
При проведении разового анализа логирование вам не понадобится. Но в случае разработки скриптов, которые будут по расписанию запускаться в пакетном режиме, логирование упростит вам процесс определения и исправления возникающих в работе скрипта ошибок.
По умолчанию скрипты которые запускаются командой R CMD BATCH логируются в одноимённые файлы с расширением .Rout. Но такие логи неудобно читать, а анализировать невозможно.
Есть целый ряд пакетов, которые берут на себя процесс логирования. В этой статье мы рассмотрим один из наиболее функциональных и новых пакетов — lgr.

Содержание
Если вы интересуетесь анализом данных возможно вам будут интересны мои telegram и youtube каналы. Большая часть контента которых посвящены языку R.
- Введение и установка нужных пакетов
- Основные объекты пакета lgr
- Настройка логгеров и обработчиков
- Установка уровня детализации для логгера или обработчика
- Схема работы логгера
- Создаём первый логгер
- Создаём JSON логгер с поддержкой пользовательских полей
- Создаём логгер, который работает с базой данных
8.1. Создание структуры таблиц для записи логов
8.2. Макет обработчика - Пользовательский формат вывода сообщений
- Фильтрация логгеров и обработчиков
- Полезные ссылки
- Какие изменения будут внедрены в ближайшее время в lgr
- Заключение
Введение и установка нужных пакетов
Основной пакет, который мы будем в ходе этой статьи использовать это lgr.
lgr — R пакет, который реализует процесс логирования. Логика lgr была заимствована из Apache Log4j и Python logging.
Пакет реализован на основе R6 классов, если вы не знаете, что это такое, то рекомендую ознакомиться со статьёй "ООП в R (часть 2): R6 классы". Если вкратце, то R6 классы это реализация классического объектно ориентированного программирования в языке R. Тем, кто знаком с Python несложно будет вникнуть в архитектуру R6 классов.
Установить пакет возможно как из репозитория CRAN, так и из GitHub. Давайте установим наиболее актуальную стабильную версию пакета.
install.packages('lgr')Для подключения пакета необходимо использовать команду library(lgr).
Основные объекты пакета lgr
В пакет lgr входят несколько разных классов объектов, которые вы будете использовать при создании процесса логирования. Давайте разберём основные из них.
- Logger — Основной объект в
lgr, это регистратор (логгер), который создаёт событие. В свою очередь созданное событие содержит добавленные вами поля, и остальные метаданные (метка времени, название логгера и так далее), и передаёт в один или несколько обработчиков (аппендеров). Создание новых регистраторов реализуется функциямиget_logger()иget_logger_glue(). - Appender — Это обработчик вывода логов. В
lgrесть множество различных обработчиков предназначенных для записи логов в консоль, текстовые файлы, JSON файлы, базы данных и так далее. Для создания обработчика вам необходимо использовать один из существующих конструкторов:
AppenderConsole$new()— обработчик для вывода сообщений в консольAppenderFile$new()— обработчик для вывода сообщений в текстовый файлAppenderJson$new()— обработчик для вывода сообщений в JSON файлAppenderDbi$new()— обработчик для вывода сообщений в различные базы данных
- Event — Событие, которое подвергается логированию.
- Filter — Фильтры, которые вы можете добавлять в логгеры, и их аппендеры, для построения сложной логики логирования, ниже мы рассмотрим процесс создания и добавления фильтров.
- Layout — Макет, с помощью которого вы можете менять формат вывода данных логгером.
