
Введение
Некоторое время назад передо мной поставили задачу разработать отказоустойчивый кластер для PostgreSQL, работающий в нескольких дата-центрах, объединенных оптоволокном в рамках одного города, и способный выдержать отказ (например, обесточивание) одного дата-центра. В качестве софта, который отвечает за отказоустойчивость, выбрал Pacemaker, потому что это официальное решение от RedHat для создания отказоустойчивых кластеров. Оно хорошо тем, что RedHat обеспечивает его поддержку, и тем, что это решение универсальное (модульное). С его помощью можно будет обеспечить отказоустойчивость не только PostgreSQL, но и других сервисов, либо используя стандартные модули, либо создавая их под конкретные нужды.
К этому решению возник резонный вопрос: насколько отказоустойчивым будет отказоустойчивый кластер? Чтобы это исследовать, я разработал тестовый стенд, который имитирует различные отказы на узлах кластера, ожидает восстановления работоспособности, восстанавливает отказавший узел и продолжает тестирование в цикле. Изначально этот проект назывался hapgsql, но со временем мне наскучило название, в котором только одна гласная. Поэтому отказоустойчивые базы данных (и float IP, на них указывающие) я стал именовать krogan (персонаж из компьютерной игры, у которого все важные органы дублированы), а узлы, кластеры и сам проект — tuchanka (планета, где живут кроганы).
Сейчас руководство разрешило открыть проект для open source-сообщества под лицензией MIT. README в скором времени будет переведен на английский язык (потому что ожидается, что основными потребителями будут разработчики Pacemaker и PostgreSQL), а старый русский вариант README я решил оформить (частично) в виде этой статьи.

Кластеры разворачиваются на виртуалках VirtualBox. Всего будет развернуто 12 виртуалок (суммарно 36GiB), которые образуют 4 отказоустойчивых кластера (разные варианты). Первые два кластера состоят из двух серверов PostgreSQL, которые размещены в разных дата-центрах, и общего сервера witness c quorum device (размещенный на дешёвой виртуалке в третьем дата-центре), который разрешает неопределенность 50%/50%, отдавая свой голос одной из сторон. Третий кластер в трех дата-центрах: один мастер, два раба, без quorum device. Четвертый кластер состоит из четырех серверов PostgreSQL, по два на дата-центр: один мастер, остальные реплики, и тоже использует witness c quorum device. Четвертый выдерживает отказ двух серверов или одного дата-центра. Это решение может быть, при необходимости, масштабировано на большее количество реплик.
Сервис точного времени ntpd тоже перенастроен для отказоустойчивости, но там используются метод самого ntpd (orphan mode). Общий сервер witness выполняет роль центрального NTP-сервера, раздавая своё время всем кластерам, тем самым синхронизируя все серверы между собой. Если witness выйдет из строя или окажется изолированным, тогда своё время начнет раздавать один из серверов кластера (внутри кластера). Вспомогательный кэширующий HTTP proxy тоже поднят на witness, с его помощью остальные виртуалки имеют доступ к Yum-репозиториям. В реальности такие сервисы, как точное время и прокси, наверняка будут размещены на выделенных серверах, а в стенде они размещены на witness только для экономии количества виртуалок и места.
Версии
v0. Работает с CentOS 7 и PostgreSQL 11 на VirtualBox 6.1.
Структура кластеров
Все кластеры предназначены для размещения в нескольких дата-центрах, объединены в одну плоскую сеть и должны выдерживать отказ или сетевую изоляцию одного дата-центра. Поэтому невозможно использовать для защиты от split-brain стандартную технологию Pacemaker, которая называется STONITH (Shoot The Other Node In The Head) или fencing. Её суть: если узлы в кластере начинают подозревать, что с каким-то узлом происходит неладное, он не отвечает или некорректно себя ведёт, то они принудительно его отключают через «внешние» устройства, например, управляющую карточку IPMI или UPS. Но такое сработает только в случаях, когда при единичном отказе сервера IPMI или UPS продолжают работать. Здесь же планируется защита от гораздо более катастрофичного отказа, когда отказывает (например обесточивается) весь дата-центр. А при таком отказе все stonith-устройства (IPMI, UPS и т.д.) тоже не будут работать.
Вместо этого в основе системы лежит идея кворума. Все узлы имеют голос, и работать могут только те, которые видят больше половины всех узлов. Это количество «половина+1» называется кворум. Если кворум не набирается, то узел решает, что он находится в сетевой изоляции и должен отключить свои ресурсы, т.е. это такая защита от split-brain. Если софт, который отвечает за такое поведение, не работает, то должен будет сработать watchdog, например, на базе IPMI.
Если количество узлов четное (кластер в двух дата-центрах), то может возникнуть так называемая неопределенность 50%/50% (фифти-фифти), когда сетевая изоляция делит кластер ровно пополам. Поэтому для четного количества узлов добавляется quorum device — нетребовательный демон, который может быть запущен на самой дешевой виртуалке в третьем дата-центре. Он дает свой голос одному из сегментов (который видит), и тем самым разрешает неопределенность 50%/50%. Сервер, на котором будет запущен quorum device, я назвал witness (терминология из repmgr, мне понравилась).
Ресурсы могут переезжать с места на место, например, с неисправных серверов на исправные, или по команде сисадминов. Чтобы клиенты знали, где находятся нужные им ресурсы (куда подключаться?), используются плавающие IP (float IP). Это IP, которые Pacemaker может перемещать по узлам (всё находится в плоской сети). Каждый из них символизирует ресурс (сервис) и будет находится там, куда надо подключаться, чтобы получить доступ к этому сервису (в нашем случае БД).
