

Понятие DevOps знакомо многим, но в своей практике я часто наблюдаю такую ситуацию, когда соискатель на должность DevOps-инженера в нашу компанию не может ответить на вопрос “А что же такое DevOps?”. В данной статье я хочу упорядочить и структурировать знания и основные понятия DevOps. Ещё раз обозначить какие процессы там существуют, для чего они и с чего начать внедрение DevOps у себя в проекте.
Философия
На текущий момент нет чёткого определения DevOps и каждый трактует его хоть и во многом схожим образом, но всё же по-своему. Если открыть любую статью, то там будет написано, что DevOps — это, прежде всего, философия, а уже только потом практика. Для тех, кто только начал заниматься данным направлением, это может показаться не очень очевидным, но по мере получения опыта смысл сказанного становится более понятным.
В своей практике мы встречаем несколько различных определений DevOps. Достаточно распространённым является то, в котором DevOps представляет собой использование специальных инструментов для построения CI/CD для деплоя новых версий приложения.
Основная проблема такого понимания в том, что оно не даёт ответа на вопрос для чего и как это делается. В действительности попытки применить в проекте DevOps именно в такой трактовке приводят к серьёзным проблемам. Мы не раз сталкивались с этим, когда только начинали предлагать нашим клиентам DevOps как услугу.
Например, если в проект с таким замечательным набором ПО для деплоя как FileZilla и бэкапами в качестве системы контроля версий добавить DevOps в обозначенной выше формулировке, и при этом не донести до разработчиков философскую составляющую, то это с высокой вероятностью приведёт к тому, что они продолжат править код прямо на production-сервере, особенно в случае обнаружения критических ошибок. Бывало и такое, что для этих целей нас даже просили поставить SSH-сервер в Docker-контейнеры.
Со временем мы пришли к пониманию того, что большинство возникающих проблем являются вызовом, скорее, с точки зрения культуры, чем технологий и перестали внедрять DevOps без предварительной идеологической подготовки сотрудников клиента.
Теперь давайте представим себе традиционную модель процесса создания ПО. В ней разработка и эксплуатация — это два разных, не всегда тесно связанных между собой отдела. При этом, их цели и задачи являются диаметрально противоположными. Первые нацелены на более частые релизы приложения. Желательно, сразу после внедрения новых фич, функционала или исправления ошибок. Но они сильно зависят от сотрудников отдела эксплуатации, для которых каждый релиз — это боль, т.к. требует внесения изменений в работающую инфраструктуру, что несёт определённые риски для её стабильности. А к этому критерию могут быть привязаны и их KPI. Поэтому при таком подходе эксплуатация будет стараться производить деплой новых версий ПО как можно реже, например, задавая окна для релиза раз в определённый период.
Всё это приводит к тому, что продукт будет выкатываться большими кусками, с объёмным набором нового функционала, который намного сложнее протестировать, откатить в случае необходимости и, что немаловажно, усложняет сбор обратной связи от пользователей.
Кроме того, в динамично развивающемся проекте требования к нему в целом или к определённой части его функционала могут меняться весьма часто, вплоть до нескольких раз за день. Это сделает релизы ещё более долгими и тяжёлыми.
Как видите, для того, чтобы Dev’ы и Ops’ы в описанной традиционной модели могли не только дружно уживаться, но и вместе создавать большие и сложные проекты, требуется дополнительная философская составляющая, направленная на активное взаимодействие и интеграцию команд разработки и эксплуатации, с целью повышения скорости выпуска и качества новых версий разрабатываемого ПО. Именно такую философию называют DevOps.
Давайте посмотрим из чего она состоит:

Как и многие другие, данная модель включает в себя теоретическую и практическую компоненты, а также имеет дополнительный слой, который на схеме представлен как “Процессы", играющий роль своеобразного буфера при переходе от теории к практике.
Что касается теории, то кроме первого базового элемента, а именно понимания тех самых принципов DevOps, приведённых выше, имеются и другие. Следующим из которых является коллективное владение продуктом (shared ownership):

Говоря другими словами — совместное владение различного рода информацией и знаниями о разрабатываемом продукте. Это важнейшая составляющая культуры DevOps, т.к. является тем самым “склеивающим раствором” между разработкой и эксплуатацией, поскольку первые начинают думать не только над тем, как будет выглядеть тот или иной функционал для конечного пользователя, но и, понимая как всё это будет работать, выбирать более правильные методы реализации, учитывая особенности работы системного ПО. Ops’ы, обладая соответствующей информацией, со своей стороны тоже смогут выбирать и предлагать более качественные, оптимальные и удобные решения с точки зрения разработки проекта. Это касается всего, что позволило бы максимально учесть все нюансы будущего приложения, от проектирования инфраструктуры и до выбора конкретных программных элементов, таких как, например, БД.
Такое вовлечение в общий процесс различных участников проекта позволяет каждому из них рассматривать проблему с разных точек зрения и наладить максимально тесное взаимодействие:

Это повысит командный дух и решение даже самых сложных задач станет интересным и увлекательным занятием.
Ещё одной значимой составляющей в философии DevOps является культура, направленная на совершенствование имеющихся процессов:

Не надо бояться экспериментировать и пробовать новые методологии и практики. Единственное, эти эксперименты должны быть контролируемыми, а все изменения хорошо прорабатываться перед внедрением. Данный момент ещё будет затронут далее в статье.
Процессы
Теперь перейдём к процессам, которые являются проводниками внедрения DevOps в проекте и первым шагом на пути практической реализации всех обозначенных выше принципов.