Основными объектами которые вы будете использовать являются регистраторы и обработчики. Структура объектов выглядит следующим образом:
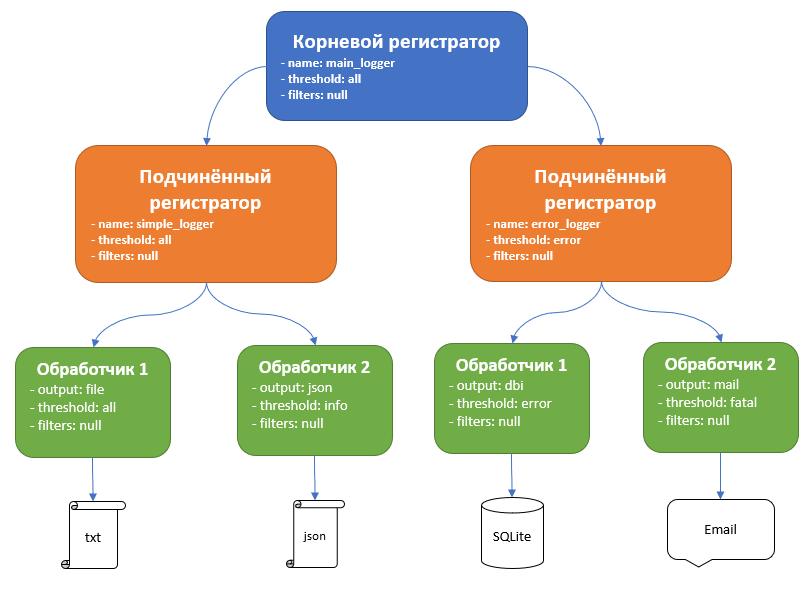
В схеме показана полная структура. Т.е. вы можете строить иерарххию логгеров, но это достаточно экзотическая структура, в основном вам будет достаточно одного логгера.
Настройка логгеров и обработчиков
Далее в статье мы подробно рассмотрим настройку логгеров и их обработчиков. А в этом разделе я всего лишь приведу основные их методы.
Методы которые можно применять и к логгерам и к обработчикам:
set_filters()— добавить фильтр на уровень логгера или обработчикаremove_filter()— удалить фильтр из логгера или обработчикаset_threshold()— установить порог детализации логгера или обработчика
Основные методы логгеров:
add_appender()— добавление обработчика в логгерremove_appender()— удаление обработчика из логгераconfig()— настройка конфигурации логгераset_propagate()— должен ли логгер передавать события в обработчики логгеров находящиеся выше по иерархии- set_exception_handler() — позволяет указать функцию, которая будет срабать если логгер столкнулся критической ошибкой при обработке события. По умолчанию отрабатывает функция
lgr::default_exception_handler().
Основные методы обработчиков:
set_file()— установка файла для записи журналаset_layout()— добавление макета изменяющего вывод записи в консольshow()— вывести записи журналаdata— вывести записи журнала в табличном виде
Конфигурацию логгера можно загружать из YAML и JSON файлов, но на данный момент этот функционал находится в разработке, и пока не поддерживает все необходимые функции.
Установка уровня детализации для логгера или обработчика
Уровни в lgr, это порог важности событий, которые необходимо фиксировать в журналах. Т.е. вы можете настроить логгер или обработчики так, что бы он фиксировал только критические ошибки, предупреждения и ошибки, а можете так, что бы в журнал записывались абсолютно все события.
Ниже приведён список встроенных по умолчанию в lgr уровней, но по необходимости вы можете добавить собственные уровни с помощью функции add_log_levels(), хотя делать это не рекомендуется.
