
Повод
Пару месяцев назад в рамках сотрудничества Amazon и Formula 1 исследователи «с использованием мощностей облачных технологий» выкатили сравнение скорости пилотов всех времен и народов (ссылка). Естественно, материал был рекламно-хайповый, и цели своей он достиг. Во всем формульном мире еще пару дней только и было разговоров в духе «а почему в рейтинге нет пилота N?» и «да как M может быть быстрее K, если K сделал его в сезоне L». Мне стало интересно более-менее повторить это исследование и, по возможности, обойтись без «всей мощи облачных технологий».

Задача
Но вернемся к постановке задачи. На скорость пилота в гонке влияет огромное число факторов. Личный талант, скорость болида, правильная стратегия, действия других пилотов, погода, аварии и многое другое. Такова специфика автоспорта. Поэтому для своего пробного шара специалисты AWS взяли много более простую задачу – сравнить скорость пилотов в квалификации. Квалификационные заезды изначально строятся таким образом, чтобы насколько это возможно уравнять внешние условия для соперников. Пилоту остается выжать максимум из своих возможностей и возможностей машины.
Как любят говорить в F1, пилот – это лишь 10% успеха в гонке, остальные 90% - машина и работа команды. Поэтому с хоть какой-то степенью достоверности можно сравнивать только напарников по команде между собой, т.к. это, в теории, нивелирует фактор машины. Здесь тоже всегда есть масса домыслов и слухов, что при необходимости команда может топить одного своего пилота, либо просто не иметь возможности привозить последние обновления сразу на обе машины и отдавать лучшее своему быстрейшему гонщику. Но, в рамках нашей задачи, будем считать болиды сокомандников одинаковыми.
Идея
В таком случае каждая квалификация для нас превращается в набор парных сравнений скорости пилотов в рамках каждой команды. К счастью, мир формульных гонок довольно мал, и «большие» пилоты успевают поездить сразу с несколькими напарниками в рамках разных команд. Таким образом, мы сможем получить сравнение 2 пилотов, никогда не выступавших в рамках одной команды, «через третьего» - пилота, с которым оба в разное время оказывались в одном коллективе. Тут так же есть очень серьезные допущения, которые портят малину. Это и допущение, что уровень пилота остается стабильным несколько лет подряд, и допущение, что машина всегда идеально подходит пилоту.
Еще один неприятный момент. Сравнить так уж прям всех пилотов за всю историю, к сожалению, не удастся. Даже используя все «попарные» мостики, не удастся добраться до всех пилотов, выступавших в Ф1. Возможны как отдельные пары пилотов, всю карьеру выступавшие только в одной команде друг с другом, так и более сложные закрытые кластера пилотов, не пилотировавшие ни с кем из общего кластера одновременно в одной команде.
Первое, что приходит в голову для решения этой задачи в очень упрощенном виде, что каждому пилоту в соответствие можно сопоставить некий коэффициент скорости kp, который проявляется в каждой квалификации.
Т.о. скорость прохождения круга в квалификации V = V0*kp*kc*Tr, где kc – такой же коэффициент скорости болида конкретной команды в конкретной гонке, а Tr – некая константа, характерная для трассы в конкретных условиях.
После серии преобразований можно вывести, что в каждой квалификации ln(ki)-ln(kj)=ln(tj)-ln(ti) для болидов гонщиков одной команды.
Получаем систему линейных уравнений. Систему довольно просто представить как матрицу m*(n+1), где n – число пилотов, m – суммарное число гонщиков в квалификациях. В каждой строке есть коэффициенты 1 и -1 в столбцах, соответствующих пилотам, и логарифм обратного отношения их времен в столбце свободных коэффициентов.
В отличие от специалистов AWS, мы посчитаем коэффициент динамически, считая, что он остается стабильным только в течение одного-двух лет. Для того, чтобы прокинуть мостик между соседними годами, искусственно внесем в таблицу результаты «из прошлого» - поменяем лишь год для пилота на предыдущий, остальные столбцы оставив неизменными. Т.о. мы получим «замыленные» на перспективу 2 лет данные для каждого пилота и поставим его прошлого к ему теперешнему в напарники с 0 разницей в скорости.
