
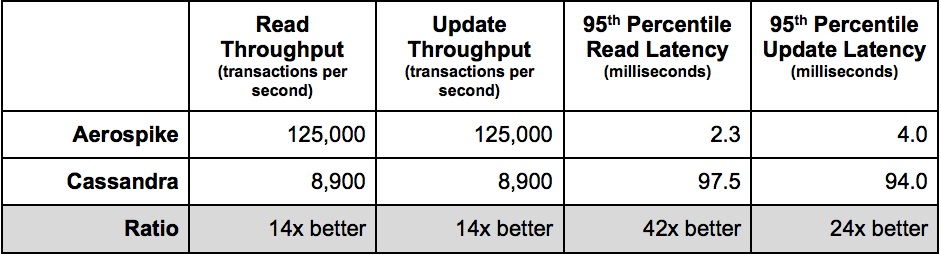
В прошлый раз обсуждение битвы тяжеловесов Cassandra VS HBase вызвало весьма бурную дискуссию, в ходе которой была много раз упомянута Scylla — которая позиционируется как более быстрый аналог Cassandra (далее CS). Также меня заинтересовал весьма любопытный Aerospike (далее AS), который в своих тестах предсказуемо побеждает CS с разгромным счетом.
По удивительному совпадению Scylla (далее SC) также легко бьет CS, о чем гордо сообщает прямо на своей заглавной странице:

Таким образом естественным образом возникает вопрос, кто кого заборет, кит или слон?
В моем тесте оптимизированная версия HBase (далее HB) работает с CS на равных, так что он тут будет не в качестве претендента на победу, а лишь постольку, что весь наш процессинг построен на HB и хочется понимать его возможности в сравнении с лидерами.
Понятно, что бесплатность HB и CS это огромный плюс, однако с другой стороны если для достижения одинаковой производительности нужно в X раз больше железа, выгоднее бывает заплатить за софт, чем выделять этаж в ЦОД под дорогие грелки. Особенно учитывая, что если уж речь зашла про производительность, то так как HDD в принципе не способны дать хоть сколько-нибудь приемлемую скорость Random Access чтений (см. "Почему HDD и быстрые Random Access чтения несовместимы"), что в свою очередь означает покупку SSD, который в объемах нужных для настоящей BigData весьма недешевое удовольствие.
Итак, было сделано следующее. Я арендовал 4 сервера в облаке AWS в конфигурации i3en.6xlarge где на борту каждого:
CPU — 24 vcpu
MEM — 192 GB
SSD — 2 x 7500 GB
Если кто-то захочет повторить, то сразу отметим, что очень важно для воспроизводимости брать конфигурации, где полный объем дисков (7500 GB). Иначе диски придется делить с непредсказуемыми соседями, которые обязательно испортят ваши тесты, как им наверняка кажется весьма ценной нагрузкой.
Далее, раскатал SC при помощи конструктора, который любезно предоставил производитель на собственном сайте. После чего залил утилиту YCSB (которая уже практически стандарт для сравнительного тестирования БД) на каждую ноду кластера.
Есть только один важный нюанс, мы практически во всех случаях используем следующий паттерн: прочитать запись до изменения + записать новое значение.
Поэтому я модифицировал update следующим образом:
Далее запускал нагрузку одновременно со всех 4х хостов (тех же самых где расположены сервера БД). Это сделано сознательно, потому что бывает клиенты одних БД больше потребляют ЦПУ чем другие. Учитывая, что размеры кластера ограничены, то хочется понимать совокупную эффективность реализации как серверной, так и клиентской части.
Результаты тестирования будут представлены ниже, но прежде чем мы перейдем к ним стоит рассмотреть также еще несколько важных нюансов.
