

К нам в рекламную группу Dentsu Aegis Network часто приходят компании-рекламодатели с запросом изучить и проанализировать их целевую аудиторию. И сделать это необходимо быстро и точно. Предположим, у нас есть клиент из автопрома, который хочет найти владельцев авто, а потом узнать их интересы, пол, возраст – в общем, «раскрасить» аудиторию. Логично было бы сделать социологическое исследование, но это займет несколько недель. А если у клиента очень дорогие авто стоимостью выше 2,5 млн рублей? Много ли таких владельцев наберется для исследования? А для фокус-группы?
Хорошим способом найти нужного человека остается социальная сеть. Это место, где пользователь оставляет о себе много полезной информации, а если даже информации нет, то можно попробовать собрать её с помощью “черной” магии. Да, все верно, тут на помощь приходит data science.
Будем решать задачи поступательно. Давайте подумаем, как найти автовладельца в социальной сети.
- Провести текстовый анализ постов
Казалось бы, здесь все просто. Написал «помыл свою зайку/ласточку» или «вечерние покатушки», и мы нашли нужного человека. Но потом выясняется, что часть примеров нерелевантна, а чистить приходится руками. - Поискать в хэштегах
Тоже вариант, но не соответствующих запросу аккаунтов еще больше: попадается и коммерция, и ребята, которые тюнингуют старые машины, и дрифтеры. А мы ищем владельцев авто за 2,5 млн рублей здесь и сейчас. - Найти пост с фотографией того авто, которое нам нужно и определить модель
Затем нужно придумать эвристику, которая с большой вероятностью бы говорила, что владелец этого аккаунта в соцсети также является владельцем нужной нам машины.
Мы пробовали все варианты, но остановились на последнем.
Первый подход к снаряду
Итак, нам необходима модель, которая бы определяла марку и производителя авто. Но сколько марок и производителей мы хотим охватить? Здравый смысл подсказывает, что можем взять наших клиентов, их основных конкурентов и на этом остановиться. Около 100 различных марок автомобилей более чем достаточно. Каждая марка автомобиля будет являться отдельным классом в модели.
Кажется, что 100 – это не так уж и много. Возможно, нам даже подойдет что-то из методов обучения с учителем. Это значит, что мы будем проводить обучение модели через примеры, по принципу «стимул-реакция».
А что если у нас появится новый клиент из нового сегмента? Будем добирать еще 50-100 марок? Да, есть компании, которые идут именно таким путем, новая проблема – это новая модель. В итоге получается зоопарк различных моделей. Мы решили, что на обучение новой модели у нас просто нет времени, поэтому сделаем все сразу.
Небольшая, но важная подготовка датасета
Если мы хотим что-то более универсальное, то в таком случае напрашивается подход обучения без учителя: система должна обучаться спонтанно, без привлечения экспериментатора. Для такого подхода собирать данные проще – берем из интернета все картинки по релевантному запросу. Благодаря тому, что многие поисковые инструменты позволяют фильтровать контент по лицензии, можно быть спокойными за соблюдение авторских прав.
Сначала данные:
Оказалось, что многие поисковые инструменты под запросом «автомобиль» могут понимать вот это:

Технически это, конечно, автомобили, но не совсем те, которые нужны нам.
Гораздо хуже, когда результат такой:

Нам был необходим датасет из качественных фотографий автомобилей в полную величину с разных сторон – спереди, сзади, сбоку. Поэтому для очистки данных мы обучили нейронную сеть так, чтобы она отбирала из всего набора фотографий только подходящие под наши критерии. Для того, чтобы выделить на изображении машину и вырезать её, мы применили подход детекции объектов.
Источник
Object detection – это технология, связанная с компьютерным зрением и обработкой изображений, которая позволяет находить объекты определенного класса на изображениях и видео.
В качестве архитектуры взяли retinanet, так как уже был готов весь пайплайн, нужно только подложить разметку. Для разметки воспользовались инструментом CVAT (подробнее мы рассказывали на pycon’19) и всей командой потратили несколько часов на это веселое занятие. За это время удалось разметить несколько тысяч картинок, что позволило обучить модель с mAP ~ 0.97.
С какими сложностями мы столкнулись при подготовке набора данных? Первое, что хочется отметить – это отсутствие автолюбителей в нашей команде, из-за чего иногда возникали споры по поводу сложных случаев, например, когда кузов авто визуально едва ли отличим на разных моделях. Хорошим примером могут послужить Lexus RX и Lexus NX.

