
Алексей Миловидов делает ClickHouse и, конечно, знает его вдоль и поперек. В том числе и о том, как его можно использовать дополнительно к его штатным и всем хорошо известным функциям.
И сегодня расскажет про эти необычные способы его использования и, может быть, даже не для хранения и обработки данных.

ClickHouse для тестов железа
Самое простое, что можно сделать с ClickHouse, если есть свободные серверы — это использовать его для тестов оборудования. Потому что его тестовый dataset содержит те же данные с production Яндекса, только анонимизированные — и они доступны снаружи для тестирования. Про то, как подготовить хорошие анонимизированные данные, я рассказывал на Saint HighLoad++ 2019 в Санкт-Петербурге.
Ставим ClickHouse на любой Linux (x86_64, AArch64) или Mac OS. Как это сделать? — мы собираем его на каждый коммит и pull request. ClickHouse Build Check покажет нам все детали всех возможных билдов:
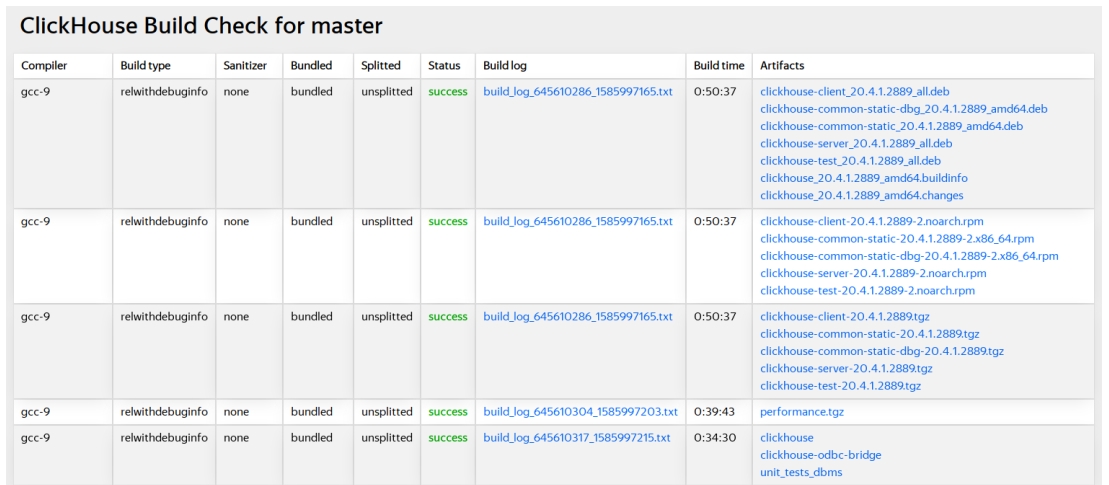
Отсюда можно скачать любой бинарник — с gcc и clang в релизе, в debug, со всякими санитайзерами или без, для x86, ARM или даже Mac OS. ClickHouse использует все ресурсы железа: все ядра CPU, шины памяти и грузит все диски. Какой сервер ему не дай — проверит полностью, хорошо или плохо тот работает.
По этой инструкции можно скачать бинарник, тестовые данные и запустить запросы. Тест займёт около 30 минут и не требует установки ClickHouse. И даже если на сервере уже установлен другой ClickHouse, вы все равно сможете запустить тест.
В результате мы получаем публичный список протестированного железа:

Все результаты мы получаем от пользователей через краудсорсинг и выглядят они примерно так:

Вы можете выбрать серверы для сравнения — для каждого можно посмотреть разницу в производительности. Конечно, и других тестов железа существует немало, например, SPECint и вообще куча тестов из организации SPEC. Но ClickHouse позволяет не просто тестировать железо, а тестировать рабочую СУБД на настоящих данных на реальных серверах откуда угодно.
ClickHouse без сервера
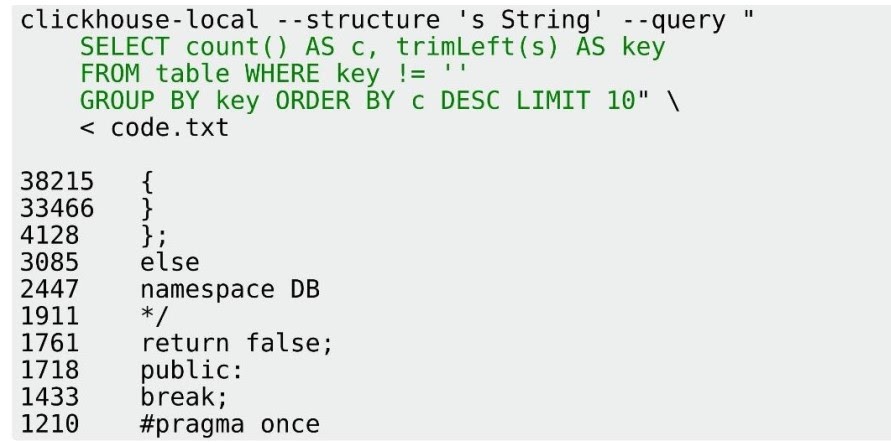
Конечно, обычно ClickHouse — это сервер + клиент. Но иногда нужно просто обработать какие-то текстовые данные. Для примера я взял все исходники ClickHouse, собрал их в файл и сконкатенировал в файл под названием code.txt:

И, например, я хочу проверить, какие строчки в коде на C++ самые популярные. С помощью типичной shell-команды удалим из каждой строчки кода начальные пробелы и пустые строки, отсортируем и посчитаем количество уникальных. После сортировки видим, что, конечно, самая популярная строчка — это открывающая фигурная скобка, за ней — закрывающая фигурная скобка, а еще очень популярно «return false».
