

Приветствую,
Вам когда-нибудь хотелось узнать, как же именно работает программа, которой вы так активно пользуетесь, игра, в которую часто играете, прошивка какого-нибудь устройства, которое что-то делает по расписанию? Если да, то для этого вам потребуется дизассемблер. А лучше — декомпилятор. И если с x86-x64, Java, Python ситуация известная: этих ваших дизассемблеров и декомпиляторов полным-полно, то с другими языками всё обстоит немного сложнее: поисковые машины уверенно утверждают — «It's impossible».
Что ж, мы решили оспорить данное утверждение и произвести декомпиляцию NodeJS, а именно выхлоп, который выдаёт npm-пакет bytenode. Об этом подробнее мы и расскажем по ходу статьи. Заметим, что это уже вторая статья в серии о нашем плагине для Ghidra (первый материал был также опубликован в нашем блоге на Хабре). Поехали.
Часть нулевая: забегая вперёд
Да, нам действительно удалось произвести декомпиляцию NodeJS в Ghidra, преодолев путь от этого кода:
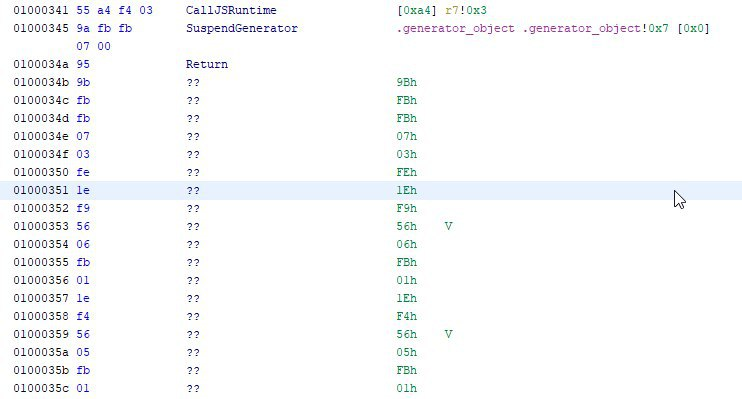
К этому:
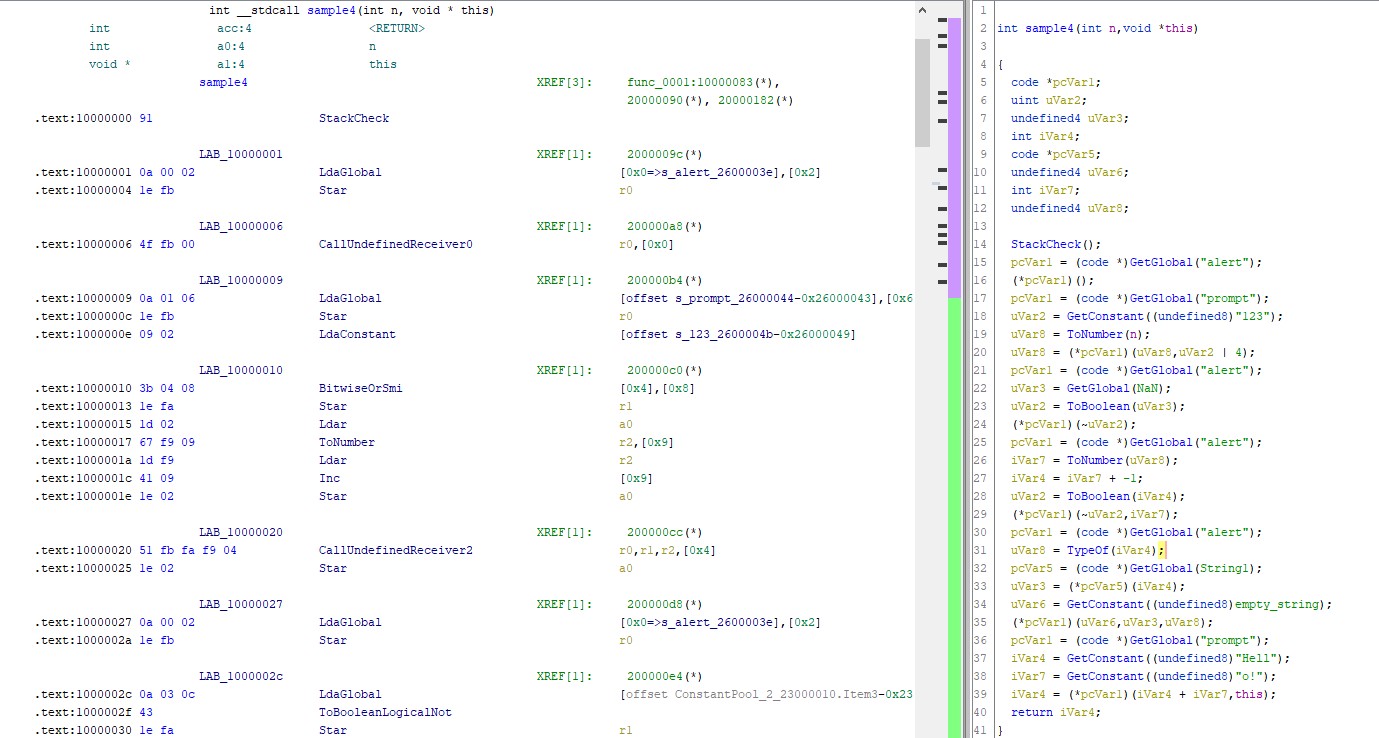
В итоге мы рады представить вам плагин-загрузчик, который обладает следующими возможностями:
- Парсинг вывода bytenode. Кроме исполняемого кода, он также парсит пул констант, аргументы функций, области видимости, обработчики исключений, контекстные переменные и многое другое.
- Полноценная загрузка исследуемого jsc-файла в Ghidra, с отображением пользователю необходимых для реверс-инжиниринга данных.
- Поддержка всех опкодов, в том числе с различными вариациями их длины — расширенных (wide) и экстрарасширенных (extra-wide).
- Подтягиваются вызовы функций стандартной библиотеки (
Intrinsic— иRuntime-вызовы). - Анализируются все перекрёстные ссылки, даже в обфусцированном коде, что дает возможность исследовать любые NodeJS-приложения.
Конечно, есть и ряд ограничений. О них в конце статьи.
Составные части плагина
Сейчас модуль состоит из четырёх частей:
- Загрузчик: парсит файл, создаёт необходимые секции для кода и констант. Тем, кому дизассемблер ближе декомпилятора, пригодится.
- Анализатор: работает после загрузчика. Расставляет перекрёстные ссылки, убирает stub-код, сгенерированный компилятором (упрощает анализ), следит за контекстом исполнения.
- Дизассемблер и по совместительству декомпилятор. Благодаря технологиям, реализованным в Ghidra, при написании дизассемблера вы одновременно получаете и декомпилятор, что очень удобно. Для этого используется внутренний язык Гидры — SLEIGH.
- Последняя часть модуля — инжектор конструкций на PCode (языке промежуточного представления в Ghidra, аналоге микрокода в IDA). Инжектор формирует промежуточное представление для декомпилятора в тех случаях, когда через SLEIGH это реализовать сложно, или даже невозможно.
Процесс создания
Как это обычно и бывает, когда ты занимаешься реверс-инжинирингом всякой дичи, «пришёл один бинарь». В нашем случае он имел расширение .jsc и запускался с помощью node.exe. Гугление по данной связке привело к bytenode — пакету для Node.js, позволяющему собрать исходник на JavaScript в виде jsc-файла с байткодом, который гарантированно запустится на той же версии Ноды, если в ней установлен этот самый bytenode.
Бинарь вроде похож на файлы .pyc или .class, где интерпретатор точно так же исполняет собранный под него файл. Проблема только в том, что и для первого, и для второго формата давно существует множество различных файлообменников декомпиляторов, а для формата Ноды — нет.
Но ведь в node, скажете вы, уже существует встроенный дизассемблер, и с его помощью можно смотреть на то, что происходит в запускаемом файле. Да, это так. Но он скорее рассчитан на то, что исходный файл у вас всё-таки имеется. У нас же его не было. Поэтому, сделав волевое усилие, мы приняли решение написать этот, будь он проклят, декомпилятор! Знали бы мы тогда, какие мучения нас ждут, — взялись бы за проект? Конечно, взялись бы!

