
Недавно прошел ID R&D Voice Antispoofing Challenge, главной задачей которого было создать алгоритм, способный отличить человеческий голос (human) от синтезированной записи (spoof). Я — ML Researcher в Dasha AI и много работаю над распознаванием речи, поэтому и решил поучаствовать. Вместе с командой мы заняли первое место. Под катом я расскажу о новых крутых подходах к обработке звука, а также о сложностях и странностях, с которыми нам пришлось столкнуться.

В соревновании участвовали 98 человек — так мало людей из-за того, что это соревнование по обработке звука, на русской платформе, да еще и в докере. Я был в команде с Дмитрием Даневским, Kaggle Master’ом, с которым мы познакомились и договорились об участии, пока обсуждали подходы в другом конкурсе.
Нам дали 5 Гбайт аудиофайлов, разбитых на классы spoof/human, и нужно было предсказать вероятность класса, завернуть в докер и отправить на сервер. Решение должно было отработать за 30 минут и весить менее 100 Мбайт. По официальной информации, необходимо было различать голос человека и автоматически сгенерированный — хотя лично мне казалось, что в класс spoof также попадали случаи, когда звук генерировали, поднося динамик к микрофону (как делают злоумышленники, похищая запись чужого голоса для идентификации).
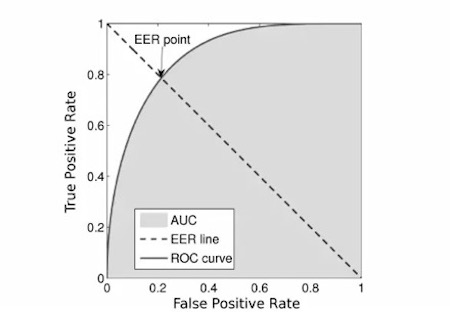
Метрикой был EER:
Мы взяли первый попавшийся код из сети, т. к. код организаторов казался перегруженным.
Организаторы предоставили бейзлайн и по совместительству главную загадку конкурса. Он был прост как палка: берем аудиофайлы, считаем мел-спектрограммы, тренируем MobileNetV2 и оказываемся где-то в районе 12-го места или ниже. Из-за этого многие могли подумать, что в конкурсе участвовали с десяток человек, а это было не так. Весь первый этап соревнования наша команда никак не могла пробить этот бейслайн. Идейно идентичный код давал результат сильно хуже, а любые улучшения (такие, как замена на более тяжелые сетки и OOF предсказания) помогали, но к бейзлайну не приближали.
И тут случилось неожиданное: где-то за неделю до окончания конкурса выяснилось, что реализация подсчета метрики организаторов содержала баг и зависела от порядка предсказаний. Примерно в это же время обнаружилось, что в докер-контейнерах организаторы любезно не выключили интернет, поэтому многие скачали тестовую выборку. Тогда конкурс заморозили на 4 дня, поправили метрику, обновили данные, отключили интернет и снова запустили еще на 2 недели. После пересчета мы оказались на 7-ом месте с одним из наших первых сабмишнов. Это послужило мощной мотивацией для продолжения участия в конкурсе.
Мы использовали resnet-like сверточную сетку, обученную поверх мел-спектрограмм.
С самого начала соревнования всех участников мучал вопрос: почему локальная валидация дает EER 0.01 и ниже, а лидерборд — 0.1 и не особо коррелирует? У нас было 2 гипотезы: либо в данных были дубликаты, либо тренировочные данные были собраны на одном множестве спикеров, а тестовые — на другом.
Истина оказалась где-то посередине. В тренировочных данных примерно 5% данных оказались дубликатами, и это считая только полные дубликаты по хэшам (кстати, там также могли содержаться разные кропы одного и того же файла, но это не так просто проверить — поэтому мы и не стали).