Tuchanka1 (схема с уплотнением)
Структура
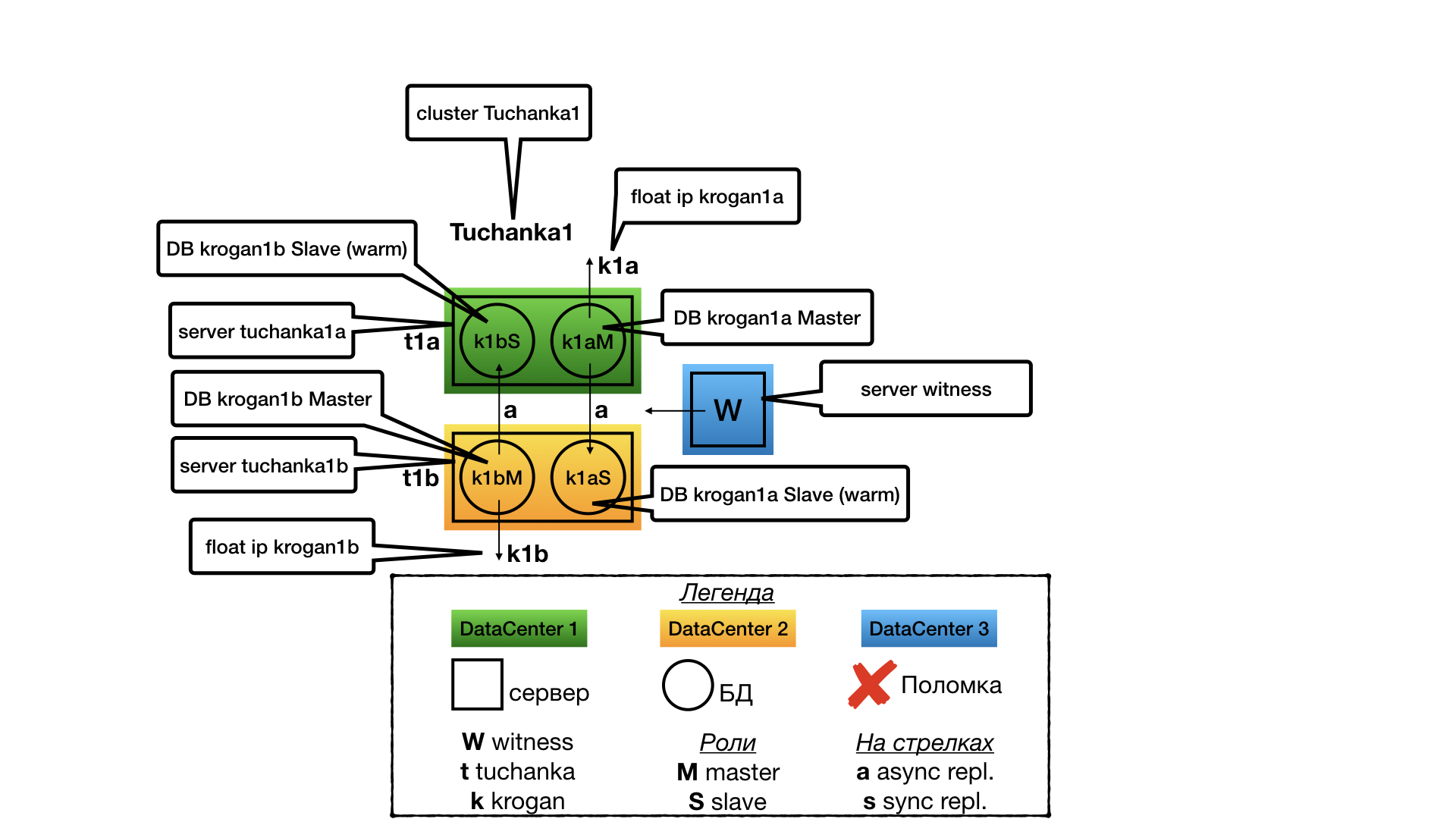
Идея была в том, что у нас есть много мелких баз данных с низкой нагрузкой, для которых невыгодно содержать выделенный slave-сервер в режиме hot standby для read only-транзакций (нет необходимости в такой растрате ресурсов).
В каждом дата-центре по одному серверу. На каждом сервере по два инстанса PostgreSQL (в терминологии PostgreSQL они называются кластерами, но во избежание путаницы я буду их называть инстансами (по аналогии с другими БД), а кластерами буду называть только кластеры Pacemaker). Один инстанс работает в режиме мастера, и только он оказывает услуги (только на него ведет float IP). Второй инстанс работает рабом для второго дата-центра, и будет оказывать услуги только если его мастер выйдет из строя. Поскольку бо?льшую часть времени оказывать услуги (выполнять запросы) будет только один инстанс из двух (мастер), все ресурсы сервера оптимизируются на мастер (выделяется память под кэш shared_buffers и т.д.), но так, чтобы на второй инстанс тоже хватило ресурсов (пусть и для неоптимальной работы через кэш файловой системы) на случай отказа одного из дата-центров. Раб не оказывает услуги (не выполняет read only-запросы) при нормальной работе кластера, чтобы не было войны за ресурсы с мастером на той же самой машине.
В случае с двумя узлами отказоустойчивость возможна только при асинхронной репликации, так как при синхронной отказ раба приведёт к остановке мастера.