MVP
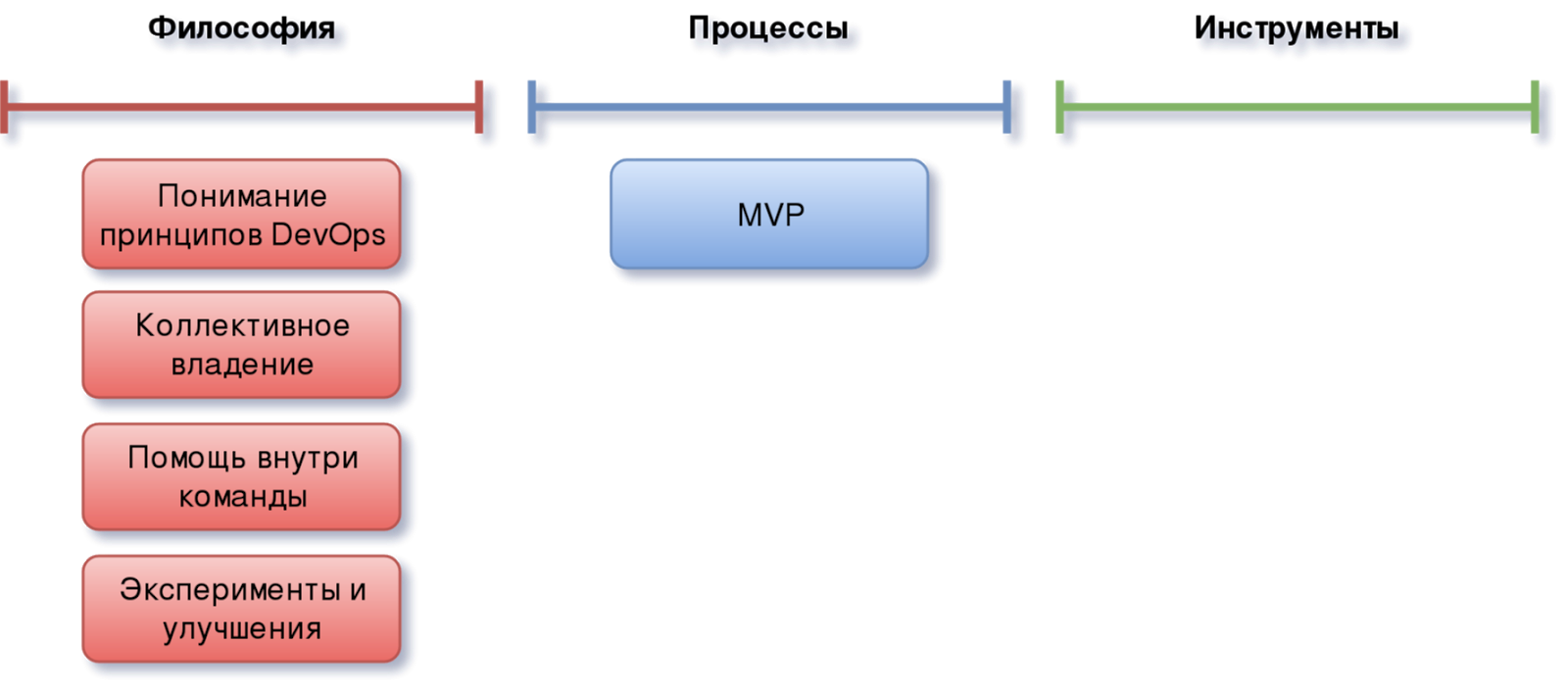
Первое о чём хотелось бы поговорить, прежде чем приступим к основной части — это MVP. Неважно какие у вас процессы, насколько хорошо они отлажены и оптимизированы. Все они так или иначе предназначены для разрабатываемого продукта, а любой продукт имеет начальную версию. Часто желанием разработчиков или даже самого заказчика, является запуск продукта после реализации всего предусмотренного функционала.
Когда задача хорошо декомпозирована и имеет проработанный roadmap, это происходит быстро и не становится проблемой. Но если первый кусок очень крупный, то процесс выхода на рынок может быть сопряжён с большими задержками и сложностями. Например, пока вы пилите своё идеальное приложение, часть функционала может устареть или кто-то другой займёт соответствующий сегмент рынка раньше. Мало приятного.
Поэтому выбор верного баланса между временем разработки и реализацией минимально необходимого функционала, который позволит показать ваш продукт целевой аудитории с лучшей стороны — это залог успешного старта и дальнейшей жизни проекта.
Continuous Integration
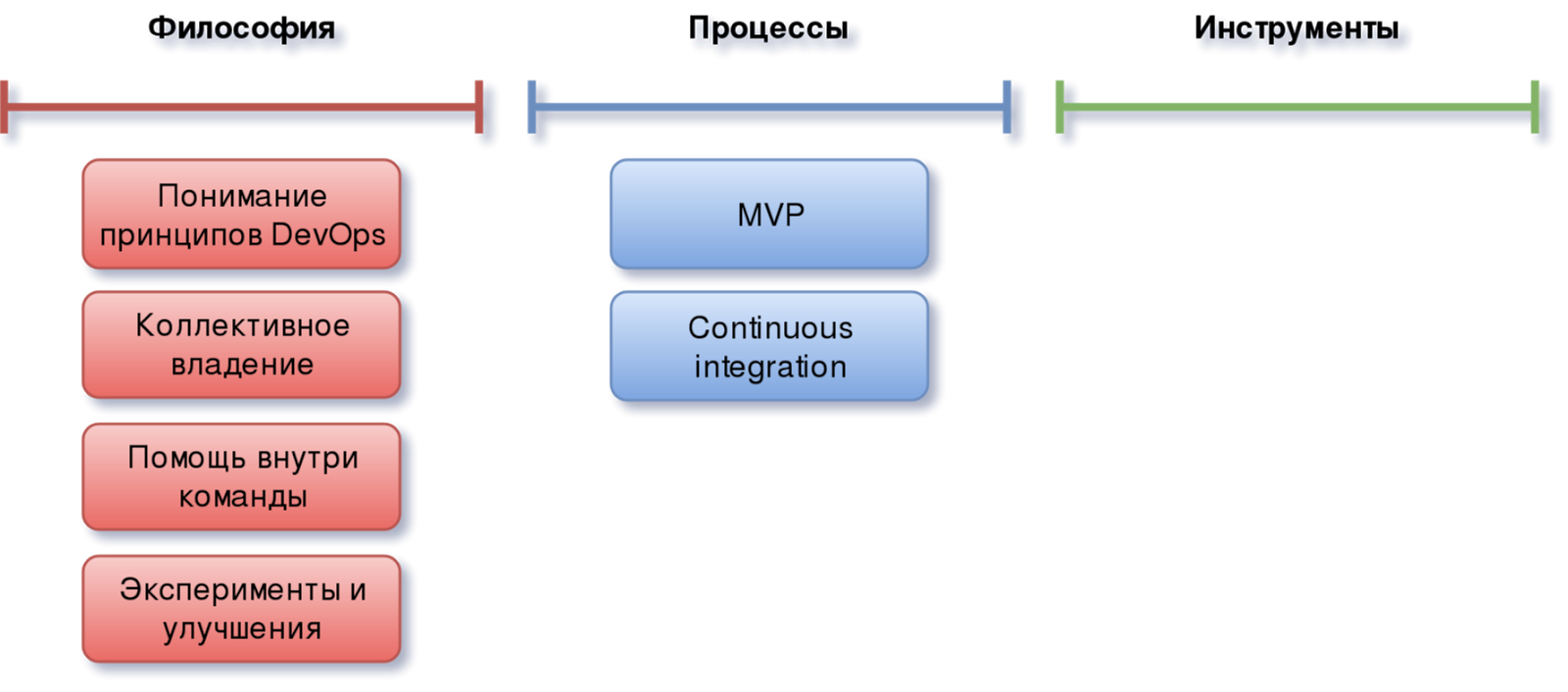
Каким бы по размерам не был продукт и на какой бы стадии его разработки вы не находились, вам потребуется иметь дело с системой контроля версий.
