

Меня зовут Илья Гуляев, я занимаюсь автоматизацией тестирования в команде Post Deployment Verification в компании DINS.
В DINS мы используем Jenkins во многих процессах: от сборки билдов до запуска деплоев и автотестов. В моей команде мы используем Jenkins в качестве платформы для единообразного запуска смоук-проверок после деплоя каждого нашего сервиса от девелоперских окружений до продакшена.
Год назад другие команды решили использовать наши пайплайны не только для проверки одного сервиса после его обновления, но и проверять состояние всего окружения перед запуском больших пачек тестов. Нагрузка на нашу платформу возросла в десятки раз, и Jenkins перестал справляться с поставленной задачей и стал просто падать. Мы быстро поняли, что добавление ресурсов и тюнинг сборщика мусора могут лишь отсрочить проблему, но не решат ее полностью. Поэтому мы решили найти узкие места Jenkins и оптимизировать их.
В этой статье я расскажу, как работает Jenkins Pipeline, и поделюсь своими находками, которые, возможно, помогут вам сделать пайплайны быстрее. Материал будет полезен инженерам, которые уже работали с Jenkins, и хотят познакомиться с инструментом ближе.
Что за зверь Jenkins Pipeline
Jenkins Pipeline — мощный инструмент, который позволяет автоматизировать различные процессы. Jenkins Pipeline представляет собой набор плагинов, которые позволяют описывать действия в виде Groovy DSL, и является преемником плагина Build Flow.
Скрипт для плагина Build Flow исполнялся напрямую на мастере в отдельном Java-потоке, который выполнял Groovy-код без барьеров, препятствующих доступу к внутреннему API Jenkins. Данный подход представлял угрозу безопасности, что впоследствии стало одной из причин отказа от Build Flow, и послужило предпосылкой для создания безопасного и масштабируемого инструмента для запуска скриптов — Jenkins Pipeline.
Подробнее об истории создания Jenkins Pipeline можно узнать из статьи автора Build Flow или доклада Олега Ненашева о Groovy DSL в Jenkins.
Как работает Jenkins Pipeline
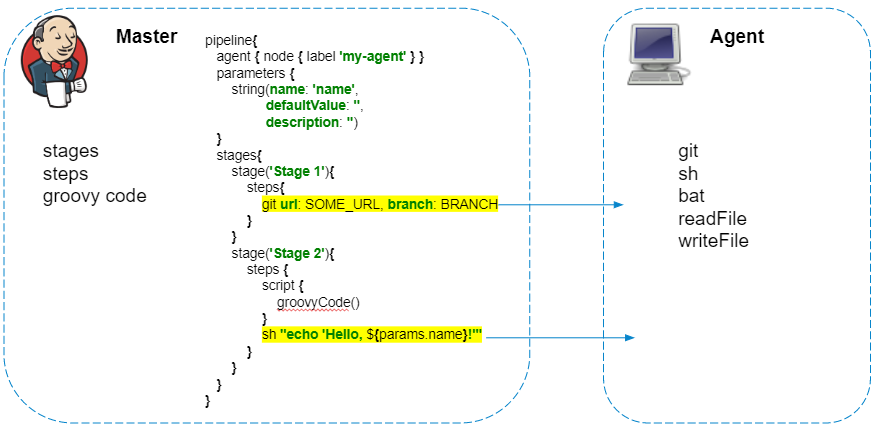
Теперь разберемся, как работают пайплайны изнутри. Обычно говорят, что Jenkins Pipeline — совершенно другой вид заданий в Jenkins, непохожий на старые добрые freestyle-джобы, которые можно накликать в веб-интерфейсе. С точки зрения пользователя это, может, и выглядит так, но со стороны Jenkins пайплайны — набор плагинов, которые позволяют перенести описание действий в код.
Сходства Pipeline и Freestyle джобы
- Описание джобы (не шагов) хранится в файле config.xml
- Параметры хранятся в config.xml
- Триггеры тоже хранятся в config.xml
- И даже некоторые опции хранятся в config.xml
Так. Стоп. В официальной документации сказано, что параметры, триггеры и опции можно задавать непосредственно в Pipeline. Где же правда?
