
Опыт использования новых маков с М1 начинает расставлять точки над i. Эти чипы быстрые. Очень быстрые. Но почему? В чем магия?
Я смотрел видео на Youtube, где автор купил iMac в прошлом году максимальной конфигурации. Машина с 40+ Gb ОЗУ стоила ему около 4000$. Он смотрел с недоверием, как его гипердорогой iMac был разнесен в пух и прах новеньким Mac mini с М1 на борту, который стоил около 700$.
В реальном мире, тест за тестом, макбуки с М1 не просто превосходят топовые компьютеры Intel прошлых поколений. Компьютеры Mac просто уничтожают их. С недоверием люди стали спрашивать, как такое возможно?
Если вы не один из этих людей, то вы пришли в правильное место. Здесь я расскажу простыми словами, что же такого сделали Apple с их М1. Особенно многих интересуют следующие вопросы:
В чем техническая причина того, что чип М1 такой быстрый?
Сделали ли Apple нечто экзотическое, чтобы добиться такого эффекта?
Легко ли будет Intel и AMD сделать то же самое, чтобы оставаться в гонке?
Конечно, вы пробовали гуглить эти вопросы. Если вы попытаетесь понять, что сделали Apple за поверхностными пояснениями, вас очень быстро завалит обилием технического жаргона. Например, “М1 использует блоки декодирования (very wide instruction decoders)”, “огромный буфер переупорядочивания (reorder buffer, ROB)” и т.д. Если вы не компьютерный гик, то подобные термины будут для вас просто чепухой.
Чтобы полностью погрузиться в тему, рекомендую к прочтению мою статью “What Does RISC and CISC Mean in 2020?“. В статье я объясняю, что такое микропроцессор CPU, а также разбираю концепции:
архитектура набора команд ISA
работа конвейера (Pipelining)
архитектура хранения и загрузки (load/store)
Микрокод vs микро-операции
Но если вы нетерпеливы, я опишу здесь кратко материал, достаточный для понимания этой статьи.
Что такое микропроцессор CPU?
Обычно, когда мы говорим о чипах от Intel или AMD, мы подразумеваем центральный процессор CPU. Как я уже писал в своей статье “RISC vs CISC”, процессор загружает инструкции из памяти, а затем каждая из них выполняется последовательно.
CPU на самом базовом уровне - это устройство с несколькими именованными ячейками памяти, называемыми регистрами, и некоторым количеством вычислительных юнитов, названных арифметико-логическими устройствами ALU. ALU выполняет сложение, вычитание и другие простые математические операции. Тем временем, эти устройства лишь соединены с регистрами CPU. Если вы хотите сложить два числа, то нужно сначала их получить из памяти, а затем положить в регистры. Ниже приведено несколько примеров типичных инструкций, которые и RISC процессор, и М1 В том числе выполняет:
load r1, 150
load r2, 200
add r1, r2
store r1, 310Здесь r1 и r2 - это регистры, о которых я говорил ранее. Современные RISC процессоры не способны выполнять операции над числами, которых нет в регистрах. Если даже числа лежат в оперативной памяти, то они все равно недоступны для CPU. Сначала их нужно поместить в два соответствующих регистра. В примере выше мы сначала сохраняем число из ячейки 150 в оперативной памяти в регистр r1, затем делаем то же самое для числа из ячейки 200 и сохраняем в регистре r2. Только после этого числа могут быть сложены инструкцией add. ?
Концепция регистров стара. Например, на этом старом калькуляторе регистр - это механизм, который удерживает число, используемое в операции. Прямо как настоящий кассовый аппарат. Регистр - это “расположение”, где вы регистрируете входящее число.
M1 - это не центральный процессор
Очень важная вещь, которую нужно запомнить: М1 - это не только CPU. Это система множества чипов, лежащих в одной кремниевой обертке. CPU же - это один из этих чипов. Технически, М1 - это весь компьютер на одном чипе. Он содержит CPU, графический процессор GPU, память, контроллеры I/O и множество других вещей, делающих компьютер компьютером. Это мы называем системой на чипе (system on the chip, SoC).
Сегодня, если вы покупаете чип - Intel или AMD - фактически вы покупаете большое число микропроцессоров в одной обертке. В прошлом у компьютеров было несколько физически отдельных чипов на материнской плате.
Сегодня у нас есть возможность поместить множество транзисторов на один чип, поэтому и Intel и AMD стали производить чипы со множеством микропроцессоров. Мы называем их “ядрами” процессора. Одно ядро, по сути, это полностью независимый чип, который может читать инструкции и исполнять их. Микрочип с несколькими CPU.
Долгое время это было сутью игры за повышение мощности: просто добавь еще ядер в CPU. Но кто-то взбунтовался в рядах производителей: один игрок на рынке чипов пошёл по своему пути.
Не такой уж засекреченный неоднородный способ вычислений от Apple
Вместо того, чтобы следовать тренду добавления ядер в процессор, Apple выбрала иную стратегию: они стали добавлять больше специализированных процессоров для выполнения конкретных задач. Преимущество заключается в том, что специализированные чипы, как правило, существенно быстрее выполняют свою задачу, затрачивая меньше энергии, чем CPU общего назначения.
Об этом способе было известно давно. Много лет уже как специализированные чипы GPU выполняют определенную задачу - обработку графики. Графические процессоры от Nvidia и AMD делают это гораздо быстрее, чем мог бы делать центральный процессор.
Apple лишь пошла более радикально по этому пути. Вместо множества ядер общего назначения, чип М1 внутри содержит:
Центральный процессор CPU - “мозги” системы на чипе. Выполняет большинство задач компьютера и программ
Графический процессор GPU - используется в обработке графики и изображения, в том числе и в играх.
Блок обработки изображений ISP - используется для увеличения производительности во время работы приложений по обработке графики.
Обработчик цифровых сигналов (digital signal processor, DSP) - Выполняет более сложные математические функции, чем центральный процессор, включая декомпрессию музыкальных файлов.
Блок нейронной обработки (Neural processing unit, NPU) - используется в топовых смартфонах, чтобы ускорить работу машинного обучения и AI.
Кодировщик видео (Video encoder/decoder) - для энергоэффективного преобразования видео разных форматов.
Блок безопасности (Secure Enclave) - шифрование, аутентификация и безопасность.
Блок единой памяти (Unified memory) - позволяет модулям чипа взаимодействовать максимально быстро.
Это только часть объяснения, почему люди, которые занимаются видео и графикой на компьютерах с процессором М1, отмечают прирост производительности. Дело в том, что задачи выполняются на том процессоре, который для этого был создан. Это позволяет относительно недорогому Mac mini с М1 на борту обработать графику, даже не вспотев, тогда как дорогой iMac с Intel запускает все свои кулеры охлаждения на полную мощность и все равно отстает от М1. Прочесть больше о неоднородном (heterogeneous) вычислении можно здесь: Apple M1 foreshadows Rise of RISC-V.
В чем особенность архитектуры Единой Памяти (UMA) от Apple?
Я немного лукавлю, когда говорю “Архитектура Единой Памяти (Unified Memory Architecture, UMA)”. Чтобы объяснить почему, вернемся на пару шагов назад.
Долгое время недорогие компьютеры имели центральный процессор с интегрированным графическим чипом на одной матрице. Он работал медленно. В прошлом, когда говорили “интегрированная графика”, подразумевали “слабая графика”. Эти процессоры были слабы по нескольким причинам. Первая заключается в том, что память для центрального процессора и графического была разделена. Если данные от центрального процессора должны были быть переданы графическому, то он не мог просто сказать “На, держи и используй”. CPU должен был явно скопировать этот блок данных в память графического процессора.
CPU и GPU работают с памятью по-разному. Позволим себе привести аналогию из жизни: CPU хочет, чтобы официант подал блюдо как можно быстрее, и маленькие порции не заботят процессор. Представьте себе небольшой французский ресторан, где официанты катаются на роликах.