Вы можете выбрать любую из них даже такую:
но помните, что так или иначе вы столкнётесь с необходимостью интеграции в единое целое не только отдельных частей проекта, таких как новые фичи, исправление багов и прочее, но и других процессов.
Для того чтобы разработка была максимально комфортной, а имеющаяся рутина как можно менее заметной, интеграция должна быть непрерывной. Т.е. подразумевается, что в любой момент времени в проекте могут (и, по-хорошему, должны) протекать процессы, запущенные вами или кем-то другим, направленные на сборку всего в единое целое.
Современные системы контроля версий предоставляют механизм ветвлений в качестве базы для непрерывной интеграции. Работа с различными ветками, их слияние между собой или в master, является пультом для управления Continuous integration в проекте.
Разумеется, что чем более удобные для себя процессы вы захотите построить, тем более сложными они получатся и тут никак не обойтись без автоматизации. Которая иногда занимает много времени и является весьма нетривиальной задачей, но это поможет решить множество интеграционных вопросов, таких как, например, сборка, выявление дефектов на ранних стадиях и другие. Что в конечном итоге существенно упростит и удешевит весь процесс.
Есть множество подходов по практической реализации CI, и все они зависят как от особенностей самого проекта, так и от конечной диаграммы процессов, которые необходимо получить в итоге.
При выстраивании CI нужно учесть:
- В системе контроля версий помимо кода приложения должно располагаться всё необходимое для его сборки и самотестирования
- Автоматизация сборки
- Автоматизация тестирования
- Разработка всех новых фич только в отдельных ветках
- Каждый пуш во временные ветки должен сопровождаться сборкой приложения
- Ежедневные пуши в центральный репозиторий всеми участниками проекта
- Наличие stage-ветки
Continuous Testing
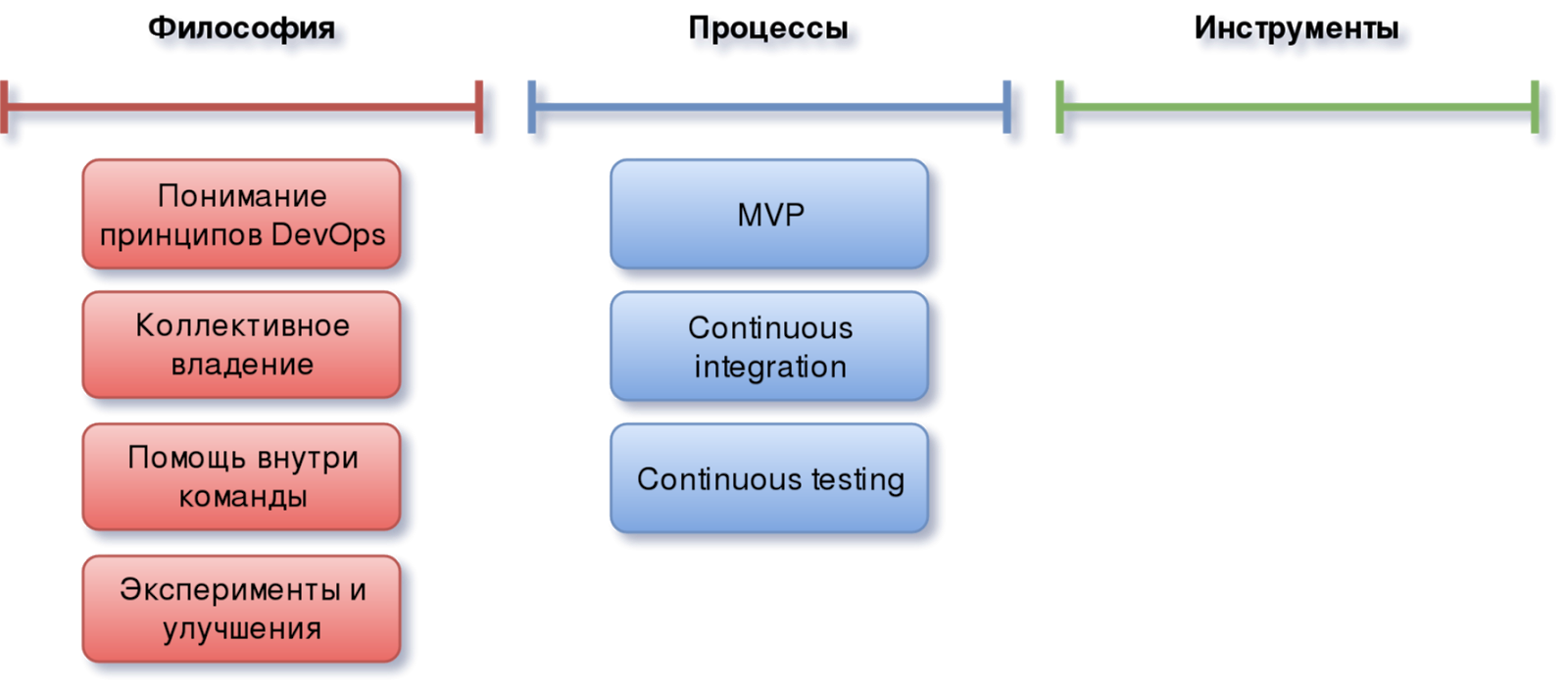
После того как ваш код написан и до того, как будет доставлен в production — он должен быть тщательно протестирован. Казалось бы, это очевидно, но на деле об этом заботятся далеко не все. Часто ограничиваются проведением только unit-тестов, а некоторые вообще тестируют на конечных пользователях в продуктовой среде и сейчас я имею в виду не A/B тестирование))
Помимо Dev и Ops одной из составляющих DevOps, правда, не такой явной, является QA. И обеспечение качества тоже должно быть частью общего Continuous!
