
Чем особенно хорош Vim/Neovim? Тем, что твой инструментарий — это не только редактор (который сам по себе сильно расширяем плагинами и имеет богатый базовый функционал и очень гибок в области кастомизации), но и всё ваше рабочее окружение, со всем юникс-вейным прилагающимся инструментарием из gnu/coreutils и не только. Можно не уходя из редактора взять любую программу или интерпретатор ЯП и использовать его прямо в редакторе.
Предисловие
Этот пост писался на скорую руку для приватного круга лиц, но я решил что его вполне можно запостить и на Хабр. Для кого-то может стать вдохновением, кому-то поможет лучше понять филосовию Vim, а кто-то приметит для себя пару трюков. Сразу на всякий случай оговорюсь, что не следует ожидать, что я стану кому-то что-то доказывать в комментариях, например убеждать что вам нужно определённо бросить вашу разжиревшую IDE и начать пользоваться Vim-ом, мне это совершенно не интересно.
К делу
Вот к примеру возьмём такой кусок кода (из конфига Haskell проекта), список зависимостей пакета (пример в вакууме):
build-depends:
X11
, base
, directory
, extra
, GLFW-b
, safe
, aeson
, containers
, data-default
, text
, process
, time
, dbusЧто мы хотим?
- Отсортировать зависимости по алфавиту, по-возрастанию
- Отсортировать регистро-независимо (
X11иGLFW-bне должны уходить вверх над всем) - Восстановить запятые (
aesonуйдёт в самый вверх и у него уже не должно быть запятой слева, а вот уX11должна добавиться запятая слева) - Восстановить отступы (чтобы можно было и в другом конфиге с другим уровнем вложенности просто достать команду из истории и переиспользовать её, или вообще забиндить команду на хоткей в конфиге Vim-а)
Решение
В первую очередь выделим (визуальным выделением) список зависимостей кроме первой строки build-depends. Можно конечно просто нажать V (визуальный режим с построчным выделением) и через jk или стрелочками вверх-вниз выделить нужные строки. В своём случае я это делаю одним взмахом руки с помощью кастомного хоткея для визуального режима:
xn iz <esc>[zV]zНаходясь например в середине списка зависимостей я просто жму viz и уменя выделены все зависимости, т.к. выделен весь fold, который в свою очередь — текущий блок вложенности (т.к. foldmethod у меня задан как indent). Но можно и вручную набирать последовательно [zV]z без кастомного хоткея ([z прыгает в начало fold-а, а ]z в конец), но т.к. для меня такая операция часто-употребляемая, то я укоротил её до viz — тут нет модификаторов вроде шифта и прожимается на рефлексах в одно мгновение (наиболее близкий стандартный аналог — vip для выделения блока до ближайших пустых строк).
Далее жмётся : (двоеточие) для перехода в командный режим для выполнения команды относительно текущего визуального выделения. По сути обычный командный режим, но с дописанными сразу маркерами выделения, т.е. будет выглядеть как :'<,'> где '<,'> — это диапазон выделения, где '< — первая строка визуального выделения, а '> — последняя.
После нажимаем ! (восклицательный знак) на клавиатуре, это будет означать что всё, что идёт дальше — это shell/bash (в зависимости от настроек) команда. Будет выглядеть как :'<,'>!. На самом деле после выделения можно сразу нажать ! и получим тот же результат — :'<,'>!.
Данная операция перенаправит выделенные строки в STDIN команды и заменит выделенные строки на STDOUT выхлоп от этой команды. Для примера можно использовать команду sort, чисто для проверки, результат пока не тот, что нам нужен — '<,'>!sort и жмём Enter, получим:
build-depends:
, aeson
, base
, containers
, data-default
, dbus
, directory
, extra
, GLFW-b
, process
, safe
, text
, time
X11Способ с coreutils и вообще башем
Восстановим предыдущее выделение (можно нажать gv для восстановления последнего выделения) и нажмём ! и далее стрелку вверх — это восстановит из истории последнюю команду, таким образом нам не надо писать заново, просто достаём из истории предыдущую команду и изменяем её. Для более комфортного редактирования команды можно нажать Ctrl+f — это откроет доп. окно с нормальлным стандартным редактированием команды, со всеми возможностями Vim-а, кстати там будут видны и все предудщие команды из истории в качестве отдельных строк, которые также можно выбрать, отредактировать и выполнить.
