
Привет! Меня зовут Алексей Пьянков, я разработчик в компании Спортмастер. В этом посте я рассказал, как начиналась работа над сайтом Спортмастер в 2012 году, какие инициативы удалось «протолкнуть» и наоборот, какие грабли мы собрали.
Сегодня я хочу поделиться мыслями, которые следуют за другим сюжетом – выбор системы кеширования для java-бэкенда в админке сайта. Этот сюжет имеет особое значение для меня – хотя история разворачивалась всего 2 месяца, но эти 60 дней мы работали по 12-16 часов и без единого выходного. Никогда раньше не думал и не представлял, что можно так много работать.
Поэтому текст разбиваю на 2 части, чтоб не загрузить по полной. Наоборот, первая часть будет очень легкой — подготовкой, введением, некоторыми соображениями, что такое кеширование. Если вы уже опытный разработчик или работали с кешами — с технической стороны ничего нового в этой статье, скорее всего, не будет. А вот для джуниора небольшой такой обзор может подсказать, в какую сторону смотреть, окажись он на таком распутье.

Когда новая версия сайта Спортмастер была запущена в продакшн, данные поступали способом, мягко говоря, не очень удобным. Основой служили таблицы, подготовленные для прошлой версии сайта (Bitrix), которые надо было затянуть в ETL, привести к новому виду и обогатить разными рюшечками еще из десятка систем. Чтобы новая картинка или описание товара оказались на сайте, нужно было подождать до следующего дня — обновление только ночью, 1 раз в сутки.
Поначалу было столько забот от первых недель выхода в прод, что такие неудобства контент-менеджеров были мелочью. Но, как только все утряслось, развитие проекта продолжилось — через несколько месяцев, в начале 2015 года мы начали активно разрабатывать админку. В 2015 и 2016 все идет хорошо, мы регулярно релизим, админка охватывает все большую часть подготовки данных и мы готовимся к тому, что вскоре нашей команде доверят самое важное и сложное – товарный контур (полная подготовка и ведение данных по всем товарам). Но летом 2017, как раз перед запуском товарного контура, проект окажется в очень сложной ситуации – именно из-за проблем с кешированием. Про этот эпизод я и хочу рассказать во второй части этой двухсерийной публикации.
Но в этом посте начну издалека, подобью некоторые мысли – представления о кешировании, прокрутить которые перед большим проектом заранее было бы хорошим шагом.
Задача кеширования не появляется просто так. Мы разработчики, пишем программный продукт и хотим, чтобы он был востребован. Если продукт востребован и успешен — пользователи прибывают. И еще прибывают и еще. И вот пользователей очень много и тогда продукт становится высоконагруженным.
На первых этапах мы не думаем про оптимизацию и производительность кода. Главное — функциональность, быстро выкатывать пилот и проверять гипотезы. И если нагрузка растет – мы прокачиваем железо. Увеличиваем раза в два-три, в пять, пускай в 10 раз. Где-то здесь – финансы больше не позволят. А во сколько раз подрастет количество пользователей? Это будет не то что 2-5-10, но в случае успеха — это будет от 100-1000 и до 100 тысяч раз. То есть, рано или поздно, но оптимизацией заняться придется.
Допустим, некоторая часть кода (назовем эту часть функцией) работает неприлично долго, и мы хотим сократить время выполнения. Функция – это может быть доступ к базе данных, может быть выполнение какой-то сложной логики – главное, что выполняется долго. На сколько можно сократить время выполнения? В пределе – сократить можно до нуля, не дальше. А как можно сократить время выполнения до нуля? Ответ: вообще исключить выполнение. Вместо этого – сразу вернуть результат. А как узнать результат? Ответ: либо вычислить, либо где-то подсмотреть. Вычислить — это долго. А подсмотреть — это, например, запомнить тот результат, который функция выдала в прошлый раз при вызове с такими же параметрами.
То есть, реализация функции нам неважна. Достаточно только знать, от каких параметров зависит результат. Тогда, если значения параметров представить в виде объекта, который возможно использовать как ключ в некотором хранилище — то результат вычисления можем сохранить и при следующем обращении считать его. Если эти запись-считывание результата проходят быстрее чем выполнение функции – имеем профит по скорости. Величина профита может достигать и 100, и 1000, и 100 тысяч раз (10^5 – это скорее исключение, но в случае с порядочно лагающей базой – вполне возможно).
Первое, что может стать требованием к системе кеширования — быстрая скорость чтения и в чуть меньшей степени – скорость записи. Это так, но только до тех пор, пока мы не выкатываем систему в продакшн.
Разыграем такой кейс.
Допустим, мы обеспечили железом текущую нагрузку и теперь понемногу внедряем кеширование. Немного прирастает пользователей, растет нагрузка – немного добавляем кешей, прикручиваем то тут, то там. Так продолжается некоторое время, и вот тяжеловесные функции уже практически не вызываются — вся основная нагрузка ложится на кеш. Количество пользователей за это время выросло в N раз.
И если начальный запас по железу мог быть 2-5 раз, то с помощью кеша мы могли подтянуть производительность раз в 10 или, в хорошем случае раз в 100, местами, возможно, и в 1000. То есть, на том же железе – обрабатываем в 100 раз больше запросов. Замечательно, заслужили пряник!
Но теперь, в один прекрасный момент, случайно, система дала сбой и кеш рухнул. Ничего особенного – ведь кеш выбрали по требованию «высокая скорость чтения и записи, остальное неважно».
Относительно стартовой нагрузки запас по железу у нас был 2-5 раз, а нагрузка за это время подросла в 10-100 раз. С помощью кеша мы исключали вызовы для тяжелых функций и поэтому все летало. А теперь, без кеша – во сколько раз у нас система просядет? Что у нас произойдет? Система ляжет.
Даже если у нас кеш не рухнул, а только очистился на некоторое время – его нужно будет прогревать, и это займет некоторое время. И на это время – основная нагрузка ляжет на функционал.
Вывод: высоконагруженные проекты в проде требуют от системы кеширования не только высокой скорости чтения и записи, но также сохранности данных и устойчивости к сбоям.
В проекте с админкой – выбор прошел так: сначала поставили Hazelcast, т.к. уже были знакомы с этим продуктом по опыту основного сайта. Но, здесь такой выбор оказался неудачным – под наш профиль нагрузки Hazelcast работает не просто медленно, а жутко медленно. А под сроками вывода в прод мы на тот момент уже подписались.
Спойлер: как именно сложились обстоятельства, что мы пропустили такую плюху и получили острую и напряженную ситуацию – я расскажу во второй части — и как оказались, и как выбрались. Но сейчас — скажу только, что это был сильный стресс, и «думать – как-то не думается, трясем бутылку». «Трясем бутылку» — это тоже спойлер, про это чуть дальше.