Для проверки второй гипотезы мы обучили speaker-id сетку, получили эмбеддинги на каждого спикера, кластеризовали это все k-means’ом и по этим кластерам стратифицировали фолды. А именно, мы обучались на спикерах из одних кластеров, а предсказывали спикеров из других. Такой метод валидации уже начал коррелировать с лидербордом, хотя и показывал score в 3-4 раза лучше. В качестве альтернативы мы пробовали валидироваться только на предсказаниях, в которых модель была хоть немного не уверена, то есть разница между предсказанием и меткой класса составляла >10**-4 (0.0001), но такая схема не принесла результатов.
В интернете достаточно просто найти тысячи часов человеческой речи. Кроме того, подобный конкурс уже проводился несколько лет назад. Поэтому очевидной идеей казалось скачать много-много данных (мы скачали ~300 Гбайт) и пообучать на этом классификатор. В отдельных случаях обучение на таких данных немного докидывало, если мы учили на дополнительных и на трейновых данных до выхода на плато, а потом дообучали только на тренировочных. Но при такой схеме модель сходилась примерно за 2 дня, что означало 10 дней на все фолды. Поэтому мы от этой идеи отказались.
Кроме того, многие участники заметили корреляцию длины файла и класса, на тестовой выборке этой корреляции замечено не было. Не очень хорошо себя проявили обычные картиночные сетки типа resnext, nasnet-mobile, mobileNetV3.
Было непросто и местами странно, но все же мы получили крутой опыт и вышли на первое место. Методом проб и ошибок я понял, какие подходы вполне рабочие, а какие — не очень. Теперь буду использовать эти инсайты у нас при обработке звука. Я много работаю над тем, чтобы вывести разговорный ИИ на уровень, неотличимый от человеческого, и поэтому всегда в поиске интересных задач и фишек. Надеюсь, вы тоже узнали что-то новое.
Ну и наконец выкладываю наш код.
В соревновании участвовали 98 человек — так мало людей из-за того, что это соревнование по обработке звука, на русской платформе, да еще и в докере. Я был в команде с Дмитрием Даневским, Kaggle Master’ом, с которым мы познакомились и договорились об участии, пока обсуждали подходы в другом конкурсе.
Задача
Нам дали 5 Гбайт аудиофайлов, разбитых на классы spoof/human, и нужно было предсказать вероятность класса, завернуть в докер и отправить на сервер. Решение должно было отработать за 30 минут и весить менее 100 Мбайт. По официальной информации, необходимо было различать голос человека и автоматически сгенерированный — хотя лично мне казалось, что в класс spoof также попадали случаи, когда звук генерировали, поднося динамик к микрофону (как делают злоумышленники, похищая запись чужого голоса для идентификации).
Метрикой был EER:
Мы взяли первый попавшийся код из сети, т. к. код организаторов казался перегруженным.
Соревнование
Организаторы предоставили бейзлайн и по совместительству главную загадку конкурса. Он был прост как палка: берем аудиофайлы, считаем мел-спектрограммы, тренируем MobileNetV2 и оказываемся где-то в районе 12-го места или ниже. Из-за этого многие могли подумать, что в конкурсе участвовали с десяток человек, а это было не так. Весь первый этап соревнования наша команда никак не могла пробить этот бейслайн. Идейно идентичный код давал результат сильно хуже, а любые улучшения (такие, как замена на более тяжелые сетки и OOF предсказания) помогали, но к бейзлайну не приближали.
И тут случилось неожиданное: где-то за неделю до окончания конкурса выяснилось, что реализация подсчета метрики организаторов содержала баг и зависела от порядка предсказаний. Примерно в это же время обнаружилось, что в докер-контейнерах организаторы любезно не выключили интернет, поэтому многие скачали тестовую выборку. Тогда конкурс заморозили на 4 дня, поправили метрику, обновили данные, отключили интернет и снова запустили еще на 2 недели. После пересчета мы оказались на 7-ом месте с одним из наших первых сабмишнов. Это послужило мощной мотивацией для продолжения участия в конкурсе.
Кстати о модели
Мы использовали resnet-like сверточную сетку, обученную поверх мел-спектрограмм.
