
Coderik однажды отметил: "Фильтра Калмана много не бывает". Так же можно сказать и о теореме Байеса, ведь это с одной стороны так просто, но с другой стороны так сложно осмыслить его глубину.

На просторах YouTube есть замечательный канал Student Dave, однако последнее видео опубликовано шесть лет назад. На канале представлены обучающие видео, в которых автор рассказывает очень простым языком сложные вещи: теорему Байеса, фильтр Калмана и пр. Свой рассказ студент Дейв дополняет примером расчета в matlab.
Однажды мне очень помог его видео урок под названием “Итеративная байесовская оценка” (на канале ему соответствует плейлист “Iterative bayesian estimation: with MATLAB”). Я захотел, чтобы каждый мог познакомиться с объяснениями Дейва, но к сожалению проект не поддерживается. Сам Дейв не выходит на связь. Добавить перевод к видео нельзя, так как это должен инициировать сам автор. Обращение в youtube не дало результата, поэтому я решил описать материал в статье на русском языке и опубликовать там, где его больше всего оценят. Материал очень сильно переработан и дополнен, так как он прошёл через мое субъективное восприятие, поэтому выложить его как перевод было бы неуместно. Но саму соль объяснения я взял у Дейва. Его код я переписал на python, так как я сам в нем работаю и считаю хорошей заменой математическим пакетам.
Итак, если вы хотите глубже осмыслить тему теоремы Байеса, добро пожаловать.
Постановка задачи
Для того чтобы проиллюстрировать мощь теоремы Байеса для непрерывных случайных величин, Дейв предлагает рассмотреть задачу “байесовского ниндзя”. Суть задачи в следующем.

Есть ниндзя-математик, который очень не любит перепелов. Перепел прячется в кустах, а ниндзя сидит на дереве рядом. Ниндзя может одним решительным прыжком на перепела сразить его, но он не знает где точно находится перепел. При этом перепел и издает время от времени звук. По звуку ниндзя может определить местоположение перепела, но очень неточно. Теорема Байеса позволяет ниндзя по серии криков перепела определить местоположение перепела все точнее и точнее. И в какой-то момент количество криков позволит ниндзя нанести сокрушительный удар.
Если вы ознакомитесь с видео на канале, то узнаете, что ниндзя так и не удалось удачно спрыгнуть на перепела, но это уже другая история.
Одномерный случай
Ниндзя-математик видит кусты как ограниченную область по оси . Истинное положение перепелки пока неизвестно. Вероятность в каждой точке области поиска одна и та же. Априорное распределение равномерное.

В процессе наблюдения (ниндзя славились своей выдержкой) были получены замеров (гипотез) местонахождения.
К тому же ниндзя замерил дисперсию измерения положения перепелки по крику .
Благодаря теореме Байеса есть возможность из равномерного распределения получить нормальное, да и с дисперсией куда меньшей чем дисперсия измерения.
Теорема Байеса
где — уточненное распределение;
— распределение известное до опыта;
— распределение модели измерения (правдоподобие ).
Дисперсия распределения модели измерения известна ниндзя заранее. За математическое ожидание принимается точка пространства, а за случайную величину замер (вероятность гипотезы о том, что в этой точке пространства сидит перепелка при получении замера):
где — функция плотности нормального распределения;
— математическое ожидание;
— стандартное отклонение измерения;
— измеренная величина.
Данную формулу необходимо повторить для серии опытов (), каждый раз подставляя вместо априорного распределение апостериорное, которое было получено при предыдущем опыте.
На анимации ниже видно как меняется распределение от оценки к оценке.