Что мы сделали:
Но это вариант, когда нужно выбрать систему, которая «пролезет по скорости» в заранее подготовленных тестах. А если таких тестов еще нет и хочется выбрать побыстрее?
Смоделируем такой вариант (сложно представить, что миддл+ разработчик живет в вакууме, и на момент выбора еще не оформил предпочтение, какой продукт пробовать в первую очередь — поэтому, дальнейшие рассуждения это, скорее теоретика/философия/про джуниора).
Определившись с требованиями, начнем выбирать решение из коробки. Зачем изобретать велосипед: мы пойдем и возьмем готовую систему кеширования.
Если вы только начинаете и будете гуглить, то плюс-минус очередность, но в целом, ориентиры будут такие. В первую очередь вы наткнетесь на Redis, он везде на слуху. Потом узнаете, что есть EhCache как самая давняя и проверенная система. Дальше будет написано про Tarantool — отечественную разработку, в которой есть уникальный аспект решения. И также Ignite, потому что он сейчас на подъеме популярности и пользуется поддержкой СберТеха. В конце еще Hazelcast, потому что в enterprise-мире он часто мелькает в среде крупных компаний.
Этим список не исчерпывается, систем существуют десятки. А прикрутим мы только одно. Возьмем выбранные 5 систем на «конкурс красоты» и проведем отбор. Кто будет победителем?
Читаем, что пишут на официальном сайте.
Redis — opensource-проект. Предлагает in-memory хранилище данных, возможность сохранения on-disk, авторазбивку на партиции, высокую доступность и восстановление после сетевых разрывов.
Вроде бы, все отлично, можно брать и прикручивать — все что нужно, он делает. Но посмотрим просто ради интереса на остальных кандидатов.
EhCache — «наиболее широко используемый кеш для Java»(перевод лозунга с официального сайта). Тоже opensource. И тут понимаем, что Redis не под java, а общий, и для взаимодействия с ним нужна обертка. А EhCache будет поудобнее. Что еще обещает система? Надежность, проверенность, полнофункциональность. Ну и еще она самая распространенная. И кеширует терабайты данных.
Redis забыт, я готов выбрать EhCache.
Но чувство патриотизма меня толкает посмотреть, чем хорош Tarantool.
Tarantool — встречает обозначением «Платформа интеграции данных в режиме реального времени». Очень сложно звучит, поэтому читаем страницу подробно и находим громкое заявление: «Кеширует 100% данных в оперативной памяти». Это должно вызвать вопросы — ведь данных может быть значительно больше, чем памяти. Расшифровка в том, что здесь подразумевается, что для записи данных на диск из памяти Tarantool не прогоняет сериализацию. Вместо этого – использует низкоуровневые особенности системы, когда память просто мэпится на файловую систему с весьма хорошими показателями I/O. В общем, сделали как-то замечательно и классно.
Посмотрим на внедрения: Mail.ru корпоративная магистраль, Авито, Билайн, Мегафон, Альфа-Банк, Газпром…
Если оставались еще какие-то сомнения по поводу Tarantool, то кейс внедрения в Mastercard меня добивает. Беру Tarantool.
Но все-таки…
… есть еще Ignite, заявлен как «in-memory вычислительная платформа… in-memory скорости на петабайтах данных». Здесь тоже много плюсов: распределенный in-memory кеш, самое быстрое key-value хранилище и кеш, горизонтальное масштабирование, высокая доступность, строгая целостность. В общем, оказывается, самый быстрый – это Ignite.
Внедрения: Сбербанк, American Airlines, Yahoo! Japan. А потом я еще узнаю, что Ignite не просто в Сбербанке внедрен, а команда СберТеха своих людей отправляет в команду самого Ignite, дорабатывать продукт. Это полностью подкупает и я готов взять Ignite.
Совершенно непонятно зачем, я смотрю на пятый пункт.
Захожу на сайт Hazelcast, читаю. И оказывается, самое быстрое-то решение для распределенного кеширования — это Hazelcast. Он на порядки быстрее всех других решений и вообще он — лидер в области in-memory data grid. На фоне этого взять что-то другое — себя не уважать. А еще использует избыточное хранение данных для непрерывной работы кластера без потерь данных.
Все, я готов взять Hazelcast.
Но если посмотреть, то все пять кандидатов так расписаны, что каждый из них – самый лучший. Как выбрать? Можем посмотреть, какой из них самый популярный, поискать сравнения, и головная боль пройдет.
Находим такой обзор, выбираем наши 5 систем.

Здесь они отсортированы: наверху Redis, на втором месте — Hazelcast, набирают популярность Tarantool и Ignite, EhCache как был, так и остается.
Но посмотрим на метод расчета: ссылки на вебсайты, общий интерес к системе, job offers — здорово! То есть, когда у меня упадет система, я скажу: «Нет, она же надежная! Вот много предложений о работе…». Такое простое сравнение не подойдет.
Все эти системы — не просто системы для кэширования. У них еще очень много функционала, в том числе – когда не данные перекачиваются клиенту на обработку, а наоборот: код, который надо выполнить над данными, переезжает на сервер, там выполняется, и результат возвращается. И как отдельную систему для кэширования их не так-то часто и рассматривают.
Хорошо, не сдаемся, найдем прямое сравнение систем. Возьмем два верхних варианта — Redis и Hazelcast. Нас интересует скорость, по этому параметру их и сравним.
Находим такое сравнение:
Синий — это Redis, красный Hazelcast. Hazelcast везде выигрывает, и этому дано обоснование: он многопоточный, высоко оптимизированный, каждый поток работает со своей партицией, поэтому нет блокировок. А Redis — однопоточный, от современных многоядерных CPU он выигрыш не берет. У Hazelcast асинхронное I/O, у Redis-Jedis — блокирующие socket’ы. В конце концов, Hazelcast использует бинарный протокол, а Redis ориентирован на текст, то есть он неэффективный.
На всякий случай обратимся к еще одному источнику сравнения. Что он нам покажет?
Еще одно сравнение:
Здесь наоборот, красный — это Redis. То есть, Redis по производительности выигрывает у Hazelcast. В первом сравнении выигрывал Hazelcast, во втором — Redis. Здесь же очень точно объяснили, почему в предыдущем сравнении выиграл Hazelcast.
Оказывается, результат первого был фактически подтасован: Redis взяли в базовой коробке, а Hazelcast заточили под тестовый случай. Тогда получается: во-первых, никому нельзя верить, во-вторых, когда мы все-таки выберем систему, нам еще нужно ее правильно настроить. Эти настройки включают в себя десятки, почти сотни параметров.
