
За несколько недель до 14 февраля системе Dodo IS немного поплохело под нагрузкой. Одной из причин стало то, что в backend’ах мобильного приложения и сайта не совсем корректно работали политики поверх HttpClient’а (Retry, Circuit Breaker, Timeout). В этой статье я хочу поделиться с вами потенциальными проблемами, которые могут возникнуть при неправильном использовании таких политик.

Политики HttpClient’а и надёжность запросов
Для начала краткая вводная: о каких «политиках поверх HttpClient’а» мы говорим, и зачем они нужны?
Допустим, сервис А запрашивает какие-то данные у сервиса B путём обычного http-запроса. К сожалению, сеть — штука ненадёжная, а сервера могут выходить из строя. Мы не можем гарантировать, что наш запрос успешно дойдёт и будет обработан на стороне сервиса B.
В ответ сервис B может ответить ошибкой или сервис B может быть недоступен, тогда наш запрос может и вовсе потеряться на просторах сети. Чтобы как-то повысить надёжность наших запросов, придуманы различные так называемые политики.
- Retry policy — для ситуации, когда в ответ на наш запрос вернулась ошибка, существует политика повторных запросов. Идея очевидная: если что-то пошло не так, то давайте попробуем ещё раз?
- На случай, если мы ждём ответ от сервиса B, а его всё нет, придумана политика таймаутов.
- Circuit Breaker — ещё одна интересная политика, которая позволяет нам останавливать все запросы к какому-то сервису, если мы точно знаем, что он недоступен (подробнее см. дальше).
Такие политики работают как обёртка над стандартным HttpClient’ом. Каждая из политик перехватывает запрос, проверяет ответ от сервера и выполняет какие-то операции.
Спасибо Polly за наше счастливое детство
В мире .NET эта проблема в некотором смысле решена. Есть прекрасная библиотека Polly, которая предоставляет уже готовые политики. Достаточно выбрать те, которые вам нужны, обернуть свой HttpClient, и дело в шляпе. Но, как мы знаем, дьявол кроется в деталях.
Если вы хорошо знаете эту библиотеку, прочитали всю документацию к ней и во всём разобрались, то можете закончить читать статью прямо сейчас, ничего нового вы не узнаете. Хотя нет, оставайтесь, сможете посмеяться над нашими ошибками.
Как ошибиться в 3 строках кода 4 раза
В чём же тут проблема? Берём клиент, обвешиваем нужными политиками, которые декорируют исходный HttpClient, и всё работает. Ниже приведён пример, как сейчас собирается HttpClient с помощью IHttpClientBuilder’а и какие политики к нему применяются.
clientBuilder
.AddRetryPolicy(settings.RetrySettings)
.AddCircuitBreakerPolicy(settings.CircuitBreakerSettings)
.AddTimeoutPolicy(settings.TimeoutPerTry);Здесь ровно три строчки кода с применением политик. Ниже мы рассмотрим, как можно ошибиться в каждой из них, вдобавок ещё и порядок напутать. Итого 4 ошибки.
Retry policy
Начнём с повторных запросов. Тут вроде бы всё достаточно просто: если код ответа от сервера находится в списке кодов, которые нужно «ретраить» (разрешите мне ввести в нашу терминологию такое классное русское слово), то мы выполняем запрос ещё раз. В самой библиотеке Polly есть описание синтаксиса и работы такой политики.
В чём же тут можно ошибиться? На самом деле, когда мы имеем дело с распределёнными системами, то ошибиться можно абсолютно во всем. Рассмотрим несколько моментов, которые могут потенциально вызвать проблему.
Какие ответы от сервера нужно ретраить
Давайте разберёмся с тем, какие ответы от сервера мы собираемся ретраить. Вообще, в индустрии уже придуманы best practices на эту тему, которые говорят, что ретраить нужно так называемые временные ошибки (transient errors).
Авторы Polly уже подумали о нас и включили в библиотеку обработчик таких ошибок. К ним относятся:
- все 5xx коды (server errors);
- код 408 (request timeout).
Про последний мы поговорим отдельно, а 5xx в идеальном мире вообще не должно быть (как бы не так!). Если сервер нам ответил пятисоткой, значит что-то не так, и мы надеемся, что это временная проблема.
У нас в компании возник один вопрос, который вызвал много горячих споров:
– А стоит ли ретраить код 500 (Internal Server Error)?
– Да, стоит.
