
Российские провайдеры давно умеют делать облачные платформы сами, а не только реселлить зарубежные. Это снижает стоимость сервисов, но их пользователям бывает интересно узнать, какая у них начинка и что обеспечивает их надёжность.
Я Дмитрий Лазаренко, директор по продуктам облачной платформы Mail.ru Cloud Solutions (MCS). Сегодня я расскажу, что под капотом у нашего Kubernetes aaS, как обеспечивается его надёжность и какие у него есть интересные функциональности, которыми любят пользоваться наши клиенты. Это автомасштабирование, интеграция с другими PaaS нашей платформы и многое другое.
Главные фичи Kubernetes на платформе MCS
Наш Kubernetes aaS включает:
- Интерфейс управления для создания кластера в несколько кликов, масштабирования и настройки.
- Автоматическое масштабирование узлов кластера в большую или меньшую сторону, то есть добавление или удаление нод (Cluster Autoscaler).
- Встроенный мониторинг на основе Prometheus Operator и Grafana. Многие наши пользователи начинают с базовых инсталляций, где запускается приложение. Когда оно выходит в продуктив, это позволяет им мониторить сервисы и сам кластер.
- Свой Terraform-провайдер для Kubernetes. Он полностью поддерживает API MCS.
- Интеграция с Docker Registry для хранения и управления образами.
- Автоматизированное развёртывание федеративных кластеров Kubernetes на базе AWS и Mail.ru Cloud Solutions (о чём мы писали тут).
- Возможность сделать Start/Stop для кластера целиком — экономия для тестовых сред. Вы можете выключить кластер одним кликом в интерфейсе и платить только за диски в случае остановленных кластеров.
- Поддержка создания Node Pools, пулов виртуальных машин разных размеров: можно запускать тяжелые задачи на больших машинах, веб-приложения на маленьких. Масштабировать группы можно независимо и размещать их в разных регионах либо зонах доступности (для большей надежности и доступности).
- Persistent Volumes интегрированы с системой хранения OpenStack.
- Поддержка приватных кластеров, доступных только через VPN-соединение.
- Поддерживается Cluster Policy: Local, которая позволяет получать реальные IP пользователей внутри кластеров.
- Создание и масштабирование кластеров Kubernetes с помощью UI или API MCS, управление сущностями через Kubernetes dashboard и kubectl.
- Плавное обновление (rolling update) в один клик без простоя как для минорных, так и для мажорных версий. Обновления кластеров до 1.16.
- На момент написания статьи мы поддерживаем Kubernetes вплоть до версии 1.17.

Создание кластера Kubernetes в несколько кликов
Дальнейшее развитие сервиса:
- CI/CD aaS, интегрированный с Kubernetes и другими сервисами платформы: дополнительные сервисы, которые обеспечивают CI/CD, на базе наших собственных доработок OpenStack.
- Логирование aaS для приложений приложений, которые работают в нашем Kubernetes. Логирование будет реализовано на базе нескольких решений OpenStack.
- Service mesh: у нас появятся плагины для Kubernetes, которые в рамках реализации service mesh будут выполнять шифрование, бэкапирование и другие функции.
Сертификация дистрибутива в Cloud Native Computing Foundation
Mail.ru Cloud Solutions входит в CNCF (Cloud Native Computing Foundation). Дистрибутив Kubernetes от MCS получил сертификат Certified Kubernetes — Hosted. Его проверили на надежность и соответствие стандартам, он отвечает всем функциональным требованиям сообщества и совместим со стандартным Kubernetes API. MCS — пока единственный в России облачный провайдер, получивший такую сертификацию.
Место Kubernetes в инфраструктуре облачной платформы
Самый нижний слой — типовые физические серверы (compute nodes). Сейчас их несколько тысяч, они используются под вычисления и хранение. Для хранения мы предоставляем файловые и блочные хранилища на базе Ceph и S3-совместимые объектные хранилища. Серверы распределены по дата-центрам, между которыми проложена сеть 40 Gbps.