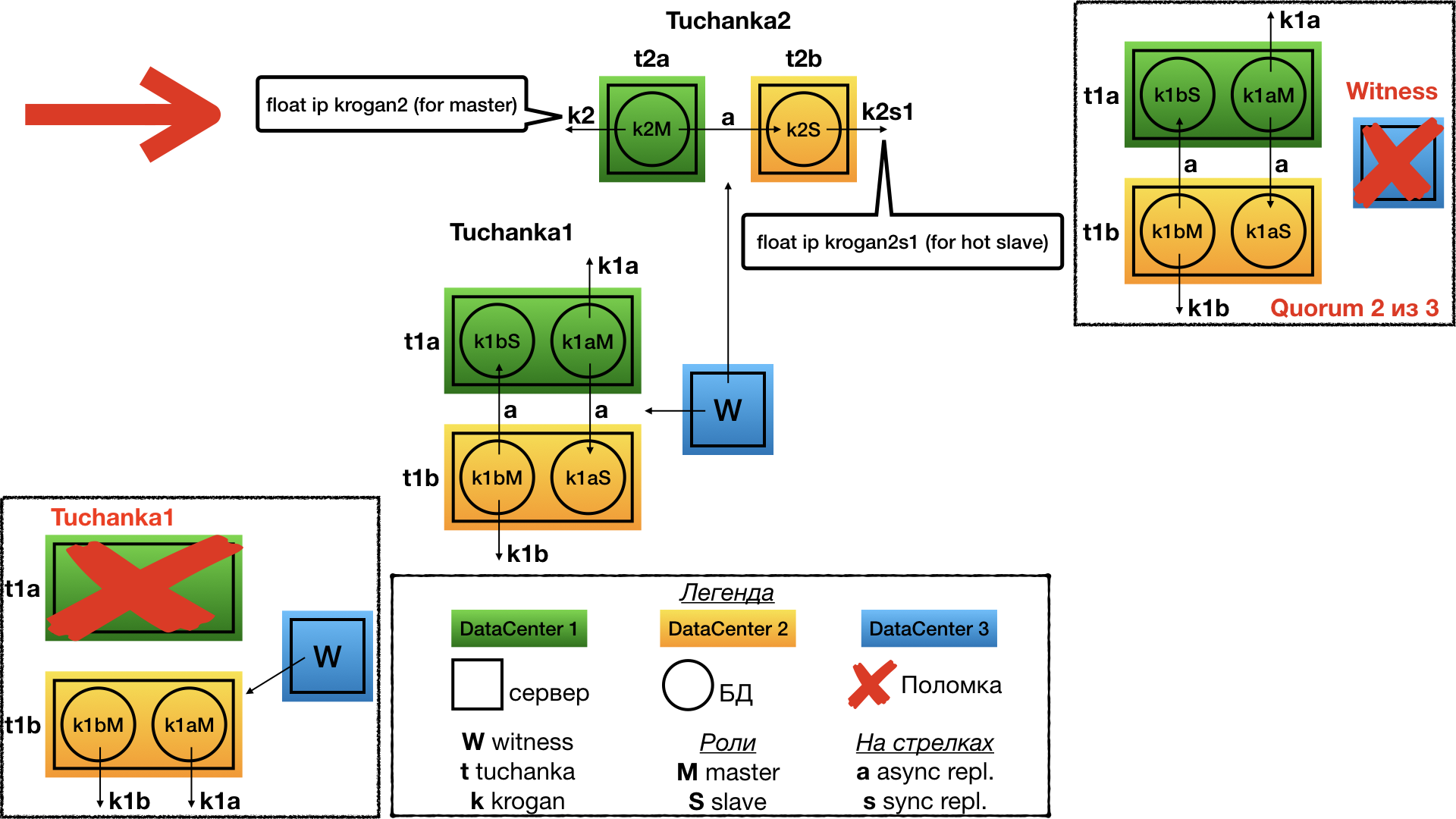
Отказ witness

Отказ witness (quorum device) я рассмотрю только для кластера Tuchanka1, со всеми остальными будет та же история. При отказе witness в структуре кластера ничего не изменится, всё продолжит работать так же, как и работало. Но кворум станет равен 2 из 3, и поэтому любой следующий отказ станет фатальным для кластера. Всё равно придётся срочно чинить.
Отказ Tuchanka1

Отказ одного из дата-центров для Tuchanka1. В этом случае witness отдает свой голос второму узлу на втором дата-центре. Там бывший раб превращается в мастера, в результате на одном сервере работают оба мастера и на них указывают оба их float IP.
Tuchanka2 (классическая)
Структура
Классическая схема из двух узлов. На одном работает мастер, на втором раб. Оба могут выполнять запросы (раб только read only), поэтому на обоих указывают float IP: krogan2 — на мастер, krogan2s1 — на раба. Отказоустойчивость будет и у мастера, и у раба.
В случае с двумя узлами отказоустойчивость возможна только при асинхронной репликации, потому что при синхронной отказ раба приведёт к остановке мастера.
