
Продолжу неспешный разбор реализации базовых типов в CPython, ранее были рассмотрены словари и целые числа. Тем, кто думает, что в их реализации не может быть ничего интересного и хитрого, рекомендуется приобщиться к данным статьям. Те, же, кто уже их прочёл, знают, что CPython хранит в себе множество интересностей и особенностей реализации. Их может быть полезно знать при написании своих скриптов, так и в качестве пособия по архитектурным и алгоритмическим решениям. Не являются исключением здесь и строки.
Начнём с небольшого экскурса в историю. Python появился в 1990-91 годах. Изначально при разработке базовой кодировкой в python была однобайтовая, старая добрая ascii. Но, примерно в то же время (чуть позже), человечеству надоело разбираться с «зоопарком» кодировок и в 1991 году был предложен стандарт юникод. Однако с первого раза тоже не получилось. Началось внедрение двухбайтных кодировок, но довольно скоро стало понятно, что двух байт на всех не хватит, была предложена 4-байтная кодировка. К сожалению, выделение по 4 байта на каждый символ выглядело напрасной тратой дискового места и памяти, особенно, в тех странах, где раньше вполне хватало однобайтовой ascii. Было запилено несколько костылей в 2-байтную кодировку, чтобы поддерживать больше символов, и всё это стало напоминать предыдущую ситуацию с «зоопарком» кодировок.
Но в 1993 году был представлен utf-8. Который являлся компромиссом: ascii была валидным подмножеством utf-8, все остальные символы, его расширяли, однако, для поддержки такой возможности, пришлось расстаться с фиксированной длиной каждого символа. Но именно ему суждено былоправить всеми стать именно юникодом, то есть единой кодировкой, поддерживаемой большинством программ, в которой хранится большинство файлов. Особенно на это повлияло развитие интернета, так как web-странички обычно использовали именно utf-8.
Поддержка этой кодировки постепенно внедрялась в языки программирования, которые, как и python, были разработаны раньше utf-8, а потому использовали другие кодировки. Существует PEP с красивым номером 100, в котором обсуждалась поддержка юникода. А в PEP-0263 появилась возможность объявлять кодировку исходных файлов. Базовой кодировкой всё ещё оставалась ascii, для объявления юникодных строк использовался префикс `u`, работа с ними всё ещё не была достаточно удобной и естественной. Зато появилась возможность творить следующую ересь:
3 декабря 2008 года произошло историческое событие для всего python-сообщества (а учитывая, как широко этот язык распространился сейчас, то, пожалуй, и для всего мира) — вышел python 3. В нём было решено раз и навсегда покончить с проблемами из-за множества кодировок, а потому базовой кодировкой стал юникод. Но мы же помним, что кодировки это сложно и с первого раза не выходит. Не получилось и в этот раз.
Большим недостатком utf-8 является то, что длина символа не фиксированна, это приводит к тому, что такая простая операция, как обращение по индексу имеет сложность O(N), так как смещение элемента не известно заранее, кроме того, зная размер буфера, выделенного под хранение строки, нельзя вычислить её длину в символах.
Во избежание всех этих проблем в python было решено использовать 2-ух и 4-байтные кодировки (в зависимости от платформы). Обращение по индексу упростилось — необходимо было лишь умножить индекс на 2 или 4. Однако, это повлекло свои проблемы:
Решение этих проблем было предложено в PEP-393, о нём и поговорим.
Было решено оставить строки как массив символов, для облегчения доступа по индексу и других операций, однако длина символов стала варьироваться. При создании строки, интерпретатор сканирует все символы и выделяет для каждого количество байт, которое необходимо для хранения самого «большого», то есть, если вы объявите ascii-строку, то все символы будут однобайтовыми, однако, если вы решите добавить к строке один знак из кириллицы, все символы уже будут двух-байтными. Всего возможны три варианта: 1, 2 и 4 байта на символ.
Строковый тип (PyUnicodeObject) объявлен следующим образом:
В свою очередь PyCompactUnicodeObject представляет собой следующую структуру (приводится с некоторыми упрощениями и моими комментариями):
Таким образом возможны 4 представления строк:
Следует обратить внимание, что python 3 так же поддерживает синтаксис объявления юникодных строк через префикс `u`.
