
Искать утечки и уязвимости в своих продуктах не только интересно и полезно, но и необходимо. Еще полезнее подключать к таким поискам внешних специалистов и энтузиастов, у которых не настолько замылен глаз, как у сотрудников. Поэтому в свое время мы в QIWI запустили программу bug bounty — исследователи писали нам об уязвимостях и получали вознаграждение, а мы — закрывали эти уязвимости.
Несколько раз нам присылали выложенный в публичный доступ код в виде ссылок на репозитории с чувствительной информацией. Причины утечек могли быть такими:
разработчик писал тестовый пример кода для себя, используя конфигурации “боевого” сервиса — не тестовую среду;
админ выкладывал скрипты автоматизации и миграции базы данных — потенциально чувствительной информации;
стажер неосознанно размещал код в своем публичном репозитории, считая, что это не несет рисков.
При этом такие утечки могут исходить как от работающих в компании разработчиков, так и от тех, кто уже уволился. Например, бывали случаи, когда уже не работающий в компании сотрудник размещал в открытом репозитории код, который когда-то брал домой, чтобы поработать с ним в свободное время. Казалось бы — звучит безобидно, но внутри такого кода вполне могли быть пароли от базы данных, конфигурации сетей или какая-то бизнес-логика, — в общем, чувствительная для компании информация, которой не должно быть в публичном доступе.
Как показывает практика, большинство компаний уже неплохо защищены от внешних угроз — и наибольший вред может нанести именно внутренняя утечка. При этом такая утечка может случиться как злонамеренно, так и по случайности — а это как раз то, о чем мы сказали выше.
И в целом безопасность компаний — не абсолютна: хорошо защищая свой периметр и информационные системы с помощью с помощью Firewall, SOC, IDS/IPS и сканеров безопасности, компании все равно подвержены многим источникам утечек — от внешней разработки и аудиторов до вендорских решений. Конечно, невозможно отвечать за безопасность других компаний, но мониторить случаи утечки вашей информации с их стороны — можно и нужно.
Поэтому мы озаботились вопросом утечек по всем источникам. Автоматизировав их поиск, мы сначала сделали продукт для себя, а теперь готовы предлагать его рынку.
Так появился QIWI Leak-Search — сервис, который ищет утечки вашего кода на Github и не только.
Как мы его делали и что он умеет — читайте в посте.
Предыстория
Сначала мы пошли в рынок и посмотрели, как там дела с такими продуктами: вдруг можно купить что-то работающее, проблема-то, прямо скажем, не только у нас такая. Рынок уверенного ответа не дал, и мы поняли — надо делать самим.