И весь процесс, который мы сейчас проделали, я могу объяснить такой метафорой «Трясем бутылку». То есть, сейчас можно не программировать, сейчас главное — уметь читать stackoverflow. И у меня в команде есть человек, профессионал, который именно так и работает в критические моменты.
Что он делает? Он видит неработающую штуковину, видит stack trace, берет какие-то из него слова(какие именно — это его экспертиза в программе), ищет в гугле, находит stackoverflow среди ответов. Не читая, не вдумываясь, среди ответов на вопрос — он выбирает что-то наиболее похожее на предложение «сделать то и то» (выбрать такой ответ — это его талант, тк не всегда это именно тот ответ, который собрал больше лайков), применяет, смотрит: если что-то поменялось, то отлично. Если не поменялось — откатываем. И повторяем запуск-проверку-поиск. И таким интуитивным способом он добивается того, что через какое-то время код работает. Он не знает почему, он не знает, что он сделал, он не может объяснить. Но! Эта зараза работает. И «пожар потушен». Вот теперь разбираемся, что мы сделали. Когда программа работает — это на порядок легче. И значительно экономит время.
Вот этот способ очень хорошо объясняется на таком примере.
Когда-то было очень популярно собирать парусник в бутылке. При этом парусник большой и хрупкий, а горлышко у бутылки очень узенькое, его внутрь пропихнуть нельзя. Как его собрать?
Есть такой метод, очень быстрый и очень эффективный.
Корабль состоит из кучи мелочей: палочек, веревочек, парусов, клея. Все это кладем в бутылку.
Берем бутылку двумя руками, и начинаем трясти. Мы ее трясем-трясем. И обычно – получается полная фигня, конечно. Но иногда. Иногда получается корабль! Точнее, что-то похожее на корабль.
Мы это что-то показываем кому-то: «Серега, видишь!?». И действительно, издалека – как будто корабль. Но дальше это пускать нельзя.
Есть еще способ. Используют ребята более продвинутые, такие хакеры.
Дал такому парню задачу, он все сделал и ушел. И смотришь – вроде сделано. А через некоторое время, когда надо доработать код — там такое начинается из-за него… Хорошо, что он уже успел далеко отбежать. Это такие ребята, которые на примере бутылки сделают так: видите, там, где донышко – стекло изгибается. И не совсем понятно, прозрачно оно или нет. Тогда «хакеры» спиливают это донышко, вставляют туда корабль, донышко потом приклеивают заново, и как будто так и надо.
С точки зрения постановки задачи вроде бы все правильно. Но вот на примере кораблей: для чего вообще делать этот корабль, кому он вообще нужен? Функциональность он никакую не несет. Обычно такие корабли — это подарки очень высокопоставленным людям, которые ставят его на полочку над собой, как некоторый символ, как знак. И вот если у такого человека, руководителя крупного бизнеса или высокопоставленного чиновника, как флаг будет стоять такая халтура, у которой спилено горлышко? Лучше будет, если он об этом никогда не узнает. Так, а как же в итоге делают эти корабли, которые можно подарить важному человеку?
Единственное место, ключевое, с которым действительно ничего нельзя поделать, это корпус. И корпус корабля как раз в горлышко проходит. Тогда как корабль собирается за пределами бутылки. Но это не просто собрать корабль, это настоящее ювелирное ремесло. В составные части добавляются специальные рычажки, которые позволяют потом их поднять. Например, складываются паруса, аккуратно заносятся внутрь, и потом с помощью пинцета очень ювелирно, точно, их подтягивают и поднимают. В результате получается произведение искусства, которое можно с чистой совестью и гордостью подарить.
И если мы хотим, чтобы проект был успешный – в команде должен быть хотя бы один человек-ювелир. Тот, кто заботится о качестве продукта и учитывает все аспекты, не жертвуя ни одним даже в моменты стресса, когда обстоятельства требуют сделать срочное в ущерб важному. Все успешные проекты, которые устойчивы, которые выдержали проверку временем, они построены на этом принципе. В них есть что-то очень точное и уникальное, что-то, что использует все доступные возможности. В примере с кораблем в бутылке – обыгрывается то, что корпус корабля проходит через горлышко.
Возвращаясь к задаче выбора нашего сервера кэширования, как этот способ можно было бы применить? Я предлагаю такой вариант выбора из всех систем, что есть — не трясти бутылку, не выбирать, а посмотреть, что в принципе в них есть такого, на что обращать внимание при выборе системы.
Попробуем не трясти бутылку, не перебирать все что есть по очереди, но посмотрим, какие задачи возникнут, если вдруг, под свою задачу – спроектировать такую систему самостоятельно. Собирать велосипед, конечно же не будем, но воспользуемся этой схемой, чтоб сориентироваться, на какие моменты обращать внимание в описаниях продуктов. Набросаем такую схему.
Если система распределенная, значит, у нас будет несколько серверов (6). Допустим, четыре (удобно разместить на картинке, но, конечно, их может быть сколько угодно). Если серверы на разных узлах, значит, на них всех крутится некоторый код, отвечающий за то, чтобы эти узлы образовали кластер и в случае разрыва – соединялись, узнавали друг друга.
Еще нужен код-логика (2), которая собственно про кеширование. С этим кодом по некоторому API взаимодействуют клиенты. Клиентский код (1) может быть как в рамках этой же JVM, так и обращаться к нему по сети. Логика, реализованная внутри – это решения, какие объекты в кеше оставлять, какие выкидывать. Для хранения кеша используем память (3), но если потребуется, часть данных можем и на диске сохранить (4).
Посмотрим, в каких частях будет возникать нагрузка. Собственно, нагружаться будут каждая стрелочка и каждый узел. Во-первых, между клиентским кодом и api, если это сетевое взаимодействие, проседание может быть довольно заметным. Во-вторых, в рамках самого api — перестаравшись со сложной логикой, можем упереться в CPU. И хорошо бы, чтоб логика не гоняла память лишний раз. И остается взаимодействие с файловой системой – в обычном варианте это сериализовать / восстановить и записать / считать.
Дальше взаимодействие с кластером. Скорее всего, он будет в этой же системе, но может быть и отдельно. Здесь тоже нужно учитывать передачу данных к нему, скорость сериализации данных и взаимодействия между кластером.
Теперь, с одной стороны – мы можем представить, «какие шестеренки будут крутиться» в кеш-системе при обработке запросов от нашего кода, и с другой стороны – мы можем прикинуть, какие и сколько запросов наш код к этой системе сгенерирует. Этого достаточно, чтобы сделать более-менее трезвый выбор – подобрать систему под наш вариант использования.
