
Использование CUDA Runtime API для вычислений. Сравнение CPU и GPU вычислений
В данной статье я решил провести сравнение выполнения алгоритма написанного на C++ на центральном и графическом процессоре(выполнение вычислений с помощью Nvidia CUDA Runtime API на поддерживаемом GPU Nvidia). CUDA API позволяет выполнение некоторых вычислений на графическом процессоре. Файл c++ использующий cuda, будет иметь расширение .cu.
Схема работы алгоритма приведена ниже.
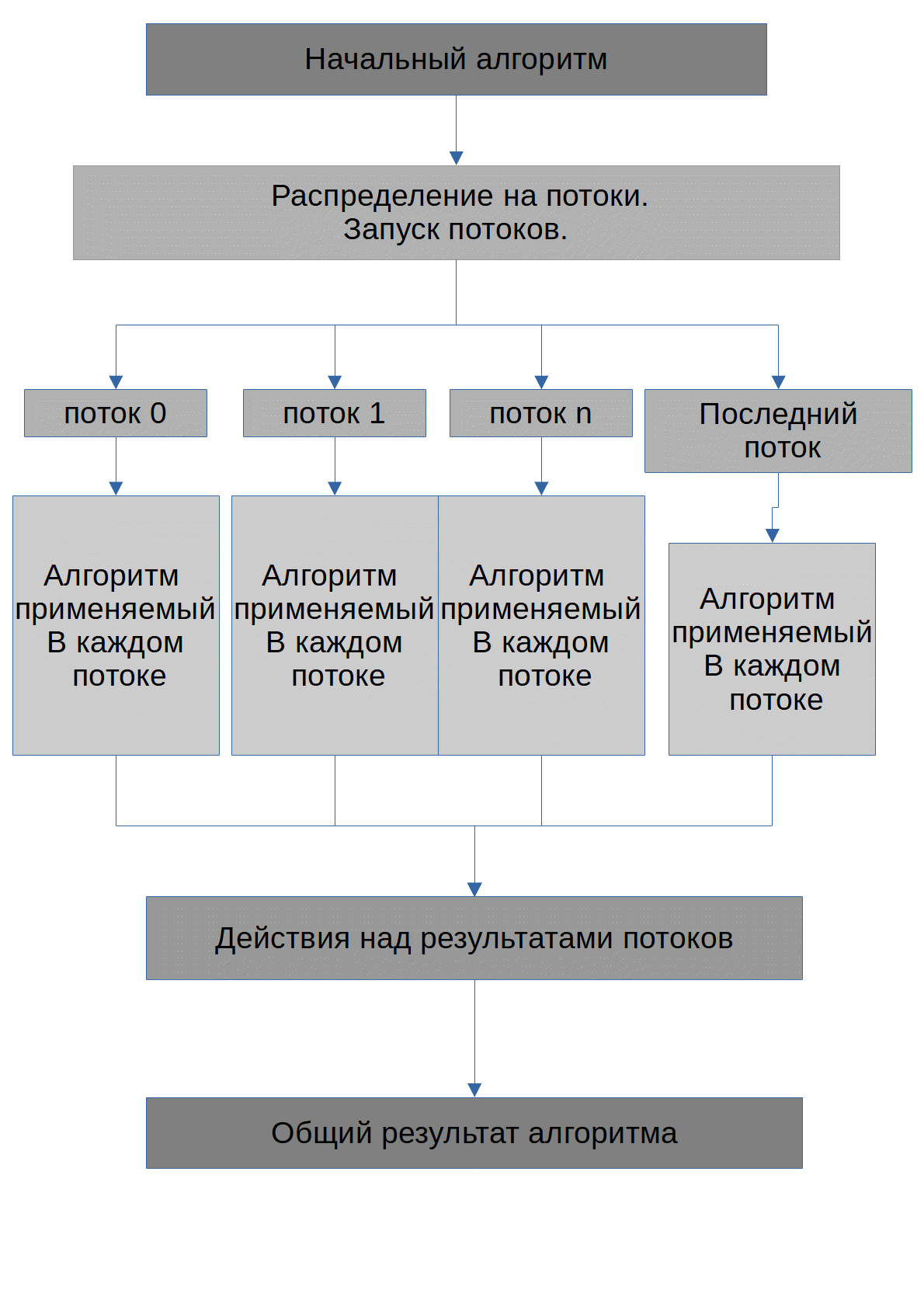
Задача алгоритма состоит в том, что найти возможные числа X, при возведении которых в степень degree_of, будет получатся исходное число max_number. Сразу отмечу, что все числа которые будут передаваться GPU, будут хранится в массивах. Алгоритм, выполняемый каждым потоком, имеет приблизительно следующий вид:
int degree_of=2;
int degree_of_max=Number_degree_of_max[0];//Массив хранящий значение максимальной степени числа
int x=thread;//номер выполняемого потока
int max_number=INPUT[0];//Массив хранящий число, которое необходимо получить
int Number=1;
int Degree;
bool BREAK=false;//Переменная для завершения while
while(degree_of<=degree_of_max&&!BREAK){
Number=1;
for(int i=0;i<degree_of;i++){
Number*=x;
Degree=degree_of;
}
if(Number==max_number){
OUT_NUMBER[thread]=X;//OUT_NUMBER Массив хранящий числа которые необходимо возвести в степень Degree для получения исходного числа
OUT_DEGREE[thread]=Degree;// OUT_DEGREE Массив хранящий степень в которую нужно возвести число X для получения исходного числа
}
degree_of++;
//В случае выхода за предел :
if(degree_of>degree_of_max||Number>max_number){
BREAK=true;
}
}
Код для выполнения на CPU C++.cpp
#include <iostream>
#include<vector>
#include<string>//необходимо для getline
#include<thread>
#include<fstream>
using namespace std;
int Running_thread_counter = 0;
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD);
void Upload_to_CPU(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int THREAD) {
int thread = THREAD;
Running_thread_counter++;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long DEGREE_OF = 2;
unsigned long long INP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X != 0 && X != 1) {
while (!BREAK) {
if (DEGREE_OF <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < DEGREE_OF; counter++) {
Calculated_number *= X;
}
if (Calculated_number == INP) {
Stepn[thread] = DEGREE_OF;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
DEGREE_OF++;
}
else { BREAK = true; }
}
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size);
int main()
{
int size = 1000;
unsigned long long *Number = new unsigned long long[size], *Degree_of = new unsigned long long[size];
unsigned long long *Max_Degree_of = new unsigned long long[1];
unsigned long long *INPUT_NUMBER = new unsigned long long[1];
Max_Degree_of[0] = 7900;
INPUT_NUMBER[0] = 216 * 216 * 216;
ifstream inp("input.txt");
if (inp.is_open()) {
string t;
vector<unsigned long long>IN;
while (getline(inp, t)) {
IN.push_back(stol(t));
}
INPUT_NUMBER[0] = IN[0];//исходное число
Max_Degree_of[0] = IN[1];//значение максимальной степени
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error << "No file " << '"' << "input.txt" << '"' << endl;
error << "Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_Degree_of[0] = 1;
}
}
// раскомментируйте следующий код , если хотите видеть исходные значения в окне консоли
//cout << INPUT[0] << endl;
bool *Elements_that_need_to_stop = new bool[size];
Parallelize_to_threads(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_Degree_of, size);