Запросить текущие уровни можно функцией get_log_levels(), а удалить существующий уровень с помощью remove_log_levels()
| Уровень | Название | Описание |
|---|---|---|
| 0 | off | Максимально возможный уровень, предназначен для выключения логирования. |
| 100 | fatal | Серьезные ошибки, которые вызывают преждевременное прекращение работы скрипта. |
| 200 | error | Ошибки во время выполнения или неожиданные условия. |
| 300 | warn | Потенциально опасная ситуация на которую стоит обратить внимание, вызванная например через `warning()` |
| 400 | info | Уведомления во время выполнения (запуск / выключение). Т.е. просто лог работы скрипта. |
| 500 | debug | Подробная информация о потоке через систему. |
| 600 | trace | Еще более подробное сообщение, чем отладка |
| NA | all | Запись абсолютно всех событий |
Под каждый уровень в lgr есть соответствующая функция, которая инициализирует события соответствующего уровня:
lgr$info()lgr$debug()lgr$warn()lgr$error()lgr$fatal()lgr$log()— позволяет инициировать событие пользовательского уровня
Задавать порог можно по его названию или коду. Вы можете задавать требуемый порог фиксации событий на уровне логгера или его отдельных обработчиков с помощью метода $set_threshold(). Т.е. если вы устанавливаете для логгера уровень порога фиксации error, или соответствующего кода 200, то такой логгер будет передавать в свои обработчики события с кодом 200 и ниже, всё, что выше уровнем будет отфильтровываться.
Это необходимо когда к примеру вы хотите выводить обычные действия с их полями в консоль, а информацию по полученным в ходе скрипта ошибкам, с сообщением об ошибке и прочей информацией в файл или таблицу в базе данных.
Схема работы логгера
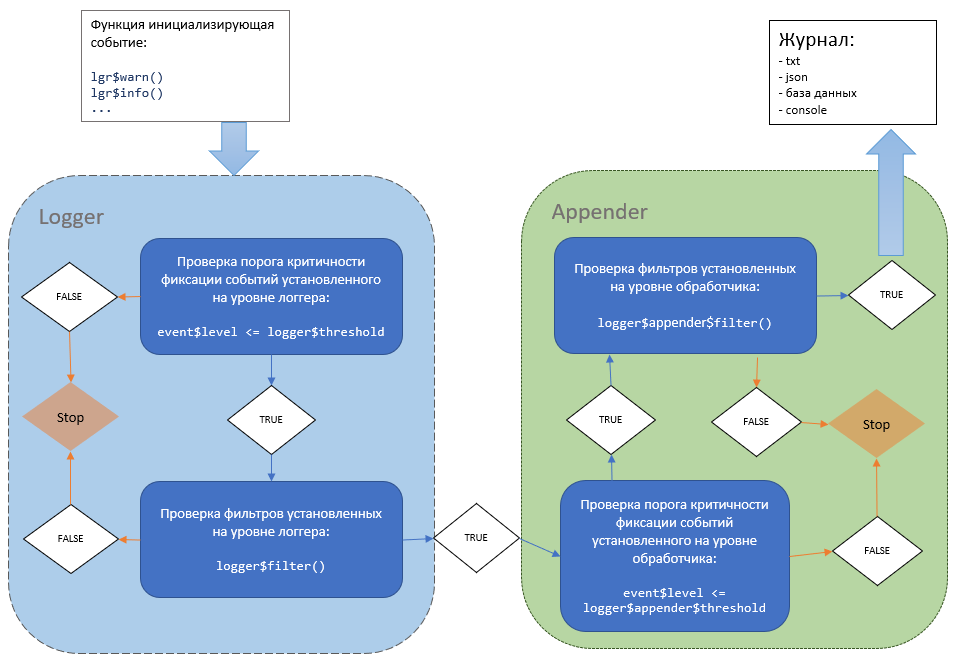
Фиксация события происходит по следующему алгоритму:
- Регистратор (Logger) инициирует начало фиксации события с помощью специальных функций (
lgr$info(),lgr$debug(),lgr$warn(),lgr$error(),lgr$fatal(),lgr$log()и т.д.). Каждая из этих функций соответствует определённому уровню важности события. В функцииlgr$log()вы можете задавать уровень самостоятельно используя аргументlevel, в который необходимо передать код или название нужного уровня события. - Проверяется установленный в логере порог фиксации события. Если уровень события равен, или ниже уровня порога логгера, событие идёт дальше.
- Проверяется фильтры логгера.
- Если событие прошло фильтр логгера, оно переходит в обработчики.