Hazelcast
Посмотрим, как такое разложение применить к нашему списку. Например, Hazelcast.
Для того чтобы положить/взять данные из Hazelcast, клиентский код обращается (1) к api. Hz позволяет запустить сервер как embedded, и в этом случае обращение к api – это вызов метода внутри JVM, можно считать бесплатно.
Чтобы отработала логика в (2), Hz опирается на хеш от байт-массива сериализованного ключа – то есть, сериализация ключа произойдет в любом случае. Это неизбежный overhead для Hz.
Eviction-стратегии реализованы хорошо, но для особых случаев – можно подключать свои. За эту часть можно не беспокоиться.
Хранилище (4) можно подключать. Отлично. Взаимодействие (5) для embedded можно считать моментальным. Обмен данными между узлами в кластере (6) – да, он есть. Это вклад в пользу отказоустойчивости ценой скорости. Снизить цену позволяет Hz-фича Near-cache – данные полученные из других нод кластера будут закешированы.
Что можно в таких условиях сделать для повышения скорости?
Например, чтоб избежать сериализации ключа в (2) – поверх Hazelcast прикрутить еще один кеш, для наиболее горячих данных. В Спортмастер для этой цели выбрали Caffeine.
Для подкрутки на уровне (6), в Hz предложены два типа хранения: IMap и ReplicatedMap.

Стоит сказать, как Hazelcast попал в стек технологий Спортмастер.
В 2012 году, когда мы работали над самым первым пилотом будущего сайта, именно Hazelcast оказался первой ссылкой, которую выдал поисковик. Знакомство завязалось «с первого раза» — нас подкупило то, что всего через два часа, когда мы прикрутили Hz в систему — он работал. И работал хорошо. До конца дня дописали сколько-то тестов, порадовались. И этого запаса бодрости хватило, чтоб преодолеть те сюрпризы, которые Hz подкидывал со временем. Сейчас у команды Спортмастер нет поводов для того, чтобы от Hazelcast отказываться.
Но такие аргументы, как «первая ссылка в поисковике» и «быстро собрали HelloWorld» — это, конечно, исключение и особенность момента, в котором проходил выбор. Настоящие испытания для выбранной системы начинаются с выходом в прод, и именно на этот этап стоит обратить внимание при выборе любой системы, в том числе и кеша. Собственно, в нашем случае можно сказать, что выбрали Hazelcast случайно, но потом оказалось, что выбрали правильно.
Для продакшн много важнее: мониторинг, обработка сбоев на отдельных узлах, репликация данных, стоимость масштабирования. То есть, стоит обратить внимание на задачи, которые возникнут как раз в сопровождении системы – когда нагрузка в десятки раз превысит запланированную, когда случайно зальем что-то не то и не туда, когда потребуется выкатить новую версию кода, заменить данные и сделать это незаметно для клиентов.
Для всех этих требований, Hazelcast, безусловно подходит.
Но Hazelcast — это не панацея. В 2017 году мы выбрали Hazelcast для кеша в админке, просто опираясь на доброе впечатление от прошлого опыта. Это сыграло ключевую роль в очень злой шутке, из-за чего мы оказались в сложной ситуации и «героически» выбирались из нее 60 дней. Но об этом, в следующей части.
А пока… Happy New Code!
Сегодня я хочу поделиться мыслями, которые следуют за другим сюжетом – выбор системы кеширования для java-бэкенда в админке сайта. Этот сюжет имеет особое значение для меня – хотя история разворачивалась всего 2 месяца, но эти 60 дней мы работали по 12-16 часов и без единого выходного. Никогда раньше не думал и не представлял, что можно так много работать.
Поэтому текст разбиваю на 2 части, чтоб не загрузить по полной. Наоборот, первая часть будет очень легкой — подготовкой, введением, некоторыми соображениями, что такое кеширование. Если вы уже опытный разработчик или работали с кешами — с технической стороны ничего нового в этой статье, скорее всего, не будет. А вот для джуниора небольшой такой обзор может подсказать, в какую сторону смотреть, окажись он на таком распутье.
Когда новая версия сайта Спортмастер была запущена в продакшн, данные поступали способом, мягко говоря, не очень удобным. Основой служили таблицы, подготовленные для прошлой версии сайта (Bitrix), которые надо было затянуть в ETL, привести к новому виду и обогатить разными рюшечками еще из десятка систем. Чтобы новая картинка или описание товара оказались на сайте, нужно было подождать до следующего дня — обновление только ночью, 1 раз в сутки.
Поначалу было столько забот от первых недель выхода в прод, что такие неудобства контент-менеджеров были мелочью. Но, как только все утряслось, развитие проекта продолжилось — через несколько месяцев, в начале 2015 года мы начали активно разрабатывать админку. В 2015 и 2016 все идет хорошо, мы регулярно релизим, админка охватывает все большую часть подготовки данных и мы готовимся к тому, что вскоре нашей команде доверят самое важное и сложное – товарный контур (полная подготовка и ведение данных по всем товарам). Но летом 2017, как раз перед запуском товарного контура, проект окажется в очень сложной ситуации – именно из-за проблем с кешированием. Про этот эпизод я и хочу рассказать во второй части этой двухсерийной публикации.
Но в этом посте начну издалека, подобью некоторые мысли – представления о кешировании, прокрутить которые перед большим проектом заранее было бы хорошим шагом.
Когда возникает задача кеширования
Задача кеширования не появляется просто так. Мы разработчики, пишем программный продукт и хотим, чтобы он был востребован. Если продукт востребован и успешен — пользователи прибывают. И еще прибывают и еще. И вот пользователей очень много и тогда продукт становится высоконагруженным.
На первых этапах мы не думаем про оптимизацию и производительность кода. Главное — функциональность, быстро выкатывать пилот и проверять гипотезы. И если нагрузка растет – мы прокачиваем железо. Увеличиваем раза в два-три, в пять, пускай в 10 раз. Где-то здесь – финансы больше не позволят. А во сколько раз подрастет количество пользователей? Это будет не то что 2-5-10, но в случае успеха — это будет от 100-1000 и до 100 тысяч раз. То есть, рано или поздно, но оптимизацией заняться придется.
Допустим, некоторая часть кода (назовем эту часть функцией) работает неприлично долго, и мы хотим сократить время выполнения. Функция – это может быть доступ к базе данных, может быть выполнение какой-то сложной логики – главное, что выполняется долго. На сколько можно сократить время выполнения? В пределе – сократить можно до нуля, не дальше. А как можно сократить время выполнения до нуля? Ответ: вообще исключить выполнение. Вместо этого – сразу вернуть результат. А как узнать результат? Ответ: либо вычислить, либо где-то подсмотреть. Вычислить — это долго. А подсмотреть — это, например, запомнить тот результат, который функция выдала в прошлый раз при вызове с такими же параметрами.