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
if (Degree_of[i] < INPUT_NUMBER[0] && Number[i] < INPUT_NUMBER[0]) {//проверка на ошибки
NUMBER.push_back(Number[i]);
DEGREEOF.push_back(Degree_of[i]);
}
}
}
// раскомментируйте следующий код , если хотите вывести результаты в консоль
//это может замедлить программу
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
}
void Parallelize_to_threads(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max, int size) {
thread *T = new thread[size];
Running_thread_counter = 0;
for (int i = 0; i < size; i++) {
T[i] = thread(Upload_to_CPU, Number, Stepn, Stop, INPUT, max, i);
T[i].detach();
}
while (Running_thread_counter < size - 1);//дождаться завершения выполнения всех потоков
}
Для работы алгоритма необходим текстовый файл с исходным числом и максимальной степенью.
Код для выполнения вычислений на GPU C++.cu
//библиотеки cuda_runtime.h и device_launch_parameters.h
//для работы с cyda
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<vector>
#include<string>//для getline
#include <stdio.h>
#include<fstream>
using namespace std;
__global__ void Upload_to_GPU(unsigned long long *Number,unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT,unsigned long long *max) {
int thread = threadIdx.x;
unsigned long long MAX_DEGREE_OF = max[0];
int X = thread;
unsigned long long Calculated_number = 1;
unsigned long long Current_degree_of_number = 2;
unsigned long long Original_numberP = INPUT[0];
Stop[thread] = false;
bool BREAK = false;
if (X!=0&&X!=1) {
while (!BREAK) {
if (Current_degree_of_number <= MAX_DEGREE_OF) {
Calculated_number = 1;
for (int counter = 0; counter < Current_degree_of_number; counter++) {
Calculated_number *=X;
}
if (Calculated_number == Original_numberP) {
Stepn[thread] = Current_degree_of_number;
Number[thread] = X;
Stop[thread] = true;
BREAK = true;
}
Current_degree_of_number++;
}
else { BREAK = true; }
}
}
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Stepn, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size);
int main()
{
int size = 1000;
unsigned long long *Number=new unsigned long long [size], *Degree_of=new unsigned long long [size];
unsigned long long *Max_degree_of = new unsigned long long [1];
unsigned long long *INPUT_NUMBER = new unsigned long long [1];
Max_degree_of[0] = 7900;
ifstream inp("input.txt");
if (inp.is_open()) {
string text;
vector<unsigned long long>IN;
while (getline(inp, text)) {
IN.push_back( stol(text));
}
INPUT_NUMBER[0] = IN[0];
Max_degree_of[0] = IN[1];
}
else {
ofstream error("error.txt");
if (error.is_open()) {
error<<"No file "<<'"'<<"input.txt"<<'"'<<endl;
error<<"Please , create a file" << '"' << "input.txt" << '"' << endl;
error << "One read:input number" << endl;
error << "Two read:input max stepen" << endl;
error << "." << endl;
error.close();
INPUT_NUMBER[0] = 1;
Max_degree_of[0] = 1;
}
}
bool *Elements_that_need_to_stop = new bool[size];
// Загрузка массивов в cuda
cudaError_t cudaStatus = Configure_cuda(Number, Degree_of, Elements_that_need_to_stop, INPUT_NUMBER, Max_degree_of, size);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
vector<unsigned long long>NUMBER, DEGREEOF;
for (int i = 0; i < size; i++) {
if (Elements_that_need_to_stop[i]) {
NUMBER.push_back(Number[i]);//занести в вектор число
DEGREEOF.push_back(Degree_of[i]);//занести в вектор степень числа
}
}
//раскоментируйте следующий код , чтобы вывести результаты в консоль
/*
for (int f = 0; f < NUMBER.size(); f++) {
