
ARPANET навсегда изменил мир компьютеров, доказав, что компьютеры совершенно различных производителей можно соединять при помощи стандартизированных протоколов. В своём посте об исторической значимости ARPANET я упомянул некоторые из этих протоколов, но не описывал их. Поэтому мне захотелось изучить их подробнее. Кроме того, я хотел понять, какая часть структуры этих первых протоколов дожила до протоколов, которые мы используем сегодня.
Протоколы ARPANET, как и современные Интернет-протоколы, были упорядочены в слои. Протоколы верхних слоёв работали поверх протоколов нижних слоёв. Сегодня стек TCP/IP имеет пять слоёв (физический, канальный, сетевой, транспортный и прикладной), но у ARPANET было всего три слоя (или четыре, смотря как считать).
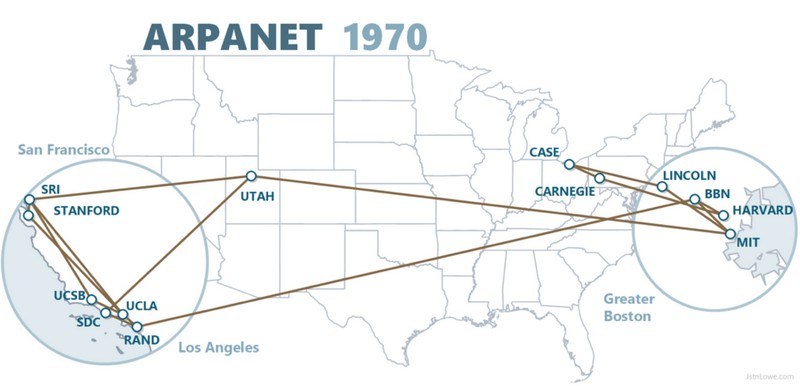
Ниже я расскажу, как работал каждый из этих слоёв, но для начала сделаем краткое отступление, чтобы рассказать, кто создавал ARPANET и чем конкретно занималась каждая из сторон. Это поможет вам понять, почему слои были разделены именно так.
Краткая историческая справка
ARPANET финансировался федеральным правительством США, и в частности Управлением перспективных исследовательских проектов (Advanced Research Projects Agency, ARPA), подчинённым Министерству обороны (отсюда и название ARPANET). Правительство США не создавало сеть самостоятельно; вместо этого оно отдало работу на аутсорс бостонской консалтинговой фирме Bolt, Beranek and Newman, более известной как BBN.
BBN, в свою очередь, взяла на себя бОльшую часть задач по реализации сети, но не весь проект целиком. BBN занималась проектированием и поддержкой машины, называемой Interface Message Processor (IMP). IMP представлял собой модернизированный микрокомпьютер Honeywell, каждый из таких компьютеров отправлялся в те учреждения по всей стране, которые должны были подключаться к ARPANET. IMP использовался в качестве шлюза в ARPANET для четырёх хостов в каждой из точек. BBN контролировала выполняемое на компьютерах IMP ПО, передающее пакеты от одного IMP к другому IMP, однако фирма не имела непосредственного контроля над машинами, подключавшимися к IMP и становившимися истинными хостами ARPANET.
Машины-хосты контролировались учёными-компьютерщиками, которые были конечными пользователями сети. Эти учёные в местах использования хостов по всей стране отвечали за написание программного обеспечения, которое бы позволило хостам общаться друг с другом. IMP предоставляли хостам возможность передавать сообщения друг другу, но это не было особо полезно, если бы хосты не согласовали используемый для сообщений формат. Для решения этой проблемы была собрана разношёрстная команда, в основном состоящая из аспирантов различных учебных заведений, где находились хосты. Эта команда самостоятельно организовала Network Working Group, занимавшуюся созданием спецификаций протоколов для использования компьютерами-хостами.
То есть если представить единичное успешное сетевое взаимодействие через ARPANET (допустим, отправку электронного письма), то за некоторые части её реализации, обеспечивающие успешное взаимодействие, отвечал один коллектив людей (BBN), а за другие части отвечал другой коллектив (Network Working Group и инженеры в каждой из точек размещения хостов). Такое организационное и логистическое стечение обстоятельств, вероятно, сыграло важную роль в выборе «слоистой» архитектуры протоколов ARPANET, что, в свою очередь, повлияло на реализацию TCP/IP в виде слоёв.
Итак, вернёмся к протоколам

Иерархия протокола ARPANET.
