
В статье приводится метод анализа вакансий по поисковому запросу «Python» с помощью модели кластеризации Gaussian Mixture Model (GMM). По каждому выделенному кластеру будут приведены наиболее востребованные навыки и диапазон заработных плат.
Для чего проводилось данное исследование? Мне хотелось узнать:

Вакансии загружались с сайта hh.ru, с использованием API: dev.hh.ru. По запросу «Python» было загружено 1994 вакансии (регион Москва), которые были разделены на обучающий и тестовый наборы, в пропорции 80% и 20%. Размер обучающего набора — 1595, размер тестового — 399. Тестовый набор будет использован только в разделах «Топ/Антитоп навыков» и «Классификация вакансий».
По тексту загруженных вакансий были сформированы две группы наиболее часто встречающихся n-грамм слов:
В вакансиях IT ключевые навыки и технологии обычно пишутся на английском языке, поэтому вторая группа включала слова только на латинице.
После отбора n-грамм первая группа содержала 81 2-граммы, а вторая 98 1-граммы:
Разбиение вакансий на кластеры было решено сделать по следующим критериям в порядке приоритета:
Определение к какой группе критериев относится n-грамма, и какой вес ей присвоить, происходило на интуитивном уровне. Приведу пару примеров:
Чем больше вес у n-граммы — тем сильней будут группироваться вакансии по данному признаку.
Для вычислений каждая вакансия была преобразована в вектор с размерностью 179 (число отобранных признаков) из целых чисел от 0 до 9, где 0 означает что i-ая n-грамма отсутствует в вакансии, а числа от 1 до 9 означают присутствие i-ой n-граммы и ее вес. Далее в тексте под точкой понимается вакансия представленная таким вектором.
Для работы с данными нужно иметь представление о них. В нашем случае хотелось бы увидеть, есть ли какие-то скопления точек, которые мы и будем считать кластерами. Для этого я использовал алгоритм t-SNE, чтобы перевести все векторы в двухмерное пространство.
Суть метода в том, чтобы понизить размерность данных, при этом максимально сохранить пропорции расстояний между точками множества. Понять по формулам, как работает t-SNE довольно сложно. Но мне понравился один пример найденный где-то на просторах интернета: допустим у нас есть шарики в трехмерном пространстве. Каждый шарик мы соединяем со всеми остальными шариками невидимыми пружинами, которые никак не пересекаются и не мешают друг другу при пересечении. Пружины действуют в две стороны, т.е. они сопротивляются как отдалению, так и приближению шариков друг к другу. Система находится в стабильном состоянии, шарики неподвижны. Если мы возьмем один из шариков и оттянем его, а затем отпустим — то за счет силы пружин он вернется в исходное состояние. Далее мы берем две большие пластины, и сжимаем шарики в тонкий слой, при этом не мешая шарикам двигаться в плоскости между двумя пластинами. Начинают действовать силы пружин, шарики перемещаются и в итоге останавливаются, когда силы всех пружин становятся уравновешенными. Пружины будут действовать так, что шарики, которые находились близко друг к другу, останутся относительно близко и на плоскости. Также и с удаленными шариками — они будут удалены друг от друга. С помощью пружин и пластин мы перевели трехмерное пространство в двухмерное, сохранив в каком-то виде расстояния между точкам!
Алгоритм t-SNE использовался мною только для визуализации множества точек. Он помог выбрать метрику, а также подбирать весы для признаков.
Если использовать метрику Евклида, которую мы используем в нашей повседневной жизни, то расположение вакансий будет выглядеть следующим образом:

На рисунке видно, что большинство точек сосредоточены в центре, и есть небольшие ответвления в стороны. При таком подходе алгоритмы кластеризации, использующие расстояния между точками, ничего хорошего выдавать не будут.
Существует большое множество метрик (способов определения расстояния между двумя точками), которые будут хорошо работать на исследуемых данных. Я выбрал в качестве меры расстояние Жаккара, с учетом весов n-грамм. Мера Жаккара простая для понимания, при этом хорошо работает для решения рассматриваемой задачи.
Была вычислена матрица расстояний между всеми парами точек, размер матрицы 1595 х 1595. Всего 1 271 215 расстояний между уникальными парами. Среднее расстояние получилось равным 0.96, между 619 659 расстояние равно 1 (т.е. сходства нет совсем). Следующая диаграмма показывает, что в целом вакансии имеют мало сходства:
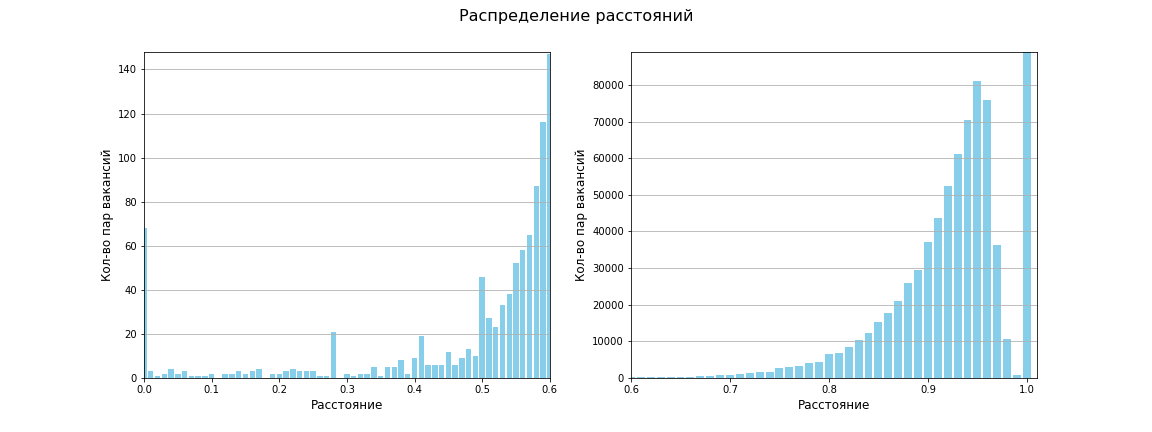
При использовании метрики Жаккара наше пространство теперь выглядит так:

Появились четыре ярко выраженных участка плотности, и два маленьких скопления с небольшой плотностью. По крайней мере, так видят мои глаза!