Отказ Tuchanka2
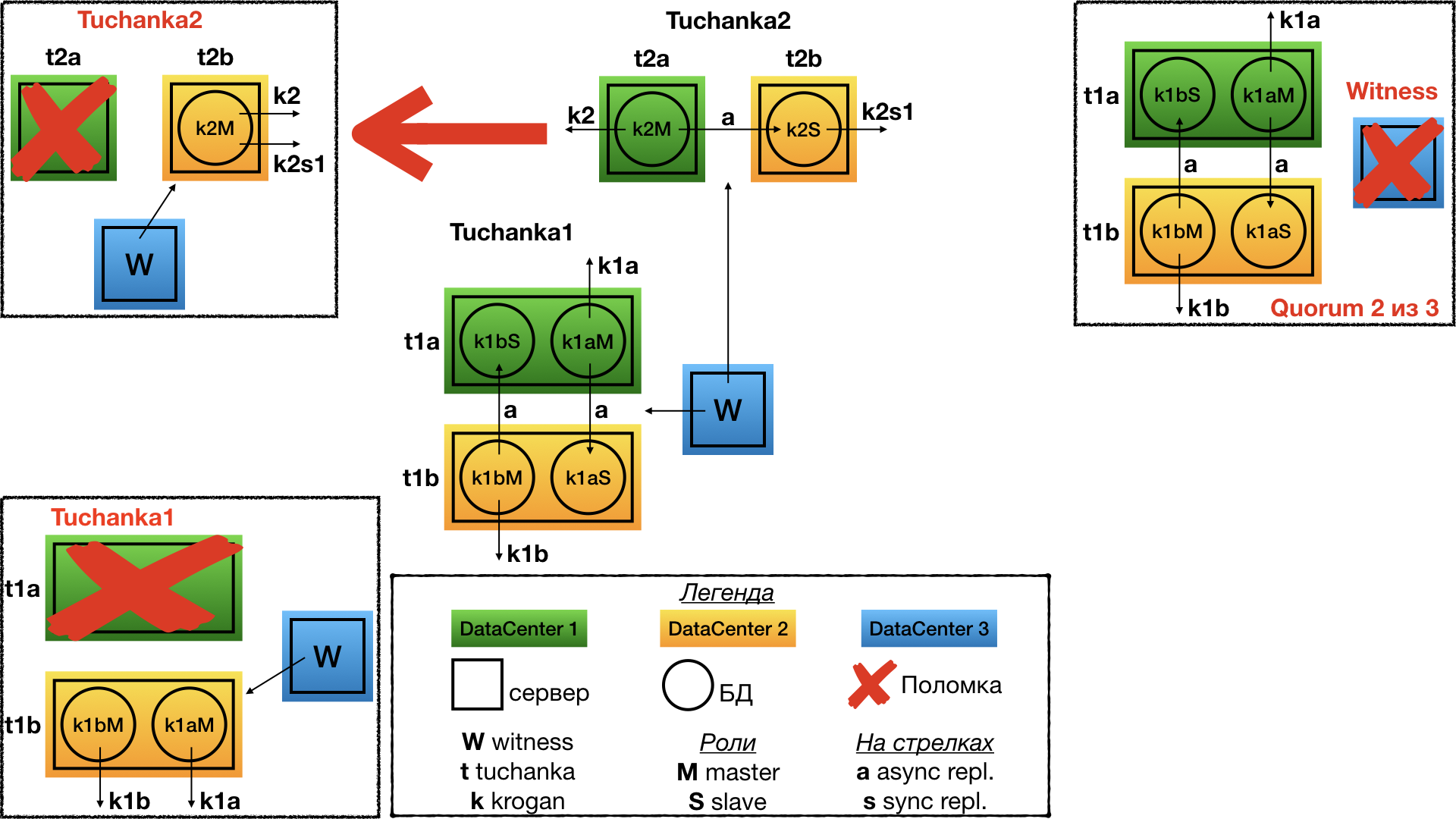
При отказе одного из дата-центров witness голосует за второй. На единственном работающем дата-центре будет поднят мастер, и на него будут указывать оба float IP: мастерский и рабский. Разумеется, инстанс должен быть настроен таким образом, чтобы у него хватило ресурсов (лимитов под connection и т.д.) одновременно принимать все подключения и запросы от мастерского и рабского float IP. То есть при нормальной работе у него должен быть достаточный запас по лимитам.
Tuchanka4 (много рабов)
Структура
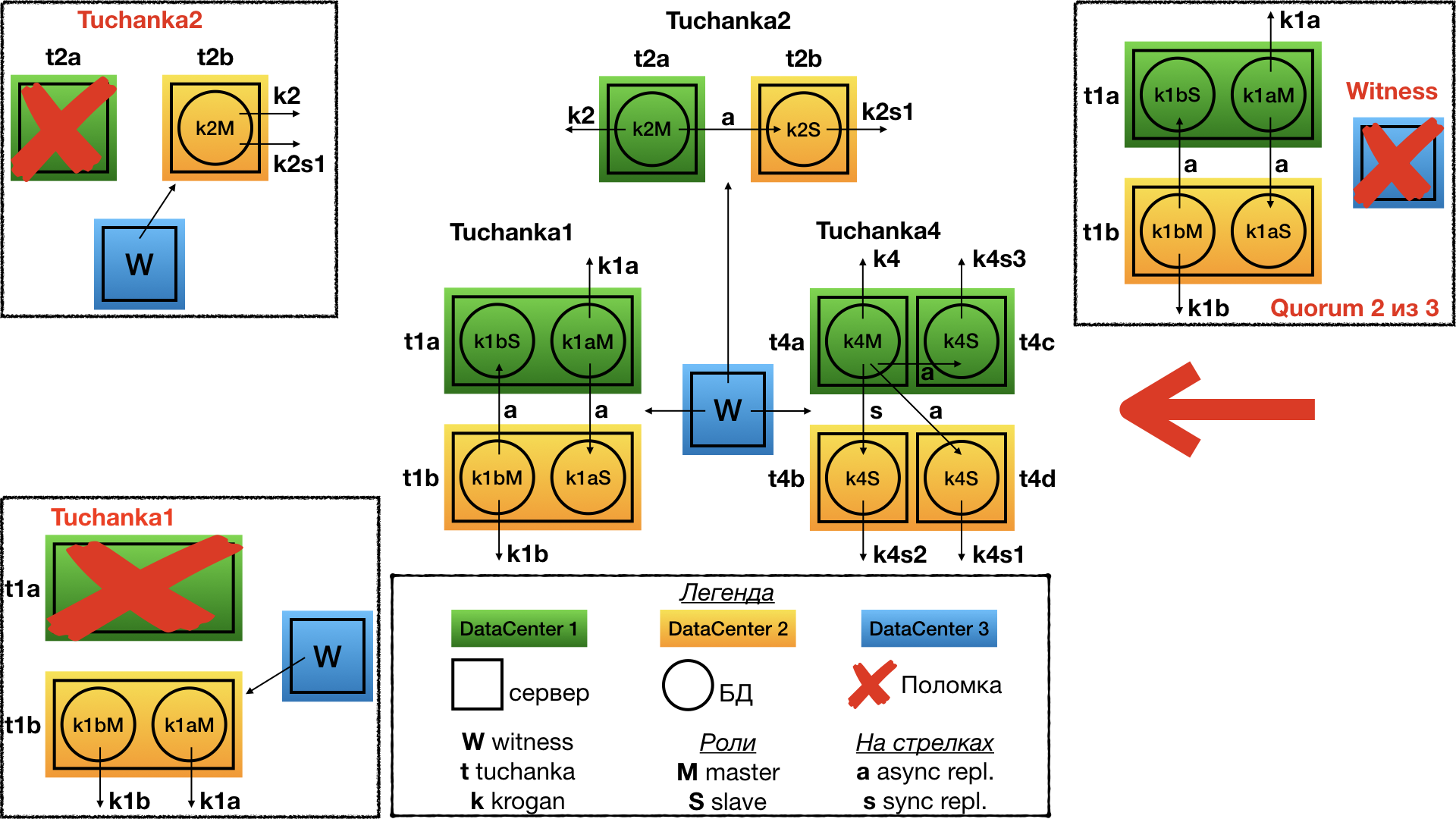
Уже другая крайность. Бывают БД, на которые идет очень много запросов read-only (типичный случай высоконагруженного сайта). Tuchanka4 — это ситуация, когда рабов может быть три или больше для обработки таких запросов, но всё же не слишком много. При очень большом количестве рабов надо будет изобретать иерархическую систему реплицирования. В минимальном случае (на картинке) в каждом из двух дата-центров находится по два сервера, на каждом из которых по инстансу PostgreSQL.
Еще одной особенностью этой схемы является то, что здесь уже можно организовать одну синхронную репликацию. Она настроена так, чтобы реплицировать, по возможности, в другой дата-центр, а не на реплику в том же дата-центре, где и мастер. На мастер и на каждый раб указывает float IP. По хорошему, между рабами надо будет делать балансировку запросов каким-нибудь sql proxy, например, на стороне клиента. Разному типу клиентов может требоваться разный тип sql proxy, и только разработчики клиентов знают, кому какой нужен. Эта функциональность может быть реализована как внешним демоном, так и библиотекой клиента (connection pool), и т.д. Всё это выходит за рамки темы отказоустойчивого кластера БД (отказоустойчивость SQL proxy можно будет реализовать независимо, вместе с отказоустойчивостью клиента).