Слои протокола были упорядочены в иерархию. В самом низу находился «уровень 0» (level 0). Это слой, который в каком-то смысле «не считается», потому что в ARPANET его целиком контролировала фирма BBN, а значит, нужда в стандартном протоколе отсутствовала. Level 0 управлял тем, как данные передаются между IMP. У BBN были внутренние правила о том, как IMP должны это делать; для всех, кто не работал в BBN, подсеть IMP оставалась «чёрным ящиком», просто передающим любые отправленные ему данные. То есть level 0 был слоем без настоящего протокола, не являлся публично открытым и общепринятым перечнем правил и его существование могло полностью игнорироваться программами, работающими на хостах ARPANET. Грубо говоря, он обрабатывал всё, что сегодня относится к физическому, канальному и сетевому слоям стека TCP/IP, и даже выполнял довольно большую часть функций транспортного слоя, но к этому мы вернёмся в конце поста.
Слой level 1 устанавливал интерфейс между хостами ARPANET и IMP, к которым они были подключены. Можно сказать, что это был API для «чёрного ящика» level 0, созданного BBN. В то время его также называли IMP-Host Protocol. Этот протокол нужно было написать и опубликовать, потому что при первоначальной подготовке ARPANET каждое учреждение с хостами должно было писать собственное ПО, обеспечивающее интерфейс с IMP. Они бы не знали, как это сделать, без помощи BBN.
Спецификация IMP-Host Protocol была записана BBN в длинном документе под названием BBN
Report 1822. В процессе эволюции ARPANET было выпущено много новых версий документа; в посте я приблизительно опишу то, как работала изначальная версия IMP-Host Protocol. Согласно правилам BBN, хосты могли передавать компьютерам IMP сообщения длиной не более 8095 бит, и каждое сообщение содержало leader (заголовок), в котором указывался номер хоста-получателя, а также нечто под названием link number (номер канала). IMP считывал номер хоста-получателя и послушно переправлял сообщение в сеть. При получении сообщений от удалённого хоста принимающий IMP заменял номер хоста-получателя на номер хоста-отправителя, а потом передавал его на локальный хост. Между самими IMP передавались не сами сообщения — IMP разбивали сообщения на мелкие пакеты для передачи по сети, однако эта особенность была сокрыта от хостов.

Формат заголовка сообщений, передаваемых между хостом и IMP, каким он был в 1969 году. Схема из BBN Report 1763.
Номер канала, который мог быть любым числом от 0 до 255, выполнял две задачи. Он использовался протоколами более высокого уровня для установки нескольких каналов связи между любыми двумя хостами в сети, потому что в текущий момент времени с хостом-получателем вполне могло общаться несколько локальных пользователей. (Другими словами, номера каналов позволяли мультиплексировать связь между хостами.) Однако также он использовался в слое level 1 для управления объёмом трафика, который можно передавать между хостами, это было необходимо для того, чтобы быстрые компьютеры не перегружали сообщениями медленные. В изначальном проекте IMP-Host Protocol ограничивал каждый хост, позволяя одновременно передавать по одному каналу всего одно сообщение. После того, как хост передал сообщение по каналу удалённому хосту, ему нужно было ждать от удалённого IMP специальное сообщение под названием RFNM (Request for Next Message), прежде чем отправлять следующее сообщение по тому же каналу. Следующие версии этой системы, созданные для повышения пропускной способности, позволяли хосту одновременно передавать другому хосту по одному каналу до восьми сообщений.
Самое интересное начинается в слое level 2, потому что этот и последующий слои BBN и Министерство обороны отдали на откуп учёными и Network Working Group, позволив изобретать их самостоятельно. Слой level 2 представлял собой Host-Host Protocol, черновик которого изначально был выпущен в RFC 9, а первая его официальная спецификация появилась в RFC 54. Более удобочитаемое объяснение Host-Host Protocol представлено в ARPANET Protocol Handbook.
Host-Host Protocol управлял тем, как хосты создавали соединения друг с другом и управляли ими. Соединение — это односторонняя линия передачи данных между сокетом записи одного хоста и сокетом считывания другого. Концепция «сокетов» (socket) была добавлена поверх имевшей ограничения системы каналов level 1 (не забывайте, что номер канала иметь только 256 значений), чтобы предоставить программам возможность адресации определённого процесса, работающего на удалённом хосте. Сокеты считывания имели нечётные номера; функция сокета (считывание или запись) назывались его «гендером». В протоколе не было «номеров портов», как в TCP. Соединения можно было открывать, манипулировать ими и закрывать их при помощи специально отформатированных контрольных сообщений Host-Host, передаваемых между хостами по каналу 0, зарезервированному для этой цели. После того, как был произведён обмен сообщениями по каналу 0 для установки соединения, дальнейшие сообщения с данными можно было передавать по каналу с другим номером, выбранным получателем.