В качестве алгоритма кластеризации была выбрана модель Gaussian Mixture Model (GMM). Алгоритм получает на вход данные в виде векторов, и параметр n_components — число кластеров, на которые надо разбить множество. О том, как работает алгоритм, можно посмотреть здесь (на английском языке). Я использовал готовую реализацию GMM из библиотеки scikit-learn: sklearn.mixture.GaussianMixture.
Отмечу, что GMM не использует метрику, а делает разделение данных только по набору признаков и их весам. В статье расстояние Жаккара используется для визуализации данных, подсчета компактности кластеров (за компактность я принял среднее расстояние между точками кластера), и определения центральной точки кластера (типичная вакансия) — точка с наименьшим средним расстоянием до других точек кластера. Многие алгоритмы кластеризации использует именно расстояние между точками. В разделе «Другие методы» будет рассказано о других видах кластеризаций, которые основываются на метрике и тоже дают хорошие результаты.
В предыдущем разделе на глаз было определено, что кластеров скорей всего будет шесть. Так выглядят результаты кластеризации при n_components = 6:

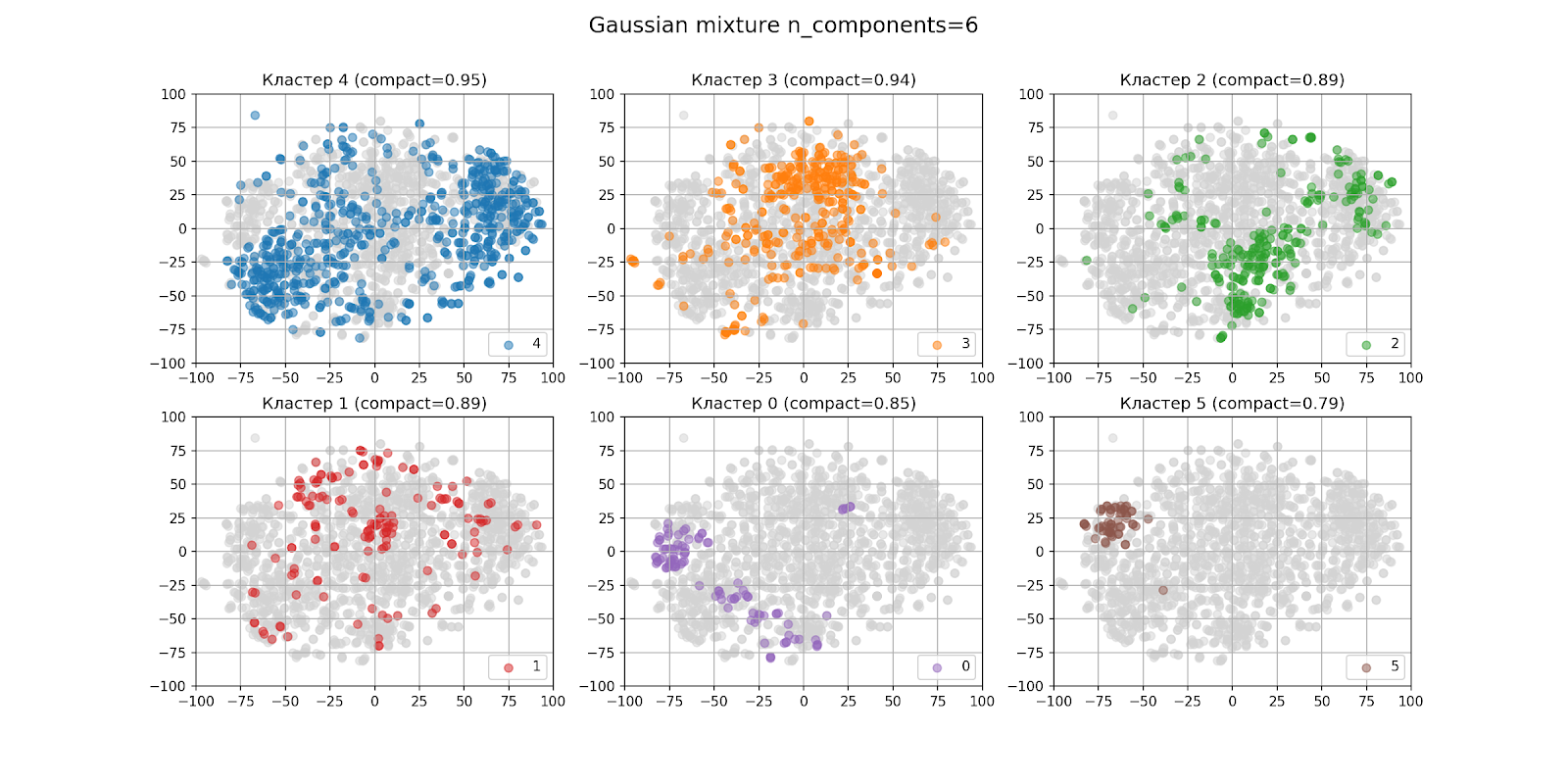
На рисунке с выводом кластеров по отдельности, кластеры располагаются в порядке убывания числа точек слева направо, сверху вниз: кластер 4 — самый большой, кластер 5 — самый маленький. В скобках для каждого кластера указана его компактность.
На вид кластеризация получилась не очень хорошей, даже если учитывать, что алгоритм t-SNE не идеален. При анализе кластеров результат тоже не обрадовал.
Для нахождения оптимального числа кластеров n_components, воспользуемся критериями AIC и BIC, о которых можно прочитать здесь. Расчет данных критериев встроен в метод sklearn.mixture.GaussianMixture. Так выглядит график критериев:

При n_components = 12 критерий BIC имеет наименьшее (наилучшее) значение, критерий AIC тоже имеет значение близкое к минимуму (минимум при n_components = 23). Произведем разделение вакансий на 12 кластеров:


Теперь кластеры имеют более компактные формы, как на вид, так и в числовом выражении. При ручном анализе вакансии оказались разбиты на характерные группы для понимания человека. На рисунке выведены названия кластеров. Кластеры под номерами 11 и 4 помечены как и <Trash 2>:
После удаления двух неинформативных кластеров под номерами 11 и 4 в итоге получилось 10 кластеров:
По каждому кластеру приведена таблица признаков и 2-грамм, которые чаще всего встречаются в вакансиях кластера.