В правильно сбалансированных проектах роль тестирования настолько велика, что влияет не только на Continuous Integration и Continuous Deployment, но и определяет вид всей инфраструктуры. При этом разработка всего необходимого для выстраивания этого процесса может занимать чуть ли ни половину от всех временных затрат на внедрение DevOps.
В прошлом году на IT-Nights я выступал с докладом, где рассказывал про микросервисную архитектуру. В нём я приводил схему, которую мы придумали и внедрили в рамках реализации одного из проектов:

Схема достаточно непростая и чтобы её подробно раскрыть потребуется отдельная статья, которую я планирую написать при первой же возможности. Сейчас я бы хотел её показать, только как демонстрацию того, как может трансформироваться инфраструктура, где обеспечению качества уделено особое внимание.
Да, процесс сложный, иногда очень нудный и не всегда интересный. Его даже можно игнорировать до определённого момента. Но главное не пропустить точку невозврата, потому что в конечном итоге это необходимое условие для предоставления качественного сервиса и, как следствие, успешного развития проекта.
Continuous Deployment

Теперь, когда всё интегрировано и протестировано, найдены и устранены все основные дефекты (ну или почти все ...), пришла пора переходить к доставке кода.
Что хотелось бы получить от этого процесса:
- Автоматическое обновление ПО
- Предоставление нового функционала постепенно
- Быстрое получение отклика от клиентов
- Быстрое реагирование на изменения рынка и бизнеса
- Снижение количества ошибок в production
- Упрощение работы Dev’ам и Ops’ам
Т.е. и к этому процессу предъявляются требования автоматизации и непрерывности. Так мы получаем Continuous Deployment.
Непосредственная реализация деплоя зависит от среды назначения и не обязательно должна производиться в Kubernetes. Помимо того, это может быть и одиноко стоящий bare-metal server, и кластер на железе, и даже пакетный репозиторий. И, очевидно, что выбор инструментария для решения этой задачи будет зависеть от того, куда именно потребуется делать деплой.
Если говорить именно о разработке и доставке сервиса, то придётся познакомиться с такими понятиями как stateless и stateful, а также столкнуться со множеством проблем, основными из которых будут:
- Простои при деплое
Естественно, всем хотелось бы выкатывать новые версии своих приложений так, чтобы при этом пользователи не наблюдали перебоев в их работе. Но, порой, это весьма дорогостоящий процесс, обеспечение которого может занять неоправданно много сил и времени. - Откат версии приложения
А когда приходится иметь дело с БД и миграциями, всё становится совсем печально.
Вообще тема Zero downtime и откат версии приложения в совокупности с БД — это действительно непростой процесс, который всегда надо чётко контролировать. В рамках данной публикации всё это рассказать будет не реально, но у нас по этой теме есть несколько статей на Habr’e (вот и вот), а также в прошлом году я делал доклад на Стачку “Rest API сервер от кода до деплоя”, там освещаются основные аспекты и те моменты, на которые стоит обратить внимание при построении деплоя с нулевым простоем совместно с прямыми и обратными миграциями БД. На эту тему я так же планирую позже написать статью.
И, кстати, Continuous Deployment тоже должен быть обёрнут в тесты. Т.е. проверка качества должна происходить не только перед доставкой кода, но и даже после этого. Разумеется, это будут разные типы тестирования.
Continuous Infrastructure
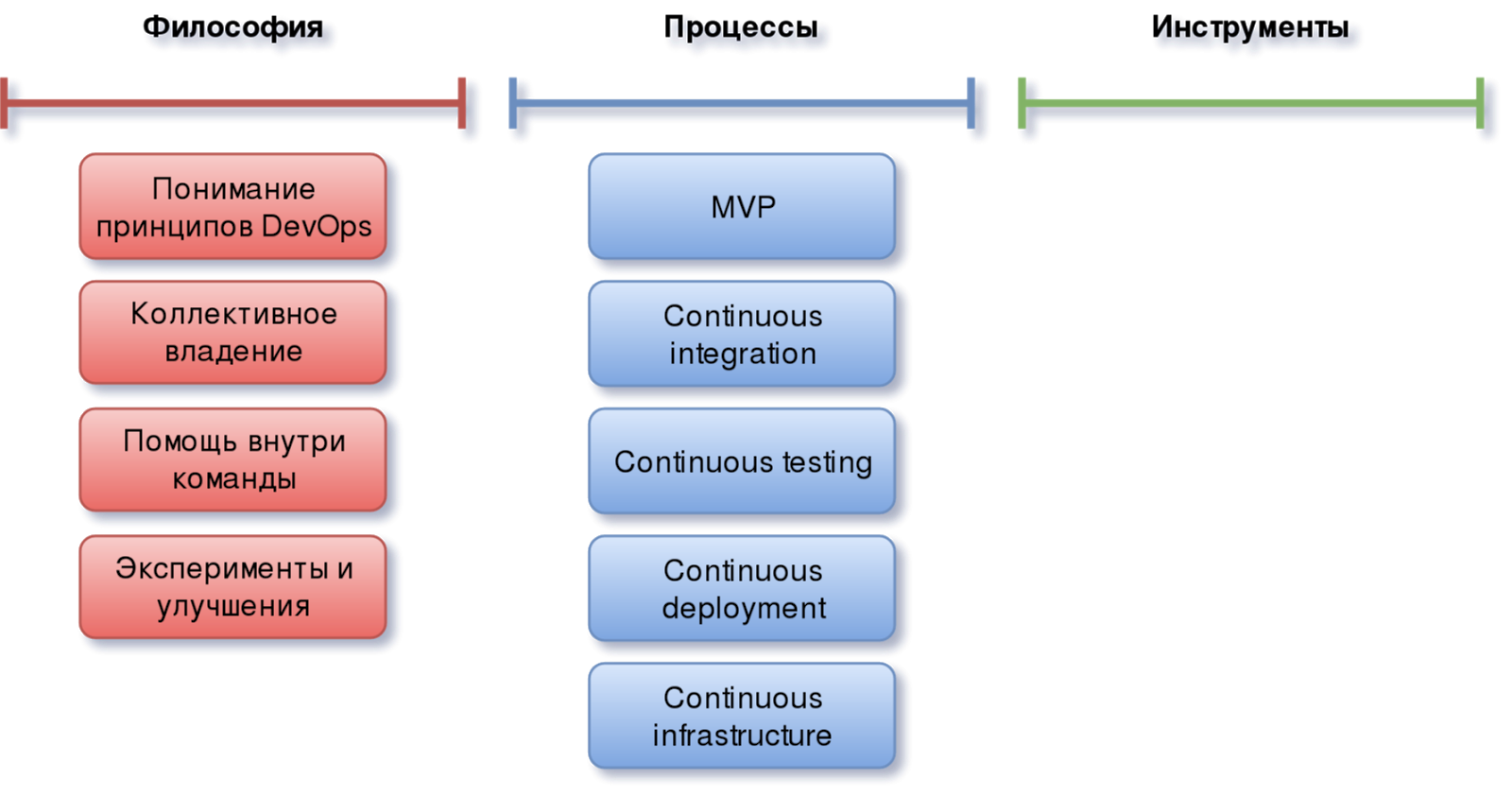
Теперь давайте поговорим о том, где будет работать всё то, что мы закодим и задеплоим — об инфраструктуре. Так же как и для остальных процессов в общей методологии DevOps, для инфраструктуры тоже есть свой Continuous — Continuous Infrastructure.