Отказ Tuchanka4

При отказе одного дата-центра (т.е. двух серверов) witness голосует за второй. В результате во втором дата-центре работают два сервера: на одном работает мастер, и на него указывает мастерский float IP (для приема read-write запросов); а на втором сервере работает раб с синхронной репликацией, и на него указывает один из рабских float IP (для read only-запросов).
Первое, что надо отметить: рабочими рабский float IP будут не все, а только один. И для корректной работы с ним нужно будет, чтобы sql proxy перенаправлял все запросы на единственно оставшийся float IP; а если sql proxy нет, то можно перечислить все float IP рабов через запятую в URL для подключения. В таком случае с libpq подключение будет к первому рабочему IP, так сделано в системе автоматического тестирования. Возможно, в других библиотеках, например, JDBC, так работать не будет и необходим sql proxy. Так сделано потому, что у float IP для рабов стоит запрет одновременно подниматься на одном сервере, чтобы они равномерно распределялись по рабским серверам, если их работает несколько.
Второе: даже в случае отказа дата-центра будет сохраняться синхронная репликация. И даже если произойдёт вторичный отказ, то есть в оставшемся дата-центре выйдет из строя один из двух серверов, кластер хоть и перестанет оказывать услуги, но всё же сохранит информацию обо всех закоммиченных транзакциях, на которые он дал подтверждение о коммите (не будет потери информации при вторичном отказе).