Обозначения:
S — доля вакансий, в которых встречается признак, умноженная на вес признака
% — процент вакансий, в которых встречается признак/2-грамма
Типичная вакансия кластера — вакансия, с наименьшим средним расстоянием до других точек кластера
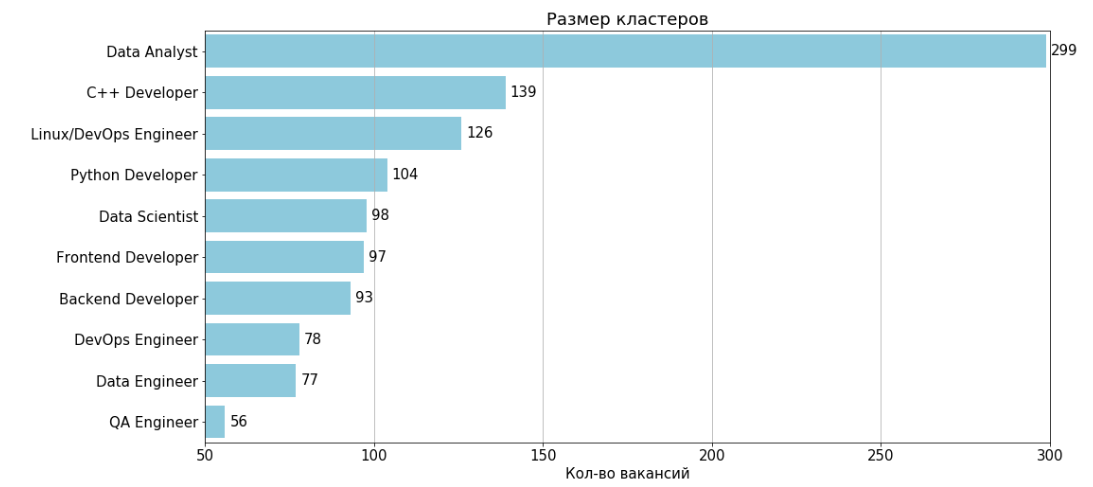
Кол-во вакансий: 299
Типичная вакансия: 35805914
Кол-во вакансий: 139
Типичная вакансия: 39955360
Кол-во вакансий: 126
Типичная вакансия: 39533926
Кол-во вакансий: 104
Типичная вакансия: 39705484
Кол-во вакансий: 98
Типичная вакансия: 38071218
Кол-во вакансий: 97
Типичная вакансия: 39681044
Кол-во вакансий: 93
Типичная вакансия: 40226808
Кол-во вакансий: 78
Типичная вакансия: 39634258
Кол-во вакансий: 77
Типичная вакансия: 40008757
Кол-во вакансий: 56
Типичная вакансия: 39630489
Зарплаты указаны только в 261 (22%) вакансии из 1167 попавших в кластеры.
При расчете зарплат:
На графике:

Диаграммы строились по всем 1994 загруженным вакансиям. Зарплаты указаны в 443 (22%) вакансиях. Для расчета по каждому признаку отбирались вакансии, где этот признак присутствует, и на их основе вычислялась медианная ЗП.

Кластеризацию можно было сделать гораздо проще, не прибегая к сложным математическим моделям: составить топ наименований вакансий, и разбить их по группам. Далее анализировать каждую группу на топ n-грамм, и средние зарплаты. Не нужно выделять признаки и присваивать им веса.
Такой подход хорошо бы работал (в какой-то мере) для запроса «Python». А вот для запроса «Программист 1С» такой подход работать не будет, т.к. для программистов 1С в наименовании вакансий редко указывают конфигурации 1С или прикладные направления. А направлений где используется 1С много: бухгалтерия, расчет ЗП, расчет налогов, расчет себестоимости на производственных предприятиях, складской учет, бюджетирование, ERP системы, розничная торговля, управленческий учет, и т.д.
Для себя я вижу две задачи по анализу вакансий:
Для решения первой задачи подходит кластеризация, для решения второй — разнообразные классификаторы, случайные леса, деревья принятия решений, нейронные сети. Тем не менее мне захотелось оценить пригодность выбранной модели для задачи классификации вакансий.
Если использовать встроенный в sklearn.mixture.GaussianMixture метод predict(), то ничего хорошего не получается. Большинство вакансий он относит к большим кластерам, а два кластера из первых трех являются неинформативными. Я использовал другой подход:
Для оценки модели случайным образом отобраны 30 вакансий из тестового набора. В колонке вердикт:
N/a: модель не классифицировала вакансию (расстояние > 0.87)
+: правильная классификация
-: неправильная классификация
Итого: на 12 вакансиях нет результата, на 2 вакансиях — ошибочная классификация, на 16 вакансиях — правильная классификация. Полнота модели — 60%, точность модели — 89%.
Первая проблема — возьмем две вакансии:
Вторая проблема — GMM кластеризует все точки множества, как и многие алгоритмы кластеризации. Неинформативные кластеры сами по себе не являются проблемой. Но и информативные кластеры содержат выбросы. Впрочем, это легко решается очисткой кластеров, например удалением самых нетипичных точек, которые имеют наибольшее среднее расстояние до остальных точек кластера.
На странице cluster comparison хорошо продемонстрированы различные алгоритмы кластеризации. GMM — единственный, который дал хорошие результаты.
Остальные алгоритмы либо не работали, либо давали очень скромные результаты.
Из реализованных мной, хорошие результаты были в двух случаях:
Проведенное исследование дало мне ответы на все вопросы, которые приведены в начале статьи. Я получил практический опыт по кластеризации, когда реализовывал вариации известных алгоритмов. Очень надеюсь, что статья мотивирует читателя провести свои аналитические исследования, и чем-то поможет в этом увлекательном занятии.
