
Привет хабр! Сегодня хочу поделиться своим кейсом. Обнаружение печатей позволило бы автоматизировать множество рутиных задач, упростив работу человека. Для своей задачи я использую модель Mask R-CNN.
Mask R-CNN представляет собой двухэтапную структуру: на первом этапе сканируется изображение и генерируются предложения (области, которые могут содержать объект). На втором этапе предложения классифицируются и создаются ограничивающие рамки и маски.
Что такое сегментация?
Сегментация - это задача определения контуров объекта на уровне пикселей. По сравнению с аналогичными задачами компьютерного зрения, это одна из самых сложных задач зрения.Обратите внимание на следующие вопросы:
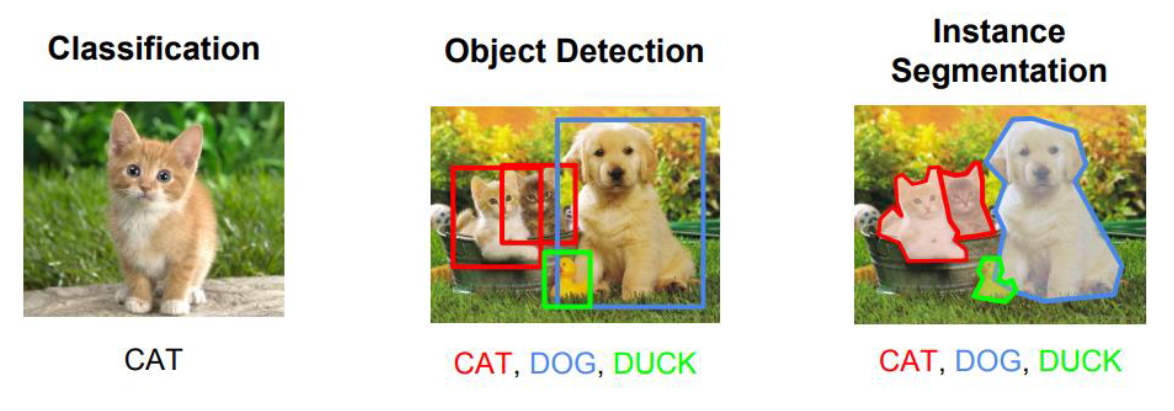
Классификация: на этом изображении есть кошка.
Обнаружение объектов: на этом изображении в этих местах есть две кошки, одна собака и утка. Мы начинаем учитывать перекрывающиеся объекты.
Сегментация: в этих местах есть 4 всплывающих окон, и это пиксели, принадлежащие каждому из них.
Подготовка набора данных для обучения
Так как, нет открытых наборов данных для печатей(по крайне мере я не нашел), я решил создать набор данных с нуля. Я искал изображения с открытых каналов глобальной паутины. Я собрал около 2 тысяч изображений разделил их на обучающий набор и набор для проверки. Искать изображения очень просто. Аннотировать их - сложная часть.
Вы наверное задаётесь вопросом, разве нам не нужен больше изображений, чем 2 тысяч для обучения модели глубокого обучения? Иногда да, но часто нет. Я полагаюсь на трансферное обучение. Это просто означает, что вместо обучения модели с нуля я начинаю с файла весов, который был обучен на наборе данных COCO (в репозитории Mask R-CNN они предоставляют его). Хотя набор данных COCO не содержит класса печатей, он содержит много других изображений (~ 120 тысяч), поэтому обученные веса уже изучили множество функций, общих для естественных изображений, что действительно помогает.
