
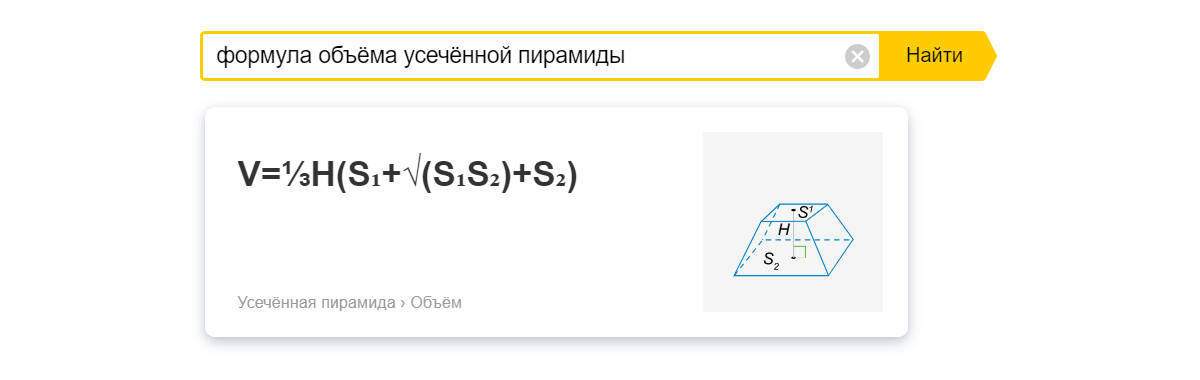
Когда мы вводим запрос в поисковую строку, то ищем информацию, а не ссылки. Более того, зачастую нам требуется короткое предложение или общеизвестный факт. К примеру, [формула объёма усечённой пирамиды] на всех сайтах одинакова — ссылки не нужны, достаточно сразу дать ответ.
Фактовыми (информационными) ответами сейчас никого не удивить, но мало кто знает, как именно они формируются, чем различаются и что важного произошло в этой области за последнее время. Меня зовут Антон Иванов. Сегодня вместе с моим коллегой Михаилом Агеевым dminer мы расскажем историю ответов в поиске и поделимся некоторыми подробностями, о которых раньше нигде не говорили. Надеюсь, будет полезно.
История интернета – это история упрощения поиска информации. Когда-то, чтобы находить ответы, люди посещали онлайн-каталоги, где по темам были сгруппированы ссылки на сайты. Со временем появились поисковые системы, они научились искать сайты по ключевым словам. Спрос на быстрый поиск информации стимулировал развитие технологий: поиск по словам постепенно эволюционировал в поиск по смыслу, когда ответ мог быть найден на странице с нулевым пересечением по ключевым словам. Но даже в этом случае приходилось кликать по ссылкам. Люди же всегда мечтали о большем.
Первые факты
Сейчас трудно вспомнить, с чего начинались фактовые ответы Яндекса. Можно сказать, что решением стал особый формат колдунщика, предполагающий короткий текстовый ответ без интерактивности (в отличие от ответов на запросы [мой ip адрес] или [цвет морской волны]). Как вы понимаете, реализовать такой формат несложно. Главный вопрос в другом: где брать ответы?

Начинали мы с самого простого в техническом плане способа. Специальные люди (асессоры) анализировали наиболее популярные запросы, выбирали те, на которые можно найти короткий ответ. Классический пример такого запроса — [сколько лап у мухи].

Таким способом можно было охватить лишь наиболее популярные запросы, а длинный хвост прочих запросов оставался без внимания. Отчасти мы решили эту задачу с помощью краудсорсинга.
Несколько лет назад толокеры начали помогать нам пополнять базу фактовых ответов. В платформу выгружались частотные запросы, толокеры видели задание: «Правда ли, что на этот запрос можно дать исчерпывающий ответ? И если правда, то дайте его». Конечно же, другие толокеры проверяли адекватность ответов, а ошибки мы ловили с помощью поискового опечаточника. Кстати, толокеры также помогли нам выяснить, что фактовые ответы с картинкой обычно нравятся пользователям больше, чем просто текст.
Помощь толокеров значительна, но даже они не помогут охватить длинный хвост низкочастотных запросов. Таких запросов просто слишком много для любой ручной разметки: их уже не десятки тысяч, а миллионы! Чтобы решить эту задачку, нам пригодился опыт поискового ранжирования.
