
В предыдущей публикации мы затронули готовое решение KCAPTCHA, которое несмотря на неплохую защищенность было распознано без сколько-нибудь серьезной предварительной обработки и сегментации, обычным многослойным персептроном.
Теперь на очереди кириллическая Яндекс капча, с которой, уверен, многие из нас отлично знакомы.
Итак, мы имеем такую капчу:

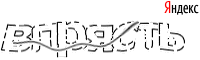
Особенности
- Переменная длина
- Искажения
- Шумы (кривая)
- Кириллические буквы
- Модный логотип в правом-верхнем углу
Слабые стороны
- Искажения незначительны, не препятствуют сегментации
- Шумы лишь незначительно усложняют распознавание
- Ограниченный словарь позволяет отсеять неверные варианты и скорректировать ответы сети
Решение
Условно разделим распознавание на следующие этапы:
- Предварительная обработка
- Поиск расположения и сегментация текста
- Распознавание
- Финальная обработка результата
Предварительная обработка
Убираем логотип Яндекса и автокадрируем изображение:
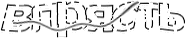
Нормализуем входные данные:
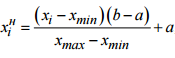
Где x — значения цвета пикселей, [a,b] – интервал допустимых значений входных сигналов. В нашем случае от -1 до 1.
Поиск расположения и сегментация текста
За распознавание длины капчи отвечает сеть с 4-мя нейронами выходного слоя, каждый из которых соответствует значению длины от 4 до 7.
Теперь, зная длину капчи, остается лишь разделить изображение на равные части, для дальнейшего распознавания:

Распознавание
Для распознавания букв используется сеть из двух слоев.
Первый слой обучаемый и состоит из 900 нейронов, выходной состоит из 31 нейрона, каждому из которых соответствует буква на картинке.
Первоначальная обучающая выборка подготовлена благодаря
Потенциально верные ответы сети, присутствующие в словаре, отправлялись на проверку Яндексу, по результатам которой и происходило обучение, что значительно сократило расходы на дальнейшее формирование выборки.
В течение суток получена точность распознавания каждого символа в 70%.
Финальная обработка результата
После получения результата распознавания проверяется наличие оного в словаре.
Если результат распознавания отсутствует в словаре, скорее всего он не верен.
Часто возникают ошибки между схожими символами, к примеру н — и, с — е, ь — ы, п — л.
В таком случае, исходя из ответов сети, выбираем наиболее вероятные буквы и ищем соответствующие слова в словаре.
Если слов не существует, выбираем варианты с аналогичной длиной и минимальным расстоянием Левенштейна.
Такой вариант дает 18% точность распознавания капчи.
Также можно задействовать частоту распределения букв и их сочетаний в русском языке, не говоря уже о готовых решениях для проверки орфографии, в любом случае вариантов множество.
Даже простое прюнинг результатов, отсутствующих в словаре отбрасывает значительную часть неверных вариантов.
Заключение
Как я говорил ранее, при желании и должном числе примеров, любая понятная [и не только] человеку капча поддается распознаванию. Упор нужно делать не на усложнении самого изображения, а на технологиях выявления ботов, пока они сами не начали выявлять и отсеивать людей.
Кириллическая Яндекс капча довольно слабая, однако порядком более дружелюбна для русскоязычных пользователей, нежели, к примеру, kcaptcha или recaptcha (особенно первой версии).
Я уверен, что в ближайшее время ребята из Яндекса поработают над своей капчей и смогут достичь компромисса между надежностью и удобством для простых людей.
Исходники
Если желаете протестировать или разобраться в работе сети — добро пожаловать на GitHub.
P.S. Если у вас есть интересные задачи в этой области — буду рад помочь.
Комментарии (17)

kronos
10.08.2015 19:03+3«Первый слой обучаемый и состоит из 600 нейронов, выходной состоит из 31 нейрона» как выбирается размер сети? Всегда интересно было

vanwin
10.08.2015 19:53+5Я так понимаю, 20x30=600 пикселей буква и на этом полотне допускается 1 из 31 букв.

Sayonji
11.08.2015 15:04Я так понимаю, автор ошибся: обучаемые слои там как раз внутренний (900 нейронов) и выходной (31).



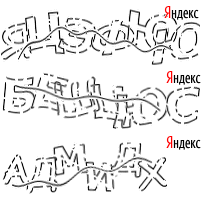


Mox
11.08.2015 03:33А за счет чего возможно повысить надежность распознования? Это количество нейронов? Количество тестовых примеров?
Как понять когда сложность сети нужно увеличивать?
Обязателен ли шаг деления на буквы, или возможно распознавать все слово?
matiouchkine
11.08.2015 08:39Для распознавания всего слова потребуется количество выходных нейронов размером со словарь. Это пока даже для распределенных вычислений непосильно.
Mox
11.08.2015 17:07Вроде IBM делала чип на 1 миллион нейронов, который к тому же параллелился и потреблял 40 милливат. То есть мощность нейростей уже достижима вполне.

GNC
11.08.2015 12:34Увеличение числа тестовых примеров позволит лишь точнее оценить распознавание.
Расширение обучающей выборки, при должной продолжительности обучения, дадут 80-85% точности для каждого символа, после чего все упрется в качество сегментации.
Сложность сети увеличивается добавлением нейронов, когда прекращается уменьшение ошибки на тестовой выборке, опять же, есть 'потолок', выше которого увеличение размерности сети не приводит к улучшению её обобщающей способности.
Шаг деления на буквы НЕ обязателен, в статье о kcaptcha сеть полностью распознает капчу, минуя этот этап. Однако в таком случае требуется порядком больший размер обучающей выборки и самой сети.
Оптимальным вариантом для распознавания капч без предварительной сегментации, будет сверточная нейросеть, эту тему я затрону в последующих публикациях.


UksusoFF
19.08.2015 17:13+1Распознали:
К сожалению, данный API более не поддерживается. Новые ключи не выдаются, а 1 октября 2015 года API будет выключен полностью.
tech.yandex.ru/cleanweb
amarao
Попробуйте собрать корпус записей из амбулаторных карточек и натравить на это роботов.
Потому что я это разобрать не могу.
Milfgard
Это тоже капча. Проходят только врачи.
rananyev
МедКапча должна будет говорить еще и «вроде как, да, похоже»