Ответа с кодом 500 не должно быть. Но в какой ситуации в реальной жизни нам может вернуться 500? Самый банальный случай — это моя самая любимая ошибка NullReferenceException (NRE) в коде на стороне сервера. И встаёт вопрос, а нужно ли ретраить NRE. Есть ли какие-то основания полагать, что с какой-то N-ной попытки наш запрос будет успешно обработан?
Да, в идеальном мире NRE не должно быть, но мы — живые люди, и мы ошибаемся. Для себя мы пока решили оставить ретраи для кода 500, но вопрос всё ещё дискуссионный.
Какие интервалы нужны между повторными запросами
Итак, с кодами ошибок разобрались. Какие ещё вопросы остались? Нужно выбрать количество повторных попыток и время между ними. Количество зависит от ситуации, разве что не имеет смысла ретраить бесконечно. А вот с интервалами нужно думать.
Тут есть несколько стратегий:
Ретраи через фиксированные интервалы времени, например, через каждые 20 ms. Такая стратегия — это просто молоток, который долбит сервер несмотря ни на что. Бывают ситуации, когда просто моргнула сеть, тогда быстрый ретрай нам как раз помогает получить ответ от сервера. Но что, если и во второй, и в третий раз нам возвращается какой-нибудь 503? Может, сервер ушёл в перезагрузку, или выкатывается новая версия. Если мы на стороне клиента поняли, что сервер сейчас недоступен, а ответ нам очень нужен, то лучше подождать побольше.
Поэтому на практике рекомендуется использовать стратегию интервалов с экспоненциальной задержкой. Например, наши интервалы будут вычисляться по формуле:
initialValue * Math.Pow(2 * i)
Здесь
initialValue— это стартовое значение, например, 20 ms, аi— номер попытки.
Хоть эта стратегия и лучше, в ней есть одна тонкость. Опасно, когда у нас начинает ретраиться много разных запросов и при этом их попытки синхронизируются по времени, пусть даже по экспоненциальной стратегии. В этом случае мы создаём моменты пиковой нагрузки на сервер, которому и без нас плохо.
Чтобы как-то защитить наш многострадальный сервер, мы можем использовать так называемый jitter. Мы немного «размажем» нагрузку и добавим некоторую случайную составляющую к интервалу между попытками, чтобы запросы не улетали одновременно. К счастью, реализация такой стратегии уже есть в Polly.
Отдельно хочу отметить, что автором алгоритма, который лежит в основе рекомендуемой к использованию стратегии
DecorrelatedJitterBackoffV2, является Георгий Полевой — разработчик из команды платформы в Dodo.
Где тут можно ошибиться? Случай из жизни
Мы вроде бы учли все эти нюансы. Использовали правильную стратегию выбора интервалов между повторными запросами. И написали вот такой код:
…
var delay = Backoff.DecorrelatedJitterBackoffV2(
medianFirstRetryDelay: TimeSpan.FromSeconds(medianFirstRetryDelayInSeconds),
retryCount: count
);
return FailurePolicyBuilder.WaitAndRetryAsync(
delay,
onRetry: (exception, retryCount) => { … });Дело в том, что DecorrelatedJitterBackoffV2 возвращает нам IEnumerable<TimeSpan>. Мы вычисляем его один раз и потом передаём в метод WaitAndRetryAsync.
DecorrelatedJitterBackoffV2 сделал всё честно и случайным образом распределил нам интервалы для ретраев. Но потом мы сохранили результат в переменной delay. И дальше мы используем эту переменную для каждого запроса, что ничем не отличается от обычной стратегии интервалов с экспоненциальной задержкой. Тем самым у нас есть риск, что наши повторные запросы синхронизируются и будут создавать пиковые нагрузки на сервер. Исправить это можно обернув всё в лямбду, например так:
Func<IEnumerable<TimeSpan>> delay = () => Backoff.DecorrelatedJitterBackoffV2(
medianFirstRetryDelay: TimeSpan.FromSeconds(medianFirstRetryDelayInSeconds),
retryCount: count);Наше решение
Собрав всё вместе, мы получили следующий код для нашей политики ретраев:
private static IHttpClientBuilder AddRetryPolicy(
this IHttpClientBuilder clientBuilder,
IRetrySettings settings)
{
return clientBuilder
.AddPolicyHandler(HttpPolicyExtensions
.HandleTransientHttpError()
.Or<TimeoutRejectedException>()
.WaitAndRetryAsync(
settings.RetryCount,
settings.SleepDurationProvider,
settings.OnRetry));
}Здесь, SleepDurationProvider — это как раз стратегия, которая под капотом использует Backoff.DecorrelatedJitterBackoffV2 обёрнутый в лямбду.