cout << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}*/
ofstream out("out.txt");
if (out.is_open()) {
for (int f = 0; f < NUMBER.size(); f++) {
out << NUMBER[f] << "^" << DEGREEOF[f] << "=" << INPUT_NUMBER[0] << endl;
}
out.close();
}
//Очистить ресурсы связанные с устройством
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
cudaError_t Configure_cuda(unsigned long long *Number, unsigned long long *Degree_of, bool *Stop,unsigned long long *INPUT, unsigned long long *max,unsigned int size) {
unsigned long long *dev_Number = 0;
unsigned long long *dev_Degree_of = 0;
unsigned long long *dev_INPUT = 0;
unsigned long long *dev_Max = 0;
bool *dev_Elements_that_need_to_stop;
cudaError_t cudaStatus;
// УСТАНОВКА ИСПОЛЬЗУЕМОГО GPU
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// РЕЗЕРВИРОВАНИЕ МЕСТА В ПАМЯТИ ПОД ДАННЫЕ
cudaStatus = cudaMalloc((void**)&dev_Number, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Number");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Degree_of, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Degree_of");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Max, size * sizeof(unsigned long long int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Max");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_INPUT, size * sizeof(unsigned long long));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_INPUT");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_Elements_that_need_to_stop, size * sizeof(bool));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!dev_Stop");
goto Error;
}
// ПЕРЕМЕЩЕНИЕ ДАННЫХ В ПАМЯТЬ GPU
cudaStatus = cudaMemcpy(dev_Max, max, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_INPUT, INPUT, size * sizeof(unsigned long long), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Upload_to_GPU<<<1, size>>>(dev_Number, dev_Degree_of, dev_Elements_that_need_to_stop, dev_INPUT, dev_Max);
// Проверка сбоев ядра
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// Ожидание завершения операций , выполняемых ядром
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Перемещение данных из памяти GPU в системную память
cudaStatus = cudaMemcpy(Number, dev_Number, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Degree_of, dev_Degree_of, size * sizeof(unsigned long long), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(Stop, dev_Elements_that_need_to_stop, size * sizeof(bool), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error://Освобождение памяти GPU от данных
cudaFree(dev_INPUT);
cudaFree(dev_Degree_of);
cudaFree(dev_Max);
cudaFree(dev_Elements_that_need_to_stop);
cudaFree(dev_Number);
return cudaStatus;
}
Идентификатор
__global__ Для работы с CUDA API, перед вызовом функции, нужно зарезервировать память под массив и перенести элементы в память GPU. Это увеличивает объем кода, но позволяет разгрузить CPU, так как вычисления производятся на GPU.Поэтому ,cuda, дает как минимум возможность разгрузить процессор для выполнения других нагрузок, не использующих cuda.
В случае примера на cuda, задача процессора заключается лишь в загрузке инструкций на GPU и обработке результатов пришедших с GPU; В то время как в коде для CPU, процессор обрабатывает каждый поток. Стоит отметить, что cyda имеет ограничения по количеству запускаемых потоков, поэтому в обоих алгоритмах я взял одинаковое количество потоков, равное 1000. Также, в случае с CPU я использовал переменную
int Running_thread_counter = 0;чтобы считать количество уже выполненных потоков и дожидаться, пока все потоки не выполнятся.
