
Машинный перевод в последние годы получил очень широкое распространение. Наверняка, большинство моих читателей хоть раз пользовались сервисами Google.Translate или Яндекс.Перевод. Также вероятно, что многие помнят, что не так уж и давно, лет 5 назад пользоваться автоматическими переводчиками было очень непросто. Непросто в том смысле, что они выдавали перевод очень низкого качества. Под катом краткая и неполная история машинного перевода, из которой будет виден в этой задаче и некоторые его причины и последствия. А для начала картинка, которая показывает важную концепцию относительно машинного перевода:

Данная концепция называется концепцией «зашумленного канала» и пришла из радиотехники. В разных вариантах ее приписывают разным ученым, Найквисту, Кюпфмюллеру, Шеннону, но я в этом споре болею за нашего соотечественника — Владимира Александровича Котельникова, который в своей работе 1933 года доказал свою знаменитую теорему. Сама по себе эта теорема находится за пределами настоящей статьи, поэтому отсылаю заинтересовавшихся в Википедию.
Для нас же важно другое. Концепция шумного канала приложили к новому направлению — автоматическому машинному переводу. После окончания Второй Мировой войны наши заокеанские партнеры решили, что Советский Союз, показавший свою мощь, победив лучшую армию Европы и мира, представляет серьезную угрозу. Для купирования этой угрозы были предприняты разные действия, в том числе были начаты работы по автоматическому переводу с русского на английский. Понадобилось это потому, что Советский Союз производил чрезвычайно много информации — телепередачи, радио-переговоры, книги и журналы. А если учесть еще и переговоры наших союзников по организации Варшавского договора, то масштаб проблемы становился уже просто пугающим: обучить, а тем более содержать такую армию профессиональных переводчиков не представлялось возможным. И вот здесь родилась идея — давайте скажем, что текст на русском — это просто искаженный текст на английском, и попробуем алгоритмически восстановить «исходный» текст. Именно это и было предложено Уорреном Уивером (Warren Weaver) в 1949 году.
Концептуально это выглядит красиво, но встает вопрос, как это реализовать. Сильно забегая вперед по времени, реализовано это было на основании так называемого фразового перевода.
Но давайте пойдем по порядку. Какой самый простой способ перевода приходит на ум? Перевод по словарю — то есть берется готовый словарь, и все слова в предложении заменяются на их эквиваленты в другом языке. Именно такой подход был предложен небезызвестной компанией IBM в 1989 году. У данного подхода есть очевидный недостаток: порядок слов в разных языках может отличаться, и порой весьма сильно. Следующий шаг в данной модели — это допустить перестановки слов. А каким образом можно предсказать данные перестановки? В той же работе была предложена другая модель (если первая называется Model 1, то вторая называется очень логично Model 2). В этой системе помимо словаря есть так называемая модель выравнивания (alignment) — соотнесения слов в двух предложениях между собой. Выравнивание выучивается на основе статистики по корпусу. Очевидным недостатком данной модели является также то, что для подготовки корпуса, в котором сделано выравнивание, требуются очень значительные усилия, профессиональные переводчики должны не просто перевести текст, но и указать, какое слово является переводом какого.
Стоит отметить, что помимо разного порядка слов существует еще, например, проблема того, что какие-то слова будут вовсе без перевода (например, артикли не существуют в русском языке), а какие-то слова будут для своего перевода требовать более, чем одно слово (например, предлог + существительное). Коллеги из IBM назвали это коэффициентом фертильности (fertility rate) и строили модели для него также на основании статистики. Это уже Model 3 (довольно предсказуемо, не правда ли?). В той же работе описаны еще несколько моделей, они развивают описанные идеи путем добавления условий на предсказание перевода слова — например, на предыдущее слово, так как некоторые слова лучше сочетаются между собой и поэтому встречаются чаще. Вся эта группа моделей дала начало так называемому фразовому переводу (phrase-based translation).