Графический процессор, напротив, жаждет большие порции и готов подождать ради этого. Он пожирает огромнейшие куски данных, потому что этот процессор - множество чипов, которые обрабатывают данные параллельно. Представьте американскую фастфуд-закусочную, где нужно немного подождать, пока прикатят тележку еды к твоему столику.
Зная разницу в способах работы с памятью у CPU и GPU, это было не самой лучшей идеей размещать их на одной плате. GPU постоянно “голодает”, пока ему подают маленькие порции методом французской сервировки. Как результат, не имело смысла ставить производительные GPU на один чип вместе с CPU. Так самые маленькие порции данных вполне могли быть “разжеваны” слабым графическим процессором.
Вторая причина слабой графики - производимое тепло мощными GPU. По этой причине нельзя было их интегрировать с CPU, не получив проблем с охлаждением. Большинство графических дискретных карт выглядит так, как карта ниже: огромные монстры с массивными кулерами. У них есть специально выделенная память, чтобы обрабатывать огромные блоки данных.
Поэтому эти карты выдают высокую производительность. Однако у них есть ахиллесова пята: если они хотят получить какие-либо данные из памяти CPU, то эти данные передаются по медным путям, называемым шиной PCIe. Попробуйте после долгой работы попить воду через тонкую соломинку. Она быстро дойдет до вашего рта, но пропускная способность будет недостаточной.
Блок единой памяти (UMA) Apple пытается решить эти проблемы без недостатков старомодной общей памяти. Они достигают этого следующим образом:
Больше нет специально ограждённых блоков памяти для CPU или GPU. Память доступна для обоих процессоров. Они используют одни и те же ячейки памяти, копирования больше нет.
Apple ставят память, которая способна выдавать большие порции данных быстро. В техническом лексиконе это называется низкой задержкой и высокой пропускной способностью (low latency and high throughput). Как следствие, соединения между двумя раздельными областями памяти не требуется.
Apple сумели снизить потребление энергии у GPU, поэтому относительно производительные графические процессоры теперь можно интегрировать на чип без перегрева. Процессоры ARM производят в целом меньше тепла, соответственно графический чип может позволить себе нагреться сильнее до допустимых температур, чем такой же чип на матрице от Intel или AMD.
Некоторые скажут, что единая память UMA - это не новинка, и это будет правдой. Различные системы в прошлом имели схожую архитектуру, однако в них, во-первых, требования к памяти не так сильно отличались, как требования от CPU и GPU. Во вторых, то, что Nvidia называют единой памятью, на самом деле не совсем таковой являлось. В мире Nvidia “единая память” - это когда программное обеспечение и железо работают так, чтобы бесшовно копировать данные между раздельными областями памяти CPU и GPU. С точки зрения программистов единая память от Apple и от Nvidia работают одинаково, но под капотом совершенно разная архитектура.
Конечно, есть и обратная сторона такой архитектуры памяти Apple. Обеспечение широкой пропускной способности памяти требует полной интеграции, что подразумевает отсутствие возможности апгрейда железа. Apple стремится минимизировать риски, в том числе работая над увеличением скорости работы SSD дисков.
Если системы SoC такие “умные”, то почему Intel и AMD не следуют той же стратегии?
Что же такого Apple делает, что не могут делать другие производители? В некоторой степени, делают. Многие производители добавляют все чаще специализированные со-процессоры. AMD тоже начали ставить более мощные графические процессоры в свои чипы, а также они постепенно двигаются к некоторой форме “систем на чипе”, называемых Accelerated Processing Unit APU, которые являются тоже комбинацией CPU и GPU на одном чипе.
Есть еще одна важная причина, почему AMD не спешат. Чип SoC - это весь компьютер на одном чипе. Это затрудняет бизнес для нынешних производителей компьютеров вроде HP или Dell. Позвольте мне прояснить позицию: если весь ваш бизнес заточен под производство двигателей для машины, то это будет необычно начинать производить и продавать целые машины.
В случае ARM же, напротив, это не проблема. Производители компьютерных деталей могут просто купить лицензию на производство ARM и другие чипы и производить SoC с теми компонентами, которые они считают полезными. Затем они отправят готовые макеты на завод производства полупроводников вроде GlobalFoundries или TSMC, которые уже сегодня производят чипы для AMD и Apple.
Здесь возникает большая проблема, связанная с бизнес-моделью Intel и AMD. Их модель основана на продаже процессоров общего назначения, которые покупатели просто вставляют в материнские платы. Любой желающий может просто купить материнскую плату, память, CPU и видеокарту от любого производителя и собрать их в одном компьютере.
Однако мы уже уходим от этого подхода. В новом мире SoC вы не собираете компоненты от разных производителей. Вместо этого вы собираете интеллектуальную собственность на производство. Вы покупаете чертежи видеокарты, CPU, модема, IO контроллеров и других деталей компьютера от разных вендоров и интегрируете их в собственном SoC. Сейчас ни Intel, ни AMD, ни Nvidia не планируют продавать лицензию на интеллектуальную собственность на производство SoC Dell, HP или любому другому производителю.
Конечно, Intel и AMD могут начать продавать произведенные SoC. Но из каких компонентов они будут состоять? У сборщиков компьютеров есть свои соображения на этот счет. В итоге эта ситуация может перерасти в конфликт между Intel, AMD, Microsoft, потому что произведенные чипы нуждаются и в программном обеспечении.
Для Apple все просто - они контролируют весь процесс производства. Они предоставляют, например, библиотеку Core ML для машинного обучения. Сторонние разработчики не задумываются даже, работает ли их код с Core ML на CPU от Apple или Нейронном чипе (Neural Engine).
Гонка наращивания мощности CPU
Неоднородные вычисления (heterogeneous computing) - это только лишь одна из причин. Ядра общего назначения процессора М1, называемые Firestorm, действительно быстры. Это главное отличие от ARM процессоров прошлого, которые были слабы по сравнению с процессорами Intel и AMD.
Firestorm обгоняет большинство процессоров Intel и почти обходит самый быстрый чип от AMD - Ryzen. Народная мудрость гласит, что этого никогда не должно произойти. Прежде чем поговорить о том, что делает Firestorm таким быстрым, важно понять концепции увеличения мощности процессора. В принципе, вы можете комбинировать два пути увеличения скорости:
Быстрее выполнять инструкции в последовательности.
Выполнять инструкции параллельно.
В далеких 80-х это было легко. Просто увеличьте частоту процессора, и инструкции будут выполнены быстрее. Цикл процессора - это когда чип выполняет какую-то операцию. Но эта операция может быть очень маленькой. Таким образом, инструкция может потребовать несколько тактов выполнения, так как состоит из нескольких мелких операций.
Тем не менее, сегодня увеличение частоты процессора становится почти неосуществимым. Это тот самый “Конец закона Мура”, о котором люди твердят последнее десятилетие. Таким образом, у нас остаётся только увеличивать количество выполняемых инструкций в параллели.
Много ядер или процессоры “исполнения вне очереди ОоОЕ”?
Как уже говорили, есть две опции:
Добавить ядер в процессор, чтобы каждое работало в параллели и независимо.
Научить каждое ядро выполнять несколько инструкций параллельно.
С точки зрения разработчика, добавить ядер - это как добавить потоки (thread) выполнения. Каждое ядро работает как физический поток. Если вы не знаете, что такое поток, то можете воспринимать его как процесс, который выполняет какую-то задачу. С двумя ядрами CPU может выполнять две задачи параллельно в два потока. Задачей же может быть две какие-либо программы или одна и та же программа, запущенная дважды. Каждый поток имеет свое “место” в последовательности программных инструкций и временно хранит результаты выполнения.
В принципе, процессор может иметь одно ядро и выполнять программы в несколько потоков. В таком случае процессор прерывает один поток и сохраняет его состояние перед переключением на другой поток. Позже он переключится назад. Такая схема более-менее работоспособна, пока процессор не начинает часто переключаться из-за:
ожидания ввода данных пользователем
данных, которые приходят медленно из-за плохого интернета и других подобных случаев.