Более того, по похожей схеме посчитаем и рейтинг болидов F1. Год от года в связи с изменением правил и техническим прогрессом машины меняются. Последние годы регламент составляется так, что в начале года команда выставляет новую машину, большую часть года ее дорабатывает, а на следующий год вынуждена делать машину, подходящую под новый регламент. Понять, насколько прогрессирует машина по ходу году довольно сложно, поэтому допустим, что она более-менее стабильна.
Здесь мы будем фиксировать пилота и трассу и смотреть, насколько на одной машине он прошел ее быстрее, чем на другой в перспективе 2 лет. У этого подхода есть 3 больших минуса. 1 – машина может быть быстрой, но не подходить пилоту. Мы же увидим, что она «хуже». Второй – трассы постоянно ротируются. Добавляются новые, уходят либо перестраиваются старые. Нам же для этого подхода нужен некоторый набор стабильных трасс. И третий – дождь. Если в один год он был, а в другой нет, то мы можем списать это на скорость машины.
Решение
Данные квалификаций спарсим из Википедии, откуда еще. Формат квалификации менялся много раз, в разные периоды она состояла из 1, 2 и как теперь 3 фаз. Хоть это и не до конца верно, будем считать, что итоговое время пилота было показано в последней доступной фазе квалификации.
import sys
import re
import urllib.request
def get_wikipedia_page(title, lang='en'):
url = 'https://'+lang+'.wikipedia.org/wiki/'+(title.replace(' ', '_'))
fp = urllib.request.urlopen(url)
mybytes = fp.read()
mystr = mybytes.decode("utf8")
fp.close()
return mystr
title = 'List of Formula One Grands Prix'
try:
print('process: '+title)
th = get_wikipedia_page(title)
r1 = re.findall(r'href="/wiki/[\d][\d][\d][\d]_[\w]*_Grand_Prix"',th)
list_of_GP = list(set(r1))
except:
print("Unexpected error:", sys.exc_info()[0])
titles = list(map(lambda x: x[12: -1].replace('_', ' '), list_of_GP))
for title in titles:
try:
print('process: '+title)
th = get_wikipedia_page(title)
with open('texts/'+title+'.txt', 'w', encoding='utf8') as the_file:
the_file.write(th)
the_file.close()
except:
print("Unexpected error:", sys.exc_info()[0])Из полученных html файлов регулярками выпарсим квалификационные таблицы. Также слегка стандартизируем текстовую часть данных. Приведем названия треков к одному виду (иногда встречаются несколько написаний одного и того же трека), сохраним его длину (это поможет различить разные версии одного и того же трека), поудаляем цифры и прочий «мусор» из имен пилотов. Сохраним итоговые данные в удобную csv.
Считаем полученный DataFrame. Создадим несколько столбцов, которые сильно нам помогут в дальнейшем:
Название трека + его длина. Этоот столбец нам понадобится, чтобы не путать разные версии одного и того же автодрома
Имя пилота + год – будем считать, что в течение 1 года пилот сохраняет один и тот же уровень формы, в течение 2 лет изменяет его незначительно
Машина = Конструктор + год. Вообще говоря, это не очень верно. На заре автоспорта производители могли использовать несколько разных версий машины в одном чемпионате и наоборот, несколько лет подряд использовать одну и ту же машину. Сейчас топ-команды умудряются привозить несколько крупных обновлений аэродинамики за год, малые команды пользуются этим реже.
qual_df = pd.read_csv('qual_results.csv')
qual_df['Track_pl_len'] = qual_df['Track'] + '_' +qual_df['Track_len'].apply(str)
qual_df['Car'] = qual_df['Constructor'] + '_' +qual_df['Year'].apply(str)
qual_df['Driver_pl_year'] = qual_df['Driver']+'_'+qual_df['Year'].apply(str)
qual_df_2 = qual_df.copy()
qual_df_2['Driver_pl_year'] = qual_df_2['Driver']+'_'+((qual_df_2['Year'].apply(int)-1)).apply(str)
double_df = pd.concat([qual_df, qual_df_2])
del qual_df2Также создадим искусственный датафрейм. Скопируем основной датафрейм, но каждому пилоту присвоим прошлый год вместо текущего. Этот датафрейм сольем с основным. Таким образом для любых методов, если группироваться по пилоту, мы удваиваем информацию. Плюс явно говорим, что уровень формы не уходит за год, а изменяется довольно плавно. Полученный удвоенный датафрейм будем использовать в дальнейших расчетах.
