

Вступление
Мониторинг информационной безопасности автоматизируют с использованием различных средств защиты: LM/SIEM, UBA/UEBA, IRP/SOAR, TIP, IDS/IPS, NTA, EDR. Объединение решений по классам одновременно и удобно, и условно. Системы одного типа отличаются не только количеством функций, но и своей философией. Вернёмся к этой идее позже.
Эти решения давно есть на рынке, но при внедрении мне, как сотруднику интегратора ИБ с большим практическим опытом, приходится сталкиваться с проблемами. Непонимание принципов работы этих инструментов приводит к попыткам «приготовить» их неправильно. Даже успешный пилот – не гарантия успешного внедрения.
Все участники рынка со стороны исполнителя – интеграторы, дистрибьюторы, сервис провайдеры (далее просто «интеграторы») и производители – коммерческие компании. Но конкуренция растёт и для беспечной старости уже недостаточно, как в нулевых, «как-то» закрыть прибыльный проект и убежать в закат. Техническая поддержка, модернизация и развитие, смежные проекты – основной источник дохода в наши дни. И он не существует без нахождения в едином понятийном поле, обмена знаниями и принятия стратегий совместно с заказчиками.
Этой статьёй я хочу внести свои пять копеек в решение проблемы. Перед тем как перейти к технической составляющей, рассмотрим два связанных с ней вопроса.
Статья рассчитана на тех, кто уже задумался о мониторинге ИБ, но ещё не погрузился в тему глубоко. Поэтому в ней не раскрываются такие базовые термины, как "событие", "мониторинг", "аналитик", "пилот" ("пилотный проект"). Смысловые компоненты, вкладываемые в них, различаются в зависимости от того, кто их применяет. А хорошее описание с обоснованием, почему именно так их определяем, может потянуть на отдельную статью.
Что нам стоит SOC построить
Чем выше бюджет проекта, чем больше проект политизирован, тем сложнее изменить его вводные. Но для решения вопросов безопасности тоже действует принцип Парето. Добивать самые трудоёмкие 1-5-10% договора, которые не будут заметны в общем результате, не выгодно ни одной из его сторон. Проект лучше разбивать на этапы, а не гнаться за постройкой условного SOC с нуля. Это позволит учесть опыт предыдущих стадий и минимизировать риски по реализации нереализуемого, а часто и не нужного.
Итоговые цели нужно как ставить, так и пересматривать. А когда они зафиксированы в договоре, это практически невозможно. Например, база данных, с которой по грандиозному плану будут собираться события аудита, упадёт под дополнительной нагрузкой, вызванной этим самым аудитом. Но в техническое задание уже заложено требование по написанию ранбука на основе данных источника и реализации его в IRP. Переходим к правкам по ходу пьесы?
Декомпозицию на этапы можно производить вплоть до подключения «вот этих 5 видов источников» или создания «вот этих 10 сценариев и ранбуков к ним». Главное – это не полнота внедрения, а полнота использования того, что внедрено. Обосновать модернизацию эффективного решения проще, чем того, которое всплывает два раза в год в негативном контексте и стоит в десять раз дороже.
Если не знаете, что точно хотите и можете получить от автоматизации – просите пилотный проект. Но если не понимаете, что вам надо «без автоматизации» – от кого будете защищаться, куда и как ему было бы интересно проникнуть, что вам с этим делать – преимуществ от пилота будет мало. В технической части вы, вероятно, совершите скачок. Но подходит ли вам конкретный продукт – сказать будет сложно. Тут нужен консалтинг, а не внедрение технических решений. Пока вы не определитесь, что хотите автоматизировать, выбор конкретной системы не будет обоснованным. То, что показалось достаточным в ходе сегодняшнего пилота, завтра придётся подпирать костылями.
Пилот должен проводиться в рамках разумного. Я знаю организацию, которая столкнулась с невозможностью масштабирования после закупки. Не первый раз просят пилот, в котором у SIEM 30 графических панелей, 40 видов источников, 50 правил корреляции и 60 отчётов. Сделайте, а мы подумаем, покупать или обойдёмся. Интересы сторон должны сходиться. В той же части масштабирования можно согласовать решение с производителем и, например, заручиться от него гарантийным письмом.