Контрольные сообщения Host-Host идентифицировались трёхбуквенной мнемоникой. Соединение устанавливалось, когда два хоста обменивались сообщением STR (sender-to-receiver) и соответствующим сообщением RTS (receiver-to-sender) — эти контрольные сообщения назывались сообщениями Request for Connection (запроса на подключение). Соединения можно было закрывать контрольным сообщением CLS (close). Существовали и другие контрольные сообщения, менявшие частоту передачи сообщений с данными от отправителя к получателю, что опять-таки нужно было для того, чтобы быстрые хосты не перегружали медленные. Управление потоками, реализованное в протоколе level 1, очевидно, было недостаточным для level 2; я подозреваю, что так получилось из-за того, что получение RFNM от удалённого IMP гарантировало только то, что удалённый IMP передал сообщение на хост-получатель, а не то, что хост полностью его обработал. Также существовали контрольные сообщения INR (interrupt-by-receiver) и INS (interrupt-by-sender), которые в основном использовались протоколами более высокого уровня.
Все высокоуровневые протоколы находились на level 3, то есть на прикладном слое ARPANET. Вероятно, самым важным из этих протоколов был Telnet, обеспечивавший виртуальное телетайпное подключение к другому хосту, но на этом уровне было и много других протоколов, например, FTP для передачи файлов и различные эксперименты с протоколами для отправки электронной почты.
Один протокол с этого уровня не походил на остальные, это Initial Connection Protocol (ICP). ICP считался протоколом level 3, но на самом деле был протоколом level 2.5, поскольку от него зависели другие протоколы level 3. ICP был необходим потому, что соединения, обеспечиваемые Host-Host Protocol на level 2, были только односторонними, однако большинству приложений для выполнения каких-то интересных задач требовалось двустороннее (т.е. полнодуплексное) соединение. ICP задавал двухэтапный процесс, при котором запущенный на одном хосте клиент подключался к долговременно работающим процессом-сервером на другом хосте. Первый этап заключался в установке одностороннего подключения от сервера к клиенту при помощи известного номера сокета процесса-сервера. После установки соединения сервер отправлял по нему клиенту новый номер сокета. Затем установленное соединение прекращалось и открывалось два новых соединения, одно для считывания, использующее переданный номер сокета, другое для записи, использующее тот же переданный номер плюс один. Этот небольшой танец был необходимой прелюдией для большинства действий, например, он был первым этапом установки соединения Telnet.
На этом наш подъём по иерархии протоколов ARPANET завершён. Вы могли ожидать, что рано или поздно я упомяну Network Control Protocol. Прежде чем я приступил к исследованиям для подготовки к этому посту, я считал, что ARPANET управлялся протоколом под названием NCP. Этой аббревиатурой иногда обозначали протоколы ARPANET в целом. Вероятно, именно поэтому у меня появилась такая мысль. Например, в RFC 801 говорится о переходе ARPANET с NCP на TCP, и это заставляет думать, что NCP это протокол ARPANET, эквивалентный TCP. Но Network Control Protocol для ARPANET никогда не существовало (хоть так и считает Encyclopedia Britannica), и я подозреваю, что люди ошибочно расшифровывали NCP как Network Control Protocol, но на самом деле это означало Network Control Program. Программа Network Control Program была программой уровня ядра, работающей на каждом хосте, отвечающем за управление сетевыми коммуникациями. Она была эквивалентом стека TCP/IP в современных операционных системах. Аббревиатура NCP, используемая в RFC 801, это псевдоним, а не протокол.
Сравнение с TCP/IP
Позже все протоколы ARPANET были вытеснены протоколами TCP/IP (за исключением Telnet и FTP, которые легко адаптировали для работы поверх TCP). Все протоколы ARPANET основывались на предположении о том, что сеть создавалась и управлялась одной организацией (BBN), а стек протоколов TCP/IP проектировался под Интер-нет, сеть сетей, где всё будет более гибким и ненадёжным. Это привело к появлению одних из наиболее очевидных отличий между современными протоколами и протоколами ARPANET, а именно к тому, как сегодня мы разделяем сетевой и транспортный слои. В ARPANET функции транспортного протокола частично выполняли IMP, а позже за них стали отвечать исключительно хосты в конечных точках сети.