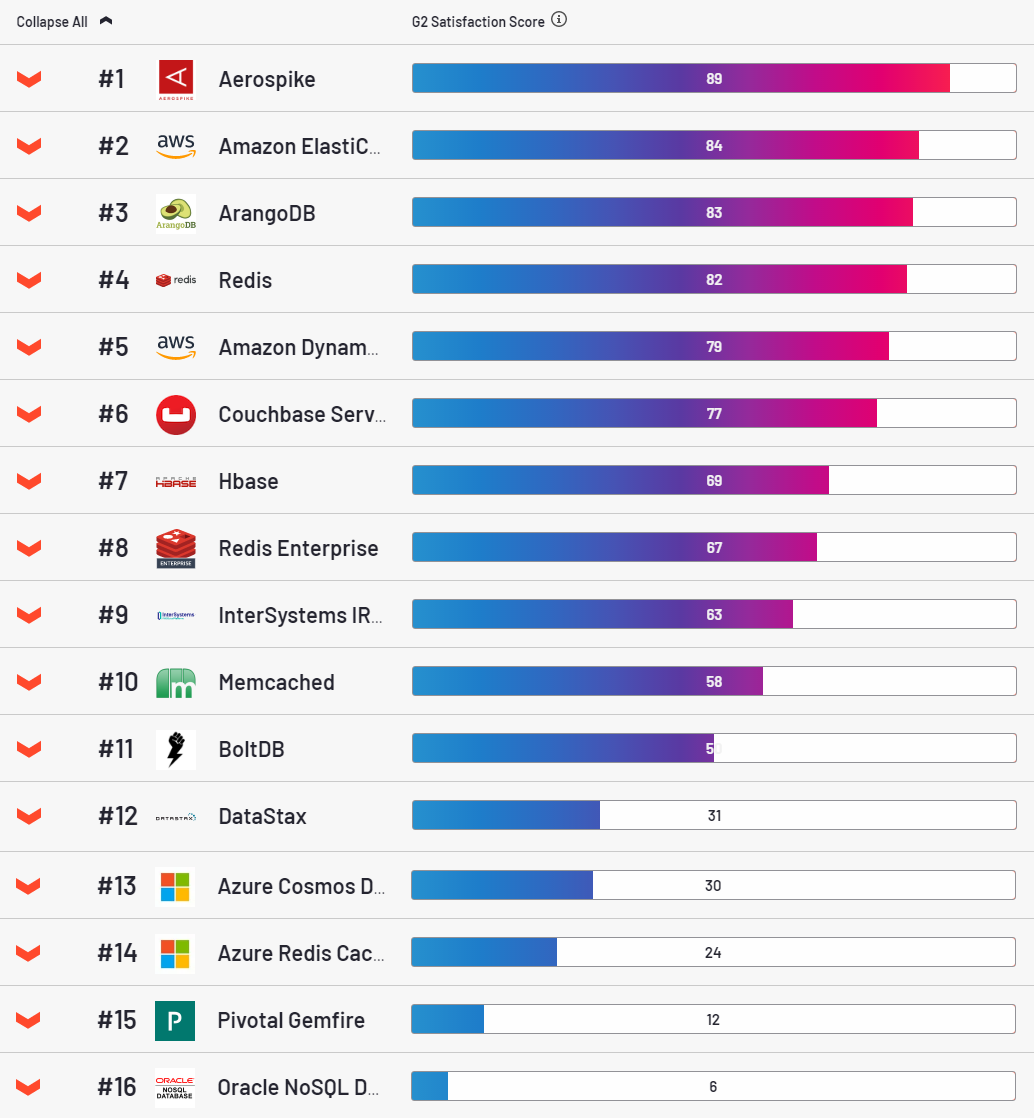
Насчет AS — это весьма привлекательная БД, лидер в номинации удовлетворенности клиентов по версии ресурса g2.
Признаться, мне она тоже как-то приглянулась. Ставится просто, вот этим скриптом достаточно легко раскатывается в облако. Стабильная, конфигурировать одно удовольствие. Однако есть у ней один очень большой недостаток. На каждый ключ она выделяет 64 байта оперативной памяти. Кажется немного, но в промышленных объемах это становится проблемой. Типичная запись в наших таблицах весит 500 байт. Именно такой объем value я использовал почти* во всех тестах (*почему почти будет сказано ниже).
Так как мы храним по 3 копии каждой записи, то получается что для хранения 1 PB чистых данных (3 PB грязных) мы должны будем выделить всего-то 400 TB оперативки. Идем дальше… нет чтооо?! Секундочку, а нельзя ли с этим что-нибудь сделать? — спросили мы у вендора.