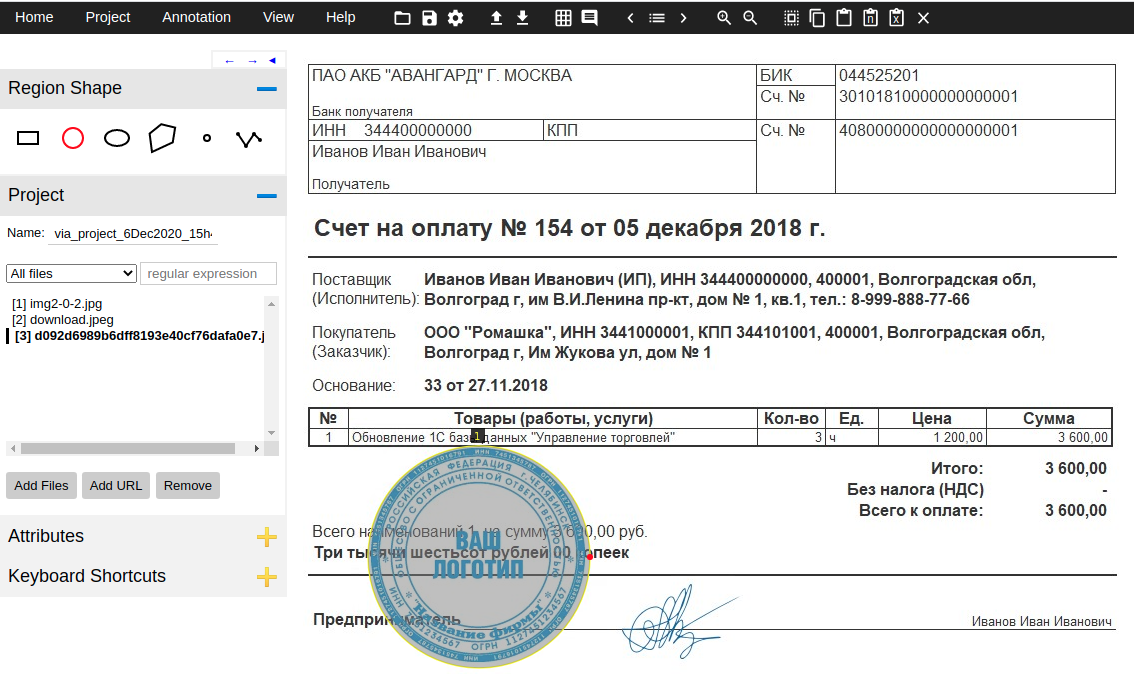
Для аннотирования изображений я использовал VIA (VGG Image Annotator). Это отдельный HTML-файл, который вы загружаете и открываете в браузере. Аннотирование первых нескольких изображений было очень медленным, но как только я привык к пользовательскому интерфейсу, я начал аннотировать объект около 20 секунд.
Загрузка набора данных
Не существует общепринятого формата для хранения масок сегментации. Некоторые наборы данных сохраняют их как изображения PNG, другие - как точки многоугольника и так далее. Для обработки всех этих случаев наша реализация предоставляет класс набора данных, который вы наследуете, а затем переопределите несколько функций для чтения ваших данных в любом формате.
Инструмент VIA сохраняет аннотации в файле JSON, и каждая маска представляет собой набор точек многоугольника. Я не нашел документации по формату, но это довольно легко понять, просмотрев сгенерированный JSON. Я включил в код комментарии, чтобы объяснить, как выполняется синтаксический анализ.
Совет по коду:простой способ написать код для нового набора данных - скопировать coco.py и изменить его в соответствии с вашими потребностями. Что я и сделал. Я сохранил новый файл как seal.py
Мой SealDataset класс выглядит так:
class SealDataset(utils.Dataset):
def load_seal(self, dataset_dir, subset):
...
def load_mask(self, image_id):
...
def image_reference(self, image_id):
...load_sealсчитывает файл JSON, извлекают аннотации и итеративно вызывает внутренние add_classи add_imageфункцию для создания набора данных.
load_maskгенерирует растровые маски для каждого объекта изображения путем рисования многоугольников.
image_referenceпросто возвращает строку, которая идентифицирует изображение для целей отладки. Здесь он просто возвращает путь к файлу изображения.
Вы могли заметить, что мой класс не содержит функций для загрузки изображений или возврата ограничивающих рамок. Функция по умолчанию load_imageв базовом Datasetклассе обрабатывает загрузку изображений. И ограничивающие прямоугольники генерируются динамически из масок.
Проверить набор данных
Чтобы убедиться, что мой новый код реализован правильно, я добавил эту записную книжку Jupyter . Он загружает набор данных, визуализирует маски и ограничивающие рамки, а также визуализирует якоря, чтобы убедиться, что размеры моих якорей подходят для размеров моих объектов. Вот пример того, что вы должны ожидать:

Совет по коду:чтобы создать этот блокнот, я скопировал файл inspect_data.ipynb , который мы написали для набора данных COCO, и изменил один блок кода вверху, чтобы вместо него загрузить набор данных Seal.
Конфигурации
Конфигурации для этого проекта аналогичны базовой конфигурации, используемой для обучения набора данных COCO, поэтому мне просто нужно было переопределить 3 значения. Как и в случае с Datasetклассом, я наследую от базового Configкласса и добавляю свои переопределения:
class SealConfig(Config):
# Give the configuration a recognizable name
NAME = "seal"
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # Background + seal
# Number of training steps per epoch
STEPS_PER_EPOCH = 100В базовой конфигурации для большей точности используются входные изображения размером 1024x1024 пикселей. Я так и оставил. Мои изображения немного меньше, но модель автоматически меняет их размер.
Обучение
Маска R-CNN - довольно большая модель. Вам нужен современный графический процессор. Я пробовал на Quadro M2000 c 4 ГБ памяти. Обучение заняло около 3-4 часов.