Одним из ключевых составляющих которой является Infrastructure as Code. Т.е. это описание инфраструктуры, необходимой для работы проекта в виде кода. Который, как и код самого приложения хранится в репозитории и версионируется. Для него точно также должны быть определены механизмы ветвления, версионирования, сборки и тестирования (например, с помощью Molecule, если речь идёт об Ansible). Т.е. процесс по своему виду очень напоминает Continuous Integration.
Смысл методологии в том, чтобы иметь полное описание своей инфраструктуры (это в идеале, конечно, на практике этого добиться весьма непросто), которое можно применять не только для того, чтобы видеть изменения, но и создавать среды для тестирования, максимально приближенные к боевой.
IaC может быть построена вокруг очень разных технологий, от обычных bash-скриптов, описывающих процесс настройки, до систем управления конфигурациями и описания инфраструктуры, такими как Ansible, Terraform и прочими.
Если вы сомневаетесь относительно необходимости наличия данного процесса в общем стеке, будучи уверенным в том, что “да я и вручную очень быстро web-сервера настраиваю”, то помните про Disaster Recovery и попробуйте ответить себе на два вопроса:
- Сколько времени займёт восстановление инфраструктуры после её полного краха? Например, метеорит упал на ДЦ и срочно потребовалось переподнять всё в другом месте.
- Как этот простой повлияет на бизнес?
Continuous Monitoring
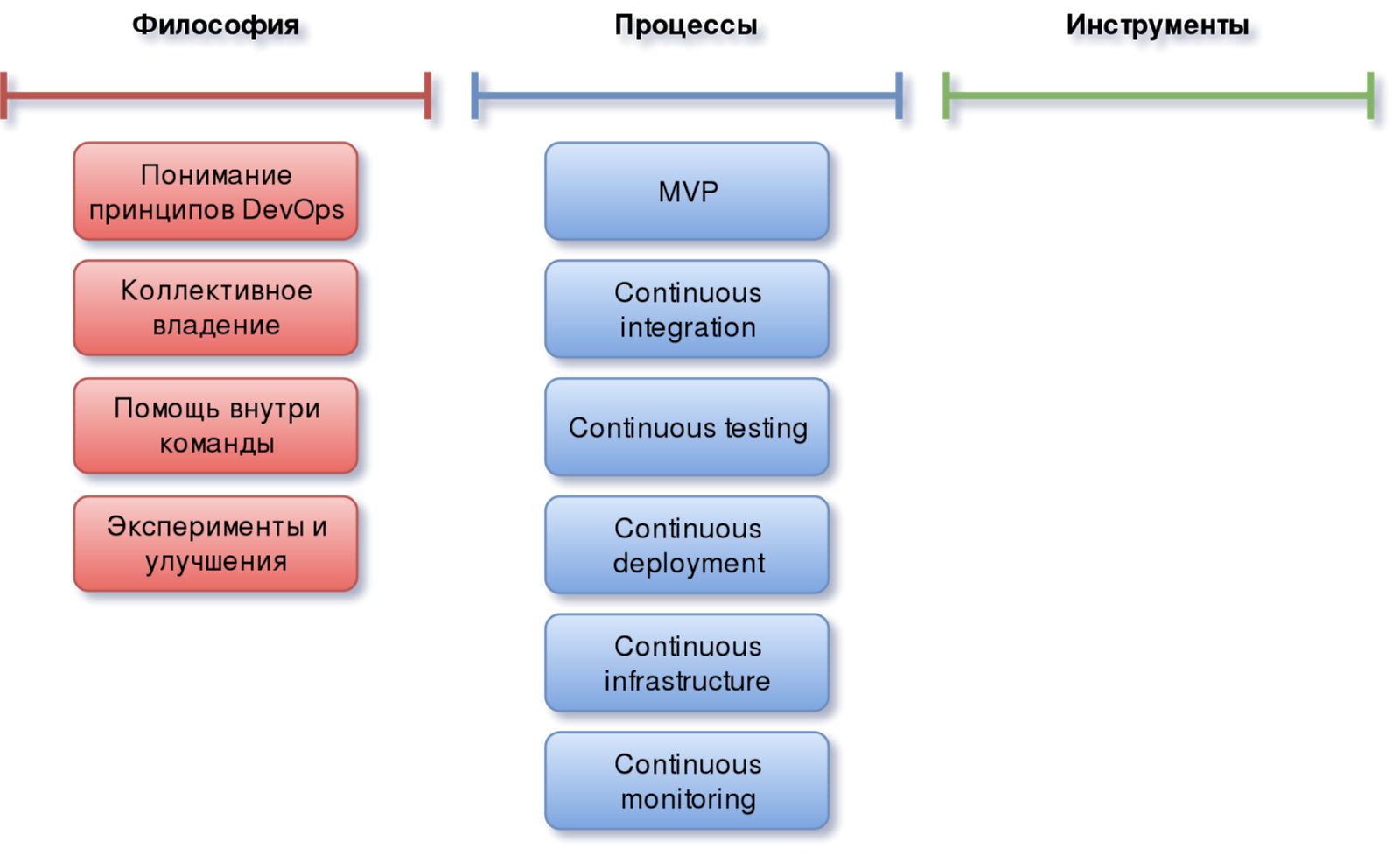
И завершающим процессом во всей этой цепочке является Continuous Monitoring. Основным назначением которого является поддержание в актуальном состоянии конфигурации мониторинга различных элементов проекта, от инфраструктуры и до приложений, входящих в его состав. Причём отслеживание и мониторинг всех необходимых метрик должен производиться автоматически. Для этого придётся постараться всем, в том числе и программистам, которые часто просто не понимают необходимость реализации в коде механизмов, позволяющих получить метрики конкретного сервиса и им достаточно простого принципа “процесс запущен, значит всё хорошо”.