Это направление существовало и развивалось, в частности, был разработан открытый фреймворк для машинного перевода Moses (по официальному сайту можно заметить, что он несколько пришел в упадок). В свое время — это было основное средство машинного перевода, хотя в то время и машинный перевод не был так распространен. Но в 2014 году случилось страшное — глубокое обучение добралось и до области машинного перевода. Если вы помните годом ранее оно добралось до векторных представлений слов, я это описывал статье, посвященной эмбеддингам. А в 2014-ом вышла статья за авторством Дмитрия Богданова (и соавторов, одним из которых был знаменитый Йошуа Бенжио (Yoshua Bengio)) под названием Neural Machine Translation by Jointly Learning to Align and Translate (или — нейронный машинный перевод путем совместного обучения выравнивания и перевода). В этой работе Дмитрий предложил использовать механизм внимания для рекуррентных нейронных сетей и с помощью него смог побить вышеупомянутый Moses на существенную величину.
Здесь нужно сделать отступление и поговорить о том, как же измерять качество машинного перевода. В работе Папинени 2002-ого года была предложена метрика BLEU (bilingual evaluation understudy — изучение двуязычного сравнения). Эта метрика в своей основе сравнивает, сколько слов из машинного перевода совпало со словами из человеческого варианта. Потом сравниваются словосочетания из двух слов, трех, четырех. Все эти цифры усредняются и получается ровно одна цифра, описывающая качество работы системы машинного перевода на данном корпусе. У данной метрики есть свои недостатки, например, могут существовать разные человеческие варианты перевода одного текста, но как ни удивительно за почти 20 лет не было предложено ничего более хорошего для оценки качества перевода.
Но вернемся к механизму внимания. Следует сказать, что рекуррентные сети были предложены 15 годами ранее, и тогда не произвели никакого фурора. Существенная проблема этих сетей была в том, что они очень быстро забывали то, что «прочли». Частично решить эту проблему для машинного перевода и помог механизм внимания. Вот он на картинке:

Что же он делает? Он взвешивает слова на входе, чтобы дать один вектор слова для перевода. Именно это позволило автоматически строить матрицы выравнивания, на основе «сырого» текста без разметки. Например, такие:

После того, как все увидели, что так можно, большие усилия были брошены на машинный перевод, который стал самой быстро развивающийся областью обработки естесственного языка. Были достигнуты существенные улучшения качества, в том числе для далеких языковых пар, таких, как английский и китайский или английский и русский. Рекуррентные сети правили бал довольно долго по современным меркам — почти 4 года. Но в конце 2017 прозвучали трубы, возвещающие о приближении нового царя горы. Это была статья Attention is all you need (внимание — все, что тебе нужно; парафраз названия знаменитой песни The Beatles «All you need is love»). В этой статье была представлена архитектура трансформер, которая чуть менее, чем полностью состояла из механизмов внимания. Подробнее про нее я рассказывал в статье, посвященной итогам 2017 года, так что не буду повторяться.
С тех пор утекло довольно много воды, но тем не менее, осталось еще много интересного. Например, два года назад, в начале 2018 года исследователи из компании Майкрософт заявили о достижении равенства по качеству с человеческим переводом на переводе с английского на китайский новостных документов. Данная статья много критиковалась, прежде всего с той позиции, что достижение равных цифр по BLEU — это показатель не полной адекватности метрики BLEU. Но хайп был порожден.
Другое интересное направления развития машинного перевода — это машинный перевод без параллельных данных. Как вы помните, применение нейронных сетей позволило отказаться от разметки выравнивания в переводных текстах для обучения модели машинного перевода. Авторы работы Unsupervised Machine Translation Using Monolingual Corpora Only (машинный перевод с использованием только одноязычных данных) представили систему, которая в некоторым качеством была способна переводить с английского на французский (качество было, конечно, ниже тогдашних лучших достижений, но всего лишь на 10%). Что интересно, те же авторы улучшили свой подход с использованием идей фразового перевода позже в том же году.
Наконец, последнее, что хотелось бы осветить, это так называемый неавторегрессивный перевод. Что это такое? Все модели, начиная, с IBM Model 3 при переводе опираются на предыдущие уже переведенные слова. А авторы работы, которая так и называется — неавторегрессивный машинный перевод, — попробовали избавить от этой зависимости. Качество получилось также несколько меньше, зато скорость такого перевода может быть в десятки раз быстрее, чем для авторегрессивных моделей. Учитывая, что современные модели могут быть очень большими и неповоротливыми, это уже существенный выигрыш, особенно под большой нагрузкой.