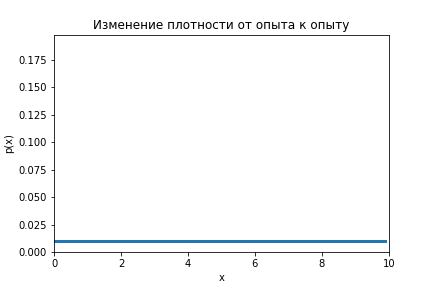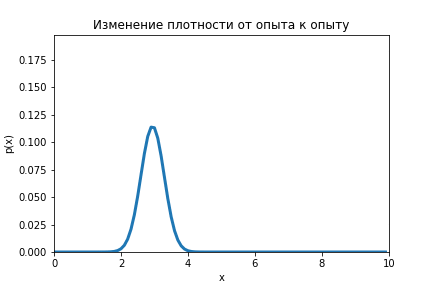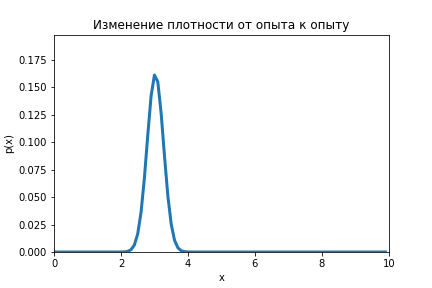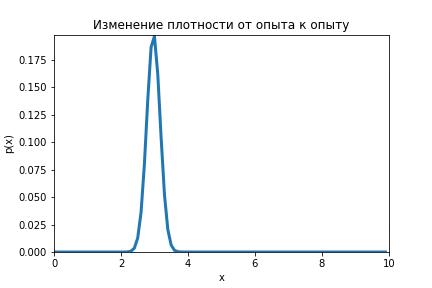
Код по ссылке.
Как только шесть уменьшатся до размера ноги ниндзя, он сможет нанести свой сокрушительный удар с вероятностью успеха в 99,7 %.
Двумерный случай
Так-то именно двумерный случай рассмотрен Дейвом, в отличие от одномерного случая.
Рассмотрим более реальную задачу. Ведь ниндзя всё таки смотрит на кусты сверху-вниз.
Истинное положение перепелки . Дисперсии (ковариационная матрица) и количество криков те же.
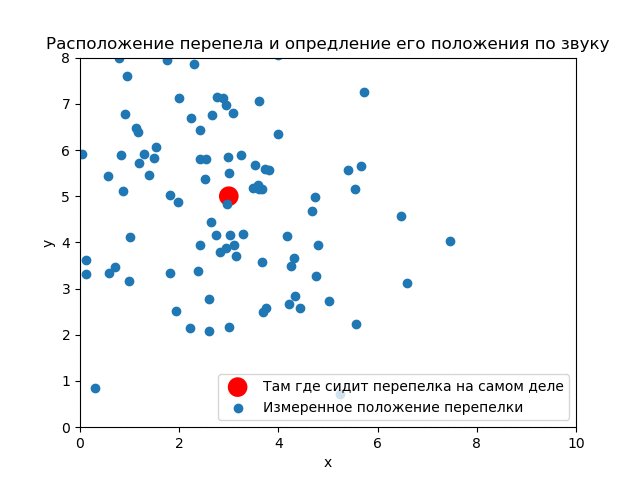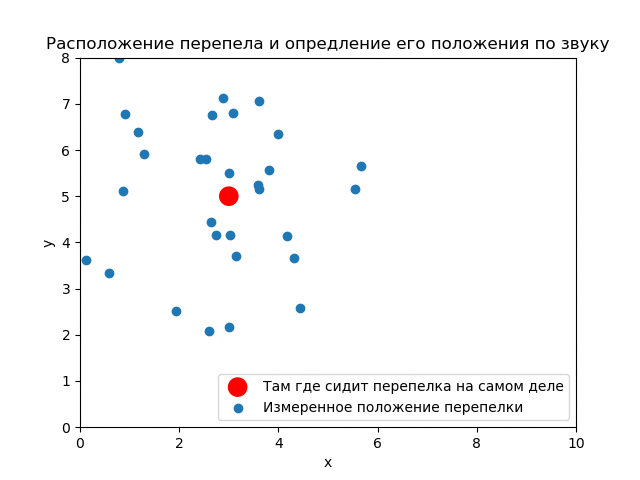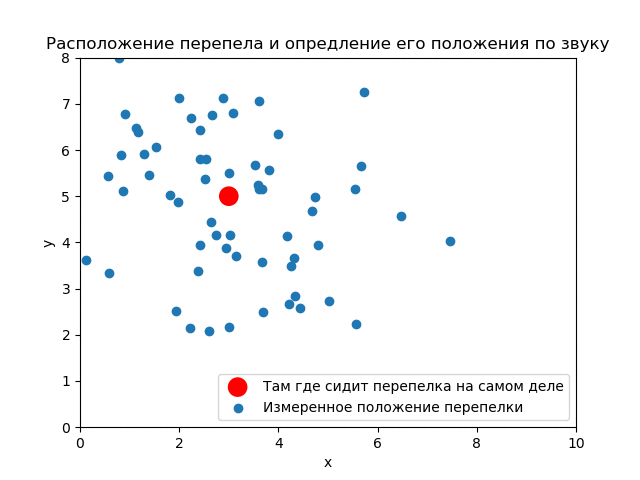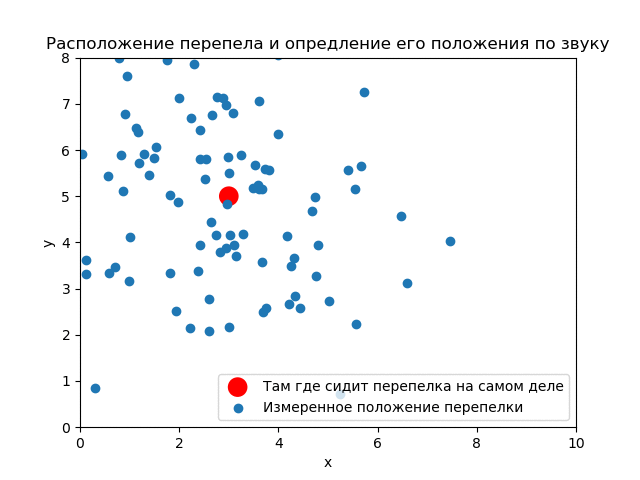
