есть топовые институты и топовые научруки, начинаешь в этом разбираться, знакомиться с людьми. А статьи можно и на arXiv почитать — и кстати, это очень круто, что за знаниями можно никуда не ехать.
Кроме того, на конференции можно глубоко погрузиться в темы, которые тебе не близки, увидеть тренды. Ну и выписать список статей для прочтения. Если вы студент — для вас это возможность познакомится с потенциальным научруком, если вы из индустрии — то с новым работодателем, а если компания — то показать себя.
Подписывайтесь на @loss_function_porn! Это личный проект: ведём вместе с karfly. Все работы, которые нам нравились во время конференции, мы постили сюда: @loss_function_live.
Комментарии (4)


Geotyper
13.11.2019 12:40ссылка @loss_function_porn правильная или все же @loss_function_chat?
нашел @loss_function_porn/ но через @loss_function_chat/ так в поиске не выдавал почему то
vlivashkin Автор
13.11.2019 12:49Похоже, телеграм фильтрует в поиске каналы, в которых есть слово porn =)
@loss_function_porn – основной канал, у него есть чат @loss_function_chat, а в лайв-канал @loss_function_live мы постили в прямом эфире то, что нам нравилось во время ICCV (в основном, постеры). В последнем не появится ничего нового до следующей поездки
AlexeyKachalov
Спасибо за обзор.