А дальше произведем небольшую манипуляцию с данными. Произведем 2 раза для разных рейтингов, но подробно разберу для рейтинга пилотов.
Посчитаем логарифм из времени на круге
Разность логарифмов времен на квалификационном круге двух сокомандников равна обратной разности логарифмов коэффициентов их скорости, т.к. все остальные переменные считаем одинаковыми и зафиксированными
Соответственно, просто мерджим 2 одинаковых датафрейма между собой по машине и гонке – и получаем большую простыню нужных нам попарных сравнений
Фильтруем полученный датасет, чтобы каждый «мостик» из сравнения двух пилотов был достаточно «надежен» - я выставил лимит в 6 и более совместных квалификаций и разницу в скорости не более 2%. Также оставляем только пилотов, отметившихся в «главной» линии пилотов Ф1 – в той, что были основные чемпионы. Некоторое количество пилотов просто не пересекались с ними ни через кого в одной команде, поэтому узнать их скорость этим методом невозможно
Выворачиваем 2 столбца с именами пилотов One Hot Encoding так, чтобы пилот x оказался с коэффициентом = 1 в столбце со своей фамилией, пилот y с -1
И запускаем линейную регрессию, она в данном случае не выбрасывает огромные коэффициенты даже без регуляризации. Единственное, что мы сделали – удалили столбец с ровно 1 пилотом, т.е. искусственно присвоили ему коэффициент скорости 1, логарифм 0. Все остальные пилоты будут выстраиваться относительно него – выше или ниже
Вытаскиваем посчитанные коэффициенты линейной регрессии. По нашей задумке они будут равны ln(k) - логарафму от коэффициента скорости пилота.
Очень похожее действие провернем и для машин, которые будем наоборот сравнивать на одних и тех же трассах с одним и тем же пилотом за рулем.
Результаты
Прежде чем подводить итоги по тому методу, по которому считал я, хочу все же показать результаты «карьерного» измерения, т.е. то, что презентовали F1 и Amazon.
Немного поигравшись с параметрами запуска, на тех же данных удалось получить следующую таблицу:
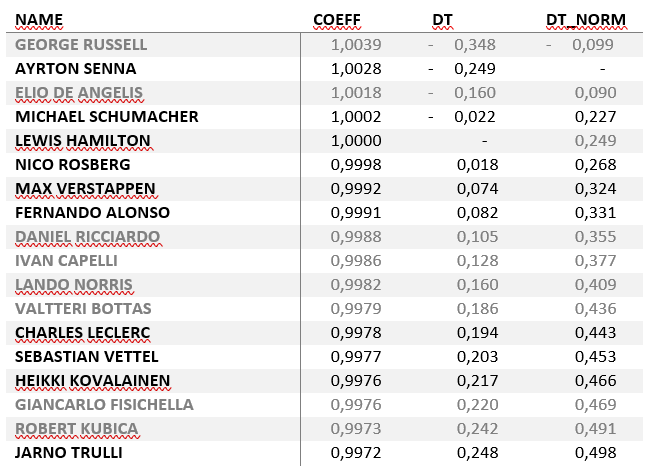
Последний столбец пересчитал исходя из того, чтобы точкой отсчета был Сенна
Это 18 первых пилотов, если составлять рейтинг без учета динамики по ходу карьеры. Опять же, параметров довольно много + ошибки парсинга + оговорки, какое время брать в многоуровневых квалификациях. Серым я затемнил пилотов, которых нет в официальной лучшей 10. Если их не учитывать, то рейтинги очень похожи. Все те же люди на похожих расстояниях. Ниже Ферстаппен, выше Феттель.
Самое интересное здесь – как в топе появился перспективный дебютант Рассел. Появился за счет 2019 года, в котором разнес вернувшегося после кучи пропущенных лет и тяжелейшей травмы некогда быстрого поляка Роберта Кубицу. Роберт весь год жаловался на машину, воевал с командой и на следующий год ушел из Ф1.
Сравнивать с ним Рассела – некорректно. Столь длинное отсутствие не могло не сказаться на форме Кубицы. В сравнении же мы считаем, что это одинаково быстрый пилот. Видимо, так же посчитали аналитики Ф1 и подчистили рейтинг. Как из него исчезли сверстабильные Боттас и Риккьярдо для меня загадка. Много лет в Ф1, точно пересекались с Хэмильтоном и Ферстаппеным и смотрелись/смотрятся на их фоне отлично.