Возможно, у вас возникнет справедливый вопрос: если мы ретраим все временные ошибки, к которым относится и код 408 (request timeout), то зачем в коде отдельно добавлена обработка TimeoutRejectedException? На этот вопрос мы подробнее ответим, когда дойдём до раздела TimeoutPolicy.
Circuit Breaker policy
Понятие Circuit Breaker’а (CB) пришло к нам из схемотехники. Идея в следующем: если мы в какой-то момент понимаем, что сервер нам перестал отвечать, то давайте не будем его добивать и «разомкнём цепь», т.е. остановим все запросы к этому серверу на некоторое время. Он и без того уже в огне. Даже если мы сделали бриллиантовую политику ретраев, то это всё равно не защищает нас от ситуаций, когда мы бесконечно стучимся в умирающий сервер.
Пользователи генерируют всё новые и новые запросы, каждый из них выполняется по несколько раз из-за ретраев. И так до бесконечности.
Задача CB — собрать статистику по ответам на наши запросы. Когда бОльшая часть запросов за какой-то период времени заканчивается неудачей, CB приостанавливает отправку запросов к серверу на некоторый интервал времени.
Для этой цели в Polly уже предусмотрено целых два CircuitBreaker’а: обычный и продвинутый. Здесь мы не будем рассматривать, как настраивается CB, так как по ссылкам выше всё подробно расписано. Вместо этого сфокусируемся на потенциальной проблеме неправильного подключения CB. Дополнительно рассмотрим ситуацию, когда клиент обращается к разным сервисам на разных хостах.
Где тут можно ошибиться? Случай из жизни
Здесь ошибка прямо противоположная той, что мы видели с ретраями. Посмотрите на пример кода:
clientbuilder
.AddPolicyHandler(policySelector: (serviceProvider, _) =>
FailurePolicyBuilder.AdvancedCircuitBreakerAsync( ... ));В AddPolicyHandler мы передаём не политику, а selector, который представляет собой лямбду, внутри которой создаётся CB.
Но как мы знаем, пропуская через себя запросы и получая ответы, CB должен накапливать статистику, чтобы принимать решение, открываться или нет. Для этого срок его жизни должен быть как минимум больше, чем срок жизни одного запроса. В данной схеме, используя лямбду, мы создавали CB на каждый запрос. И, конечно, никакой статистики CB накопить не успевал. Решение в данном случае очень простое: избавиться от лямбды и передавать в AddPolicyHandler саму политику.
Наше решение
Вот так выглядит наш текущий код, где исправлена данная проблема:
private static IHttpClientBuilder AddCircuitBreakerPolicy(
this IHttpClientBuilder clientBuilder,
ICircuitBreakerSettings settings)
{
return clientBuilder.AddPolicyHandler(BuildCircuitBreakerPolicy(settings));
}
private static AsyncCircuitBreakerPolicy<HttpResponseMessage> BuildCircuitBreakerPolicy(
ICircuitBreakerSettings settings)
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.Or<TimeoutRejectedException>()
.OrResult(r => r.StatusCode == (HttpStatusCode) 429) // Too Many Requests
.AdvancedCircuitBreakerAsync(
settings.FailureThreshold,
settings.SamplingDuration,
settings.MinimumThroughput,
settings.DurationOfBreak,
settings.OnBreak,
settings.OnReset,
settings.OnHalfOpen);
}Тут нет ничего особенного, всё то же, что и в ретраях, за исключением ошибки Too Many Requests (429). Если сервер начал нам отвечать, что он уже не может обрабатывать запросы, для нас это повод начать считать такие ответы и приостановить дальнейшие попытки нагружать сервер.
Есть ещё одна интересная ситуация, когда у нас есть один клиент и много серверов, которые расположены на разных хостах.