Этот результат я получил за 1,665 секунд. Потому что все это было сделано с учетом сложной локали. Если локаль заменить на простую, выставив переменную окружения LC_ALL=C, то будет всего лишь 0,376 с, то есть в 5 раз быстрее. Но это всего-лишь шел скрипт.
Можно ли быстрее? Да, если использовать clickhouse-local, будет еще лучше.
Это как-будто одновременно и сервер и клиент, но на самом деле ни то, и ни другое — clickhouse-local может выполнять SQL запросы по локальным файлам. Вам достаточно указать запрос, структуру и формат данных (можно выбрать любой из форматов, по умолчанию — TabSeparated), чтобы обработать запрос на входном файле. За 0.103 секунд — то есть в 3,7–16 раз быстрее (в зависимости от того, как вы запускали предыдущую команду).
Для демонстрации чего-то более серьезного давайте посмотрим на те данные, которые собирает GitHub Archive — это логи всех действий всех пользователей, которые происходили на GitHub, то есть коммиты, создание и закрытие issue, комментарии, код-ревью. Все это сохраняется и доступно для скачивания на сайте https://www.gharchive.org/ (всего около 890 Гб):
Чтобы их как-нибудь обработать, выполним запрос с помощью ClickHouse local:
time clickhouse-local --query "SELECT * FROM
file('*.json.gz', TSV, 'data String')
WHERE JSONExtractString(data, 'actor', 'login') = 'alexey-milovidov'
LIMIT 10" | jq
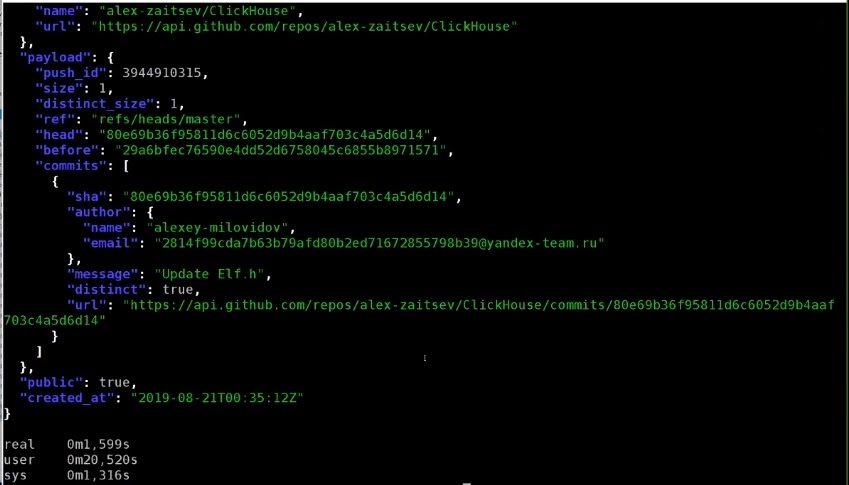
Я выбрал все данные из табличной функции file, которая берет файлы вида *.json.gz — то есть все файлы в формате TSV, интерпретируя их как одно поля типа string. С помощью функции для обработки JSON я вытащил из каждой JSON‘ины сначала поле 'actor', а потом — поле 'login' в случае, когда оно равно «Алексей Миловидов» — и выбрал таких первых 10 действий на GitHub.