Fact Snippet
Когда вы что-то ищете в поиске Яндекса, то видите не только 10 ссылок, но и заголовок, описание, иконку и прочие данные.
Сфокусируемся на описании. Наш поиск создаёт его автоматически. Для выделения лучшего фрагмента текста применяется лёгкая модель CatBoost, которая оценивает близость фрагмента текста и запроса. Получается, что в описаниях ссылок иногда уже содержатся фактовые ответы. Было бы странно не воспользоваться этим — но не всё так просто.
Может показаться, что задача сводится к выбору «наиболее фактового» описания среди всех описаний найденных по запросу страниц, но такой подход сработает плохо. Причина в том, что информативное описание страницы далеко не всегда совпадает с хорошим ответом на прямой вопрос человека. Поэтому наша технология Fact Snippet строит факты параллельно с описаниями страниц, но на основе других параметров, чтобы результат был похож на ответ. И вот уже среди них нужно выбрать наиболее качественный ответ.
Мы уже рассказывали на Хабре о поисковых алгоритмах «Палех», «Королёв» и о подходе DSSM. Задача тогда сводилась к поиску близких по смыслу текстов при ранжировании страниц. По сути, мы сравнивали два вектора: вектор запроса и вектор текста документа. Чем ближе эти векторы в многомерном пространстве, тем ближе смыслы текстов. Чтобы выбрать наиболее качественные факты, мы сделали то же самое. Наша нейросетевая модель, обученная на уже известных нам ответах, строит векторы ответов для найденных в поиске страниц и сравнивает их с вектором запроса. Так мы получаем лучший ответ.
Понятно, что отвечать таким образом на все-все запросы не стоит: большинству запросов не требуется фактовый ответ. Поэтому мы используем ещё одну модель для отсева «нефактовых» запросов.
Fact Snippet 2.0
Всё, о чём мы говорили выше, касалось «классических» фактовых ответов: коротких, исчерпывающих, как в энциклопедии. Это направление долго было единственным. Но чем дальше, тем больше мы видели, что деление именно по признаку существования исчерпывающего ответа, с одной стороны, очень зыбкое, а с другой — непрозрачное для пользователя: ему нужно просто решить свою задачу быстрее. Потребовалось выйти за рамки привычных фактов. Так появился проект Fact Snippet 2.0.
Если всё упростить, то Fact Snippet 2.0 — это тот же Fact Snippet, но без требования найти «исчерпывающий ответ». На самом деле всё несколько сложнее.
Напомню, что Fact Snippet работает в два этапа. На первом этапе мы с помощью лёгкой модели оцениваем «фактовость» запроса: подразумевает он фактовый ответ или нет. Если да, на втором этапе ищем ответ, он появляется в результатах поиска. Для Fact Snippet 2.0 мы адаптировали оба этапа так, чтобы находить ответы на более широкий срез вопросов. Такие ответы не претендуют на энциклопедическую полноту, но всё равно полезны.
Подобрать абзац текста на любой запрос можно, но не всегда нужно. Иногда найденные тексты недостаточно релевантны запросу. Иногда у нас уже есть хорошие ответы из других источников — и нужно решить, какой выбрать. К примеру, зачем предлагать адрес организации текстом, если можно показать интерактивную карту, номер телефона и отзывы. Эту задачу мы решаем с помощью блендерного классификатора, с которым читателей Хабра уже знакомил Андрей Стыскин. А ещё в ответе не должно быть грубостей, оскорблений. Практически на каждое такое разумное ограничение есть свой классификатор, и заставить его работать в рантайме за доли секунды — тот ещё квест.
Переформулировки запросов
Охватили ещё часть длинного хвоста, но за бортом по-прежнему остались многие «уникальные» запросы. Их существенная доля — это иные формулировки уже известных нам запросов. Например, [когда щука меняет зубы] и [в какое время зубы меняет щука] — почти одно и то же.