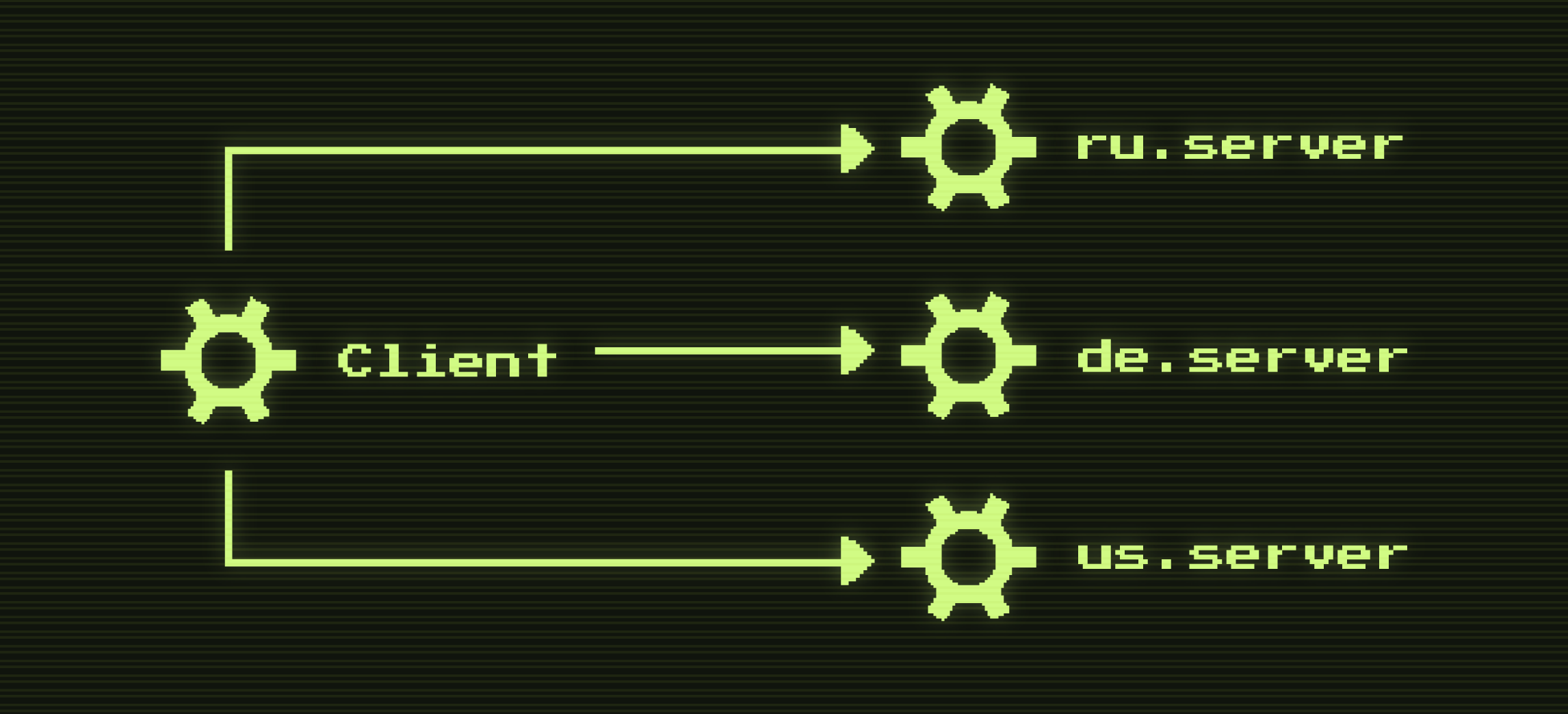
Рис. 1. Один клиент взаимодействует с несколькими серверами на разных хостах
Практический сценарий в нашем случае: у нас есть country agnostic бэкенд мобильного приложения (клиент), один и тот же для всех стран. Он обращается за данными в бэкофис (сервер). Бэкофис пока ещё country specific и под каждую страну деплоится отдельно (см. рис 1).
Представим себе ситуацию, когда бэкофис на какой-то стране из-за местного национального праздника перестал справляться с запросами, и CB на стороне клиента решил открыться. В текущей реализации политики для CB это означает, что у нас остановятся все запросы для всех стран. Этого мы не хотим, поэтому нам нужно каким-то образом привязать запросы к хостам, к которым они обращаются, и открывать CB раздельно. Такая возможность существует. Для этого у Polly предусмотрен PolicyRegistry, который под капотом содержит ConcurrentDictionary. Использовать его можно следующим образом:
private static IHttpClientBuilder AddHostSpecificCircuitBreakerPolicy(
this IHttpClientBuilder clientBuilder,
ICircuitBreakerSettings settings)
{
var registry = new PolicyRegistry();
return clientBuilder.AddPolicyHandler(message =>
{
var policyKey = message.RequestUri.Host;
var policy = registry.GetOrAdd(policyKey, BuildCircuitBreakerPolicy(settings));
return policy;
});
}BuildCircuitBreakerPolicy не изменился, его мы видели выше. А вот AddPolicyHandler теперь опять принимает лямбду. Однако теперь у нас не будет проблемы, потому что наши политики сохраняются в PolicyRegistry и достаются оттуда по имени хоста, а не создаются на каждый запрос.
