
Недавно был разработан алгоритм быстрой сортировки, сложность которого определяется как 2*N (2 умножить на N).
В данной статье не будем разбирать сам алгоритм сортировки, а, только проведя серию тестов, сравним его с сортировкой, используемой в Visual Studio (функция std::sort). Как говорится: только факты и минимум эмоций.
Сортировать будем текстовую информацию, в качестве которой будем рассматривать массив слов. Данный массив будем формировать на основе литературных произведений. Для этого все слова данных произведений по порядку заведем в данный массив. Разбиение на слова происходит без модернизации, признаком начала нового слова является пробел. Слова в массиве полностью соответствуют словам в тексте. Так как знаки препинания (точка, запятая и так далее) и управляющие символы пишутся за словами без пробелов, то, как следствие, они являются частью слов. Отдельно стоящие знаки препинания и управляющие символы рассматриваются как самостоятельные слова. В файлах присутствуют адреса сайтов, где эти файлы находятся. Данные адреса являются одним словом. Самое длинное слово состоит из 95 символов. В рассматриваемых произведениях присутствуют буквы латинского алфавита, кириллицы, знаки препинания и управляющие символы.
Сортируемая информация является произвольной, никаким образом не упорядоченной, и, как следствие, специальные сортировки не применяются.
Сравниваются два метода сортировки: вновь разработанный алгоритм сортировки со сложностью 2*N и алгоритм, используемый в Visual Studio 2017 (функция std::sort). Интересуют время сортировки и количество используемой для этого памяти каждого из методов на каждом тесте.