Ха, конечно можно много чего, загибаем пальцы:
Хорошо, теперь разберемся с HB и можно уже будет рассмотреть результаты тестов. Для установки Hadoop у Амазона предусмотрена платформа EMR, которая позволяет легко раскатать необходимый вам кластер. Мне пришлось только поднять лимиты на число процессов и открытых файлов, иначе падало под нагрузкой и заменил hbase-server на свою оптимизированную сборку (подробности тут). Второй момент, HB безбожно тормозит при работе с одиночными запросами, это факт. Поэтому мы работаем только батчами. В данном тесте батч = 100. Регионов в таблице 100.
Ну и последний момент, все базы тестировались в режиме «strong consistency». Для HB это из коробки. AS доступно только в enterprise версии (т.е. в данном тесте было включено). SC гонялась в режиме write consistency=all. Replication factor везде 3.
Итак, поехали. Insert в AS:
10 sec: 360554 operations; 36055,4 current ops/sec;
20 sec: 698872 operations; 33831,8 current ops/sec;
…
230 sec: 7412626 operations; 22938,8 current ops/sec;
240 sec: 7542091 operations; 12946,5 current ops/sec;
250 sec: 7589682 operations; 4759,1 current ops/sec;
260 sec: 7599525 operations; 984,3 current ops/sec;
270 sec: 7602150 operations; 262,5 current ops/sec;
280 sec: 7602752 operations; 60,2 current ops/sec;
290 sec: 7602918 operations; 16,6 current ops/sec;
300 sec: 7603269 operations; 35,1 current ops/sec;
310 sec: 7603674 operations; 40,5 current ops/sec;
Error while writing key user4809083164780879263: com.aerospike.client.AerospikeException$Timeout: Client timeout: timeout=10000 iterations=1 failedNodes=0 failedConns=0 lastNode=5600000A 127.0.0.1:3000
Error inserting, not retrying any more. number of attempts: 1Insertion Retry Limit: 0
Упс, а вы точнопродюсер промышленная база? Можно подумать так на первый взгляд. Однако оказалось, что проблема в ядре амазонской версии линукса. На них завели тикет и в версии amzn2-ami-hvm-2.0.20210326.0-x86_64-gp2 проблему исправили. Но для этих тестов вендор предложил использовать скрипты ансибла для раскатки ubuntu, где эта проблема не возникала (для этого нужно выбрать соответствующую ветку в гите).
Ладно, продолжаем. Запускаем загрузку 200 млн. записей (INSERT), потом UPDATE, потом GET. Вот что получилось (ops — операций в секунду):

ВАЖНО! Это скорость одной ноды! Всего их 4, т.е. чтобы получить суммарную скорость нужно умножать на 4.
Первая колонка 10 полей, это не совсем честный тест. Т.е. это когда индекс в памяти, чего в реальной ситуации BigData недостижимо.
Вторая колонка это упаковка 10 записей в 1. Т.е. тут уже реально идет экономия памяти, ровно в 10 раз. Как отлично видно из теста, такой фокус не проходит даром, производительность существенно падает. Причина очевидна, каждый раз чтобы обработать одну запись, приходится иметь дело с 9 соседними. Оверхед короче.
Ну и наконец all-flush, тут примерно такая же картина. Чистые вставки хуже, но ключевая операция Update быстрее, так что дальше будем сравнивать только с all-flush.
Собственно не будем тянуть кота, сразу вот:

(ops — операций в секунду)
Все в общем-то понятно, но что тут стоит добавить.
Возможно где-то косяк с настройками или всплыл тот баг с ядром, не знаю. Но настраивал все от и до скрипт от вендора, так что мопед не мой, все вопросы к нему.
Еще нужно понимать, что это весьма скромный объем данных и на больших объемах ситуация может измениться. В ходе экспериментов я спалил несколько сотен баксов, так что энтузиазма хватило только на long-run тест лидера и в ограниченном одним сервером режиме.