Как тут правильно поступить — можно выдумать находу, мой же поинт такой: сначала удаляем запятые, сортируем без них (регистро-независимо), потом возвращаем запятые, кроме самой первой строки.
Сначала удаляем запятые (а у первой строки доп. отступ, чтобы у всех строк был одинаковый отступ) используя команду sed с регулярным выражением ([, ] — запятая или пробел, а затем ещё пробел, \(\w\) экранированные скобки для выделения блока для подстановки, чтобы он потом был доступен как \1, \w — первый буквенный символ, в замене мы востанавливаем буквенный символ подстановкой \1):
:'<,'>!sed 's/[, ] \(\w\)/\1/'Получим следующее:
build-depends:
X11
base
directory
extra
GLFW-b
safe
aeson
containers
data-default
text
process
time
dbusДалее пайпим (через символ | — это фича баша) в команду сортировки sort передавая ключ -f для регистро-нечувствительности:
:'<,'>!sed 's/[, ] \(\w\)/\1/' | sort -fПолучаем:
build-depends:
aeson
base
containers
data-default
dbus
directory
extra
GLFW-b
process
safe
text
time
X11Почти готово! Осталось только добавить запятые, а первой строке — пару пробелов. Воспользуемся всё тем же sed, в синтаксисе его операций можно указывать строки и диапазоны строк (как и в самом Vim-е, синтаксис такой же, ну или почти такой же). Префикс 1 будет означать первую строку, 2,$ означает диапазон со 2-ой строки и до конца ($, как и ^ означает начало файла, по аналогии с такими же символами в регулярных выражениях, которые означают конец и начало строки). Будем использовать \w чтобы скипнуть отступ и сразу выделить первый буквенный символ: 1s/\w/ &/ — тут мы делаем замену для первой строки, восстанавливаем первый буквенный символ через & (по аналогии с \1, только & означает всё, что попало под регулярку целиком, в то время как \1 означает первый блок, завёрнутый в круглые экранированные скобки), добавив перед ним пару пробелов. Для остальных строк вместо двух пробелов добавим запятую + пробел следом: 2,$s/\w/, &/, целиком команда будет такой: sed -e '1s/\w/ &/' -e '2,$s/\w/, &/', — -e мы используем чтобы отделить 2 операции друг от друга. В Vim вся операция целиком будет выглядеть как:
:'<,'>!sed 's/[, ] \([^, ]\)/\1/' | sort -f | sed -e '1s/\w/ &/' -e '2,$s/\w/, &/'Применяем и получаем:
build-depends:
aeson
, base
, containers
, data-default
, dbus
, directory
, extra
, GLFW-b
, process
, safe
, text
, time
, X11Готово! Писать второй раз её уже не нужно, просто набираем первые несколько символов, напр: :'<,'>!se (фактически нужно нажать лишь !se), — и стрелкой вверх достаём нужную команду из истории. Так или иначе рекомендую почаще тренироваться писать такие штуки сходу. Таким образом вы как прокачаете навыки повседневной работы в bash, так и в самом Vim-е, т.к. по сути вы делаете тоже самое.
В конце-концов, всю эту команду можно назначить на хоткей, или абстрагировать в функцию, и переиспользовать всюду на раз-два.
Используя сторонний ЯП
Вместо запуска чего-то из coreutils можно запустить интерпретатор какого-нибудь удобного для вас ЯП, мне вот нравится такие штуки делать через Perl6 (он же недавно переименовался в Raku):
:'<,'>!perl6 -e 'my @x=lines.map(*.subst(/<[,\s]>\s(\w)/,{$0})).sort(*.lc); @x.shift.subst(/\w/,{q/ /~$_}).say; .subst(/\w/,{q/, /~$_}).say for @x'Да хоть на жопоскрипте (node.js):
:'<,'>!node -e 'let fs=require("fs"), x=fs.readFileSync(process.stdin.fd).toString().replace(/\n$/,'').split(/\n/).map(x=>x.replace(/[, ] (\w)/,"$1")).sort((a,b)=>a.toLowerCase().localeCompare(b.toLowerCase())); console.log(x.shift().replace(/(\w)/," $1")); process.stdout.write(x.map(x=>x.replace(/(\w)/,", $1")).join("\n"))'Такое можно проделать и на VimL/Vimscript внутри самого Vim, без вызова внешних команд. Но этот пост не об этом.
