
Что делать, если в базу хочется записать массу «фактов» много большего объема, чем она способна выдержать? Сначала, конечно, приводим данные к более экономичной нормальной форме и получаем «словари», в которые будем писать однократно. Но как это делать наиболее эффективно?
Именно с таким вопросом мы столкнулись при разработке мониторинга и анализа логов серверов PostgreSQL, когда остальные способы оптимизации записи в БД оказались исчерпаны.
Сразу оговоримся, что наши коллекторы работают под управлением Node.js, поэтому с процессорными регистрами и кэшами мы никак не взаимодействуем. А вариант использования «стораджей» или внешних кэширующих сервисов/БД дает слишком большие задержки при входящих потоках в несколько сотен Mbps.
Поэтому мы стараемся кэшировать все в RAM, конкретно — в памяти JavaScript-процесса. Про то, как эффективнее это организовать, и пойдет речь дальше.
Наша основная задача — сделать так, чтобы в БД попал по возможности единственный экземпляр какого-либо объекта. Такими у нас выступают многократно повторяющиеся оригинальные тексты SQL-запросов, шаблоны планов их выполнения, узлов этих планов — короче, какие-то текстовые блоки.
Исторически так сложилось, что в качестве идентификатора мы использовали
То есть само оригинальное текстовое значение нам хранить не требуется (а иногда оно занимает десятки килобайт) — достаточно всего лишь самого факта наличия соответствующего хеша в словаре.
Такой словарь можно вести в
Поэтому в эпоху до ES6 традиционным решением было хранение
Но вполне очевидно, что мы тут явно храним лишнее — то самое значение ключа, которое никому не нужно. А что если его — вообще не хранить? Так и появился объект Set.
Тесты показывают, что поиск с помощью
Итак,

То есть
Вообще, в природе распределенных систем UUID-ключи достаточно распространены — у нас в СБИСе они, как минимум, применяются для идентификации документов и регламентов в электронном документообороте, персон в обмене сообщениями,…
Давайте теперь еще раз внимательно посмотрим на картинку выше — каждый UUID-ключ, хранимый в hex-представлении, «стоит» нам 56 байт памяти. Но у нас их — сотни тысяч, поэтому резонно спросить: «А меньше — можно?»
Для начала вспомним, что UUID — это 16-байтовый идентификатор. По сути, кусок бинарных данных. А для передачи по email, например, двоичные данные кодируются в base64 — попробуем его применить:
Уже по 48 байт — лучше, но неидеально. Давайте попробуем перевести шестнадцатиричное представление прямо в строку:
Вместо 56 байт на каждый ключ — 40 байт, экономия почти 30%!
Учитывая, что словарные данные от воркеров достаточно сильно пересекаются, мы сделали хранение словарей и запись их в БД в мастер-процессе, а передачу данных от воркеров через механизм IPC-сообщений.
Однако существенная доля времени мастера тратилась на
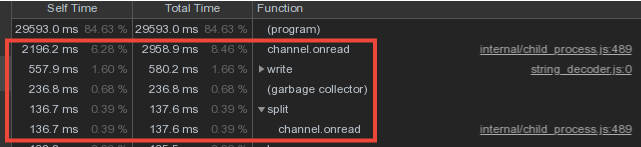
Теперь на секунду задумаемся — воркеры шлют и шлют мастеру одни и те же словарные данные (в основном — это шаблоны планов и повторяющиеся тела запросов), он их в поте лица парсит и… ничего не делает, потому что они в БД уже были отправлены раньше!