Это называется логическими потоками. Физические же потоки используют физические ядра для ускорения работоспособности.
Для разработчиков проблему составляют логические потоки, ведь под них необходимо специально писать мультипоточный код. Это сложно, а в прошлом это было едва ли не самой сложной задачей. Тем не менее, сервер со множеством логических потоков - это не сложно: каждый веб-запрос пользователя обрабатывается отдельным потоком. Таким образом, множество физических ядер дает ощутимое преимущество. Особенно для облачных вычислений.
Вот поэтому мы и видим процессоры ARM с безумными 128-мью ядрами. Этот чип был специально разработан для “облаков”. Вам не нужна сумасшедшая производительность от одного ядра, потому что в облачных сервисах важно наличие как можно большего количества физических ядер на 1 Ватт мощности, чтобы обработать как можно больше запросов пользователей. Более подробно о многоядерных процессорах можно прочесть в статье Are Servers Next for Apple?.
Apple же на противоположной стороне спектра устройств. Они производят устройства для одного пользователя, и множество ядер - это небольшое преимущество. Покупатели ведь используют свои компьютеры для игр, видеоредакторов и разработки программ. Они хотят девайсы с мощной графикой.
Программы для пользовательского рынка обычно не используют много ядер компьютера. Например, игры работают прекрасно и на восьмиядерных процессорах, а 128 ядер - это трата ресурсов. Тут лучше меньше ядер, но более мощных.
Как работают процессоры Out-of-Order
Чем больше параллельно выполняемых инструкций, тем быстрее процессор. Принцип выполнения Out-of-order execution (ОоОЕ) заключается в том, что инструкции выполняются параллельно и при этом эта параллельность незаметна разработчикам программного обеспечения. Об альтернативном решении можно почитать здесь: Very Long Instruction Word Microprocessors.
Разработчики не должны писать код, чтобы воспользоваться преимуществами ОоОЕ. С точки зрения разработчика это выглядит так, как будто каждое ядро работает быстрее. Прошу заметить, что это не прямая альтернатива физическим потокам. Можно использовать оба варианта в зависимости от проблемы, которую необходимо решить. Чтобы понять, как работает ОоОЕ, нужно понимать принцип работы памяти компьютера. Запрашивание данных из одного расположения работает медленно, а процессор способен запрашивать данные параллельно. Следовательно, передача 1 байта информации займет столько же времени, сколько и 100 следующих байт.
Вот вам аналогия: посмотрите на подъемники на складе, например, на этих красных роботов на фото. Постоянные перемещения по пространству и быстрое взятие объектов из близлежащих ячеек хранения. Память компьютера похожа на это. Вы можете вытащить информацию очень быстро, если она лежит в близких друг к другу ячейках.
Данные пересылаются по шине данных (databus). Это похоже на дорогу или трубу между памятью и компонентами процессора, куда данные отправляются. В реальности мы имеем даже медные дорожки на плате. Чем шире шина, тем больше байт одновременно мы можем передать.
Процессор получает блок инструкций для выполнения полностью, но выполняет их одну за другой. Современные процессоры могут выполнять их по принципу Out-of-Order-execution. Это значит, что процессор анализирует инструкции на предмет зависимости между операциями.
01: mul r1, r2, r3 // r1 < r2 ? r3
02: add r4, r1, 5 // r4 < r1 + 5
03: add r6, r2, 1 // r6 < r2 + 1Умножение - довольно тяжелая операция, она требует несколько тактов процессора. Вторая операция из последовательности выше вынуждена подождать, когда будет выполнена первая операция, так как ей требуется ее результат. Но третья операция не зависит от первых двух. Следовательно, процессор с ОоОЕ может выполнить третью операцию параллельно первым двум в отдельном потоке.
В жизни инструкций может быть тысячи, но процессор все равно способен анализировать зависимости между ними. Процессор смотрит на входные данные каждой инструкции, зависят ли они от результатов других инструкций. Например, инструкция add r4, r1, 5 зависит от значения в регистре r1, которое является результатом операции умножения. Все эти связи складываются в проработанный граф операций, с которым CPU вполне справляется: узлы - это инструкции, а линии соединения - регистры.
CPU анализирует этот граф связей, чтобы понять, какие инструкции можно выполнять параллельно, а какие - отложить, так как их входные данные еще не были получены. Большинство операций будет выполнено еще до того, как процессор обозначит их завершенными. Со стороны же всё выглядит так, как будто инструкции были выполнены в том же порядке, в котором они были поданы процессору.
В принципе, у вас есть две формы параллелизма: одну разработчики программ должны учитывать при написании кода, а вторая - неявная, которая полагается на множество транзисторов, выполняющих их на CPU с помощью магии Out-of-Order-Execution. Для небольших процессоров с малым количеством транзисторов это не будет работать эффективно.
Именно магия OoOE и делает процессор М1 таким быстрым. На данный момент этот процессор быстрее, чем любое решение от Intel или AMD, и все складывается так, как будто они и не догонят никогда Apple. Чтобы понять почему, мы должны погрузиться немного в детали.
Инструкции ISA и микро-операции
Я пропустил некоторые детали о работе ОоОЕ. Программы, загруженные в память, были собраны для конкретной архитектуры процессора ISA. Например, для x86, ARM, PowerPC, 68K, MIPS, AVR и других.
Для процессора x86 операция извлечения числа из памяти выглядит так:
MOV ax, 24У x86 регистры названы как ax, bx, cx и dx (мы ведь помним, что это именованные ячейки памяти в CPU). Такая же операция для процессора ARM будет выглядеть так:
LDR r0, 24Процессоры Intel и AMD построены на x86 архитектуре, а М1 от Apple - ARM. Внутри эти процессоры работают совершенно иначе, но программисты этого не видят. Мы описываем их работу микро-операциями (micro-ops, ?ops). С этими инструкциями железо Out-of-Order и работает.
Но почему ОоОЕ не может работать с обычным машинным кодом? Это потому что процессор вынужден хранить различную дополнительную информацию к инструкциям, чтобы иметь возможность выполнять их параллельно. Таким образом, обычная ARM инструкция может быть длиной 32 бита максимум (последовательность из 32 цифр: 0 и 1), а инструкции из микро-операций могут быть гораздо длиннее. Они содержат информацию о порядке исполнения.
01: mul r1, r2, r3 // r1 < r2 ? r3
02: add r4, r1, 5 // r4 < r1 + 5
03: add r1, r2, 1 // r1 < r2 + 1Как вы помните, мы выполняем операции 01 и 03 параллельно. И обе операции хранят результат своей работы в регистре r1. Если мы запишем результат 03 перед тем, как начнет выполняться операция 02, то вторая операция получит неверные входные данные. Следовательно, соблюдать очередность исполнения очень важно. Очередность выполнения хранится вместе с самой микро-операцией, а также хранятся и зависимости операций друг от друга.
Поэтому мы не можем написать программу специально под микро-операции, так как они содержат очень много дополнительной специфичной информации. Для двух различных ARM процессоров последовательность микро-операций может быть очень разной.
CPU может выполнять микро-операции очень быстро, потому что микро-операция - это одинарная очень простая операция. Обычно инструкции ISA могут быть очень сложными. Они состоят из множества команд, которые переводятся в микро-операции. Само слово “микро” происходит от сути операции, а не занимаемой ею памяти.
Для процессоров CISC зачастую нет других решений, кроме микро-операций, формирующих длинные последовательные цепочки. Это исключает использование ОоОЕ. Процессоры RISC же могут выбирать. Например, некоторые небольшие ARM процессоры не используют микро-операции. Но также они и не выполняют код с помощью ОоОЕ.
Почему выполнение ОоОЕ процессорами Intel и AMD уступает чипу М1?