Естественно, как уже можно было догадаться, вы можете легко сохранить свой скрипт в отдельный файл, или даже скомпилировать собственную программу, которая что-то берёт на вход в STDIN и выдаёт что-то обработанное в STDOUT и использовать это в Vim просто вызывая (что, опять же, можно назначить на хоткей):
:'<,'>!~/my-program-or-scriptТаким образом, когда вы пишете код в Vim, в вашем распоряжении не только сам Vim, но и всё ваше рабочее окружение.
Один из самых простых примеров, отпреттифаить JSON-файл:
:%!jqВсего несколько нажатий клавиш, зачем переизобретать AST-парсер и преттифаер для JSON для любого нового редактора/IDE/whatever, когда можно просто взять и пропустить файл через jq никуда не уходя из Vim-а? Я уж не говорю о том, что вы можете через jq таким образом обработать ваш большой JSON файл, никуда не уходя из Vim-а, найти например нужный ключ в дереве, отсортировать, оставить только нужные данные, etc.






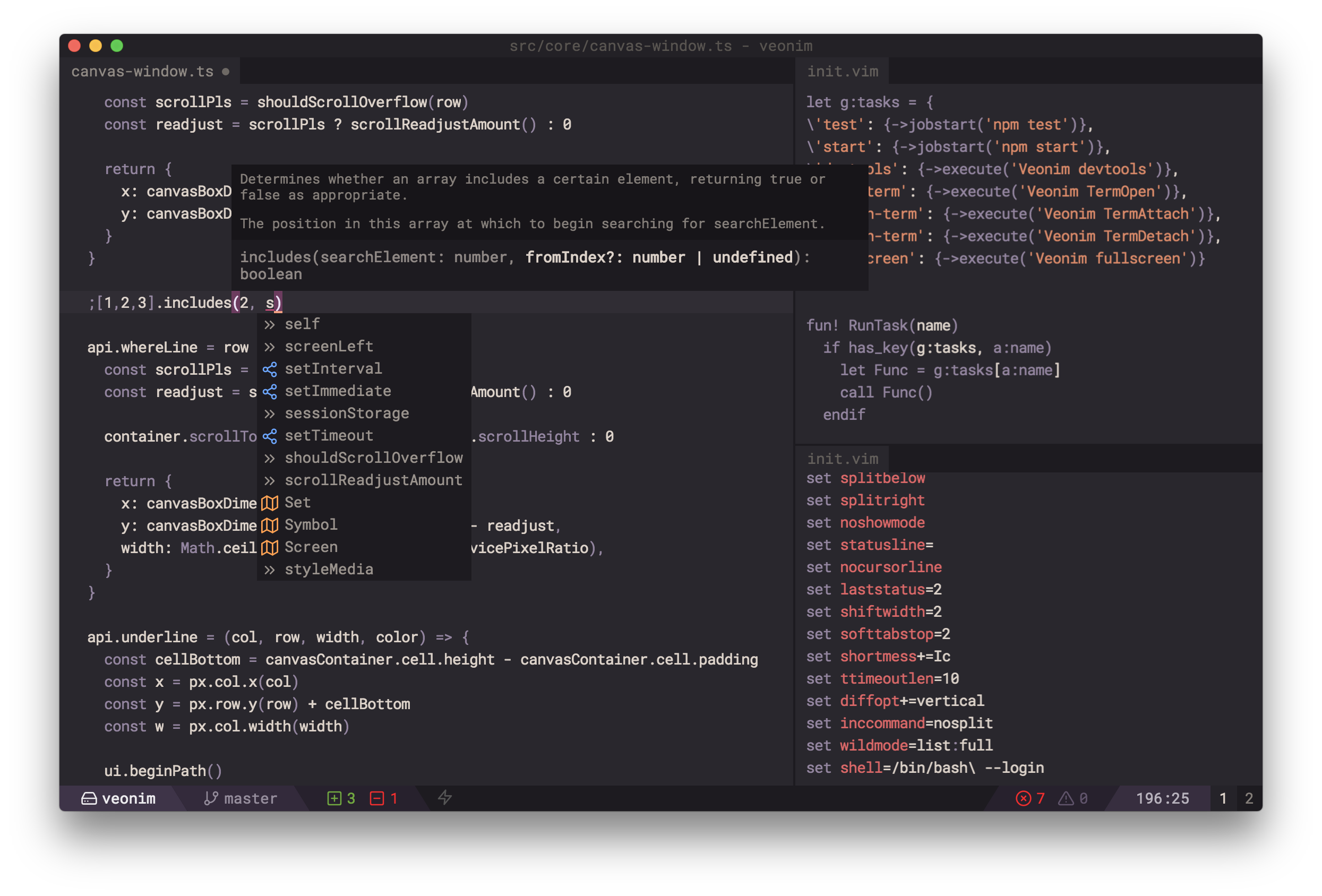


numitus2
У меня простой вопрос: Сколько надо времени на обучение командам, чтобы vim выйграла у обычной графической IDE
eXtReeM
Познание бесконечности — требует бесконечного времени.