Эти новые решения класса _подставить_нужное_ - только очередная трата денег
А может построим ИБ без технических средств? Есть оценка рисков, вы вольны выбрать одну из стратегий: избегание, минимизация, передача и принятие. По какой-то логике вы выбираете минимизацию. Дальше уже не важно, как вы будете её реализовывать. Чью экспертизу задействовать – положитесь на защиту от вредоносов с помощью антивирусов, будете пытаться блокировать их на подлёте, внедрив решение типа IPS, или выберете гибридный вариант? Будут ваши затраты входить в CAPEX из-за внедрения средства защиты в инфраструктуре предприятия или весь ЦОД, вместе с системами обеспечения безопасности, поедет в облако, попадая в OPEX? Доверитесь встроенным решениям от облачного провайдера, или, уйдя в облака, предпочтёте наложенные средства? Технические средства служат автоматизации или привносят экспертизу, подсвечивая расхождения текущего состояния с лучшими практиками? Всё это будет не интересно руководству, которое спросит только, удалось ли минимизировать риски и сколько это стоит.
Хотя важен не подход, а результат, лучший вариант – соблюдение баланса между трудозатратами сотрудников и использованием систем защиты. Можно пытаться обходиться без технических решений. Но если компания развивается и растёт, то растут и риски, как качественно, так и количественно. А вслед за ними – желание этими рисками управлять. В том числе, за счёт улучшения качества мониторинга – увеличения его «площади» (сегментов сети, тактик, техник) и «глубины» (не очевидное использование тех же техник, уменьшение порогов срабатывания). Чем больше угроз вы мониторите, тем больше аналитиков вам потребуется. Специалисты в дефиците, а растить их приходится годами.
Автоматизировать те, и только те процессы, которые достигли зрелости – хорошая идея. Да, на начальном этапе это трудозатраты и дополнительные требования к персоналу. Но после выполнения проекта подход приносит плоды в части операционных затрат. Другой ответ на вопрос «зачем» – не устраивает время реакции на инцидент. Если десять аналитиков примутся за одну задачу, результат не будет получен в десять раз быстрее. Но если доверить что-то автоматике, это достижимо.
Важно отличать полезное, новое техническое средство от ребрендинга чего-то старого. А систему, которая принесёт вам пользу уже сейчас, от той, которая будет мигать огоньками в стойке. А когда понадобится – устареет.
Перейдем к техническим средствам системы мониторинга.
1. Log Management
Первым этапом может быть Log Management (LM) в виде специализированного решения или унифицированного варианта, типа Elastic Stack. Вы получите централизованное хранилище журналов событий различных источников, которые приведены к единой модели данных «из коробки» или под ваши требования рядом нехитрых манипуляций. Система обеспечивает простой, гибкий и производительный поиск по событиям, отчёты и визуальные панели (дашборды) на основе таких поисков.
Почему полезно начать с данного этапа, а не сразу переходить к SIEM? Это дешевле, а решаемые в процессе внедрения вопросы одинаковые. Учитывайте и стоимость поддержки от покупки до перевода в промышленную эксплуатацию – 30-60% от стоимости в год. Растянулся проект на два года – скупой платит дважды в прямом смысле слова.
Система может продолжить работать рядом с SIEM для экономии его лицензионной квоты одновременно с хранением дополнительных данных для расследований и Threat Hunting-а. Или её можно модернизировать в SIEM: некоторые производители предлагают такой вариант.
Какие задачи стоит решить при внедрении решения LM:
Определить перечень источников, настроек аудита, полей событий и способов сбора; подключить все типы источников, чтобы определить все связанные риски. Модель нарушителя, модель угроз и оценка рисков – это шаг номер ноль в построении системы мониторинга. Но как эти документы конвертируются в перечень источников и настройки их аудита? С типовыми решениями типа операционных систем или активного сетевого оборудования всё более или менее понятно. Есть читшиты по EventID, примеры поиска угроз с использованием их событий и т.д. Но при подключении какой-нибудь системы ip-телефонии всё может быть не так тривиально. Набор полей генерируемого события не закроет потребности расследования. Представление событий на источнике будет отличаться от того, что он отдаёт вовне. Цель подключения теряется, но договор дороже денег.
Да, эту подготовительную работу можно произвести без LM, обратившись к событиям на источнике напрямую. Но в предложенном подходе кроется ряд возможностей:
Изучение логов в производительной среде. Попробуйте поискать события на Windows Event Collector, агрегирующем данные с трёхсот хостов, с помощью встроенных инструментов. Поиск растягивается на минуты, если вообще завершается корректно. А возможности настройки фильтрации очень ограничены.
Оценка нагрузки на источник от передачи событий в стороннюю систему. Заодно можно изучить и нагрузку на сеть. Помню случай, когда трафик проходил через межсетевой экран по пути от одной подсети сегмента в другую (о чём заказчик предпочёл умолчать). Поток Syslog-событий большого объёма привёл к отказу в обслуживании на данном файрволе.
