
Однажды знойным зимним вечером к нам пришла идея написать приложение для проверки Sitemap фирмы, в которой мы работаем, с возможностью нотификации при возникновении ошибки.
Постепенно эта идея перешла к реализации, там появились мысли по улучшению, возник мониторинг хостов, затем — мониторинг приложений, и как вишенка на торте — инциденты с нотификацией.
В итоге мы получили полноценную систему мониторинга, являющуюся полностью open-source self-host решением, не имеющим внешних коммуникаций, с полностью определяемыми пользователем инцидентами.
И в этом посте мы хотим познакомить Вас с получившимся продуктом.
Для разработки была выбрана микросервисная архитектура. Бэкэнд разрабатывался на GoLang-е, как быстром и удобном языке для разработки микросервисов. Для общения между сервисами мы использовали gRPC. Кроме того, что gRPC работает на HTTP/2 со всеми вытекающими, описание интерфейсов сервисов через proto позволит Вам, как пользователям, создавать собственные имплементации отдельных частей системы, если в этом возникнет необходимость.
В проекте используются Mongo как база быстрого доступа и Postgres для хранения собираемой статистики.
Для сборки и деплоя использовался Bazel. Bazel позволяет декларативно описывать зависимости и отношения между пакетами в Golang. Кроме этого, мы начали тестировать Bazel с remote cache, что позитивно сказывается на скорости работы системы. Также Bazel собирает все приложения в Docker и организует Unit testing. Все это интегрировано в Github actions.
Dashboard системы написан на Angular 9.
Мы стараемся держать планку в unit тестах, в данный момент покрыта каждая сущность. В ближайших планах реализация интеграционных и E2E тестов, для наиболее полного поддержания системы
Как уже было сказано выше, Squzy представляет собой набор взаимодействующих друг с другом микросервисов, каждый из которых занимается отдельно взятой задачей.
Список сервисов:
Схема взаимодействия сервисов выглядит следующим образом:

Для демонстрации возможностей Squzy разработано демо, мониторящее свой же сервер и позволяющее следить за системой на dashboard’e: https://demo.squzy.app/.
Некоторые возможности, такие как добавление/удаление новых сущностей, в демо отключены, однако оно позволяет увидеть и пощупать все части системы. Ниже остановимся поподробнее на каждом из видов мониторинга.
Эта часть системы отвечает за external/internal проверки. В данный момент она позволяет отправлять запросы и ожидать ответы на следующие типы endpoint-ов:
Squzy позволяет добавлять свои заголовки ко всем видам HTTP проверок.
Интерфейс добавления проверки через Squzy dashboard выглядит следующим образом:
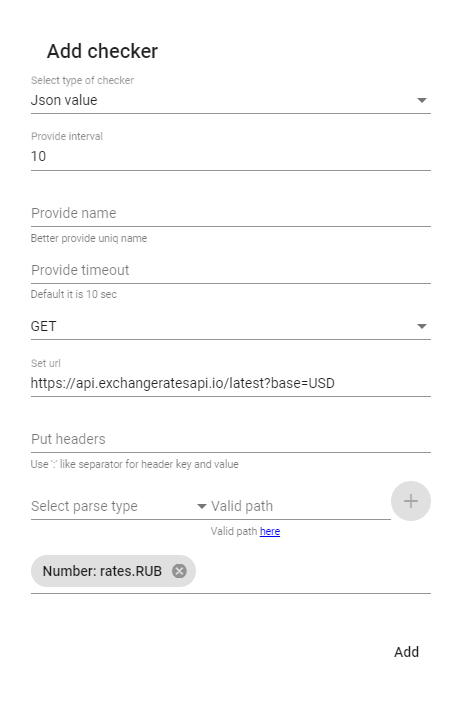
Здесь интервал — интервал между проверками в секундах, а timeout — время, после которого проверка считается неудачной.
После создания пользователю доступна конфигурация чекера:

На каждый вид проверки можно написать инцидент правило. Подробнее об инцидентах будет рассказано ниже, здесь же просто приведем пример:

В данном случае мы измеряем значение курса доллара с сайта, и если он будет больше 80 мы создадим инцидент.
Ссылка на demo.
Инциденты можно создавать на:
Для мониторинга хостов в системе используется Squzy Agent, устанавливаемый на сервер. В данный момент он собирает следующую статистику:
Timeline агента:
Если связи с сервером нет, агент продолжает собирать статистику и она будет отправлена при восстановлении соединения.