Поверх уровня серверов работает OpenStack, который обеспечивает виртуализацию для пользовательских окружений. А уже поверх виртуальных машин, сетей и балансировщиков работают PaaS-решения: Kubernetes, базы данных, DWH на базе ClickHouse, Hadoop, Spark и другие.
Аналогичную схему мы строим и в приватных инсталляциях Kubernetes как сервиса в дата-центрах наших заказчиков в формате частного облака.

Архитектура облачной платформы
Интеграция Kubernetes с облаком не односторонняя. Kubernetes не просто развертывается на виртуальных машинах, он полностью интегрируется с IaaS OpenStack.
На основе провайдера Cloud Provider OpenStack мы сделали Cloud Provider для MCS, который в рамках вашего проекта (тенанта) OpenStack соединяется с API MCS и создает, конфигурирует, удаляет диски, балансеры, внешние IP-адреса, подключает их к нодам Kubernetes, конфигурирует security-группы (фактически виртуальный firewall). Без Cloud Provider создание тех же Persistent Volumes — головная боль для всех, кто запускает Kubernetes on-premise, на железе либо просто в облаке.

Интеграция Kubernetes с IaaS OpenStack
Какие инструменты мы используем
- Операционная система. Сначала мы использовали CoreOS, которая работает на хостах, сейчас у нас Fedora Atomic (1.14-1.15) и CentOS (1.16).
- Сеть — Calico. Сети Kubernetes зависят от облачной сети, которая обеспечивается SDN всего облака. В основе нашей SDN изначально был OpenStack Neutron. Но год назад мы начали разработку модуля Sprut — нашего собственного SDN-решения, которое поддерживает API Neutron, но работает по другим принципам. Подход Sprut решил наши проблемы масштабируемости, возникающие из-за десятков тысяч сетевых сущностей (портов) у нас в облаке, когда при падении сетевых нод в сети такого размера начинался процесс полной синхронизации (fullsync). Сейчас Sprut мы задействуем для тех клиентов, для которых в силу особенностей нагрузки на сеть использовать его целесообразнее, чем Calico, в перспективе мы его откроем для всех.
- Кластерный DNS на базе CoreDNS, со всеми его Service Discovery, метриками Prometheus и другими стандартными фичами.
- Ingress Controller. Сейчас это Nginx, но мы также планируем добавить Envoy, как дополнительный Ingress Controller. Наши тесты показывают, что Envoy часто быстрее. Ingress Controller интегрирован с облачным балансировщиком нагрузки на базе OpenStack Octavia и поддерживает Proxy Protocol.
- Мониторинг на базе Prometheus Operator. Раньше использовали просто Prometheus, но сейчас все хотят автоматизацию и сервис-мониторы, поэтому мы уже несколько месяцев предлагаем Prometheus Operator + Grafana, в рамках которой можно добавлять сервис-мониторы и выполнять мониторинг кластеров.
- Аддоны (опциональные расширения). В один клик можно установить Docker registry, интегрированный с нашим S3-хранилищем, ingress controller, различные системы мониторинга (Heapster, Prometheus).
Multi Master и сетевая топология
Kubernetes от Mail.ru поддерживает деплой в формате Multi Master, при этом каждая пользовательская группа нод уже находится в конкретной зоне доступности.
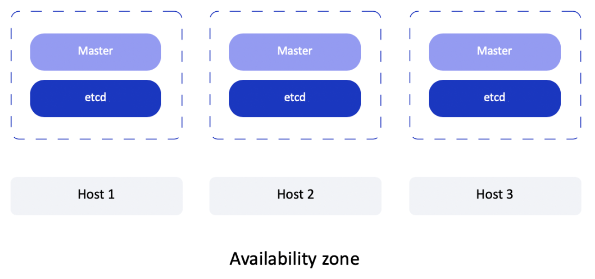
Multi Master в облаке
В Multi Master etcd работает в кластерном режиме, так что если что-то случается с одним из мастеров, другие продолжают работать. Под каждый etcd выделен отдельный SSD-диск, что обеспечивает хороший latency и быструю работу API-сервера, т.к. в etcd находится служебная информация о всех ресурсах кластера Kubernetes.