Оптимизация процессов
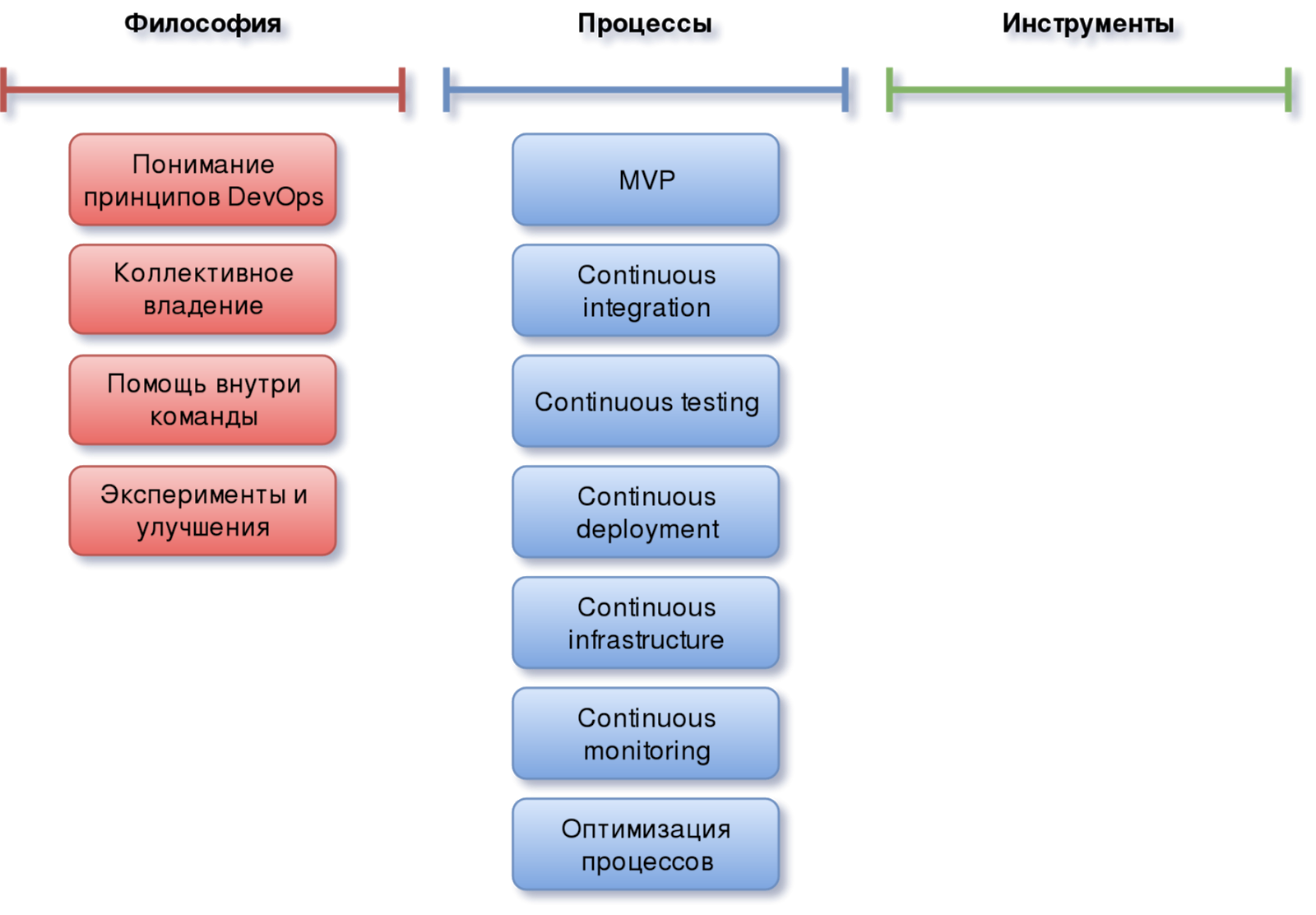
В DevOps, так же как и в большинстве сфер деятельности, мало создать и внедрить процессы, их надо поддерживать, постоянно улучшать и оптимизировать. Следить, чтобы они отвечали всем текущим требованиям бизнеса и были максимально простыми, понятными и удобными для участников проекта.
Когда возникает какая-то идея по улучшению того или иного процесса — часто приходится иметь дело с дилеммой: а как распространить эти улучшения на остальные аналогичные элементы системы, стоит ли это вообще делать и если да, то когда следует остановиться?
С какими проблемами можно столкнуться:
- Если не делать: очень быстро мы получим набор схожих по функционалу и назначению процессов, но разных по реализации. Понятно, что это будет приводить к сложностям в их обслуживании.
- Если делать: будем вынуждены тратить на распространение изменений почти всё рабочее время. Причём ситуация будет усугубляться с ростом проекта.
И это действительно очень хороший философский вопрос, на который не существует однозначного ответа. Но, как правило, истина где-то посередине или почти посередине.