Понимание, необходимы ли вам дополнительные логгеры на существующих источниках по результатам расследований. События Sysmon могут быть информативнее событий Windows. А Auditbeats фиксирует то же, что и auditd, но не дробит единое событие на четыре строки, что требует дополнительной корреляции и лицензионной квоты. Если такие логгеры нужны, как вы будете ими управлять? Часть решений стабильны, часть оставляет желать лучшего. Это всплывает только при масштабировании. Готовы ли вы «платить» за их преимущества?
Оценка потока событий. У интеграторов и производителей есть калькуляторы, чтобы теоретически прикинуть это значение. Но я видел межсетевые экраны, которые давали как 50 событий в секунду, так и 12000. Нагрузка, под которой находится устройство, пиковые скачки данных и когда они происходят, что из событий будет отфильтровано – всё это калькуляторы не учтут. А лицензия уже заложена в бюджет.
На примере сбора событий рассмотрим различие в философии решений одного класса. Что вы собираете и в какую модель данных складываете, хочется оптимизировать хотя бы со стороны лицензии и объёма хранилища. Но один вендор рекомендует собирать только те события, которые нужны, и вытаскивать из них только то, что полезно. И вообще, сделать всё, чтобы не размывать фокус аналитика. Что же тут интересного? В этой системе такая философия реализована вкладкой, позволяющей посмотреть сгруппированные данные по всем событиям и провалиться в искомые. Есть возможность хранить с различными сроками одни метаданные событий для операционной деятельности и другие для комлайенса и отчётности. Удобно устанавливать предварительные фильтры и способы отображения данных не только для ограничения доступа, но и для удобства оператора. Нужен ли вам такой подход? Зависит от задач. Но близкое знакомство с этой, шестой для меня SIEM, изменило представление о классе решений в целом.
Привести инфраструктуру в соответствие с политиками и регламентами. Для большинства этих кейсов корреляция не требуется. Но без такого порядка борьба со сложными угрозами не будет результативна. Действительно ли межсетевое взаимодействие идёт только по разрешенным портам? Все ли пользователи работают через корпоративный браузер? Используются ли где-то вместо технических персональные учётные записи? Вопросов к ИТ здесь может возникнуть масса. И теперь у вас есть инструмент для их решения. Идеализировать не стоит – инфраструктура меняется быстро, лес рубят – щепки летят. Но поэтапно закручивать гайки не в ущерб бизнесу – вполне.
Организовать Threat Hunting и расследование инцидентов. LM для данной задачи – единственная необходимая платформа. Вы видите подбор пароля на котроллере домена по событиям 4776, в которых виден только FQDN атакующего, и он отсутствует в DNS. Что делать дальше? Есть ли у вас логи рабочих станций и серверов с соотносимыми 4625? Аутентифицируются ли устройства при подключении к сети? Существует ли актуальная CMDB и процедуры её обновления? Кто может в обход VPN подключаться удалённо? Что делать, если подбор пароля идёт через почтовый сервер? Эти вопросы могут привести вас к мысли о необходимости сбора дополнительных событий или внедрения отсутствующих средств защиты. Также результаты расследований должны привести к решению следующих задач:
Определить список критичных инцидентов и создать для них ранбуки или плейбуки (далее – ранбуки, как более пригодный для автоматизации вариант). Это утвердит алгоритм и результаты расследований. Станет понятно, что автоматизировать с помощью SIEM. Возможно, вы решите пойти по моделям в ИБ систематически или решите свои критичные задачи. Важно понять, хватает ли вам информации, чтобы отличить нормальную активность от инцидента, и к кому с ним идти. Сможете ли вы оперативно заблокировать учётную запись или порт, или ИТ потребуется на это неделя? Результаты корреляции настолько же важны, насколько их отсутствие, если их некому анализировать, а, обнаружив угрозу, вы не в состоянии её подтвердить и устранить.
Устранить ложно положительные (ЛПС) и ложно отрицательные (ЛОС) «срабатывания». Под срабатываниями понимают автоматическое создание подозрения на инцидент в SIEM. Но ими можно считать и результаты ручной работы. Что если любое прилетающее обновление ПО вызовет шквал фолсов? Или события генерируются не тогда, когда вы этого ожидаете, и вы пропускаете угрозу. Или требуется дополнительная информация, чтобы отличить штатную работу от инцидента. Если ЛПС или ЛОС будет слишком много, смысл автоматической корреляции теряется. Возможно, стоит посмотреть на проблему под иным углом: искать более подходящие индикаторы. Инцидент – это не атомарное действие, а целый Kill Chain. Злоумышленник оставляет множество следов. Если у вас нет способа засечь атакующего на одном шаге, ловите на другом. Говорят, что безопасность – это сложно достижимое состояние. Потому что команда защитников одна, а команд атакующих – целая плеяда. Но верно и обратное – если злоумышленнику надо успешно завершить каждый шаг атаки, то защитнику достаточно обнаружить его на любой стадии. После этого легко размотать всю последовательность действий.