Для доступа извне используется балансировщик нагрузки API сервера Kubernetes, который имеет внешний IP-адрес. При этом все ноды — и мастера, и миньоны — находятся в приватной сети (фактически в виртуальном частном облаке) и не имеют публичных адресов.
Доступ к кластеру Kubernetes из публичной сети: запуск трафика и балансировка нагрузки
В общем случае способы доступа к сервисам внутри кластера перечислены здесь. Подробности нашей реализации:
NodePort открывает публичный порт на ноде. Однако есть ограничение: в целях безопасности по умолчанию публичные IP-адреса не установлены ни на мастера, ни на миньоны, кластеры создаются без белых IP-адресов. Пользователь может их сам установить.
Load Balancer. Наш Kubernetes интегрирован с облачной платформой MCS, так что платформа предоставляет Load Balancer как сервис и может сама создавать балансировщики. Для сравнения, если пользователь настраивает Kubernetes (например, в он премисе), нужно самостоятельно поднимать и настраивать софтверные балансеры. На платформе MCS балансировщики поднимаются сразу в отказоустойчивом режиме active-standby. Когда поднимается основной балансер (на HAProxy), у него всегда есть standby, спящий балансер. Между ними настроен VRRP. Если основной балансер отказывает, весь трафик мгновенно переключается на standby, при этом IP-адрес не меняется.

Отказоустойчивый Load Balancer как сервис на платформе MCS. Kubernetes создаёт nodeport на каждой ноде и балансировщик
В настройке балансировки для Kubernetes помогает наш Cloud Provider. Нужно создать манифест, в котором пользователь указывает тип манифеста «сервис» и тип сервиса «Load Balancer». После деплоя этого манифеста Kubernetes (точнее, Cloud Provider, который работает в Kubernetes) обращается к OpenStack API, создаёт балансировщик и внешний IP-адрес, если это необходимо. Если внешний адрес не нужен, нужно поставить аннотацию, что требуется внутренний балансировщик, и можно пускать трафик на кластер, не открывая публичный IP-адрес на каждой ноде.
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
k8s-app: nginx-backend
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer:"true"
spec:
type: LoadBalancer
externalTrafficPolicy: Cluster
selector:
k8-app: nginx-backend
ports:
-port: 80
name: http
targetPort: http
-port: 443
name: https
targetPort: httpn
Сервисный манифест для создания балансировщика нагрузки с помощью Cloud Provider
Не всегда удобно создавать по балансеру на каждый сервис, 10 сервисов — есть 10 балансировщиков, 50 сервисов — 50 балансировщиков. Ими потом также приходится управлять, это тяжелые сущности. Эту проблему решает Ingress.
Ingress. Чтобы можно было не создавать много балансировщиков, мы добавили поддержку Ingress Controller. Ingress Controller интегрирован с балансировщиком OpenStack. То есть в декларации сервиса конкретного Ingress Controller указан тип Load Balancer. Для кластера создается один балансировщик, по которому Ingress Controller работает и дальше распределяет трафик по сервисам. Ingress Controller балансирует по DNS-именам.
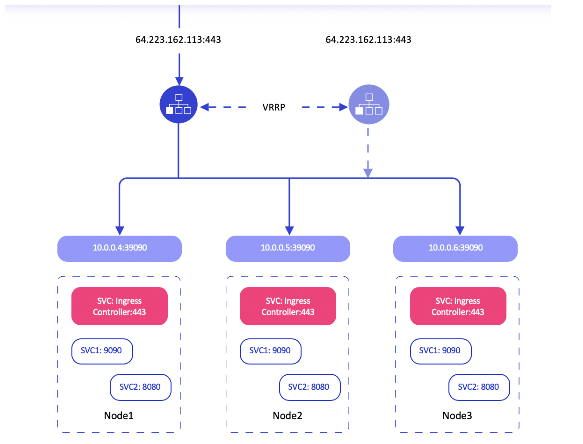
Схема работы Ingress
Для некоторых клиентов было важно, чтобы в подах было видно IP-адреса клиентов, получающих доступ в кластер. При балансировке теряются заголовки IP-пакетов: приложение не получает реальный IP-адрес клиента. Балансировщик OpenStack ещё видит заголовок X-Forwarded-For, но Ingress Controller и под его уже не получают. Это не позволяет настроить доступ пользователей по White Lists, не работают сервисы типа GeoIP или anti-DDoS, которым нужно видеть реальные IP-адреса клиентов.