Demo версию агента можно посмотреть здесь: https://demo.squzy.app/agents/5f142b6141a1c6518723483a/live
Агент также может иметь набор правил для проверки инцидентов:

Для мониторинга приложений разработаны интеграции с популярными frameworks для Go/NodeJs (дальше больше, как говорят успешные маркетологи). Интеграции определяют тип транзакции (Http/Router/gRPC/WebSocket/etc) и анализируют ответы от движков/запросов.
Также Squzy поддерживает Tracing транзакций, что позволяет мониторить связанные между собой транзакции нескольких серверов/сервисов. Пример мониторинга таких транзакций на Dashboard: https://demo.squzy.app/transactions/om8l8LP96PRsvx67UxkES.
Библиотеки для интеграции в Go и Node Js.
По своей сути библиотеки представляют собой Middleware, засекающий время до отправки транзакции и время после ее обработки и анализирующий ответ. Также мы написали пример GO приложения для мониторинга: https://github.com/squzy/test_tracing.
Вы можете создавать свои транзакции и измерять время их выполнения, статусы и ошибки. Для это используйте пакет Core. Для удобства поддержки продукта во всех языках будут использоваться одинаковые названия для пакетов, определяющих поведение.
Можно создавать инциденты на транзакции, основываясь на следующих данных:
Инциденты в Squzy основаны на правилах. При добавлении новой сущности в Storage происходит проверка выполнения описанного правила, и в случае, если оно выполняется, создается инцидент (если он уже не был создан).
Правила представляют собой расширенную версию expr, к которой добавлены специфические правила, учитывающие спецификацию системы, такие как Last (берет n последних записей из Storage), Use (использовать при этом конкретный фильтр) и так далее. Подробное описание всех правил Вы можете найти на https://squzy.app/usage/squzy-incident/incident-rules, здесь же мы остановимся на показательном примере.
Представим, что у Вас есть сервер с 1792 процессорами, 256 Гб ОЗУ и 16 Тб места на жестком диске. И Вы очень хотите проверить, что ваш девопс не запускает Doom на мониторе отображения загрузки ЦП. Вы знаете, что поддержка одностраничного сайта, который обслуживает Ваш сервер, никогда не загружает на 100 процентов больше 8 процессоров дольше, чем на минуту. Кроме того, оперативка свободна более чем наполовину. В то время как жесткий диск имеет целый Тб свободного места в запасе (не хранить же известные архивы дома — жена увидит). В таком случае, зная, что метрики собираются раз в 10 секунд, вы можете определить следующее правило для проверки корректности работы Вашего сервера:
Аналогично Squzy позволяет описывать различные паттерны нежелательного поведения системы.
После того, как проверка правила прошла успешно (или, скорее, неуспешно), создается инцидент и происходит нотификация пользователя, в случае, если она настроена.
Активный инцидент, то есть инцидент, который еще не был проверен пользователем, может быть закрыт автоматически, то есть если он в какой-то момент не прошел проверку, в случае выбора соответствующего параметра.
На каждую проверяемую сущность будь то приложение/чекер/агент, можно создать свои нотификации об инцидентах.
Сейчас мы находимся в стадии сбора фидбеков и комментариев от IT- сообщества.
Уже сейчас у нас есть ряд планов по развитию продукта:
Мы будем рады любым фидбекам и предложениям.
P.S.:
Спасибо за статью Vonotirax
Попробовать в 1 клик
Постепенно эта идея перешла к реализации, там появились мысли по улучшению, возник мониторинг хостов, затем — мониторинг приложений, и как вишенка на торте — инциденты с нотификацией.
В итоге мы получили полноценную систему мониторинга, являющуюся полностью open-source self-host решением, не имеющим внешних коммуникаций, с полностью определяемыми пользователем инцидентами.
И в этом посте мы хотим познакомить Вас с получившимся продуктом.
Технические детали
Для разработки была выбрана микросервисная архитектура. Бэкэнд разрабатывался на GoLang-е, как быстром и удобном языке для разработки микросервисов. Для общения между сервисами мы использовали gRPC. Кроме того, что gRPC работает на HTTP/2 со всеми вытекающими, описание интерфейсов сервисов через proto позволит Вам, как пользователям, создавать собственные имплементации отдельных частей системы, если в этом возникнет необходимость.
В проекте используются Mongo как база быстрого доступа и Postgres для хранения собираемой статистики.
Для сборки и деплоя использовался Bazel. Bazel позволяет декларативно описывать зависимости и отношения между пакетами в Golang. Кроме этого, мы начали тестировать Bazel с remote cache, что позитивно сказывается на скорости работы системы. Также Bazel собирает все приложения в Docker и организует Unit testing. Все это интегрировано в Github actions.
Dashboard системы написан на Angular 9.