Результаты использования LM:
Логи собираются в централизованное хранилище, доступное аналитику для поисковых запросов, построения отчётов и визуальных панелей. Это позволяет оперативно проверять гипотезы (Threat Hunting) и обеспечивает единую консоль для анализа данных всех средств защиты.
Для значительной части вопросов и проблем, которые возникнут при внедрении системы следующего уровня, уже выработаны решения.
Определены перечни инцидентов для мониторинга. Аналитик выявляет, расследует и реагирует на данные инциденты по ранбукам, попутно уменьшая ЛОС и ЛПС.
Состояние инфраструктуры приведено в соответствие с политиками и стандартами.
Возможность и способ сбора событий, их состав и объём определены и управляемы.
Следующий этап зрелости – переход от LM к SIEM. Мы пойдём более кратко: этот раздел уже создал нам базу.
2. SIEM
Переход от LM к системам класса Security Information and Event Management требуется в двух случаях:
Необходимо оповещение операторов о подозрениях на инциденты (далее - инциденты) в режиме близком к реальному времени. К этой опции должны прилагаться сотрудники, работающие в том же режиме - 24х7.
Необходимо выявление последовательностей разнородных событий. Это уже не просто фильтрация и агрегация, как в LM или Sigma (на текущий момент).
Дополнительно вы получите:
Правила «из коробки», которые хороши в качестве примеров или отправной точки. Или после глубокой доработки и настройки.
Историческую корреляцию, совмещающую преимущества SIEM (структура корреляционного запроса) и LM (работа с данными на всю глубину). Быстрое тестирование нового правила на исторических данных, проверка только что пришедшего IOC, который обнаружен две недели назад, запуск правил с большими временными окнами в неурочное время – всё это применения данной функции. Она может быть частью базового решения, требовать отдельных лицензий или вовсе отсутствовать.
Второстепенные для одних, но критичные для других функции. Иное представление данных на дашбордах, отправка отчётов в мессенджер, гибкое управление хранением событий и т.д. Производитель стремится оправдать скачок цены от LM к SIEM.
Задачи на этом этапе следующие:
Создание логики детектирования всех интересных вам инцидентов. Без автоматизации вам приходилось выбирать только самые критичные. Сейчас можно учесть всё действительно важное. Главный вопрос – как на таком потоке выстроить реагирование.
Уменьшение ЛПС и ЛОС путём обогащения данных – добавления информации из внешних справочников, изменения пороговых значений, дробления правил по сегментам, группам пользователей и т.д. Возросший объём статистики по работе сценариев улучшает качество их анализа.
Обе задачи решаем итерационно. Хороший показатель – 15 инцидентов на смену аналитика. Достигли его – закручиваем гайки дальше.
Начинаем оценивать эффективность расследования – время на приём в работу инцидента, время на реагирование, время на устранение последствий и т.д. И пытаться этой эффективностью управлять – что мешает работать быстрее, где основные задержки?
Результаты использования SIEM:
Выявление инцидентов происходит в автоматическом режиме, возможно обнаружение и корреляция цепочек разнородных событий.
Рост числа типов инцидентов. Аналитик переключает внимание с обнаружения на расследование и реагирование. При этом не стоит забывать про Threat Hunting – этот метод остаётся лучшим для определения новых для вас угроз.
Какой шаг сделать дальше? Тут лучших практик нет. Следующие этапы могут идти последовательно в любом порядке, параллельно или вовсе отсутствовать.
3. UBA или UEBA
Некоторые решения данного класса являются самостоятельными продуктами. Но многие вендоры SIEM предоставляют его в виде модуля. Кто-то говорит, что он заменяется набором правил (а кто-то даже заменяет). Какие возможности даёт это техническое средство?
Если в двух словах – это антифрод, только более универсальный. Идеи в основе схожи. Если подробнее – каждое подозрительное действие, совершенное пользователем (User в User Behavior Analysis) или и пользователем, и сущностью (Entity в UEBA; чаще всего это хост), приводит к добавлению баллов. После достижения определённой суммы создаётся подозрение на инцидент или аналитик сам следит за ТОП10-20-50 подозрительных пользователей. «Репутация» обеляется со временем. Например, сумма баллов уменьшается на фиксированную величину или процент каждый час. Работа с такими данными не отличается от стандартных подозрений на инциденты.