Тестируемая конфигурация
Сведения о CUDA были взяты из GPU-Z
- CPU :amd ryzen 5 1400(4core,8thread)
- ОЗУ:8гбDDR4 2666
- GPU:Nvidia rtx 2060
- OS:windows 10 version 2004
- Cuda:
- Compute Capability 7.5
- Threads per Multiprocessor 1024
- CUDA 11.1.70
- GPU-Z:version 2.35.0
- Visual Studio 2017
Сведения о CUDA были взяты из GPU-Z
Для тестирования алгоритма я использовал
следующий код на C#
, который создавал файл с исходными данными, затем последовательно запускал exe файлы алгоритмов использующих CPU или GPU и замерял время их работы, затем заносил это время и результаты работы алгоритмов в файл result.txt. Для замера загруженности процессора использовался диспетчер задач windows.using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.IO;
namespace ConsoleAppTESTSTEPEN_CPU_AND_GPU_
{
class Program
{
static string Upload(Int64 number,Int64 degree_of)
{
string OUT = "";
string[] Chord_values = new string[2];
Int64 Degree_of = degree_of;
Int64 Number = number;
Chord_values[0] = Number.ToString();
Chord_values[1] = Degree_of.ToString();
File.WriteAllLines("input.txt", Chord_values);//файл входных данных
OUT+="input number:" + Number.ToString()+"\n";
OUT+="input degree of number:" + Degree_of.ToString()+"\n";
DateTime running_CPU_application = DateTime.Now;//записать время запуска программы
Process proc= Process.Start("ConsoleApplication29.exe");//exe реализация алгоритма на c++ x64 использующая CPU для вычислений
while (!proc.HasExited) ;//дождаться завершения программы
DateTime stop_CPU_application = DateTime.Now;//записать время остановки программы
string[]outs = File.ReadAllLines("out.txt");//получить результаты
File.Delete("out.txt");
OUT+="CPU:"+"\n";
if (outs.Length>0)
{
for (int j = 0; j < outs.Length; j++)
{
OUT+=outs[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_CPU_application:" + running_CPU_application.ToString()+"\n";
OUT+="stop_CPU_application:" + stop_CPU_application.ToString()+"\n";
OUT+="GPU:"+"\n";
//альтернативные действия для реализации алгоритма korenXN.exe x64 использующего для вычислений GPU
DateTime running_GPU_application = DateTime.Now;
Process procGPU = Process.Start("korenXN.exe");
while (!procGPU.HasExited) ;
DateTime stop_GPU_application = DateTime.Now;
string[] outs2 = File.ReadAllLines("out.txt");
File.Delete("out.txt");
if (outs2.Length > 0)
{
for (int j = 0; j < outs2.Length; j++)
{
OUT+=outs2[j]+"\n";
}
}
else { OUT+="no values"+"\n"; }
OUT+="running_GPU_application:" + running_GPU_application.ToString()+"\n";
OUT+="stop_GPU_application:" + stop_GPU_application.ToString()+"\n";
return OUT;//возвратить результат
}
static void Main()
{
Int64 start = 36*36;//начальное значение входного числа
Int64 degree_of_strat = 500;//начальное значение максимальной степени
int size = 20-5;//количество элементов в массиве
Int64[] Number = new Int64[size];//массив входных чисел
Int64[] Degree_of = new Int64[size];//массив максимальных степеней
string[]outs= new string[size];//массив результатов
for (int n = 0; n < size; n++)
{
if (n % 2 == 0)
{
Number[n] = start * start;
}
else
{
Number[n] = start * degree_of_strat;
Number[n] -= n + n;
}
start += 36*36;
Degree_of[n] = degree_of_strat;
degree_of_strat +=1000;
}
for (int n = 0; n < size; n++)
{
outs[n] = Upload(Number[n], Degree_of[n]);
Console.WriteLine(outs[n]);
}
System.IO.File.WriteAllLines("result.txt", outs);//записать результаты в файл result.txt
}
}
}
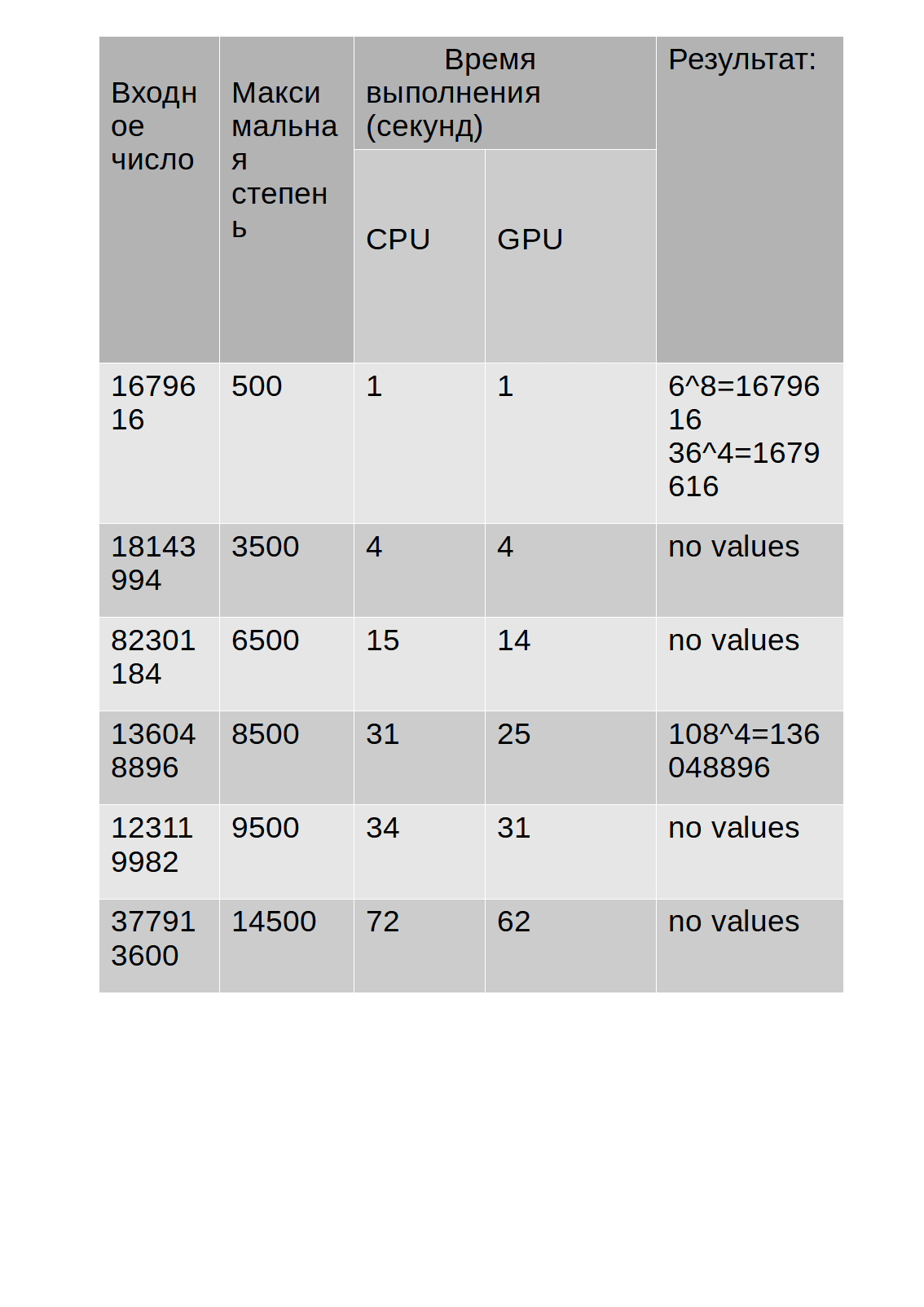
Результаты теста приведены в таблице:

Как видно из таблицы, время выполнения алгоритма на GPU немного больше, чем на CPU.