Tuchanka3 (3 дата-центра)
Структура
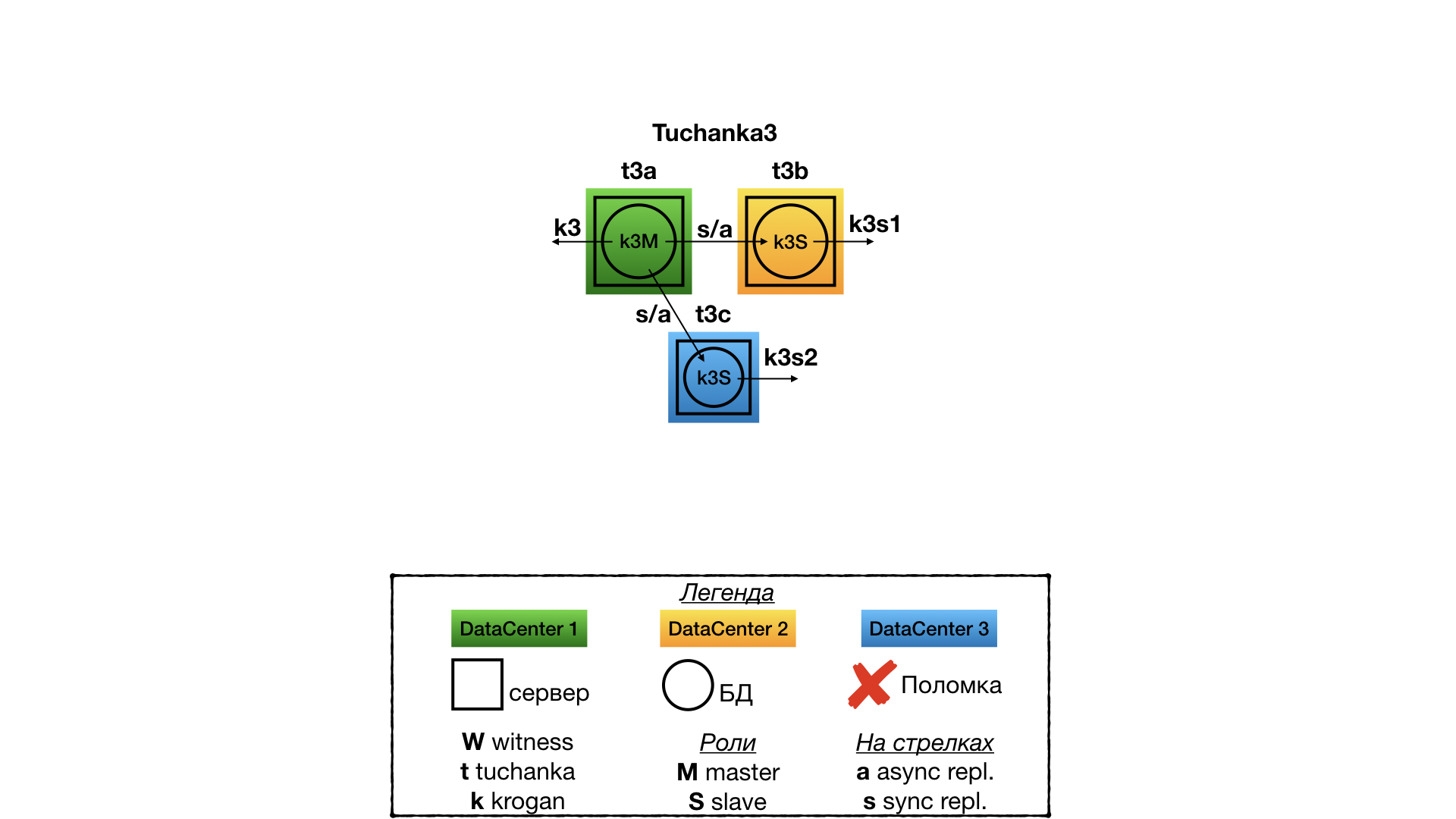
Это кластер для ситуации, когда есть три полноценно работающих дата-центра, в каждом из которых есть полноценно работающий сервер БД. В этом случае quorum device не нужен. В одном дата-центре работает мастер, в двух других — рабы. Репликация синхронная, типа ANY (slave1, slave2), то есть клиенту будет приходить подтверждение коммита, когда любой из рабов первым ответит, что он принял коммит. На ресурсы указывает один float IP для мастера и два для рабов. В отличие от Tuchanka4 все три float IP отказоустойчивы. Для балансировки read-only SQL-запросов можно использовать sql proxy (с отдельной отказоустойчивостью), либо половине клиентов назначить один рабский float IP, а другой половине — второй.
Отказ Tuchanka3
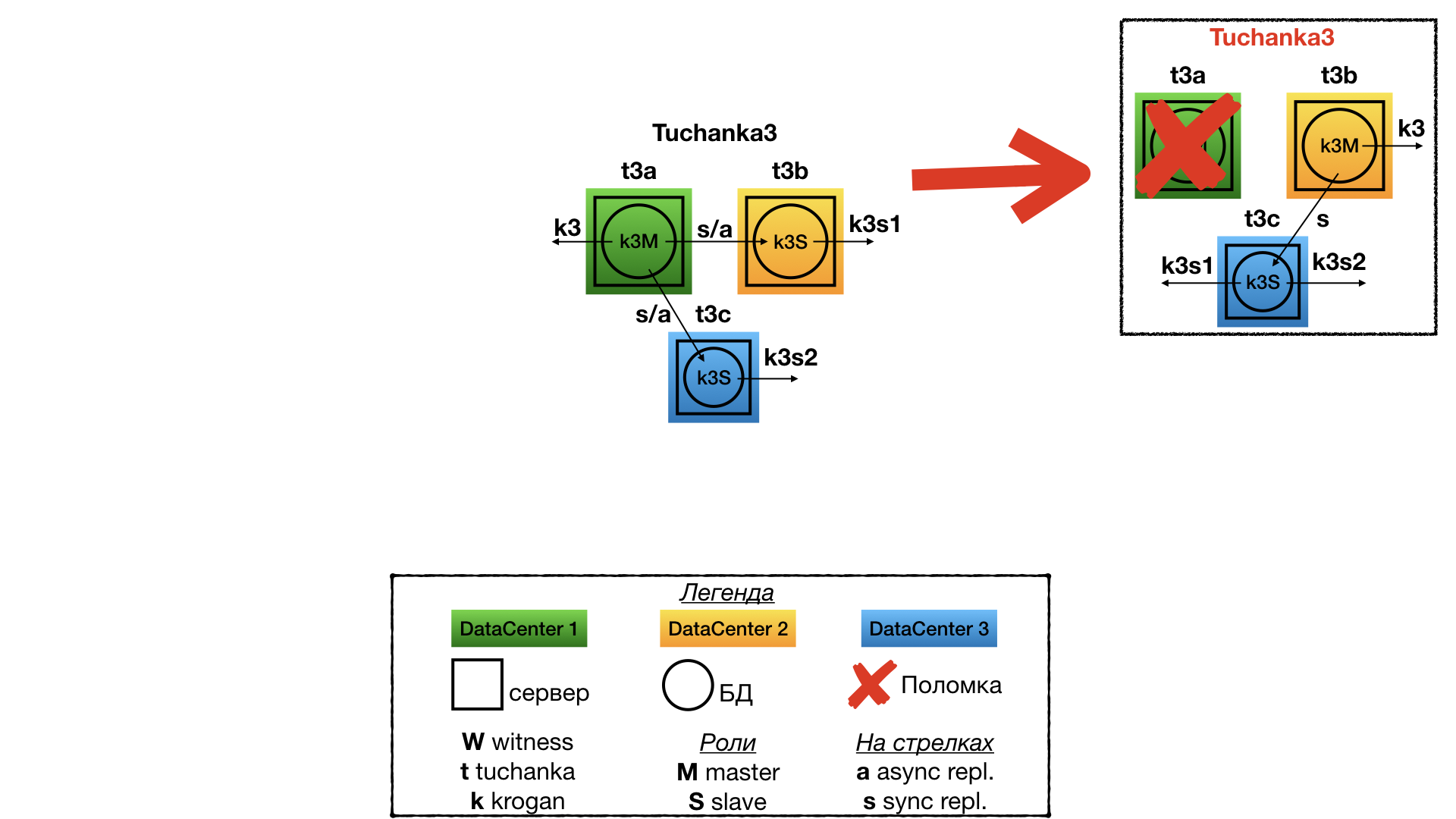
При отказе одного из дата-центров остаются два. В одном поднят мастер и float IP от мастера, во втором — раб и оба рабских float IP (на инстансе должен быть двукратный запас по ресурсам, чтобы принять все подключения с обоих рабских float IP). Между мастеров и рабом синхронная репликация. Также кластер сохранит информацию о закоммиченных и подтвержденных транзакциях (не будет потери информации) в случае уничтожения двух дата-центров (если они уничтожены не одновременно).
Подробное описание файловой структуры и развертывания я решил не вставлять. Кто захочет поиграться, можете всё это прочитать в README. Я привожу только описание автоматического тестирования.
Система автоматического тестирования
Для проверки отказоустойчивости кластеров с имитацией различных неисправностей сделана система автоматического тестирования. Запускается скриптом test/failure. Скрипт может принимать в качестве параметров номера кластеров, которые хочется потестировать. Например, эта команда:
test/failure 2 3будет тестировать только второй и третий кластер. Если параметры не указаны, то тестироваться будут все кластеры. Все кластеры тестируются параллельно, а результат выводится в панели tmux. Tmux использует выделенный tmux сервер, поэтому скрипт можно запускать из-под default tmux, получится вложенный tmux. Рекомендую применять терминал в большом окне и с маленьким шрифтом. Перед началом тестирования все виртуалки откатываются на снэпшот на момент завершения скрипта setup.

Терминал разбит на колонки по количеству тестируемых кластеров, по умолчанию (на скриншоте) их четыре. Содержимое колонок я распишу на примере Tuchanka2. Панели на скриншоте пронумерованы:
- Здесь выводится статистика по тестам. Колонки:
- failure — название теста (функции в скрипте), который эмулирует неисправность.