Вы, может быть, удивлены, почему это имеет значение? Почему эта деталь важна для понимания, из-за чего Apple превосходит Intel и AMD? Суть заключается в том, как быстро вы сможете заполнить буфер микро-операций. Если у вас большой объем памяти, то ОоОЕ сможет быстрее найти независимые цепочки инструкций, которые могут быть выполнены параллельно. Но это имеет мало смысла, если у вас не получается быстро заполнять освободившееся пространство памяти после выполнения инструкций. Способность быстро заполнять буфер полагается на способность быстро нарезать машинный код на микро-операции. Устройства, которые этим занимаются, называются декодерами (decoder).
И тут мы, наконец-то, видим киллер-фичу процессора М1. Самый большой и “подлый” процессор Intel имеет на борту 4 декодера. А чип М1 - неслыханные 8 декодеров - значительно больше, чем кто бы то ни было до этого. Так можно заполнять буфер гораздо быстрее. Помимо этого, буфер для инструкций у чипа М1 больше в три раза, чем у среднего чипа в индустрии.
Почему Intel и AMD не могут добавить больше декодеров?
Здесь мы можем заметить “месть” процессоров RISC и начинаем понимать, почему чип М1 построен на базе ARM архитектуры. Видите ли, инструкция для процессора x86 может быть от 1 до 15 байтов длиной. Инструкция для RISC же имеет постоянную длину - 4 байта. Почему это важно для нас? Дело в том, что разделение потока байтов на ограниченные инструкции, чтобы “накормить” ими восемь декодеров процессора параллельно, становится тривиальной задачей, если инструкции всегда одной и той же длины.
Тем не менее, декодеры в x86 не знают, где начнется следующая инструкция. Получается, что декодерам приходится анализировать и длину инструкций. Intel и AMD решила эту задачу топорно: декодер постоянно пытается определить, является ли выполняемая операция начальной точкой инструкции. Таким образом, процессор совершает очень много неудачных попыток. Это создает очень запутанную и сложную стадию декодирования, и из-за этого действительно сложно добавить больше декодеров. Но для Apple же это становится тривиальной задачей. Фактически, 4 декодера - это максимальное число возможных декодеров для Intel и AMD.
Это и есть главная причина, почему М1 ядра Firestorm могут обрабатывать в два раза больше инструкций, чем Intel и AMD, на той же частоте процессора.
Одни могут возразить, что инструкции CISC содержат больше микро-операций. х86 инструкция превращается в две микро-операции, тогда как ARM инструкция - это одна микро-операция. Затем 4 декодера х86 обработают такое же количество микро-операций за такт, какое 8 декодеров у CPU. К сожалению, такое происходит редко в жизни. Очень оптимизированный код для x86 редко использует сложные CISC инструкции, которые могли бы быть переведены во множество микро-операций. Фактически, большая часть этих инструкций будет переведена в одинарные микро-операции.
Тем не менее, эти простые инструкции х86 не помогают Intel и AMD. Несмотря на то, что инструкции длиной в 15 байтов - редкость, декодеры все равно должны быть готовы их обработать, и это и мешает производителям добавлять больше декодеров.
Но ядра процессора AMD Zen3 ведь быстрее, так?
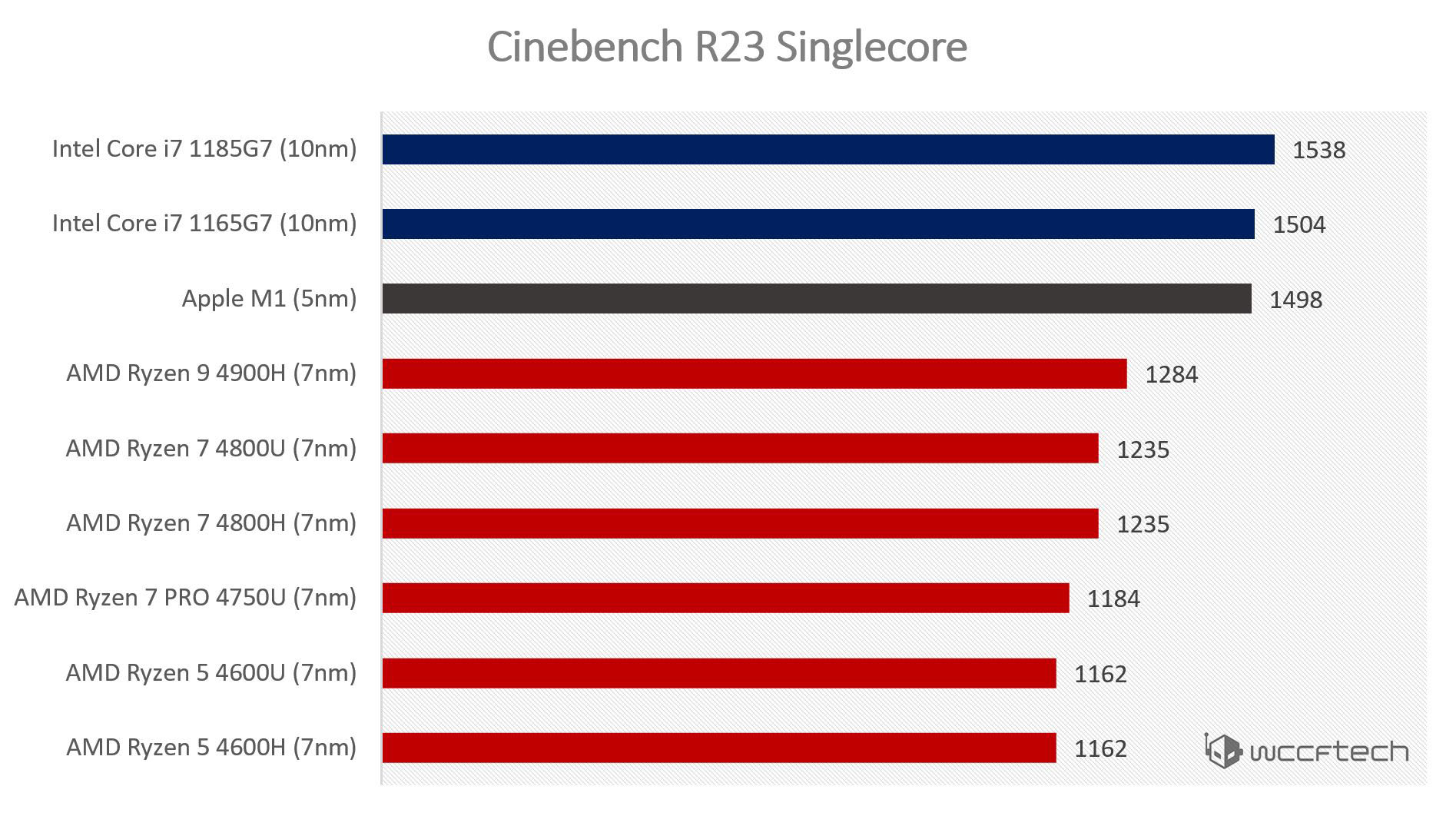
Насколько я помню из последних бенчмарков, новейшие ядра AMD Zen3 немного быстрее, чем ядра М1 Firestorm. Но здесь есть небольшой трюк - ядра Zen3 работают на частоте 5 Гц, тогда как Firestorm работают на частоте 3.2 Гц. Ядра Zen3 лишь немного превосходят Firestorm, несмотря на то, что работают на частоте выше на 60%.
Но почему же Apple тоже не повышает частоту процессора? Ответ прост - чип станет горячее. Это одна из особенностей Apple - их компьютеры не требуют сильного охлаждения, в отличие от Intel и AMD. В сущности, ядра Firestorm превосходят Zen3, тогда как Zen3 вынужден оставаться в игре за счет гораздо большего перегрева. Apple просто не выбирают этот путь.
Если Apple захотят больше мощности, они добавят больше ядер, и это позволит дать больше производительности, не увеличивая сильно потребление энергии.