Так если мы
Собственно, что и было сделано, и сократило втрое прямые издержки на обслуживание канала обмена:

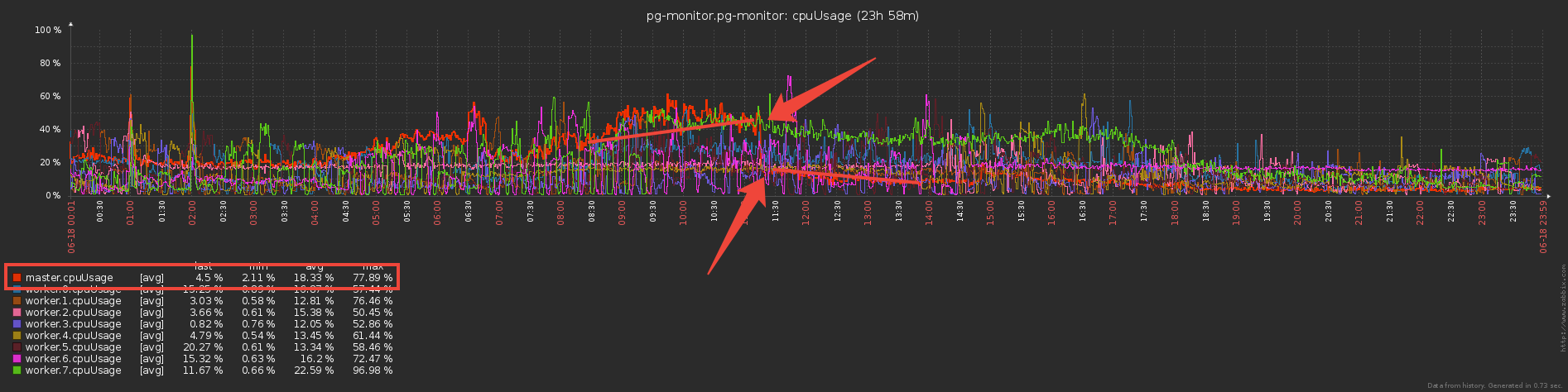
Но ведь теперь воркеры делают вроде как больше работы — хранят словари и фильтруют по ним? Или нет?.. На самом деле, работать они стали существенно меньше, поскольку сама передача больших объемов (даже по IPC!) — это не дешево.
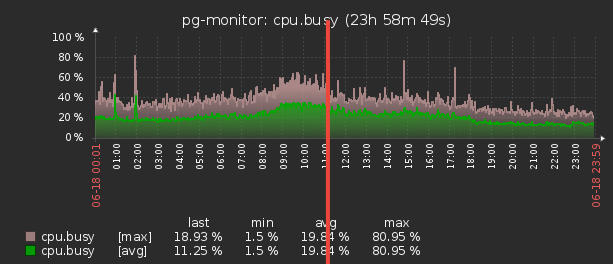
Поскольку мастер теперь стал принимать гораздо меньший объем информации, то и памяти под эти контейнеры стал выделять гораздо меньше — а, значит, затраты времени на работу Garbage Collector'а сильно снизились, что положительно повлияло на latency системы в целом.
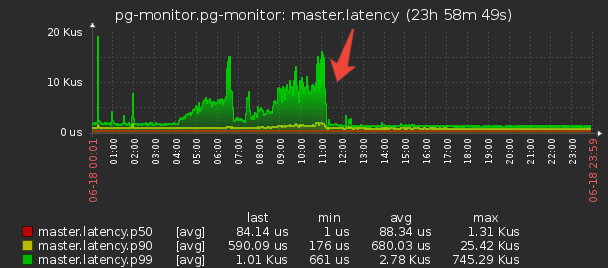
Такая схема обеспечивает защиту от повторных записей на уровне коллектора, но что делать, если у нас несколько коллекторов? Тут поможет только триггер с
В нашей архитектуре весь поток логов с одного сервера PostgreSQL обрабатывает один воркер.
То есть один сервер — это одна задача на воркере. При этом загрузка воркеров балансируется назначением задач-серверов так чтобы потребление CPU воркерами всех коллекторов было примерно одинаковым. Этим занимается отдельный сервис диспетчера.
«В среднем» каждый воркер обрабатывает несколько десятков задач, которые дают примерно одинаковую суммарную нагрузку. Однако, есть сервера, которые по количеству записей в логе значительно превосходят остальные. И даже в том случае, если диспетчер оставляет эту задачу единственной на воркере, его загрузка сильно выше остальных:

Сняли CPU-профайл этого воркера:

На верхних строках — вычисление MD5-хешей. А их действительно вычисляется огромное количество — для всего потока входящих объектов.
Как оптимизировать эту часть, если не считать эти хеши мы не можем?
Решили попробовать другую хеш-функцию — xxHash, реализующую Extremely fast non-cryptographic hash algorithm. И модуль для Node.js — xxhash-addon, который использует свежую версию библиотеки xxHash 0.7.3 с новым алгоритмом XXH3.
Проверим, прогнав каждый вариант на наборе строк разной длины:
Результаты:
Как и ожидалось, xxhash3 оказался намного быстрее MD5!