Однако самым интересным в протоколах ARPANET мне кажется то, что большой объём функций транспортного слоя, присутствующий сегодня TCP, прошёл этап незрелой юности ARPANET. Я не специалист по сетям, поэтому мне пришлось достать свой учебник по сетям из колледжа (Куросе и Росс, на помощь!), и в нём нашлось достаточно неплохое краткое описание того, за что в целом отвечает транспортный слой. Протокол транспортного слоя минимально должен выполнять следующие задачи. Сегмент здесь, по сути, является термином, аналогичным сообщению в ARPANET:
- Обеспечивать службу доставки между процессами, а не просто хостами (мультиплексирование и демультиплексирование транспортного слоя)
- Обеспечивать проверку целостности каждого сегмента (то есть проверять, что при передаче не произошла порча данных)
Кроме того, транспортный слой, как и TCP, может обеспечивать надёжную передачу данных, то есть:
- Сегменты доставляются по порядку
- Потерянные сегменты отсутствуют
- Сегменты не доставляются так быстро, что отбрасываются получателем (управление потоками)
Похоже, в ARPANET существовала некоторая запутанность в способе реализации мультиплексирования и демультиплексирования для обмена данными процессов — BBN реализовала для этого номер канала на уровне IMP-Host, но оказалось, что всё равно поверх него требуются номера сокетов на уровне Host-Host. Поэтому номер канала использовался только для управления потоками на уровне IMP-Host, но BBN, похоже в дальнейшем отказалась от этой схемы в пользу управления потоками между уникальными парами хостов, то есть изначально номер канала был перегруженным элементом, а позже, по сути, стал рудиментарным. Сегодня TCP использует вместо них номера портов, выполняя управление потоками отдельно для каждого TCP-соединения. Мультиплексирование и демультиплексирование уровня «процесс-процесс» происходит целиком внутри TCP и не «утекает» на нижний слой, как это было в ARPANET.
К тому же, в свете того, как Куросе и Росс развивают идеи, лежащие в основе TCP, любопытно было увидеть, что ARPANET начинались с того, что авторы учебника назвали бы реализацией надёжной передачи данных на уровне IMP-Host при помощи строгого подхода «остановиться и ждать». Принцип «остановиться и ждать» заключается в том, что после передачи сегмента узел отказывается передавать любые другие сегменты, пока не получит подтверждение получения последнего переданного сегмента. Это простое решение, но оно означает, что в любой момент времени по сети передаётся только один сегмент, из-за чего протокол оказывается очень медленным. Именно поэтому Куросе и Росс назвали подход «остановиться и ждать» просто переходным этапом на пути к полнофункциональному протоколу транспортного слоя. В ARPANET какое-то время использовался подход «остановиться и ждать», поскольку на уровне IMP-Host перед отправкой дальнейших сообщений нужно было получить Request for Next Message в ответ на каждое исходящее сообщение. Но надо отдать должное BBN, поначалу она считала, что это будет необходимо для обеспечения управления потоками между хостами, поэтому замедление было намеренным. Как я говорил выше, требование RFNM позже было смягчено ради повышения скорости, а IMP начали прикреплять к сообщениям порядковые номера и отслеживать «окна» передаваемых сообщений примерно так же, как сегодня это делается в реализациях TCP.
Итак, пример ARPANET продемонстрировал, то обмен данными между неоднородными вычислительными системами возможен, если всем сторонам удастся договориться об общих правилах. Как говорилось ранее, это и есть самое важное наследие ARPANET. Но я ещё и надеюсь на то, что внимательное изучение этих правил показало вам, что принципы протоколов ARPANET ещё и сильно повлияли на протоколы, которые мы используем сегодня. Разумеется, разделение функций транспортного слоя между хостами и IMP было очень неуклюжим, а иногда и избыточным. И сегодня нам может показаться забавным, что хосты поначалу могли одновременно отправлять друг другу по любому из каналов только одно сообщение. Однако эксперименты с ARPANET стали уникальной возможностью получить эти уроки благодаря реализации настоящей сети и управления ею; похоже, эти уроки пошли впрок, когда пришло время совершенствования системы и превращения её в тот Интернет, который мы используем сегодня.