В самом начале наш сервис автоматического поиска утечек представлял собой набор скриптов, и в таком виде он просуществовал около двух месяцев. Только потом уже начал вырисовываться полноценный сервис. Сейчас это понятный веб-интерфейс, где представитель любой компании может быстро задать тот или иной запрос и посмотреть, все ли у компании хорошо в плане утечек.
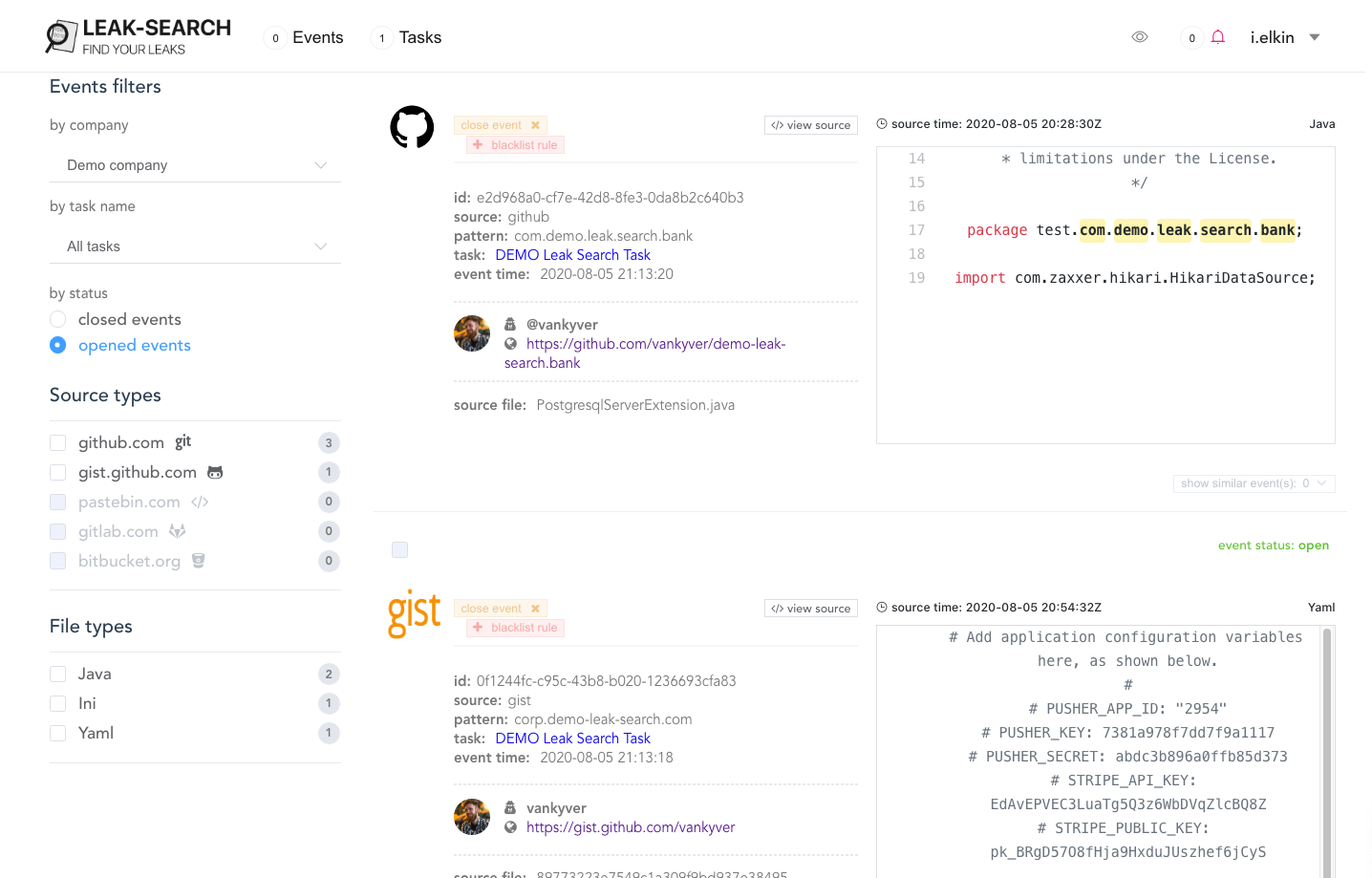
Тестировали Leak-Search мы прежде всего на себе, но затем решили посмотреть, есть ли проблемы с утечками у компаний, которые явно тратят на информационную безопасность немало средств и времени. Мы взяли компании из рейтинга Fortune и проверили их с помощью нашего сервиса. Тогда мы удостоверились, что вне зависимости от того, сколько ресурсов компания вкладывает в ИБ, подобного рода утечки встречаются и у нее.
Затем мы решили проверить отечественные крупные компании, которые своими силами борются с утечками. У них тоже нашлись подобные ИБ-сложности: доступы к базам данных, почтовым серверам, к управлению гипервизорами и многое другое. В общем, если вы представите себе какую-то известную компанию, знайте: скорее всего, у нее ситуация с утечками примерно такая же — есть над чем работать.
Вот несколько примеров, которые мы нашли с помощью Leak-Search. Крупная российская компания из сферы ритейла “дает” доступ к ERP-системам для управления деталями заказов — кто хотел бы бесплатно перенаправлять себе чужие заказы на технику и одежду? Один из международных ИТ-гигантов “предоставляет” исходники операционной системы для IoT-устройств — почему бы не поискать уязвимости, обладая максимальными правами доступа? Неназванное западное управление по исследованию космоса “без проблем” открывает информацию о потенциально опасных астероидах — отличная возможность получить доказательства для создателей пугающего контента. Детали и названия этих компаний по понятным причинам мы не разглашаем.
Что и как ищет QIWI Leak-Search
Код для любой компании — это интеллектуальная собственность со всеми вытекающими юридическими последствиями. Но самое главное — это детали реализации системы, содержащие бизнес-логику, внутреннюю информацию или ключевые фичи — в общем, вещи, которым в публичном доступе не место. Совсем.
В нашем случае, да и в случае других банков и финансовых компаний, основное — это код, относящийся к механизму процессинга проведения платежей и переводов, к расчету банковских ставок и агентских комиссий, идентификации разных типов клиентов, протоколов взаимодействия с другими банками и провайдерами, — то есть ядро финансовой деятельности.
Появление таких данных в открытом доступе может повлечь не только потерю интеллектуальной собственности, но и денег — и стать угрозой репутации. Как минимум, какой-нибудь багхантер напишет очередной пост про слив и утечки, как максимум — этот кусок кода может содержать скрытую уязвимость, приводящую к реальной эксплуатации и взлому.