Будущее
Похоже, что AMD и Intel загнали себя в угол по двум фронтам:
У них нет бизнес-модели, чтобы так же легко продолжать стратегию разнородных вычислений (heterogenous computing) и следовать SoC разработкам.
Их устаревший набор инструкций CISC теперь преследует их, не позволяя улучшать мощность Out-of-Order.
Это не значит, что игра окончена. Они могут увеличивать частоту процессора и применять больше охлаждения, подбрасывать больше ядер и наращивать объем кэша CPU. В любом случае, оба производителя в невыгодном положении. Intel даже хуже, ведь они на данный этап официально проигрывают гонку производительности, а их GPU очень слабы для интеграции в чипах SoC.
Проблема с подбрасыванием большего числа ядер заключается в том, что ядер становится слишком много. Это хорошо только для серверных станций. Тем не менее, Amazon и Ampere атакуют рынок с их монструозными 128-ядерными процессорами. Это схоже с ситуацией, когда вы боретесь на восточном и западном фронте одновременно.
К счастью для Intel и AMD, Apple не продают свои чипы на рынок, поэтому пользователи вынуждены смириться с тем, что производители чипов им предлагают. Покупатели могут лишь спрыгнуть с корабля, но этот процесс медленный. Вы не сможете быстро сменить платформу, так как инвестировали в нее уже немало. А молодые профессионалы с деньгами, которые не успели еще выбрать свою платформу, могут инвестировать все больше в Apple, укрепляя свои позиции на премиум рынке и, следовательно, свои акции на рынке ПК.
UPD от переводчика: статья вызвала бурное обсуждение, что не может не радовать. Очень много комментариев с более глубоким пояснением, как процессоры работают. Также в комментариях привели много полезных ссылок:
Is Apple silicon ready? - покажет, какие программы уже оптимизированы для М1
Apple's M1 Chip Benchmarks focused on the real-world programming
Автор оригинальной статьи не привел ссылку на то самое видео-сравнение, но тут можно посмотреть сравнение Mac mini с М1 vs Mac Pro










































{kind=link}
{kind=link}
Pro-dev-pm
Очень смешной гуглтранслейт
Harkonnen
Перевод, вроде, нормальный. У меня больше нарекания по исходному контенту.
Есть такое понятие как 'registry file' — r1 в первых двух командах и r1 в третьей технически будут разными 'r1' (этих «слотов» в современных процессорах как бы не 128-1024, точных цифр не знаю).0. Интегрированные видяшки на x86 тоже UMA (unified memory architecture).
1. Intel/AMD — тоже SoC. Южные мосты вроде как в прошлом (т.е. в чипе).
2. Почти всё начало статьи подаётся как будто в x86 нет out-of-order-execution.
3. Ничего не сказано про просуперскалярность — тут было бы к месту.
4. Ничего не сказано про branch prediction — тоже было бы к месту.
5. Ощущение, что местами hyper-threading перепутан с out-of-order-execution.
6. Но главное, что добило:
По итогу — кроме fixed-instruction-length на декодерах разницы вроде и не видно.
Viknet
Только AMD и только на консолях (но там тоже свои особенности с разными шинами к памяти и без общих кэшей). В ноутбуках/десктопах GPU просто выделяется отдельный пул памяти, в который CPU копирует данные, чтобы GPU мог с ними работать.
Кроме того, что из-за этого стало возможно сделать 8 параллельных декодеров и быстро заполнять reorder buffer в 600+ команд. У anandtech есть технический разбор микроархитектуры процессоров Apple.
Вообще эта статья для тех, кто в процессорах до этого ничего не понимал, поэтому вольно обращается с терминами.
Harkonnen
docs.microsoft.com/en-us/windows/win32/direct3d12/memory-management-strategies
Технически, по идее, не должно быть препятствий, чтобы писать в ту память хоть прямо из user-space (окромя concurrency с другими приложениями). Ну и если не из user-space, то в любом случае это будет kernel memcpy, а не проброс по PCI-E.
Viknet
Это как раз для XBox и сделано, где особенная архитектура APU и свои драйвера.
Насколько я знаю, поддержка HSA и HMM в Linux была реализована в каком-то виде под Kaveri, для специализированных задач, но статус в настоящее время непонятен.
До windows-PC и полноценных драйверов вообще дело не дошло.
Harkonnen
На XBox One, на сколько помню, диалект DirectX 11.1 (Durango) с некоторыми доп-фишками на Map/UpdateResource для UMA. На PS4 примерно та же песня на свой ляд (забыл название API). На Win10 DirectX12 давно уже работает что на встроенных в проц, что на внешних видяшках.
Antervis
Harkonnen
Интересно тогда, почему nVidia/AMD не встраивают GDDR видеопамять в чип. Нагрев?
Antervis
intel например представили пару lakefield SoC, правда это скорее продукты начального уровня. Но вообще мне кажется здесь и проявляется разница между «делать чипы для своих устройств» от apple и «делать чипы для устройств других производителей» от intel — вторые должны быть более универсальными и модульными.
stlimafon
Кто бы первым это не начал делать у вас всегда была бы возможность задать вопрос:
а «почему кто-то другой этого не делает? нагрев?»
Кто то же должен быть первым.
Остальные подтянутся. Вангую: через пару лет такие чипы с памятью и у других производителей будут не экзотикой.
JPEGEC
stlimafon
Интерес Apple к ARM древние корни имеет. Компания Advanced RISC Machines (ARM) изначально была основана как совместное предприятие между Acorn Computers, Apple Computer (сегодня — Apple Inc.) и VLSI Technology в 1990 году.
JPEGEC
Вопрос то не в этом. Вопрос почему ни один из двух основных игроков рынка этого не делал, а некий второстепенный персонаж взял и сделал.
Но в комментариях уже пояснили, что это таки делалось уже. Осталось понять почему не получило особенного развития.
stlimafon
Потому что нужен спрос.
Apple может заменять процессор. И сохранить спрос.
Поменяв ПО. Это уже было в истории Apple. У них были платформы различные — Motorola, PowerPC, Intel
Остальные «ведущие игроки» — просто железячники. На рынке ПО они не могут сделать такие вещи как «поменять ОС под новую систему команд».
Прецеденты были — Intel уже пролетала с Itanium.
JPEGEC
Основные игроки не увидели спроса на такое, и не смогли его создать или решили не заморачиваться такой суетой.
Такая мысль?
stlimafon
Они не могут создать спрос. Они железячники.
А с MS видимо не договорились тогда.
MS вовсю пилит в Windows для ARM инструментарий эмуляции x86 для него для переходного периода — только вот прямо сейчас.
Ноутбуки на ARM уже много лет как выпускались. Только они никому не были нужны. Софта-то не было. Как оказалось, массовому рынку недостаточно Linux, который нужно доводить руками. Нужны системы «сел и работай». А их только 2 — MacOS и Windows. Производство ARM ноутбуков тех — и заглохло.
Harkonnen
Я думаю, Intel пролетел с Itanium из-за наличия на рынке Sun SPARC со всем Solaris обвесом. Сейчас история могла бы быть другой. Плюс сейчас докеры, cpp-to-js-to-llvm-to-whatever, opensource-with-cmake, железо всё меньшую роль играет в vendor lock-in.
Dim0v
Потому что оба "основных игрока" связаны по рукам и ногам
1) обратной совместимостью
2) многолетним участием в производственных цепочках десятков, если не сотен производителей конечных устройств
3) наличием второго игрока, продукцией которого можно вообще без проблем заменить твою продукцию в случае, если у твоей появляются проблемы с первыми двумя пунктами.