Может возникнуть впечатление, что 890 Гб данных смогли обработаться за 1,3 секунды. Но на самом деле запрос работает потоково. После того, как находятся первые 10 строк, процесс останавливается. Теперь попробуем выполнить более сложный запрос, например, я хочу посчитать, сколько всего действий я совершил на GitHub.
clickhouse-local --query "SELECT count() FROM
file('*.json.gz', TSV, 'data String')
WHERE JSONExtractString(data, 'actor', 'login') = 'alexey-milovidov'"
Используем SELECT COUNT... и через полторы секунды кажется, что ничего не происходит. Но что происходит на самом деле, мы можем посмотреть в соседнем терминале с помощью программы dstat:
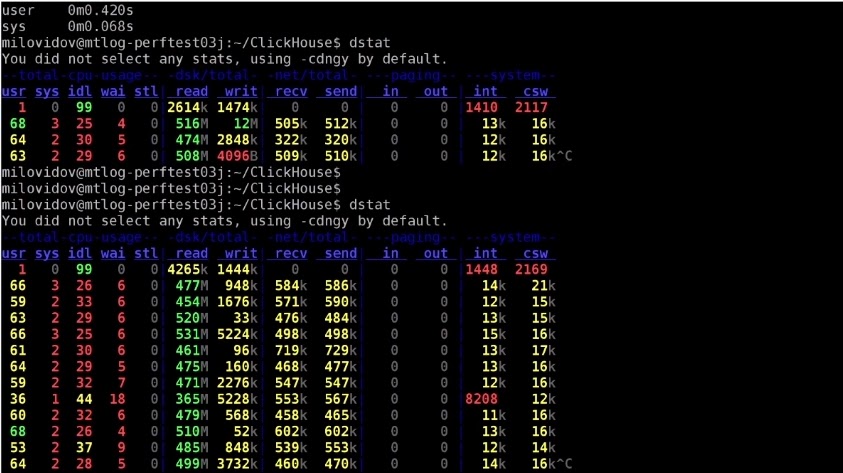
И мы видим, что данные читаются с дисков со скоростью примерно 530 Мб/с и все файлы обрабатываются параллельно почти с максимальной скоростью — насколько позволяет железо (на сервере RAID из нескольких HDD).

Но можно использовать ClickHouse local даже без скачивания этих 980 Гб. В ClickHouse есть табличная функция url — то есть можно вместо file написать адрес https://.../*.json.gz, и это тоже будет обрабатываться.
Чтобы можно было выполнять такие запросы в ClickHouse, мы реализовали несколько вещей:
Табличная функция file.
Поддержка glob patterns. В качестве имени файлов можно использовать шаблон с glob patterns (звёздочка, фигурные скобки и пр.)
Поддержка сжатых файлов в формате gzip, xz и zstd из коробки. Указываем gz и всё работает.
Функции для работы с JSON. Могу утверждать, что это самые эффективные функции для обработки JSON, которые мы смогли найти. Если вы найдёте что-нибудь лучше, скажите мне.
Параллельная обработка файлов. Там несколько тысяч файлов, и будут использоваться все процессорные ядра. И даже один файл будет обрабатываться параллельно, потому что у нас есть параллельный парсинг форматов данных.
Тот самый параллельный парсинг.
Применять можно, само собой, для обработки текстовых файлов. Еще — для подготовки временной таблицы и партиций для MergeTree. Можно провести препроцессинг данных перед вставкой: читаете в одной структуре, преобразовываете с помощью SELECT и отдаете дальше в clickhouse-client. Для преобразования форматов тоже можно — например, преобразовать данные в формате protobuf с разделителями в виде длины в JSON на каждой строке:
clickhouse-local --input-format Protobuf --format-schema такая-то
--output-format JSONEachRow ...
Примечание: более подробно про анализ данных GitHub Archive рассказано в отдельной статье.
Serverless ClickHouse
ClickHouse может работать в serverless-окружении. Есть пример, когда ClickHouse засунули в Лямбда-функцию в Google Cloud Run: https://mybranch.dev/posts/clickhouse-on-cloud-run/ (Alex Reid). Там на каждый запрос запускается маленький ClickHouse на фиксированных данных и эти данные обрабатывает.
Текстовые форматы
Для обработки текстовых данных, естественно, есть поддержка форматов tab separated (TSV) и comma separated (CSV). Но еще есть формат CustomSeparated, с помощью которого можно изобразить и тот, и другой в качестве частных случаев.
CustomSeparated:
format_custom_escaping_rule
format_custom_field_delimiter
format_custom_row_before/between/after_delimiter
format_custom_result_before/after_delimiter
Есть куча настроек, которые его кастомизируют. Первая настройка — это правило экранирования. Например, вы можете сделать формат CSV, но в котором строки экранированы как в JSON, а не как CSV. Разница тонкая, но довольно важная. Можно указать произвольный разделитель типа | и пр. между значениями, между строками и т.п.
Более мощный формат — это формат Template:
format_template_resultset
format_template_row
format_template_rows_between_delimiter
С его помощью можно указать произвольный шаблон, где в строке есть подстановки, и в этих подстановках тоже указывается, какой столбец в каком формате отформатирован. Можно даже парсить XML, если очень надо.
Есть формат Regexp:
format_regexp
format_regexp_escaping_rule
format_regexp_skip_unmatched
И тут clickhouse-local превращается в настоящий awk. Указываете регулярные выражения, в Regexp есть subpatterns, и каждый subpattern теперь парсится как столбец. Его содержимое обрабатывается согласно некоторому правилу экранирования. И конечно можно написать — пропускать строки, для которых регулярное выражение сработало, или нет.