- В обработчике событие сначала фильтруется по уровню критичности установленного в самом обработчике.
- Далее проверяются фильтры обработчика.
- Если событие соответствует уровням, и фильтрам логгера и его обработчика оно регистрируется в соответствующих журналах.
Создаём первый логгер
Пакет lgr при подключении автоматически создаёт корневой логгер, в который уже добавлен аппендер с выводом сообщений в консоль.
lgr<LoggerRoot> [info] root
appenders:
console: <AppenderConsole> [all] -> consoleПри печати логгера в консоль выводится информация об имени логгера, установленном в нём уровне детализации журнала, и о типе всех добавленных в него обработчиков, и их уровнях детализации.
Несмотря на то, что при подключении пакета автоматически создаётся логгер, вы можете создать свой собственный логгер с помощью одной из двух функций:
get_logger(name, class = Logger, reset = FALSE)get_logger_glue(name)
Разница между этими функциями заключается лишь в том, что get_logger() под капотом для подстановки в свои сообщения переменных использует функцию sprintf(), а get_logger_glue() использует пакет glue.
# создаём обычный логгер
lg <- get_logger('simple logger')
# создаём glue логгер
lg_glue <- get_logger_glue('glue logger')
# создаём переменную
st <- Sys.time()
# синтаксис интерполяции строк в простом логгере
lg$info('Now %s', st)
# синтаксис интерполяции строк в glue логгере
lg_glue$info('Now {st}')Оба логгера в данном случае выведут информацию примерно следующего содержания исключительно в консоль:
INFO [17:42:04.493] Now 2020-11-25 17:40:50 Создаём JSON логгер с поддержкой пользовательских полей
Аппендер, который просто выводит информационные сообщения в консоль не особо полезен в приложениях работающих в пакетном режиме, т.к. такие логи можно просмотреть в .Rout файле, но анализировать их сложно.
Более продвинутым типом аппендера является аппендер записывающий все данные в JSON файл. Создать его можно с помощью конструктора AppenderJson$new(), в который необходимо передать путь к файлу — журналу.
# создаём аппендер
js_a <- AppenderJson$new('log.json')
# добавляем аппендер в созданный ранее логгер
lg_glue$add_appender( js_a, name = 'json' )
# задаём порог детализации в новом аппендере
lg_glue$appenders$json$set_threshold('error')
# смотрим что получилось
lg_glue<LoggerGlue> [info] glue logger
appenders:
json: <AppenderJson> [error] -> log.json
inherited appenders:
console: <AppenderConsole> [all] -> consoleТеперь в нашем регистраторе присутствует два обработчика, json фиксирует исключительно ошибки и записывает их в файл log.json, а console фиксирует сообщения всех уровней, и выводит их в консоль.
Инициируем запись информации в журналы:
# инициируем запись
lg_glue$info("Information message")
lg_glue$warn("Warning message")
lg_glue$error("Error Message")
lg_glue$fatal("Critical Error Message", user = "Username", error_data = "Error details")В последнем сообщении с критической ошибкой мы передаём 2 кастомных поля, user и error_data. На самом деле вы таким способом можете передавать любое количество дополнительных полей с различной информацией из ваших скриптов. Правда поддержка дополнительных пользовательских полей есть не во всех обработчиках, но JSON файлы и базы данных такую функцию поддерживают.
Что мы увидим в консоли:
INFO [19:49:45.444] Information message
WARN [19:49:45.460] Warning message
ERROR [19:49:45.476] Error Message
FATAL [19:51:38.232] Critical Error Message {user: Username, error_data: Error details}В консоли отобразились все 4 отправленных сообщения, потому что уровень детализации обработчика который выводит сообщения в консоль установлен на 'all'. Как вы помните это максимальный уровень детализации, который регистрирует все сообщения.
Теперь мы можем запросить данные из json журнала с помощью метода $show() и свойства data.