Если бы условный интел заявил, что очередное поколение процессоров будет с памятью на SoC, которую нельзя проапгрейдить, то единственное, чего он достиг бы — это практически полной потери рынка энтузиастов и прочих само-сборщиков (которые, так уж повелось, любят периодически апгрейдиться и иметь возможность это сделать). А так же огромными потерями на OEM рынке. Т.к. хоть условному производителю ноутбуков невозможность апгрейда и не настолько критична (подавляюще большинство ноутов и так с распаянной на материнке памятью), но критична логистика и всякие цепочки поставок. Если с классической схемой он мог из абсолютно одинаковых компонентов собрать 4 разных конфигурации ноута (CPU X 4GB RAM, CPU X 8GB RAM, CPU X 12GB RAM, CPU X 16GB RAM), то с "новыми улучшенными" SoC это будет уже 4 разных компонента. И проблемы с доступностью любого из них автоматически будут означать проблемы с производством и доступностью соотв. ноутбуков. А если сюда еще добавить разные модели CPU, то и вовсе получаем квадратичный рост зависимостей.
Короче говоря, Apple может себе это позволить благодаря вертикальной интеграции и отсутствию конкуренции внутри платформы. Intel и AMD — не могут, т.к. у них такой роскоши нет.
JPEGEC
Я не понимаю почему звучит как «теперь наши процы будут с памятью на SoC».
Речь же о ситуации «а еще у нас теперь будут процессоры с памятью на SoC».
Если процы получаются сказочные то на них постепенно поползут все.
DirectoriX
Тогда придётся иметь значительно больше производственных линий, только чтобы «лепить» память на CPU.
А корпоративному рынку всё равно потребуется возможность создания нестандартных конфигураций, но если сейчас это CPU + RAM, то как будет потом? SoC не будут выпускать для корпоративного рынка? Или будет что-то вроде SoC(CPU+16 GB RAM) + RAM снаружи?
Dim0v
В таком случае эти "а еще" будут просто никому не нужны по ровно тем-же причинам. "Сказочность" памяти на SoC не решает ни одну из этих проблем. И сам по себе факт переноса памяти на SoC не делает процессор достаточно "сказочным", чтобы эти проблемы перевесить.
JPEGEC
Тогда не понимаю чего такого сказочного сделала Эпл что это перевесило все проблемы и теперь хоры оды поют.
Dim0v
Попробуйте ещё раз перечитать вот этот мой коммент https://m.habr.com/ru/post/538812/comments/#comment_22586742
Эппл не решила эти проблемы, у неё их и не было.
Хоры оды поют M1 в целом, а не памяти на SoC. Помимо памяти на SoC в нем есть ещё огромная куча отличий от процессоров «основных игроков». И часть этих отличий нельзя (или по крайней мере очень трудно) перенести на x86 by design.
JPEGEC
Про память это для простоты. Изначально вопрос был почему основные два игрока рынка не сделали то что сделала сейчас Эпл.
Эти игроки в принципе забили на ARM кусок рынка? В этом мысль?
stlimafon
Потому что этого рынка не было.
Его только-только создает Apple. Как производитель полного цикла — процессоры, компьютеры, софт — она может это сделать.
Основные два игрока — это железячники, обслуживающие имеющиеся на рынке потребности.
Чтобы AMD/Intel стали делать под ARM нужно было чтобы сподобилась сделать полноценное решение под ARM Microsoft. А чтобы Microsoft начала делать это решение — нужно чтобы AMD/Intel сделали. Заколдованный круг.
И только производитель полного цикла не имеет тут заколдованного круга.
Viknet
Но Microsoft сделала своё решение уже 3 года назад...
stlimafon
Какие три года?
Эмуляции Win64 еще нет
Эмуляция Win32 только допиливается.
Если вы про голый Windows чисто под ARM — он не нужен никому такой без эмуляции. Переходный период будет длинный.
Antervis
stlimafon
Назовите кто из производителей железа его покупал? Какие модели ноутбуков с этим процессором.
Рынок это наличие и спроса тоже.
А не наличие лишь только предложения.
Viknet
https://en.wikipedia.org/wiki/Devices_using_Qualcomm_Snapdragon_processors#Snapdragon_835,_850,_7c,_8c,_8cx_and_8cx_Gen_2
stlimafon
А где это можно купить?
Все упомянутые ноутбуки в продаже видны только в версиях с классически процессорами.
Viknet
Samsung Galaxy Book S
Lenovo Flex 5G
Surface Pro X
Более новое или только анонсировано или отменено в связи с отсутствием спроса.
stlimafon
Ага. Спроса нет. Спасибо.
И за ссылки тоже спасибо.
Antervis
Я не спорю, что без нормальной софтовой поддержки от MS windows продукты на основе ARM процов достаточно нишевые и мало кому нужные. Я лишь отрицаю утверждение про «рынка не было».
stlimafon
Именно. Аналоги новых ноутов Apple тех что на M1 у других производителей — фактически тестовые.
И да, на ARM ноуты выпускаются давно.
Но старые модели смысла не имели, ибо были тормозными, а жрали столько же сколько классические x86.
На ARM свежих, тех, что достаточно быстры для работы — в свободной продаже есть только устройства производства Apple.
Все прочие — заявлены на сайтах производителей. Но вот в наличии их нигде нет.
Буду признателен, если вы покажите, где их реально можно купить.
JPEGEC
Что такое полноценное решение? В контексте например хостера? Который масштабирует один-два сервиса на миллионные инстансы?
Мне кажется что мы по разному понимаем потребителя продукции производителя процессоров.
Xaliuss
ИМХО, потому что разработка процессоров очень сложное дело с большим количеством компромиссов. В АМД для райзенов например сделали чиплеты, где отдельно ядра, отдельно остальное, что позволило значительно улучшить выход годных кристаллов.
По примеру М1 мы видим, что чип очень большой, без возможности масштабирования по ядрам и памяти, это цена полной интеграции. Причём если для масштабирования в райзенах надо просто добавить или улучшить чиплет, добавить планку памяти, то тут задача на порядок сложнее.
Так же при сравнениях надо учитывать, что у М1 уже 5 нм процесс, что даёт им преимущество. Посмотрим, что будет, когда нанометры будут одинаковые.
Dim0v
Они не забили. Не было никакого ARM рынка. Его нужно было создать. Эппл создала.
Им это было сделать на порядок проще, потому что они контролируют свою экосистему. Им достаточно сказать "ребят, через 2 года интел не нужон" и все эта экосистема дружно перейдет на ARM. Начиная с самих процессоров, продолжая прочим железом их компьютеров, поддержкой ОС, библиотек и фреймворков. И заканчивая прикладным софтом сторонних производителей, у которых во-первых есть все инструменты для поддержки ARM, а во-вторых — банально нет выбора, т.к. через 2 года их приложения превратятся в тыкву, если не обновятся.
Intel и AMD чтобы провернуть подобный трюк нужно было бы договориться с кучей производителей промежуточных звеньев на пути от CPU к потребителю. Если любое из этих звеньев откажется участвовать в затее или не справится со своей задачей — конечный потребитель продолжит пользоваться старыми привычными x86 продуктами, в которых все работает.
Посмотрите на скорость отказа от WinXP и Win7. А это ведь намного менее радикальное изменение, чем переход на абсолютно новую архитектуру CPU. Экосистема PC очень отличается от Mac.
Поэтому переход PC мира (с Intel и AMD включительно) на ARM если и произойдет, то только в случае огромного пинка в виде намного более производительных ARM маков (и M1 — это еще недостаточно сильный пинок). И даже в таком случае этот переход для PC будет значительно труднее, болезненнее и дольше, чем для маков.
JPEGEC
Я не пойму почему вы упорно говорите о переходе PC мира на ARM?
Речь о том почему основные игроки не сделали ранее свой вариант того что сделала Эпл. На любой продукт есть свой покупатель. Если продукт на голову выше того что вокруг (даже в какой-то узкой области) заинтересованные люди быстро придумают как использовать себе на пользу. Вплоть до сборки своей оси.