ClickHouse для полуструктурированных данных
Первая идея в этом случае — не использовать ClickHouse. Берите Mongo, которая отлично подходит именно для этого. Но если вдруг вы так любите ClickHouse, что просто не можете им не пользоваться — можно и с его помощью.
Допустим, у вас есть таблица с логами, в ней есть столбец с датой и временем, а вот всё остальное — вообще непонятно что. Очень соблазнительно всю эту кучу данных записать в один столбец 'message' с типом String. Если эта куча в формате JSON, функции для работы с JSON будут работать. Но неэффективно — каждый раз, когда нам будет нужно только одно поле, например 'actor.login', читать придется весь JSON — не будет преимущества столбцовой базы данных. С помощью ClickHouse мы легко это исправим прямо на лету, добавив с помощью запроса ALTER материализованный столбец:
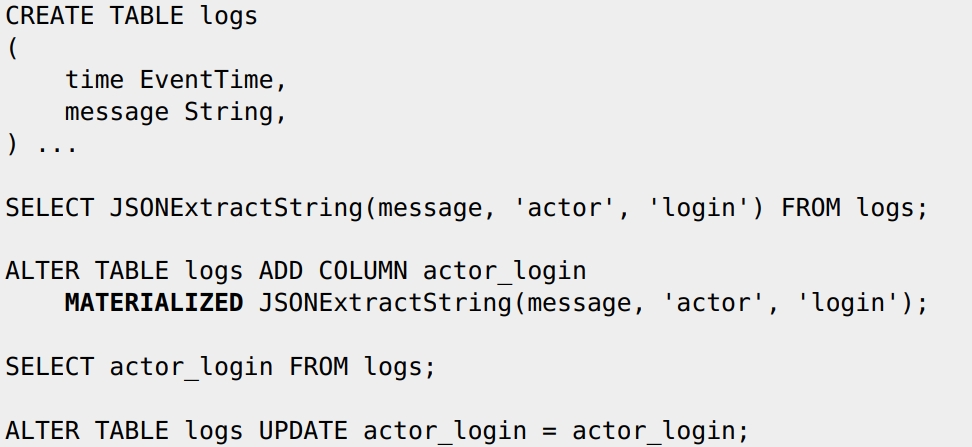
После того, как материализованный столбец actor_login начнет записываться для новых данных в таблице, SELECT для новых данных будет читаться эффективно, а для старых — будет вычисляться. Для материализации старых данных можно использовать несколько странный запрос для материализации всех данных в прошлом:
ALTER TABLE logs UPDATE actor_login = actor_login
И вы можете добавлять столбцы по мере необходимости, чтобы ускорить запросы.
Ускорение MySQL
В ClickHouse можно создать таблицу на основе табличной функции MySQL. Это просто: указываете хост, порт, БД, таблицу, имя пользователя и пароль (прямо так, как есть), делаем SELECT и всё выполняется за 15 секунд:
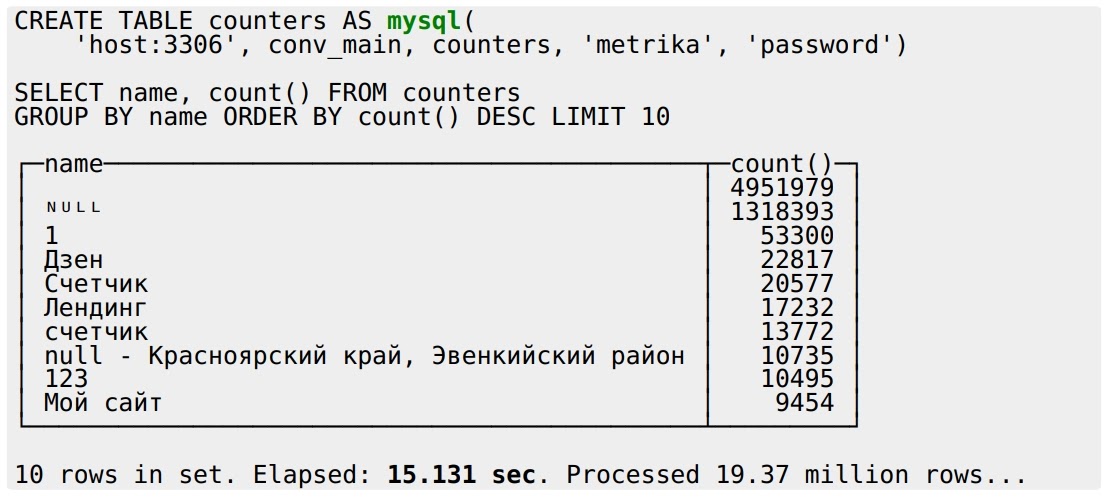
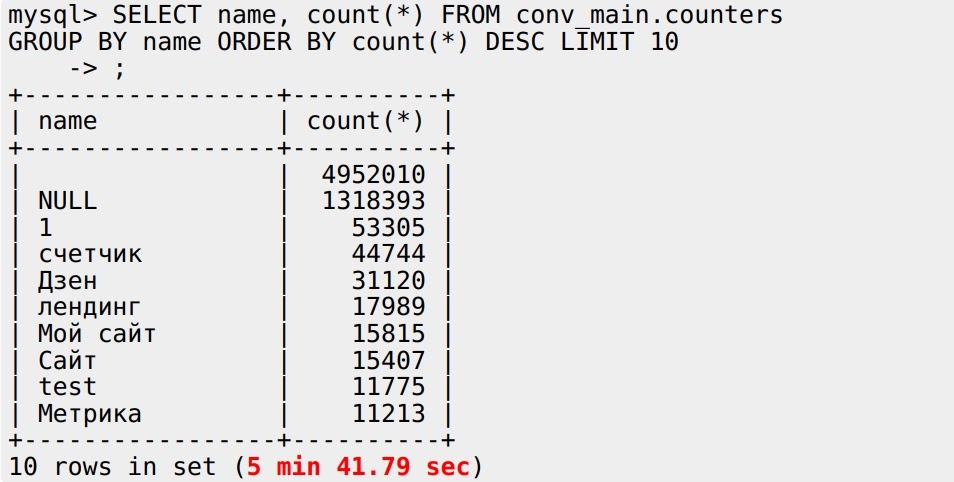
Работает это тоже без всякой магии: табличная функция MySQL переписывает запрос, отправляет его в MySQL и читает все данные назад, на лету — на всё 15 секунд. Но что будет, если я тот же самый запрос выполню в MySQL как есть?
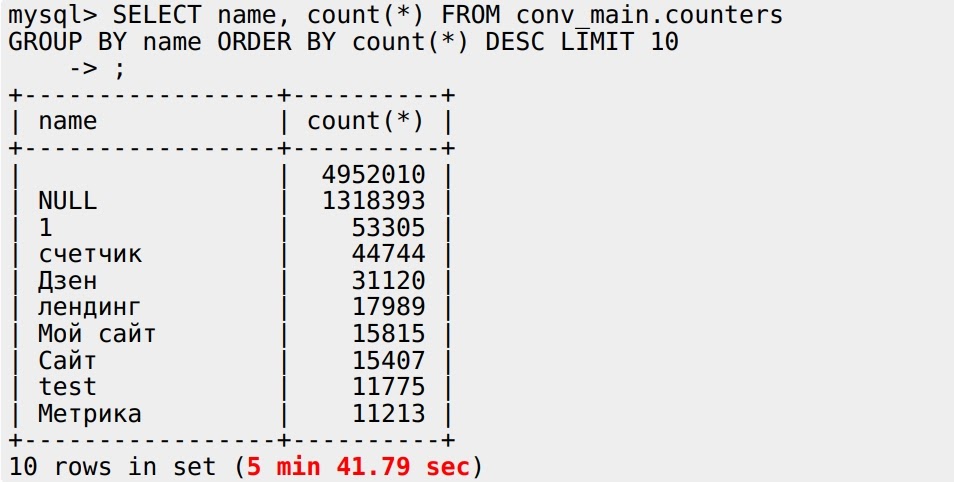
5 минут 41 секунда — это позор! У ClickHouse тут как-будто нет преимуществ — данные нужно переслать из MySQL в ClickHouse и потом уже обработать. А MySQL обрабатывает сам у себя локально — почему же он так медленно работает?