Для чего проводилось данное исследование? Мне хотелось узнать:
- В каких прикладных направлениях используется Python
- Какие требуются знания: базы данных, библиотеки, фреймворки
- Насколько востребованы специалисты каждого направления
- Какие зарплаты предлагают
Загрузка данных
Вакансии загружались с сайта hh.ru, с использованием API: dev.hh.ru. По запросу «Python» было загружено 1994 вакансии (регион Москва), которые были разделены на обучающий и тестовый наборы, в пропорции 80% и 20%. Размер обучающего набора — 1595, размер тестового — 399. Тестовый набор будет использован только в разделах «Топ/Антитоп навыков» и «Классификация вакансий».
Признаки
По тексту загруженных вакансий были сформированы две группы наиболее часто встречающихся n-грамм слов:
- 2-граммы на кириллице и латинице
- 1-граммы на латинице
В вакансиях IT ключевые навыки и технологии обычно пишутся на английском языке, поэтому вторая группа включала слова только на латинице.
После отбора n-грамм первая группа содержала 81 2-граммы, а вторая 98 1-граммы:
| № | n | n-грамма | Вес | Вакансии |
| 1 | 2 | на python | 8 | 258 |
| 2 | 2 | ci cd | 8 | 230 |
| 3 | 2 | понимание принципов | 8 | 221 |
| 4 | 2 | знание sql | 8 | 178 |
| 5 | 2 | разработка и | 9 | 174 |
| ... | ... | ... | ... | ... |
| 82 | 1 | sql | 5 | 490 |
| 83 | 1 | linux | 6 | 462 |
| 84 | 1 | postgresql | 5 | 362 |
| 85 | 1 | docker | 7 | 358 |
| 86 | 1 | java | 9 | 297 |
| ... | ... | ... | ... | ... |
Разбиение вакансий на кластеры было решено сделать по следующим критериям в порядке приоритета:
| Приоритет | Критерий | Вес |
| 1 | Сфера (прикладное направление), должность, опыт n-граммы: «машинного обучения», «администрирования linux», «отличное знание» |
7-9 |
| 2 | Инструменты, технологии, программное обеспечение. n-граммы: «sql», «ос linux», «pytest» |
4-6 |
| 3 | Прочие навыки n-граммы: «техническое образование», «английского языка», «интересные задачи» |
1-3 |
Определение к какой группе критериев относится n-грамма, и какой вес ей присвоить, происходило на интуитивном уровне. Приведу пару примеров:
- С первого взгляда «Docker» можно отнести ко второй группе критериев с весом от 4 до 6. Но упоминание «Docker» в вакансии, скорей всего говорит о том, что вакансия будет на должность «DevOps инженер». Поэтому «Docker» попал в первую группу и получил вес равный 7.
- «Java» тоже попадает в первую группу, т.к. в большинстве рассматриваемых вакансий с присутствием слова «Java» ищут Java-разработчика с пунктом «будет дополнительным преимуществом знание Python». Бывают и вакансии с поиском «человека-оркестра». Как первые, так и вторые вакансии меня не интересуют, поэтому их я хочу отделить от остальных вакансий, соответственно присваиваю «Java» наибольший вес 9.
Чем больше вес у n-граммы — тем сильней будут группироваться вакансии по данному признаку.
Преобразование данных
Для вычислений каждая вакансия была преобразована в вектор с размерностью 179 (число отобранных признаков) из целых чисел от 0 до 9, где 0 означает что i-ая n-грамма отсутствует в вакансии, а числа от 1 до 9 означают присутствие i-ой n-граммы и ее вес. Далее в тексте под точкой понимается вакансия представленная таким вектором.
Пример:
Допустим список n-грамм содержит всего три значения:
№ n n-грамма Вес Вакансии 1 2 на python 8 258 2 2 понимание принципов 8 221 3 1 sql 5 490
Тогда для вакансии с текстом.
Требования:
- Опыт разработки на python от 3-х лет.
- Хорошее знание sql
вектор равен [8, 0, 5].
Метрика
Для работы с данными нужно иметь представление о них. В нашем случае хотелось бы увидеть, есть ли какие-то скопления точек, которые мы и будем считать кластерами. Для этого я использовал алгоритм t-SNE, чтобы перевести все векторы в двухмерное пространство.
Суть метода в том, чтобы понизить размерность данных, при этом максимально сохранить пропорции расстояний между точками множества. Понять по формулам, как работает t-SNE довольно сложно. Но мне понравился один пример найденный где-то на просторах интернета: допустим у нас есть шарики в трехмерном пространстве. Каждый шарик мы соединяем со всеми остальными шариками невидимыми пружинами, которые никак не пересекаются и не мешают друг другу при пересечении. Пружины действуют в две стороны, т.е. они сопротивляются как отдалению, так и приближению шариков друг к другу. Система находится в стабильном состоянии, шарики неподвижны. Если мы возьмем один из шариков и оттянем его, а затем отпустим — то за счет силы пружин он вернется в исходное состояние. Далее мы берем две большие пластины, и сжимаем шарики в тонкий слой, при этом не мешая шарикам двигаться в плоскости между двумя пластинами. Начинают действовать силы пружин, шарики перемещаются и в итоге останавливаются, когда силы всех пружин становятся уравновешенными. Пружины будут действовать так, что шарики, которые находились близко друг к другу, останутся относительно близко и на плоскости. Также и с удаленными шариками — они будут удалены друг от друга. С помощью пружин и пластин мы перевели трехмерное пространство в двухмерное, сохранив в каком-то виде расстояния между точкам!
Алгоритм t-SNE использовался мною только для визуализации множества точек. Он помог выбрать метрику, а также подбирать весы для признаков.
Если использовать метрику Евклида, которую мы используем в нашей повседневной жизни, то расположение вакансий будет выглядеть следующим образом:
На рисунке видно, что большинство точек сосредоточены в центре, и есть небольшие ответвления в стороны. При таком подходе алгоритмы кластеризации, использующие расстояния между точками, ничего хорошего выдавать не будут.