Программы написаны в среде — Visual Studio 2017, на платформе — Windows x64. Тестирование проводилось в 2-х конфигурациях. Результаты тестирования в конфигурации Debug и конфигурации Release представлены в таблицах 1 и 2 соответственно. В таблицах представлены результаты тестирования двух методов сортировки.
Так как результаты по времени вычисления — плавающие (значения меняются в пределах 10%), то по каждому тесту проводилась серия вычислений, из которых выбирались наименьшие значения и эти значения ставились в таблицы. Время, указанное в 4 и 6 колонках, является только временем сортировки. Дополнительные процессы (такие как считывание и запись в файл, формирование массива) в указанное время не входят.
Эффективность по времени и по памяти рассчитывается по следующим формулам соответственно:
где — количество временных тактов, за которые выполняется функция std::sort, используемой в Visual Studio, и новый алгоритм сортировки соответственно; — количество используемой памяти, необходимой для выполнения функции std::sort, используемой в Visual Studio, и нового алгоритма сортировки соответственно.
Таблица 1.
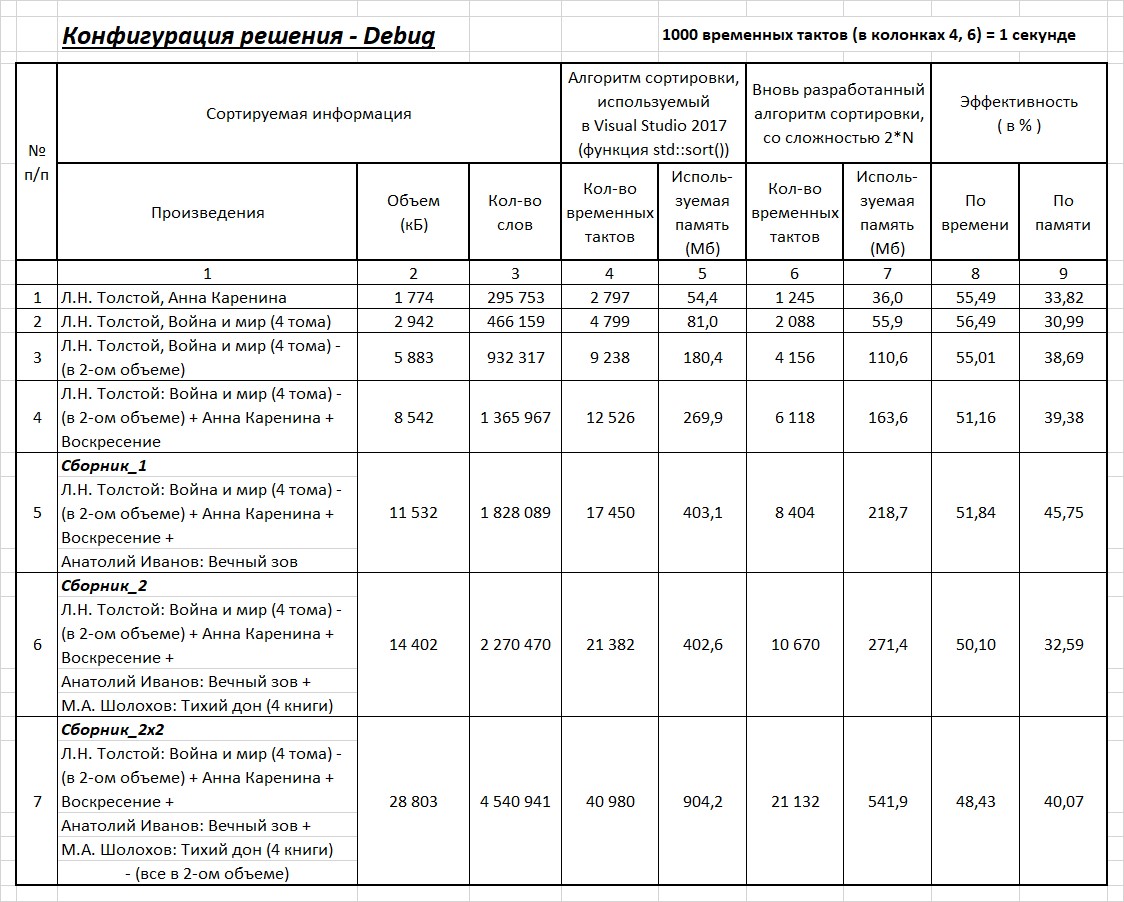
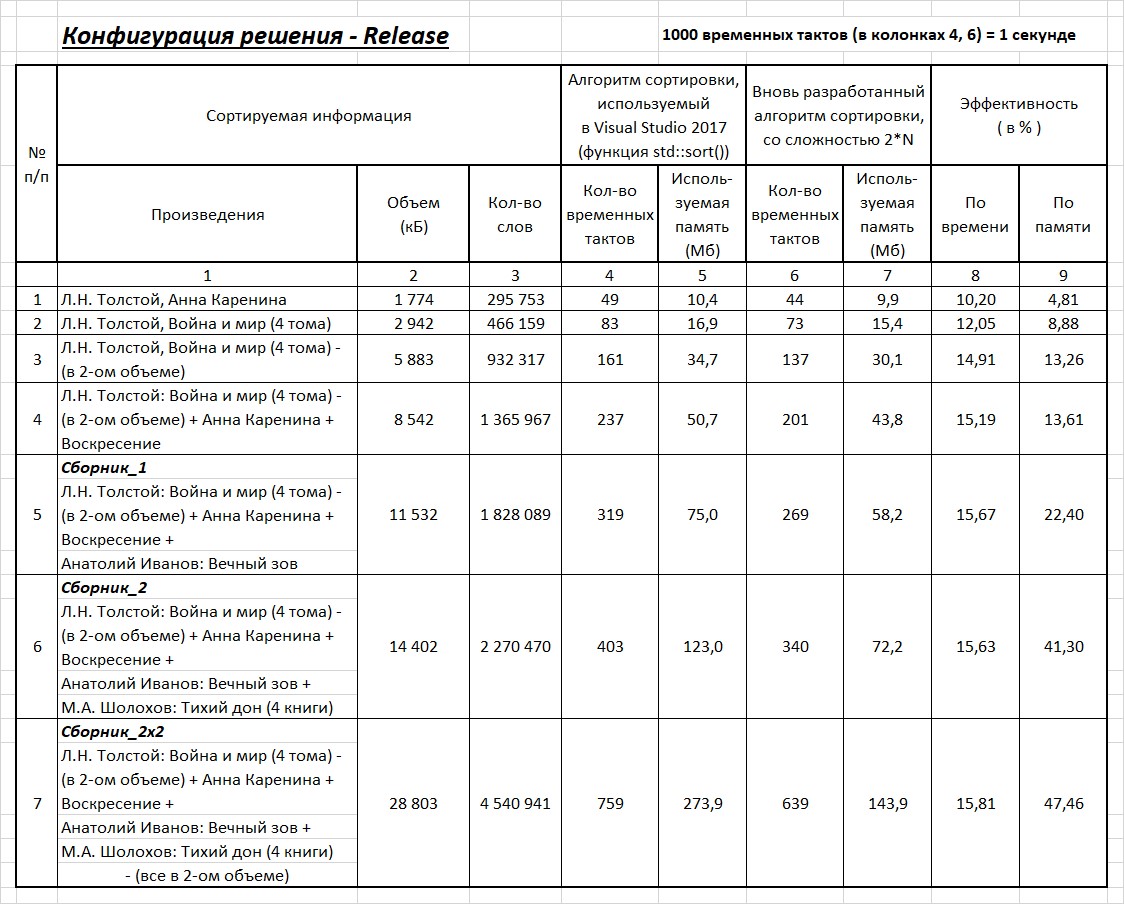
Таблица 2.
Насколько вновь разработанный алгоритм сортировки со сложностью 2*N является более эффективным (как по времени, так и использованию памяти) алгоритма, используемого в Visual Studio 2017 (функция std::sort) судите сами.
В данной статье не будем разбирать сам алгоритм сортировки, а, только проведя серию тестов, сравним его с сортировкой, используемой в Visual Studio (функция std::sort). Как говорится: только факты и минимум эмоций.