Осталось проверить на стойкость к коллизиям. Секции таблиц словарей у нас создаются новые на каждый день, поэтому за рамками суток мы спокойно можем допустить пересечение хешей.
Но на всякий случай проверили с запасом на интервале в три дня — ни одной коллизии, что нас более чем устраивает.

Но просто взять и поменять в таблицах-словарях старые UUID-поля на новый хеш мы не можем — ведь и база, и существующий frontend ждут, что объекты продолжат идентифицироваться по UUID.
Поэтому добавим в коллекторе еще один кэш — для уже посчитанных MD5. Теперь это будет Map, в котором ключи — xxhash3, значения — MD5. Для одинаковых строк мы не пересчитываем заново «дорогой» MD5, а берем его из кэша:
Снимаем профайл — доля времени вычисления хешей заметно снизилась, ура!

Так что теперь мы считаем xxhash3, затем проверяем кэш MD5 и получаем искомый MD5, а затем проверяем кэш словаря — если там этого md5 нет, то отправляем на запись в БД.
Что-то слишком много проверок… Зачем проверять кэш словаря, если уже проверили кэш MD5? Выходит, все кэши словарей теперь не нужны и достаточно иметь всего один кэш — для MD5, с которым и будут производиться все основные операции:

В итоге, мы заменили проверку в нескольких кэшах «объектных» словарей одним кэшем MD5, а ресурсоемкую операцию расчета MD5-хеша выполняем только для новых записей, используя для входящего потока гораздо более эффективный xxhash.
Спасибо Kilor за помощь в подготовке статьи.
Именно с таким вопросом мы столкнулись при разработке мониторинга и анализа логов серверов PostgreSQL, когда остальные способы оптимизации записи в БД оказались исчерпаны.
Сразу оговоримся, что наши коллекторы работают под управлением Node.js, поэтому с процессорными регистрами и кэшами мы никак не взаимодействуем. А вариант использования «стораджей» или внешних кэширующих сервисов/БД дает слишком большие задержки при входящих потоках в несколько сотен Mbps.
Поэтому мы стараемся кэшировать все в RAM, конкретно — в памяти JavaScript-процесса. Про то, как эффективнее это организовать, и пойдет речь дальше.
Кэширование наличия
Наша основная задача — сделать так, чтобы в БД попал по возможности единственный экземпляр какого-либо объекта. Такими у нас выступают многократно повторяющиеся оригинальные тексты SQL-запросов, шаблоны планов их выполнения, узлов этих планов — короче, какие-то текстовые блоки.
Исторически так сложилось, что в качестве идентификатора мы использовали
UUID-значение, которое получали в результате прямого вычисления MD5-хеша от текста объекта. После этого проверяем наличие такого хеша в локальном «словаре» в памяти процесса, и вот если его там нет — только тогда пишем в БД в «словарную» таблицу.То есть само оригинальное текстовое значение нам хранить не требуется (а иногда оно занимает десятки килобайт) — достаточно всего лишь самого факта наличия соответствующего хеша в словаре.
Словарь ключей
Такой словарь можно вести в
Array, и использовать Array.includes() для проверки наличия, но это достаточно избыточно — поиск деградирует (по крайней мере, в предыдущих версиях V8) линейно от размера массива, O(N). Да и в современных реализациях, несмотря на все оптимизации, проигрывает по скорости 2-3%.Поэтому в эпоху до ES6 традиционным решением было хранение
Object, ключами которого выступали хранимые значения. А вот значениями ключей каждый назначал что хотел — например, Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Но вполне очевидно, что мы тут явно храним лишнее — то самое значение ключа, которое никому не нужно. А что если его — вообще не хранить? Так и появился объект Set.