А вот что получается, если построить рейтинг год к году:
N | Driver | Total min |
1 | Ayrton Senna | - 0,435 |
2 | Michael Schumacher | - 0,408 |
3 | Alain Prost | - 0,289 |
4 | Damon Hill | - 0,037 |
5 | Lewis Hamilton | - 0,037 |
6 | Charles Leclerc | 0,016 |
7 | Rubens Barrichello | 0,024 |
8 | Fernando Alonso | 0,067 |
9 | Nico Rosberg | 0,081 |
10 | Nigel Mansell | 0,102 |
11 | Carlos Pace | 0,117 |
12 | Mika Hakkinen | 0,145 |
13 | Max Verstappen | 0,147 |
14 | Valtteri Bottas | 0,153 |
15 | Elio de Angelis | 0,164 |
16 | Daniel Ricciardo | 0,165 |
17 | Jarno Trulli | 0,172 |
18 | Giancarlo Fisichella | 0,184 |
И расширить его в перспективе времени (для всех пилотов здесь первый отмеченный год предваряет дебют или возвращение после перерыва, т.е. фактически в Ф1 пилота еще не было):
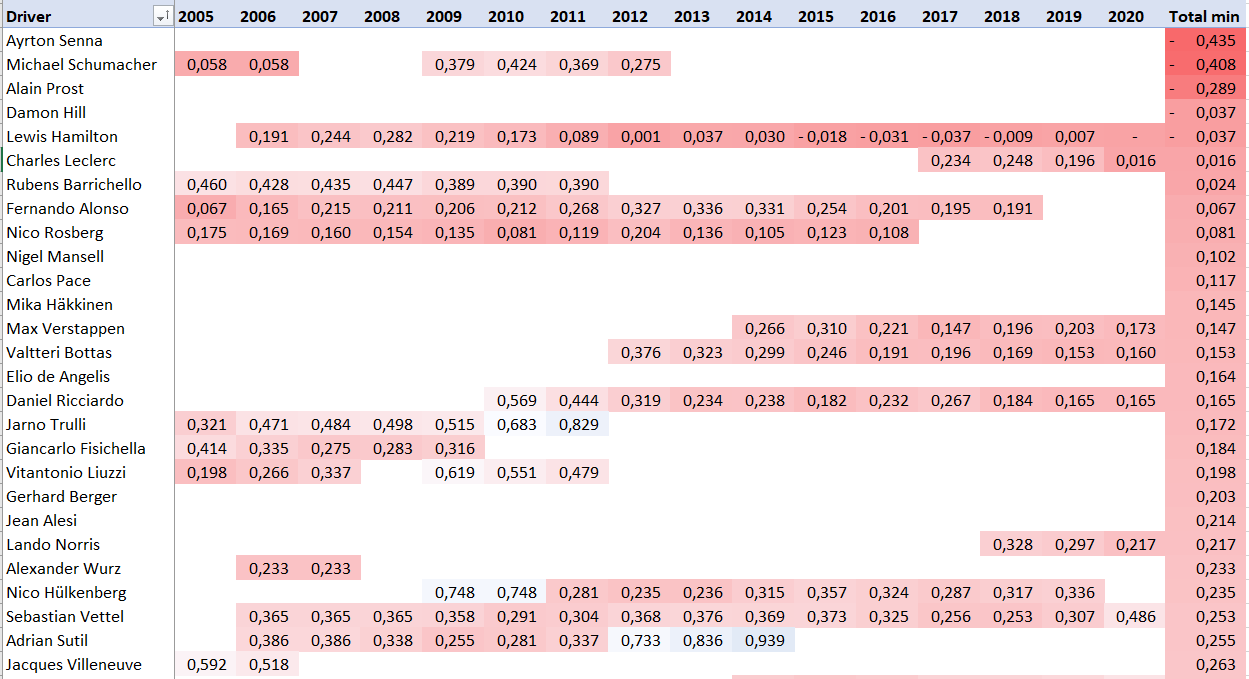
Можно в разрезе каждого года выступлений смотреть, какой гонщик был в наибольшей квалификационной форме.