Эта возможность была добавлена для облегчения портирования кода со второй версии на третью в PEP-414 в python 3.3 только в феврале 2012 года, напомню, что python 3 вышел в декабре 2008, да никто не спешил с переходом.
Вооружившись этим знанием и стандартным модулем ctypes, мы можем получить доступ к внутренним полям строки.
И даже «сломать» интерпретатор, как сделали это в предыдущей части.
DISCLAIMER: Следующий код поставляется as is, автор не несёт никакой ответственности и не может гарантировать состояние интерпретатора, а также душевное здоровье вас и ваших коллег, после запуска этого кода. Код протестирован на версии cpython 3.7 и, к сожалению, не работает с ascii строками.
Для этого надо изменить код, описанный вверху, на:
В данных примерах используется интерполяция строк, добавленная в python 3.6. Python далеко не сразу пришёл к данному способу вывода строк: были испробованны %-синтаксис, format, что-то perl подобное (более подробное описание с примерами можно найти здесь).
Пожалуй это изменение для своего времени (до python 3.8 с его `:=` оператором) было самым противоречивым. Обсуждение (и осуждение) велось как на reddit и даже в виде PEP. Высказывались идеи улучшения/исправления в виде добавления i-строк, для которых пользователи смогли бы писать свои парсеры, для лучшего контроля и во избежание SQL-инъекций и прочих проблем. Однако данное изменение было отложено, для того, чтобы люди привыкли к f-строкам и выявили проблемы, если они есть.
У f-строк, есть одна особенность(недостаток): в них нельзя указывать спец символы со слэшами, например, '\n' '\t'. Однако, это легко обойти, объявив отдельную строку, содержащую спец-символы и передав её в f-строку, что и было проделано в примере выше, зато можно использовать вложенные скобки.
Как вы могли заметить, строки хранят свой хэш, было предложение использовать это значение для сравнения строк, исходя из простого правила: если строки одинаковы — то у них одинаков и хэш, а из этого следует, что строки с разным хэшем не одинаковы. Однако оно осталось не реализованным.
При сравнении двух строк проверяется, ссылаются ли указатели на строки на один адрес, если нет — то запускается посимвольное сравнение или memcmp в случаях, когда это допустимо.
Однако, косвенным образом значение хэша влияет на сравнение. Дело в том, что в cpython строки интернируются, то есть хранятся в одном словаре. Это верно не для всех строк, интернируются все константы, ключи словарей, поля и переменные и ascii строки длиной меньше 20.
А пустая строка вообще синглтон
Как мы видим, cpython смог создать простую, но в то же время, эффективную реализацию строкового типа. Удалось сократить используемую память и ускорить операции в некоторых случаях, благодаря функциям memcmp, memcpy, вместо посимвольных операций. Как видим строковый тип совсем не так прост в реализации, как может показаться с первого раза. Но разработчики cpython достаточно умело подошли к своему делу и поэтому мы можем им пользоваться и даже не задумываться, что там «под капотом».
Начнём с небольшого экскурса в историю. Python появился в 1990-91 годах. Изначально при разработке базовой кодировкой в python была однобайтовая, старая добрая ascii. Но, примерно в то же время (чуть позже), человечеству надоело разбираться с «зоопарком» кодировок и в 1991 году был предложен стандарт юникод. Однако с первого раза тоже не получилось. Началось внедрение двухбайтных кодировок, но довольно скоро стало понятно, что двух байт на всех не хватит, была предложена 4-байтная кодировка. К сожалению, выделение по 4 байта на каждый символ выглядело напрасной тратой дискового места и памяти, особенно, в тех странах, где раньше вполне хватало однобайтовой ascii. Было запилено несколько костылей в 2-байтную кодировку, чтобы поддерживать больше символов, и всё это стало напоминать предыдущую ситуацию с «зоопарком» кодировок.