Само собой, что область не стоит на месте и предлагаются новые идеи, например, так называемый back-translation, когда переведенные самой моделью одноязычные данные используются для дальнейшей тренировки; использование сверточных сетей, что также быстрее стандартного в наши дни трансформера; использование предобученных больших языковых моделей (про них у меня есть отдельная статья). Все, к сожалению, не перечислить.
В нашей компании работает один ведущих ученых в области машинного перевода — профессор Цунь Лю (Qun Liu). Профессор Лю и я ведем курс по обработке естественного языка, в котором существенное внимание уделено именно машинному переводу. Если вы заинтересовались этой областью, то вы еще можете присоединиться к нашему курсу, который начался месяц назад.
А если вы чувствуете в себе силы, то мы будем рады видеть вас среди участников нашего соревнования по переводу с китайского на русский! Соревнование начнется 14 апреля и продлится ровно месяц. Надеемся, что наши участники добьются новых результатов в этой задаче и смогут продвинуть всю область машинного перевода. Соревнование пройдет на платформе MLBootCamp, и мы очень благодарны команде MLBootCamp и лично Дмитрию Санникову за помощь в организации.
Ссылка на соревнование
Данная концепция называется концепцией «зашумленного канала» и пришла из радиотехники. В разных вариантах ее приписывают разным ученым, Найквисту, Кюпфмюллеру, Шеннону, но я в этом споре болею за нашего соотечественника — Владимира Александровича Котельникова, который в своей работе 1933 года доказал свою знаменитую теорему. Сама по себе эта теорема находится за пределами настоящей статьи, поэтому отсылаю заинтересовавшихся в Википедию.
Для нас же важно другое. Концепция шумного канала приложили к новому направлению — автоматическому машинному переводу. После окончания Второй Мировой войны наши заокеанские партнеры решили, что Советский Союз, показавший свою мощь, победив лучшую армию Европы и мира, представляет серьезную угрозу. Для купирования этой угрозы были предприняты разные действия, в том числе были начаты работы по автоматическому переводу с русского на английский. Понадобилось это потому, что Советский Союз производил чрезвычайно много информации — телепередачи, радио-переговоры, книги и журналы. А если учесть еще и переговоры наших союзников по организации Варшавского договора, то масштаб проблемы становился уже просто пугающим: обучить, а тем более содержать такую армию профессиональных переводчиков не представлялось возможным. И вот здесь родилась идея — давайте скажем, что текст на русском — это просто искаженный текст на английском, и попробуем алгоритмически восстановить «исходный» текст. Именно это и было предложено Уорреном Уивером (Warren Weaver) в 1949 году.
Концептуально это выглядит красиво, но встает вопрос, как это реализовать. Сильно забегая вперед по времени, реализовано это было на основании так называемого фразового перевода.
Но давайте пойдем по порядку. Какой самый простой способ перевода приходит на ум? Перевод по словарю — то есть берется готовый словарь, и все слова в предложении заменяются на их эквиваленты в другом языке. Именно такой подход был предложен небезызвестной компанией IBM в 1989 году. У данного подхода есть очевидный недостаток: порядок слов в разных языках может отличаться, и порой весьма сильно. Следующий шаг в данной модели — это допустить перестановки слов. А каким образом можно предсказать данные перестановки? В той же работе была предложена другая модель (если первая называется Model 1, то вторая называется очень логично Model 2). В этой системе помимо словаря есть так называемая модель выравнивания (alignment) — соотнесения слов в двух предложениях между собой. Выравнивание выучивается на основе статистики по корпусу. Очевидным недостатком данной модели является также то, что для подготовки корпуса, в котором сделано выравнивание, требуются очень значительные усилия, профессиональные переводчики должны не просто перевести текст, но и указать, какое слово является переводом какого.
