

В первой части мы рассказали о том, почему решили поменять старую BMS-систему в наших ЦОДах на новую. И не просто поменять, а разработать с нуля под свои требования. Во второй части рассказываем, как мы это делали.
Анализ рынка
С учетом описанных в первой части пожеланий и решения отказаться от обновления существующей системы мы написали ТЗ для поиска решения на рынке и сделали запросы в несколько крупных компаний, занимающихся только созданием промышленных систем SCADA.
Первые же ответы от них показали, что лидеры рынка систем мониторинга преимущественно продолжают работать на железных серверах, хотя процесс миграции в облака в этом сегменте уже начался. Что касается резервирования виртуальных машин – эту опцию не поддерживал никто. Более того, складывалось ощущение, что никто из заметных на рынке разработчиков не продемонстрировал даже понимания необходимости резервирования: «облако же не падает» был наиболее частый ответ. Фактически нам предлагали разместить мониторинг ЦОДа в облаке, физически находящемся в этом же ЦОДе.
Тут надо сделать небольшое отступление о процессе выбора подрядчика. Цена, конечно, имеет значение, но во время любого тендера на реализацию сложного проекта, на стадии диалога с поставщиками ты начинаешь чувствовать, кто из кандидатов более заинтересован и способен реализовать его.
Это особенно заметно на сложных проектах.
По характеру уточняющих вопросов к ТЗ можно разделить подрядчиков на заинтересованных просто продать (ощущается стандартный напор менеджера по продажам) и на заинтересованных в том, чтобы разработать продукт, услышав и поняв заказчика, внести конструктивные правки в ТЗ еще до финального выбора (даже несмотря на реальный риск улучшить чужое ТЗ и проиграть тендер), в конце концов просто готовых принять профессиональный вызов и сделать хороший продукт.
Все это заставило нас обратить внимание на относительно небольшого локального разработчика – группу компаний «Санлайн», который откликнулся на большинство наших требований сразу и был готов реализовать все потребности касательно новой BMS.
Риски
Пока большие игроки пытались понять, что же мы хотим, и вели с нами неспешную переписку с привлечением специалистов уровня пресейл, локальный девелопер назначил встречу в нашем офисе с участием своей технической команды. На этой встрече подрядчик еще раз продемонстрировал желание участвовать в проекте и – главное – объяснил, как требуемая система будет реализована.
Перед встречей мы видели два риска работы с командой, не имеющей за спиной ресурса большой национальной или международной компании:
- Специалисты могли переоценить свои возможности и в результате просто не справиться, например, будут использовать сложный софт или спроектируют невыполнимые алгоритмы резервирования.
- После реализации проекта команда проекта может распасться и, следовательно, поддержка продукта окажется под угрозой.
Чтобы минимизировать эти риски, мы пригласили на встречу собственных специалистов по разработке. Сотрудники потенциального подрядчика были тщательно опрошены на предмет того, на чем строится система, как планируется реализовывать резервирование и по другим вопросам, в которых мы, как служба эксплуатации, недостаточно компетентны.
Вердикт был положительным: архитектура имеющейся уже платформы BMS современна, проста и надежна, может быть доработана, предлагаемая схема резервирования и синхронизации логична и работоспособна.
С первым риском справились. Второй исключили, получив от подрядчика подтверждение о готовности передать нам исходники кода системы и документации, а также выбрав язык программирования Python, хорошо знакомый нашим специалистам. Это гарантировало нам возможность поддерживать систему своими силами без каких-либо затруднений и длительного периода обучения сотрудников в случае ухода компании-разработчика с рынка.
Дополнительным плюсом платформы являлось то, что она была реализована в Docker контейнерах: в этой среде функционируют ядро, веб-интерфейс и БД продукта. Такой подход дает множество преимуществ, включая предустановку настроек для высочайшей скорости развертывания решения по сравнению с «классикой» и простое добавление в систему новых устройств. Принцип «все вместе» максимально упрощает внедрение системы: достаточно распаковать систему и можно сразу ее эксплуатировать.