Но в 1993 году был представлен utf-8. Который являлся компромиссом: ascii была валидным подмножеством utf-8, все остальные символы, его расширяли, однако, для поддержки такой возможности, пришлось расстаться с фиксированной длиной каждого символа. Но именно ему суждено было
Поддержка этой кодировки постепенно внедрялась в языки программирования, которые, как и python, были разработаны раньше utf-8, а потому использовали другие кодировки. Существует PEP с красивым номером 100, в котором обсуждалась поддержка юникода. А в PEP-0263 появилась возможность объявлять кодировку исходных файлов. Базовой кодировкой всё ещё оставалась ascii, для объявления юникодных строк использовался префикс `u`, работа с ними всё ещё не была достаточно удобной и естественной. Зато появилась возможность творить следующую ересь:
class ???:
моя_переменная = 2
? = ???()
print(?)
3 декабря 2008 года произошло историческое событие для всего python-сообщества (а учитывая, как широко этот язык распространился сейчас, то, пожалуй, и для всего мира) — вышел python 3. В нём было решено раз и навсегда покончить с проблемами из-за множества кодировок, а потому базовой кодировкой стал юникод. Но мы же помним, что кодировки это сложно и с первого раза не выходит. Не получилось и в этот раз.
Большим недостатком utf-8 является то, что длина символа не фиксированна, это приводит к тому, что такая простая операция, как обращение по индексу имеет сложность O(N), так как смещение элемента не известно заранее, кроме того, зная размер буфера, выделенного под хранение строки, нельзя вычислить её длину в символах.
Во избежание всех этих проблем в python было решено использовать 2-ух и 4-байтные кодировки (в зависимости от платформы). Обращение по индексу упростилось — необходимо было лишь умножить индекс на 2 или 4. Однако, это повлекло свои проблемы:
- На каждой платформе была своя кодировка, что могло повлечь проблемы с переносимостью кода
- Повышенный расход памяти и/или проблемы с кодированием хитрых символов, не влезающих в два байта
Решение этих проблем было предложено в PEP-393, о нём и поговорим.
Было решено оставить строки как массив символов, для облегчения доступа по индексу и других операций, однако длина символов стала варьироваться. При создании строки, интерпретатор сканирует все символы и выделяет для каждого количество байт, которое необходимо для хранения самого «большого», то есть, если вы объявите ascii-строку, то все символы будут однобайтовыми, однако, если вы решите добавить к строке один знак из кириллицы, все символы уже будут двух-байтными. Всего возможны три варианта: 1, 2 и 4 байта на символ.
Строковый тип (PyUnicodeObject) объявлен следующим образом:
/* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
В свою очередь PyCompactUnicodeObject представляет собой следующую структуру (приводится с некоторыми упрощениями и моими комментариями):
/* Структура для не ascii строк */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* количество байт под utf-8 буфер (без учёта
\0 терминатора)*/
char *utf8; /* UTF-8 представление (с \0 терминатором)*/
Py_ssize_t wstr_length; /* Количество code point в wstr. */
} PyCompactUnicodeObject;
/* Структура для ascii строк */
typedef struct {
PyObject_HEAD /* стандартный заголовок (указатель на тип и счётчик ссылок) */
Py_ssize_t length; /* количество code point в строке */
Py_hash_t hash; /* Хэш или -1, если хэш ещё не установлен */
struct {
/*
SSTATE_NOT_INTERNED (0)
SSTATE_INTERNED_MORTAL (1)
SSTATE_INTERNED_IMMORTAL (2)
*/
unsigned int interned:2;
/* Размер символа:
- PyUnicode_WCHAR_KIND (0):
* wchar_t (16 или 32 бита, в зависимости от платформы (старый формат))
- PyUnicode_1BYTE_KIND (1):
- PyUnicode_2BYTE_KIND (2):
- PyUnicode_4BYTE_KIND (4):
*/
unsigned int kind:3;
/* Флаг компактной формы
(если установлен, то вся структура лежит в обном блоке памяти,
если сброшен - то data лежит в другом). */
unsigned int compact:1;
/* Строка содержит только символы из диапазона U+0000-U+007F (ASCII) */
unsigned int ascii:1;
/* установлен, если структура полностью инициализирована,
использовался в старых реализациях */
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t представление ( с \0 терминатором) */
} PyASCIIObject;
Таким образом возможны 4 представления строк:
- legacy string, ready
* structure = PyUnicodeObject structure * Проверка на тип: !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 разделяется с data.any и utf8_length = length если ascii = 1 * utf8_length = 0 если utf8 is NULL * wstr разделяется с with data.any и wstr_length = length если kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 если wstr is NULL - legacy string, not ready
* structure = PyUnicodeObject * Проверка на тип: kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0 - compact ascii
* structure = PyASCIIObject * Проверка на тип: PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — длина utf8 и wstr строк) * (data располагается сразу за структурой) * (так как ascii является подмножеством поле utf8 string и есть data) - compact
* structure = PyCompactUnicodeObject * Проверка на тип: PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 и data различны * utf8_length = 0 если utf8 is NULL * wstr разделяется с data и wstr_length=length если kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 есди wstr is NULL * (data располагается сразу за структурой)
Следует обратить внимание, что python 3 так же поддерживает синтаксис объявления юникодных строк через префикс `u`.
