
В стародавние времена я работал айтишником в одной фирме и в какое-то время возникла задача поиска по локальному хранилищу документов. Искать желательно было не только по названию файла, но и по содержанию. Тогда ещё были популярны локальные поисковые механизмы типа архивариуса и даже от Яндекса был отдельностоящий поисковик. Но это были не корпоративные решения их нельзя было развернуть централизовано для совместного использования. Яндекс, честности ради начал делать что-то похожее, но потом забросил.
Но у всех этих решений не было того, что мне нужно:
И я решил сделать своё.
Раскрою по пунктам, что я имею в виде для избегания разности толкований и недопониманий.
Централизованная установка – клиент-серверное исполнение. У всех перечисленных выше решений одна фундаментальная проблема – каждый пользователь делает свой локальный поисковый индекс, что в случае больших объёмов хранилищ затягивает индексирование, растёт профиль пользователя на машине и вообще неудобно в случае прихода нового сотрудника или переезда на новую машину.
Поисковая выдача в учётом прав – тут всё просто – выдача должна соответствовать правам сотрудника на файловый ресурс. А то получится, что даже если у сотрудника нет прав на ресурс, но он может всё почитать из поискового кеша. Неудобненько получится, согласитесь? Поиск по содержимому документа – поиск по тексту документа, тут всё очевидно, как мне кажется и разночтений быть не может.
Морфология – ещё проще. Указали в запросе «нож» и получили, как «нож», так и «ножи», «ножевой» и «ножик». Желательно, чтобы это работало для русского и английского языков.
С постановкой задачи определились, можно переходить к реализации.
В качестве именно поисковой машины я выбрал систему Sphinx, а язык разработки интерфейса C# и .net и в итоге проект получил название Vidocq (Видок) по имени французского сыщика. Ну типа найдёт всё и вот это вот всё.
Архитектурно приложение выглядит следующим образом:
Поисковый робот рекурсивно обходит файловый ресурс и обрабатывает файлы по заданному списку расширений. Обработка заключается в получении содержимого файла, сжатию текста – из текста убираются кавычки, запятые, лишние пробелы и прочее, дальше содержимое помещается в базу (MS SQL), делается отметка о дате помещения и робот идёт дальше.
Индексатор Сфинса работает уже непосредственно с полученной базой, формируя свой индекс и возвращая в качестве ответа указатель на найденный файл и сниппет найденного фрагмента текста.
На C# была разработана форма, которая общалась со Сфинксом через MySQL-коннектор. Сфинкс отдаёт массив файлов в соответствии с запросом, дальше массив фильтруется на право доступа того пользователя, который осуществляет поиск, выдача форматируется и показывается пользователю.
О файле нам понадобится хранить следующую информацию:
Это всё делается одной таблицей и в неё всё будет складывать поисковый робот. Дата добавления необходима для того, чтобы когда робот в следующий обход сравнивал дату изменения файла с датой помещения в базу и если даты различаются, то обновить информацию о файле.
Дальше настраивать саму поисковую машину. Я не буду описывать весь конфиг, он будет доступен в архиве проекта, но освещу лишь основные моменты.
Основной запрос, формирующий базу
source documents: documents_base
Настройка морфологии через лемматайзер.
После этого на базу можно натравливать индексатор и проверять работу.
Тут путь к индексатору дальше имя индекса в который поместить обработанное, путь к конфигу и Флаг –rotate означает, что индексация будет выполняться наживую, т.е. при работающей службе поиска. После завершения индексации индекс будет заменен на обновлённый.
Проверяем работу в консоли. В качестве интерфейса можно использовать клиента MySQL, взятого, например, из комплекта веб-сервера.
после этого запрос select id from documets; должен вернуть список проиндексированных документов, если, конечно, вы перед этим запустили саму службу Sphinx и всё сделали правильно.
Хорошо, консоль это прекрасно, но мы же не будем заставлять пользователей вбивать руками команды, верно?