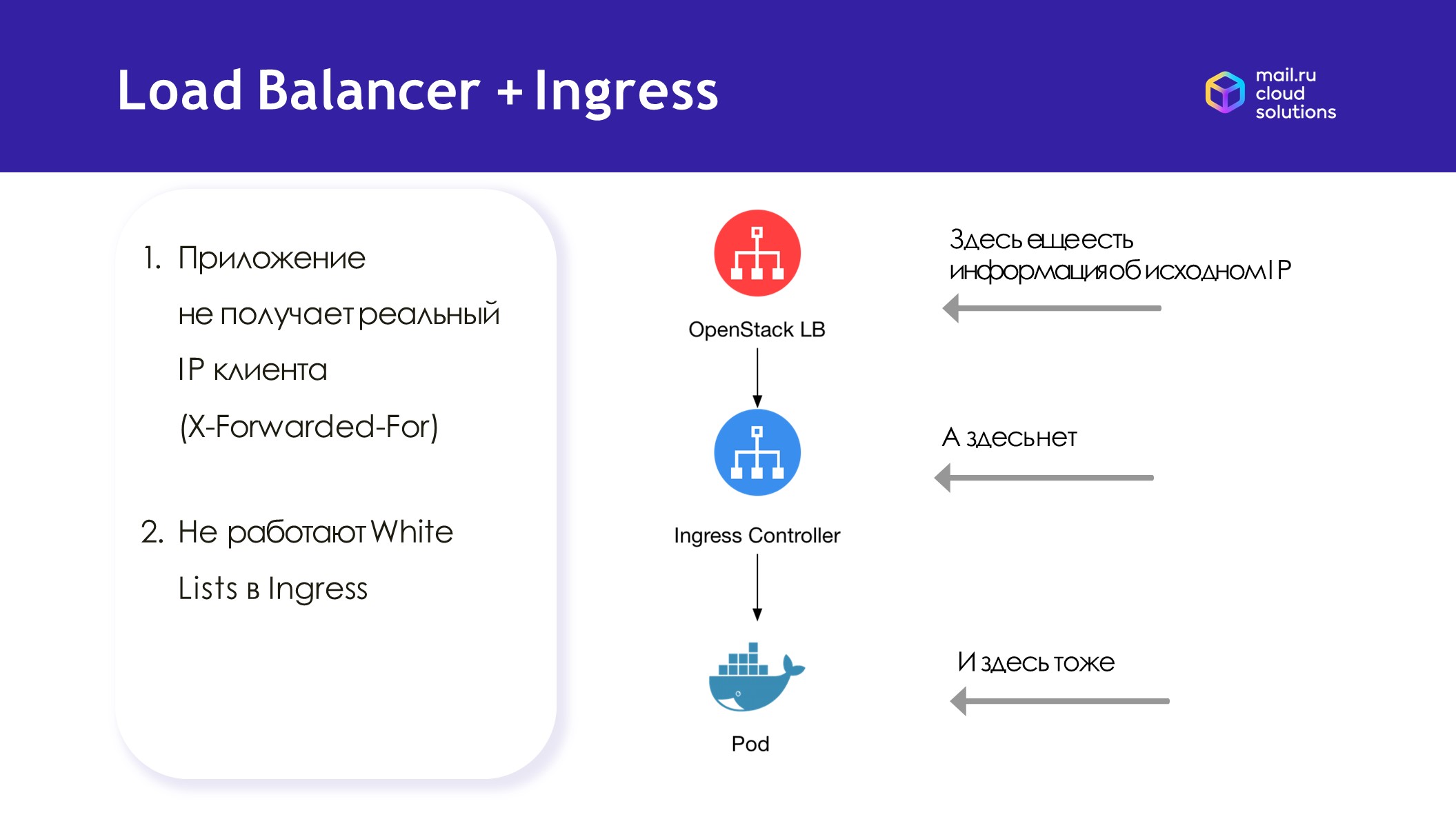
IP-адрес клиента не доходит до пода
И здесь у нас оказалось два решения:
Сделать режим proxy-протокола как в Amazon. Ради этой возможности мы перешли на балансировщик OpenStack Octavia, так как в стандартном балансировщике OpenStack нет такой опции. В итоге мы сделали новый балансировщик, который поддерживал как TCP-балансировку, так и HTTP с терминацией SSL.