Метод $show() выводит информацию журнала в сыром виде:
lg_glue$appenders$json$show(){"level":200,"timestamp":"2020-11-26 19:51:38","logger":"glue logger","caller":"(shell)","msg":"Error Message"}
{"level":100,"timestamp":"2020-11-26 19:51:38","logger":"glue logger","caller":"(shell)","msg":"Critical Error Message","user":"Username","error_data":"Error details"}Свойство data возвращает журнал логов в виде таблицы.
lg_glue$appenders$json$data level timestamp logger caller msg user error_data
1 200 2020-11-26 19:51:38 glue logger (shell) Error Message <NA> <NA>
2 100 2020-11-26 19:51:38 glue logger (shell) Critical Error Message Username Error detailsКак видите в json обработчике зарегистрировано всего две записи, связано это с тем, что мы установили для него порог детализации error. На этом уровне обработчик передаёт в журнал сообщения уровня error (200) и ниже.
Записывать логи в json файлы удобно, по той причине, что вы в любой момент через свойство data можете получить записи в табличном виде, для дальнейшего анализа.
Создаём логгер, который работает с базой данных
Для логирования данных в базы нам потребуется пакет lgrExtra, который расширяет базовые возможности пакета lgr дополнительными типами обработчиков. С его помощью вы можете отправлять логи в:
- базы данных
- электронную почту
- push уведомления
На момент написания статьи пакет lgrExtra находится в стадии активной разработки и является экспериментальным. Поэтому его синтаксис может измениться в ближайшее время, но автор обещает завершить работу в январе 2021 года, и опубликовать пакет на CRAN. Пока lgrExtra доступен только на GitHub, и установить его можно командой devtools::install_github("s-fleck/lgr").
После установки и подключения lgrExtra у вас появится ряд новых типов обработчиков, среди которых будет AppenderDbi. С его помощью вы сможете писать логи в различные базы данных поддерживающиеся DBI интерфейсом. Более подробно о взаимодействии R с базами данных я писал в этой статье.
В данном случае мы разберём логирование в базы данных на примере SQLite, для чего нам потребуется пакет RSQLite.
Создание структуры таблиц для записи логов
Автор lgrExtra рекомендует предварительно создавать таблицы в базе данных через SQL команду CREATE TABLE:
CREATE TABLE log_data (
session_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"timestamp" DATETIME NOT NULL,
"level" INTEGER NOT NULL,
msg TEXT,
logger TEXT,
caller TEXT
);Макет обработчика
Есть альтернативный способ создать структуру таблицы в базе данных — задать описание столбцов с помощью конструктора макетов обработчика LayoutDbi.
Ранее я уже упоминал макеты, когда перечислял основные классы объектов в lgr. Макет позволяет вам редактировать формат вывода сообщений обработчиками. Для каждого обработчика есть свой конструктор форматов: LayoutDbi, LayoutJson, LayoutGlue и так далее.
Для построения макетов наиболее популярных баз данных есть отдельные конструкторы макетов:
LayoutSqlite— макет для SQLiteLayoutPostgres— макет для PostgreSQLLayoutMySql— макет для MySQLLayoutDb2— макет для DB2
Но мы воспользуемся общим макетом для баз данных LayoutDbi. Пример создания такой же таблицы через конструктор:
# создаём макет будущей таблицы логов
dbi_lo <- LayoutDbi$new(
col_types = c(session_id = "integer",
timestamp = "datetime",
level = "integer",
msg = "varchar(2048)",
logger = "varchar(256)",
caller = "varchar(256)"
),
fmt = "{logger} {level_name}({level}) {caller}: {toupper(msg)} {{custom: {custom}}}",
timestamp_fmt = "%Y-%m-%d %H:%M:%S"
)Далее необходимо создать логгер и обработчик:
# добавляем новый обработчик для записи логов в базу в логгер lg_glue
lg_glue$
add_appender(
name = "db",
AppenderDbi$new(
layout = dbi_lo,
conn = DBI::dbConnect(RSQLite::SQLite(), 'log.db'),
table = "log_table",
buffer_size = 0
)
)Теперь попробуем записать сообщение в журнал базы данных.