Стоит отметить, что помимо разного порядка слов существует еще, например, проблема того, что какие-то слова будут вовсе без перевода (например, артикли не существуют в русском языке), а какие-то слова будут для своего перевода требовать более, чем одно слово (например, предлог + существительное). Коллеги из IBM назвали это коэффициентом фертильности (fertility rate) и строили модели для него также на основании статистики. Это уже Model 3 (довольно предсказуемо, не правда ли?). В той же работе описаны еще несколько моделей, они развивают описанные идеи путем добавления условий на предсказание перевода слова — например, на предыдущее слово, так как некоторые слова лучше сочетаются между собой и поэтому встречаются чаще. Вся эта группа моделей дала начало так называемому фразовому переводу (phrase-based translation).
Это направление существовало и развивалось, в частности, был разработан открытый фреймворк для машинного перевода Moses (по официальному сайту можно заметить, что он несколько пришел в упадок). В свое время — это было основное средство машинного перевода, хотя в то время и машинный перевод не был так распространен. Но в 2014 году случилось страшное — глубокое обучение добралось и до области машинного перевода. Если вы помните годом ранее оно добралось до векторных представлений слов, я это описывал статье, посвященной эмбеддингам. А в 2014-ом вышла статья за авторством Дмитрия Богданова (и соавторов, одним из которых был знаменитый Йошуа Бенжио (Yoshua Bengio)) под названием Neural Machine Translation by Jointly Learning to Align and Translate (или — нейронный машинный перевод путем совместного обучения выравнивания и перевода). В этой работе Дмитрий предложил использовать механизм внимания для рекуррентных нейронных сетей и с помощью него смог побить вышеупомянутый Moses на существенную величину.
Здесь нужно сделать отступление и поговорить о том, как же измерять качество машинного перевода. В работе Папинени 2002-ого года была предложена метрика BLEU (bilingual evaluation understudy — изучение двуязычного сравнения). Эта метрика в своей основе сравнивает, сколько слов из машинного перевода совпало со словами из человеческого варианта. Потом сравниваются словосочетания из двух слов, трех, четырех. Все эти цифры усредняются и получается ровно одна цифра, описывающая качество работы системы машинного перевода на данном корпусе. У данной метрики есть свои недостатки, например, могут существовать разные человеческие варианты перевода одного текста, но как ни удивительно за почти 20 лет не было предложено ничего более хорошего для оценки качества перевода.
Но вернемся к механизму внимания. Следует сказать, что рекуррентные сети были предложены 15 годами ранее, и тогда не произвели никакого фурора. Существенная проблема этих сетей была в том, что они очень быстро забывали то, что «прочли». Частично решить эту проблему для машинного перевода и помог механизм внимания. Вот он на картинке:
Что же он делает? Он взвешивает слова на входе, чтобы дать один вектор слова для перевода. Именно это позволило автоматически строить матрицы выравнивания, на основе «сырого» текста без разметки. Например, такие:
После того, как все увидели, что так можно, большие усилия были брошены на машинный перевод, который стал самой быстро развивающийся областью обработки естесственного языка. Были достигнуты существенные улучшения качества, в том числе для далеких языковых пар, таких, как английский и китайский или английский и русский. Рекуррентные сети правили бал довольно долго по современным меркам — почти 4 года. Но в конце 2017 прозвучали трубы, возвещающие о приближении нового царя горы. Это была статья Attention is all you need (внимание — все, что тебе нужно; парафраз названия знаменитой песни The Beatles «All you need is love»). В этой статье была представлена архитектура трансформер, которая чуть менее, чем полностью состояла из механизмов внимания. Подробнее про нее я рассказывал в статье, посвященной итогам 2017 года, так что не буду повторяться.
С тех пор утекло довольно много воды, но тем не менее, осталось еще много интересного. Например, два года назад, в начале 2018 года исследователи из компании Майкрософт заявили о достижении равенства по качеству с человеческим переводом на переводе с английского на китайский новостных документов. Данная статья много критиковалась, прежде всего с той позиции, что достижение равных цифр по BLEU — это показатель не полной адекватности метрики BLEU. Но хайп был порожден.