Начните обучение с этой команды, запущенной из seal. Здесь мы указываем, что тренировка должна начинаться с предварительно натренированных весов COCO. Код автоматически загрузит веса из нашего репозитория:
python seal.py train --dataset=/путь/к/датасету --model=cocoИ возобновить тренировку, если она остановилась:
python seal.py train --dataset=/путь/к/датасету --model=lastПроверка результатов
В записной книжке inspect_seal_model показаны результаты, полученные с помощью обученной модели. Проверьте блокнот, чтобы увидеть больше визуализаций и пошаговое руководство по конвейеру обнаружения.
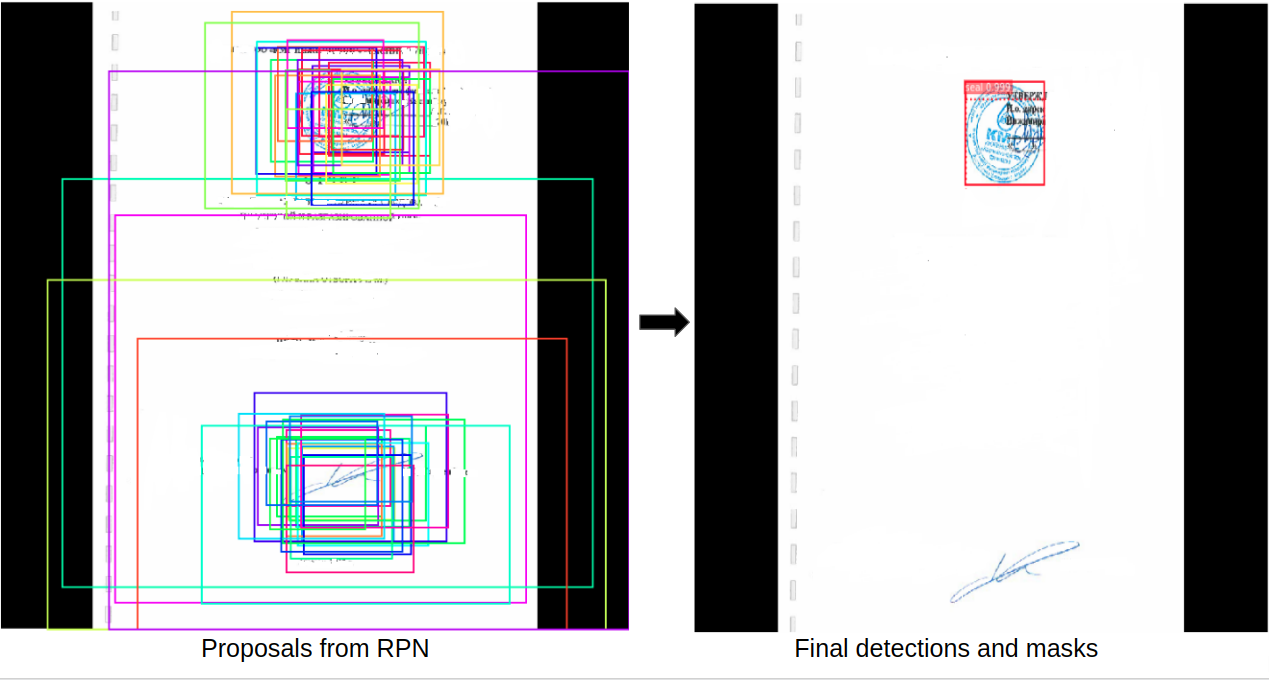
Предобученные весы для обнаружения и сегментации можете скачать здесь. Чтобы использовать, добавьте проект в папку samples в Mask R-CNN. Если есть необходимость датасета, напишите мне в почту: galym55010@gmail.com

begemot_sun
Так зачем распознавать печати?
modernToking Автор
Здравствуйте, обнаружение печатей можно использовать в крупных компаниях, где иерархия власти огромная, а передача документов происходить из рук в руки, где можно легко упустить из виду некоторые моменты, если учесть человеческий фактор. Например: при обнаружений печатей документ можно отправить в исполнение, а если нет, то в редактирование или ёще что-то.
oleg_gavrilov
А расскажите пожалуйста, зачем вот так писать? Это какая-то сео-оптимизация для самопродвижения?
modernToking Автор
Добрый день Олег, сколько людей, столько и мнений. По-моему, как писать, дело каждого. Платформа это позволяет, и я этим воспользовался. Кому то это нравится, а кому то нет. Если вам не нравится, то просто игнорьте).
begemot_sun
А подписи вы уже научились распознавать? без подписи ответственного лица ваши печати ничего не значат.