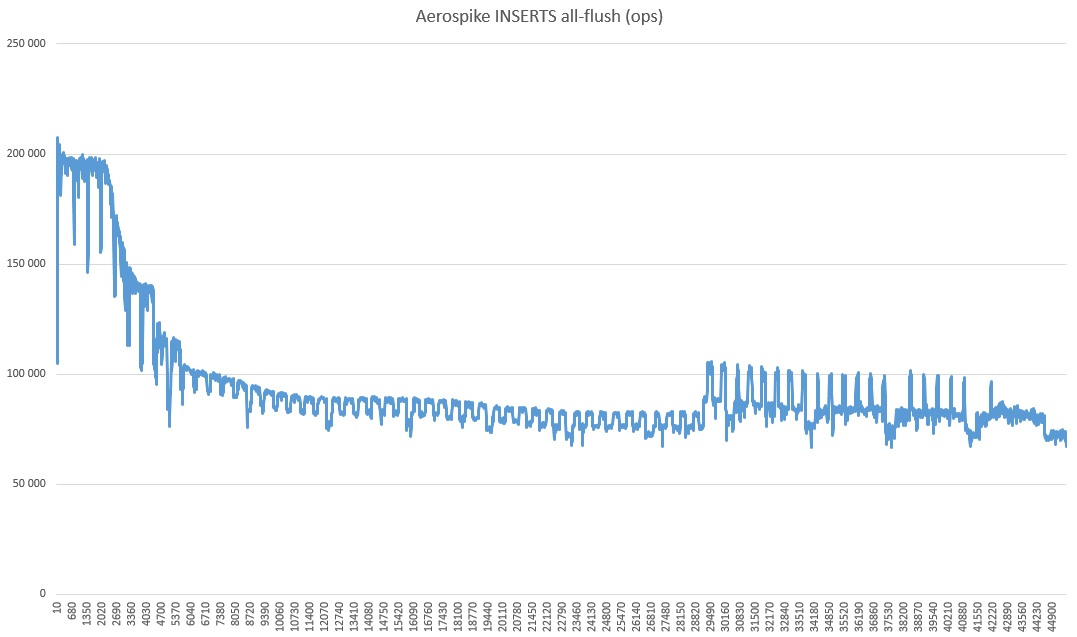
Почему оно так просело и что за оживление в последней трети — загадка природы. Можно также заметить, что скорость радикально выше, чем в тестах чуть выше. Полагаю это потому что выключен режим strong consistency (т.к. сервер всего один).
Ну и наконец GET+WRITE (поверх залитых тестом выше трех миллиардов записей):
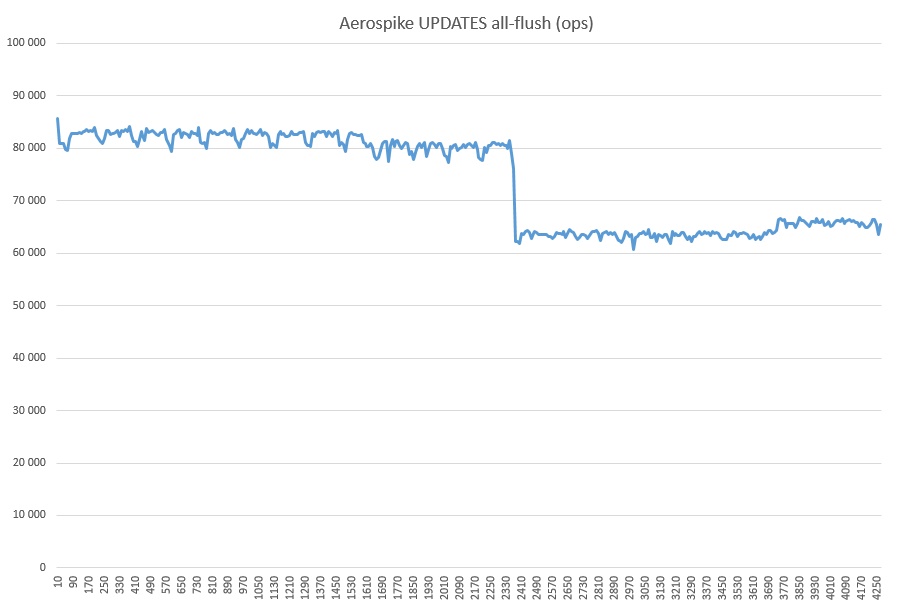
Что за просадка такая, в душе не догадываюсь. Никаких посторонних процессов не запускалось. Возможно как-то связано с кешом SSD, потому что утилизация во время всего хода тестирования AS в режиме all-flush была 100%.

На этом собственно все. Выводы в целом очевидны, нужно больше тестов. Желательно всех самых популярных БД в одинаковых условиях. В инете этого жанра как-то не особо много. А хорошо бы, тогда вендоры баз будут мотивированы оптимизироваться, а мы — осознанно выбирать лучших.