Тесты показывают, что поиск с помощью
Set.has() быстрее примерно на 20-25%, чем проверка ключа в Object. Но это не единственное его преимущество. Раз мы храним меньше, то и памяти нам должно требоваться меньше — а это впрямую сказывается на производительности, когда речь идет о сотнях тысяч таких ключей.Итак,
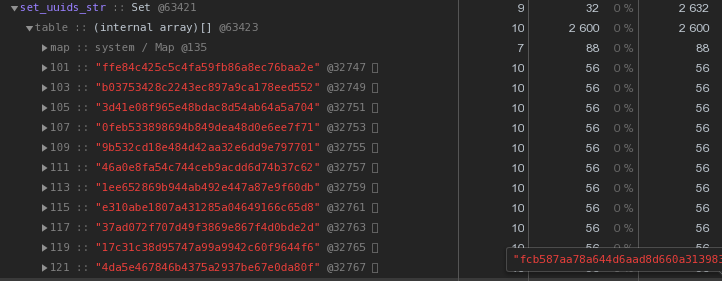
Object, в котором находится 100 UUID-ключей в текстовом представлении, занимает в памяти 6216 байт:Set с тем же содержимым — 2632 байта:То есть
Set работает быстрее и при этом занимает в 2.5 раза меньше памяти — победитель очевиден.Оптимизируем хранение UUID-ключей
Вообще, в природе распределенных систем UUID-ключи достаточно распространены — у нас в СБИСе они, как минимум, применяются для идентификации документов и регламентов в электронном документообороте, персон в обмене сообщениями,…
Давайте теперь еще раз внимательно посмотрим на картинку выше — каждый UUID-ключ, хранимый в hex-представлении, «стоит» нам 56 байт памяти. Но у нас их — сотни тысяч, поэтому резонно спросить: «А меньше — можно?»
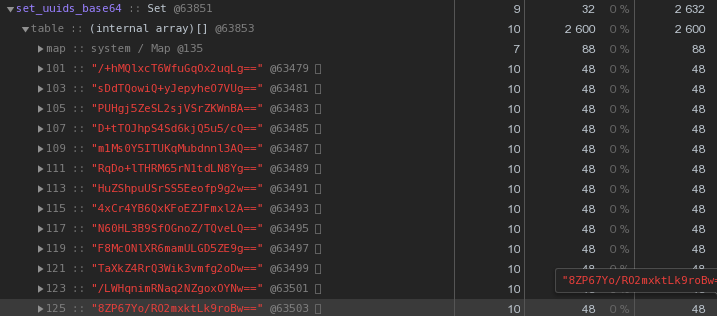
Для начала вспомним, что UUID — это 16-байтовый идентификатор. По сути, кусок бинарных данных. А для передачи по email, например, двоичные данные кодируются в base64 — попробуем его применить:
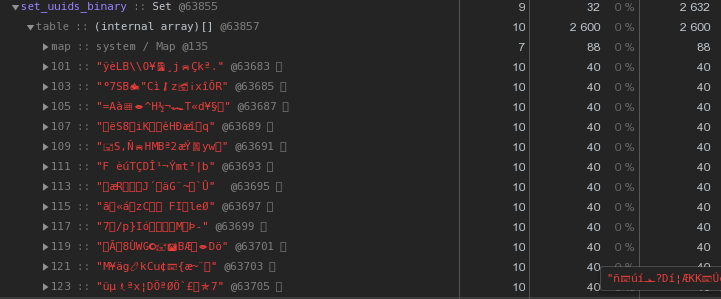
let str = Buffer.from(uuidstr, 'hex').toString('base64');Уже по 48 байт — лучше, но неидеально. Давайте попробуем перевести шестнадцатиричное представление прямо в строку:
let str = Buffer.from(uuidstr, 'hex').toString('binary');Вместо 56 байт на каждый ключ — 40 байт, экономия почти 30%!
Master, worker — где хранить словари?
Учитывая, что словарные данные от воркеров достаточно сильно пересекаются, мы сделали хранение словарей и запись их в БД в мастер-процессе, а передачу данных от воркеров через механизм IPC-сообщений.
Однако существенная доля времени мастера тратилась на
channel.onread — то есть на обработку получения пакетов со «словарной» информацией от дочерних процессов:Двойной Set-барьер от записи
Теперь на секунду задумаемся — воркеры шлют и шлют мастеру одни и те же словарные данные (в основном — это шаблоны планов и повторяющиеся тела запросов), он их в поте лица парсит и… ничего не делает, потому что они в БД уже были отправлены раньше!
Так если мы
Set-словариком «защитили» базу от повторной записи из мастера, почему бы не применить тот же подход для «защиты» мастера от передачи из воркера?..Собственно, что и было сделано, и сократило втрое прямые издержки на обслуживание канала обмена:
Но ведь теперь воркеры делают вроде как больше работы — хранят словари и фильтруют по ним? Или нет?.. На самом деле, работать они стали существенно меньше, поскольку сама передача больших объемов (даже по IPC!) — это не дешево.