- reaction — среднее арифметическое время в секундах, за которое кластер восстановил свою работоспособность. Замеряется от начала работы скрипта, эмулирующего неисправность, и до момента, когда кластер восстанавливает свою работоспособность и способен продолжать оказывать услуги. Если время очень маленькое, например, шесть секунд (так бывает в кластерах с несколькими рабами (Tuchanka3 и Tuchanka4)), это означает, что неисправность оказалась на асинхронном рабе и никак не повлияла на работоспособность, переключений состояния кластера не было.
- deviation — показывает разброс (точность) значения reaction методом «стандартная девиация».
- count — сколько раз был выполнен этот тест.
- Краткий журнал позволяет оценить, чем занимается кластер в текущий момент. Выводится номер итерации (теста), временна?я метка и название операции. Слишком долгое выполнение (> 5 минут) говорит о какой-то проблеме.
- heart (сердце) — текущее время. Для визуальной оценки работоспособности мастера в его таблицу постоянно пишется текущее время с использованием float IP мастера. В случае успеха результат выводится в этой панели.
- beat (пульс) — «текущее время», которое ранее было записано скриптом heart в мастер, теперь считывается из раба через его float IP. Позволяет визуально оценить работоспособность раба и репликации. В Tuchanka1 нет рабов с float IP (нет рабов, оказывающих услуги), но зато там два инстанса (БД), поэтому здесь будет показываться не beat, а heart второго инстанса.
- Мониторинг состояния кластера с помощью утилиты
pcs mon. Показывает структуру, распределение ресурсов по узлам и другую полезную информацию. - Здесь выводится системный мониторинг с каждой виртуалки кластера. Таких панелей может быть и больше — сколько виртуалок у кластера. Два графика CPU Load (в виртуалках по два процессора), имя виртуалки, System Load (названый как Load Average, потому что он усреднен за 5, 10 и 15 минут), данные по процессам и распределение памяти.
- Трассировка скрипта, выполняющего тестирования. В случае неисправности — внезапного прерывания работы либо бесконечного цикла ожидания — здесь можно будет увидеть причину такого поведения.
Тестирование проводится в два этапа. Сначала скрипт проходит по всем разновидностям тестов, случайным образом выбирая виртуалку, к которой этот тест применить. Затем выполняется бесконечный цикл тестирования, виртуалки и неисправность каждый раз выбираются случайным образом. Внезапное завершение скрипта тестирования (нижняя панель) или бесконечный цикл ожидания чего-либо (> 5 минут время выполнения одной операции, это видно в трассировке) говорит о том, что какой-то из тестов на этом кластере провалился.
Каждый тест состоит из следующих операций:
- Запуск функции, эмулирующей неисправность.
