

Мы тут автоматизируем автобусы, недавно вот с нашей помощью все билеты в России стали электронными. Рынок только-только хоть как-то приходит в ИТ, и там всё ещё очень много всего делается в амбарных книгах.
Расскажу про один простой эпизод автоматизации, который уже десятки лет назад пройден в авиации и на железной дороге, но только-только начался у нас. Итак, ситуация: есть примерно сотня разных информационных систем, которые присылают нам данные про автобусные рейсы. Это набор самописных автоматизаций разных перевозчиков и конкурирующих коммерческих продуктов. Каждая система имеет свой формат записи о том, как делается возврат билета на автобус. Чаще всего — человекочитаемая запись на русском языке, написанная для операторов и кассиров, но около 20% систем вообще не присылают данные о возврате в принципе.
Часть правил пересекаются, причём может быть несколько уровней вложенности: «Все билеты невозвратные, но на этом направлении туда возвращаем по 259-ФЗ, обратно — вот по этим условиям».
Нам нужно показывать пассажиру условия возврата билета (возвратный, невозвратный, 100% возврат или нет, когда можно возвращать), использовать эти параметры для поиска, сравнения и, собственно, автоматизации возвратов.
Ну а мне нужно было понять, как несколько тысяч текстов на русском языке превратить в параметры билета, где хранить и как этим всем управлять.
Как выглядят ответы источников данных?
Вот примеры:



Первое, что приходит в голову — это NLP-разбор. Чтобы научить нейросетевой движок NLP разбирать всё это, нужен набор правил, который сформирует корпус для обучения. Чтобы получить набор правил, нужно распарсить всё вручную и свести к неким наборам правил в едином формате.
Решение оказалось простым, как бревно. Правила возврата почти у всех не меняются годами, и в месяц приходит всего несколько новых строк. У нас есть отдел контента, который занимается тем, что собирает данные из разных источников — например, обзванивает автовокзалы, собирает данные об остановках и так далее. Что-то из этого автоматизируется, что-то нет. То, что автоматизируется — покрывается скриптом и тестами и идёт в прод. То, что делается вручную, может быть упрощено тем, что в контент будут приходить уже подготовленные данные, то есть мы будем вызывать человека-оператора через некое API, содержащее типовую форму запроса.
Распарсить всё вручную один раз и поддерживать изменения вручную оказалось дешевле, чем прикручивать и поддерживать автоматизацию, а потом следить за её правильностью. В итоге мы использовали сложные нейросети — непосредственно мозг операторов. И они показали очень высокую производительность.
Потом мы добавили хеширование правила по MD5 после очистки от нефункциональных пробелов и приведения к одному регистру — чтобы понимать, что оно поменялось. Если оно поменялось — автоматизация ставит задачу отделу контента, а отдел контента заносит новое правило в нашу систему.
Опять же, правильно использовать для хранения множества правил решения класса BRMS. Но у нас всё оказалось проще, всё множество правил свелось к вот таким матрицам:
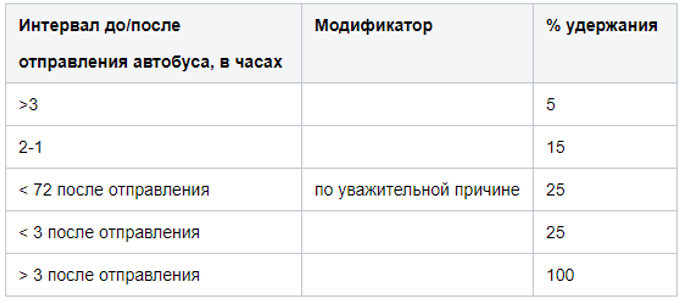
В этой итерации решили на модификаторы забить. Во-первых, непонятно какие они бывают. Во-вторых — похоже, что они мало где используются. По крайней мере, до сих пор особой необходимости в них не возникало.
Превращается это вот в такой текст единого формата:

Поэтому мы их храним прямо в своей системе, управляющей параметрами билетов. То есть, по сути, просто добавляем в базу данных в каждый билет ссылку на правила его возврата от данной компании.
Вот так это стало выглядеть:

GDS — это источники, дальше идёт «схлопывание» рейсов (один и тот же рейс может прийти из разных источников с некоторыми изменениями, больше про этот ад есть вот здесь, например).
Вот так работает уровень матчера правил. Из каждого рейса достаётся правило возврата, по его хешу ищется соответствующее наше правило (разобранное в нужный нам вид), и если всё получилось, оно применяется:

Часто GDS не присылает для какого-то рейса правила возврата. В таком случае мы можем завести свои, «ручные», правила возврата. Например, можем применить стандартные, прописанные в федеральном законе. Кстати, что интересно, по идее, это должны быть минимальные условия для всех, но на практике они часто либо улучшаются, либо ухудшаются перевозчиками.
У перевозчиков могут быть локальные правила, как я приводил пример — «для всех рейсов так, но на рейсах Москва — Петербург — вот так». Специально для этого мы для «ручных» правил сделали параметр «приоритет». В итоге такое «ручное» правило возврата состоит из трёх частей: параметры, по которым мы понимаем, что это правило подходит (город отправления/прибытия, перевозчик, GDS), приоритет и результат (собственно, те самые интервалы с процентами удержания). Когда GDS отдаёт рейс без правил возврата, мы идём в базу с «ручными» правилами, выбираем все подходящие и берём то, у которого наибольший приоритет. Дальше рейс декорируется этими полученными правилами.
Конечно, мы можем что-то не покрыть такими «ручными» правилами. Для этого мы сделали отчёт, в который попадают направления, не покрытые правилами. Его в ручном режиме разбирают сотрудники отдела контента.
Вот так. Как я говорил, всё довольно просто, но таких ситуаций на рынке ещё море, потому что автобусный рынок только-только открывает электронные продажи, и там огромный зоопарк самописных решений, либо же вообще часто никакой автоматизации нет.
Ну а мы теперь создали единую базу правил возврата билетов для каждого известного нам официального автобусного рейса в России.

ivanokunev
Обидно! Заголовок обещает матчер, по факту матчер остается физическим (глаза/мозг)
agoosev89 Автор
В данном случае такое решение оказалось самым дешевым и эффективным) Оказалось проще дать разметить эти правила операторам (учитывая их количество и частоту обновления), чем прикручивать нейросети, NLP и вот это все.