Такой подход полезен в двух случаях:
Индикаторы, считающиеся подозрительными, не могут в одиночку свидетельствовать о возникновении инцидента.
Использование статистики или машинного обучения (такими границами производители обозначают алгоритмы в составе решений) над вашими данными выдвигает и проверяет гипотезы, которые сложно тестировать вручную или с помощью корреляции. Например, сравнение сущности с остальными представителями ее группы. Почему сотрудник маркетинга ходит на какой-то ресурс, если его коллеги этого не делают? Ему нужны такие полномочия? На AD DC в 2 раза больше попыток аутентификации, чем на других. Это ИТ или ИБ проблема? Важно сформировать вводные для алгоритмов – от пороговых значений, до групп сущностей.
Результат использования U(E)BA – выявление угроз методами с высоким ЛПС или методами, для которых невозможно создать и поддерживать простой алгоритм без ущерба для качества обнаружения инцидентов.
4. IRP или SOAR
Эти термины изначально говорили о разных системах: Incident Response Platform и Security Orchestration, Automation and Response (или Report). Но современные решения расположились по всей палитре между этими огнями и поэтому термины стали синонимами с широким диапазоном значений.
Основных функций у этих систем четыре:
Тикетница. В карточке инцидента аналитики получают задачи, комментируют их выполнение, передают активности между сменами и т.д.
Создание ранбуков. Варианты функционала различны: просто графическое представление алгоритма действий, оно же с функцией отображения хода расследования или расширенный вариант – каждый из шагов алгоритма может быть автоматизирован скриптом.
Автоматизированное реагирование на инциденты. Каждый шаг алгоритма может быть выполнен вручную, автоматизировано или автоматически. Зависит только от уровня контроля человеком, который вы хотите оставить. Блокировать ли в автоматическом режиме учётную запись для предотвращения развития инцидента? А если это ЛПС? А если это учётка главного бухгалтера в день выдачи заработной платы? А если это учётка администратора домена и через минуту будет поздно? Производитель даёт набор интеграций из коробки и инструменты создания практически любых пользовательских вариантов с использованием нескольких языков программирования.
Анализ метрик эффективности SOC, доступных системе.
Это специализированный сервис деск с функцией исполнения скриптов. Если у вас получится закрыть часть требований встроенным функционалом, вам необходимо получить более простые и стабильные способы работы со скриптами или дать службе мониторинга отдельный от ИТ инструмент со специализированным интерфейсом – это решения для вас.
Автоматизация способна ускорить реагирование на часть кейсов на 1-2 порядка. Но далеко не в каждом случае. Второй вариант использования – учёт действий аналитика. Если в инциденте участвует критичный актив, например, АСУ ТП, каждый шаг должен быть выполнен компетентным сотрудником, который ответственен за решение; ничего не должно быть пропущено, лог реагирования сохранён. Здесь будут преимущества от использования даже полностью «ручных» ранбуков. Таким образом систему можно применить к любому инциденту, сочетая оба варианта использования в разных пропорциях.
Результата использования IRP/SOAR:
Алгоритмы решения всех инцидентов собраны воедино, выстроен автоматизированный процесс расследования и реагирования.
Ведётся лог действий по реагированию, что позволяет как контролировать его в ручном режиме, так и собирать метрики для оценки эффективность процесса.
5. TIP
TIP или TI Platform – это средство обработки входящего Threat Intelligence. TI – это тема для отдельной статьи. Тут под TI будем понимать лишь малую его часть: перечни IOC – IP, FQDN, хэшей и т.д., считающихся злонамеренными; а под пользой TI – сокращение разрыва между первым обнаружением атаки где-то в мире и возможностью выявлять её у нас в инфраструктуре.
Разве нельзя IOC использовать в средствах защиты напрямую, зачем TIP? Этот класс решений предоставляет функционал управления TI – нормализация, обогащение, дедупликация, приоритезация, хранение, устаревание, удаление. Эти задачи могут реализовываться в ручном, автоматизированном или автоматическом режиме.