С таким решением проще делать копии системы, а усовершенствовать ее и реализовывать апгрейды можно в отдельной среде, без остановки работы решения в целом.
После того как оба риска были минимизированы, подрядчик предоставил КП. В нем были проработаны все самые важные для нас параметры системы BMS.
Резервирование
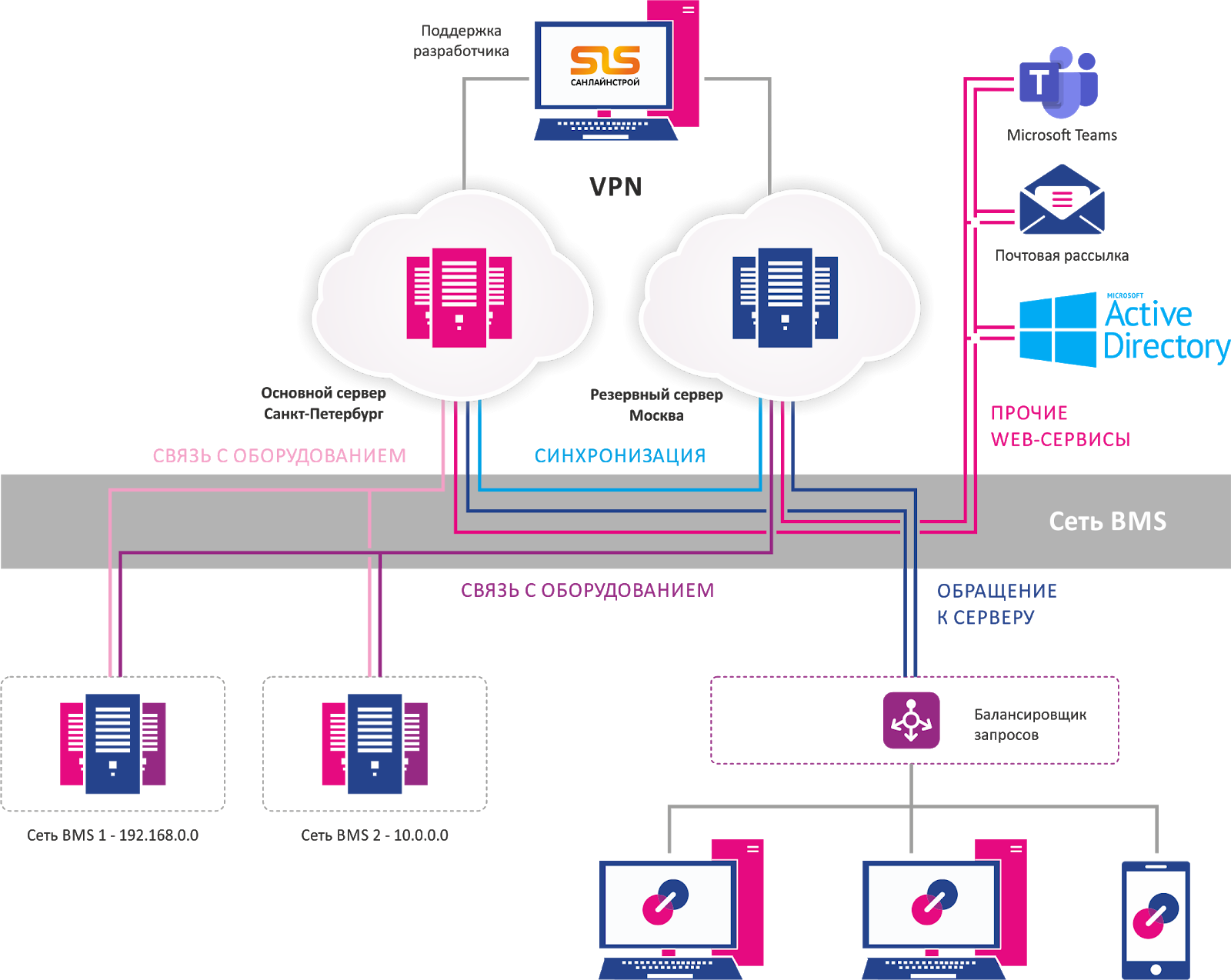
Новая BMS-система должна была находиться в облаке, на виртуальной машине.
