

Исследователи из команды Microsoft AI представили новый алгоритм на ИИ, который может восстанавливать старые изображения, но не допускает искажений или потери текстур. Он использует метод глубокого обучения.
Новый алгоритм создает для реальных изображений синтетические фотопары. Команда Microsoft Research обучила два вариационных автокодера, которые помогают в этой работе.
Алгоритм считывает общие данные для обоих изображений пары, а затем находит разницу. Это могут быть механические повреждения старого снимка, например, пятна пыли или царапины. Он также отмечает дефекты снимка, в том числе размытость.
В работе алгоритма впервые задействовали предложенный исследователями параметр суперразрешения изображения (RefSR). Помимо изображения с высоким разрешением, которое является фотопарой входного снимка, используется новая сеть текстурных трансформеров (TTSR). Подобные методы уже использовали при обработке естественного языка.

Обучаемый экстрактор текстур использует обновленные параметры для каждого снимка в результате сквозного обучения. Это позволяет точно передать текстуру и избежать «мыльных» зон на восстановленной фотографии. Модуль мягкого внимания помогает более точно использовать переданные текстуры.
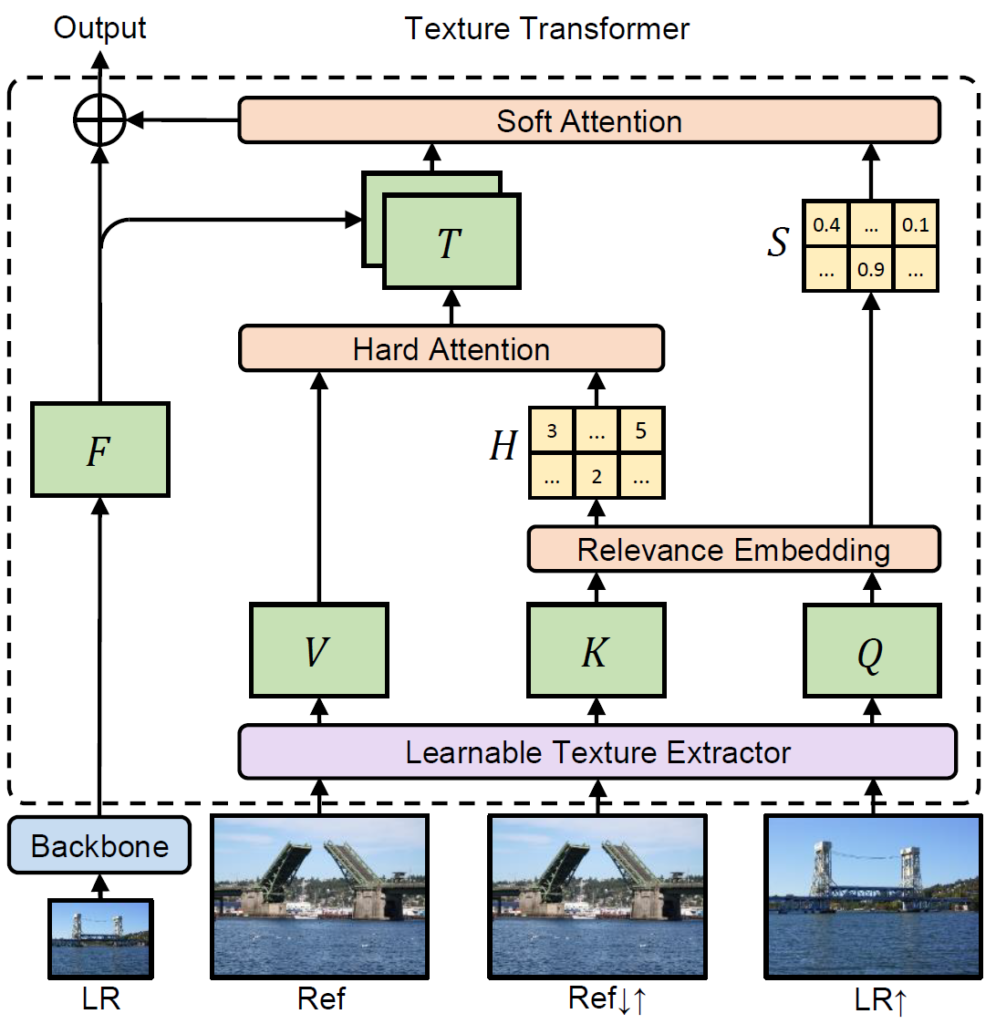
Отмечается, что эта новая методика превосходит самые современные методы восстановления старых фотографий.
Ранее исследователи продемонстрировали работу новой системы на ИИ, которая генерирует изображение «с повышением частоты дискретизации» в 64 раза по сравнению с оригиналом с низким разрешением. Был задействован алгоритм исследования скрытого пространства. Система показала, что воспроизведенное изображение может кардинально отличаться от оригинала. Данный метод вряд ли будет применяться при восстановлении снимков, но может быть полезен в сферах медицины или астрономии.
См. также:


MrCheater
Всегда задавался вопросом, почему такие публикации предоставляются без репозитория на github со скриптом start.sh, в который можно фотку скормить? Или с репозиторием, но чтобы там что-то запустить, нужно несколько дискретных видюх за 1000$ и пачка входных данных для обучения, которую не дали. Может кто-нибудь подсказать?
SidMeier
Реализация не публичная, в отличие от научной работы на тему, что позволяет компаниям на этом зарабатывать.
sumanai
Да и научная работа обычно не очень воспроизводима.
logran
Ибо на словах все «Лев Толстой», а на деле… Фейковые статьи на фейковых статьсях и фейковыми статьями погоняют.
Репозиторий с требованиями к пачке видях — это еще очень хороший случай. Тот же jukebox от OpenAI обучить можно только на пачке видях (очень большой пачке очень специфических видях), а попробовать (с трудом) — лишь на Google Colab если Tesla P100 словить. Но он рабочий. Его можно запустить и его код можно почитать. Просто очень большой и сложный.
Большинство статей (особенно новые «прорывные» методы дипфейков) этого не имеют и даже читая сами работы видно, что результаты подогнаны под статью и весьма сомнительны, а кода нет.
cepera_ang
В первую очередь, потому, что учёных оценивают по статьям, а публикация кода — не всегда даёт какие-то преимущества самим, но это относительно современный тренд и всё чаще работы без кода никуда особо не идут, кроме пыльных журналов, а те, что с кодом имеют хоть какой-то шанс на популярность.