В систему приходит IOC и подвергается нормализации – приведению к единому набору полей заданного формата. С ним можно связать другие индикаторы – узнать FQDN по IP или всё семейство хэшей по исходному. Если IOC уже есть в базе – добавить атрибуты, например, что мы видели его в данных ещё одного источника в такое-то время. И присвоить ему оценку. Пришёл с трёх источников – достовернее, оценка выше; IOC в виде IP с источника X – уменьшаем оценку, IP от этих ребят быстро устаревают; индикатор ложный – обнуляем вручную. Оценка падает с течением времени – угроза либо теряет актуальность сама по себе (пирамида боли в действии), либо производители средств защиты блокируют её более рационально, чем по IOC.
При работе с индикатором аналитик исследует гипотезу, подтверждает или опровергает её, строит граф связей, а если не успевает закончить – ставит задачи или оставляет комментарии для следующей смены. Всё тот же функционал сервис деска, теперь в составе TIP.
Результат использования TIP – на средства защиты, в том числе в систему мониторинга, попадает более качественный, однозначно трактуемый и актуальный TI. А перечни IOC сокращаются на порядок, что позволяет повысить эффективность средств защиты, их использующих.
6. IDS или IPS
Этот класс решений скорее всего уже внедрён вами как отдельное средство защиты. Он позволяет анализировать копию трафика (Detection в Intrusion Detection Systems) или блокировать вредоносную активность (Prevention). Современные решения работают в гибридном режиме. Это аналог антивируса для сети. Основным методом обнаружения угроз являются сигнатуры, от обновления которых производителем или сообществом (в случае opensource решения) зависит эффективность работы системы. Специалисту или даже отделу сложно угнаться за скоростью обновления такой низкоуровневой логики при самостоятельной разработке. При этом основных сетевых протоколов несколько десятков, что делает решение «из коробки» довольно эффективным. По крайней мере, не так сильно зависящим от инфраструктуры, как хостовые средства защиты.
Пользовательские сигнатуры позволяют часть логики корреляции, относящейся к сети, вынести во внешнее относительно SIEM устройство. Это отлично дополняет SIEM, даже если он анализирует копию трафика.
Результат использования IDS/IPS:
Угрозы на уровне сети выявляются в автоматическом режиме с высоким качеством. Нетиповые атаки закрываются пользовательским контентом или несигнатурными модулями – поведенческий анализ, выявление IOC и т.д.
SIEM получает готовые подозрения на инциденты. Если корреляция и требуется, то это корреляция второго и выше уровней.
7. NTA и NBA
У вас уже скорее всего есть SIEM, который получает агрегированные данные трафика в форматах NetFlow, sFlow, jFlow, Packeteer или сам создаёт такие агрегаты из копии трафика. Их основные данные – информация L3 и L4 OSI. Также, у вас скорее всего внедрён IDS/IPS, который не записывает трафик, но анализирует его полную копию от L2 до L7, насколько позволяет шифрование.
Если эти средства не решили ваши задачи, можно дополнить систему мониторинга с помощью Network Traffic Analysis. Это решение производит запись трафика для его последующего исследования. При планировании стоит учесть гораздо больший по сравнению с LM/SIEM объем хранилища и необходимость предварительной расшифровки данных.
Трафик объединяет в себе и информацию, и факт её передачи. В отличие от событий, генерация которых избирательна, он полностью описывает, что произошло между двумя взаимодействующими системами, и его нельзя удалить или сфабриковать. События собираются в LM или SIEM с некоторой задержкой, если это не Syslog, в случае которого возможен спуфинг. А если успеть очистить журнал источника – действие, подозрительное само по себе – что точно случилось узнать будет трудно.
Также можно использовать решения класса Network Behavior Analysis – аналог U(E)BA для сети со всеми его преимуществами и недостатками, но с парой особенностей. Во-первых, эти решения гораздо чаще выпускаются в виде обособленных продуктов. Во-вторых, как мы уже говорили в части 6, основных сетевых протоколов несколько десятков, что делает решение «из коробки» довольно эффективным.
Результат использования NTA и NBA – у вас есть аналоги SIEM и U(E)BA, позволяющие использовать все особенности трафика.
8. EDR
Постепенно ряд производителей включает решения данного класса в состав уже существующих агентов – антивирусной защиты, систем защиты от утечек данных и т.д. Но оно несёт принципиально другой функционал – это дополнительная телеметрия (Detection в Endpoint Detection and Response) и возможности по реагированию (Response).
Телеметрия расширяет и унифицирует функции штатных журналов операционных систем. То, что раньше выявлялось SIEM на основе нескольких событий или не выявлялось вовсе, теперь фиксируется как единая запись агента EDR, обогащённая различными метаданными. И, насколько это возможно, не зависит от семейства и версии операционной системы, на которую установлен агент.