unclechu Автор
Это очень индивидуально, также сильно зависит от предыдущего бэкграунда.
Для начала нужно освоить базу, пройти какой-нибудь vimtutor, пройти VIM Adventures. Начать работать в Vim сначала "по-тупому", но время от времени добавлять к своим навыкам что-то новое, можно найти какой-нибудь ресурс, который раз в день постит новый хоткей или описание фичи, и как этим пользоваться. Выписывать интересное на бумажку и стараться сразу начать употреблять.
Считаю также для эффективности крайне полезным сразу освоить слепую 10-и пальцевую печать, для этого полно онлайн-ресурсов. Vim как никакой другой редактор для этого очень приспособлен прямо "из коробки".
Смысл не в том чтобы сразу загрузить в себя большой массив знаний, навыков, умений. А в том, чтобы начать с чего-то, и постепенно улучшать этот навык, расширять понимание и кругозор в плане фич, возможностей, способов сделать что-то.
Вообще могу от себя дать хороший совет: наблюдать за тем, как ты работаешь в Vim, если ты чувствуешь что повторяешь что-то рутинно, шаблонно, по 10 раз одну последовательность действий, — значит самое время подумать или поискать в интернете или на форумах, как это можно автоматизировать или упростить.
BekoBou
Если владеете слепой печатью, то команды постепенно учатся. Опять же, никто не мешает вам использовать часть команд или сочетаний у вас в IDE. А выигрывать во времени я начал сразу — просто vim быстрее работает. С другой стороны я не использую всю мощь IDE. Мне для 80% задач хватает обычного редактора типа vim или VS Code.
unclechu Автор
По поводу "графичности", у Neovim есть различные GUI, например есть такой с поддержкой лигатур в шрифтах.
Есть и всякие экзотические проекты вроде onivim, которые сильно изменяют привычный облик vim, делая его более похожим на какой-нибудь sublime или atom, предоставляя различные не-текстовые элементы интерфейса.
Полный список доступных GUI для Neovim можно найти тут.
0xd34df00d
А у консольного vim тоже вполне себе лигатуры поддерживаются (если их поддерживает терминал). Например:
Да и вообще юникод:
Ну и вообще можно сделать, чтобы и автокомплит, и рефакторинги с ренеймами, и квикфиксы. Например, если я выше сделаю опечатку, то vim сразу покажет красненьким на полосе слева, что есть ошибка, подчеркнёт плохой терм, и при наведении курсора на него (которое можно сделать и командой, у меня замаплено на
<Leader>gn) покажет ошибку:Если теперь нажать
<Leader>qf, то оно там само поправится наconvert.gecube
Сколько времени нужно, чтобы запомнить все комбинации серьезной ИДЕ, например, IntelliJIDEA?
Думаю, что сравнимо с vim'ом. Дело ведь в логике наименования и конструирования шоркатов.
chapuza
И в виме это для почти всего — мнемоника, а в идее — случайный набор модификаторов и букв.
gecube
Ну, не случайный. Но логика явно была из серии — ctrl+c/x/z / shift+ins сделаем как в остальной системе, а остальное распихаем по ограниченному (!) набору шоркатов как сможем. В результате получается весьма странные комбинации из трёх одновременно нажимаемых клавиш.
vim'овские же комбинации больше похоже на макросы — максимальная расширяемость
lrrr11
слухи о том, что для эффективного использования вима надо выучить какие-то невероятные множества магических команд, сильно преувеличены. Ну да, их там много, но я не встречал еще ни одного вимера, который бы пользовался ими всеми. Все пользуются каким-то сильно ограниченным подмножеством, у каждого своим.