Мы стараемся держать планку в unit тестах, в данный момент покрыта каждая сущность. В ближайших планах реализация интеграционных и E2E тестов, для наиболее полного поддержания системы
Описание системы
Как уже было сказано выше, Squzy представляет собой набор взаимодействующих друг с другом микросервисов, каждый из которых занимается отдельно взятой задачей.
Список сервисов:
- Agent Client — клиент, разворачиваемый на устройстве. Собирает информацию о процессоре, загрузке памяти и сетевом взаимодействии. Отправляет информацию в Agent Server.
- Agent Server — обработчик информации, поступающей от клиента. Собирает список клиентов в Mongo, а информацию от агентов передает в Storage.
- Application Monitoiring — мониторинг приложений, осуществляемый путем добавления модулей/пакетов Squzy в приложения, собирающих информацию о транзакциях. На текущий момент поддерживается GoLang и NodeJS, в краткосрочной перспективе — PHP & Java имплементации.
- Monitoring — мониторинг external/internal сервисов.
- Storage — сервис для доступа к собранной статистике. Текущая имплементация использует Postgres, но в дальнейшем планируется перейти на ClickHouse.
- Incident Manager- обработка инцидентов. Система позволяет пользователю создавать свои собственные правила обработки нештатных ситуаций (подробнее об этом расскажем чуть позже). Сами правила хранятся в Mongo, в то время как инциденты в случае возникновения передаются в Storage.
- Notification Manager — сервис для уведомления пользователей в случае возникновения инцидента. На текущий момент поддерживает уведомления в Webhook & Slack.
- API — является API Gateway для системы
Схема взаимодействия сервисов выглядит следующим образом:
Для демонстрации возможностей Squzy разработано демо, мониторящее свой же сервер и позволяющее следить за системой на dashboard’e: https://demo.squzy.app/.
Некоторые возможности, такие как добавление/удаление новых сущностей, в демо отключены, однако оно позволяет увидеть и пощупать все части системы. Ниже остановимся поподробнее на каждом из видов мониторинга.
Эта часть системы отвечает за external/internal проверки. В данный момент она позволяет отправлять запросы и ожидать ответы на следующие типы endpoint-ов:
- Tcp — проверка открытого порта;
- gRPC — проверка по протоколу;
- Http — проверка на соответствие статус коду;
- SiteMap — проверка того, что все URL из Sitemap отвечают 200 OK;
- JsonValue — сбор определенных значений из JSON ответа.
Squzy позволяет добавлять свои заголовки ко всем видам HTTP проверок.
Интерфейс добавления проверки через Squzy dashboard выглядит следующим образом:
Здесь интервал — интервал между проверками в секундах, а timeout — время, после которого проверка считается неудачной.
После создания пользователю доступна конфигурация чекера:
На каждый вид проверки можно написать инцидент правило. Подробнее об инцидентах будет рассказано ниже, здесь же просто приведем пример:
В данном случае мы измеряем значение курса доллара с сайта, и если он будет больше 80 мы создадим инцидент.
Ссылка на demo.
Инциденты можно создавать на:
- Длительность проверки (время получения ответа от сервера);
- Статус (возвращаемый статус код);
- Значение (информация, передаваемая в чекере).
Squzy agent
Для мониторинга хостов в системе используется Squzy Agent, устанавливаемый на сервер. В данный момент он собирает следующую статистику:
- CPU — нагрузка по процессорам;
- Memory — Used/Free/Total/Shared;
- Disk — Used/Free/Total по каждому из дисков;
- Net — по каждому сетевому интерфейсу.
Timeline агента:
- Агент регистрируется в Agent Server и получает ID (при регистрации есть возможность указать интервал мониторинга и имя агента);
- Агент с определенным интервалом отправляет статистику на сервер;
- ….
- Агент уведомляет сервер о выключении.
Если связи с сервером нет, агент продолжает собирать статистику и она будет отправлена при восстановлении соединения.
Demo версию агента можно посмотреть здесь: https://demo.squzy.app/agents/5f142b6141a1c6518723483a/live
Агент также может иметь набор правил для проверки инцидентов:
Squzy Application Monitoring
Для мониторинга приложений разработаны интеграции с популярными frameworks для Go/NodeJs (дальше больше, как говорят успешные маркетологи). Интеграции определяют тип транзакции (Http/Router/gRPC/WebSocket/etc) и анализируют ответы от движков/запросов.
Также Squzy поддерживает Tracing транзакций, что позволяет мониторить связанные между собой транзакции нескольких серверов/сервисов. Пример мониторинга таких транзакций на Dashboard: https://demo.squzy.app/transactions/om8l8LP96PRsvx67UxkES.
Библиотеки для интеграции в Go и Node Js.