Хотя во многих таких ситуациях даже не нужен взлом. Мы часто сталкивались с тем, что админы и разработчики разных компаний сами могут случайно выложить в общий доступ код, содержащий пароли, токены и ключи доступа к системам компании.
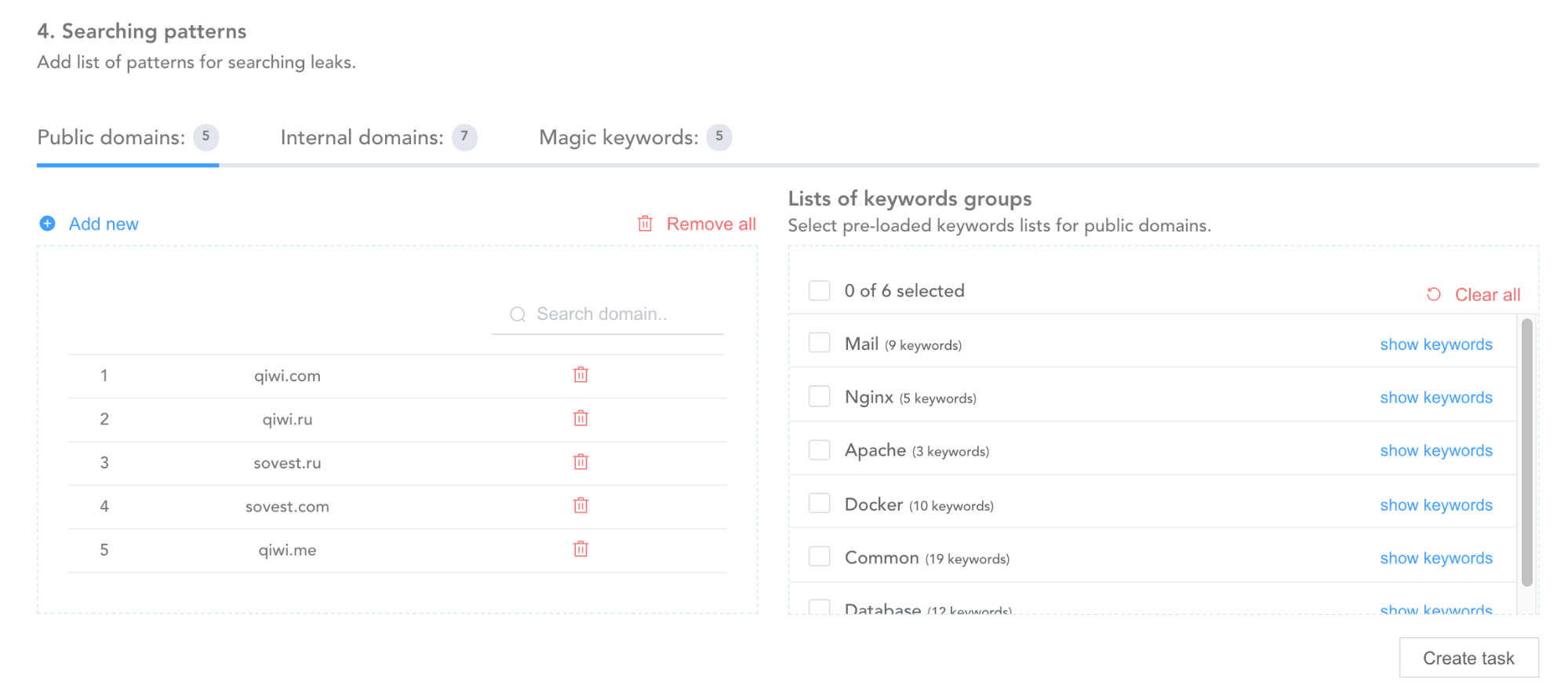
Поэтому в Leak-Search мы ищем все, что может относиться к чувствительным данным. Например:
— набор определенных ключевых слов — smtp, Dockerfile, proxypass, Authorization;
— названия пакетов — com.qiwi.processing.common;
— адреса серверов — int.qiwi.com, 10.4.3.255;
— названия переменных, характерных именно для внутренней разработки компании — QIWISECRET_KEY, qiwiToken.
В ядро системы зашито множество поисковых паттернов, определяющих, что та или иная информация является конфиденциальной. Именно поиск по ряду таких параметров сразу и позволяет обнаруживать что-то полезное — утечки, которые нужно брать в работу и устранять.
Особенности поиска системы
Репозиториев существует великое множество. А еще много как просто похожих репозиториев, так и форков. У нас тоже много вещей отдано в Open Source: мы поддерживаем это движение и рады делиться с ИТ-сообществом ценными наработками. Пользователи из наших исходных кодов уже успели сделать больше сотни разных форков.