По удивительному совпадению Scylla (далее SC) также легко бьет CS, о чем гордо сообщает прямо на своей заглавной странице:
Таким образом естественным образом возникает вопрос, кто кого заборет, кит или слон?
В моем тесте оптимизированная версия HBase (далее HB) работает с CS на равных, так что он тут будет не в качестве претендента на победу, а лишь постольку, что весь наш процессинг построен на HB и хочется понимать его возможности в сравнении с лидерами.
Понятно, что бесплатность HB и CS это огромный плюс, однако с другой стороны если для достижения одинаковой производительности нужно в X раз больше железа, выгоднее бывает заплатить за софт, чем выделять этаж в ЦОД под дорогие грелки. Особенно учитывая, что если уж речь зашла про производительность, то так как HDD в принципе не способны дать хоть сколько-нибудь приемлемую скорость Random Access чтений (см. "Почему HDD и быстрые Random Access чтения несовместимы"), что в свою очередь означает покупку SSD, который в объемах нужных для настоящей BigData весьма недешевое удовольствие.
Итак, было сделано следующее. Я арендовал 4 сервера в облаке AWS в конфигурации i3en.6xlarge где на борту каждого:
CPU — 24 vcpu
MEM — 192 GB
SSD — 2 x 7500 GB
Если кто-то захочет повторить, то сразу отметим, что очень важно для воспроизводимости брать конфигурации, где полный объем дисков (7500 GB). Иначе диски придется делить с непредсказуемыми соседями, которые обязательно испортят ваши тесты, как им наверняка кажется весьма ценной нагрузкой.
Далее, раскатал SC при помощи конструктора, который любезно предоставил производитель на собственном сайте. После чего залил утилиту YCSB (которая уже практически стандарт для сравнительного тестирования БД) на каждую ноду кластера.
Есть только один важный нюанс, мы практически во всех случаях используем следующий паттерн: прочитать запись до изменения + записать новое значение.
Поэтому я модифицировал update следующим образом:
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Далее запускал нагрузку одновременно со всех 4х хостов (тех же самых где расположены сервера БД). Это сделано сознательно, потому что бывает клиенты одних БД больше потребляют ЦПУ чем другие. Учитывая, что размеры кластера ограничены, то хочется понимать совокупную эффективность реализации как серверной, так и клиентской части.
Результаты тестирования будут представлены ниже, но прежде чем мы перейдем к ним стоит рассмотреть также еще несколько важных нюансов.
Насчет AS — это весьма привлекательная БД, лидер в номинации удовлетворенности клиентов по версии ресурса g2.
Признаться, мне она тоже как-то приглянулась. Ставится просто, вот этим скриптом достаточно легко раскатывается в облако. Стабильная, конфигурировать одно удовольствие. Однако есть у ней один очень большой недостаток. На каждый ключ она выделяет 64 байта оперативной памяти. Кажется немного, но в промышленных объемах это становится проблемой. Типичная запись в наших таблицах весит 500 байт. Именно такой объем value я использовал почти* во всех тестах (*почему почти будет сказано ниже).
Так как мы храним по 3 копии каждой записи, то получается что для хранения 1 PB чистых данных (3 PB грязных) мы должны будем выделить всего-то 400 TB оперативки. Идем дальше… нет чтооо?! Секундочку, а нельзя ли с этим что-нибудь сделать? — спросили мы у вендора.
Ха, конечно можно много чего, загибаем пальцы:
- Упаковать несколько записей в одну (хопа).
- Тоже самое что в п.1, только за счет расширения числа полей.
- Включить режим all-flush. Суть — хранить индекс не в памяти, а на диске. Правда есть нюанс, Ватсон, опция доступна только в entreprise версии (в моем случае доступно в рамках trial-периода).
Хорошо, теперь разберемся с HB и можно уже будет рассмотреть результаты тестов. Для установки Hadoop у Амазона предусмотрена платформа EMR, которая позволяет легко раскатать необходимый вам кластер. Мне пришлось только поднять лимиты на число процессов и открытых файлов, иначе падало под нагрузкой и заменил hbase-server на свою оптимизированную сборку (подробности тут). Второй момент, HB безбожно тормозит при работе с одиночными запросами, это факт. Поэтому мы работаем только батчами. В данном тесте батч = 100. Регионов в таблице 100.