Еще одна проблема — результаты расходятся. У ClickHouse две строки “счетчик” (20577 и 13772), у MySQL — один (44744), потому что он здесь учитывает collation (правила сравнения строк в разном регистре) при GROUP BY. Чтобы это исправить, можно перевести имя в нижний регистр, сгруппировать по нему и выбрать любой вариант:
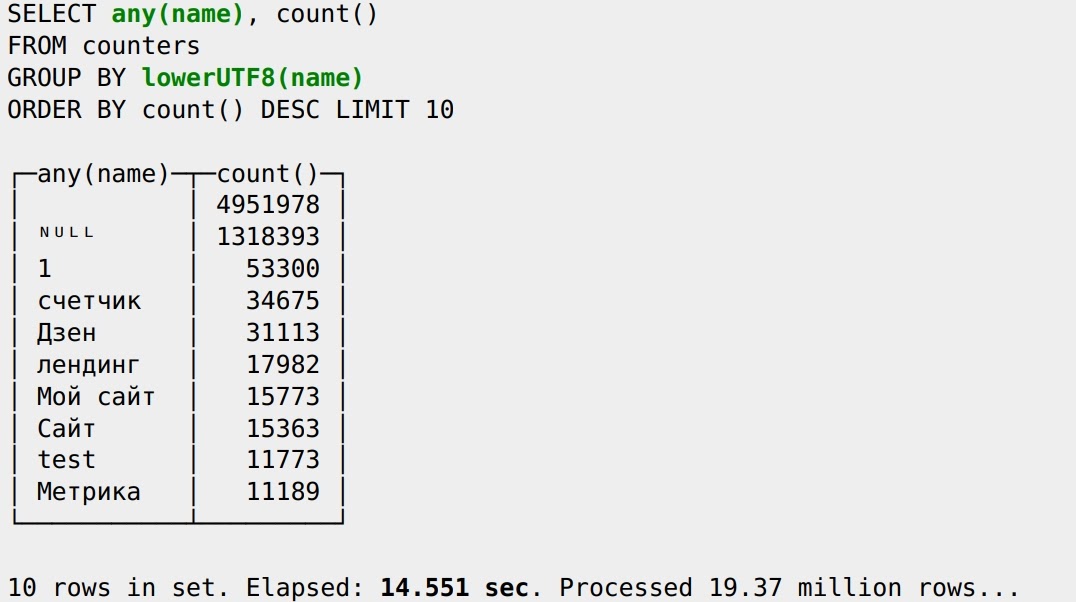
Теперь счетчик один, данные почти совпадают и запрос даже ускорился. То есть ClickHouse быстрый независимо от того, какие выражения я напишу. Попробуем ускорить запрос еще больше. На основе данных из MySQL в ClickHouse можно создать словарь. Указываем в словаре ключ и источник MySQL со всеми этими данными:
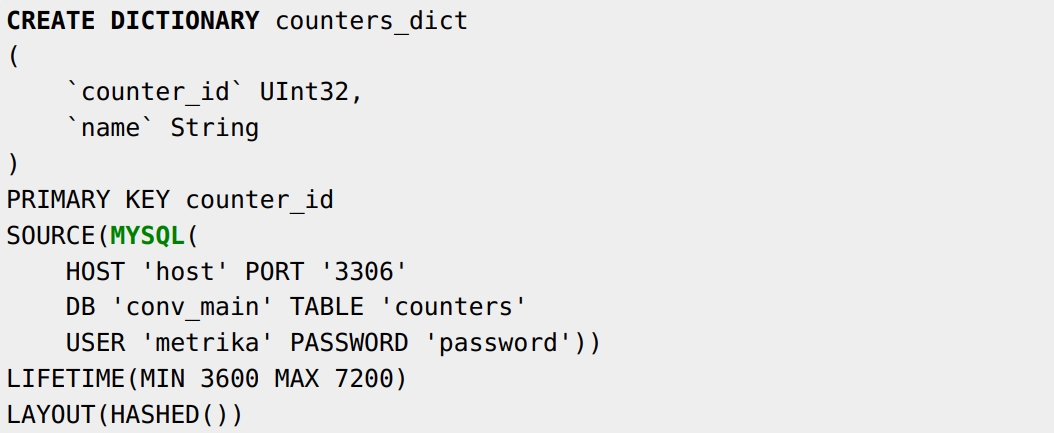
Словарь будет периодически загружать таблицу в оперативку, она будет кэшироваться. Можно применять SELECT:
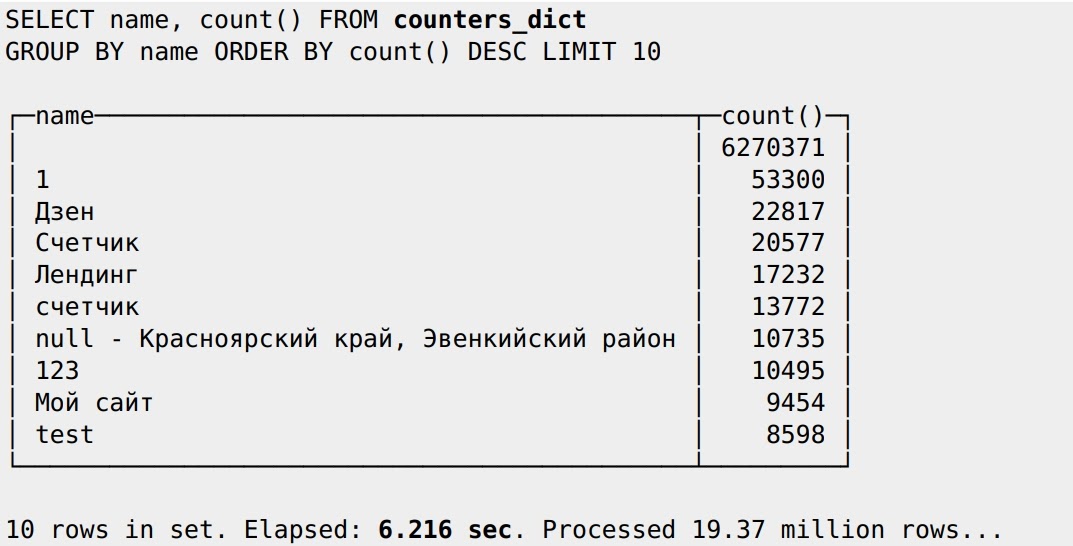
Получилось уже 6 секунд, хотя основное предназначение словаря — использование для джойнов, когда, например, нам нужно получить данные динамически через другие столбцы. Можно также создать словари MySQL на каждом сервере в кластере ClickHouse и быстро с ними работать. Но если MySQL не выдержит нагрузки при обновлении словаря на каждом сервере в кластере, то можно создать из MySQL словарь на двух ClickHouse-серверах, и они будут доступны в виде таблиц в ClickHouse. Если с помощью движка Distributed создать таблицу, которая смотрит на эти два сервера как на реплики, то можно на всех ClickHouse-серверах создать словари из ClickHouse, которые смотрят на таблицу, которая смотрит на словарь MySQL.