То есть, реализация функции нам неважна. Достаточно только знать, от каких параметров зависит результат. Тогда, если значения параметров представить в виде объекта, который возможно использовать как ключ в некотором хранилище — то результат вычисления можем сохранить и при следующем обращении считать его. Если эти запись-считывание результата проходят быстрее чем выполнение функции – имеем профит по скорости. Величина профита может достигать и 100, и 1000, и 100 тысяч раз (10^5 – это скорее исключение, но в случае с порядочно лагающей базой – вполне возможно).
Основные требования к системе кеширования
Первое, что может стать требованием к системе кеширования — быстрая скорость чтения и в чуть меньшей степени – скорость записи. Это так, но только до тех пор, пока мы не выкатываем систему в продакшн.
Разыграем такой кейс.
Допустим, мы обеспечили железом текущую нагрузку и теперь понемногу внедряем кеширование. Немного прирастает пользователей, растет нагрузка – немного добавляем кешей, прикручиваем то тут, то там. Так продолжается некоторое время, и вот тяжеловесные функции уже практически не вызываются — вся основная нагрузка ложится на кеш. Количество пользователей за это время выросло в N раз.
И если начальный запас по железу мог быть 2-5 раз, то с помощью кеша мы могли подтянуть производительность раз в 10 или, в хорошем случае раз в 100, местами, возможно, и в 1000. То есть, на том же железе – обрабатываем в 100 раз больше запросов. Замечательно, заслужили пряник!
Но теперь, в один прекрасный момент, случайно, система дала сбой и кеш рухнул. Ничего особенного – ведь кеш выбрали по требованию «высокая скорость чтения и записи, остальное неважно».
Относительно стартовой нагрузки запас по железу у нас был 2-5 раз, а нагрузка за это время подросла в 10-100 раз. С помощью кеша мы исключали вызовы для тяжелых функций и поэтому все летало. А теперь, без кеша – во сколько раз у нас система просядет? Что у нас произойдет? Система ляжет.
Даже если у нас кеш не рухнул, а только очистился на некоторое время – его нужно будет прогревать, и это займет некоторое время. И на это время – основная нагрузка ляжет на функционал.
Вывод: высоконагруженные проекты в проде требуют от системы кеширования не только высокой скорости чтения и записи, но также сохранности данных и устойчивости к сбоям.
Муки выбора
В проекте с админкой – выбор прошел так: сначала поставили Hazelcast, т.к. уже были знакомы с этим продуктом по опыту основного сайта. Но, здесь такой выбор оказался неудачным – под наш профиль нагрузки Hazelcast работает не просто медленно, а жутко медленно. А под сроками вывода в прод мы на тот момент уже подписались.
Спойлер: как именно сложились обстоятельства, что мы пропустили такую плюху и получили острую и напряженную ситуацию – я расскажу во второй части — и как оказались, и как выбрались. Но сейчас — скажу только, что это был сильный стресс, и «думать – как-то не думается, трясем бутылку». «Трясем бутылку» — это тоже спойлер, про это чуть дальше.
Что мы сделали:
- Составляем список из всех систем, которые подсказывает google и StackOverflow. Чуть больше 30
- Пишем тесты с нагрузкой, характерной для продакшн. Для этого записали данные, которые проходят через систему в продакшн-окружении — эдакий сниффер для данных не в сети, но внутри системы. В тесты запускали ровно эти данные
- Всей командой, каждый выбирает следующую систему из списка, настраивает, прогоняет тесты. Не проходит тест, не тянет нагрузку – выбрасываем, переходим к следующей в очереди.
- На 17-й системе стало понятно, что все безнадежно. Хватит «трясти бутылку», пора серьезно подумать.
Но это вариант, когда нужно выбрать систему, которая «пролезет по скорости» в заранее подготовленных тестах. А если таких тестов еще нет и хочется выбрать побыстрее?
Смоделируем такой вариант (сложно представить, что миддл+ разработчик живет в вакууме, и на момент выбора еще не оформил предпочтение, какой продукт пробовать в первую очередь — поэтому, дальнейшие рассуждения это, скорее теоретика/философия/про джуниора).
Определившись с требованиями, начнем выбирать решение из коробки. Зачем изобретать велосипед: мы пойдем и возьмем готовую систему кеширования.
Если вы только начинаете и будете гуглить, то плюс-минус очередность, но в целом, ориентиры будут такие. В первую очередь вы наткнетесь на Redis, он везде на слуху. Потом узнаете, что есть EhCache как самая давняя и проверенная система. Дальше будет написано про Tarantool — отечественную разработку, в которой есть уникальный аспект решения. И также Ignite, потому что он сейчас на подъеме популярности и пользуется поддержкой СберТеха. В конце еще Hazelcast, потому что в enterprise-мире он часто мелькает в среде крупных компаний.
Этим список не исчерпывается, систем существуют десятки. А прикрутим мы только одно. Возьмем выбранные 5 систем на «конкурс красоты» и проведем отбор. Кто будет победителем?
Redis
Читаем, что пишут на официальном сайте.
Redis — opensource-проект. Предлагает in-memory хранилище данных, возможность сохранения on-disk, авторазбивку на партиции, высокую доступность и восстановление после сетевых разрывов.
Вроде бы, все отлично, можно брать и прикручивать — все что нужно, он делает. Но посмотрим просто ради интереса на остальных кандидатов.
EhCache
EhCache — «наиболее широко используемый кеш для Java»(перевод лозунга с официального сайта). Тоже opensource. И тут понимаем, что Redis не под java, а общий, и для взаимодействия с ним нужна обертка. А EhCache будет поудобнее. Что еще обещает система? Надежность, проверенность, полнофункциональность. Ну и еще она самая распространенная. И кеширует терабайты данных.
Redis забыт, я готов выбрать EhCache.
Но чувство патриотизма меня толкает посмотреть, чем хорош Tarantool.
Tarantool
Tarantool — встречает обозначением «Платформа интеграции данных в режиме реального времени». Очень сложно звучит, поэтому читаем страницу подробно и находим громкое заявление: «Кеширует 100% данных в оперативной памяти». Это должно вызвать вопросы — ведь данных может быть значительно больше, чем памяти. Расшифровка в том, что здесь подразумевается, что для записи данных на диск из памяти Tarantool не прогоняет сериализацию. Вместо этого – использует низкоуровневые особенности системы, когда память просто мэпится на файловую систему с весьма хорошими показателями I/O. В общем, сделали как-то замечательно и классно.