Реагирование средствами EDR делает процесс локальным и увеличивает его стабильность.
Так как к этому этапу у вас уже выстроены процессы обнаружения и реагирования, при оценке эффективности от внедрения EDR можно приложить решение к каждому из них и понять, какой плюс будет в конкретном случае и суммарно.
Результат использования EDR – расширенная телеметрия и локальное автоматизированное реагирование.
Заключение
Рассмотренные нами решения являются одновременно и специализированными, и универсальными. Поэтому они не соберутся в единую систему как кубики. Каждый придётся дорабатывать напильником не только для стыковки друг с другом, но и с вашими задачами и процессами. Это стоит учитывать при планировании сроков проекта.
Если вы ещё не строили подобных систем, ваши знания, а соответственно, и требования к техническим решениям будут меняться по ходу проекта. В процессе его реализации будут эволюционировать инфраструктура, угрозы безопасности, сам бизнес. И после достижения цели – создания системы – изменения продолжатся. Проект живой, его не уложить на бумагу от и до. Это стоит учесть при планировании задач проекта и создании технических требований к его решениям.
Поэтому важен поэтапный подход. В обозримые сроки вы получаете то, что запланировали. Берёте паузу и добиваетесь максимума эффективности, попутно понимая, чего не хватает. Переходите к следующему этапу, который может быть как развитием системы, так и модернизацией или заменой её существующих компонентов.
Эта статья – описание технических решений. Она поможет выделить такие этапы. За кадром остались ценные для мониторинга, но более обособленные решения: почти все средства защиты, VM, CMDB и т.д. Не забудьте и о них.
13oz
По ходу чтения возникло много вопросов, в какой-то момент перестал записывать.
ELK для LM — такое себе решение. Да, многое умеет «из коробки», но отсутствие агрегации и крайне тяжкий кросс-индексный поиск — это проблема. Со вторым еще можно жить, а вот требования к хранилищу будут очень жесткие.
Точно знаете, что такое threat hunting? А гипотезы генерировать специалисты будут, видимо, из головы, и никаких знаний о том, какие TTP, кто и против кого применяет, нам не нужно. Как и IOC. Не считая того, что, вообще-то, это один из самых сложных процессов, и главная его проблема даже не в технических решениях, а в рабочей силе — людей, умеющих делать TH, на рынке не много.
Откуда такая интересная и странная метрика? И такая однозначная? А если у заказчика инфраструктура на 8 часовых поясов и на 20к+ источников данных, не считая сетевого оборудования?
Глобально, тема поднята интересная, но:
Смешанные чувства оставила статья. Тема интересная, но раскрыта однобоко и странно.
ANosarev Автор
Статья обзорная, она не ставит перед собой цель уйти глубоко в детали. Её задача — выработать общий понятийный аппарат с теми, для кого направление мониторинга не основное, а одно из многих. Для непрофильных компаний это частая история. Всё, что выглядит как технические детали призвано иллюстрировать необходимость, а не создать законченное видение автора, и уж тем более не заменить необходимость разработки проектной документации. Любое из направлений, обозначенных в статье, можно расписать на книгу или несколько и это будет не истина в последний инстанции, так как здесь пересекается множество плоскостей — техническая, организационная, экономическая и пр.
Далее кратко по пунктам:
Может быть, но это не останавливает производителей от его использования. Я знаю минимум 4 отечественных SIEM на нём. Зарубежные появились раньше ELK, поэтому у них почти всегда самописные базы, они не показатель. Это не мешает производителю самого ELK строить SIEM на нём, исходя из запросов заказчиков. Попутно дорабатывая кросс-кластерный поиск и агрегацию, что прослеживается по последним релизам. А дальше сравнение, плюсы и минусы можно на отдельную статью или цикл расписать. Я бы такую с удовольствием прочитал.
Использование LM как основного и почти единственного инструмента для TH это не моя оригинальная мысль, достаточно посмотреть эфиры некоторых русскоязычных ресурсов на эту тему за последний месяц. И основные источники гипотез для начинающих в этом направлений свой путь тоже очень простые и не требуют технических средств — модели ИБ (тот же ATT&CK), бюллетени уязвимостей, да даже новостные рассылки, тот же Exchange несколько недель назад упомянули все, даже не отраслевые СМИ и новостные каналы.
Дальше можно бесконечно погружаться в TI тактический и стратегический, проверку статистики от специализированных (UEBA, NBA) и систем общего профиля, систему обратной связи от сотрудников и прочего. Но это не база, а потому не предмет данной статьи.
