

В прошлых статьях мы разобрались, как создаются и обрабатываются торговые заявки. Темой сегодняшней статьи будут вопросы обработки и хранения информации, необходимой для графических инструментов анализа рынка – биржевых графиков.
Прежде чем начать, хочу сделать небольшое отступление. Для внутренних проектов Vonmo используется обычная схема именования V+слово, наиболее ёмко характеризующее функции проекта. Сегодня я обнаружил, что VTrade – уже существующая компания. Дабы не вносить путаницу, я переименовал эксперимент в VonmoTrade.
Чтобы оценить состояние рынка, одной книги ордеров и истории сделок недостаточно. Нужен инструмент, позволяющий наглядно и быстро выявить тренд рыночной цены. Торговые графики можно разделить на два типа:
- Линейные;
- Интервальные.
Линейные графики
Самый простой и понятный без подготовки график. Отображает зависимость цены финансового инструмента от времени.

Основное достоинство этого типа графиков – простота. Из него же вытекает основной недостаток – низкая информативность.
Если график строится на основе сырых данных, то берется цена последнего закрытия. Но обычно графики строят на основе агрегированных данных. В этом случае берется цена закрытия каждого интервала. Так как мы отбрасываем все, что происходило в интервале, и берем только цену закрытия интервала, из-за этого теряется информативность.
Разрешение графика
Если мы начнем строить график на основе всех изменений цены, т.е каждая закрытая сделка будет попадать на график, то человеку будет сложно его воспринимать. Да и мощности, затраченные на обработку и доставку такого графика, будут израсходованы неэффективно.
Поэтому данные прореживают, разбивая ось времени на интервалы и агрегируя цены в этих интервалах.
Разрешение – размер элементарного интервала разбиения оси времени: секунда, минута, час, день и так далее.
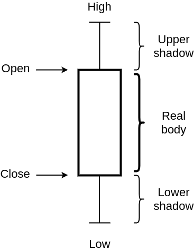
Бары
Относятся к интервальным графикам. Для повышения информативности, необходимо для каждого интервала времени отобразить информацию о цене в начале и конце интервала, а также максимальную и минимальную цену. Графическое отображение этого набора называется баром. Рассмотрим схему одного бара:

Последовательность баров формирует график:
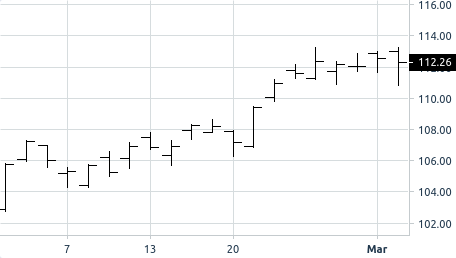
Японские свечи
Как и бары, относятся к интервальным графикам. Являются самым популярным типом графика при техническом анализе. Свеча состоит из чёрного либо белого тела и теней: верхней и нижней. Иногда тень называют фитилем. Верхняя и нижняя граница тени отображает максимум и минимум цены за соответствующий период. Границы тела отображают цену открытия и закрытия. Изобразим свечу:
Последовательность свеч образуют график:

OHLCV нотация
В прошлой статье мы разобрались со схемой хранения данных для графика в postgresql и создали таблицу для источника данных, которая будет хранить агрегированные данные:
CREATE TABLE df
(
t timestamp without time zone NOT NULL,
r df_resolution NOT NULL DEFAULT '1m'::df_resolution,
o numeric(64,32),
h numeric(64,32),
l numeric(64,32),
c numeric(64,32),
v numeric(64,32),
CONSTRAINT df_pk PRIMARY KEY (t, r)
)Поля не требуют объяснения, кроме поля r – разрешение ряда. В postgresql есть перечисления, ими удобно пользоваться, когда заранее известен набор значений для какого-то поля. Через перечисления определим новый тип для допустимых разрешений графиков. Пусть это будет ряд от одной минуты до одного месяца:
CREATE TYPE df_resolution AS ENUM
('1m', '3m', '5m', '15m', '30m', '45m',
'1h', '2h', '4h', '6h', '8h', '12h',
'1d', '3d', '1w', '1M');Важно найти баланс между производительностью дисковой системы, процессора и итоговой стоимостью владения. В системе на данный момент определены 16 резолюций. Очевидными являются два решения:
- Мы можем рассчитывать и хранить все резолюции в базе. Вариант удобен тем, что при выборке мы не тратим мощности на агрегацию интервалов, все данные сразу готовы к выдаче. В месяц для одного инструмента будет создано чуть более 72 тыс. записей. Выглядит просто и удобно, однако такая таблица будет слишком часто изменяться, так как на каждое обновление цен необходимо создать или обновить 16 записей в таблице и перестроить индекс. В postgresql дополнительно может возникнуть проблема со сборкой мусора.
- Другим вариантом является хранение единственной базовой резолюции. При выборке из базовой резолюции необходимо построить требуемые резолюции. Например, при хранении минутной резолюции в качестве базовой в месяц для каждого инструмента будет создано 43 тыс записей. Таким образом, по сравнению с прошлым вариантом, объем записи и накладных расходов уменьшается на 40%. Нагрузка на процессор, однако, возрастает.
Как говорилось выше, важно найти баланс. Поэтому компромиссным вариантом будет хранение не одной базовой резолюции, а нескольких: 1 минута, 1 час, 1 день. При такой схеме для каждого инструмента в месяц будет создано 44,6 тыс записей. Оптимизация объема записи составит 36%, но при этом нагрузка на процессор будет приемлемой. Например, для построения недельных интервалов вместо считывания и агрегации 10080 записей в случае минутной базовой резолюции, нам потребуется считать с диска и агрегировать данные всего 7-ми дневных резолюций.
Хранение OHLCV
По природе OHLCV – временной ряд. Как известно, реляционная база данных не очень хорошо подходит для хранения и обработки подобных данных. Для решения этих проблем в проекте используется расширение Timescale.
Timescale улучшает производительность операций вставки и обновления, позволяет настроить партиционирование, предоставляет оптимизированные специально для работы с временными рядами аналитические функции.
Для создания и обновления баров нам потребуются только стандартные функции:
date_trunc(‘minute’ | ’hour’ | ’day’, transaction_ts)– для нахождения начала интервала минутной, часовой и дневной резолюции соответственно.greatestиleastдля определения максимальной и минимальной цены.
Благодаря upsert api на каждую транзакцию выполняется только один запрос обновления.
У меня получился вот такой SQL для фиксации изменений рынка в базовых резолюциях:
FOR i IN 1 .. array_upper(storage_resolutions, 1)
LOOP
resolution = storage_resolutions[i];
IF resolution = '1m' THEN
SELECT DATE_TRUNC('minute', ts) INTO bar_start;
ELSIF resolution = '1h' THEN
SELECT DATE_TRUNC('hour', ts) INTO bar_start;
ELSIF resolution = '1d' THEN
SELECT DATE_TRUNC('day', ts) INTO bar_start;
END IF;
EXECUTE format(
'INSERT INTO %I (t,r,o,h,l,c,v)
VALUES (%L,%L,%L::numeric,%L::numeric,%L::numeric,%L::numeric,%L::numeric)
ON CONFLICT (t,r) DO UPDATE
SET h = GREATEST(%I.h, %L::numeric), l = LEAST(%I.l, %L::numeric), c = %L::numeric, v = %I.v + %L::numeric;',
df_table, bar_start, resolution, price, price, price, price, volume,
df_table, price, df_table, price, price, df_table, volume
);
END LOOP;При выборке, для агрегации интервалов нам понадобятся следующие функции:
time_bucket– для разбиения на интервалыfirst– для нахождения цены открытия –Omax– наибольшая цена за интервал –Hmin– наименьшая цена за интервал –Llast– для нахождения цены закрытия –Csum– для нахождения объема торгов –V
Единственная найденная проблема при использовании Timescale – ограничения функции time_bucket. Она позволяет оперировать только интервалами меньшими чем месяц. Для построения месячной резолюции необходимо использовать стандартную функцию date_trunc.
API
Для отображения графиков на клиенте будем использовать lightweight-charts от Tradingview. Библиотека позволяет полностью настроить внешний вид графиков и удобна в работе. У меня получились вот такие графики:

Поскольку основная часть взаимодействия между браузером и платформой осуществляется через websocket, то проблем с интерактивностью не возникает.
Источник данных
Источник данных для графиков (датафид) должен возвращать необходимую часть временного ряда в требуемой резолюции. При этом для экономии трафика и уменьшения времени обработки на клиенте сервер должен упаковать точки.
API для датафида изначально нужно проектировать так, чтобы можно было запросить множество графиков в одном запросе и подписаться на их обновления. Это сократит количество команд и ответов в канале.
Рассмотрим пример запроса 50 последних минут для USDGBP, с автоматической подпиской на обновления графика:
{
"m":"market",
"c":"get_chart",
"v":{
"charts":[
{
"ticker":"USDGBP",
"resolution":"1h",
"from":0,
"cnt":50,
"send_updates":true
}
]
}
}Можно, конечно же, запрашивать диапазон дат (from, to), но так как интервал каждого бара известен, то декларативное API с указанием момента и количества бар мне кажется более удобным.
Датафид на этот запрос ответит подобным образом:
{
"m":"market",
"c":"chart",
"v":{
"bar_fields":[
"t","uts","o","h","l","c","v"
],
"items":[
{
"ticker":"USDGBP",
"resolution":"1h",
"bars":[
[
"2019-12-13 13:00:00",1576242000,"0.75236800",
"0.76926400","0.75236800","0.76926400","138.10000000"
],
....
]
}
]
}
}Поле bar_fields содержит информацию о позициях элементов. Дальнейшая оптимизация – вынести это поле в конфигурацию клиента, которую он получает от сервера при загрузке.
Таким образом, клиент получает необходимую часть исторических данных и строит начальное состояние графика. Если состояние меняется, ему приходит обновление, затрагивающее только последний бар.
{
"m":"market",
"c":"chart_tick",
"v":{
"ticker":"USDGBP",
"resolution":"1h",
"items":{
"v":"140.600",
"ut":1576242000,
"t":"2019-12-13T13:00:00",
"o":"0.752368",
"l":"0.752368",
"h":"0.770531",
"c":"0.770531"
}
}
}Предварительный итог
На протяжении цикла статей мы с вами разбирали теорию и практику построения биржи. Пришло время собирать систему воедино.
В следующей статье мы затронем вопросы разработки графических интерфейсов пользователя: служебный UI для управления платформой и UI для конечных потребителей. Также будет представлена демонстрационная версия Vonmo Trade.