Да и если подумать, то ведь у обычных текстовых редакторов тоже есть много хоткеев для управления с клавиатуры. Даже прямо тут, в форме для добавления коммента. Очистить строку —
Home,Shift+End,Del, назад —Ctrl+Z, и т.п. И ими тоже кто-то пользуется, а кто-то нет.zoonman
Нисколько. Как только начинаются реальные задачи, вроде отладки, рефакторинга классов, вычленения интерфейсов, генерации заглушек и т.д., все эти ваши vim, Atom, VSCode, Sublime, Notepad++ и иже с ними, тихонько уступают продуктам от JetBrains. Поэтому vim никогда не выиграет у нормальных IDE.
vim — это про шаблонное редактирование текста. Если код требует шаблонного редактирования, значит что-то с ним не так. В 99% это спагетти код или код с низким уровнем абстраций.
Ребята, не надо путать теплое с мягким. Полноценные IDE и vim даже с кучей плагинов всегда будут разными. В vim удобно редактировать данные и простой код вроде типичного HTML.
У IDE уже сейчас есть достаточно мощная система анализа кода на пример дубликации, спорных моментов, еще немного и IDE начнут подсказывать, какой дальше писать код и т.д. Т.е. пока они делают подсказки через простые штуки вроде геттеров/сеттеров/ и т.п., но развитие AI очень скоро начнет предсказывать вещи вроде простых условий.
Еще немного и такие стандартные куски начнут генерироваться автоматически с учетом контекста. Пока это реализовано в виде шаблонов, в стиле vim так сказать, однако время не будет стоять на месте.
Мой совет — не тратье время на изучение очередного текстового редактора, он уже есть внутри вашей IDE. Потратьте время на изучение горячих клавиш IDE, и да, вы все их можете сменить по своему усмотрению. Да и на изучение самой IDE, вы будете сильно удивлены, насколько продуктивнее вы сможете работать.
EvgeniiR
То есть если в коде нет классов, интерфейсов и заглушек с ним что-то не так?
Я б её вырубал. Вреда от нее больше чем пользы, а некоторые горе-девелоперы потом путают принцип DRY и дублирование кода.
Если вы активно используете генерацию геттеров/сеттеров то что-то с вашим кодом не так -_- (геттеры/сеттеры не нужны).
Вы не подумайте, я исключительно за IDE, особенно в мейнстрим языках. Просто не ради этих фич, а ради продвинутого автодополнения, других инспекций, кастомных шаблонов, дебаггинга, удобной настройки всего этого и т.п.
ArXen42
Либо я плохо искал, либо здесь еще не упомянули — ко всем IDE от JetBrains есть отличное расширение IdeaVim, которое предлагается поставить прямо со стартовой страницы после установки IDE. Можно, так сказать, взять лучшее от двух миров.
К VS, VS Code и другим IDE/редакторам зачастую тоже есть аналогичные плагины.
Даже для браузеров есть vim-style плагины для более удобной клавиатурно-ориентированной навигации.
0xd34df00d
А какой продукт от JetBrains вы посоветуете для хаскеля?
gecube
Очевидно же, что IntelliJIDEA, т.к. все остальные среды (PyCharm, Goland etc.) сделаны на ее основе )))) вперед — к истокам
0xd34df00d
Я туда ставил плагин для хаскеля, и он что-то не завёлся вообще.
Arqwer
TabNine это уже делает. Причём работает и в JetBrains и в популярных редакторах.
maydjin
Нисколько он никогда не начнёт выигрывать в том смысле который вы(и куча людей включая меня в прошлом) рисуете у себя в голове :) Но сами по себе IDE — переоценены, это просто способ посадить не очень квалифицированные кадры выполнять типовые рутинные задачи максимально быстро(и посадить и выполнять).
Раньше я дивился с того, что очень технически крутые люди польюзуются для разработки каким нить notepad++ или vim без плагинов. Мне казалось, что я умнее и я им говорил что-то в духе — блин, ну тут даже интеграции с отладчиком нет, ты таааак долго делаешь эту хрень, смотри как у меня в <idename> всё круто. Они соглашались — круто, прикольно, так держать :) Но продолжали пилить код в текстовом редакторе, иногда даже без подсветки синтаксиса. И выполняли задачи, особенно сложные, в разы быстрее чем я…
На данный момент — поймал себя на том, что у меня уже пару месяцев как сломалось автодополнение, но меня это чет как то даже и не парит, вот думаю — может пора начать удалять плагины? Когда по большому счёту используешь только редактор, а те миллисекунды которые выскакивает комплит начинают тебя напрягать а и сбивать с мысли, а инфа в этом комплите выглядит как "да ладно, спасибо кэп", это видимо первые звоночки.