Правда в том, что параметры, описанные в Pipeline, автоматически добавятся в раздел настройки в веб-интерфейсе при запуске джобы. Верить мне можно потому, что этот функционал в последней редакции писал я, но об этом подробнее во второй части статьи.
Отличия Pipeline и Freestyle джобы
- На момент старта джобы Jenkins ничего не знает про агента для выполнения джобы
- Действия описываются в одном groovy-скрипте
Запуск Jenkins Declarative Pipeline
Процесс запуска Jenkins Pipeline состоит из следующих шагов:
- Загрузка описания задания из файла config.xml
- Старт отдельного потока (легковесного исполнителя) для выполнения задания
- Загрузка скрипта пайплайна
- Построение и проверка синтаксического дерева
- Обновления конфигурации задания
- Объединение параметров и свойств заданных в описании задания и в скрипте
- Сохранение описания задания в файловую систему
- Выполнение скрипта в groovy-песочнице
- Запрос агента для всего задания или отдельного шага
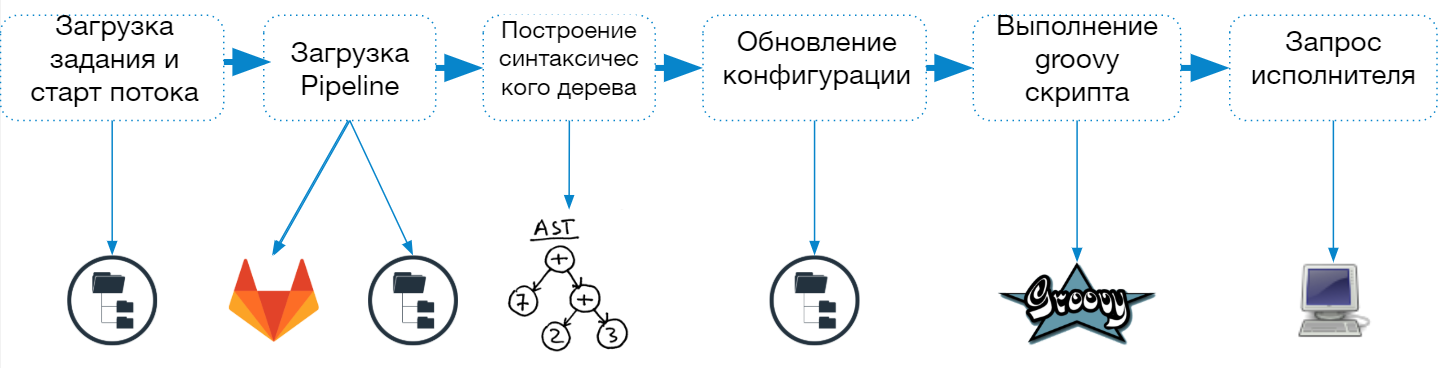
При старте pipeline-джобы Jenkins создает отдельный поток и направляет задание в очередь на выполнение, а после загрузки скрипта определяет, какой агент нужен для выполнения задачи.
Для поддержки данного подхода используется специальный пул потоков Jenkins (легковесных исполнителей). Можно заметить, что они выполняются на мастере, но не затрагивают обычный пул исполнителей:
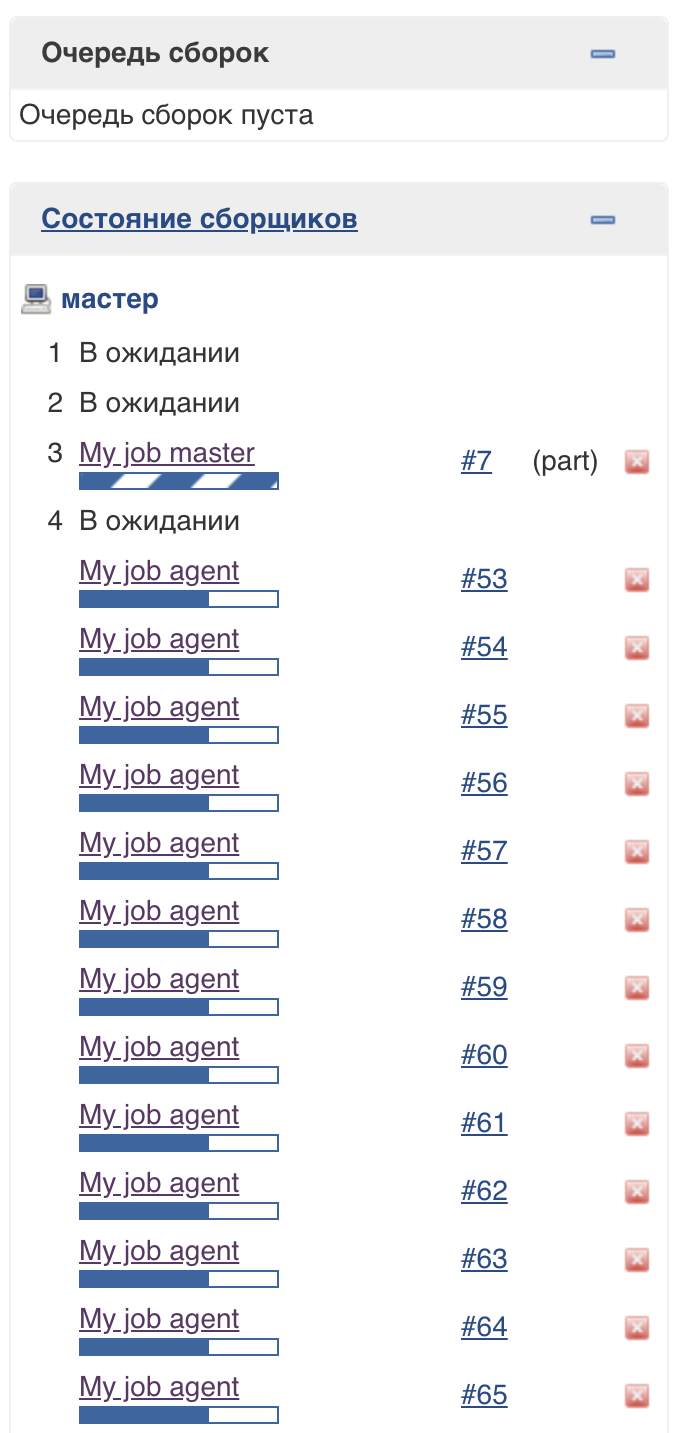
Количество потоков в данном пуле не ограничено (на момент написания статьи).
Работа параметров в Pipeline. А также триггеров и некоторых опций
Обработку параметров можно описать формулой:

Из параметров джобы, которые мы видим при запуске, сначала удаляются параметры Pipeline из предыдущего запуска, а уже потом добавляются параметры заданные в Pipeline текущего запуска. Это позволяет удалить параметры из джобы, если они были удалены из Pipeline.
Как это работет изнутри?
Рассмотрим пример config.xml (файл, в котором хранится конфигурация джобы):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
В секции properties находятся параметры, триггеры и опции, с которыми будет запускаться джоба. Дополнительная секция DeclarativeJobPropertyTrackerAction служит для хранения параметров, заданных только в пайплайне.
При удалении параметра из пайплайна, он будет удлён как из DeclarativeJobPropertyTrackerAction так и из properties, так как Jenkins будет знать, что параметр был определён только в пайплайне.
При добавлении параметра ситуация обратная, параметр добавится DeclarativeJobPropertyTrackerAction и properties, но только в момент исполнения пайплайна.
Именно поэтому если задать параметры только в пайплайне, то они будут недоступны при первом запуске.