# логируем ошибку с пользовательским полем session_id
lg_glue$error("New error message", session_id = 1)
# смотрим результат
lg_glue$appenders$db$data session_id timestamp level msg logger caller
1 1 2020-12-01 19:46:27 200 New error message glue logger (shell)Мы записали информацию об ошибке с пользовательским полем session_id, вы можете таким же способом передавать в журнал любое количество пользовательских полей.
Пользовательский формат вывода сообщений
При создании обработчика для записи логов в базу данных помимо описания полей, которое мы задали с помощью аргумента col_types, мы использовали ещё два дополнительных аргумента конструктора LayoutDbi:
fmt— формат вывода логовtimestamp_fmt— формат даты и времени для вывода в журналы
В зависимости от того, какой логгер вы используете, обычный, созданный функцией get_logger() или glue логгер созданный с помощью get_glue_logger() синтаксис формата вывода в аргументе fmt так же будет меняться.
Обычный логгер для форматирования использует функцию sprintf(), вы можете в сообщение выводимое таким логгером прокидывать следующие данные, которые lgr фиксирует по умолчанию:
%t— Отметка времени сообщения, отформатированная в соответствии сtimestamp_fmt.%l— Название уровня журнала в нижнем регистре%L— Название уровня журнала в верхнем регистре%k— Первая буква уровня журнала в нижнем регистре%K— Первая буква уровня журнала в верхнем регистре%n— Уровень журнала в числовом представлении%p— Идентификатор процесса, имеет смысл использовать в случае если ваш код запускает параллельные процессы%c— Вызывающая функция$m— Сообщение%f— Все настраиваемые поля x в формате псевдо-JSON, оптимизированном для удобства чтения и вывода на консоль.%j— Все настраиваемые поля x в правильном JSON. Для этого требуется, чтобы у вас был установленjsonlite, и он не поддерживает цвета, в отличие от%f.
Вы можете задать формат при создании и добавлении нового обработчика в логгер, либо в любой момент переопределить формат вывода журнала в одном из присутствующих в логгере обработчиков.
# Определяем формат при создании и добавлении обработчика
lg$add_appender(AppenderConsole$new(
layout = LayoutFormat$new("PID: %p, [%t], %c(): [%n] %m",
colors = getOption("lgr.colors"))
)
)
lg$warn("Warn message")PID: 14016, [2020-12-08 18:44:10.097], (shell)(): [300] Warn messagelg$appenders[[1]]$layout$set_fmt(
"PID: %p \nMessage: %m\nTime: %t"
)
lg$warn("Warn message", custom = 'not critical')PID: 14016
Message: Warn message
Time: 2020-12-08 19:03:13.253Фильтрация логгеров и обработчиков
Ранее мы уже разобрались с тем, как фильтровать сообщения отправляемые в журнал с помощью установки порога уровня логирования. В некоторых ситуациях одного фильтра по уровням может быть недостаточно. В таком случае вы можете добавлять любое количество пользовательских фильтров.
Фильтры это функции, которые всегда принимают один аргумент event, и должны возвращать логическое TRUE или FALSE.
Добавить фильтр в логгер, и любой его обработчик можно с помощью метода $set_filters().
Ниже я приведу небольшой пример. Мы создадим логгер с двумя обработчиками имеющими одинаковый уровень логирования, но они будут фиксировать в журналах разные события. Один — simple appender будет фиксировать все события. Второй special appender будет фиксировать только те события, которые в пользовательском поле custom содержит пометку special.