И такой же рейтинг для машин:
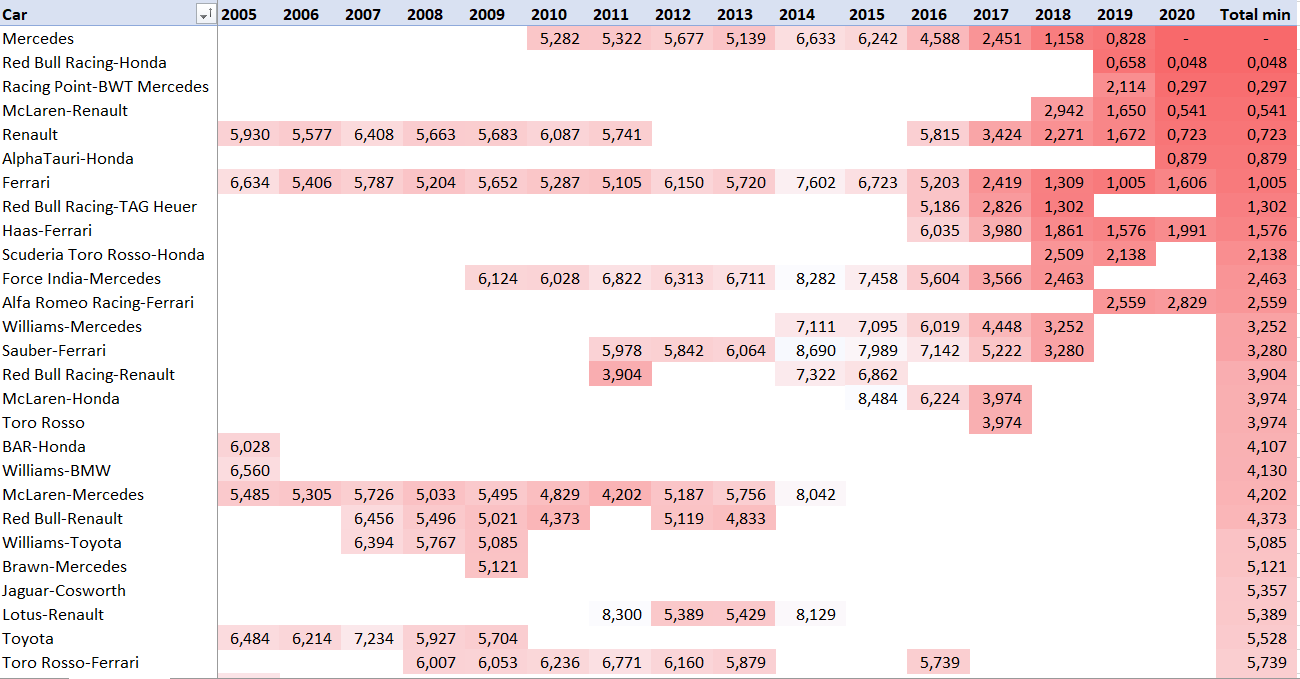
Мерседес 2020 года – быстрейшая машина не только чемпионата, но и за всю историю (формально – с 1979 года, дальше проследить связи между конкретными машинами тяжело ввиду изменений в календаре).
На графике бросается в глаза, как Renault сбросило секунду за счет нового двигателя не только на заводских машинах, но и на клиентах. Невероятно быстрый Racing Point, сбросивший почти 2 сек за межсезонье, Alpha Tauri 2020, неприлично похожая на Red Bull 2019 и провал двигателя Ferrari 2020, из-за которого команда откатилась на уровень 2018 года вместе со своими клиентами.
Интересно, что по этой графике быстрейшей машиной 2019 года была не Mercedes, которая взяла 10 поулов, а Red Bull и только более быстрый Хэмилтон позволял команде завоевывать поулы и титул. Леклер же, который взял поулов больше, чем Хэмилтон и Боттас каждый, творил просто чудеса, не вписывающиеся в модель.
Здесь во всей красе проявляется несовершенство самого метода попарных сравнений. Если у пилота есть длительные периоды стабильных выступлений с одним и тем же сокомандником, построить по нему статистику крайне тяжело. Сравнения получаются через много-много лет и пилотов, а каждое лишнее звено добавляет неточности. То же самое касается рейтинга машин. Чудо, что он вообще строится и выглядит адекватно.