Я набросал вот такую вот форму
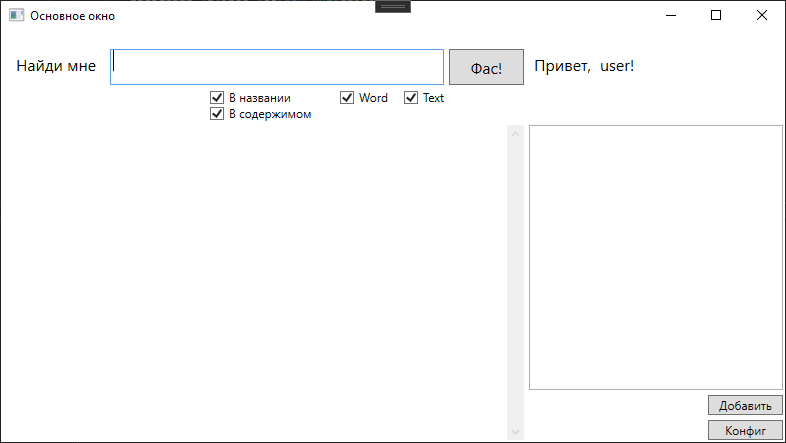
И вот с результатами поиска

При щелчке по конкретному результату открывается документ.
Как реализовано.
Да, тут быдлокод, но это MVP.
Собственно, тут формируется запрос к Сфинксу в зависимости от выставленных чексбоксов. Чекбоксы указывают на тип файлов в которых искать и область поиска.
Дальше запрос уходит в Сфинкса, а потом разбирается полученный результат.
На этом же этапе формируется выдача. Каждый элемент выдачи – richtextbox с событием открытия документа на клик. Элементы помещаются на StackPanel и перед этим идёт проверка доступности файла пользователю. Таким образом, в выдачу не попадёт файл, недоступный пользователю.
Преимущества такого решения:
Разумеется, для полноценной работы такого решения в компании должно быть соответствующим образом организован файловый архив. В идеале должны быть настроены перемещаемые профиля пользователей и прочее. И да, я знаю про наличие SharePoint, Windows Search и скорее всего ещё нескольких решений. Дальше можно бесконечно долго дискутировать о выборе платформы разработки, поисковой машине Sphinx, Manticore или Elastic и так далее. Но мне было интересно решить задачу тем инструментарием в котором я немного разбираюсь. Сейчас оно работает в режиме MVP, но я развиваю его.
Но в любом случае я готов выслушать ваши предложения о том, какие моменты можно или улучшить или переделать на корню.
Но у всех этих решений не было того, что мне нужно:
- Централизованная установка
- Поисковая выдача с учётом прав доступа
- Поиск по содержимому документа
- Морфология
И я решил сделать своё.
Раскрою по пунктам, что я имею в виде для избегания разности толкований и недопониманий.
Централизованная установка – клиент-серверное исполнение. У всех перечисленных выше решений одна фундаментальная проблема – каждый пользователь делает свой локальный поисковый индекс, что в случае больших объёмов хранилищ затягивает индексирование, растёт профиль пользователя на машине и вообще неудобно в случае прихода нового сотрудника или переезда на новую машину.
Поисковая выдача в учётом прав – тут всё просто – выдача должна соответствовать правам сотрудника на файловый ресурс. А то получится, что даже если у сотрудника нет прав на ресурс, но он может всё почитать из поискового кеша. Неудобненько получится, согласитесь? Поиск по содержимому документа – поиск по тексту документа, тут всё очевидно, как мне кажется и разночтений быть не может.
Морфология – ещё проще. Указали в запросе «нож» и получили, как «нож», так и «ножи», «ножевой» и «ножик». Желательно, чтобы это работало для русского и английского языков.
С постановкой задачи определились, можно переходить к реализации.
В качестве именно поисковой машины я выбрал систему Sphinx, а язык разработки интерфейса C# и .net и в итоге проект получил название Vidocq (Видок) по имени французского сыщика. Ну типа найдёт всё и вот это вот всё.
Архитектурно приложение выглядит следующим образом:
Поисковый робот рекурсивно обходит файловый ресурс и обрабатывает файлы по заданному списку расширений. Обработка заключается в получении содержимого файла, сжатию текста – из текста убираются кавычки, запятые, лишние пробелы и прочее, дальше содержимое помещается в базу (MS SQL), делается отметка о дате помещения и робот идёт дальше.
Индексатор Сфинса работает уже непосредственно с полученной базой, формируя свой индекс и возвращая в качестве ответа указатель на найденный файл и сниппет найденного фрагмента текста.
На C# была разработана форма, которая общалась со Сфинксом через MySQL-коннектор. Сфинкс отдаёт массив файлов в соответствии с запросом, дальше массив фильтруется на право доступа того пользователя, который осуществляет поиск, выдача форматируется и показывается пользователю.