Сортировать будем текстовую информацию, в качестве которой будем рассматривать массив слов. Данный массив будем формировать на основе литературных произведений. Для этого все слова данных произведений по порядку заведем в данный массив. Разбиение на слова происходит без модернизации, признаком начала нового слова является пробел. Слова в массиве полностью соответствуют словам в тексте. Так как знаки препинания (точка, запятая и так далее) и управляющие символы пишутся за словами без пробелов, то, как следствие, они являются частью слов. Отдельно стоящие знаки препинания и управляющие символы рассматриваются как самостоятельные слова. В файлах присутствуют адреса сайтов, где эти файлы находятся. Данные адреса являются одним словом. Самое длинное слово состоит из 95 символов. В рассматриваемых произведениях присутствуют буквы латинского алфавита, кириллицы, знаки препинания и управляющие символы.
Сортируемая информация является произвольной, никаким образом не упорядоченной, и, как следствие, специальные сортировки не применяются.
Сравниваются два метода сортировки: вновь разработанный алгоритм сортировки со сложностью 2*N и алгоритм, используемый в Visual Studio 2017 (функция std::sort). Интересуют время сортировки и количество используемой для этого памяти каждого из методов на каждом тесте.
Программы написаны в среде — Visual Studio 2017, на платформе — Windows x64. Тестирование проводилось в 2-х конфигурациях. Результаты тестирования в конфигурации Debug и конфигурации Release представлены в таблицах 1 и 2 соответственно. В таблицах представлены результаты тестирования двух методов сортировки.
Так как результаты по времени вычисления — плавающие (значения меняются в пределах 10%), то по каждому тесту проводилась серия вычислений, из которых выбирались наименьшие значения и эти значения ставились в таблицы. Время, указанное в 4 и 6 колонках, является только временем сортировки. Дополнительные процессы (такие как считывание и запись в файл, формирование массива) в указанное время не входят.
Эффективность по времени и по памяти рассчитывается по следующим формулам соответственно:
где — количество временных тактов, за которые выполняется функция std::sort, используемой в Visual Studio, и новый алгоритм сортировки соответственно; — количество используемой памяти, необходимой для выполнения функции std::sort, используемой в Visual Studio, и нового алгоритма сортировки соответственно.
Таблица 1.
Таблица 2.
Насколько вновь разработанный алгоритм сортировки со сложностью 2*N является более эффективным (как по времени, так и использованию памяти) алгоритма, используемого в Visual Studio 2017 (функция std::sort) судите сами.













Petrenuk
Что за алгоритм? Кем разработан?
Знакома ли авторам big-O нотация? Если вы говорите об асимптотической сложности алгоритма, выражение 2*N не имеет смысла, пишут O(N). Иначе вам придется пояснять что такое N. Операции? Сравнения?
HabrArkady Автор
Я специально написал, что сложность 2*N. Я нигде не понимал это как O(2*N). Прекрасно знаю, что означает O(N). Это может быть и 2*N, и 10*N, и 1000*N. Вообще запись O(N) означает k*N, где k много меньше N (k<<N). Почему я написал, что сложность 2*N. Алгоритм линейный, в нем нет сравнений элементов друг с другом. С каждым элементом выполняются определенные действия. Это одно N. Второе N – это накладные расходы. В реальности они много меньше N, но я поднял границу до N. Вот почему я написал, что сложность алгоритма 2*N. Если бы накладные расходы были сравнимы с N или кратны N, тогда я бы написал, что сложность алгоритма O(N). Но накладные расходы много меньше N.
Petrenuk
Я поддерживаю вашу увлечённость алгоритмами и ни в коем случае не стремлюсь охладить ваш энтузиазм. Но если вы хотите чтобы ваш анализ воспринимали серьезно, желательно придерживаться строгой общепринятой терминологии. Если вы используете big-O нотацию, читателю сразу понятно что речь идёт об асимптотической сложности, которая растёт линейно с увеличением объема входных данных. Если вы пишете «сложность алгоритма 2*N», это можно интерпретировать как угодно. Есть хорошие причины почему в научных исследованиях пользуются строгими метриками, например системой СИ. Если бы в каждой статье по астрофизике использовались произвольные аршины и попугаи, сравнивать результаты было бы чрезвычайно сложно. И ваше пояснение про накладные расходы не делает картину более понятной.
По поводу алгоритма и сложности. Давно известно что алгоритмы основанные только на сравнениях имеют оптимальную сложность O(nlogn). Любые варианты с меньшей сложностью так или иначе используют ограниченность пространства ключей, либо другие свойства данных. Скорее всего вы изобрели radix, или counting sort, или trie, или какой-то вариант другой известной идеи. Может быть вы придумали что-то новое и полезное, в таком случае снимаю шляпу! Но из статьи этого не видно.
Сам факт того что какой-то кастомный алгоритм сортировки для определенного типа данных может быть быстрее std::sort никого не удивит. std::sort это универсальный алгоритм основанный только на сравнениях, который не использует знания о типах данных никаким образом. Когда программист вызывает std::sort, он как бы говорит системе: интерпретируй мои данные как абстрактные ключи и используй operator< для их сравнения, я знаю что я делаю. Создатели stl не пытались предоставить наибыстрейший алгоритм сортировки для всех возможных типов данных.
lair
Нет, вы явно не знаете, что означает O(N).
Значит, это не универсальный алгоритм сортировки. Что и требовалось доказать.