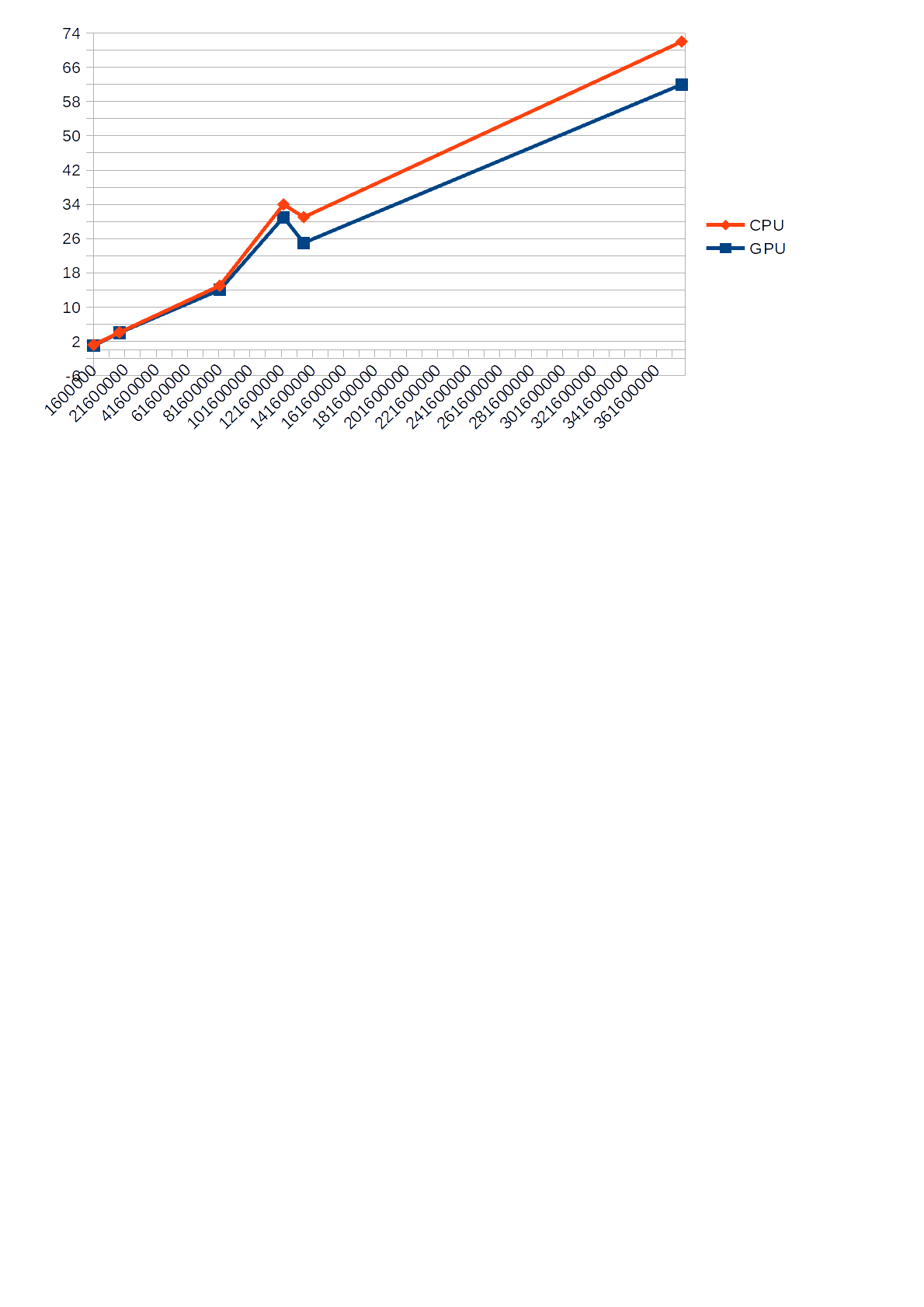
Однако, отмечу, что вовремя работы алгоритма использующего для вычислений GPU, загрузка алгоритмом CPU, отображаемая в Диспетчере задач, не превышала 30%, в то время как алгоритм использующий для вычислений CPU, загружал его на 68-85%, что в свою очередь иногда приводило к замедлению других приложений. Также, ниже приведен график, показывающий различие во
времени выполнения (по оси Y)CPU и GPU в зависимости от входного числа(по оси X).