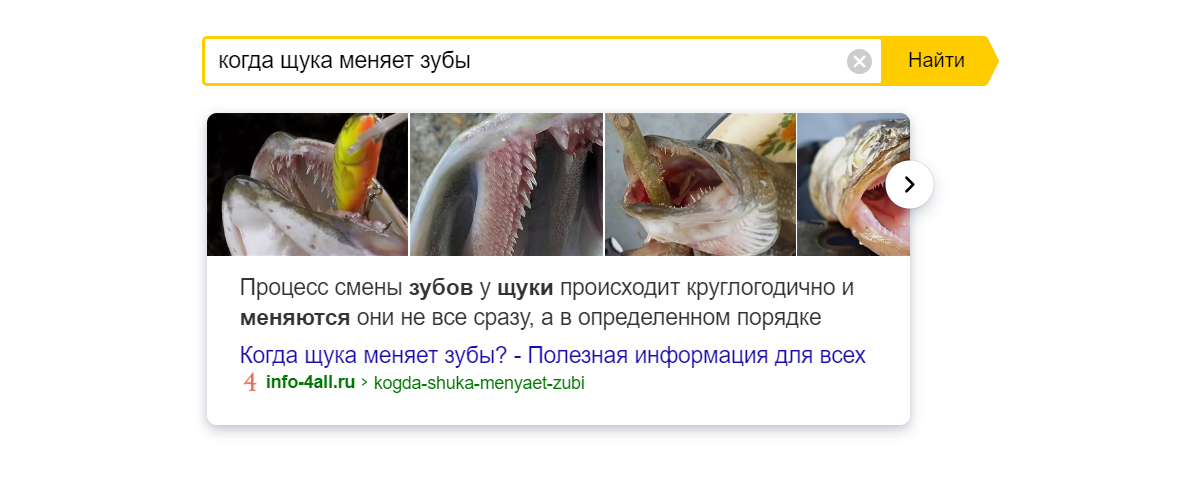
Чтобы решить эту проблему, мы придумали механизм, который на лету понимает, что пришедший запрос — алиас (означает то же самое) другого запроса, ответ на который у нас уже есть. Так проще и быстрее, чем независимо формировать два фактовых ответа.
Мы берём все запросы, на которые есть ответы, преобразуем их в векторы и кладём в индекс k-NN (точнее, в его оптимизированную версию HNSW, которая позволяет искать намного быстрее). Далее мы строим векторы запросов, на которые нет ответа по прямому совпадению, и ищем топ N наиболее похожих запросов в нашем k-NN.
Далее проходим по этому топу и прогоняем через катбустовый классификатор тройки:
— запрос пользователя;
— запрос из k-NN;
— ответ на запрос из k-NN.
Если вердикт классификатора положительный — запрос считается алиасом запроса из k-NN, мы можем вернуть уже известный ответ.
Основная творческая часть этой конструкции — в написании факторов для классификатора. Тут мы перепробовали довольно много разных идей. Среди самых сильных факторов:
— векторы запросов;
— расстояния Левенштейна;
— пословные эмбеддинги;
— факторы на основе разнообразных колдунщиков по каждому из запросов;
— расстояние между словами запросов.
Отдельно расскажу о трюке с применением нейросети BERT. У нас довольно сильные ограничения на время поиска алиаса: максимум несколько миллисекунд. Выполнять BERT за такое время при нагрузке в несколько тысяч RPS на текущих ресурсах невозможно. Поэтому мы собрали нашей BERT-моделью очень много (сотни миллионов) искусственных оценок и обучили на них более простую нейронную сеть DSSM, которая очень быстро работает в рантайме. В результате с некоторой потерей точности удалось получить сильный фактор.
На самом деле определять смысловую близость запросов можно и другими способами. Например, если два запроса отличаются друг от друга одним словом — проверить, как отличаются результаты поиска по этим запросам (посмотреть на число совпадающих ссылок в топе). Если повторить это много миллионов раз и усреднить результаты, то получится довольно хорошая оценка того, насколько меняется смысл запроса, если поменять в нём одно слово на другое. После этого можно сложить все данные в одну структуру (например, trie) и вычислить меру близости запросов через обобщённое расстояние Левенштейна. Можно расширить данный подход и считать не только слова, но и пары слов (но при этом trie получается значительно больше из-за экспоненциального роста данных).
Что дальше
По нашим подсчётам, благодаря фактовым/информационным ответам мы экономим пользователям 20 тыс. часов каждый день, ведь им не приходится просматривать ссылки в выдаче (и это не считая времени, которое они бы потратили на поиск ответа на сайтах). Это хорошо, но всегда есть куда расти. К примеру, сейчас мы для ответов используем текст, который находим в интернете, но готовый фрагмент текста не всегда можно найти в одном месте или в правильной форме. С помощью нейросетей эту проблему можно решить: генерировать ответ так, чтобы он соответствовал запросу и не содержал лишнего. В этом и заключается наш проект нейросуммаризации поиска, о котором, надеюсь, мы расскажем в следующей раз.