До опыта (априори) вероятность того, что перепелка будет в любом месте кустов одинакова. Априорное распределение равномерное.
Формула Байеса для непрерывных многомерных случайных величин примет вид:
где — вектор координат вида ;
— уточненное распределение;
— распределение известное до опыта;
— распределение модели измерения.
Распределение модели измерения:
где — ковариационная матрица;
— результат замера вида .
На анимации ниже видно, как меняется распределение от опыта к опыту.
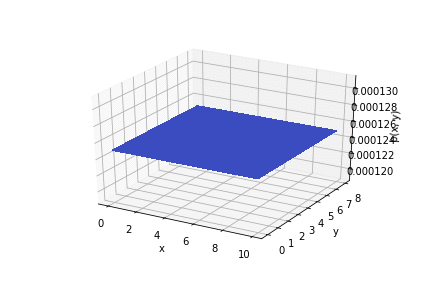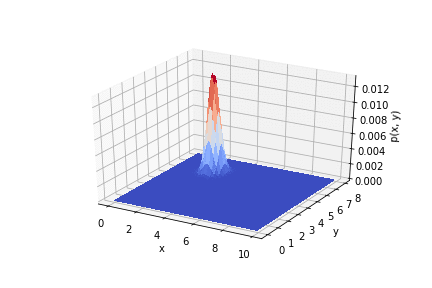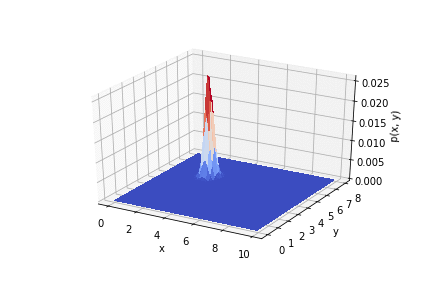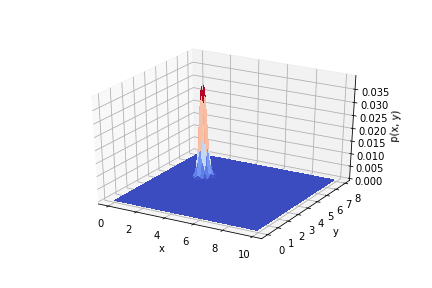
Код по ссылке.