Также проблему можно было решить другим способом — завести для каждого хоста свой собственный HttpClient. В этом случае они бы работали независимо друг от друга.
Timeout policy
Начнём с того, что таймаутов, вообще говоря, несколько.
- Таймаут на отдельный запрос. Это временное ограничение, которое мы накладываем на каждый запрос в отдельности. В случае с ретраями — на каждую попытку в отдельности.
- Общий таймаут на одну логическую операцию. Например, мы посылаем запрос к серверу и ожидаем получить результат в течение 30 секунд. Нас не интересует, будут ли там внутри ретраи, открылся CB или нет. Если за 30 секунд мы не получили ответ, то всё, операция считается неуспешной. Это такой же таймаут, но уже вне зоны действия политики ретраев.
- Также сам HttpClient имеет свой внутренний таймаут, который по умолчанию равен 100 секундам.
Polly, разумеется, предоставляет нам готовую политику таймаутов. С её помощью можно реализовать как таймаут на отдельный запрос, так и общий таймаут. Когда такой таймаут истечёт, будет сгенерировано исключение TimeoutRejectedException. Как вы видели в коде выше, мы перехватываем и обрабатываем эту ошибку и в политике ретраев, и в CB.
HttpClient в случае своего таймаута генерирует другую ошибку — TaskCancelledException. Если она произошла, то клиент остановит все запросы в данной сессии вне зависимости от ваших политик, поэтому такой исход тоже нужно учитывать.
В общем случае нужно убедиться, что таймауты выставлены корректно: таймаут на клиенте больше, чем таймаут на попытку. Ошибки в этих настройках могут свести на нет все остальные настройки политик, так как работа будет прерываться по таймауту раньше, чем нужно.
Наше решение
Сейчас мы в качестве политики используем только таймаут на одну попытку + выставляем таймаут на самом HttpClient’е. Эта политика выглядит проще всего:
private static IHttpClientBuilder AddTimeoutPolicy(
this IHttpClientBuilder httpClientBuilder,
TimeSpan timeout)
{
return httpClientBuilder.AddPolicyHandler(
Policy.TimeoutAsync<HttpResponseMessage>(timeout));
}Следует помнить ещё про один вид таймаутов: таймаут, который может прийти от сервера. Сервер может нам ответить кодом 408 (Request Timeout). Это именно ответ от сервера, политика таймаутов к такому ответу не имеет отношения. Код 408 может вернуться в ситуациях, когда сервер примет решение закрыть неиспользуемые соединения в целях экономии ресурсов. Такой ответ относится к временным (transient) ошибкам, и мы будем его ретраить.
Порядок имеет значение
Итак, у нас есть некоторый набор политик, и мы знаем, как они работают. Кроме понимания работы каждой политики в отдельности важно, чтобы вместе они работали правильно. Политики подключаются как декораторы, так что запрос, проходя через политики, сначала обрабатывается политикой A, затем B, затем C, а ответ в обратном порядке: C -> B -> A (см. рис. 2). Это важно, потому что неправильный порядок может привести к непредсказуемым результатам.