Никакого железа, никаких серверов и всех связанных с этой моделью развертывания неудобств и рисков – облачное решение позволяло нам избавиться от них навсегда. Было решено, что система будет работать в нашем облаке на двух площадках ЦОДа в Санкт-Петербурге и Москве. Это две полностью функциональные системы, работающие в режиме active standby с доступом для всех авторизованных специалистов.
Две системы страхуют друг друга, обеспечивая полный резерв и по вычислительным мощностям, и по каналам передачи данных. Также настроены дополнительные меры безопасности, включая резервное копирование данных и каналов, систем, виртуальных машин в целом, и отдельное резервное копирование БД раз в месяц (самый ценный ресурс в перспективе управления и анализа).
Отметим, что резервирование как опция BMS-решения было разработано специально под наш запрос. Сама схема резервирования выглядела вот так:
Поддержка
Важнейший момент для эффективной эксплуатации BMS-решения – техподдержка.
Здесь все просто: новая система стоила бы нам по этому показателю 35 000 руб. в месяц за SLA «реакция в течение 8 часов», то есть 35 000 х 12 / 80 = $5 250 в год. Первый год – бесплатно.
Для сравнения: поддержка старой BMS от вендора обходилась в $18 000 долларов в год с увеличением суммы за каждое новое добавленное устройство! При этом выделенного менеджера компания не предоставляла, все взаимодействие происходило через менеджера по продажам, который заинтересован в нас как в потенциальном покупателе с соответствующим акцентом в обработке запросов.
За меньшие деньги мы получили полноценную поддержку продукта, с аккаунт-менеджером, который принимал бы участие в разработке продукта, с единой точкой входа и т.д. Поддержка становилась на порядок более гибкой – благодаря прямому доступу к разработчикам для оперативных корректировок по любым аспектам работы системы, интеграции через API и т.д.
Обновления
По предложенному КП в новой BMS все обновления включены в стоимость поддержки, т.е. не требуют дополнительной оплаты. Исключение составляет разработка дополнительной функциональности, сверх той, что указана в ТЗ.
Старая система предполагала оплату как за обновление встроенного бесплатного ПО (типа Java), так и за исправление ошибок. Отказаться от этого было нельзя, при отсутствии обновлений система в целом «тормозила» из-за старых версий внутренних компонентов.
И, само собой, нельзя было обновить ПО без покупки пакета поддержки.
Гибкий подход
Еще одно принципиальное требование касалось интерфейса. Мы хотели обеспечить доступ к нему через веб-браузер из любой точки, без обязательного присутствия инженера на территории ЦОДа. Кроме того, мы стремились к созданию анимированного интерфейса, чтобы динамика функционирования инфраструктуры была более наглядной для дежурных инженеров.
Также в новой системе нужно было обеспечить поддержку формул для обсчета работы виртуальных датчиков в инженерных системах – например, для оптимального распределения электрических мощностей по стойкам с оборудованием. Для этого нужно иметь в своем распоряжении все привычные математические операции, применимые к показателям датчиков.
Далее, требовался доступ к базе данных SQL с возможностью брать из нее нужные данные о работе оборудования – а именно, все записи о мониторинге двух тысяч устройств и двух тысяч виртуальных датчиков, генерирующих примерно 20 тысяч переменных.
Нужен был также модуль учета оборудования в стойке, дающий графическое представление расположения устройств в каждом юните с подсчетом общего веса «железа», ведением библиотеки устройств и подробной информацией о каждом элементе.
Согласование ТЗ и подписание договора
На тот момент, когда было необходимо начинать работу над новой системой, переписка с «большими» компаниями все еще была очень далека от обсуждения стоимости их предложений, поэтому мы сравнили полученное КП с затратами на обновление старой БМС (см. первую часть), и в результате оно оказалось более привлекательным по цене и соответствующим нашим требованиям.
Выбор был сделан.