Поскольку абсурдность и низкое качество полученной модели уже понятны, приложу ее предсказания на предстоящий этап в Имоле (результаты Уильямсов предсказать не получится, т.к. в команде 2 молодых пилота, не пересекавшихся с остальными пилотами в Ф1):
Driver | Car | Time_predicted_sec |
Lewis Hamilton | Mercedes | 77,711 |
Valtteri Bottas | Mercedes | 77,850 |
Max Verstappen | Red Bull Racing-Honda | 78,252 |
Lando Norris | McLaren-Renault | 78,324 |
Sergio Perez | Racing Point-BWT Mercedes | 78,345 |
Lance Stroll | Racing Point-BWT Mercedes | 78,439 |
Daniel Ricciardo | Renault | 78,451 |
Carlos Sainz Jr. | McLaren-Renault | 78,549 |
Esteban Ocon | Renault | 78,665 |
Alexander Albon | Red Bull Racing-Honda | 78,878 |
Pierre Gasly | AlphaTauri-Honda | 78,985 |
Daniil Kvyat | AlphaTauri-Honda | 79,108 |
Charles Leclerc | Ferrari | 79,116 |
Sebastian Vettel | Ferrari | 79,531 |
Romain Grosjean | Haas-Ferrari | 79,656 |
Kevin Magnussen | Haas-Ferrari | 79,738 |
Kimi Raikkonen | Alfa Romeo Racing-Ferrari | 80,399 |
Antonio Giovinazzi | Alfa Romeo Racing-Ferrari | 80,658 |
Выводы
Формула 1 и Amazon добились своей цели и привлекли внимание к себе. Так же они подкинули интересную задачку: как разделить влияние пилота и машины в таком своеобразном виде спорта.
Есть ощущение, что уровень упрощения, на который пошли авторы оригинального исследования, заставил их сильно фильтровать исходные данные / результаты, чтобы получить рейтинг, который всех устроит.
В задаче оказалось больше подводных камней, чем казалось сначала. Дожди, поломки, неравнозначность сезонов и болидов – чего только не встречалось за 70 лет истории Ф1. И чудо, что большая часть этих данных оцифрована и доступна для ознакомления и обработки.
Приличной регрессии построить так и не удалось, вроде бы беспроблемная модель все равно подкидывает неожиданные результаты. Все попытки построить единую модель, учитывающую одновременно влияние машины и пилота, пришли к необходимости жесткой регуляризации.
К статье прикладываю гитхаб с исходными данными и сводными таблицами для самостоятельного изучения, код добавлю, как только мне будет за него не так стыдно.
Redrik05
Ну думаю, что подобное сравнение пилотов уместно, когда болиды каждый год меняют
в маркетинговый целях самое оно. Согласен!
molec Автор
В том и суть. Берем пары пилотов, которые выступают на одной машине и на одной трассе. Смотрим, кто быстрее. Прокидываем сквозь года — в теории должны получить рейтинг всех времен и народов, который игнорирует разницу в машинах.
Imenem
Осталось научиться игнорировать разницу в скорости пилотов из-за:
1. Машины, которая не подходит стилю одного из гонщиков. Пример из текущего сезона: Феттель/Леклер в Феррари. Проблемы Феррари со стабильностью задней части из-за неудачной подвески, настройки которой плавают в зависимости от температуры жидкости. Леклер смог к этому адаптироваться, а Феттель — нет. В итоге Феттель на 0.5 секунды медленнее. Можно еще взять любого партнера Алонсо после Хэмильтона, машины всегда строились именно под Алонсо.
2. Новой, незнакомой машины. Пример из прошлого: когда Хэмильтон пришел в Мерседес, он долго не мог использовать тормоза на 100%, потому что ощущения от них сильно отличались от тормозов Макларен. В то же время Росберг к тому времени был в команде давно и к тормозам привык. В тот сезон Нико был быстрее, но зато на следующий Льюис уже привык к машине и опережал.
Даже в моносерии не получится легко и просто сравнить пилотов, потому что машины нужно настраивать и не все команды могут правильно попасть в настройки.
molec Автор
Безусловно, подходит — не подходит самая тяжелая вещь. Вроде бы 100% она существует, но как ее отделить от снижения формы/мотивации — ума не приложу. Честно — так и не смог сделать даже более простого: разделить все машины на «аэродинамические» и «прижимные». В теории все просто — делим трассы на медленные и быстрые. Какие машины выделяются на медленных — прижимные, на быстрых — аэродинамические. Но не все так просто :)