Другое интересное направления развития машинного перевода — это машинный перевод без параллельных данных. Как вы помните, применение нейронных сетей позволило отказаться от разметки выравнивания в переводных текстах для обучения модели машинного перевода. Авторы работы Unsupervised Machine Translation Using Monolingual Corpora Only (машинный перевод с использованием только одноязычных данных) представили систему, которая в некоторым качеством была способна переводить с английского на французский (качество было, конечно, ниже тогдашних лучших достижений, но всего лишь на 10%). Что интересно, те же авторы улучшили свой подход с использованием идей фразового перевода позже в том же году.
Наконец, последнее, что хотелось бы осветить, это так называемый неавторегрессивный перевод. Что это такое? Все модели, начиная, с IBM Model 3 при переводе опираются на предыдущие уже переведенные слова. А авторы работы, которая так и называется — неавторегрессивный машинный перевод, — попробовали избавить от этой зависимости. Качество получилось также несколько меньше, зато скорость такого перевода может быть в десятки раз быстрее, чем для авторегрессивных моделей. Учитывая, что современные модели могут быть очень большими и неповоротливыми, это уже существенный выигрыш, особенно под большой нагрузкой.
Само собой, что область не стоит на месте и предлагаются новые идеи, например, так называемый back-translation, когда переведенные самой моделью одноязычные данные используются для дальнейшей тренировки; использование сверточных сетей, что также быстрее стандартного в наши дни трансформера; использование предобученных больших языковых моделей (про них у меня есть отдельная статья). Все, к сожалению, не перечислить.
В нашей компании работает один ведущих ученых в области машинного перевода — профессор Цунь Лю (Qun Liu). Профессор Лю и я ведем курс по обработке естественного языка, в котором существенное внимание уделено именно машинному переводу. Если вы заинтересовались этой областью, то вы еще можете присоединиться к нашему курсу, который начался месяц назад.
А если вы чувствуете в себе силы, то мы будем рады видеть вас среди участников нашего соревнования по переводу с китайского на русский! Соревнование начнется 14 апреля и продлится ровно месяц. Надеемся, что наши участники добьются новых результатов в этой задаче и смогут продвинуть всю область машинного перевода. Соревнование пройдет на платформе MLBootCamp, и мы очень благодарны команде MLBootCamp и лично Дмитрию Санникову за помощь в организации.
Ссылка на соревнование
Exchan-ge
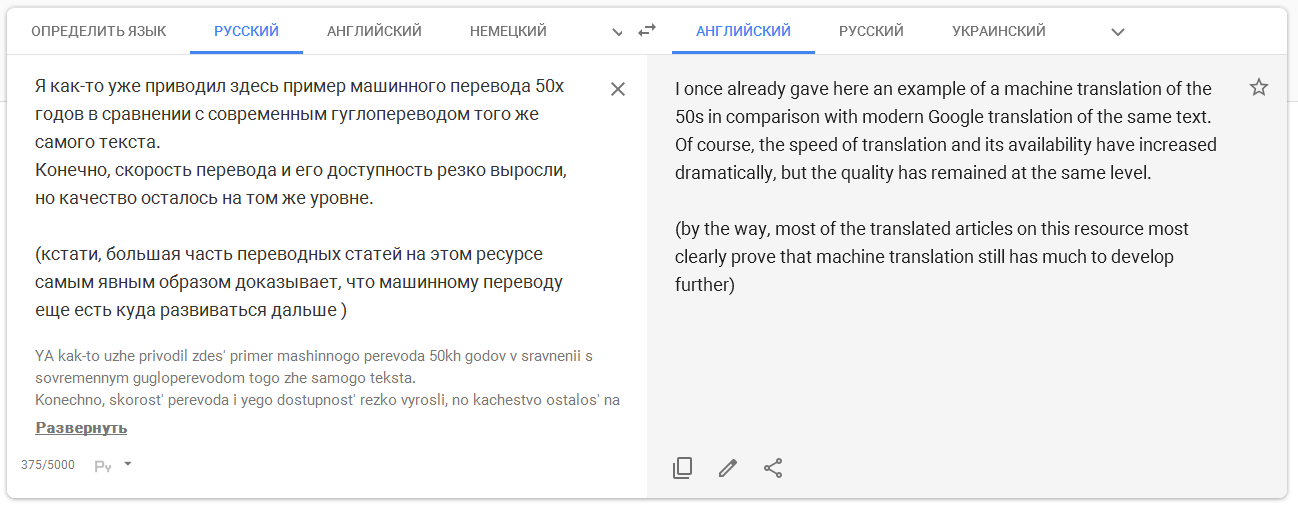
Я как-то уже приводил здесь пример машинного перевода 50х годов в сравнении с современным гуглопереводом того же самого текста.