После выбора подрядчика юристы стали составлять договор, а технические команды с обеих сторон шлифовать ТЗ. Как известно, подробное и грамотное ТЗ – это основа успеха любых работ. Чем больше конкретики в ТЗ, тем меньше разочарований вроде «а мы хотели не так».
Приведу два примера уровня детализации требований в ТЗ:
- Дежурные ЦОД наделены полномочиями добавлять в BMS новые устройства, чаще всего это PDU. В старой BMS это был уровень «администратора», позволяющий в том числе менять уставки переменных всех устройств, и разделить функции было невозможно. Нас это не устраивало. В имеющейся базовой версии новой платформы схема была аналогичной. Мы сразу указали в ТЗ, что хотим разделить эти роли: уставки должен менять только уполномоченный сотрудник, но дежурные должны и дальше иметь возможность добавлять устройства. Эта схема и была принята к реализации.
- В любой стандартной BMS есть три типовые категории уведомлений: КРАСНАЯ – надо немедленно реагировать, ЖЕЛТАЯ – можно наблюдать, СИНЯЯ – «Информационная». Мы традиционно использовали «синие» уведомления для мониторинга превышения коммерческих параметров, например, превышение лимита мощности стойки клиента. Этот тип уведомлений в нашем случае был предназначен для менеджеров и не был интересен службе эксплуатации, но в старой BMS регулярно засорял список активных инцидентов и мешал оперативной работе. Саму логику и цветовую дифференциацию
штановуведомлений мы посчитали удачной и сохранили, однако в ТЗ специально указали, что «синие» уведомления должны, не отвлекая дежурных, беззвучно «сыпаться» в отдельный раздел, где ими будут заниматься коммерческие специалисты.
С аналогичной степенью детализации были прописаны форматы построения графиков и выведения отчетов, очертания интерфейсов, перечень устройств, которые надо было мониторить и еще множество других вещей.
Это была по-настоящему творческая работа трех рабочих групп – службы заказчика, которая диктовала свои требования и условия; технических специалистов с обеих сторон, в задачу которых входило преобразование этих условий в техническую документацию; команды программистов подрядчика, которые реализовывали требования заказчика по разработанной технической документации… В итоге что-то из наших непринципиальных требований мы адаптировали под функционал уже имеющейся платформы, что-то подрядчик обязался дописать под нас.