график

Далее я решил провести тестирование при процессоре нагруженном другими приложениями. Процессор был нагружен так, что запущенный в приложение тест, не занимал больше 55% ресурсов процессора. Результаты теста приведены ниже:
График
Как видно из таблицы, в случае с нагруженным CPU, выполнение вычислений на GPU, дает прирост производительности, так как загруженность процессора в 30% укладывается в лимит 55%, а в случае использования CPU для вычислений, его загрузка составляет 68-85% , что тормозит работу алгоритма, если CPU нагружен другими приложениями.
Причина отставания GPU от CPU, на мой взгляд, может заключатся в том, что у CPU выше производительность ядра(3400 МГц CPU, 1680 МГц GPU). В том случае, когда ядра процессора нагружены другими процессами, быстродействие будет зависть от количества обрабатываемых потоков за определенный интервал времени и в этом случае быстрее будет GPU, так как он способен одновременно обрабатывать больше потоков (1024 GPU,8 CPU).
Поэтому, можно сделать вывод, что использование GPU для вычислений, не обязательно должно давать более быструю работу алгоритма, однако, оно способно разгрузить CPU, что может играть роль, если он нагружен другими приложениями.
atri1
Я не минусую никого на хабре, но могу предположить почему твою статью заминусовали.
Ты сам не разобрался в вопросе и сравниваешь несравнимое.
На хабре сидят другие разработчики для которых твой вопрос в статье может быть "уже пройденным этапом", опятьже я не говорю про себя, мой уровень как разработчика очень низок.
Имею в виду что люди знают для каких задач применимо GPU и что GPU дает десятки и сотни раз выигрыш производительности(скорости и времени), и в твоей статье скорее надо разобрать "почему" у тебя медленнее, и подходит ли задача для GPU.
Прочитай про SIMD. Разницы между CPU и GPU нет, и там и там используются одинаковые вычислительные блоки.
Мое личное пожелание — если сравниваешь GPU-алоритм с "CPU" то, пожалуйста, не используй ".Net" или Java или Питон, даже ученые уже "воют" от ужаса, что современные программисты даже для науки все штампуют на скриптовых языках которые в десятки раз медленнее Си/С++
Stalker31 Автор
ne_kotin
Потому что они позволяют меньше стрелять в ногу и быстрее получать результат?
В коде выше десяток раз надо проверить статус. Почему? Потому что, наверное, нормальных исключений нет?
Про бойлерплейт с явным выделением и возвратом памяти я уже вообще молчу.
В этом плане тот же питон намного дружелюбней, тем более, что в случае с CUDA на нем пишется только «склеивающий» код, некритичный к производительности.
beerware
+
Если Питон использовать по уму с модулями типа numpy то никакого драматического снижения производительности нет
gitKroz
Если С++ использовать по уму, то выстрелов в ногу тоже не будет.
Суть в том, что программист высокого уровня (обученный и с опытом) может написать как быструю программу на Python, так и безопасную программу на C++. А значит, выбор языка будет определяться другими факторами: конкретным сценарием / use case'ом, практиками принятыми в организации и т. п. Преимуществом языков с автоматизацией управления памятью, дополнительными проверками, прозрачной конвертацией типов и т. п. состоит в том, что человек с нуля может уже через небольшое время начать писать программы, которые будут работать. Если же есть возможность нанять человека уже со значительным опытом, то это преимущество нивелируется.
gitKroz
Да, именно поэтому. Они делают 1000 проверок там, где достаточно 10. Соответственно, приходится выбирать: либо написать программу быстро, либо написать быструю программу.
Что ты понимаешь под «нормальными исключениями», и где по твоему мнению их нет?
ne_kotin
Например? С пруфами, желательно.
В контексте «написать загрузчик параллельного кода на GPU, который протащит туда данные откуда-то» проблема «написать быструю программу» вообще не стоит. Стоит как правило задача БЫСТРО алгоритмизировать задачу и дать ей вообще возможность пережевать данные параллельно. Силами специалиста-предметника (датасатаниста).
Поэтому — pyCUDA, numpy, pandas — уже написанные на С или С++ — их всё. А питон достаточно выразителен, чтобы эту задачу изложить средствами языка.
Поэтому — где си/кресты — а где научные вычисления.
Под нормальными исключениями я понимаю наличие конструкций throw, try-except-finally, и нет их в фрагменте кода ниже.
И это типичный севый бойлерплейт лет уже 30 как. Что там было про проверки?
anonymous
Молекулярная динамика. Самые ходовые пакеты:
LAMMPS — C++
GROMACS — C/C++
DLPOLY — Fortran
Если у вас такое случилось в научном коде, значит где-то косяк во входных данных или алгоритме. И нужно искать причину, почему так случилось, а если вы проглотили ошибку и продолжили считать…
ne_kotin
Ну так и сидите тогда на медленных CPU ) а если вам таки ускорение занедорого — извольте написать CUDA-ядрышки и покормить видюху данными.
И вот тут — внезапно — оказывается, что:
а) задача разбивается на 3 независимых: управление жизненным циклом контекста, организация пайплайна «источник — ядро — получатель», и собственно — перенос вычислительного ядра на синтаксис CUDA.