Вывод
Таким образом видно, как результаты опыта влияют на априорное распределение.
Теорема Байеса очень необычная. Ты вроде её понял, но она не устает удивлять тебя своими применениями.
Заходите на канал Дейва в течении этих недель самоизоляции. Всем добра.
NeoCode
Уже не первый раз наталкиваюсь на статьи о невероятной глубине теоремы Байеса. Но мне как не математику интуитивно кажется, что это просто какое-то усреднение. Делаем N измерений, как-то усредняем и получаем что-то более-менее близкое к реальности. Чем больше измерений — тем ближе к реальности. Или я не прав и тут кроется какой-то очень глубокий смысл?
toyban
Так и есть. Если мы предпологаем, что распределение положения перепела нормальное, то для оценки его среднего и стандартного отклонения достаточно посчитать среднее выборки и среднее выборки квадратов. Байес тут вообще не причем.
Biga
Помните Акинатора? В первый раз очень удивляет, когда «угадывает мысли» за несколько простых вопросов. Там тоже Байес, на Хабре есть статьи про это.
rahmaevao Автор
Тут и кроется глубина)
Байес может «усреднить» распределение уже по одному результату. Он может выдать получившееся распределение (то какова вероятность в каждой области пространства)
Но по 100 опытам лучше все таки просто усреднить (дешевле вычислять).
toyban
А Вы не могли бы подробней описать, как Байес может оценить параметры нормального распределения по одному измерению? Что получится в итоге?
Как оценить среднее за одно измерение — это тривиально, да, но вот оценку стандартного отклонения — это уже за гранью моей фантазии.
rahmaevao Автор
Так об этом и статья. Формулы есть.

Можно поменять в коде количество экспериментов с 100 до одного.
Я сделал это. Вот результат. Получившееся СКО 1.6579451124819917.
Фишка в том, что по одному опыту строится распределение вероятности, а не просто средняя оценка.
toyban
Как же, однако, забавно получается. Вы знаете, что дисперсия криков перепела — 4, но при этом смогли получить оценку для этой величины меньше, чем она есть на самом деле, причем за одно измерение. Это как?
И еще одно замечание. Если Вы в курсе, что дисперсия криков — 4, это значит, что Вы как-то все же провели ее оценку, нет? А этого невозможно сделать за одно измерение.
Но и в этом случае априорное распределение положения перепела не может быть равномерным в области [-20, 20], как на картинке выше. Перепел может находиться только в интервале длиной sqrt(48).
И да, что Вы будете делать, когда Вам будет неизвестна дисперсия апостериорного распределения перед началом эксперимента, что бывает практически всегда? Как тут поможет Байес?
rahmaevao Автор
Ну вот так вот. Результат ведь формируется не по распределению измерения, а по функции правдоподобия.
Да, а эту дисперсию нужно получать кучей измерений.
Я взял [-20, 20] только чтобы интегрирование было пополнее. А в остальном немного не понял вопрос.
Апостериорное и ищем по теореме Байеса. Она как раз и помогает его найти.
toyban
Давайте я Вам расскажу, как это выглядит с моей стороны. Вот приходите Вы и утверждаете, что знаете способ оценки нормального распределения по одному измерению. Я говорю, что это невозможно, но Вы настаиваете на своем и даже предлагаете провести эксперимент.
Я из-за своего безмерного любопытства соглашаюсь на этот эксперимент. И пока я вожусь с генератором случайных нормально распределенных величин, Вы вспоминаете об одной детали: Вам надо знать дисперсию моего распределения.