О файле нам понадобится хранить следующую информацию:
- Id файла
- Имя файла
- Путь к файлу
- Содержимое файла
- Расширение
- Дата добавления в базу
Это всё делается одной таблицей и в неё всё будет складывать поисковый робот. Дата добавления необходима для того, чтобы когда робот в следующий обход сравнивал дату изменения файла с датой помещения в базу и если даты различаются, то обновить информацию о файле.
Дальше настраивать саму поисковую машину. Я не буду описывать весь конфиг, он будет доступен в архиве проекта, но освещу лишь основные моменты.
Основной запрос, формирующий базу
source documents: documents_base
{
sql_query = select DocumentId as 'Id', DocumentPath as 'Path', DocumentTitle as 'Title', DocumentExtention as 'Extension', DocumentContent as 'Content' from VidocqDocs
}Настройка морфологии через лемматайзер.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}После этого на базу можно натравливать индексатор и проверять работу.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateТут путь к индексатору дальше имя индекса в который поместить обработанное, путь к конфигу и Флаг –rotate означает, что индексация будет выполняться наживую, т.е. при работающей службе поиска. После завершения индексации индекс будет заменен на обновлённый.
Проверяем работу в консоли. В качестве интерфейса можно использовать клиента MySQL, взятого, например, из комплекта веб-сервера.
mysql -h 127.0.0.1 -P 9306после этого запрос select id from documets; должен вернуть список проиндексированных документов, если, конечно, вы перед этим запустили саму службу Sphinx и всё сделали правильно.
Хорошо, консоль это прекрасно, но мы же не будем заставлять пользователей вбивать руками команды, верно?
Я набросал вот такую вот форму
И вот с результатами поиска
При щелчке по конкретному результату открывается документ.
Как реализовано.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Да, тут быдлокод, но это MVP.
Собственно, тут формируется запрос к Сфинксу в зависимости от выставленных чексбоксов. Чекбоксы указывают на тип файлов в которых искать и область поиска.
Дальше запрос уходит в Сфинкса, а потом разбирается полученный результат.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}На этом же этапе формируется выдача. Каждый элемент выдачи – richtextbox с событием открытия документа на клик. Элементы помещаются на StackPanel и перед этим идёт проверка доступности файла пользователю. Таким образом, в выдачу не попадёт файл, недоступный пользователю.
Преимущества такого решения:
- Индексация происходит централизованно
- Чёткая выдача с учётом прав доступа
- Настраиваемый поиск по типам документов
Разумеется, для полноценной работы такого решения в компании должно быть соответствующим образом организован файловый архив. В идеале должны быть настроены перемещаемые профиля пользователей и прочее. И да, я знаю про наличие SharePoint, Windows Search и скорее всего ещё нескольких решений. Дальше можно бесконечно долго дискутировать о выборе платформы разработки, поисковой машине Sphinx, Manticore или Elastic и так далее. Но мне было интересно решить задачу тем инструментарием в котором я немного разбираюсь. Сейчас оно работает в режиме MVP, но я развиваю его.
Но в любом случае я готов выслушать ваши предложения о том, какие моменты можно или улучшить или переделать на корню.





{kind=link}
devopg
Если вы разбираетесь, видел такой интересный вопрос в одной телеграмм группе на который никто не смог ответить.
Есть видео (название, описание, тэги) они находятся в эластике.
И есть супер частая, супер обновляемая статистика которая находится в mongodb.
И допустим по запросу «коты» с лимитом 10 (для пагинации), эластик возвращает и нет проблем. всего подходящий записей по слову «коты» 100млн.
Но тут появляется проблема отсортировать эти записи по статистике. Как это сделать?
1) не будешь же ты делать выбрать 100 млн из эластика, а потом писать запрос для mongo selec from x where ID in(100млн записей) order by field.
2) не будешь же ты в эластик пихать это поле статистики, т.к. она супер часто обновляется, эластик утонет в абсолютно бесполезной переиндексации документов.
lair
Насколько я знаю, в таких случаях статистику в эластике (точнее, в query side, не важно, эластик ли это) начинают обновлять не на каждый чих, а с запаздыванием (eventual consistency). Пользователю почти всегда все равно, смотрит он на текущие данные по лайкам видео с котиками, или пятисекундной давности (особенно учитывая, что за время между поиском и переходом на само видео статистика все равно поменяется).