Ну и последний момент, все базы тестировались в режиме «strong consistency». Для HB это из коробки. AS доступно только в enterprise версии (т.е. в данном тесте было включено). SC гонялась в режиме write consistency=all. Replication factor везде 3.
Итак, поехали. Insert в AS:
10 sec: 360554 operations; 36055,4 current ops/sec;
20 sec: 698872 operations; 33831,8 current ops/sec;
…
230 sec: 7412626 operations; 22938,8 current ops/sec;
240 sec: 7542091 operations; 12946,5 current ops/sec;
250 sec: 7589682 operations; 4759,1 current ops/sec;
260 sec: 7599525 operations; 984,3 current ops/sec;
270 sec: 7602150 operations; 262,5 current ops/sec;
280 sec: 7602752 operations; 60,2 current ops/sec;
290 sec: 7602918 operations; 16,6 current ops/sec;
300 sec: 7603269 operations; 35,1 current ops/sec;
310 sec: 7603674 operations; 40,5 current ops/sec;
Error while writing key user4809083164780879263: com.aerospike.client.AerospikeException$Timeout: Client timeout: timeout=10000 iterations=1 failedNodes=0 failedConns=0 lastNode=5600000A 127.0.0.1:3000
Error inserting, not retrying any more. number of attempts: 1Insertion Retry Limit: 0
Упс, а вы точно
Ладно, продолжаем. Запускаем загрузку 200 млн. записей (INSERT), потом UPDATE, потом GET. Вот что получилось (ops — операций в секунду):
ВАЖНО! Это скорость одной ноды! Всего их 4, т.е. чтобы получить суммарную скорость нужно умножать на 4.
Первая колонка 10 полей, это не совсем честный тест. Т.е. это когда индекс в памяти, чего в реальной ситуации BigData недостижимо.
Вторая колонка это упаковка 10 записей в 1. Т.е. тут уже реально идет экономия памяти, ровно в 10 раз. Как отлично видно из теста, такой фокус не проходит даром, производительность существенно падает. Причина очевидна, каждый раз чтобы обработать одну запись, приходится иметь дело с 9 соседними. Оверхед короче.
Ну и наконец all-flush, тут примерно такая же картина. Чистые вставки хуже, но ключевая операция Update быстрее, так что дальше будем сравнивать только с all-flush.
Собственно не будем тянуть кота, сразу вот:
(ops — операций в секунду)
Все в общем-то понятно, но что тут стоит добавить.
- Вендор AS подтвердил, что результаты выше по их БД релевантные.
- У SC вставки были какие-то не очень правильные, вот более подробный график в разрезе по серверам:

Возможно где-то косяк с настройками или всплыл тот баг с ядром, не знаю. Но настраивал все от и до скрипт от вендора, так что мопед не мой, все вопросы к нему.
Еще нужно понимать, что это весьма скромный объем данных и на больших объемах ситуация может измениться. В ходе экспериментов я спалил несколько сотен баксов, так что энтузиазма хватило только на long-run тест лидера и в ограниченном одним сервером режиме.
Почему оно так просело и что за оживление в последней трети — загадка природы. Можно также заметить, что скорость радикально выше, чем в тестах чуть выше. Полагаю это потому что выключен режим strong consistency (т.к. сервер всего один).
Ну и наконец GET+WRITE (поверх залитых тестом выше трех миллиардов записей):
Что за просадка такая, в душе не догадываюсь. Никаких посторонних процессов не запускалось. Возможно как-то связано с кешом SSD, потому что утилизация во время всего хода тестирования AS в режиме all-flush была 100%.
На этом собственно все. Выводы в целом очевидны, нужно больше тестов. Желательно всех самых популярных БД в одинаковых условиях. В инете этого жанра как-то не особо много. А хорошо бы, тогда вендоры баз будут мотивированы оптимизироваться, а мы — осознанно выбирать лучших.




ivankudryavtsev
Полезно, но сумбурно.
pustota_2009 Автор
Да, так и есть, за пару-тройку часов написал, хотелось уже выложить результаты, свопнуть так сказать из оперативки и заняться плотно другими делами)