При этом поддержку proxy-протокола нужно включать как на самом балансировщике (HAproxy), так и на Nginx Ingress Controller, который выступает таким приемником. Иначе схема пропускания трафика ломается. Также важно, что SSL-терминация, если у вас стандартный веб-трафик, должна проходить на Ingress:
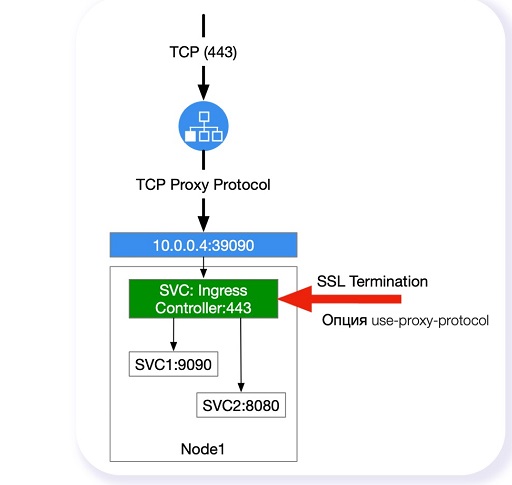
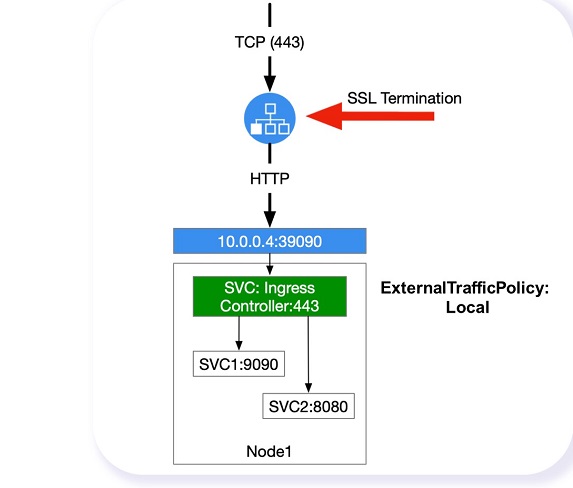
Терминация SSL на балансировщике. Здесь на балансер приходит HTTPS, он расшифровывается, и в кластер идет HTTP. Если всё это сделать и активировать в сервисе ExternalTrafficPolicy: Local, вы будете видеть заголовки IP-пакетов:
Storage и Kubernetes
Если разворачивать Kubernetes локально или в облаке просто на виртуальных машинах, то по умолчанию в нем нет нормальной работы с постоянными дисками. Можно использовать Host Path, Local volume (no-provisioner), либо прямо в кластере Kubernetes разворачивать экзотические программно-определяемые системы хранения типа Linstor или OpenEBS. Но что произойдет с данными или очередью данных, которая размещается в кластере, если умрет нода или под?
При самостоятельном подключении блочных устройств к кластеру есть проблемы: CSI-драйверы не идеальны для многих типов стораджей, и автоматическое перемонтирование может не произойти. Мы сделали работу с блочными устройствами автоматизированной. Чтобы при отключении пода блочное устройство переподключалось к новому поду само.