EzikBro
Маленький баг-репорт:
При перемещении по цветам в приведенном запросе [цвет морской волны] иногда виджет залезает за первый запрос.
anton_ai_ivanov Автор
Спасибо, проверим.
Maccimo
Hint: Для картинок есть https://habrastorage.org/
prostofilya
А про это напишете?)
BarakAdama
Да, мы тогда подробно разобрали этот баг в блоге Яндекса yandex.ru/blog/company/vkladka-s-obsuzhdaemym-kontentom-razbor-poletov
Am0ralist
Эх, кто б ещё научил сервисы яндекса искать заданные пользователем запросы, а не то, что яндексу показалось удобным втюхать. Это ж сколько лет можно было бы пользователям сэкономить! Особенно при поиске товаров, когда уже даже через обычный поиск в мейле товар найти проще, чем через маркет яндекса.
А то после жалобы, что точный поиск в яндексе перестал работать программисты решили задачу правильно: удалили настройку «искать как в запросе». Ну а что, решили же проблему, да?
LAutour
А мне еще вспоминается как когда-то у них была такая удобная вещь как сортировка поиска.
LAutour
Как убрать с главной страницы значки сервисов яндекса? В настройках блоков их нет, а так только место зря занимают.
Paranoich
Полагаю, что большинство пользователей всё-таки ищут ссылки на вменяемые сайты с более обширной информацией. Ведь если человек ищет «формулу объёма усечённой пирамиды», то уверен, что делает это не от бессонницы. Скорее всего ему понадобиться что-то ещё из формул и следовательно ему проще открыть сайт, где есть не только эта формула и куцее изображение пирамиды.
Информацию о количестве ног/лап у мухи получить действительно просто. Но представьте себе, что этот любознательный человек захотел также узнать что мухи кушают. И вместо того чтобы просто пройти в какую-нибудь вики, где и про ноги и про остальное написано на одной странице, он продолжает задавать вопросы прямо в поисковой строке. Что он узнает о питании мух?
Именно «засохший»? Свежий не кушают? А что насчёт засохшей крови если уж «в рационе» присутствуют «гниющие трупы»? А что насчёт овощей? А котлетку, на кухне оставленную?
Ответ неполный, да и невозможно вам выдать достаточно развёрнутый ответ. А пройдя по ссылке пользователь узнал бы какие мухи что кушают (даже в городе не один вид мух). И, простите, правильнее писать «экскременты», а не «фекалии», это более обширное понятие, включающее и фекалии тоже.
Школьник, пройдя в википедию узнал бы больше. Может поэтому они лишь и знают, что «Ленин — это лысый коммунист был такой», «Сталин был генерал и разбил фрицев под этим самым… Как его… Волгоградом», «землеройка ест землю, а гремучая змея ест гречу» и прочие короткие ответы на всё-всё.
Я совсем не против таких вот быстрых ответов в поиске, но предпочёл бы иметь возможность выключать их.
nitrosbase
А на чем-то типа недавнего Compositional Generalization Dataset пробовали прогонять? Как результаты?
anton_ai_ivanov Автор
Нет — эту модель не пробовали. CGD кажется только на английском языке
A114n
Я думаю, вам уже много раз об этом писали, но «Хорошее повтори и ещё раз повтори».
Подобные схемы «поиска» уничтожают поиск как таковой. Конечно, они очень выгодны для вас, так как помогают впаривать домохозяйкам товары от самых щедрых рекламодателей. Но для людей, которые знают, что хотят найти — ваш поиск это сущий ад. И он вдвойне стал адом после того, как из него удалили все возможности искать точные совпадения.
adsensei
Как мы учим Яндекс воровать хлеб у владельцев сайтов.
Pan_brigadir
Пользуюсь поиском Яндекса, но для вопросов по программированию приходится пользоваться Гуглом из-за того что он выдаёт стопку ответов с StackOverFlow
Возможно ли аналогичное сделать в Яндексе?
yavtoroy
Из недавнего:
Am0ralist
а зачем на левый ресурс лить картинки, когда есть хабрасторадж?
anton_ai_ivanov Автор
Спасибо! Удалили неправильный ответ. На его место подтянулся нужный.
prostofilya
машинное обучение)
mypallmall
Google: кто играл лапшу в фильме однажды в америке


Яндекс: кто играл лапшу в фильме однажды в америке
Возможности поиска на английском языке:
Как говорится: почувствуйте разницу.