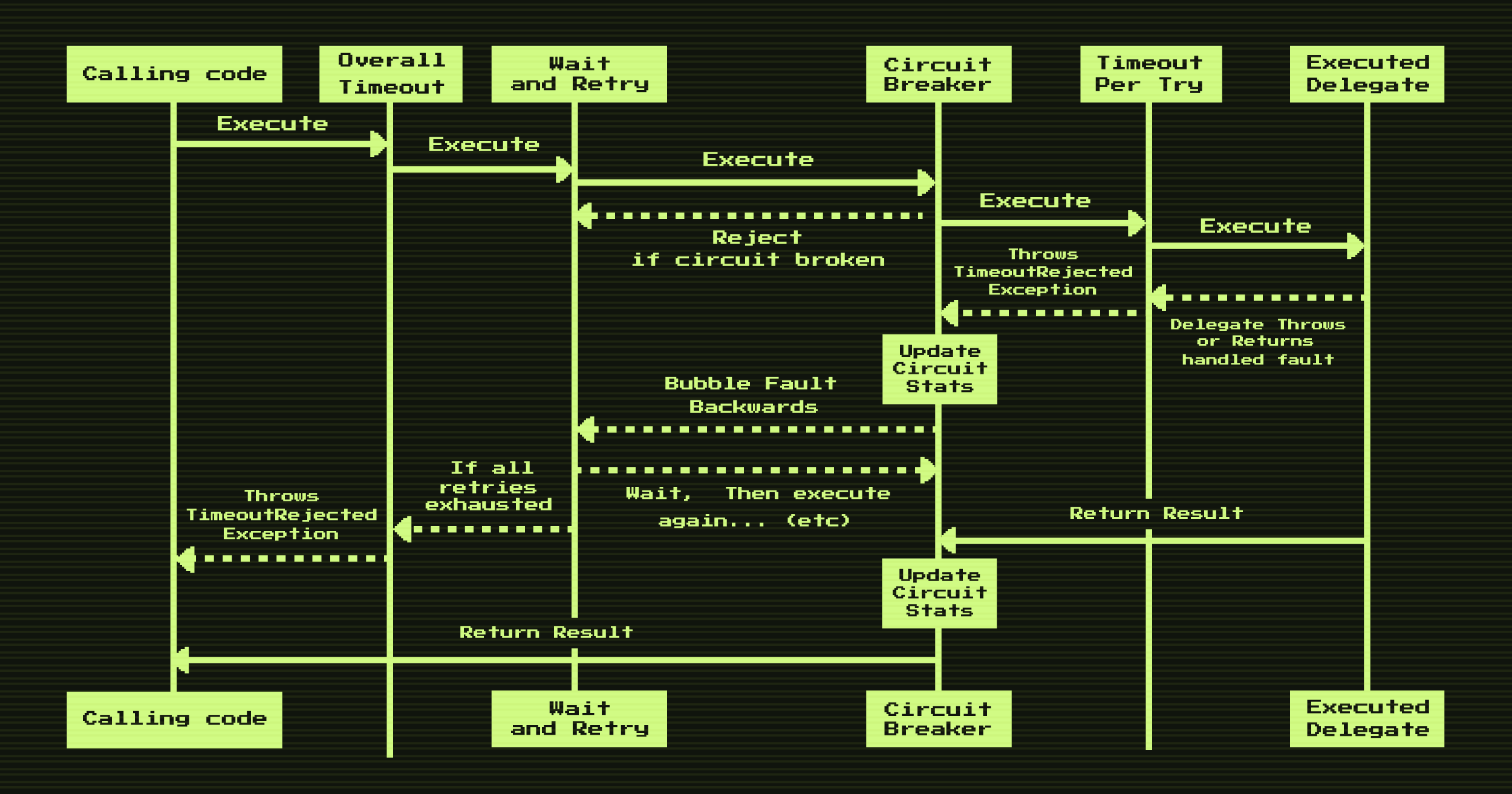
Рис. 2. Путь запроса и ответа через политики
Например, если наша политика CB окажется левее на схеме, чем политика ретраев (WaitAndRetry), то наш CB или никогда не откроется, или же откроется катастрофически поздно. Так, если запрос пройдет CB и попадет в политику ретраев, то он будет спокойно ретраиться и CB не получит ответ до тех пор, пока не пройдут все ретраи.
Также важно помнить о том, что политика таймаутов может появляться в нескольких местах. На рис. 2 показаны расположения таймаута на попытку (Timeout Per Try) и общего таймаута (Overall Timeout), про которые мы говорили выше. Поэтому крайне важно точно понимать ту схему работы вашего клиента, которую вы ожидаете, и, исходя из неё, подключить политики в правильном порядке.
Идемпотентность и подводные камни
При работе с распределёнными системами ещё важно помнить про такую штуку как идемпотентность запросов.
Идемпотентность означает, что если мы выполняем один и тот же запрос несколько раз, то мы получим ровно тот же результат, что и при однократном выполнении запроса. Иными словами, повторные запросы не приведут к новым изменениям состояния сервера.