Мы используем Ceph. Главное, что они работают через OpenStack, который предоставляет специальные модули, абстрагирующие Kubernetes (или любые виртуальные машины, работающие в облаке), на конкретных драйверах — OpenStack Cinder.
У нас несколько разных storage-классов, которые работают в Kubernetes: SSD Ceph, HDD Ceph, геораспределенные Ceph между нашими ЦОДами. Есть storage-класс, отвечающий за блочные диски: фактически это дисковые шкафы с SSD, они подключаются к хост-машинам по iSCSI.
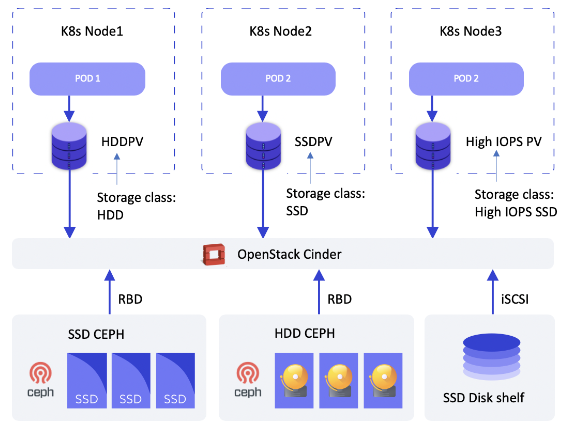
Несколько Storage-классов в MCS
При необходимости мы используем NFS, когда клиенты не могут переписать приложения в микросервисную архитектуру. У нас есть аналог сервиса EFS от Amazon — файловое хранилище с NFS-протоколом, доступное как сервис. Оно подходит, если у вас legacy-приложение, которое вы переводите в Kubernetes.
Кроме того, у нас есть локальные SSD, но здесь сложно гарантировать их доступность и переезд данных, поскольку они доступны только с физических серверов, к которым подключены.
Всё это подключается через единый модуль OpenStack — OpenStack Cinder, к каждой ноде Kubernetes и обеспечивает возможность переезда стораджа в случае падения ноды. А также когда повышается нагрузка чтения/записи и Kubernetes решает перевозить неважные поды на другие ноды — тогда он автоматически переводит монтирование этого диска к другим Kubernetes-нодам.
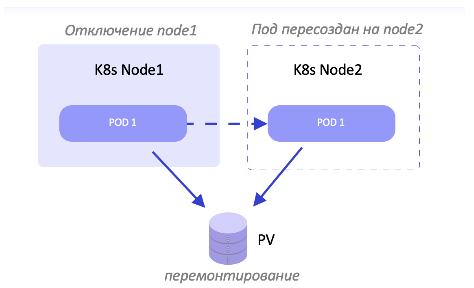
Так происходит автоматическое перемонтирование
Можно использовать storage class, написав декларации PersistentVolumeClaim. На примере, который изображён ниже, Cloud Provider выделит в заданной зоне доступности новый Persistent Volume, размером 30 ГБ с типом диска SSD, подключит его к ноде и примонтирует к подам. Также он будет следить, чтобы этот диск переезжал между нодами в случае переезда подов:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-pvc-ssd
spec:
accessModes:
-ReadWriteOnce
storageClassName: dp1-ssd
resources:
requests:
storage: 30Gi
Автоматическое масштабирование
В MCS есть Cluster Autoscaler. Это не просто автоскейлинг подов внутри кластера, а автоскейлинг самого кластера по необходимости: новые ноды добавляются, когда нагрузка выросла, и удаляются, если нагрузка упала. Масштабирование происходит автоматически — до 100 узлов и обратно за несколько минут.
Автоскейлинг позволяет для каждой группы узлов задать свои правила автомасштабирования, например максимальное и минимальное число нод, которое может задать автоскейлер.