Инструменты
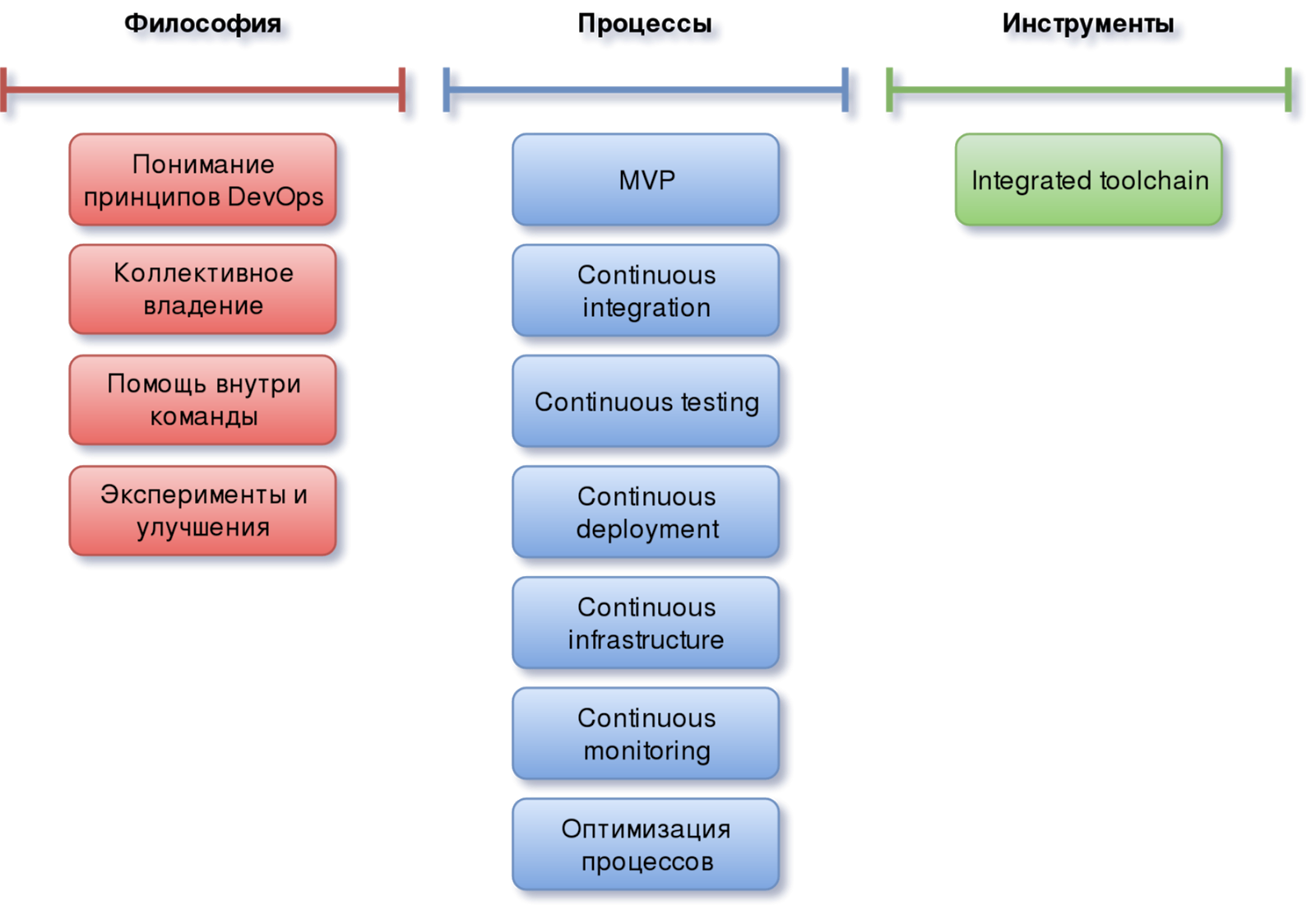
Поскольку доступный сейчас инструментарий для организации CI/CD и реализации DevOps очень обширен, схож между собой по функционалу и может отличаться наличием лишь некоторых фич и удобством их реализации, выбор конкретных решений основан, скорее, на степени знакомства команды с тем или иным ПО.
Используемый стек может быть весьма различным. Главное — это гармоничная интеграция каждого инструмента в общую цепочку, обеспечивающую непрерывность процессов разработки и деплоя продукта.
DevOps-минимум
Понятно, что реализация всех описанных процессов в рамках даже небольшого проекта может быть делом весьма продолжительным и сложным. Поэтому многие команды задаются логичным вопросом: “С чего начать DevOps? Какой минимум необходим? И какие элементы нужны в первую очередь?”.
Реализовав множество проектов различной сложности по внедрению DevOps, на основе полученного опыта наша команда может ответить на этот вопрос так:
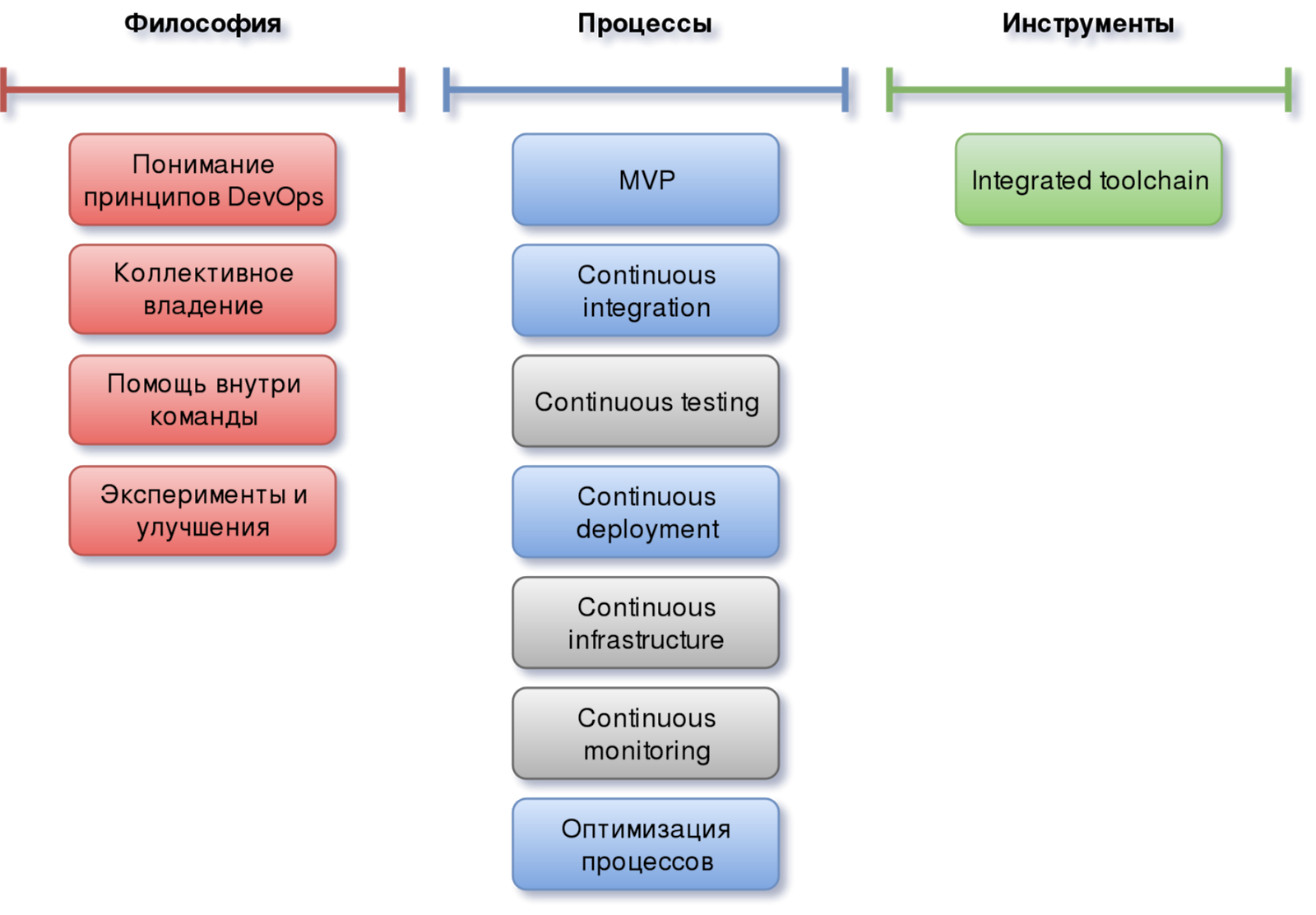
Такой выбор объясняется следующим образом. Как описывалось ранее, для того, чтобы появившийся DevOps ни только не умер, но и мог развиваться, ему нужна очень прочная и хорошо усвоенная философская составляющая. Т.е. потребуется очень чёткое понимание смысла и назначения внедряемой методологии. Поэтому все пункты из блока “философия” в полном составе попадают в наш DevOps-минимум.
Что касается процессов, то тут уже не всё из обозначенного выше имеет критическое значение на начальных этапах появления DevOps. Здесь нам никак не обойтись без двух “continuous”: Integration и Deployment. В первую очередь потому, что без этого DevOps так останется просто теорией и не будет иметь никакого практического смысла.
При этом благодаря наличию у остальных элементов этого блока определённой схожести с CI и CD, их отложенная реализация уже с учётом полученного на предыдущих этапах опыта и понимания нюансов, может быть проведена более оптимально.
Учитывая специфику статьи, инструменты описываются в ней в виде некоторой абстракции во многом потому, что выбранный набор может быть любым и с развитием процессов может даже меняться. Важно, чтобы он отвечал двум требованиям:
- Команда должна хорошо понимать и владеть инструментарием
- Каждый из инструментов должен быть не только хорошо интегрирован с другим, но чётко вписываться в имеющиеся на текущий момент процессы.
Заключение
В конце хотелось бы ещё раз подчеркнуть основные мысли, которые я попытался донести в данной статье. Первое с чего необходимо начать внедрение DevOps — это понимание и принятие принципов и философии данной методологии всеми участниками команды. Пока это не так, не стоит набрасываться на практическую реализацию, как бы ни был велик соблазн или поджимали сроки. В конечном итоге такой подход сделает только хуже. Следует помнить об MVP не только в отношении продукта, но и процессов. Не все из них необходимы сразу. А при правильном подходе их внедрение на более поздних этапах может быть даже более эффективным. Главное — это держать руку на пульсе развития DevOps в своём проекте и контролировать процессы.