Поэтому, если начать искать утечки исходного кода таким образом, можно получить выдачу с огромным количеством нерелевантных результатов — в ней будут все «клонированные» репозитории и форки.
Масла в огонь подольет еще и StackOverflow — один разработчик придет на портал с вопросом, разместив часть кода, которую он не понял. Второй ответит в комментариях и даст другой отрывок кода в качестве ответа. Третий через пару месяцев найдет эту ветку обсуждения, потому что тоже не понял код, и заберет пример из комментария к себе на Github. И скорее всего, найдет ветку и возьмет код не он один.
Да и, признайтесь, были же случаи, когда вы писали какой-то код для себя, а потом решили посмотреть, как такое же сделал кто-то на Github — и вуаля, у вас в репозитории абсолютно такой же кусок. И это нормально.
Что можно найти таким методом сравнения, если очистить и кластеризовать поиск? Если вы ищете следы возможной уязвимости, вы найдете репозитории, в которых она была переиспользована. То же случится, если вы захотите посмотреть, где именно используют ваши идеи.
Но сравнение результатов — это не killer feature продукта. Leak-Search может больше: он позволяет пользователю персонализировать поиск и использовать механизм фильтрации, чтобы исключить ложные срабатывания. Во-первых, можно включить определенные репозитории в такой фильтр и не искать фрагменты утечки по ним. Во-вторых, фокусируясь только на конкретных, интересующих вас объектах, вы будете получать нужные результаты.

Разработка и поддержка
Возможно, вы замечали, что после достаточно активного использования open source, в таких сервисах, как Github, система безопасности сервиса могла вас заблокировать за превышение лимитов запросов. Поэтому нам пришлось постараться, чтобы Leak-Search имитировал “человеческий” поиск.
При этом мы активно добавляем публичные платформы для хранения исходных кодов в список источников, по которым осуществляется поиск. Начали мы с Github — но теперь Leak-Search ищет утечки уже и в Gist. В бета-тесте у нас Pastebin и Gitlab, и еще планируем добавить BitBucket. А под каждый источник мы учитываем его специфику поиска и работы с API.
В рамках алгоритма, конечно, бывают и ложные срабатывания — как false positive, так и false negative. Пока мы решаем это добавлением новых правил для фильтров, чтобы те работали все точнее.
Также мы планируем сделать “черный список” самих запросов. К примеру, вас не интересуют конкретные пользователи, репозитории или их связки с определенным типом файла — и вы просто настраиваете это в параметрах поиска, чтобы соответствующих результатов не было в выдаче.
Идеальной нам видится система, когда Leak-Search можно будет встроить на саму площадку с репозиториями. Мы делали подобное у себя. На внутренний репозиторий мы вешали Leak-Search как триггер, он срабатывал при попытках выложить код с важной информацией — это тоже одно из направлений развития сервиса.
Этическая сторона вопроса
Как и любой сервис, связанный с поиском утечек, Leak-Search можно использовать не только для защиты, но и для “нападения”. Скажем больше — когда мы пилотировали продукт с некоторыми компаниями, сталкивались с тем, что их сотрудники вместо того, чтобы тщательно исследовать свои ИБ-проблемы, сканировали утечки конкурентов.
Такую возможность мы пресекли на старте, и поэтому сервис работает по правилам жесткой модерации. Чтобы человек получил возможность сканировать репозитории конкретной компании, он должен подтвердить, что является ее действующим сотрудником. Мы регистрируем новых пользователей после личной коммуникации, но все равно продолжаем премодерировать поисковые запросы — чтобы исключить риск неправомерного использования платформы.
Вот так из сервиса, который мы делали для себя, чтобы мониторить утечки, мы сделали продукт, работающий сейчас уже не только для нас, но и для крупнейших российских компаний в сфере IT, финансов и маркетинга.
Если вам интересно что-то еще, о чем мы не упомянули в посте, — спрашивайте, ответим.




awoland
Имел я когда-то идентифицированный кошелек QIWI… Даже карты заказывал пластиковые раза три. Пользовался ими активно. К кошельку тому были привязаны тоже идентифицированные (проффессиональные) кошельки WebMoney и ЯндексДеньги. Телефон на который был привязан кошелек не менялся никогда. Только лишь однажды перешел с этим своим номером от одного оператора сотовой связи к другому. Скан-копии всех паспортов тоже загружал в сервис QIWI неоднократно. Электронную почту тоже никогда не менял… Но когда с меня в очередной раз потребовали пройти процедуру идентификации кошелька (после уже пройденных трех до этого) я понял, что больше не буду пользоваться сервисами QIWI…