Словари еще можно использовать для шардирования, если схема расположена во внешней мета-базе (и не обязательно в ClickHouse). Это тоже будет работать:

Есть вариант как радикально ускорить запрос, и для этого не нужны словари — надо всего лишь переложить данные в полноценную таблицу типа MergeTree такой же структуры. Вставляем туда данные и делаем SELECT:
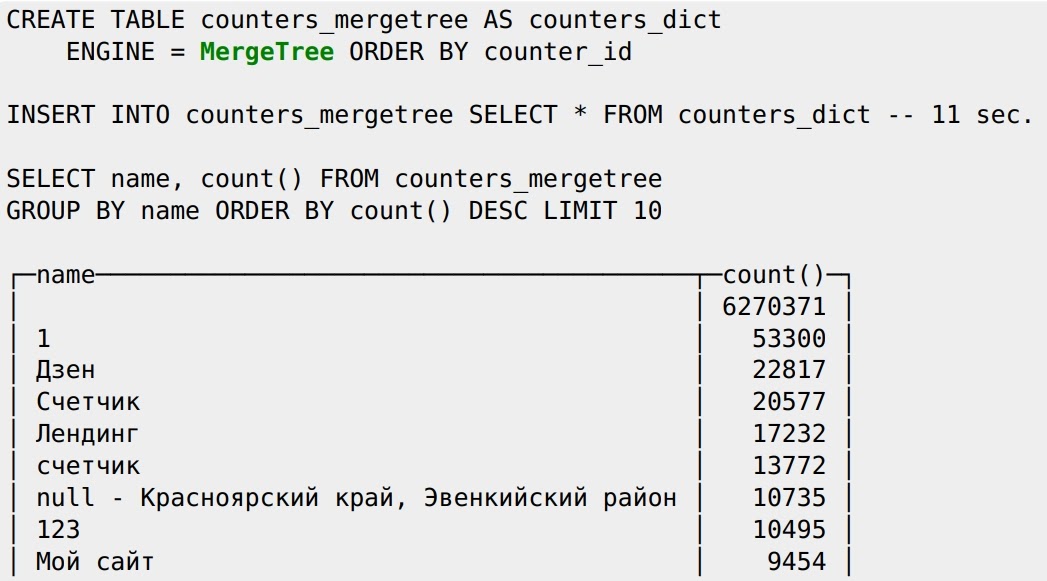
Видим, что SELECT выполняется за 0,6 с. Вот это настоящая скорость, какая должна быть — это скорость ClickHouse!
В ClickHouse можно даже создать базу данных типа MySQL. Движок БД MySQL создает в ClickHouse базу данных, которая содержит таблицы, каждая из которых представляет таблицу, расположенную в MySQL. И все таблицы будут видны прямо в ClickHouse:

А вообще в ClickHouse много табличных функций. Например, с помощью табличной функции odbc можно обратиться к PostgreSQL, а с помощью url — к любым данным на REST-сервере. И все это можно поджойнить:

Примечение: в свежих релизах ClickHouse появилась табличная функция postgresql, движок баз данных PostgreSQL и даже поддержка бинарного протокола PostgreSQL. Кажется это даже слишком круто.
Машинное обучение в ClickHouse
В ClickHouse можно использовать машинное обучение с помощью подключения готовых моделей CatBoost. После объявления модели в конфигурационном файле, она доступна для применения в виде функции modelEvaluate.
Это можно использовать для заполнения пропусков в данных. Пример: компания, занимающаяся недвижимостью, публикует объявления о квартирах с разными параметрами: количество комнат, цена, метраж. Часто некоторые параметры не заполнены — например, квадратные метры есть, а количества комнат нет. В этом случае мы можем использовать ClickHouse с моделью CatBoost, чтобы заполнить пропуски в данных.