б) жизненный цикл вообще пофиг на чем делать — были бы байндинги к CUDA, и он туп и единообразен для любого CUDA-приложения
в) в случае, когда исходные данные лежат в большом удаленном источнике (БД, координатор распределенных вычислений) — бутылочным горлышком оказывается не локальное I/O, не процессор, не видеокарта — а сеть.
То есть 2/3 такого ускоренного приложения — абсолютно пофиг на чем писать, и языки с неявным управлением памятью и исключениями выигрывают: бойлерплейта меньше, код выразительнее, время до запуска прототипа катастрофически сокращается.
А 1/3 решает предметник, который хорошо раскурил особенности зеленых карточек и сумел оптимизировать ядро.
С какого перепугу в входных данных? С какого перепугу в алгоритме? Косяк может случиться в I/O и он может быть исправлябельным (recoverable, retriable). Косяк может случиться где угодно, но когда количество мест, где косяки могут случаться переваливает за разумное количество — вложенные if-ы да еще круто приправленные goto-хами просто ломают понимание и читабельность кода.
Тогда как исключения предоставляют структурированный подход к обработке ошибок. И даже если у меня случилась ошибка во время расчета — это еще не повод программе подымать лапки и валиться в корку. Это повод промаркировать текущий workunit как сбойный, просигнализировать, и попросить другой.
anonymous
Так так и делают. Все эти пакеты имеют параллельную версию, по крайней мере для вычислительных кластеров.
ne_kotin
«параллельная версия» не то же самое, что «GPGPU-версия». сильно не то же самое.
anonymous
LAMMPS точно имеет версию для GPU. Возможно и остальные
gitKroz
Ну, например, проверка выхода индекса за границы массива.
Вот этот Python код завершится исключением, так как проверяет границы:
Этот код на C++ код завершается нормально, так не делает такой проверки.
Да, с одной стороны это возможность выстрелить себе в ногу. А с другой стороны, если у меня в программе невозможно выйти за пределы массива by design, зачем это каждый раз это проверять? В большинстве случаев это не мешает, но когда обрабатываются большие объемы данных, и важна производительность, это может сыграть роль. И это только один из примеров.
Кстати, в C++ тоже можно писать так, чтобы библиотека автоматически делала проверку. Следующий код на C++ завершится исключением:
То есть в C++ можно писать и так, и так. Но нужно время, обучить человека это понимать. И поэтому всё упирается в длительность подготовки специалиста.
В С++ исключения есть.
ne_kotin
Потому что это правило хорошего дизайна программы.
Вот вы щас серьезно? if в машинном коде обычно разворачивается до jz/jnz и других условных переходов. там даже без спекулятивного исполнения разница несколько тактов обычно. И я специально выше обратил внимание, что в гибридной модели бутылочное горлышко у вас будет не процессор, а I/O. Так что — экономия на спичках.
Siemargl
Это слишком упрощенное понимание. Для развертывания в векторные инструкции, подобное — стоппер для компилятора.
ne_kotin
а при чем здесь векторные инструкции, если мы про GPGPU?
Siemargl
Да потому что они там есть.
gitKroz
Правило хорошего дизайна программы — делать ровно то, что необходимо для выполнения задачи.
Неужели? Тогда объясните, пожалуйста, почему на банальном цикле и сложении, код на C++ оказывается в 100 раз быстрее кода на Python. И на этот раз попрошу пруфы от вас, если у вас есть контр-аргументы:
Тест:
$ ./test.py
100000000
Execution time: 45297.41560799994 milliseconds
$ g++ ./test.cpp && ./a.out
100000000
Execution time: 405 milliseconds
test.py
test.cpp:
ne_kotin
Нене. Она еще должна работать предсказуемо, и не валить в случае сбоя за собой всю систему. Так что — проверять границы, null pointer-ы и ставить хуки чтобы взятую память отдавать обратно, если не хотите в автоматическое управление памятью.
А почему вы апеллируете к элементарной арифметике, когда мы с вами обсуждаем прокачку данных на GPU, распределеночку, координацию через сеть? Нравится натягивать сов на глобус? Так возьмите асм, и ручками AVX512 в цикле разложите — еще порядок-два выиграете.
Вон, возьмите матрицу 4096х4096, заполните рандомно double-ами, и одной на CPU плюсами посчитайте скалярное произведение, а другую — CUDA-й через pyCUDA.
Или методом Монте-Карло посчитайте пи так и сяк до 10000-го знака.
Почему у меня Folding@Home на RTX 2080 воркюнит переваривает за час, а на Ryzen-е — не менее суток?
Разница в производительности, кстати, примерно та же, что и в вычислении скалярного произведения — примерно 20х.
А все потому, что банальное сложение в цикле никакого отношения к реальной производительности не имеет.
gitKroz
… в тех сценариях, для которых она (программа) предназначена. И только в них. Если вы пишите тулу, которая запустится пару десятков раз, да еще и из ваших рук, прорабатывать все exceptional scenarions не имеет никакого смысла. Особенно если это негативно сказывается на скорости выполнения.
На этот раз хотелось бы увидеть код от вас. Сравнение реализации на Python и C++, замеры скорости.
ne_kotin
Их в помянутом кейсе не более десятка точно.
Сорян, но программа, написанная без обработки исключений — это говнокод. Вы сейчас защищаете написание говнокода.
ne_kotin
beerware
Может ученым не нужно работать в Питоне как в Фортране и не бегать по массивам циклом for а работать с ними одним куском?