Гораздо сложнее, когда кузов один и тот же, а названия автомобилей разные. Такое случается, когда бренд по разному себя позиционирует на разных рынках. Примеры Chevrolet Spark и Ravon R2:

Autoencoder
Приступаем к выбору модели. Первое что пришло нам на ум, – это автоэнкодеры.

Автоэнкодер – это нейронная сеть, состоящая из двух частей: энкодер и декодер, предназначенная обычно для снижения размерности.
- Энкодер сжимает входные данные в скрытое пространство (latent space).
- Декодер восстанавливает входные данные из скрытого пространства.
Прелесть автоэнкодера в том, что он обучается без учителя. А скрытое пространство может помочь кластеризовать данные.
С помощью автоэнкодеров кластеризуют даже Trading Card Game карточки, например, Magic the Gathering, так что появилось желание сделать кластеризацию автомобилей именно через этот инструмент. К сожалению, получилось неудачно: время потратили, а результат не оправдал ожиданий. Стали думать дальше.
Semantic Embeddings
И наткнулись на эту статью. В ней авторы предлагают обучить нейронную сеть с иерархической структурой классов для получения эмбеддингов, учитывающих семантическую близость объектов.
Идея кратко: мы не просто ищем визуально похожие объекты, но и учитываем семантику запроса, т.е. пикапы должны располагаться в искомом пространстве ближе к пикапам, кабриолеты к кабриолетам и т.п.
Иерархия классов представляет собой направленный ацикличный граф с множеством вершин и множеством ребер , что определяет гипонимические связи между семантическими понятиями. Другими словами, ребро означает что является подклассом . Тогда классы являются вершинами такого графа . Пример графа представлен ниже:

Авторы использовали меру непохожести , рассчитываемую по формуле , где под высотой имеется в виду самый длинный путь от текущей вершины до листа. двух вершин – это ближайший предок к этим двум вершинам. Так как ограничено между 0 и 1, авторы определили меру семантической близости между двумя семантическими понятиями как .
Рассмотрим граф из рисунка выше, его высота равняется 3, , а , тогда , а . Таким образом, кошка и собака в представленной модели более близки семантически друг к другу, чем собака и форель.
Цель авторов – посчитать вектора единичной длины для всех классов , так, чтобы скалярное произведение векторов соответствующих классов было равно мере их похожести:
Собирать такой датасет показалось слишком долгим и дорогим процессом, ведь помимо сбора релевантных фотографий необходимо думать над грамотной иерархией классов по текстовым запросам. Но авторы предлагают вариант без иерархии, с поддержкой датасета Stanford Cars, который имеет 196 различных классов автомобилей и по 80 фотографий на каждый (почти то, что нам нужно, да?). Результат на stanford cars оказался лучшим, чем все то, что было до этого. Но на наших данных повторить успех не удалось. Понять, что на это повлияло – плохая разметка, шум в данных или что-то еще – не удалось, так как время на эксперименты закончилось, а проект был отложен на неопределенный срок.

Siamese Networks или от китов к машинам
Спустя 9 месяцев снова родилась необходимость в определении модели авто по фото. На этот раз у нас была возможность привлечь команду асессоров, чтобы собрать более качественный датасет. А самое главное, появилось понимание, какие марки авто нам нужны точно и какие необходимо добавить, чтобы иметь задел на будущее. Вместе с более качественной разметкой пришла идея использовать metric learning подход, например, сиамские сети c triplet loss.
Сразу в голове всплыло соревнование на kaggle, которое проходило совсем недавно, да еще и полностью дублирует нашу задачу: по фотографии хвоста кита определить, какой особе он принадлежит. Не долго думая мы взяли решение первого места и использовали его на наших данных. Архитектура этого решения представлена ниже.

Было привлекательно, что решение представляло из себя всего одну модель, а не целый зоопарк, как это бывает на kaggle. Из интересных особенностей, которые могли быть использованы у нас: на вход к 3 стандартным RGB каналам подаются маски. Поэтому размер входа составляет 512х256х4.
В первом подходе мы решили обучить модель без использования масок и получили на валидации mAP = 0.89. Такой результат с самого старта нас очень обрадовал. Но прогнав модель на отложенной выборке из «живой» среды обитания результат оказался плачевен.