Более простые модели можно обучать прямо в ClickHouse. Модель машинного обучения у нас будет представлена как агрегатная функция — например, стохастическая логистическая регрессия. Задаются гиперпараметры, значение предсказываемой функции и значения фич, причем обучение будет независимым для каждого ключа агрегации, если в запросе указан GROUP BY:

А еще мы можем добавить к агрегатной функции суффикс State:
SELECT stochasticLogisticRegressionState(...
Так можно обучить логистическую регрессию для каждого k и получить состояние агрегатной функции. Состояние имеет полноценный тип данных AggregateFunction(stochasticLogisticRegression(01, 00, 10, 'Adam'), ...), который можно сохранить в таблицу. Достать его из таблицы и применить обученную модель можно функцией applyMLModel:

Но и это еще не все. Мы можем обучить тысячи маленьких простых моделей, записать их в таблицу и сделать джойн из этой таблицы, чтобы применять свою модель для каждого ключа:
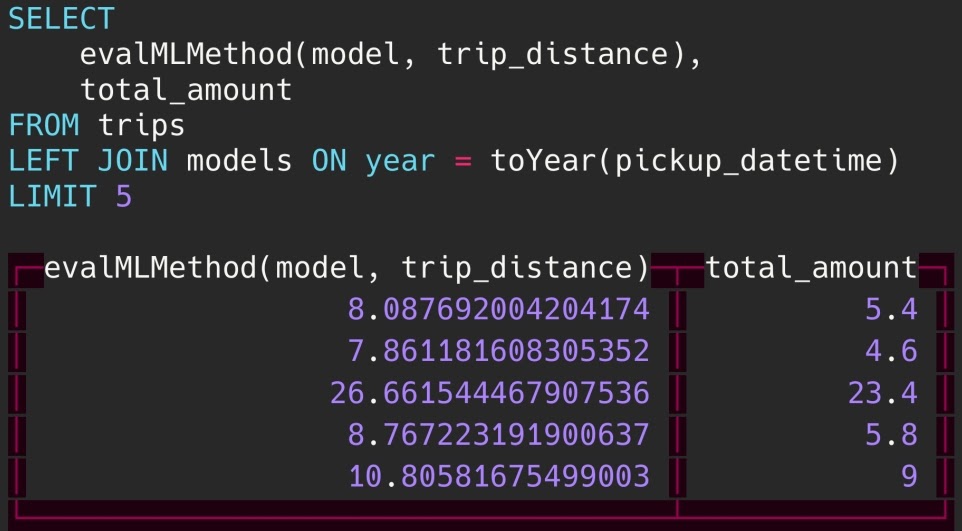
Более развернуто описано в этой презентации.
ClickHouse как графовая база данных
Конечно, ClickHouse — это не графовая БД и никогда даже не планировался для этого, но тем не менее. Представьте, что таблицы представляют собой ребра графа. С помощью табличной функции можно записывать алгоритмы на графах, например, реализовать алгоритм pagerank:

Это работает, и говорят, даже быстрее, чем некоторые другие графовые базы данных. Разработал его наш друг, один из ведущих контрибьюторов Amos Bird. Правда, эта разработка не доступна в open-source. Но мы не обижаемся.
UDF в ClickHouse
Казалось бы, в ClickHouse нет возможности написать пользовательские функции (user defined functions). Но на самом деле есть. Например, у вас есть cache-словарь с источником executable, который для загрузки выполняет произвольную программу или скрипт на сервере. И в эту программу в stdin передаются ключи, а из stdout в том же порядке мы будем считывать значения для словаря. Словарь может иметь кэширующий способ размещения в памяти, когда уже вычисленные значения будут кэшированы.
И если вы пишете произвольный скрипт на Python, который вычисляет, что угодно — пусть те же модели машинного обучения, — и подключаете его в ClickHouse, то получаете вы как раз аналог user defined function.
Примечание: полноценная реализация UDF находится в roadmap на 2021 год.
ClickHouse на GPU и как Application Server
Это ещё два необычных примера. В компании nVidia ClickHouse заставили работать на графических ускорителях, но рассказывать я про это не буду.
А наш друг Zhang2014 — превратил ClickHouse почти в Application Server. У Zhang2014 есть pull request, где можно определить свои HTTP-хэндлеры и этим хэндлерам приписать подготовленный запрос (SELECT с подстановками или INSERT). Вы делаете POST на какой-то хэндлер для вставки данных, или делаете вызов какой-то GET ручки, передаете параметры, и готовый SELECT выполнится.
Вывод
ClickHouse — очень интересная система, в которой всегда можно найти что-то новое, причем, что интересно, что-то новое там всегда могу найти даже я. Многие разработчики удивляют меня тем, что они могут реализовывать внутри ClickHouse всего лишь чуть-чуть поменяв его код. И эти штуки будут работать и в production!


vitaly_il1
Пример с clickhouse-local — обалдеть!