Также читайте другие статьи в нашем блоге:
- Canary Deployment в Kubernetes #1: Gitlab CI
- Аутентификация и чтение секретов в HashiCorp's Vault через GitLab CI
- Fluentd: почему важно настроить выходной буфер
- С чем нам пришлось столкнуться при использовании утилиты Csync2
- Создание дополнительного kube-scheduler’a с кастомным набором правил планирования
essome
Статья хорошая, но у всех статей про dev ops есть один недостаток, ваша — не исключение.
Все говорят про философию, про инструменты и прочее, но никто не показывает примеров «Так с чего же начать»?
Философия и пуши в ветки — это понятно всем разработчикам.
Но вот я создаю пет проект и хочу деплоить его по вашей философии, что мне нужно установить и настроить для автодеплоя? Автотестов? Какие инструменты изучать?
Например я хочу что-бы при пуше в ветку prod — запускались тесты, после этого сервер автоматически делал pull и перезапускал билд, как мне этого добиться если я не знаю ничего про администрирование?
Или еще сложнее — при создании новой ветки — создавался поддомен на тестовом сервере с названием этой ветки автоматически.
Думаю люди которые знают все эти инструменты и как с ними работать — не нуждаются в подобных статьях, а людям вроде меня ваши статьи ничего кроме «философии» не объясняют.
borisershov Автор
Здравствуйте!
Целью данной статьи было показать, что DevOps — это, прежде всего, про философию и понимание сути и состава этой методологии, а не про инструменты. Вначале я как раз и говорю о том, что многие (и зачастую это далеко не новички в данной сфере) воспринимают DevOps именно как использование специального ПО для построения CI/CD. Затем я поясняю, почему такой подход не правильный и к чему приводит практическое применение DevOps в такой трактовке. А так как мы в своей практике встречаемся с последствиями этих проблем довольно часто, то и возникла мысль написать статью, которая показывала бы первичность теоретической составляющей, что позволило бы заложить прочную базу для дальнейшего развития DevOps в проекте в правильном направлении.
Практической же стороне вопроса внимания удаляется лишь в виде отсылки к абстрактному набору инструментов, который может быть выбран любым и будет сильно зависеть от особенностей конкретного проекта. Я подумаю над возможностью написания второй части статьи, которая бы освещала эти моменты. Но и та статья не будет описывать какой-то конкретный стек ПО (мануалов и холиваров на эту тему и и-нете достаточно) и будет касаться лишь вопросов выбора того или иного инструментария в зависимости от различных факторов.
essome
Много статей было про философию)
но что с этой философией дальше делать — неясно, пишите больше, надеюсь будет еще не одна статья, а хотя-бы штук 10
Например следующая о выборе инструмента, а после нее уже примеры работы со стеком каких-то инструментов на ваш выбор.
Это конечно же только мои желания, но думаю многим зашло бы, спасибо.