Cluster Autoscaler лучше настраивать совместно с Horizontal Pod Autoscaler. Различие использования двух вариантов Autoscaler:
- Cluster Autoscaler позволяет расширять сами выделенные для кластера ресурсы. По сути он может автоматически арендовать дополнительные ресурсы или сократить их использование через Cloud Provider.
- Horizontal Pod Autoscaler позволяет расширять ресурсы подов в рамках существующих выделенных ресурсов кластера, чтобы оптимально их использовать.
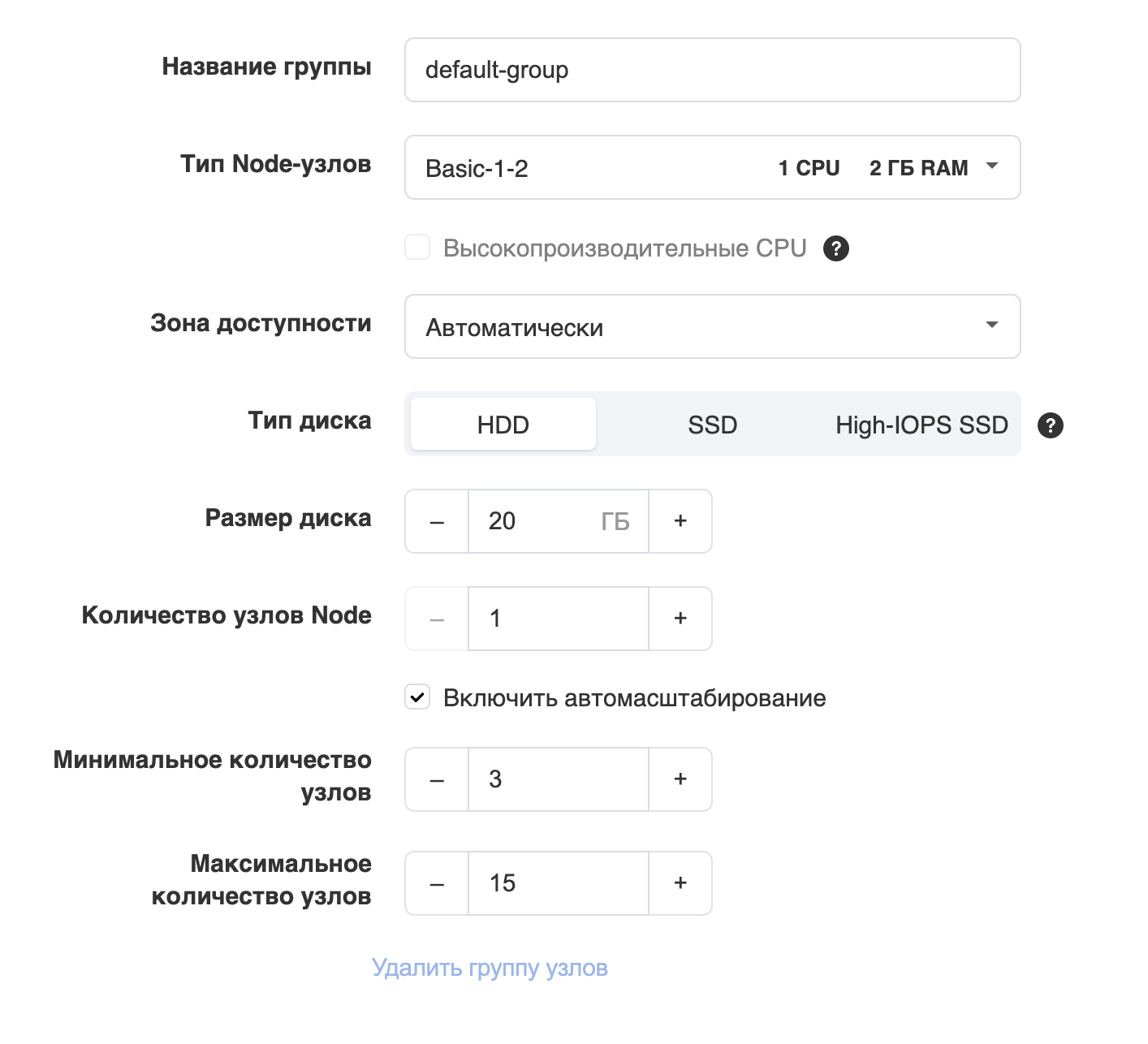
Настройка автоскейлинга
Функциональности
Совместимость со стандартными инструментами Kubernetes
Так как наш Kubernetes aaS полностью совместим со стандартным Kubernetes API, вы можете свободно пользоваться всеми возможностями экосистемы Kubernetes.