Возникает предположение что либо выгода не так сильна как заявляют митингующие, либо есть какие-то нюансы (например масштабирование или тупиковость идеи в проекции будущего), ну или игроки мощно протупили.
alsoijw
JPEGEC
Откуда мне такое знать, и для чего?
Когда была необходимость портировали. Без особенных эмоций, какая разница программисту что писать в рабочее время?
Про компиляторы ничего не скажу, последний раз доводилось писать оное в качестве курсовой достаточно много лет назад. А по роду деятельности не сталкиваюсь.
alsoijw
0xd34df00d
Ну, например, у разных людей разная квалификация? И значимая часть программистов на C++ просто не будет разбираться в кишках gcc и clang?
Я уж не говорю о том, что разным людям интересны разные задачи.
0xd34df00d
А зачем каждому линуксоиду это уметь? В этом же ведь и прелесть опенсорса — достаточно суметь это сделать нескольким энтузиастам.
alsoijw
0xd34df00d
Так, опять же, в контексте портирования в пределе достаточно одного человека, чьими трудами потом будут пользоваться все остальные.
Dim0v
Не на любой, а только на законченный. В случае десктопа законченный продукт помимо процессора включает в себя еще кучу всего. В экосистеме мака эту кучу всего эппл может просто взять и сделать. В экосистеме pc нужно договориться с кучей производителей и убедить каждого из них рискнуть и вложиться в поддержку новой архитектуры.
… то во всяких узких областях ARM уже давным давно активно используется. Просто десктоп в эти узкие области не входит.
Да, есть. Я про них многократно написал уже. Нюанс в необходимости привлечения множества независимых производителей и их слаженной работы в случае с PC и в отсутствии такой необходимости в случае с mac.
JPEGEC
Вы опять за свое. Причем тут десктоп? Речь за процессоры.
Производителей чего? Цпу дали, референсный чипсет. Что еще нужно? Сейчас как-то иначе разве?
Dim0v
Так ARM процессоры давным-давно используются в своих нишах. Десктоп в эти ниши не входил. Благодаря Apple теперь вошел. Вероятно скоро и pc мир подтянется. Вон MS активизировались, стали активнее допиливать трансляцию x64.
Я перестаю понимать, в чем ваш вопрос. Почему Intel и AMD не делают ARM процессоры? Потому что целятся в массовый рынок, а не в нишевый, где каждый процессор в силу малого тиража будет стоить как крыло от самолета.
И что дальше? Зачем мне инвестировать кучу бабла в производство, скажем, материнок под этот процессор, для которого нет софта, если я могу потратить эти деньги на приклеивание еще 2 RGB лампочек к материнке, на которую точно будет огромный спрос?
JPEGEC
В чем и был вопрос. Они забили на этот сегмент рынка. Теперь понятно.
Почему нет софта если это ARM? Использование фич нового процессора потребует не просто обновленного компилятора а новых алгоритмов?
alsoijw
Dim0v
Ну возьмите какой-нибудь девайс на Windows 10 ARM и посмотрите какое там обилие софта.
Даже если для сборки ARM версии достаточно поменять один флаг компиляции (а это далеко не всегда так просто) — нужно чтобы кто-то это сделал. И потом эту версию тестировал и поддерживал. А это никому не нужно из-за размера ниши ARM десктопов.
JPEGEC
Опять вы за свое. Причем тут десктопы. Речь за процессоры.
Я может чего не понимаю и этот процессор от Эпл имеет смысл исключительно в контексте десктопа?
Тогда я вообще не вижу смысла во всем этом диалоге.
Dim0v
facepalm.jpg
То есть весь сыр-бор из-за непонимания, что процессор, созданный исключительно для десктопа (при чем мобильного) имеет смысл исключительно в контексте десктопа?
Да, в таком случае диалог определенно бессмысленный. Хотя я рад, что вы в итоге все таки пришли к этому нетривиальному умозаключению.
logran
Интелу и АМД достаточно сделать как Apple и заявить "через N лет х86 — всё, будем производить только ARM" не оставив выбора, и сразу и производители материнок подтянутся (ибо раз х86 процев не будет — под них уже не по-клепаешь) и производители софта (ибо иначе их софт будет лишь на компах N-летней давности).
Единственная сложность — это то что intel и amd должны провернуть это относительно синхронно.
Dim0v
Какая несущественная мелочь. Всего-то убедить конкурента не захватывать рынок, который ты ему добровольно отдал "через N лет", а вместо этого потратить кучу ресурсов на рискованный переход на новую архитектуру вместе с тобой.
webkumo
Даже если на секундочку подумать, что Intel и AMD не против… То тут есть пара нюансов:
Т.е. вместо взаимного гашения вопроса об лицензионных отчислениях они будут вынуждены добавлять лицензионные отчисления… и удорожать процессоры вот на ровном месте. Далее, сразу выдать "прям топчик" на новой архитектуре у них не факт, что выйдет — а это репутационные риски. Ну и для красоты добавим, что им ещё сами процессоры с нуля придётся делать. В общем — грандиозные капитало- и репутационные вложения с непонятным итогом… Ибо вероятность выжить ниже, чем при сохранении собственной ниши.
Endeavour
Что делать с полувеком legacy кода, который никто не знает как переписать?
sumanai
Эмулятор. В маке вот уже работает, в Windows на стадии дописывания.
DirectoriX
Грубо говоря если завтра Intel захочет выпустить процессор не на x86_64, а на ARM — они будут вынуждены делать его аппаратно совместимым с существующими процессорами — только потому что помимо CPU в компьютеры обычно добавляют RAM, накопители, зоопарк PCI-карт и т.д. и т.п. И даже если они сделают такой процессор (или договорятся со всеми соответствующими производителями о выпуске новых версий железа, специально для чудо-процессора) — программы сами себя не портируют.
JPEGEC
Откровенно говоря не вижу такой необходимости.
Есть старая линейка. А появляется дополнительно новая с килер фичей.
Ну а программы портируют разумеется потребители, был бы выхлоп.
DirectoriX
Это сработает только если новая линейка будет ощутимо превосходить существующую, с учётом более дорогой обвязки (потому что новая и пока что малотиражируемая) и недостатка ПО. Если новый ARM-процессор будет (условно) на 10% мощнее нового x86_64, то большинство обычных пользователей даже не подумает переходить на него в ближайшие пару лет. Корпоративные — возможно, но опять таки после портирования всего нужного ПО.
JPEGEC
Новый ARM от Эпл разве не преподносится как ощутимо превосходящий? Это разве не подтверждение правильности подхода?
Какое ПО нужно тому же хостеру или производителю систем видеонаблюдения, или систем хранения данных и тд? В чем там особенность сборки под новую целевую платформу?
DirectoriX
Преподносится — да, фактически — не очень понятно (полно противоречивых комментариев). То, что Apple решила перейти на ARM говорит только то, что Apple решила. Через год они и вовсе могу решить перейти на какую-нибудь собственную iArch — могут позволить в рамках 100% своей экосистемы.
Я не смотрел исходные коды, но вдруг условный Nginx использует ассемблерные вставки для особо критичных мест? Их портировать не очень приятно будет.а вот в видеокодеках повсеместно используют ассемблер, который точно придётся переписывать (ну или в железо выносить).
JPEGEC
Разумеется. Но портирование одного сервиса раскатывается на миллионы клиентов. И уже появляется какой-то экономический выхлоп. Понятно что если каждому клиенту портировать индивидуальный софт то можно сразу застрелиться, с ногами в тазу с бетоном на краю плотины.
А какие процессоры стоят сейчас зачастую во всех этих системах? ARM и стоит. Вопрос насколько обсуждаемый кентавр совместим с ними. И стоит ли адаптация суеты.
v12aml
Справедливости ради ARM и так есть тот самый собственный iArch. Apple — один из родоначальников ARM и один из основных владельцев.
stlimafon
Нужна критическая масса владельцев девайсов, чтобы программы начали портировать.