Метрика из практики MSSP, подтвержденная и теорией из книг типа «Ten Strategies of a World-Class Cybersecurity Operations Center». Это метрика на аналитика, сколько кейсов он сможет реально расследовать, а не засунуть за 2 минуты в категорию ЛПС\ЛОС. Сколько нужно таких аналитиков параллельно — это другой вопрос и может решаться очень по разному.
Отсечена заголовком статьи. При этом безусловно, тема важная, даже более, чем техническая.
После пункта 2 система нумерация чисто условная, о чем в статье написано. По сути пункт про IPS открывает тему трафика в мониторинге в рамках данной статьи и тут рассматривается не как самостоятельное решение, как и когда внедрять которое — отдельный вопрос.
Статья не погружается в технические детали. Их десятки по каждому классу систем и каждому производителю.
Оценка рисков, часть из которых риски ИБ, часть из которых решаются методом минимизации, часть из которых за счёт мониторинга — отдельная область знаний. В статью не вместилась.
Однобоко — так и планировалось, иначе можно писать минимум книгу. Странно — на усмотрение читателя. Учту как заявку на расширение тематики в будущих публикациях, если кто то не успеет осветить смежные вопросы раньше и лучше меня. Я за то, чтобы появилась статья «Все вопросы мониторинга ИБ на 10 страницах» или хотя бы «Мониторинг ИБ от А до Я». Но пока десятки книг от разных авторов никто не смог скомпоновать.
13oz
Хм. В моей голове понятийный аппарат для мониторинга ИБ уже достаточно неплохо разобран в 27k и NIST SP 800-53. Он там не до конца однороден, т.к. разны организации это делают, но тем не менее, вполне хорош. Основные термины там разобраны неплохо. Хотя место для срача а-ля «что есть событие ИБ, а что есть инцидент ИБ» остается, да. И еще есть термин, который не ясно, как вводить в русскоязычную документацию — security breach.
И все они добавляют свои костыли для агрегации и корреляции.
Всё так, но у них эти фичи появляются уже в платной версии, которая стоит, как настоящий SIEM.
Так-то, у них и EDR есть свой.
У меня есть серьезное подозрение, что русскоязычные авторы это пишут потому, что у них (а у нас большая часть авторов — это сотрудники вендоров) просто нет ничего другого. И, в любом случае, хантинг — это сложный и тяжелый процесс, думать о котором имеет смысл только тогда, когда уже есть baseline-ы по мониторингу, процессы управления инцидентами работают, и мы уже перешли к весьма зрелому SOC-у.
Как мне кажется, это можно рассматривать только как пристрелочное значение для определение количества аналитиков. Как метрика эффективности внедрения она все-таки не подойдет, по моему мнению.
Боюсь, что это будет не статья, а цикл уровня четверокнижия Таненбаума :)
ANosarev Автор
Всё в целом так, как вы говорите. Но как минимум в русскоязычном сегменте не многие так глубоко погружаются. Тот же NIST — очень хороший стандарт, на хабре даже есть на него обзоры. Только лучше всё же читать весь цикл:
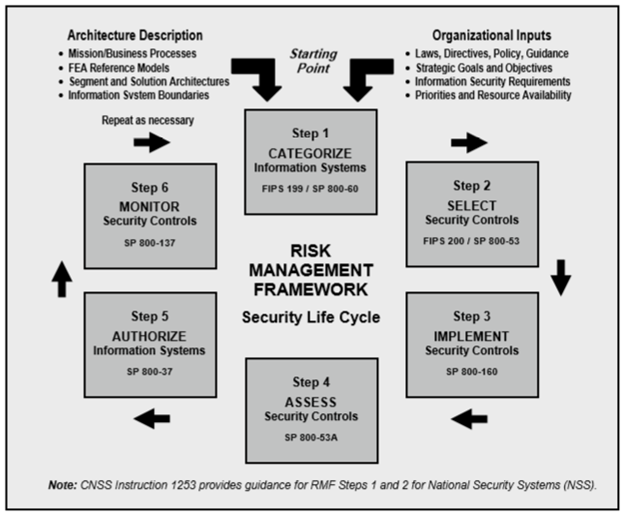
А это уже несколько тысяч страниц хотя бы по диагонали.
Эта статья прежде всего ликбез для тех, для кого тема не является основной. Краткая шпаргалка, которой можно поделиться или использовать самому, если нужно быстрое и общее понимание. Та же тема КИИ сейчас активно развивается. Хочется, чтобы организации не только получали подтверждение соответствия «на бумаге», но и за почти те же деньги имели реальные результаты уже сейчас. Тут все в плюсе будут.