Я это к чему? Когда знаешь чего написать и как отладить — ты просто это записываешь и всё, с тем же усилием, как и документацию, просто на другом я зыке. Потом берёшь и отлаживаешь. А свистелки помогают пока не очень точно уверен, как ты собираешься сделать то, что собрался делать.
Чем хорош конкретно vim? Тем что с ним просто работать на удалённой машине, и он позволяет достаточно просто(так что можно хоть под каждый ишью писать скриптец) и вешать их на горячие клавиши или просто держать близко в истории. Ну и руки с хоумроу можно не убирать практически никогда (не для всех это плюс, помахать мышкой — тоже своя развлекуха имеется). Ну, ещё конфиг сравнительно просто утаскивается и размножается.
chapuza
Абсолютно. +100500.
EvgeniiR
Польза IDE переоценена, а польза работы на удаленной машине нет?
А остальное реализуемо в IDE.
maydjin
Работа на удалённой машине так же реализуема в некоторых IDE. Польза от работы на удалённой машине в том, что вы можете трудиться с лёгкого и сравнительно дешёвого терминала, утилизируя мощное серверное железо, без шума пыли. Я вот например сильно не уверен, что вы прямо сейчас сходу сможете начать работать с кодовой базой chromium на своём текущем конфиге без его апргрейда по железу :)
Arenoros
а вот запросто, не понимаю с чего разработчикам вообще жаловаться или ущемшять себя в железе? ПК это то на чем я работаю и зарабатываю, почему бы не купить мощный удобный ноут за 200k? И ещё в вопросе vim vs ide я за ide особенно когда начинаю задвигать что он быстрее, у меня вопрос возникает, у вас железо в 2000х засатряло?
unclechu Автор
Какую задержку между событием и откликом на него вы считаете приемлемой?
Несмотря на ультрамощное железо некоторые современные приложения на electron или какая-нибудь IDE, могут легко дать задержку с полсекунды на всплывание какого-нибудь автокомплита! Это совершенно неприемлемо, не потому что полсекунды — это как полвечности, а потому что таких событий у опытного разработчика во время работы с кодом могут происходить десятки на полминуты. И если отклик на рядовое событие будет длиться полсекунды, или даже 300-400мс — это замедлит работу в несколько раз (компьютер не поспевает за ходом мысли/рефлексами пишущего код), не говоря уже об общей раздражительности от дискомфорта использования таких решений, когда начинаешь ощущать, что тебе нужно ждать.
Если у вас всё хорошо с 10 fingers typing, у вас развиты рефлексы работы в вашем окружении, то такие задержки сразу начинают ощущаться и доставлять дискомфорт, чем их меньше, тем лучше, желательно чтобы любой отклик на действие укладывался в 100мс.
EvgeniiR
А могут и не дать.
А может IDE работать быстро, а Vim с задержкой в пол секунды.
У меня вот опыт обратный вышему, давайте не генерализировать частные случаи.
Моя IDE от JetBrains без проблем настраивается в отличие от Vim, и работает без видимых задержек, я не вижу ни единой причины переходить на текстовый редактор который либо имеет нулевой функционал, либо лишь часть от того что умеет IDE, но не факт что меньше лагая при этом(с плагинами).
p.s. Про переоценку частных случаев больше даже относится к комментарию maydjin выше, исходя из комментария которого выходит что все кто не работает над кодовой базой сравнимой по объёмом с базой хромиума «не очень квалифицированные кадры».
unclechu Автор
У меня стоит пол сотни плагинов, Vim запускается почти мгновенно (пол сотни, которые расширяют функционал, более сотни, включая поддержку многих языков и форматов файлов и цветовые схемы).
Остальное я даже комментировать не буду, глупости одни.
EvgeniiR
Ну то есть раз у вас так, значит у всех так? Ясно. Демагогия.
maydjin
Во-первых никого не хотел задеть вышеуказанной фразой. И уж тем более не считаю, что разработка небольших и шустрых проектов требует меньше квалификации, чем разработка больших (в случае хромого, я бы даже сказал монструозных) кодовых баз.