Существует большое множество метрик (способов определения расстояния между двумя точками), которые будут хорошо работать на исследуемых данных. Я выбрал в качестве меры расстояние Жаккара, с учетом весов n-грамм. Мера Жаккара простая для понимания, при этом хорошо работает для решения рассматриваемой задачи.
Пример:
Вакансия 1 содержит n-граммы: «на python», «sql», «docker»
Вакансия 2 содержит n-граммы: «на python», «sql», «php»
Веса:
«на python» — 8
«sql» — 5
«docker» — 7
«php» — 9
Пересечение множеств (n-грамма встречается в 1-ой и 2-ой вакансии): «на python», «sql» = 8 + 5 = 13
Объединение множеств (все n-граммы из 1-ой и 2-ой вакансии): «на python», «sql», «docker», «php» = 8 + 5 + 7 + 9 = 29
Расстояние =1 — (Пересечение множеств / Объединение множеств) = 1 — (13 / 29) = 0.55
Была вычислена матрица расстояний между всеми парами точек, размер матрицы 1595 х 1595. Всего 1 271 215 расстояний между уникальными парами. Среднее расстояние получилось равным 0.96, между 619 659 расстояние равно 1 (т.е. сходства нет совсем). Следующая диаграмма показывает, что в целом вакансии имеют мало сходства:
При использовании метрики Жаккара наше пространство теперь выглядит так:
Появились четыре ярко выраженных участка плотности, и два маленьких скопления с небольшой плотностью. По крайней мере, так видят мои глаза!
Кластеризация
В качестве алгоритма кластеризации была выбрана модель Gaussian Mixture Model (GMM). Алгоритм получает на вход данные в виде векторов, и параметр n_components — число кластеров, на которые надо разбить множество. О том, как работает алгоритм, можно посмотреть здесь (на английском языке). Я использовал готовую реализацию GMM из библиотеки scikit-learn: sklearn.mixture.GaussianMixture.
Отмечу, что GMM не использует метрику, а делает разделение данных только по набору признаков и их весам. В статье расстояние Жаккара используется для визуализации данных, подсчета компактности кластеров (за компактность я принял среднее расстояние между точками кластера), и определения центральной точки кластера (типичная вакансия) — точка с наименьшим средним расстоянием до других точек кластера. Многие алгоритмы кластеризации использует именно расстояние между точками. В разделе «Другие методы» будет рассказано о других видах кластеризаций, которые основываются на метрике и тоже дают хорошие результаты.
В предыдущем разделе на глаз было определено, что кластеров скорей всего будет шесть. Так выглядят результаты кластеризации при n_components = 6:
На рисунке с выводом кластеров по отдельности, кластеры располагаются в порядке убывания числа точек слева направо, сверху вниз: кластер 4 — самый большой, кластер 5 — самый маленький. В скобках для каждого кластера указана его компактность.
На вид кластеризация получилась не очень хорошей, даже если учитывать, что алгоритм t-SNE не идеален. При анализе кластеров результат тоже не обрадовал.
Для нахождения оптимального числа кластеров n_components, воспользуемся критериями AIC и BIC, о которых можно прочитать здесь. Расчет данных критериев встроен в метод sklearn.mixture.GaussianMixture. Так выглядит график критериев:
При n_components = 12 критерий BIC имеет наименьшее (наилучшее) значение, критерий AIC тоже имеет значение близкое к минимуму (минимум при n_components = 23). Произведем разделение вакансий на 12 кластеров:
Теперь кластеры имеют более компактные формы, как на вид, так и в числовом выражении. При ручном анализе вакансии оказались разбиты на характерные группы для понимания человека. На рисунке выведены названия кластеров. Кластеры под номерами 11 и 4 помечены как и <Trash 2>:
- В кластере 11 все признаки имеют приблизительно одинаковые суммарные веса.
- Кластер 4 выделен по признаку Java. Тем не менее вакансий на должность Java Developer в кластере мало, часто знание Java требуется как «будет дополнительным плюсом».
Кластеры
После удаления двух неинформативных кластеров под номерами 11 и 4 в итоге получилось 10 кластеров:
По каждому кластеру приведена таблица признаков и 2-грамм, которые чаще всего встречаются в вакансиях кластера.
Обозначения:
S — доля вакансий, в которых встречается признак, умноженная на вес признака
% — процент вакансий, в которых встречается признак/2-грамма
Типичная вакансия кластера — вакансия, с наименьшим средним расстоянием до других точек кластера
Data Analyst
Кол-во вакансий: 299
Типичная вакансия: 35805914