- Всего таких блоков было 5. После каждого такого блока мы делали deep supervision и увеличивали количество фильтров в полтора раза.
- По ходу соревнования мы перешли от бинарной классификации к многоклассовой для того, чтобы эффективнее утилизировать технику mixup, при которой мы смешиваем два звука и суммируем их метки классов. Кроме того, после такого перехода мы смогли искусственно повысить вероятность класса spoof, домножив ее на 1.3. Нам это помогло, поскольку имелось предположение, что баланс классов в тестовой выборке может быть отличным от обучающей, и таким образом мы поднимали качество моделей.
- Обучались модели на фолдах и предсказания нескольких моделей усреднялись.
- Также пригодилась техника Frequency encoding. Суть такова: 2D-свертки инвариантны к позиции, а в спектрограммах значения по вертикальной оси имеют совсем разный физический смысл, поэтому мы бы хотели передать эту информацию в модель. Для этого мы конкатенировали спектрограмму и матрицу, состоящую из чисел в отрезке от -1 до 1 снизу вверх.
Для наглядности приведу код:n, d, h, w = x.size() vertical = torch.linspace(-1, 1, h).view(1, 1, -1, 1) vertical = vertical.repeat(n, 1, 1, w) x = torch.cat([x, vertical], dim=1) - Все это мы обучали в том числе и на псевдолейбленных данных из утекшей тестовой выборки первого этапа.
Валидация
С самого начала соревнования всех участников мучал вопрос: почему локальная валидация дает EER 0.01 и ниже, а лидерборд — 0.1 и не особо коррелирует? У нас было 2 гипотезы: либо в данных были дубликаты, либо тренировочные данные были собраны на одном множестве спикеров, а тестовые — на другом.
Истина оказалась где-то посередине. В тренировочных данных примерно 5% данных оказались дубликатами, и это считая только полные дубликаты по хэшам (кстати, там также могли содержаться разные кропы одного и того же файла, но это не так просто проверить — поэтому мы и не стали).
Для проверки второй гипотезы мы обучили speaker-id сетку, получили эмбеддинги на каждого спикера, кластеризовали это все k-means’ом и по этим кластерам стратифицировали фолды. А именно, мы обучались на спикерах из одних кластеров, а предсказывали спикеров из других. Такой метод валидации уже начал коррелировать с лидербордом, хотя и показывал score в 3-4 раза лучше. В качестве альтернативы мы пробовали валидироваться только на предсказаниях, в которых модель была хоть немного не уверена, то есть разница между предсказанием и меткой класса составляла >10**-4 (0.0001), но такая схема не принесла результатов.
А что не заработало?
В интернете достаточно просто найти тысячи часов человеческой речи. Кроме того, подобный конкурс уже проводился несколько лет назад. Поэтому очевидной идеей казалось скачать много-много данных (мы скачали ~300 Гбайт) и пообучать на этом классификатор. В отдельных случаях обучение на таких данных немного докидывало, если мы учили на дополнительных и на трейновых данных до выхода на плато, а потом дообучали только на тренировочных. Но при такой схеме модель сходилась примерно за 2 дня, что означало 10 дней на все фолды. Поэтому мы от этой идеи отказались.
Кроме того, многие участники заметили корреляцию длины файла и класса, на тестовой выборке этой корреляции замечено не было. Не очень хорошо себя проявили обычные картиночные сетки типа resnext, nasnet-mobile, mobileNetV3.
Послесловие
Было непросто и местами странно, но все же мы получили крутой опыт и вышли на первое место. Методом проб и ошибок я понял, какие подходы вполне рабочие, а какие — не очень. Теперь буду использовать эти инсайты у нас при обработке звука. Я много работаю над тем, чтобы вывести разговорный ИИ на уровень, неотличимый от человеческого, и поэтому всегда в поиске интересных задач и фишек. Надеюсь, вы тоже узнали что-то новое.
Ну и наконец выкладываю наш код.