Конечно, скорость перевода и его доступность резко выросли, но качество осталось на том же уровне.
(кстати, большая часть переводных статей на этом ресурсе самым явным образом доказывает, что машинному переводу еще есть куда развиваться дальше )
Of course, the transfer speed and its availability increased dramatically, but the quality remains at the same level.
(By the way, most of the translated articles on this resource thus clearly shows that the machine translation there is much more to develop further)
Zet_Roy
Английский язык очень специфический относительно русского языка, например фраза «make friends» можно перевести как «делать дружбу» или «совершать дружбу» а не «заводить дружбу», это конечно простая фраза и гугл переводит ее правильно, но все же подобных фраз десятки тысяч и вряд ли удастся исправить эту проблему.
Exchan-ge
Ну, вот этот результат поиска однозначно свидетельствует о том, что поисковая система Гугла правильно распознала значение слова «гуглперевод»:
найдя в этом составном слове «перевод».
Почему же переводчик от того же Гугла не смог сделать точно такое же действие?
(это, кстати, характерно и для других случаев, когда переводится составное слово — переводчик гугла иногда не способен распознать составные слова на английском языке)
Mingun
Эм, вот у меня, например, гуглоперевод выдал такой результат:
Так что всё распознаётся :)
Exchan-ge
Mingun
Я с сайта переводил:
Exchan-ge
Я верю.
Но и там и там, по идее — одна система.
(кстати о системе)
«4.4. The software is protected by laws of Russian Federation and international copyright treaties»
Гугл, вне контекста QTranslate — знает только одну QuestSoft.
Но как-то сомнительно, что QTranslate — это ее разработка.
Mingun
Ну, судя по всему, гугл через API, которым пользуется QTranslate, отдаёт перевод через более старую версию алгоритма (поскольку не вызывает сомнения тот факт, что на сайте будет использоваться самая новейшая версия, а с сайта и через API перевод различается, очевидно, что перевод через API использует более старую версию с качеством похуже).
HardNikKG
Извините, 15 лет занимаюсь проблемой создания машинного перевода с русского на тюркский и обратно. И, такое ощущение, что мы с Вами не коллеги. Написать статью о машинном переводе с/на русский без единого упоминания слов: Зализняк, AOT, Яндекс — для меня — шок. Мы с Вами живём в ортогональных вселенных. В любом случае — большое искреннее спасибо за статью, ибо, на самом деле, решение задачи — в комплексном анализе, симбиозе аналитического и статистического подходов.
madrugado Автор
стоит начать с того, что я не являюсь специалистом по машинному переводу непосредственно, я им занимался существенно меньше, чем другими задачами обработки естественного языка; но да, я приверженец статистического подхода, на мой взгляд использование словарей и сложных автоматов для словоизменения — это излишне, все может быть реализовано статистически; само собой не претендую на абсолютную истину, но в данный момент развитие области идет в направлении статистического обучения
к слову, в нашем курсе мы стараемся дать полную картину и те подходы, которые вы упоминаете, там тоже описываются
PerlPower
Были ли какие-то попытки доказать математически, что полноценный перевод возможен без понимания семантики слов, объектов и действий скрывающихся за ними, и то как они могут взаимодействовать?
Ну например измерить информацию об объектах несомую фразой на одном языке(пусть хотя бы количество признаков), и измерить ту же информацию для фразы языка на который сделан перевод. И если даже для небольших фраз количество признаков будет разниться для двух языков, то для более сложных конструкций тем более.
В принципе это происходит и в рамках одного языка при передаче сообщения от человека к человеку, где каждый рассказывая своими словами немного искажает смысл. И было бы разумно измерить среднее искажение количества признаков для одного языка для двух людей. А затем взять эту величину как эталонный критерий максимально допустимого искажения для перевода с одного языка на другой.