Причина заключалась в том, что природа живых фотографий сильно отличается от собранных фотографий в датасете. И при его создании никто на это не обратил внимания.
Пример из обучения:

Что поступало на вход, и это ещё очень удачный пример:

Очевидно, что нужно было что-то сделать с обучающим набором данных. Мы решили оставить всё как есть, но использовать более сильную аугментацию. Для этого использовали пакет albumentations. Он поддерживает bounding box’ы и mask’и, имеет множество готовых преобразований: помимо стандартных flip-crop-rotate еще и различные distortion’ы.
К более сильной аугментации решили сразу добавить маски. Для предсказания масок использовали фейсбуковский detectron. Мотивацией послужило наличие модели для сегментации изображений, обученной на датасете COCO, в котором присутствует класс авто. И наличие пайплайна под детектрон, потому что он уже был использован в команде. А еще мы любим копаться в гите facebookresearch.
Обучив модель на дополненных данных с новой аугментацией, мы смогли получить mAP ~ 0.81. Это сильно хуже предыдущего результата, но зато модель получилась более жизнеспособная.
Эвристики
Теперь, научившись работать с марками машин, мы вплотную подошли к проблеме эвристик, которые помогут отличать истинного владельца от ложного. Давайте разберем основные варианты ошибок, которые могут встретиться:
- Пользователь сфотографировался с автомобилем на фоне.
- Авто могло оказаться на фоне случайно.
- Автолюбитель выкладывает фотографии его любимых марок. Тут может быть случай и многих различных марок, и одной единственной.
- Мы попали в профиль автодилера, автомастерской или автоблогера.
- ...
- И десятки других вариантов.
Как понять, что две фотографии одного и того же автомобиля являются одним и тем же автомобилем? Можно определить цвет автомобиля. Но с цветом имеются свои проблемы, так как даже зеленый цвет при определенном освещении выглядит серым. Кажется, что если мы научились отличать несколько сотен моделей авто друг от друга, то с цветом проблем возникнуть не должно. Поэтому мы взяли пайплайн для retinanet и обучили еще одну нейронную сеть на определение 16 цветов.
Чтобы найти владельца искомого авто с высокой вероятностью, оказалось достаточным зафиксировать определенный период времени, к примеру, в полгода или год, и оставлять только тех пользователей, у которых внутри этого периода не так много различных марок авто. При этом искомая марка должна встречается не менее определенного количества раз и быть одного и того же цвета.
Заключение и применение модели
Мы научились находить владельцев определенных авто по их постам. Что нам для этого понадобилось: нейронная сеть для первичной чистки данных; 5 человек, помогающих с разметкой; нейронная сеть для создания масок; нейронная сеть для определения марки автомобиля; нейронная сеть для определения цвета автомобиля. Почему бы теперь не применить результат в бою?
Попробуем найти владельцев BMW с большим количеством подписчиков:

Фотография BMW M5. Источник.
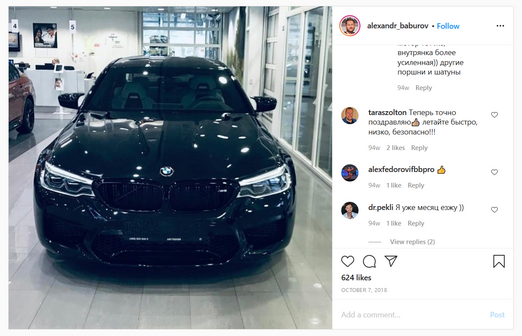
Ещё один пример BMW M5 от того же автора. Источник.