Нужна критическая масса программ, чтобы девайсы начали покупать.
Замкнутый круг.
Кроме Apple:
Apple, имея полный цикл производства и железа и софта и обладая внушительной властью над сторонними разработчиками — может менять платформу и уже делала это Motorola => PowerPC => Intel.
Фирма Apple может сказать и рынку (на котором она по сути монополист) и разработчикам — «или делай что я сказала, или иди в нецензурную сторону».
Кроме процессоров фирма Apple в приказном порядке это делала для многого. Хоть судьбу OpenGL и Vulkan посмотрите.
Потому что конкурентов в своей ниши у Apple нет.
И потому что Apple производит полный цикл — процессор, девайсы, софт, а также диктует свою политику разработчикам.
Ну а теперь представьте, что будет, когда тоже самое скажет какая то из фирм, поддерживающи на x86. У них у всех есть конкуренты. И клиенты уйдут к конкурентам.
В том то и дело, что киллер-фичи у M1 нет.
Это довольно хороший продукт. Но не более.
Однако у потребителей, предпочитающих Apple — нет выбора. Это не киллер-фича, это просто принуждение.
В принципе, все согласны, поскольку их пересаживают не на говно, а на процессор сопоставимый с AMD/Intel.
Antervis
ну как нет выбора то, переходить на windows никто не запрещает. А тех, кто залочен на яблоке намертво, всеже меньшинство.
Что до opengl/vulkan — без их поддержки в консолях теряется весь смысл пытаться тянуть универсальный графический api.
stlimafon
Разработка современного процессора чрезвычайно дорогостоящая.
Ради 3,14 энтузиастов это бессмысленно.
Если только энтузиасты не согласятся покупать процессор по цене самолета. А на это согласится еще меньше небольшого числа энтузиастов.
То есть вы предлагаете произвести миллионы процессоров (а иначе это экономически не рентабельно).
Выпустить на их базе миллионы ноутбуков.
Выложить эти миллионы ноутбуки без софта на полки магазинов.
Как вы думаете, сколько экземляров из этих миллионов без ОС будут проданы? 200 шт.?
Кто будет оплачивать весь этот банкет, все те годы, пока энтузиасты не запилят свою ОС?
Магазины? Производители процессоров или производители ноутбуков?
Речь то не о копеечных убытка. А о миллиардах.
Покупатель есть не на любой продукт, а на завершенный до логического конца продукт.
То есть без желания MS подключиться к проекту или кого-то тоже мощного в софтостроении — продукта не выйдет.
Условно говоря:
AMD + Asus + MS = должны договориться, чтобы сделать новый продукт.
Причем для всех трех компаний это миллиардные риски.
Зачем они им?
JPEGEC
Какие ноутбуки, о чем вы? Речь за процессоры.
Если у нового процессора будет серьезное преимущество его моментально пристроят к делу. И будут это совсем не пользователи ноутбуков и прочие игруны.
Dim0v
Повторюсь, "совсем не пользователи ноутбуков и прочие игруны" уже давно пользуются ARM процессорами
JPEGEC
Я это прекрасно знаю, но не теми прекрасными ARM о которых мы говорим. И которые, якобы, на голову выше того что есть и среди ARM и вообще.
Или ARM от Эпл это как раз для ноутов, игр и прочей бытовухи, для серьезных задач не предназначены?
sumanai
У меня есть программа, скомпилированная в 2007 году. Она достаточно хорошо работает на новейшей Windows 10. И что теперь, мне её выкинуть, так как автор её уже 100 лет не поддерживает, и даже наличие исходных кодов никак не помогает?
Dim0v
Да, именно поэтому для PC процесс перехода будет более болезненным и долгим. Спасибо за наглядную иллюстрацию.
arheops
Вспомните сколько срача было с «теперь у нас будет встроенная в процы графика, если вам не надо — не используйте».
sumanai
Благо в моём проце графики нет ))
JerleShannara
Почему не используют? Очень даже используют, правда HBM.
Harkonnen
Ну оно так себе «интегрировано», просто вплотную interposer влепили прямо к чипу, если вот эти синенькие фиговины — чипы памяти. Зато решили вопрос с нагревом :)
JerleShannara
Так у яблок точно такая-же интеграция — чиплеты www.eetasia.com/why-is-apple-m1-processor-passing-on-the-chiplets просто яблоки поставили обычную память, т.к. HBM штука очень быстрая, но дорогая. Собственно AMD HBM использует уже какое-то время в топовых решениях www.amd.com/en/technologies/hbm, как и NVidia images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
Дело в том, что технологии, по которой делается память, не очень сочетается с той, по которой делается числодробилка. С флешем тоже самое, как и с DAC/ADC. Но если интерконект сделать на кремнии и с минимальными длинами — то получаются довольно вкусные и шустрые решения.
anonymous
Дорого. В проф сегменте лет 5 минимум HBM для этого используется.
beeruser
Там используется обычная PoP память, как в любом телефоне. Разве что только для лучшего охлаждения смещена в сторону.
Какие задержки это уменьшает и на сколько?
Без цифр ваше утверждение является пустым сотрясанием воздуха.
3-х уровневый.
3-й уровень это SLC кэш размером 16МБ, для связи блоков внутри чипа. Правда до сих пор точно не понятно как ядро с ним работает.
Antervis
«As for SLC cache, that’s for flash, not for the memory subsystem.»
beeruser
Чистая спекуляция. Какие конкретно задержки это уменьшает?
Насколько эти несколько тактов значительны на фоне общей латентности памяти?
Если вы встали с утра с кровати, эти несколько сантиметров вас конечно приблизят к поверхности Марса (или отдалят), но не сильно.
Ладно, я понимаю что из вас клещами нужно цифры вытягивать.
У 9900K латентность DDR4 памяти 70 нс.
У Apple M1 с LPDDR4X — 96 нс.
Так что там уменьшается? Кроме расстояния есть и другие, более важные параметры.
Ну это совсем ржака. Человек просто перепутал SLC (Single Level Cell) область в SSD и SLC (System Level Cache) в SoC.
Apple говорит о System Cache, но ARM называет его SLC.
Вот, например, документации к шине Corelinк:
developer.arm.com/documentation/100180/0103/introduction/product-documentation-and-design-flow
«Configurables include size and device placement and an optional System Level Cache (SLC).»
developer.arm.com/documentation/100180/0103/slc-memory-system/about-the-slc-memory-system
Я конечно криво написал про System Level Cache — cache, но Андрей из Анандтек так же облажался :) «Такова селяви»(с)
Собственно там не только кэш, но и свитч и coherence point. Всё в одном.
Вот патент Apple на системный кэш:
patents.google.com/patent/US20140075125
Antervis
Про кеш теперь еще более непонятно становится. Я в курсе что там L2 уже общий между ядрами, и не понимаю зачем тогда SLC и какую роль он играет.
beeruser
Вообще-то там такты (clocks).
210 тактов на 4ГГц это около 52нс. Т.е. даже меньше.
Я хотел использовать другой график (с нс шкалой), но там не было подписано значение.
Согласно 7-cpu www.7-cpu.com/cpu/Skylake.html
«RAM Latency = 42 cycles + 51 ns (i7-6700 Skylake)»
На частоте 4ГГц, 42 такта это 10,5 нс.
Итого получаем 63,5нс для DDR4-2400 памяти.
ЕМНИП, другие измерения что я встречал, доходили до 67-70нс.
Между процессорными ядрами. В каждом кластере L2 свой.
У больших ядер 12МБ, у маленьких 4МБ.
Связь всех основных блоков чипа — CPU, GPU, NPU, ISP и других.
Для эффективного обмена данными и кэш когерентности.
Antervis
спасибо за разъяснения
dakuan
Ммм… а не северный?
sumanai
Весь северный и половина южного.
czz
На EPYC уже даже и южного нет.
tongohiti
Ох уж эти загадочные Entrance/Exit Controllers…