Посмотрим на внедрения: Mail.ru корпоративная магистраль, Авито, Билайн, Мегафон, Альфа-Банк, Газпром…
Если оставались еще какие-то сомнения по поводу Tarantool, то кейс внедрения в Mastercard меня добивает. Беру Tarantool.
Но все-таки…
Ignite
… есть еще Ignite, заявлен как «in-memory вычислительная платформа… in-memory скорости на петабайтах данных». Здесь тоже много плюсов: распределенный in-memory кеш, самое быстрое key-value хранилище и кеш, горизонтальное масштабирование, высокая доступность, строгая целостность. В общем, оказывается, самый быстрый – это Ignite.
Внедрения: Сбербанк, American Airlines, Yahoo! Japan. А потом я еще узнаю, что Ignite не просто в Сбербанке внедрен, а команда СберТеха своих людей отправляет в команду самого Ignite, дорабатывать продукт. Это полностью подкупает и я готов взять Ignite.
Совершенно непонятно зачем, я смотрю на пятый пункт.
Hazelcast
Захожу на сайт Hazelcast, читаю. И оказывается, самое быстрое-то решение для распределенного кеширования — это Hazelcast. Он на порядки быстрее всех других решений и вообще он — лидер в области in-memory data grid. На фоне этого взять что-то другое — себя не уважать. А еще использует избыточное хранение данных для непрерывной работы кластера без потерь данных.
Все, я готов взять Hazelcast.
Сравнение
Но если посмотреть, то все пять кандидатов так расписаны, что каждый из них – самый лучший. Как выбрать? Можем посмотреть, какой из них самый популярный, поискать сравнения, и головная боль пройдет.
Находим такой обзор, выбираем наши 5 систем.
Здесь они отсортированы: наверху Redis, на втором месте — Hazelcast, набирают популярность Tarantool и Ignite, EhCache как был, так и остается.
Но посмотрим на метод расчета: ссылки на вебсайты, общий интерес к системе, job offers — здорово! То есть, когда у меня упадет система, я скажу: «Нет, она же надежная! Вот много предложений о работе…». Такое простое сравнение не подойдет.
Все эти системы — не просто системы для кэширования. У них еще очень много функционала, в том числе – когда не данные перекачиваются клиенту на обработку, а наоборот: код, который надо выполнить над данными, переезжает на сервер, там выполняется, и результат возвращается. И как отдельную систему для кэширования их не так-то часто и рассматривают.
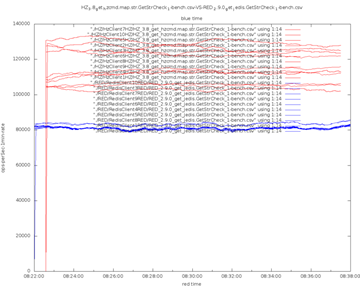
Хорошо, не сдаемся, найдем прямое сравнение систем. Возьмем два верхних варианта — Redis и Hazelcast. Нас интересует скорость, по этому параметру их и сравним.
Hz vs Redis
Находим такое сравнение:
Синий — это Redis, красный Hazelcast. Hazelcast везде выигрывает, и этому дано обоснование: он многопоточный, высоко оптимизированный, каждый поток работает со своей партицией, поэтому нет блокировок. А Redis — однопоточный, от современных многоядерных CPU он выигрыш не берет. У Hazelcast асинхронное I/O, у Redis-Jedis — блокирующие socket’ы. В конце концов, Hazelcast использует бинарный протокол, а Redis ориентирован на текст, то есть он неэффективный.
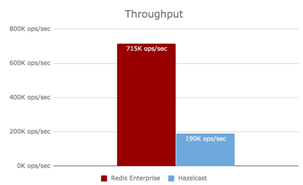
На всякий случай обратимся к еще одному источнику сравнения. Что он нам покажет?
Redis vs Hz
Еще одно сравнение:
Здесь наоборот, красный — это Redis. То есть, Redis по производительности выигрывает у Hazelcast. В первом сравнении выигрывал Hazelcast, во втором — Redis. Здесь же очень точно объяснили, почему в предыдущем сравнении выиграл Hazelcast.
Оказывается, результат первого был фактически подтасован: Redis взяли в базовой коробке, а Hazelcast заточили под тестовый случай. Тогда получается: во-первых, никому нельзя верить, во-вторых, когда мы все-таки выберем систему, нам еще нужно ее правильно настроить. Эти настройки включают в себя десятки, почти сотни параметров.
Трясем бутылку
И весь процесс, который мы сейчас проделали, я могу объяснить такой метафорой «Трясем бутылку». То есть, сейчас можно не программировать, сейчас главное — уметь читать stackoverflow. И у меня в команде есть человек, профессионал, который именно так и работает в критические моменты.
Что он делает? Он видит неработающую штуковину, видит stack trace, берет какие-то из него слова(какие именно — это его экспертиза в программе), ищет в гугле, находит stackoverflow среди ответов. Не читая, не вдумываясь, среди ответов на вопрос — он выбирает что-то наиболее похожее на предложение «сделать то и то» (выбрать такой ответ — это его талант, тк не всегда это именно тот ответ, который собрал больше лайков), применяет, смотрит: если что-то поменялось, то отлично. Если не поменялось — откатываем. И повторяем запуск-проверку-поиск. И таким интуитивным способом он добивается того, что через какое-то время код работает. Он не знает почему, он не знает, что он сделал, он не может объяснить. Но! Эта зараза работает. И «пожар потушен». Вот теперь разбираемся, что мы сделали. Когда программа работает — это на порядок легче. И значительно экономит время.
Вот этот способ очень хорошо объясняется на таком примере.
Когда-то было очень популярно собирать парусник в бутылке. При этом парусник большой и хрупкий, а горлышко у бутылки очень узенькое, его внутрь пропихнуть нельзя. Как его собрать?
Есть такой метод, очень быстрый и очень эффективный.
Корабль состоит из кучи мелочей: палочек, веревочек, парусов, клея. Все это кладем в бутылку.
Берем бутылку двумя руками, и начинаем трясти. Мы ее трясем-трясем. И обычно – получается полная фигня, конечно. Но иногда. Иногда получается корабль! Точнее, что-то похожее на корабль.
Мы это что-то показываем кому-то: «Серега, видишь!?». И действительно, издалека – как будто корабль. Но дальше это пускать нельзя.
Есть еще способ. Используют ребята более продвинутые, такие хакеры.