- Go — https://github.com/squzy/squzy_go (GIN/gRPC/Http);
- NodeJs — https://github.com/squzy/squzy_node (Express) + FE (Angular + vanilla).
По своей сути библиотеки представляют собой Middleware, засекающий время до отправки транзакции и время после ее обработки и анализирующий ответ. Также мы написали пример GO приложения для мониторинга: https://github.com/squzy/test_tracing.
Вы можете создавать свои транзакции и измерять время их выполнения, статусы и ошибки. Для это используйте пакет Core. Для удобства поддержки продукта во всех языках будут использоваться одинаковые названия для пакетов, определяющих поведение.
Можно создавать инциденты на транзакции, основываясь на следующих данных:
- Длительность транзакции;
- Статус транзакции;
- Полученные ошибки;
- Тип транзакции.
Squzy Incident Manager + Notification Manager
Инциденты в Squzy основаны на правилах. При добавлении новой сущности в Storage происходит проверка выполнения описанного правила, и в случае, если оно выполняется, создается инцидент (если он уже не был создан).
Правила представляют собой расширенную версию expr, к которой добавлены специфические правила, учитывающие спецификацию системы, такие как Last (берет n последних записей из Storage), Use (использовать при этом конкретный фильтр) и так далее. Подробное описание всех правил Вы можете найти на https://squzy.app/usage/squzy-incident/incident-rules, здесь же мы остановимся на показательном примере.
Представим, что у Вас есть сервер с 1792 процессорами, 256 Гб ОЗУ и 16 Тб места на жестком диске. И Вы очень хотите проверить, что ваш девопс не запускает Doom на мониторе отображения загрузки ЦП. Вы знаете, что поддержка одностраничного сайта, который обслуживает Ваш сервер, никогда не загружает на 100 процентов больше 8 процессоров дольше, чем на минуту. Кроме того, оперативка свободна более чем наполовину. В то время как жесткий диск имеет целый Тб свободного места в запасе (не хранить же известные архивы дома — жена увидит). В таком случае, зная, что метрики собираются раз в 10 секунд, вы можете определить следующее правило для проверки корректности работы Вашего сервера:
any(Last(7, UseType(All)),
{all(.CpuInfo.Cpus, {.Load > 80}) &&
.MemoryInfo.Mem.UsedPercent < 50 &&
.DiskInfo.Disks["System"].Free > 1000000000000}
)
Аналогично Squzy позволяет описывать различные паттерны нежелательного поведения системы.
После того, как проверка правила прошла успешно (или, скорее, неуспешно), создается инцидент и происходит нотификация пользователя, в случае, если она настроена.
Активный инцидент, то есть инцидент, который еще не был проверен пользователем, может быть закрыт автоматически, то есть если он в какой-то момент не прошел проверку, в случае выбора соответствующего параметра.
На каждую проверяемую сущность будь то приложение/чекер/агент, можно создать свои нотификации об инцидентах.
Заключение
Сейчас мы находимся в стадии сбора фидбеков и комментариев от IT- сообщества.
Уже сейчас у нас есть ряд планов по развитию продукта:
- добавление Java/PHP интеграций;
- чекеры баз данных;
- переход с Postgres на ClickHouse;
- больше методов нотификаций;
- интеграция с kubernetes;
- улучшение документации;
- GQL API;
- Интеграционные и E2E тесты ;
- мониторинг мобильных приложений.
- Автодополнения для правилов инцидентов на UI
Мы будем рады любым фидбекам и предложениям.
Ссылки
- Backend системы: https://github.com/squzy/squzy
- Frontend системы: https://github.com/squzy/squzy-dashboard
- Demo dashboard: https://demo.squzy.app/
- Документация: https://squzy.app/
- Авторы: PxyUp DreamAndDrum
P.S.:
Спасибо за статью Vonotirax
Попробовать в 1 клик





rzerda
Расскажите, чем это решение лучше Prometheus/TICK и чего-нибудь, основанного на OpenTracing? Почему отказались от версионируемой текстовой конфигурации и discovery в пользу API? Кто целевая аудитория?
PYXRU Автор
Prometheus — не поддерживает транзакции, также инциденты. Сейчас все можно налипить на всем. Мы писали из идеи: сделать все из коробки и удобные инциденты, которые вы можете сделать как угодно(мы про правила). Яб сказал наша система больше всего похожа на newrelic self-host бесплатная версия. Плюс своя система инцидентов которые вы можете написать как угодно только ориентируюясь на данные сбора. Целевая аудитория: мы писали в расчете на среднии компании, которым нужен мониторинг из коробки + не хотят платить деньги большие.
Конфигурация текстовая будет в дальнейшем, сейчас было сделано через API по той причине что Dashboard нужен был больше чем тектовая концигурация.