>>> b = u"тут"
>>> b
'тут'
Эта возможность была добавлена для облегчения портирования кода со второй версии на третью в PEP-414 в python 3.3 только в феврале 2012 года, напомню, что python 3 вышел в декабре 2008, да никто не спешил с переходом.
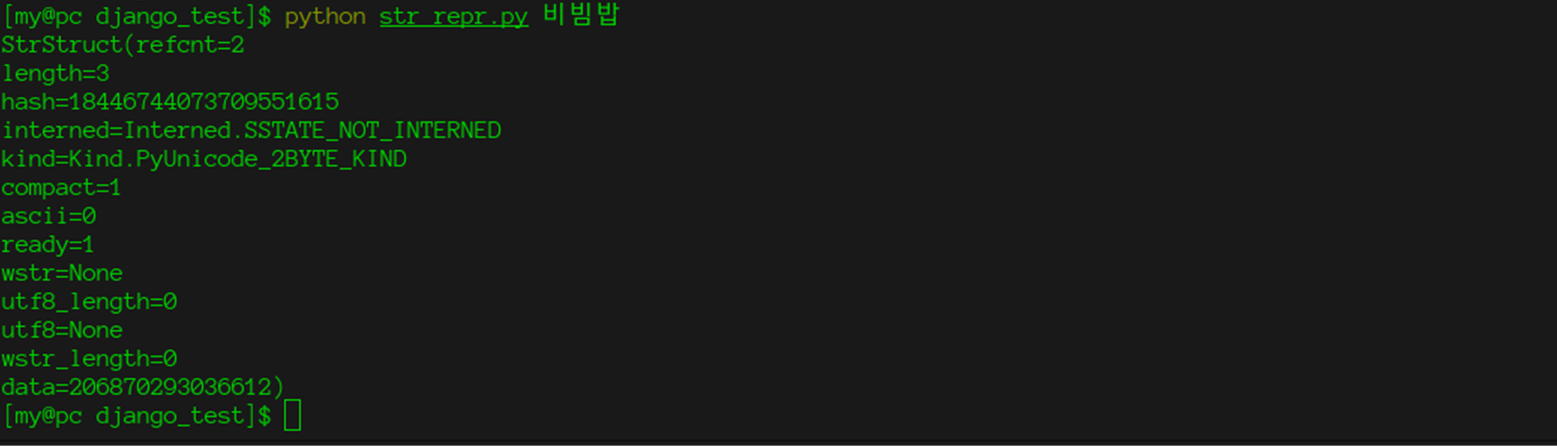
Вооружившись этим знанием и стандартным модулем ctypes, мы можем получить доступ к внутренним полям строки.
import ctypes
import enum
import sys
class Interned(enum.Enum):