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | excel | 3.13 | sql | 64.55 | знание sql | 18.39 |
| 2 | r | 2.59 | excel | 34.78 | в разработке | 14.05 |
| 3 | sql | 2.44 | r | 28.76 | python r | 14.05 |
| 4 | знание sql | 1.47 | bi | 19.40 | с большими | 13.38 |
| 5 | анализа данных | 1.17 | tableau | 15.38 | разработка и | 13.38 |
| 6 | tableau | 1.08 | 14.38 | анализа данных | 13.04 | |
| 7 | с большими | 1.07 | vba | 13.04 | знание python | 12.71 |
| 8 | разработка и | 1.07 | science | 9.70 | аналитический склад | 11.71 |
| 9 | vba | 1.04 | dwh | 6.35 | опыт разработки | 11.71 |
| 10 | знание python | 1.02 | oracle | 6.35 | базами данных | 11.37 |
С++ Developer
Кол-во вакансий: 139
Типичная вакансия: 39955360
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | c++ | 9.00 | c++ | 100.00 | опыт разработки | 44.60 |
| 2 | java | 3.30 | linux | 44.60 | c c++ | 27.34 |
| 3 | linux | 2.55 | java | 36.69 | c++ python | 17.99 |
| 4 | c# | 1.88 | sql | 23.02 | на c++ | 16.55 |
| 5 | go | 1.75 | c# | 20.86 | разработки на | 15.83 |
| 6 | разработки на | 1.27 | go | 19.42 | структур данных | 15.11 |
| 7 | хорошее знание | 1.15 | unix | 12.23 | опыт написания | 14.39 |
| 8 | структур данных | 1.06 | tensorflow | 11.51 | программирования на | 13.67 |
| 9 | tensorflow | 1.04 | bash | 10.07 | в разработке | 13.67 |
| 10 | опыт программирования | 0.98 | postgresql | 9.35 | языков программирования | 12.95 |
Linux/DevOps Engineer
Кол-во вакансий: 126
Типичная вакансия: 39533926
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | ansible | 5.33 | linux | 84.92 | ci cd | 58.73 |
| 2 | docker | 4.78 | ansible | 76.19 | опыт администрирования | 42.06 |
| 3 | bash | 4.78 | docker | 74.60 | bash python | 33.33 |
| 4 | ci cd | 4.70 | bash | 68.25 | tcp ip | 39.37 |
| 5 | linux | 4.43 | prometheus | 58.73 | опыт настройки | 28.57 |
| 6 | prometheus | 4.11 | zabbix | 54.76 | мониторинга и | 26.98 |
| 7 | nginx | 3.67 | nginx | 52.38 | prometheus grafana | 23.81 |
| 8 | опыт администрирования | 3.37 | grafana | 52.38 | систем мониторинга | 22.22 |
| 9 | zabbix | 3.29 | postgresql | 51.59 | с docker | 16.67 |
| 10 | elk | 3.22 | kubernetes | 51.59 | управления конфигурациями | 16.67 |
Python Developer
Кол-во вакансий: 104
Типичная вакансия: 39705484
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | на python | 6.00 | docker | 65.38 | на python | 75.00 |
| 2 | django | 5.62 | django | 62.50 | разработки на | 51.92 |
| 3 | flask | 4.59 | postgresql | 58.65 | опыт разработки | 43.27 |
| 4 | docker | 4.24 | flask | 50.96 | django flask | 24.04 |
| 5 | разработки на | 4.15 | redis | 38.46 | rest api | 23.08 |
| 6 | postgresql | 2.93 | linux | 35.58 | python от | 21.15 |
| 7 | aiohttp | 1.99 | rabbitmq | 33.65 | базами данных | 18.27 |
| 8 | redis | 1.92 | sql | 30.77 | опыт написания | 18.27 |
| 9 | linux | 1.73 | mongodb | 25.00 | с docker | 17.31 |
| 10 | rabbitmq | 1.68 | aiohttp | 22.12 | с postgresql | 16.35 |
Data Scientist
Кол-во вакансий: 98
Типичная вакансия: 38071218
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | pandas | 7.35 | pandas | 81.63 | машинного обучения | 63.27 |
| 2 | numpy | 6.04 | numpy | 75.51 | pandas numpy | 43.88 |
| 3 | машинного обучения | 5.69 | sql | 62.24 | анализа данных | 29.59 |
| 4 | pytorch | 3.77 | pytorch | 41.84 | data science | 26.53 |
| 5 | ml | 3.49 | ml | 38.78 | знание python | 25.51 |
| 6 | tensorflow | 3.31 | tensorflow | 36.73 | numpy scipy | 24.49 |
| 7 | анализа данных | 2.66 | spark | 32.65 | python pandas | 23.47 |
| 8 | scikitlearn | 2.57 | scikitlearn | 28.57 | на python | 21.43 |
| 9 | data science | 2.39 | docker | 27.55 | математической статистики | 20.41 |
| 10 | spark | 2.29 | hadoop | 27.55 | алгоритмов машинного | 20.41 |
Frontend Developer
Кол-во вакансий: 97
Типичная вакансия: 39681044
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | javascript | 9.00 | javascript | 100 | html css | 27.84 |
| 2 | django | 2.60 | html | 42.27 | опыт разработки | 25.77 |
| 3 | react | 2.32 | postgresql | 38.14 | в разработке | 17.53 |
| 4 | nodejs | 2.13 | docker | 37.11 | знание javascript | 15.46 |
| 5 | frontend | 2.13 | css | 37.11 | и поддержка | 15.46 |
| 6 | docker | 2.09 | linux | 32.99 | python и | 14.43 |
| 7 | postgresql | 1.91 | sql | 31.96 | css javascript | 13.40 |
| 8 | linux | 1.79 | django | 28.87 | базами данных | 12.37 |
| 9 | html css | 1.67 | react | 25.77 | на python | 12.37 |