Дал такому парню задачу, он все сделал и ушел. И смотришь – вроде сделано. А через некоторое время, когда надо доработать код — там такое начинается из-за него… Хорошо, что он уже успел далеко отбежать. Это такие ребята, которые на примере бутылки сделают так: видите, там, где донышко – стекло изгибается. И не совсем понятно, прозрачно оно или нет. Тогда «хакеры» спиливают это донышко, вставляют туда корабль, донышко потом приклеивают заново, и как будто так и надо.
С точки зрения постановки задачи вроде бы все правильно. Но вот на примере кораблей: для чего вообще делать этот корабль, кому он вообще нужен? Функциональность он никакую не несет. Обычно такие корабли — это подарки очень высокопоставленным людям, которые ставят его на полочку над собой, как некоторый символ, как знак. И вот если у такого человека, руководителя крупного бизнеса или высокопоставленного чиновника, как флаг будет стоять такая халтура, у которой спилено горлышко? Лучше будет, если он об этом никогда не узнает. Так, а как же в итоге делают эти корабли, которые можно подарить важному человеку?
Единственное место, ключевое, с которым действительно ничего нельзя поделать, это корпус. И корпус корабля как раз в горлышко проходит. Тогда как корабль собирается за пределами бутылки. Но это не просто собрать корабль, это настоящее ювелирное ремесло. В составные части добавляются специальные рычажки, которые позволяют потом их поднять. Например, складываются паруса, аккуратно заносятся внутрь, и потом с помощью пинцета очень ювелирно, точно, их подтягивают и поднимают. В результате получается произведение искусства, которое можно с чистой совестью и гордостью подарить.
И если мы хотим, чтобы проект был успешный – в команде должен быть хотя бы один человек-ювелир. Тот, кто заботится о качестве продукта и учитывает все аспекты, не жертвуя ни одним даже в моменты стресса, когда обстоятельства требуют сделать срочное в ущерб важному. Все успешные проекты, которые устойчивы, которые выдержали проверку временем, они построены на этом принципе. В них есть что-то очень точное и уникальное, что-то, что использует все доступные возможности. В примере с кораблем в бутылке – обыгрывается то, что корпус корабля проходит через горлышко.
Возвращаясь к задаче выбора нашего сервера кэширования, как этот способ можно было бы применить? Я предлагаю такой вариант выбора из всех систем, что есть — не трясти бутылку, не выбирать, а посмотреть, что в принципе в них есть такого, на что обращать внимание при выборе системы.
Где искать bottle-neck
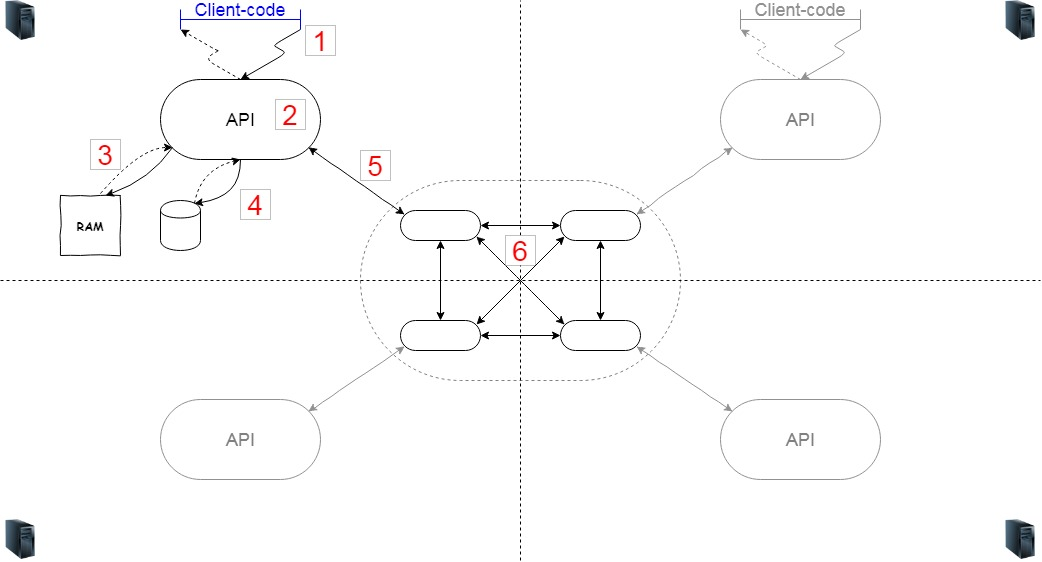
Попробуем не трясти бутылку, не перебирать все что есть по очереди, но посмотрим, какие задачи возникнут, если вдруг, под свою задачу – спроектировать такую систему самостоятельно. Собирать велосипед, конечно же не будем, но воспользуемся этой схемой, чтоб сориентироваться, на какие моменты обращать внимание в описаниях продуктов. Набросаем такую схему.
Если система распределенная, значит, у нас будет несколько серверов (6). Допустим, четыре (удобно разместить на картинке, но, конечно, их может быть сколько угодно). Если серверы на разных узлах, значит, на них всех крутится некоторый код, отвечающий за то, чтобы эти узлы образовали кластер и в случае разрыва – соединялись, узнавали друг друга.
Еще нужен код-логика (2), которая собственно про кеширование. С этим кодом по некоторому API взаимодействуют клиенты. Клиентский код (1) может быть как в рамках этой же JVM, так и обращаться к нему по сети. Логика, реализованная внутри – это решения, какие объекты в кеше оставлять, какие выкидывать. Для хранения кеша используем память (3), но если потребуется, часть данных можем и на диске сохранить (4).
Посмотрим, в каких частях будет возникать нагрузка. Собственно, нагружаться будут каждая стрелочка и каждый узел. Во-первых, между клиентским кодом и api, если это сетевое взаимодействие, проседание может быть довольно заметным. Во-вторых, в рамках самого api — перестаравшись со сложной логикой, можем упереться в CPU. И хорошо бы, чтоб логика не гоняла память лишний раз. И остается взаимодействие с файловой системой – в обычном варианте это сериализовать / восстановить и записать / считать.
Дальше взаимодействие с кластером. Скорее всего, он будет в этой же системе, но может быть и отдельно. Здесь тоже нужно учитывать передачу данных к нему, скорость сериализации данных и взаимодействия между кластером.
Теперь, с одной стороны – мы можем представить, «какие шестеренки будут крутиться» в кеш-системе при обработке запросов от нашего кода, и с другой стороны – мы можем прикинуть, какие и сколько запросов наш код к этой системе сгенерирует. Этого достаточно, чтобы сделать более-менее трезвый выбор – подобрать систему под наш вариант использования.