Параллельная работа двух систем
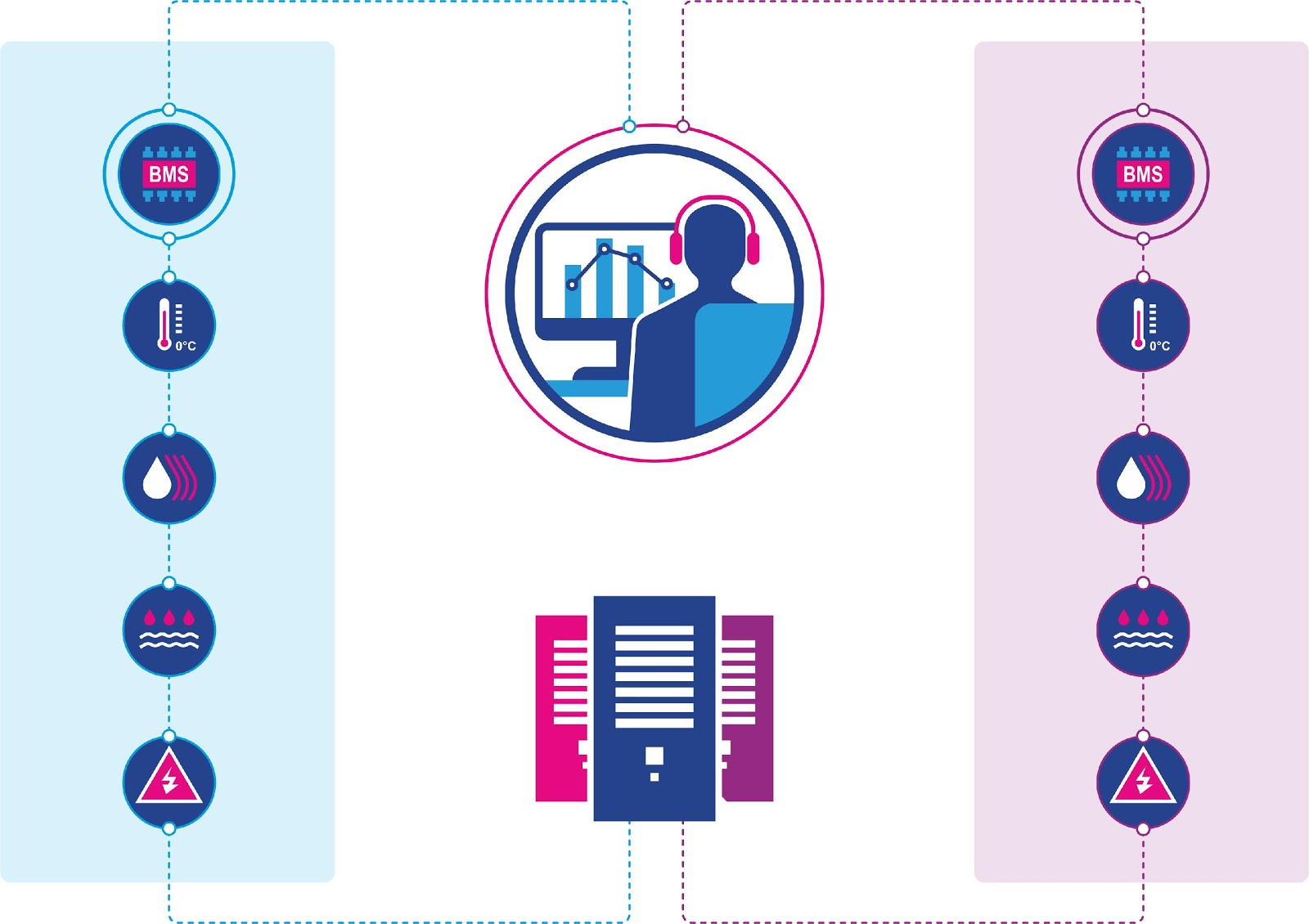
Настало время реализации. На практике это означало, что мы даем подрядчику возможность развернуть прототип BMS в нашем виртуальном облаке и предоставляем сетевой доступ ко всем устройствам, требующим мониторинга.
При этом новая система еще не была готова к работе. На данном этапе для нас было важно сохранить мониторинг в старой системе и одновременно дать доступ к устройствам новой системе. Невозможно нормально построить систему, не видя в ней устройств, которые в свою очередь нельзя отключить от мониторинга старой системой.
Выдержат ли устройства одновременный опрос двумя системами, было неочевидно без реальных испытаний. Существовала вероятность, что двойной одновременный опрос приведет к частым отказам в ответах от устройств и мы получим множество ошибок по недоступности устройств, что в свою очередь заблокирует работу старой системы мониторинга.
Сетевой отдел прокинул виртуальные маршруты от прототипа новой BMS, развернутого в облаке, к устройствам, и мы получили результаты:
- устройства, подключенные по протоколу SNMP, практически не выпадали в дисконнект из-за одновременных обращений,
- устройства, подключенные через шлюзы по протоколам modbas-TCP, имели проблемы, которые были решены разумным снижением частоты их опроса.
А дальше мы стали наблюдать, как на наших глазах строится новая система, в ней появляются уже знакомые нам устройства, но в другом интерфейсе – удобном, быстром, доступном даже с телефона.
О том, что получилось в итоге, мы расскажем в третьей части нашей статьи.


hooperer
И в этом моменте интересно, к каким создателям исключительно Scada систем с таким ТЗ обращались?
ну то-есть те — кто не умеет облака известны так же как и те, кто умеет облака.
Linxdatacenter
Добрый день, мы бы не хотели давать в статье рекламу или антирекламу, поэтому решили не упоминать компании, с которыми расстались на этапе обсуждения ТЗ.
hooperer
Достаточно мудрое решение.
При этом мне кажется в сфере Scada систем все на рынке и так знают функционал каждой систем. Это достаточно развитый рынок где у каждой компании есть своя ниша.