Короче говоря кто-то предпринимал в принципе попытки доказать возможность перевода без использования сильного ИИ?
Celsius
Вряд-ли можно доказать это математически, язык это такая аморфная структура, которую человек не может объяснить. У лингвистов есть несколько теорий, некоторые вполне себе рабочие, но все держится на каких-то костылях, есть пробелы в логике.
Взять, например, идеи Ноама Хомского. Можно для многих ситуаций сделать универсальные парсеры и генераторы, вроде-бы даже перевод неплохой получится. Но проблема в том, что большая часть языковых конструкций определяется временем и культурой. Если что-то в языке строго описать и захардкодить, то через десяток лет оно развалится из-за того, что язык, контекст, культура и носители постоянно меняются.
Тут только два пути — либо ждать, когда все языки сольются в один, либо создать сильный ИИ (второе как-то реалистичней).
Exchan-ge
Или ждать появления устройств, способных читать мысли (это как-то реалистичнее второго варианта)
SEN7759
Давно известен третий путь: вспомогательный международный язык — эсперанто. Он обладает таким важнейшим свойством: позволяет переводить на него почти дословно (для большинства языков Европы). Т.е. хороший посредник при переводе. Кроме того, относительно простая грамматика и логичность, в сочетании с выразительностью/гибкостью. Обученные роботы могли бы выразить и понять намного больше при использовании эсперанто.
Exchan-ge
Это и есть его главный недостаток.
(Центр мира сместился в Юго-восточную Азию, но мы этого еще не осознали).
SEN7759
Нет. Эсперантисты из восточных стран осваивают эсперанто намного быстрее, чем европейские языки (эсперанто близок им по способу словообразования, например, т.е. некоторая грамматическая близость есть; кроме того, он прост и логичен). Это они сами пишут.
Exchan-ge
Тут ключевое слово — «эсперантисты». Т.е. энтузиасты этого языка.
А, например, мои знакомые лингвисты-профессионалы считают, что китайский им выучить легче.
SEN7759
О! Назовите, пожалуйста, одного из них. Это будет исключительный пример. Обычно лингвисты знают базовый эсперанто (в программе есть), а многие полиглоты советуют с него начинать (поскольку там международные корни и потом остальные языки легче выучить).
Exchan-ge
Ближайший сидит в соседней комнате.
(не полиглот, но знает английский, немецкий, французский и шведский. Сейчас как раз учит китайский :)
SEN7759
Странно. Разговаривал пару месяцев назад с математиком Мартыновым, который знает 15 языков (включая китайский (мандарин)). Он сказал, что эсперанто настолько лёгкий, что он его играючи давно выучил и до сих пор помнит. Потом выдал речь на правильном эсперанто.
SEN7759
Мантуровым*
SEN7759
Китайцы пару лет эсперанто преподают в паре университетах и нескольких школах. Издают эл. журнал на эсперанто, переводят Курьер ЮНЕСКО на эсперанто (с согласия ЮНЕСКО, разумеется).
Exchan-ge
Это другая сфера.
У юристов, например, своя. Где и на родном языке есть тонкости в значении слов.
SEN7759
Было важно: он полиглот и его оценка простоты эсперанто
(а китайский по его мнению намного сложнее; корейский ещё сложнее). Меня очень удивило мнение Вашего полиглота. У меня ещё одина знакомая-полиглот (8 языков) считает китайский сложным для нее языком.
Exchan-ge
Конечно. Но тем интереснее его изучать. Тем более — с перспективой поехать в Китай на стажировку (пока сорвалось, по известным событиям).
Кстати, попробуйте изучить шведский, не зная до этого немецкого :)
А вот знание эсперанто вряд ли сможет в этом помочь.
SEN7759
И от темы отвлеклись и не убедили.
Exchan-ge
Уточню — знание эсперанто не помогает в изучении натуральных языков, но знание натуральных языков помогает в изучении эсперанто.
SEN7759
Сами проверяли :). Есть несколько исследований, Google в помощь.
malkovsky
А как же автоматическое выравнивание? Собственно решение от IBM
madrugado Автор
fast align — отличная штука, но он был сделан в 2013 году, а IBM Models — это на 20 лет раньше