# создаём логгер
lg <- get_logger('logger_1')
# добавляем 2 обработчика
lg$add_appender(AppenderFile$new(file = 'special.log'), name = 'special appender')
lg$add_appender(AppenderFile$new(file = 'simple.log'), name = 'simple appender')
# создаём фильтрующую функцию
filter_fun <- function(event) grepl( pattern = 'special', event$custom, ignore.case = TRUE )
# добавляем на основе созданной функции фильтр
lg$appenders$`special appender`$add_filter(filter_fun, name = 'spec_filter')
# смотрим созданный фильтр
lg$appenders$`special appender`$filters$spec_filterfunction(event) grepl( pattern = 'special', event$custom, ignore.case = TRUE )Далее инициируем несколько записей логга:
# Запись в журнал
lg$info('Обычное сообщение', custom = 'any data')
lg$info('Специальное сообщение', custom = 'special data')Посмотрим, что записал обычный обработчик:
# смотрим обычный журнал
lg$appenders$`simple appender`$show()INFO [2020-12-08 20:36:44.980] Обычное сообщение
INFO [2020-12-08 20:36:45.309] Специальное сообщениеА в специальном обработчике, при том же пороге логирования, зафиксировалось всего одно событие:
# смотрим специальный журнал
lg$appenders$`special appender`$show()INFO [2020-12-08 20:36:45.309] Специальное сообщениеИспользуем lgr совместно с tryCatch()
Наиболее эффективный вариант использования пакета lgr заключается в совместном использовании с конструкцией tryCatch(). Данная конструкция позволяет вам отлавливать и обрабатывать ошибки и предупреждения.
Если в двух словах, то конструкция tryCatch() имеет 4 основные аргумета, которые разбивают её на блоки:
- expr — основное выражение, по сути ваш рабочий код
- error — принимает безымянную функцию, которая будет выполненна если в ходе выполнения
exprскрипт остановился изза ошибки - warning — принимает безымянную функцию, которая будет выполненна если в ходе выполнения
exprвы получили предупрежденя - finnaly — часть кода которая будет выполнена в любом случае, независимо от того успешно был выполнен код в
expr, или завершился изза ошибки. Как правило в блокfinnalyпомещают разрыв соединения с базами данных или файлами.
Пример совместнго использования lgr c tryCatch():
tryCatch(
expr = {
lgr$info("Выполняется блок кода")
~ ваш код ~
lgr$debug("Выполняется шаг 1")
~ ваш код ~
lgr$debug("Выполняется шаг 2")
~ ваш код ~
lgr$debug("Выполняется шаг ...")
},
error = function(err) {
lgr$fatal(err$message)
},
warning = function(warn) {
lgr$warn(warn$message)
},
finnaly = {
lgr$info("Завершение работы кода")
}
)Более подроно ознакомится с синтаксисом и возможностями tryCatch() можно в этом видео уроке.
Полезные ссылки
Данная статья не является переводом справки, тем не менее при её написании я использовал информацию из следующих источников:
Какие изменения будут внедрены в ближайшее время в lgr
В первую очередь автор пакета собирается доработать обрабочики, которые выделены в lgrExtra. Поэтому вероятно их синтаксис поменяется.
Возможно будут добавлены новые обработчики, например я предложил автору добавить обработчик отправляющий данные в Telegram. Хочу отметить, что автор очень активно отвечает на запросы которые приходят ему на GitHub, так что каждый может поучавствовать в развитии lgr и lgrExtra.
Заключение
Т.к. пакеты lgr и lgrExtra на данный момент находятся в стадии разработки возможно их интерфейс будет меняться, а функционал расширяться, в связи с чем данная статьи периодически будет актуализироваться.
Временные затраты на добавления процесса логгирования в ваши скрипты в дальнейшем будут компенсированы экономией времени которое вам понадобится на выявление и исправление ошибок.
Если вы интересуетесь, или планируете изучать язык программирования R подписывайтесь на мой канал R4marketing в telegram и youtube. Большая часть контента канала посвящены языку R, и его применению в интернет маркетинге.