Если Питон собран с модулями под ATLAS или BLAS + LAPACK и последнее умеет на GPU то все вообще будет ок
TitovVN1974
В Фортране как раз цикл for не обязателен (другое дело, что оптимизирующий компиллятор может весьма эффективно такой цикл векторизовать и… даже распараллелить)
Siemargl
Поставил плюс.
Пусть (возможно) тут куча ошибок, но тема настолько неудобная, что стартовые разборы, даже неудачные, стоят того.
Изобретателям ассемблера для GPU желаю отдельный котел в аду.
Barabashkad
Прекрассный отрицательный пример того что CUDA это не панацея
и что ею надо знать как и уметь пользоваться :-)
для начала, CPU код можно еще оптимизиорвать если использовать векторные AVX инструкции
но и для GPU… можно не мерять время выделения памяти и копирования…
и тогда картина станет более многогранной и пестрой :-)
Stalker31 Автор
Я посчитал, что рациональнее мерить время работы всей программы, а не конкретной части, чтобы определить какой из вариантов будет более медленным.
Barabashkad
а если бы измерили ооочень бы удивились :-)
тут как раз и собака зарыта
для многих копирование данных не важная операциа
но не так, особенно на коротких задачах
как я и сказал, померяв все по отдельности картина стала бы пестрой
В вашем примере есть еще и загруска самой тестовой апплицации
что бы нивилировать все накладные расходы
желательно повторять тест внутри тестовой аппликации несколько десятков раз
на одном и томже наборе данных без повторных выделений памяти и копирования данных
atri1
да хотелось бы читать и про скорость выделения памяти и оптимизации для GPU медленной памяти, и про SIMD… они не используются в коде… понятно что это может первый опыт автора, и удачи ему в изучении и повышения "скила"
lightln2
Я правильно понимаю, что задача состоит в том, чтобы для чисел A и M найти такие числа x и y, что x^y = A, 2 <= y <= M?
Задача очень похожа на задачи из Project Euler и, наверно, поэтому не самая лучшая для сравнения CPU и GPU, поскольку, как мне кажется, она решается меньше, чем за секунду на CPU (в один поток) для любых 64-битных A и M. Идея в том, что если A — полный квадрат, то это легко проверить, просто взяв Math.Sqrt, а если A является степенью 3 или больше какого-то числа, то у него будет простой делитель, не превосходящий (примерно) один миллион, и его можно найти простым перебором. После факторизации числа A найти нужные x и y достаточно тривиально (у будет равен наименьшему общему делителю всех степеней простых чисел, входящих в разложение A).
Если абстрагироваться от задачи, то действительно интересно, почему CUDA медленней — обычно такое бывает либо потому, что время работы GPU мало по сравнению с временем подготовки и передачи данных, либо потому, что данные кладутся не в оптимальный для них тип GPU-памяти.
AlexeyALV
А где так учили блок-схемы рисовать? Или стандарты поменяли внезапно?
cpp_stranger
Меня немного удивляет, что никто не хочет указать автору Stalker31 на его ошибки. Попробую это сделать. (Если заметите ошибки и у меня, поправляйте, буду только «ЗА!»).
Про алгоритм. Вся его суть (без всякой математики по факторизации чисел) сводится к такой реализации:
Отмечу, что диапазон значений unsigned long long не обязательно хватит для любых входных данных, поэтому не забываем о возможном переполнении.
Но вернемся к Вашему методу.
Вот вы пишете ожидания завершения потоков:
На самом деле, у Вас тут гонка данных (race condition) за общий разделяемый ресурс , поскольку каждый поток в Вашей реализации увеличивает эту переменную в самом начале своей работы (а нужно в конце, ибо мы ждем завершения!!!), и никто точно не знает, какое значение осталось в кэше потока. Для более корректного применения такого подхода нужно использовать , но в идеале я написал бы так:
Неужели Вас совершенно не удивило, что работа 1000 потоков на 8-ми ядерном процессоре быстрее, чем на графическом процессоре, у которого допустимое число потоков куда больше?
Реализация для графического процессора у Вас просто не подходящая, мягко говоря. Если писать на коленке, то в моем видении, это должно выглядеть примерно так:
Я бы Вам советовал почитать книжки:
Ну и конечно, больше практики. Успехов!
Stalker31 Автор
Я решил что у CPU выше производительность ядра.
berez
Все правильно. Одно ядро быстрее, чем один поток на GPU, раз этак в 10. Вот только ядер у CPU 8 (и то гипертрединг), а на видеокарте — больше тысячи. И если их все загрузить работой, то производительность видеокарты будет в десятки и сотни раз выше, чем CPU.
Проблема в том, что пересылка данных между хостом и видеокартой может занимать много-много времени :)
beerware
Используйте GPU по назначению, например для FFT2 и будет вам прирост производительности
ghosts_in_a_box
Попытался воспроизвести сравнение на своей машине, но ни порядок величин, ни харатер зависимости не совпали ни для CPU ни для GPU.
Compute Capability 6.1
Threads per Multiprocessor 1024
CUDA 10.2
Stalker31 Автор
Для начала скажу, что для тестирования я использовал приложение на C#, его код приведён в статье, поэтому результаты не совпадают.