- Ready? — ожидание восстановления работоспособности кластера (когда оказываются все услуги).
- Показывается время ожидания восстановления кластера (reaction).
- Fix — кластер «чинится». После чего он должен вернуться в полностью работоспособное состояние и готовности к следующей неисправности.
Вот список тестов с описанием, что они делают:
- ForkBomb: создает "Out of memory" с помощью форк-бомбы.
- OutOfSpace: переполняет винчестер. Но тест, скорее, символичный, при той незначительной нагрузке, которая создаётся при тестировании, при переполнении винчестера отказа PostgreSQL обычно не происходит.
- Postgres-KILL: убивает PostgreSQL командой
killall -KILL postgres. - Postgres-STOP: подвешивает PostgreSQL командой
killall -STOP postgres. - PowerOff: «обесточивает» виртуалку командой
VBoxManage controlvm "виртуалка" poweroff. - Reset: перегружает виртуалку командой
VBoxManage controlvm "виртуалка" reset. - SBD-STOP: подвешивает демон SBD командой
killall -STOP sbd. - ShutDown: через SSH посылает на виртуалку команду
systemctl poweroff, система корректно завершает работу. - UnLink: сетевая изоляция, команда
VBoxManage controlvm "виртуалка" setlinkstate1 off.
Завершение тестирование либо с помощью стандартной командой tmux "kill-window" Ctrl-b &, либо командой "detach-client" Ctrl-b d: при этом тестирование завершается, tmux закрывается, виртуалки выключаются.
Выявленные при тестировании проблемы
На текущий момент watchdog демон sbd отрабатывает остановку наблюдаемых демонов, но не их зависание. И, как следствие, некорректно отрабатываются неисправности, приводящие к зависанию только Corosync и Pacemaker, но при этом не подвешивающие sbd. Для проверки Corosync уже есть PR#83 (в GitHub у sbd), принят в ветку master. Обещали (в PR#83), что и для Pacemaker будет что-то подобное, надеюсь, что к RedHat 8 сделают. Но подобные «неисправности» умозрительные, легко имитируются искусственно с помощью, например,
killall -STOP corosync, но никогда не встречаются в реальной жизни.
У Pacemaker в версии для CentOS 7 неправильно выставлен sync_timeout у quorum device, в результате при отказе одного узла с некоторой вероятностью перезагружался и второй узел, на который должен был переехать мастер. Вылечилось увеличением sync_timeout у quorum device во время развертывания (в скрипте
setup/setup1). Эта поправка не была принята разработчиками Pacemaker, вместо этого они пообещали переработать инфраструктуру таким образом (в некотором неопределенном будущем), чтобы этот таймаут вычислялся автоматически.
Если при конфигурировании базы данных указано, что в
LC_MESSAGES(текстовые сообщения) может использоваться Юникод, например,ru_RU.UTF-8, то при запуске postgres в окружении, где locale не UTF-8, допустим, в пустом окружении (здесь pacemaker+pgsqlms(paf) запускает postgres), то в логе вместо букв UTF-8 будут знаки вопроса. Разработчики PostgreSQL так и не договорились, что делать в этом случае. Это обходится, нужно ставитьLC_MESSAGES=en_US.UTF-8при конфигурировании (создании) инстанса БД.
Если выставлен wal_receiver_timeout (по умолчанию он 60s), то при тесте PostgreSQL-STOP на мастере в кластерах tuchanka3 и tuchanka4 не происходит переподключение репликации к новому мастеру. Репликация там синхронная, поэтому останавливается не только раб, но и новый мастер. Обходится установкой wal_receiver_timeout=0 при настройке PostgreSQL.
Изредко наблюдал подвисание репликации у PostgreSQL в тесте ForkBomb (переполнение памяти). После ForkBomb иногда рабы могут не переподключаться к новому мастеру. Я встречал такое лишь в кластерах tuchanka3 и tuchanka4, где из-за того, что репликация синхронная, подвисал мастер. Проблема проходила сама, спустя какое-то длительное время (порядка двух часов). Требуется дополнительное исследование, чтобы это исправить. По симптомам похоже на предыдущий баг, который вызывается другой причиной, но с одинаковыми последствиями.
Картинка крогана взята с Deviant Art c разрешения автора:







medvedd
Боже упаси вас употреблять слова master и slave.
Вокнутые заклюют, к сожалению.
splarv Автор
Поэтому я вместо них использую слова «мастер» и «раб». :)
zuborg
«хозяин» и «раб» же!
splarv Автор
Не совсем так. Это в английском master это хозяин, причем, как я понимаю, ремесленной мастерской в феодальные времена. А в американском… Может читали Марка Твена «Приключе?ния Ге?кльберри Фи?нна»? Книжка про то как белый пацан-беспризорник путешествовал по реке на плоту вместе с беглым негром. Так вот, негр постоянно обращается к пацану "мастэ". Так вот это оно и есть, Гек никаким хозяином негру не был.
JuriM
сервиторы :)
BjLomax
Лучше «барин» и «холоп»
splarv Автор
Холоп это военнопленный, наихудшая форма рабства на Руси. Потом так стали называть и обычных крестьян. А полным аналогом "мастэ" будет господин он же господарь. Это и было обозначение рабовладельца, которое потом перешло в обычное обращение. Собственно когда цари стали себя наименовать "господарь всея Руси" это означало что всё остальное население, включая дворян, это рабы по отношению к царю. При великих князьях такого разумеется не было.
Ну а если серьезно, почему я использовал "мастер" и "раб", потому что, понятно, английские термины, которые приняты много где, в том числе и Pacemaker, это master и slave. И если слово "мастер" по русским падежам нормально склоняется, то как "слейв" склоняется по падежам мне не понравилось.