# SSTATE_NOT_INTERNED (0)
# SSTATE_INTERNED_MORTAL (1)
# SSTATE_INTERNED_IMMORTAL (2)
# If interned != SSTATE_NOT_INTERNED, the two references from the
# dictionary to this object are *not* counted in ob_refcnt.
SSTATE_NOT_INTERNED = 0
SSTATE_INTERNED_MORTAL = 1
SSTATE_INTERNED_IMMORTAL = 2
class Kind(enum.Enum):
PyUnicode_WCHAR_KIND = 0
PyUnicode_1BYTE_KIND = 1
PyUnicode_2BYTE_KIND = 2
PyUnicode_4BYTE_KIND = 4
# PyUnicodeObject
class StrStruct(ctypes.Structure):
_fields_ = [("refcnt", ctypes.c_long),
("type", ctypes.c_void_p),
("length", ctypes.c_long),
("hash", ctypes.c_void_p), # ascii fields
("_interned", ctypes.c_uint, 2),
("_kind", ctypes.c_uint, 3),
("compact", ctypes.c_uint, 1),
("ascii", ctypes.c_uint, 1),
("ready", ctypes.c_uint, 1),
("_rest_state", ctypes.c_uint, 16), # for future use
("wstr", ctypes.c_wchar_p),
# PyCompactUnicodeObject
("utf8_length", ctypes.c_ssize_t), # Number of bytes in utf8, excluding the terminating \0.
("utf8", ctypes.c_char_p),
("wstr_length", ctypes.c_ssize_t), # Number of code points
("data", ctypes.c_void_p) # canonical, smallest-form Unicode buffer
]
_printable_fields = ("refcnt", "length", "hash", "interned", "kind", "compact", "ascii", "ready", "wstr",
"utf8_length", "utf8", "wstr_length", "data")
@property
def interned(self):
return Interned(self._interned)
@property
def kind(self):
return Kind(self._kind)
def __repr__(self):
new_line = '\n' # f-string expression part cannot include a backslash
return f"StrStruct({new_line.join(f'{key}={getattr(self, key)}' for key in self._printable_fields)})"
if __name__ == '__main__':
string = sys.argv[1]
s = StrStruct.from_address(id(string))
print(s)
И даже «сломать» интерпретатор, как сделали это в предыдущей части.
DISCLAIMER: Следующий код поставляется as is, автор не несёт никакой ответственности и не может гарантировать состояние интерпретатора, а также душевное здоровье вас и ваших коллег, после запуска этого кода. Код протестирован на версии cpython 3.7 и, к сожалению, не работает с ascii строками.
Для этого надо изменить код, описанный вверху, на:
def make_some_magic(str1, str2):
s1 = StrStruct.from_address(id(str1))
s2 = StrStruct.from_address(id(str2))
s2.data = s1.data
if __name__ == '__main__':
string = "???"
string2 = "hac"
print(string == string2) # False
make_some_magic(string, string2)
print(string == string2) # True
В данных примерах используется интерполяция строк, добавленная в python 3.6. Python далеко не сразу пришёл к данному способу вывода строк: были испробованны %-синтаксис, format, что-то perl подобное (более подробное описание с примерами можно найти здесь).
Пожалуй это изменение для своего времени (до python 3.8 с его `:=` оператором) было самым противоречивым. Обсуждение (и осуждение) велось как на reddit и даже в виде PEP. Высказывались идеи улучшения/исправления в виде добавления i-строк, для которых пользователи смогли бы писать свои парсеры, для лучшего контроля и во избежание SQL-инъекций и прочих проблем. Однако данное изменение было отложено, для того, чтобы люди привыкли к f-строкам и выявили проблемы, если они есть.
У f-строк, есть одна особенность(недостаток): в них нельзя указывать спец символы со слэшами, например, '\n' '\t'. Однако, это легко обойти, объявив отдельную строку, содержащую спец-символы и передав её в f-строку, что и было проделано в примере выше, зато можно использовать вложенные скобки.
>>> number = 2
>>> precision = 3
>>> f"{number:.{precision}f}"
2.000
# впрочем, format тоже позволяет такие приёмы
>>> "{:{}f}".format(number, precision)
2.000
Как вы могли заметить, строки хранят свой хэш, было предложение использовать это значение для сравнения строк, исходя из простого правила: если строки одинаковы — то у них одинаков и хэш, а из этого следует, что строки с разным хэшем не одинаковы. Однако оно осталось не реализованным.