Я, с одной стороны, удивлен столь неожиданным требованием, но с другой — теперь все становится понятно, ведь для оценки моего распределения вам осталось только уточнить среднее. А это уже можно сделать за одно измерение. Причем это тривиально.
Но, может, у Вас какой интересный метод, а потому я вполне согласен продолжить этот эксперимент. И вот я настроил генератор случайных чисел, чтоб он выдавал мне нормальные переменные с неким среднем и дисперсией, скажем, 4. И я Вам сообщил эту дисперсию, а также число, полученное из моего генератора.
Вы что-то у себя поколдовали и принесли мне оценку распределения моего генератора:
И тут Вы меня оставляете крайне озадаченным. Ведь Вы принесли мне нормальное распределение с дисперсией около 2.72, но я же Вам сам сказал, что дисперсия этого распределения — 4. Я не солгал и ничего не утаил, оно такое и есть.
И более того, этот факт Вы используете в своих расчетах. Вы не уточняете дисперсию с каждым измерением. Вы всегда используете дисперсию 4, когда оцениваете апостериорное распределение. Так откуда же взялось 2.72 у финальной оценки?
Из-за этого парадокса под вопросом становится надежность всего этого подхода.
PS. Кстати, у Вас что-то не так с вероятностями на картинках. У Вашего равномерного распределения полная вероятность — 0.1, если судить по голубой линии на графике. Подозреваю, что то же самое происходит и с нормальным.
rahmaevao Автор
Дорогой друг. Это здорово, что ты заинтересовался темой.
Я рад этой беседе (без подкола). Так мы сможем улучшить материал, в случае ошибки.
Чтобы более структурировано вести диалог, я хотел бы уточнить суть твоей претензии.
Я попытаюсь тогда построить аргументацию, а то я немного не подгружаю о чем ты говоришь.
З. Ы. За равномерное распределение спасибо. Не учел шаг. И в статье та же проблема. Починю позже. Вчера только переехал в новую квартиру. Времени не так много.
toyban
Ну, вроде, в статье не приводится какая-то особая теорема Байеса для НСВ (кстати, что это?), чтоб с ней не соглашаться. А с самой теоремой тяжело не согласиться, так как ее доказательство — это просто следствие из определения условной вероятности, и выполняется она для любых событий (с небольшой оговоркой).
Это уже ближе к правде.
Я считаю, что применение теоремы Байеса в данном случае хоть и забавно, но абсолютно бессмысленно. Чтоб посчитать среднее распределения, нам надо просуммировать все измерения и разделить на их количество. Все! А дисперсию распределения Вы и так знаете.
Более того, Ваш результат получается противоречивым, что только добавляет недоверия этому подходу.
У меня критика к двум вещам: во-первых, к Вашему заявлению будто дисперсию можно оценить по одному измерению, чего невозможно сделать; во-вторых, что этот метод дает очень подозрительные результаты.
Вот Вы серьезно не видите проблемы в Ваших расчетах? У вас есть нормальное распределение с дисперсией 4 из которого Вы получаете случайные числа. И Вы знаете, что дисперсия этого распределения именно 4.
Вы ищете оценку этого распределения. Для этого используете другое нормальное распределение. И в результате каких-то вычислений Вы получаете распределение, у которого дисперсия серьезно отличается от оригинального. И такое было бы возможно (хотя маловероятно в случаях экспоненциально убывающих распределений), если б Ваши расчеты уточняли дисперсию с каждым измерением. Но они этого не делают! Вы на каждом шаге используете тот факт, что дисперсия первоначального распределения 4, но результирующее распределении дает меньшую дисперсию. И я спрашиваю Вас, как такое возможно? Почему результирующее распределение имеет дисперсию, которая отличается от оригинального, если Вы наперед знаете эту дисперсию?
Если совсем кратко — почему оценка распределения совсем не похожа на оригинальное распределение?