Приятный бонус
Поскольку мастер теперь стал принимать гораздо меньший объем информации, то и памяти под эти контейнеры стал выделять гораздо меньше — а, значит, затраты времени на работу Garbage Collector'а сильно снизились, что положительно повлияло на latency системы в целом.
Такая схема обеспечивает защиту от повторных записей на уровне коллектора, но что делать, если у нас несколько коллекторов? Тут поможет только триггер с
INSERT ... ON CONFLICT DO NOTHING.Ускоряем вычисление хешей
В нашей архитектуре весь поток логов с одного сервера PostgreSQL обрабатывает один воркер.
То есть один сервер — это одна задача на воркере. При этом загрузка воркеров балансируется назначением задач-серверов так чтобы потребление CPU воркерами всех коллекторов было примерно одинаковым. Этим занимается отдельный сервис диспетчера.
«В среднем» каждый воркер обрабатывает несколько десятков задач, которые дают примерно одинаковую суммарную нагрузку. Однако, есть сервера, которые по количеству записей в логе значительно превосходят остальные. И даже в том случае, если диспетчер оставляет эту задачу единственной на воркере, его загрузка сильно выше остальных:
Сняли CPU-профайл этого воркера:
На верхних строках — вычисление MD5-хешей. А их действительно вычисляется огромное количество — для всего потока входящих объектов.
xxHash
Как оптимизировать эту часть, если не считать эти хеши мы не можем?
Решили попробовать другую хеш-функцию — xxHash, реализующую Extremely fast non-cryptographic hash algorithm. И модуль для Node.js — xxhash-addon, который использует свежую версию библиотеки xxHash 0.7.3 с новым алгоритмом XXH3.
Проверим, прогнав каждый вариант на наборе строк разной длины:
const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Результаты:
xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Как и ожидалось, xxhash3 оказался намного быстрее MD5!
Осталось проверить на стойкость к коллизиям. Секции таблиц словарей у нас создаются новые на каждый день, поэтому за рамками суток мы спокойно можем допустить пересечение хешей.
Но на всякий случай проверили с запасом на интервале в три дня — ни одной коллизии, что нас более чем устраивает.
Подмена хешей
Но просто взять и поменять в таблицах-словарях старые UUID-поля на новый хеш мы не можем — ведь и база, и существующий frontend ждут, что объекты продолжат идентифицироваться по UUID.
Поэтому добавим в коллекторе еще один кэш — для уже посчитанных MD5. Теперь это будет Map, в котором ключи — xxhash3, значения — MD5. Для одинаковых строк мы не пересчитываем заново «дорогой» MD5, а берем его из кэша:
const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Снимаем профайл — доля времени вычисления хешей заметно снизилась, ура!
Так что теперь мы считаем xxhash3, затем проверяем кэш MD5 и получаем искомый MD5, а затем проверяем кэш словаря — если там этого md5 нет, то отправляем на запись в БД.
Что-то слишком много проверок… Зачем проверять кэш словаря, если уже проверили кэш MD5? Выходит, все кэши словарей теперь не нужны и достаточно иметь всего один кэш — для MD5, с которым и будут производиться все основные операции:
В итоге, мы заменили проверку в нескольких кэшах «объектных» словарей одним кэшем MD5, а ресурсоемкую операцию расчета MD5-хеша выполняем только для новых записей, используя для входящего потока гораздо более эффективный xxhash.
Спасибо Kilor за помощь в подготовке статьи.

nin-jin
Не думали в сторону фильтра Блума?
Почему для такой задачи вообще выбран JS?
Kilor
Много сетевых потоков, асинхронности и работы со строками (регекспы, парсинг, ...) — NodeJS удобен в этих аспектах.
nin-jin
Блум — это set с ненулевой вероятностью ложноположительного срабатывания.
Kilor
Я имел в виду, что поиск в нем — быстр, но насколько эффективно он модифицируем при добавлении нового элемента.
nin-jin
Добавление и чтение одинаковы по стоимости. А вот удалять нельзя.
babylon
Почему вы ограничились UUID, а не сделали произвольный контекст. Насколько я помню, например, в Tarantool нет таких ограничений
Kilor
Что такое «произвольный контекст»?
Нас uuid как значение просто устроил своими характеристиками — как с точки зрения длины/вероятности коллизий, так и эффективного хранения на стороне БД.