Hazelcast
Посмотрим, как такое разложение применить к нашему списку. Например, Hazelcast.
Для того чтобы положить/взять данные из Hazelcast, клиентский код обращается (1) к api. Hz позволяет запустить сервер как embedded, и в этом случае обращение к api – это вызов метода внутри JVM, можно считать бесплатно.
Чтобы отработала логика в (2), Hz опирается на хеш от байт-массива сериализованного ключа – то есть, сериализация ключа произойдет в любом случае. Это неизбежный overhead для Hz.
Eviction-стратегии реализованы хорошо, но для особых случаев – можно подключать свои. За эту часть можно не беспокоиться.
Хранилище (4) можно подключать. Отлично. Взаимодействие (5) для embedded можно считать моментальным. Обмен данными между узлами в кластере (6) – да, он есть. Это вклад в пользу отказоустойчивости ценой скорости. Снизить цену позволяет Hz-фича Near-cache – данные полученные из других нод кластера будут закешированы.
Что можно в таких условиях сделать для повышения скорости?
Например, чтоб избежать сериализации ключа в (2) – поверх Hazelcast прикрутить еще один кеш, для наиболее горячих данных. В Спортмастер для этой цели выбрали Caffeine.
Для подкрутки на уровне (6), в Hz предложены два типа хранения: IMap и ReplicatedMap.
Стоит сказать, как Hazelcast попал в стек технологий Спортмастер.
В 2012 году, когда мы работали над самым первым пилотом будущего сайта, именно Hazelcast оказался первой ссылкой, которую выдал поисковик. Знакомство завязалось «с первого раза» — нас подкупило то, что всего через два часа, когда мы прикрутили Hz в систему — он работал. И работал хорошо. До конца дня дописали сколько-то тестов, порадовались. И этого запаса бодрости хватило, чтоб преодолеть те сюрпризы, которые Hz подкидывал со временем. Сейчас у команды Спортмастер нет поводов для того, чтобы от Hazelcast отказываться.
Но такие аргументы, как «первая ссылка в поисковике» и «быстро собрали HelloWorld» — это, конечно, исключение и особенность момента, в котором проходил выбор. Настоящие испытания для выбранной системы начинаются с выходом в прод, и именно на этот этап стоит обратить внимание при выборе любой системы, в том числе и кеша. Собственно, в нашем случае можно сказать, что выбрали Hazelcast случайно, но потом оказалось, что выбрали правильно.
Для продакшн много важнее: мониторинг, обработка сбоев на отдельных узлах, репликация данных, стоимость масштабирования. То есть, стоит обратить внимание на задачи, которые возникнут как раз в сопровождении системы – когда нагрузка в десятки раз превысит запланированную, когда случайно зальем что-то не то и не туда, когда потребуется выкатить новую версию кода, заменить данные и сделать это незаметно для клиентов.
Для всех этих требований, Hazelcast, безусловно подходит.
To be continued
Но Hazelcast — это не панацея. В 2017 году мы выбрали Hazelcast для кеша в админке, просто опираясь на доброе впечатление от прошлого опыта. Это сыграло ключевую роль в очень злой шутке, из-за чего мы оказались в сложной ситуации и «героически» выбирались из нее 60 дней. Но об этом, в следующей части.
А пока… Happy New Code!




maxim_ge
Можно поподробнее, что такое «кеш рухнул»? В чем конкретно это выражалось на клиентской и серверной частях и как долго продолжалось?
Интересно! Хотелось бы деталей касательно профиля.
miptalex Автор
Очень подробный и точный ответ дан в предыдущем комментарии, от miksir
Добавлю только, что прогрев кеша на продакшн-объемах данных — в редкой системе не приведет к выходу даунтайма за рамки SLA.
maxim_ge
Можно здесь конкретизировать, в цифрах? Скорость прогрева кэша, каковы рамки SLA?
miptalex Автор
для админки к товарному контуру, в 2017 было требование прогонять все данные за 10 минут. Прогреть кеш — в нашем случае можно было только запустив ETL на всех данных. Это порядка 30Гб сериализованных данных для результатов промежуточных вычислений.
maxim_ge
Благодарю — то, что надо!
Однако ж, еще пара вопросов, если можно.
1) Какова была архитектура кеша до падения ( количество узлов, распределенность/репликация?)
2) 30Гб — что это за данные, вкратце? Описание товаров/складов/пользователей/счетов или что-то еще типа заказов/оплат/списаний?
miptalex Автор
1. На первых порах взяли IMap с репликацией 1, в кластере из 4 узлов. То есть, для каждого шарда в кластере есть 2 узла, на которых он представлен. Но, когда узел «отваливался» из кластера — вот на нем то данных и не хватало.
Сейчас перешли на ReplicatedMap.
2. Здесь я указал данные по админке, которые нужны в ETL-расчетах — в основном для обеспечения вычислений по дельтам данных (флаги, что где проходило ранее). Немного про эту систему будет в следующей части статьи. И, возможно, подробно расскажу про наш дельта-процессор отдельным постом. Но это объемно и не скоро )
miptalex Автор
На проде мы такой неприятности не ловили. Подготовились благодаря тестам на uat.
Для Hazelcast версий 6-ти летней давности, при запуске в сетевом окружении того времени — узлы довольно часто теряли друг друга из вида, из-за чего кластер перестраивался. Потом кластер восстанавливался, но на некоторое время узел мог остаться без части данных. Потребовалось время, чтоб разобраться в настройках. Сейчас такой проблемы нет.
miptalex Автор
Профиль нагрузки в задачах админки того времени: put/get запросы в любой пропорции и за объектами любого размера.
Точной картинки спектра не сохранилось, но примерно:
* пропорция put/get в основном попадает в диапазон от 1:2 до 1:10, но есть несколько пиков в районе 1:100 и 1:10 000
* размер объектов — от небольших с 2-5 полями, до слонопотамов с 15 этажами вложенности (в сериализованном виде 10Кб, и несколько объектов поболее 100Кб)
на этом этапе Hazelcast кое-как устраивал. То есть, было плохо, в заданные рамки 10^5 RPS мы совершенно не укладывались, но была надежда, что можно что-то подкрутить, что-то вынести в специальный «горячий» кеш в памяти (тех самых итоговых слонопотамов, которых генерили в ETL). Была надежда, что потом еще что-нибудь в логике оптимизируем и будет нормально.
Но условия поменялись.
Добавилось очень, очень много запросов, когда по ключу нужно хранить только true/false.
И вот здесь стало совсем плохо.
То, что должны были выполнять за 10 минут — работало более 30 часов. То есть, через 30 часов тест прекратили, за сколько он отработал бы — осталось не известно.