BMW 3 серии. Источник.
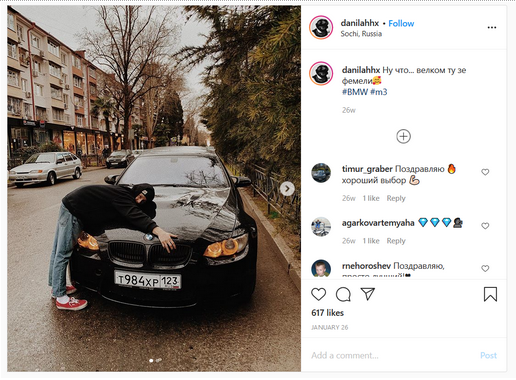
BMW M3. Источник.
Зачем нам искать владельцев BMW с большим количеством подписчиков, которые часто постят свой автомобиль? Например, они могут стать амбассадорами бренда.
Статья начиналась с того, что мы хотим найти автовладельцев конкретной марки, для того, чтобы рассказать кто они с точки зрения интересов, пола и возраста. Давайте протестируем этот подход на Audi:
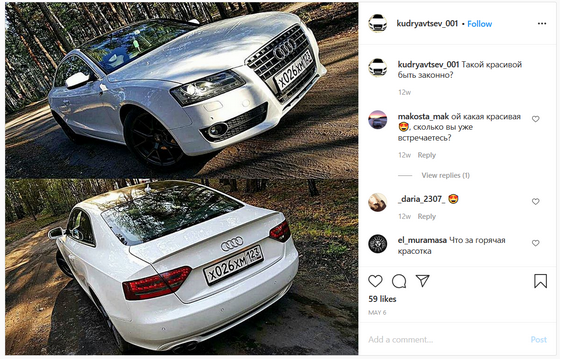


С определением пола и возраста по профилю в социальной сети всё более-менее понятно. Могут возникнуть вопросы, как определять интересы по профилю. Для этой цели мы пользуемся алгоритмом определения пересекающихся сообществ, описанным нашей командой в прошлом году. Посмотрим что получается:
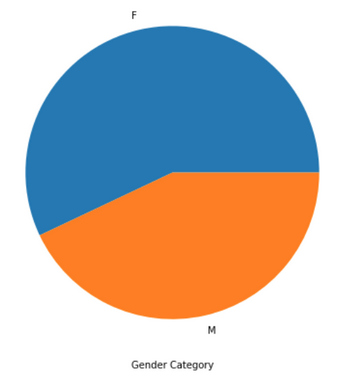
Распределение по полу:
Распределение по возрасту:

Топ-10 верхнеуровневых интересов:

Спустимся на два уровня ниже в категорию “Спорт и активных отдых”:

Кажется, что Audi преимущественно не женский автомобиль. Разберемся почему же у нас выходит 57% женщин? Согласно исследованию brand analytics, распределение мужчин и женщин в инстаграме соотносится как 25:75. Учитывая этот факт, можно сделать перевзвес наших данных и получить более натуральное распределение по полу среди автовладельцев Audi. По этой причине при анализе социальной сети необходимо учитывать её специфику.
Что ещё мы можем узнать про автовладельцев?
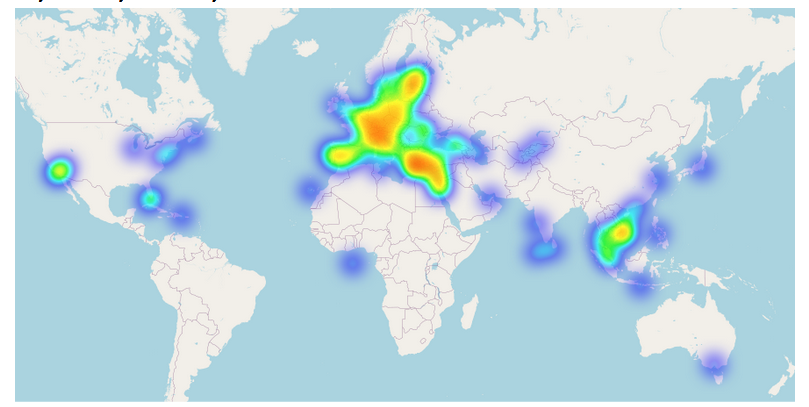
Например, откуда они:

И куда они путешествуют:
Что можно сделать еще?
Здесь можно выделить два направления: улучшение текущего решения и новые подходы. Гипотезы для улучшения модели:
- В первую очередь хотелось бы ещё раз пройтись по датасету. Как известно, есть прямая взаимосвязь между качеством моделей машинного обучения и данных, которые они используют.
- Mixup аугментация. Смысл её в том, чтобы с разными весами смешать две картинки в одну. Веса при этом должны давать в сумме единицу. Сложность заключается в том, что для такой аугментации нужны несколько картинок. В то время как пакет albumentation работает с одной картинкой на вход. Делать самописное решение или добавлять стороннее для проверки гипотезы на тот момент показалось нецелесообразным.
Пример:

- Попробовать другие архитектуры нейронных сетей. Тут всё просто — мы взяли решение первого места. Но ведь можно попробовать более простые архитектуры, потерять немного в качестве, но сильно выиграть в скорости. Ведь мы не на kaggle, и нам не так важны сотые и тысячные значения в метрике качества.
- Добавить задачу определения цвета автомобиля в нейронную сеть определяющую марку и модель автомобиля. Иногда оказывается, что добавление дополнительного выхода в нейронную сеть для решения ещё одной проблемы повышает и качество метрики, и обобщающую способность.
Что касается новых подходов: мы использовали только внешний вид автомобиля, чтобы определить марку и модель. Но можно применить ту же самую технику и для определения модели по фотографии салона. Это может стать одним из наших следующих шагов.

Благодарим за внимание и надеемся, что этот материал будет полезен и интересен читателям Хабра!
Статья написана при поддержке моих коллег Артёма Королёва, Алексея Маркитантова и Арины Решетниковой.
R&D Dentsu Aegis Network Russia.


{kind=link}
algotrader2013
Без обид, но попахивает лютым оверинжинирингом и задачей ради процесса решения, а не результата.
Понимаю, что задача определения автомобиля по фото это прям серьёзный интересный вызов уровня FAANG, и хорошо, когда хозяин бабла готов оплачивать такой опыт. Но, если говорить о коммерческой части, то вижу следующее:
Прежде всего, судя по фоткам-примерам, где все кейсы максимально простые, подобный результат можно получить и сильно проще. Например, поиском госномера на картинке и последующим поиском логотипа над номером.
Идем дальше. Раз уж несложно доставать госномер (а это задача прям затяганная, как предсказание утонувших на титанике), то не дешевле ли поискать базу номеров, и по ней получать модель. Скорее всего, в РФ это может быть незаконно, но, как говорится, на что не пойдёт капиталист… А цена базы может быть ух как дешевле, чем работа датасаентистов.
Ок. Вы научились определять. Глазами посмотрели. Все ок, красиво. Но! Теперь идем к выводам. Если цель — делать реально полезные статистические выводы, то надо и не забывать об условных вероятностях. А о них в тексте ни слова, хотя они могут сломать тему напрочь. Например, нейросеть определяет BMW из за более характерных черт кузова, как ноздри, на 30% лучше, чем Toyota, но вы об этом не знаете -> привет перекос в исследованиях вида "на какой машине ездит наш клиент". Или ещё, предположим, что девушки реже фоткаются около свой машины, чем парни -> получаем перекос в соцдем исследованиях. Продолжать можно очень долго.
tim_kadyrov Автор
Никаких обид! Тем более это очень здоровая критика.
Вы правы, задача действительно решается сложным путём и выглядит как оверинжиниринг. Мы бы хотели сделать решение проще. Были даже предприняты несколько подходов, в основном связанные с текстами. Но получилось плохо, всё равно оставалось множество нерелевантных запросу примеров.
Если бы была законная возможность иметь доступ к базе номеров, то мы скорее всего пошли бы именно таким путём. Но тогда встает вопрос: что делать с фотографиями на которых номер либо не виден, либо скрыт?
И вы снова абсолютно правы на счет смещения в статистических исследованиях. Кажется, что сделать не смещенное статистическое исследование основанное на социальной сети не простое занятие. На мой взгляд, эта тема выходит за рамки текущей статьи. Спасибо за пищу для размышлений, мы постараемся подготовить материал на эту тему. :)
В защиту текущей модели могу добавить, что собирать отчёты с минимальным привлечением человека стало проще.
rinatsakaev
Необязательно даже искать логотип над номером, есть сайты, которые дают и модель авто
tim_kadyrov Автор
Возможно, мы плохо исследовали вопрос. Не подскажите какие сайты и сколько стоит 1000к распознований? Например, cloud vision api гугла нам не подошёл. Но даже если бы он умел хорошо определять модель авто, то при наших объемах его стоимость обходилась бы космических денег.
rinatsakaev
Видимо, невнимательно статью прочитал. Вот здесь можно поискать по номеру и получить модель. Но это не решает вашего вопроса, так что извиняюсь.