- Хранение и обработка serverless-функций в контейнерах: OpenFaaS, OpenWhisk, Kubeless.
- Инструменты Service Mesh: Istio, Consul, Linkerd.
- Мониторинг, аналитика, логирование: Prometheus, Fluentd, Jaeger, OpenTracing.
- CI/CD: Gitlab, CircleCI, Travis CI.
- IaC (описание приложений): Terraform, Helm.
И многие другие инструменты.
Про Terraform отдельно стоит сказать, что стандартный провайдер OpenStack не был полностью совместим с API платформы MCS, так что мы сделали собственный Terraform-провайдер, который полностью совместим с последней версией API MCS. Поддержка API включает:
- листинг ресурсов MCS (cluster, cluster template, node group)
- поддержку managed node groups
- поддержку действий через API: создание/удаление, горизонтальное и вертикальное масштабирование, включение/выключение кластера, обновление версии.
Безопасность
- Kubernetes использует аутентификацию по сертификатам.
- Систему безопасности кластеров можно интегрировать с LDAP/Active Directory для аутентификации пользователей. При этом ролевую модель безопасности в Kubernetes можно настроить на проверку прав доступа на основе принадлежности пользователя к группам в LDAP-каталоге.
- Для сетевой безопасности можно применять Calico Network Policy.
- В наш Kubernetes aaS интегрирован Docker Registry, защищённый SSL.
- Планируем реализовать SSO (single sign-on) в интеграции с нашим IAM (identity and access management) на уровне OpenStack.
Резервное копирование и миграция
- Мы поддерживаем интеграцию с Velero. Velero выполняет резервное копирование, которое позволяет бэкапить манифесты etcd и Persistent Volumes, вот гайд по тому, как это сделать.
- Также с помощью Velero можно мигрировать кластеры on-premises и других провайдеров на наш Kubernetes.
- Или запросите миграцию на наш Kubernetes «под ключ». Поможем.
Работа с большими данными
Kubernetes по сути можно использовать для любых микросервисных приложений, работающих с данными. Чем Kubernetes на платформе MCS интересен для data scientist’ов:
- Автомасштабирование позволяет выдерживать большие вычислительные нагрузки.
- Можно создавать событийные (event-triggered) обработчики данных.
- Приложения на Kubernetes легко интегрировать с другими нашими PaaS для Big Data, машинного обучения, в рамках одной сети.
- Если хочется поэкспериментировать, то для ускорения обучения к очереди событий или событийному обработчику на базе Kubernetes можно напрямую подключить GPU.
Ещё о нашем Kubernetes aaS
- Попробовать бесплатно наш Kubernetes aaS можно тут.
- В этих двух Telegram-каналах вас ждут новости нашего Kubernetes aaS и анонсы мероприятий @Kubernetes meetup.



iwram
Будет ли возможность кастомизации нод пользователем? Например, хочется поставить свой сборщик логов на уровне systemd, еще какой либо софт для сбора метрик с самой ноды и т.п.
ndal Автор
Мы движемся в сторону полностью Managed-решения, а это накладывает определенные ограничения на возможности пользователей в обмен на 100% доступность сервиса. Кастомизация будет за счет механизма сертифицированных аддонов (тех, которые мы тестируем и гарантируем работу). Наиболее типовые кейсы кастомизации (мониторинг, логирование, cert manager) будут запакованы в аддоны.