При сравнении двух строк проверяется, ссылаются ли указатели на строки на один адрес, если нет — то запускается посимвольное сравнение или memcmp в случаях, когда это допустимо.
int
PyUnicode_Compare(PyObject *left, PyObject *right)
{
if (PyUnicode_Check(left) && PyUnicode_Check(right)) {
if (PyUnicode_READY(left) == -1 ||
PyUnicode_READY(right) == -1)
return -1;
/* переданы две идентичные строки */
if (left == right)
return 0;
return unicode_compare(left, right); // посимвольное сравнение или memcmp
}
Генерация ошибки
}Однако, косвенным образом значение хэша влияет на сравнение. Дело в том, что в cpython строки интернируются, то есть хранятся в одном словаре. Это верно не для всех строк, интернируются все константы, ключи словарей, поля и переменные и ascii строки длиной меньше 20.
if __name__ == '__main__':
string = sys.argv[1]
string2 = sys.argv[2]
print(id(string) == id(string2))
$ python check_interned.py a a
True
$ python check_interned.py ??? ???
False
$ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa
False
А пустая строка вообще синглтон
static PyUnicodeObject *
_PyUnicode_New(Py_ssize_t length)
{
PyUnicodeObject *unicode;
size_t new_size;
/* Optimization for empty strings */
if (length == 0 && unicode_empty != NULL) {
Py_INCREF(unicode_empty);
return (PyUnicodeObject*)unicode_empty;
}
...
}
Как мы видим, cpython смог создать простую, но в то же время, эффективную реализацию строкового типа. Удалось сократить используемую память и ускорить операции в некоторых случаях, благодаря функциям memcmp, memcpy, вместо посимвольных операций. Как видим строковый тип совсем не так прост в реализации, как может показаться с первого раза. Но разработчики cpython достаточно умело подошли к своему делу и поэтому мы можем им пользоваться и даже не задумываться, что там «под капотом».
Комментарии (12)

khim
29.12.2019 21:11-1Как мы видим, cpython смог создать простую, но в то же время, эффективную реализацию строкового типа.
Это сарказм такой? Не знаю насчёт скорости, но наворотов тут даже больше, чем в C++std::string, который тоже считается сложным (ради эффективности, понятно).LinearLeopard Автор
29.12.2019 21:30+2Ждём от Вас статьи про std::string. Я не в курсе, слышал только про 2 реализации всех строковых алгоритмов в java: для ascii и для не ascii строк и флаг, указывающий на тип.
Ну и самое простое — это хранить массив из 4 байт на каждый символ. Вот только эффективно ли это?
В cpython удалось добиться не большого расхода памяти, при этом скрыть особенности реализации от пользователя, благодаря чему он может, например, обращаться по индексу, в отличие от Rust или Julia.
А так ли важно, сколько там наворотов, если абстрация не течёт? :)khim
30.12.2019 00:11-1А так ли важно, сколько там наворотов, если абстрация не течёт? :)
Ну абстракция всё равно течёт, конечно. Они почти все текут. Да собственно вашcheck_internedэто показывает (там, кстати, можно писать неid(string) == id(string2), по-простому:string is strings… что, кстати, показывает как протечка в этой абстракции может вас «укусить» в реальной программе).
Но самая большая проблема со строками в Python3 — это то, что все эти навороты решают непонятно какую проблему, но понятно какую проблему они не решают: работу с реальными данными.
Потому что вся работа со строками в Python3 построена вокруг двух предположений:
1. Строки (текст) и бинарные данные строго отделены друг от друга.
2. Во всех случаях когда мы работаем со строками мы всегда заранее знаем кодировку.
Поскольку в реальном мире оба этих предположения неверны, то строки в Python — это боль и содомия. Чего одна история с path-like объектами стоит!
А в C++ строки не так интересны — хотя там они считаются сложными они на порядок меньше вот всего того, что тут навернули. Первый бит указывает на то короткая строка или длинная, оставшееся интерпретируется в зависимости от этого — собственно и всё.LinearLeopard Автор
30.12.2019 09:57Потому что вся работа со строками в Python3 построена вокруг двух предположений:
1. Строки (текст) и бинарные данные строго отделены друг от друга.
2. Во всех случаях когда мы работаем со строками мы всегда заранее знаем кодировку.
Поскольку в реальном мире оба этих предположения неверны, то строки в Python — это боль и содомия. Чего одна история с path-like объектами стоит!
Что для вас отстоят отдельно? Разные типы? Ну это логично, строки — частный случай бинарных данных, вполне можно навесить дополнительных проверок и операций, чтобы облегчить работу программисту. Как я уже упоминал, в некоторых языках даже индексирование не возможно.