| 10 | php | 1.58 | nodejs | 23.71 | проектирования и | 11.34 |
Backend Developer
Кол-во вакансий: 93
Типичная вакансия: 40226808
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | django | 5.90 | django | 65.59 | python django | 26.88 |
| 2 | js | 4.74 | js | 52.69 | опыт разработки | 25.81 |
| 3 | react | 2.52 | postgresql | 40.86 | знание python | 20.43 |
| 4 | docker | 2.26 | docker | 35.48 | в разработке | 18.28 |
| 5 | postgresql | 2.04 | react | 27.96 | ci cd | 17.20 |
| 6 | понимание принципов | 1.89 | linux | 27.96 | уверенное знание | 16.13 |
| 7 | знание python | 1.63 | backend | 22.58 | rest api | 15.05 |
| 8 | backend | 1.58 | redis | 22.58 | html css | 13.98 |
| 9 | ci cd | 1.38 | sql | 20.43 | умение разбираться | 10.75 |
| 10 | frontend | 1.35 | mysql | 19.35 | в чужом | 10.75 |
DevOps Engineer
Кол-во вакансий: 78
Типичная вакансия: 39634258
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | devops | 8.54 | devops | 94.87 | ci cd | 51.28 |
| 2 | ansible | 5.38 | ansible | 76.92 | bash python | 30.77 |
| 3 | bash | 4.76 | linux | 74.36 | опыт администрирования | 24.36 |
| 4 | jenkins | 4.49 | bash | 67.95 | и поддержка | 23.08 |
| 5 | ci cd | 4.10 | jenkins | 64.10 | docker kubernetes | 20.51 |
| 6 | linux | 3.54 | docker | 50.00 | разработки и | 17.95 |
| 7 | docker | 2.60 | kubernetes | 41.03 | опыт написания | 17.95 |
| 8 | java | 2.08 | sql | 29.49 | и настройка | 17.95 |
| 9 | опыт администрирования | 1.95 | oracle | 25.64 | разработка и | 16.67 |
| 10 | и поддержка | 1.85 | openshift | 24.36 | написания скриптов | 14.10 |
Data Engineer
Кол-во вакансий: 77
Типичная вакансия: 40008757
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | spark | 6.00 | hadoop | 89.61 | обработки данных | 38.96 |
| 2 | hadoop | 5.38 | spark | 85.71 | big data | 37.66 |
| 3 | java | 4.68 | sql | 68.83 | опыт разработки | 23.38 |
| 4 | hive | 4.27 | hive | 61.04 | знание sql | 22.08 |
| 5 | scala | 3.64 | java | 51.95 | разработка и | 19.48 |
| 6 | big data | 3.39 | scala | 51.95 | hadoop spark | 19.48 |
| 7 | etl | 3.36 | etl | 48.05 | java scala | 19.48 |
| 8 | sql | 2.79 | airflow | 44.16 | качества данных | 18.18 |
| 9 | обработки данных | 2.73 | kafka | 42.86 | и обработки | 18.18 |
| 10 | kafka | 2.57 | oracle | 35.06 | hadoop hive | 18.18 |
QA Engineer
Кол-во вакансий: 56
Типичная вакансия: 39630489
| № | Признак с весом | S | Признак | % | 2-грамма | % |
| 1 | автоматизации тестирования | 5.46 | sql | 46.43 | автоматизации тестирования | 60.71 |
| 2 | опыт тестирования | 4.29 | qa | 42.86 | опыт тестирования | 53.57 |
| 3 | qa | 3.86 | linux | 35.71 | на python | 41.07 |
| 4 | на python | 3.29 | selenium | 32.14 | опыт автоматизации | 35.71 |
| 5 | разработки и | 2.57 | web | 32.14 | разработки и | 32.14 |
| 6 | sql | 2.05 | docker | 30.36 | тестирования опыт | 30.36 |
| 7 | linux | 2.04 | jenkins | 26.79 | опыт написания | 28.57 |
| 8 | selenium | 1.93 | backend | 26.79 | тестирования по | 23.21 |
| 9 | web | 1.93 | bash | 21.43 | автоматизированного тестирования | 21.43 |
| 10 | backend | 1.88 | ui | 19.64 | ci cd | 21.43 |
Зарплаты
Зарплаты указаны только в 261 (22%) вакансии из 1167 попавших в кластеры.
При расчете зарплат:
- Если указывался диапазон «от … и до ...», то использовалось среднее значение
- Если указывалось только «от ...» или только «до ...», то это значение и бралось
- При расчетах использовалась(или приводились) ЗП после уплаты налогов (NET)
На графике:
- Кластеры идут в порядке убывания медианной зарплаты
- Вертикальная черта в коробке — медиана
- Коробка — диапазон [Q1, Q3], где Q1 (25%) и Q3 (75%) перцентили. Т.е. в коробку попадают 50% зарплат
- В «усы» попадают зарплаты из диапазона [Q1 — 1.5*IQR, Q3 + 1.5*IQR], где IQR = Q3 — Q1 — интерквартильный размах
- Отдельные точки — аномалии, не попавшие в усы. (Есть аномалии не попавшие и на диаграмму)
Топ/Антитоп навыков
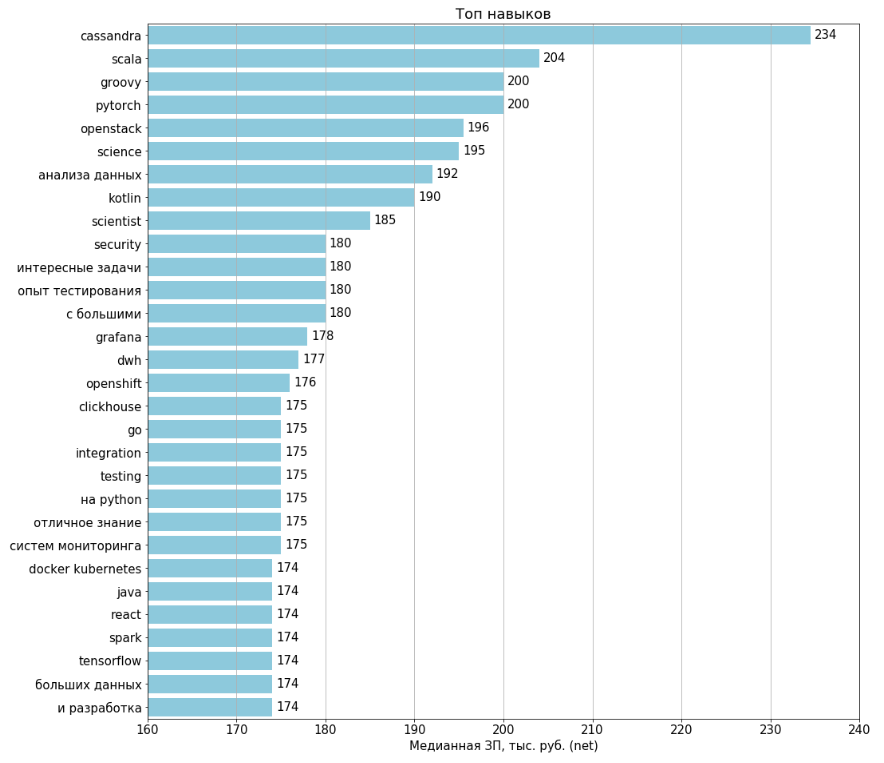
Диаграммы строились по всем 1994 загруженным вакансиям. Зарплаты указаны в 443 (22%) вакансиях. Для расчета по каждому признаку отбирались вакансии, где этот признак присутствует, и на их основе вычислялась медианная ЗП.
Классификация вакансий
Кластеризацию можно было сделать гораздо проще, не прибегая к сложным математическим моделям: составить топ наименований вакансий, и разбить их по группам. Далее анализировать каждую группу на топ n-грамм, и средние зарплаты. Не нужно выделять признаки и присваивать им веса.