Выполнение Jenkins Pipeline
Когда Pipeline-скрипт загружен и скомпилирован, начинается процесс выполнения. Но этот процесс состоит не только из выполнения groovy. Я выделил основные тяжеловесные операции, которые выполняются в момент исполнения джобы:
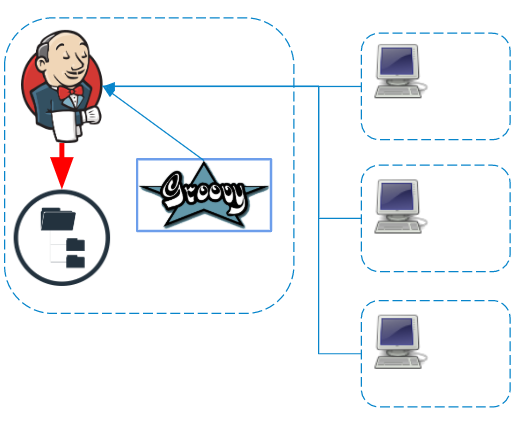
Выполнение Groovy-кода
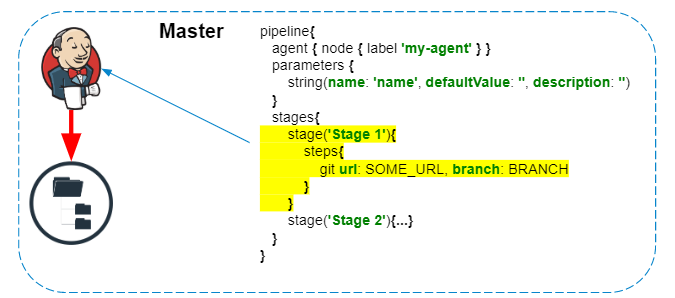
Скрипт пайплайна всегда выполняется на мастере — об этом нельзя забывать, чтобы не создавать лишнюю нагрузку на Jenkins. На агенте исполняются только шаги, которые взаимодействуют с файловой системой агента или системными вызовами.
В пайплайнах есть замечательный плагин, который позволяет делать HTTP запросы. В добавок ответ можно сохранять в файл.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Изначально может показаться, что данный код должен полностью выполняться на агенте, послать с агента запрос, а ответ сохранить в файл result.json. Но всё происходит наоборот, и запрос выполняется с самого дженкинса, а для сохранения содержимое файла копируется на агент. Если дополнительная обработка ответа в пайплайне не требуется, то советую заменять такие запросы на curl:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Работа с логами и артефактами
Независимо от того, на каком агенте выполняются команды, логи и артефакты обрабатываются и сохраняются на файловую систему мастера в режиме реального времени.
Если в пайплайне используются секреты (credentials), то перед сохранением логи дополнительно фильтруются на мастере.
Сохранение шагов (Pipeline Durability)
Jenkins Pipeline позиционирует себя как задача, которая стоит из отдельных кусочков, которые независимы и могут быть воспроизведены при падении мастера. Но за это приходится платить дополнительными записями на диск, потому что в зависимости от настроек задачи шаги с различной степенью детализации сериализуются и сохраняются на диск.
В зависимости от параметра живучести (pipeline durability) шаги графа пайплайна будут храниться в одном или нескольких файлах для каждого запуска джобы. Выдержка из документации:
В плагине workflow-support для хранения степов (FlowNode) используется класс FlowNodeStorage и его реализации SimpleXStreamFlowNodeStorage и BulkFlowNodeStorage.
- FlowNodeStorage использует кэширование в памяти для объединения операций записи на диск. Буфер автоматически записывается во время выполнения. Как правило, вам не нужно беспокоиться об этом, но имейте в виду, что сохранение FlowNode не гарантирует, что он будет немедленно записан на диске.
- SimpleXStreamFlowNodeStorage использует по одному небольшому XML-файлу для каждого FlowNode — хотя мы используем кеш с soft-reference в памяти для узлов, это приводит к гораздо худшей производительности при первом прохождении через степы (FlowNodes).
- BulkFlowNodeStorage использует один XML-файл большего размера со всеми FlowNodes в нем. Этот класс используется в режиме живучести PERFORMANCE_OPTIMIZED, который записывает гораздо реже. Как правило, это намного эффективнее, потому что одна большая потоковая запись выполняется быстрее, чем группа небольших записей, и сводит к минимуму нагрузку на ОС для управления всеми крошечными файлами.
Оригинал
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
Сохранённые шаги можно найти в директории:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
Пример файла:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Итоги
Надеюсь, данный материал был интересен и помог лучше понять, что из себя представляют пайплайны и как они работают изнутри. Если у вас остались вопросы — делитесь ими ниже, буду рад ответить!
Во второй части статьи я рассмотрю отдельные кейсы, которые помогут найти проблемы с Jenkins Pipeline и ускорить ваши задачки. Узнаем, как решать проблемы параллельного запуска, рассмотрим параметры «живучести» и обсудим, зачем профилировать Jenkins.
vladshulkevich
Вот реально, не могу понять, за что я не люблю xml