Насчёт кодировок — константы всегда приходят из исходника с известной кодировкой, при чтении файлов, её тоже можно указать. Если он не известна то, что вы предлагаете делать?khim
30.12.2019 23:07Ну это логично, строки — частный случай бинарных данных, вполне можно навесить дополнительных проверок и операций, чтобы облегчить работу программисту.
Это у нормальных людей строки — это частный случай бинарных данных. В python3 — нет. Отсюда, собственно, появление path-like объектов: поскольку имя файлов (на на Linux, ни на Windows) не обязано быть валидной UTF-8 или UTF-16 строкой, то можно было легко создать файл, который в ранних версиях python-3 нельзя в принципе никак открыть.
То же самое с HTTP-серверами и с массой других протоколов. Ситуация, когда вперемешлу «в потоке байт» идут строки и «сырые» данные — исключением совершенно не является. Ситуация, когда вы вначале должны распарсить строку, а потом — узнаёте в какой она кодировки… тоже типична.
Всё это решается в Python3 втыканием всё большего и большего числа костылей в разные места (начиная с Python 3.5 поддерживается%, может со временем иformatдобавят).
Как я уже упоминал, в некоторых языках даже индексирование не возможно.
А в python возможно? Да неужели?
>>> 'Хуи?ня'[4] 'н' >>> 'Хуйня'[4] 'я'
Это, по вашему, нормальная индексация?
Я вообще не знаю ни одного практически полезного алгоритма, для которого такая индексация годилась бы, а побайтовая индексация UTF-8 текста — не годилась бы.
Но за эту блажь платится усложнением реализации, замедлением и усложнением языка. Впрочем это всё в духе Python, так что, в принципе, неудивительно.
Python3 по сравнению с Python2 — это как C++ по сравнению с C: выстрелить в ногу слегка сложнее, но всё равно не очень сложно, а разрушений — намного больше.
Насчёт кодировок — константы всегда приходят из исходника с известной кодировкой, при чтении файлов, её тоже можно указать. Если он не известна то, что вы предлагаете делать?
Работать с данными как с последовательностью байт. А кодировку использовать там и тогда, когда это реально нужно.
Какой процент строк из вашей программы у вас отображается на экране? Зачем засорять работу с теми из них (а это, в типичном случае 90%, а во многих программах и 99%) сущностью, которая вам не нужна?LinearLeopard Автор
30.12.2019 23:45Я не понимаю ваших претензий.
Это у нормальных людей строки — это частный случай бинарных данных. В python3 — нет.
Давайте не переходить на уровень «настоящих шотландцев». Что вы подразумеваете, под тем, что в python3 строки не бинарные данные?
А в python возможно? Да неужели?
>>> 'Хуи?ня'[4]
'н'
>>> 'Хуйня'[4]
'я'
У вас в первом случае должна быть [3]? Ну выглядит как логичное и ожидаемое поведение, строка — последовательность символов, индексируясь по ней — получаем символы. Ещё раз есть языки, в которых на такой операции вы получите ошибку компиляции, это лучше?
Я вообще не знаю ни одного практически полезного алгоритма, для которого такая индексация годилась бы, а побайтовая индексация UTF-8 текста — не годилась бы.
1. encode вам в помощь.
2. ну и не работайте в таком случае не с python, зачем грызть кактус?) Есть C, который гораздо лучше подходит под обработку бинарных данных, python вообще не про это.
Но за эту блажь платится усложнением реализации, замедлением и усложнением языка. Впрочем это всё в духе Python, так что, в принципе, неудивительно.
Критикуешь — предлагай. Как вы посоветуете переписать реализацию? Можно хоть в виде PEP на оф. сайте. Всё сообщество будет вам благодарно.
Python3 по сравнению с Python2 — это как C++ по сравнению с C: выстрелить в ногу слегка сложнее, но всё равно не очень сложно, а разрушений — намного больше.
Всё смешалось, кони-люди. В C++ выстрелить в ногу сложнее или в C? Какие разрушения вы получите в случае с python? Я пытался, я менял служебные поля в рантайме, в большинстве случаев получал падение интерпретатора, никуда буферы не текли, стеки не переполнялись, произвольный код не выполнялся. Хотя достичь этого можно, но надо прям специально постараться, это не выстрел в ногу — это осознанный суицид.