Во-вторых — ничто не истина в последней инстанции, более того — органы у всех находятся в разном состоянии, я вот например много играл в очень динамичные игрушки с минимальным пингом 5ms и видимо это заставило меня уметь различать разницу между 5ms и 10ms rtt на глаз при наличии тактильного отклика, я считаю, что это скорее плохо чем хорошо для моего душевного состояния если честно. К примеру — иногда ловлю лаг своей bluetooth клавиатуры, когда она подключенна не по проводу(к слову, в 2.4Ггц решениях такого не замечал, точнее замечал только на мышках и только в играх).
В третьих — vim можно настроить до состояния "лагает", и даже не очень сложно. А можно и не настраивать. Вот с настройкой ide обычно выходит сложнее, есть вещи которые решили за вас и их объективно больше, и это приятно с одной стороны, люблю когда кто-то что-то делает вместо меня. Но при этом — нет свободы отключить или заменить что-то, а коробка может не радовать. Тот же CLion кажется тормозом даже после QtCreator, примерно таким же, как Eclipse на фоне всех их. Я потрудился в 5-7 ide, во многих по несколько лет, поэтому, хочется верить, что мои замечания могут быть хоть от части объективными. К слову — тот же QtCreator единственный не вызывал у меня отторжений по времени отклика, пока я не начал перезжать на удалённый конфиг. Разница в том, что qtc начинает выдавать видимые для меня фризы на пинге 40 до целевого хоста, а vte-based терминал + ssh + vim на 80(а это уже даже для lte много).
gecube
Мощный ноут абсолютно не противоречит тормозам IDE при попытке автокомплита или когда увешался 100500 плагинов
Т.е., согласен, что мощное железо — необходимое условие эффективной работы, тем более, когда это инструмент. Но, к сожалению, не достаточное.
maydjin
Потому, что не изобрели ещё мощных ноутов которые держат батарейку хотя бы 8 часов и весят так, что бы не нужно было бы быть атлетом для их регулярного перемещения и комфортной работы. При этом получаемая производительность на выходе всё равно остаётся намного ниже. Это к вопросу о мобильности, нужна она не всем и не всегда. Но тем не менее, почему-то куча народу таскает с собой эти коробочки с микросхемами.
Второй момент сборный, это шум, пыль, занимаемое свободное место. Если вас шум вентилятора не отвлекает — окей. Я вот когда слышу этот чудный звук — ищу виновника и причиняю ему -9 и прочие радости доставляю. Можно взять рабочую станцию с водянкой например — это вполне себе вариант, но он ощутимо дороже, не мобильный и занимает непозволительно много свободного места, при условии, что этого можно было бы и избежать. Мы же не в 90ых живём в конце концов, я вот планирую в этом году переехать на разработку со своего телефона полностью, ноут большой и тяжёлый же.
Третий момент самый тонкий, спорный и низкоприоритетный — время отклика. Казалось бы сети должны его повысить, но, как показывает практика, многие GUI решения локально оказываются в этом плане тупее, чем терминал по ssh с пингом 60 например до свободного железа. Ноги у этого феномена растут понятно откуда — в условиях вытесняющей многозадачности, на клиентском терминале за ресурсы дерутся куда больше приложений и служб, чем на выделенном удалённом и когда в игру вступает такая сложная система как IDE — мы видим нестыковки в процессах планирования и артефакты борьбы за ресурсы. Когда я вижу фриз в каком нить VisualStudio PRO за многоденег, на свежей рабочей станции от какого нить HP тоже за многоденег, меня это расстраивает. Не сильно, но достаточно, что бы я написал об этом параграф приведённого размера. И достаточно, что бы моё душевное спокойствие вернулось в норму при открытии того же кода в другом решении.
orizonti
Для любой IDE доступны плагины реализующие 80-90% vim, на изучение основных команд хватит 1-2 недели, чтобы добиться существенного повышения эффективности редактирования, но по мере овладевания начинает раздражать отсутствие 10-20% функционала и ты полностью переходишь на vim для редактирования кода, используя IDE только для отладки.
Самая большая проблема это плагины уже для самого vim/neovim, при попытке полного перехода, мало того что они кривые и труднонастраиваемые, но зачастую возникает необходимость их самостоятельного дописывания и на полное удовлетворение своих потребностей могут уходить недели.
maydjin
Это основное заблуждение тех кто трогает vim по минимуму :) Там только возможности редактирования представлены на эти 80-90% и то, обычно в лучшем случае. Т.е. ощущение "я это по-любому сделаю/прикручу" — пропадает, а те 10% в которые втыкаешься из нереализованных или плохореализованных фич слегка сбивают.