Если мы говорим про REST, то в общем случае POST запрос, который по классике отвечает за создание нового ресурса, не является идемпотентным сам по себе, так как повторное выполнение запроса будет создавать новые ресурсы.
А в каком случае может возникнуть повторное выполнение? В том случае, если мы ретраим наши запросы. Важно помнить, что если нам вернулся, например, таймаут, и мы повторно отправляем запрос, то это не значит, что первоначальный запрос не был обработан сервером. Таймаут означает лишь то, что мы больше не ждём этот результат.
Таким образом, ретраи могут быть потенциально опасны для сервера, и мы должны на серверной стороне учитывать это и обрабатывать такие запросы корректно, чтобы они не приводили к повторным изменениям состояния сервера. Другими словами, нам необходимо на серверной стороне обеспечить идемпотентность любых запросов. Здесь мы не будем разбирать возможные решения данной проблемы, это тема отдельной статьи. Просто стоит об этом помнить.
Ещё один важный момент — посмотреть на свои политики со стороны пользователя. Казалось бы, что все эти ретраи и прочие таймауты — внутренняя кухня сервиса, но всё это занимает время. Если мы сделали супернадёжную систему, но пользователь, нажимая на кнопку создания заказа, смотрит на крутящийся спиннер 2 минуты, пока мы там в фоне ретраим или ещё что-нибудь делаем, то клиент просто уйдёт, и наша надёжная система станет никому не нужна.
Иногда лучше «упасть раньше» и сообщить клиенту, что у нас что-то не получилось, чем создавать бесконечное ожидание. Это вопрос уже не технический, а, скорее, продуктовый, но о нём тоже не стоит забывать.
Наша open-source библиотека
К сожалению, эта статья написана кровью. Чтобы избежать подобных ошибок в будущем, мы упаковали всю описанную выше логику в отдельную библиотеку. Библиотека предоставляет преднастроенные политики по умолчанию, позволяет их сконфигурировать (например, передать количество попыток при ретраях или время таймаутов). Например, все описанные выше политики с нашей библиотекой могут выглядеть так:
using Dodo.HttpClient.ResiliencePolicies;
…
// С настройками по умолчанию, если вы нам доверяете :)
clientBuilder
.AddDefaultPolicies();
// Вы можете определить свои настройки и использовать политики с этими настройками
var settings = new HttpClientSettings(…);
clientBuilder
.AddDefaultPolicies(settings);Под капотом мы используем Polly и предоставляем обёртку над этой библиотекой. Сейчас это решение по умолчанию для большинства наших сервисов. Если у нас нет каких-то специфичных требований (или нет желания читать всю документацию к Polly), то просто берём эту библиотеку и получаем HttpClient на стероидах.
Проект Dodo Open Source
Мы как компания исследуем тему и задумываемся о том, что нужно инвестировать в Open Source, а также вносить свой вклад в комьюнити разработчиков. В этом смысле платформенные инструменты и библиотеки — отличные кандидаты на эту роль. И начинаем мы как раз с библиотеки для повышения надёжности HttpClient’а.
Библиотека называется Dodo.HttpClient.ResiliencePolicies. Исходный код доступен на GitHub. Распространяется как NuGet-пакет.
Мы будем очень рады, если эта библиотека окажется вам полезной. И, разумеется, в этой библиотеке есть ещё над чем поработать, так что ваши Issues и PR приветствуются.
Заключение
Помните, с чего всё начиналось? Не с проблем с HttpClient’ом, а с Дня Святого Валентина. Так вот, 14 февраля мы успешно пережили, достигнув в пике 369 заказов в минуту. Мне как разработчику приятно осознавать, что наша библиотека стала одним из кубиков в стабильности всей системы. Помимо того, что мы научились лучше решать проблемы, возникающие при взаимодействии сервисов, мы также сделали первый шаг в сторону Open Source. И я искренне надеюсь, что это первый шаг на большом пути. Присоединяйтесь!
Полезные ссылки
- Cloud Design Patterns – прекрасный набор архитектурных паттернов от Microsoft, в котором раскрываются эти и множество других вопросов при проектировании распределённых систем.
- Библиотека Polly.
- Библиотека Dodo.HttpClient.ResiliencePolicies.





ZJenyaZ
Ceridan Автор
При работе с распределенными системами нужно быть немножко философом :)
Xneg
При работе с распределенными системами и разработке браузеров)
AgentFire
норм, vk api опрашивать — самое оно, его как мейл купил, так там через день 500 стало падать