Работать с данными как с последовательностью байт. А кодировку использовать там и тогда, когда это реально нужно.
Так используйте) Кто вам не разрешает?
Какой процент строк из вашей программы у вас отображается на экране? Зачем засорять работу с теми из них (а это, в типичном случае 90%, а во многих программах и 99%) сущностью, которая вам не нужна?
Вот здесь вообще не понял.khim
01.01.2020 20:43Что вы подразумеваете, под тем, что в python3 строки не бинарные данные?
То, что в них нельзя засунуть произвольную последовательность байт, очевидно. Например вы не можете имя файлы (которое в Windows не обязано быть валидной UTF-16 последовательностью, а в Linux валидной UTF-8 последовательностью) поместить в строку и проверить — не начинается оно с нужного вам префикса.
Ещё раз есть языки, в которых на такой операции вы получите ошибку компиляции, это лучше?
Лучше конечно. Отсуствие идиотского поведения всегда лучше его наличия. Хорошее поведение — ещё лучше, конечно, вот только при работе со строками его нет. В принципе нет — и всё.
Ну выглядит как логичное и ожидаемое поведение, строка — последовательность символов, индексируясь по ней — получаем символы.
Ну и кому и зачем это может быть нужно? Зачем оптимизировать работу под операции которые никогда не используются (или используются исключительно редко) за счёт операций, которые используются часто?
Есть C, который гораздо лучше подходит под обработку бинарных данных, python вообще не про это.
А про что он вообще тогда?
Как вы посоветуете переписать реализацию?
Никак — ошибка же в дизайне. Остаётся только смириться. Ну вот такой вот бессмысленный высер, который обошёлся индустрии в миллиарды и не дал никакой прибыли. Конструктивно — нужно убрать человека, который его затеял, чтобы больше такого не повторялось.
Это, впрочем, уже сделано, так что ничего менять уже не нужно.
В C++ выстрелить в ногу сложнее или в C?
В C++ сложнее наделать проблем гораздо сложнее, но если уж это удалось сделать — то разрушений намного больше.
То же самое с Python2 строками vs Python3 строками. Python2 позволяет легко сделать что-то не совсем правильно — но это быстро обваливается и легко чинится. В Python3 любое простое решение «правильно на 99.9%», но вот оставшийся 0.1% — исправить, зачастую, возможно только полными переписываением всей программы. Что дорого и сложно.
Так используйте) Кто вам не разрешает?
Python3. Масса операций, имеющих полный смысл для последовательностей байт — не работает с бинарными строками. А строковые операции не принимают произвольные последовательности байт. В Python2 — проблем не было.
Простейший пример, которым я всегда тыкаю в нос — простенький файл для работы со словариком и там буквально пяток функций для каждого языка. Которые просто возвращают список гласных, список согласных и так далее. Для английского, немецкого, польського и русского (там ещё что-то было — но эти ключевые). Функции, работающие с немецким рассчитаны на Latin-1, на польский — на Latin-2, Руссики — windows-1251… ну и комментарии в UTF-8 для удобства.
Всё это, ещё раз повторяю, в одном файле. Инструменты старого образца (Emacs, Far или тот же Python2) — вообще не проблема. Говорим, что это последовательность байт и всё. Что-то сделать в Python3… практически невоможно.
Ну потому что этот текстовый файл в Python3 строку — не лезет. Ну никак.
1. encode вам в помощь.
С этого момента — поподробнее: как его применять для редактирования подобного файла?
unishift
У меня всегда работали. Проверил сейчас на python 3.8. Следующий код выводит и перевод строки, и табуляцию.
LinearLeopard Автор
Действительно, так работает, но вот в фигурных скобках, указывать нельзя:
unishift
Спасибо за уточнение. Буду знать
Не сталкивался с этим ограничением, т.к. обычно более-менее сложные конструкции выношу в отдельные переменные :)
LinearLeopard Автор
Я сам с удивлением узнал, впрочем, это действительно затрудняет парсинг и создаёт возможные уязвимости.
Вот здесь есть несколько примеров.