Такой подход хорошо бы работал (в какой-то мере) для запроса «Python». А вот для запроса «Программист 1С» такой подход работать не будет, т.к. для программистов 1С в наименовании вакансий редко указывают конфигурации 1С или прикладные направления. А направлений где используется 1С много: бухгалтерия, расчет ЗП, расчет налогов, расчет себестоимости на производственных предприятиях, складской учет, бюджетирование, ERP системы, розничная торговля, управленческий учет, и т.д.
Для себя я вижу две задачи по анализу вакансий:
- Понять, где используется язык программирования, о котором я мало знаю (как в этой статье).
- Фильтровать новые опубликованные вакансии.
Для решения первой задачи подходит кластеризация, для решения второй — разнообразные классификаторы, случайные леса, деревья принятия решений, нейронные сети. Тем не менее мне захотелось оценить пригодность выбранной модели для задачи классификации вакансий.
Если использовать встроенный в sklearn.mixture.GaussianMixture метод predict(), то ничего хорошего не получается. Большинство вакансий он относит к большим кластерам, а два кластера из первых трех являются неинформативными. Я использовал другой подход:
- Берем вакансию, которую хотим классифицировать. Векторизуем ее и получаем точку в нашем пространстве.
- Рассчитываем расстояние от этой точки до всех кластеров. Под расстоянием между точкой и кластером я принял среднее расстояние от этой точки до всех точек кластера.
- Кластер с наименьшим расстоянием и является предсказанным классом для выбранной вакансии. Расстояние до кластера указывает надежность такого предсказания.
- Для увеличения точности модели я выбрал расстояние 0.87 как пороговое, т.е. если расстояние до ближайшего кластера больше 0.87, то модель не классифицирует вакансию.
Для оценки модели случайным образом отобраны 30 вакансий из тестового набора. В колонке вердикт:
N/a: модель не классифицировала вакансию (расстояние > 0.87)
+: правильная классификация
-: неправильная классификация
| Вакансия | Ближайший кластер | Расстояние | Вердикт |
| 37637989 | Linux/DevOps Engineer | 0.9464 | N/a |
| 37833719 | C++ Developer | 0.8772 | N/a |
| 38324558 | Data Engineer | 0.8056 | + |
| 38517047 | C++ Developer | 0.8652 | + |
| 39053305 | Trash | 0.9914 | N/a |
| 39210270 | Data Engineer | 0.8530 | + |
| 39349530 | Frontend Developer | 0.8593 | + |
| 39402677 | Data Engineer | 0.8396 | + |
| 39415267 | C++ Developer | 0.8701 | N/a |
| 39734664 | Data Engineer | 0.8492 | + |
| 39770444 | Backend Developer | 0.8960 | N/a |
| 39770752 | Data Scientist | 0.7826 | + |
| 39795880 | Data Analyst | 0.9202 | N/a |
| 39947735 | Python Developer | 0.8657 | + |
| 39954279 | Linux/DevOps Engineer | 0.8398 | - |
| 40008770 | DevOps Engineer | 0.8634 | - |
| 40015219 | C++ Developer | 0.8405 | + |
| 40031023 | Python Developer | 0.7794 | + |
| 40072052 | Data Analyst | 0.9302 | N/a |
| 40112637 | Linux/DevOps Engineer | 0.8285 | + |
| 40164815 | Data Engineer | 0.8019 | + |
| 40186145 | Python Developer | 0.7865 | + |
| 40201231 | Data Scientist | 0.7589 | + |
| 40211477 | DevOps Engineer | 0.8680 | + |
| 40224552 | Data Scientist | 0.9473 | N/a |
| 40230011 | Linux/DevOps Engineer | 0.9298 | N/a |
| 40241704 | Trash 2 | 0.9093 | N/a |
| 40245997 | Data Analyst | 0.9800 | N/a |
| 40246898 | Data Scientist | 0.9584 | N/a |
| 40267920 | Frontend Developer | 0.8664 | + |
Итого: на 12 вакансиях нет результата, на 2 вакансиях — ошибочная классификация, на 16 вакансиях — правильная классификация. Полнота модели — 60%, точность модели — 89%.
Слабые стороны
Первая проблема — возьмем две вакансии:
Вакансия 1 — «Ведущий программист C++»
«Требования:
- Опыт разработки на C++ от 5-ти лет.
- Дополнительным плюсом будет знание Python»
Вакансия 2 — «Ведущий программист Python»С точки зрения модели эти вакансии идентичны. Я пробовал корректировать веса признаков на порядок их нахождения в тексте. Ни к чему хорошему это не привело.
«Требования:
- Опыт разработки на Python от 5-ти лет.
- Дополнительным плюсом будет знание C++»
Вторая проблема — GMM кластеризует все точки множества, как и многие алгоритмы кластеризации. Неинформативные кластеры сами по себе не являются проблемой. Но и информативные кластеры содержат выбросы. Впрочем, это легко решается очисткой кластеров, например удалением самых нетипичных точек, которые имеют наибольшее среднее расстояние до остальных точек кластера.
Другие методы
На странице cluster comparison хорошо продемонстрированы различные алгоритмы кластеризации. GMM — единственный, который дал хорошие результаты.
Остальные алгоритмы либо не работали, либо давали очень скромные результаты.
Из реализованных мной, хорошие результаты были в двух случаях:
- Выбирались точки с большой плотностью в некоторой окрестности, стоящие на удаленном расстоянии друг от друга. Точки становились центрами кластеров. Далее на основе центров начинался процесс формирования кластеров — присоединение соседних точек.
- Агломеративная кластеризация — итерационное слияние точек и кластеров. В библиотеке scikit-learn этот вид кластеризации представлен, но работает плохо. В своей реализации я менял матрицу соединений после каждой итерации слияния. Процесс останавливался по достижению некоторых граничных параметров — по факту дендрограммы не помогают понять процесс слияния, если кластеризуются 1500 элементов.
Заключение
Проведенное исследование дало мне ответы на все вопросы, которые приведены в начале статьи. Я получил практический опыт по кластеризации, когда реализовывал вариации известных алгоритмов. Очень надеюсь, что статья мотивирует читателя провести свои аналитические исследования, и чем-то поможет в этом увлекательном занятии.