(Пример jsc-файла в hex-редакторе. Видны некоторые заголовки и строки)
Погружение и сборка node.js
Итак, что нам необходимо, чтобы начать разбор формата? Теория, в которой рассказывается о принципах работы Ноды? Кто вообще так делает? (Между прочим, данная теория прекрасно изложена в статье по ссылке.) Нам нужны исходники Node! Более того, они должны быть той же версии, в которой собран jsc-файл. Иначе не заработает.
Сделав клон репозитория и попытавшись его собрать, мы наткнулись на первые трудности: не собирается. Конечно, учитывая размеры репозитория и его кроссплатформенность — удивляться нечему. Тем более последнюю на момент написания статьи версию Visual Studio 2019 в системе сборки Node.js стали поддерживать не так давно. Поэтому, чтобы собрать именно нужную нам v8.16, пришлось клонировать обе ветки: современную и нужную нам, а затем сравнивать систему сборки.
Система сборки состоит из набора Python-скриптов, «батников» и sln-проектов. Python-скрипты генерируют проекты для Visual Studio, подставляются дефайны, а затем Студия всё это дело собирает. Действительно, собирает. Но только в режиме сборки Release оно почему-то работает, а в Debug — нет. А для наших целей нужна была именно дебажная сборка.
В ходе разборок со Студией, которые отняли несколько дней, выяснилось, что виной всему флаги препроцессора: они почему-то ломают работу интерпретатора именно при взаимодействии с bytenode. Ну ничего, флаги во всех ?10 проектах для всех вариантов сборок были поправлены, и дебажная Нода была успешно собрана.

(Часть проекта NodeJS в Visual Studio)
Теперь с её помощью можно успешно отлаживать исходный код самой Node.js. Кроме того, появляются дополнительные флаги трассировки при исполнении, которые ещё больше помогают понять, что происходит при исполнении кода.
Парсинг формата
Было установлено огромное количество брейкпоинтов (точек останова) во всех местах, где, по идее, мог начинаться разбор jsc-файла, и наконец-то была запущена отладка.
Некоторые из установленных брейкпоинтов начали срабатывать ещё до того, как начинался разбор самого jsc-файла, что говорит нам о том, что сама Нода использует такой формат для хранения скомпилированных jsc-файлов у себя внутри исполняемого файла. В конце концов дело дошло и до нашего файла.
И тут началось.
Уже давно никто не удивляется, что в крупных проектах на C++ используется огромное количество макросов. Да, несомненно, они помогают при написании кода сократить большие и повторяющиеся участки, но при отладке они совсем не помогают, а делают этот процесс очень сложным и долгим, особенно если нужно найти, где что объявляется или присваивается, а присваивается и объявляется оно в макросе, который состоит примерно из 20 строк.
Тем не менее с каждой новой сессией построчной отладки код разборщика всё расширялся и расширялся, пока нам всё же не удалось написать свой собственный парсер на Python, который успешно проходил все сериализованные данные.
Конечно, навигация по JSON (о нём расскажем чуть позже) — та ещё весёлая задача, поэтому было принято не менее важное решение, очень сильно повлиявшее на наши дальнейшие запросы, — перейти на Ghidra. Это решение влекло за собой следующие проблемы, которые пришлось решать:
- перенос парсера с Python на Java и написание загрузчика jsc-формата;
- создание нового процессорного модуля, который позволит дизассемблировать V8 (именно этот движок используется в Node.js);
- реализация логики самих опкодов V8 с целью получения декомпилированного листинга.
Загрузчик для Ghidra № 1
Первый загрузчик был простым: он разбирал JSON, который генерировался Python-версией парсера, создавал все секции, объекты, загружал байткод. Пока одна часть команды писала разборщик, другая её часть занималась реализацией опкодов на SLEIGH, параллельно создавая концепт плагина для Ghidra. Таким образом, к моменту, когда этот вариант загрузчика был готов, вся команда могла работать совместно.
Хотя этот вариант нас и устраивал, делать публичный релиз именно таким не хотелось: неюзабельно, неудобно и вообще… Поэтому мы взялись писать загрузчик № 2.
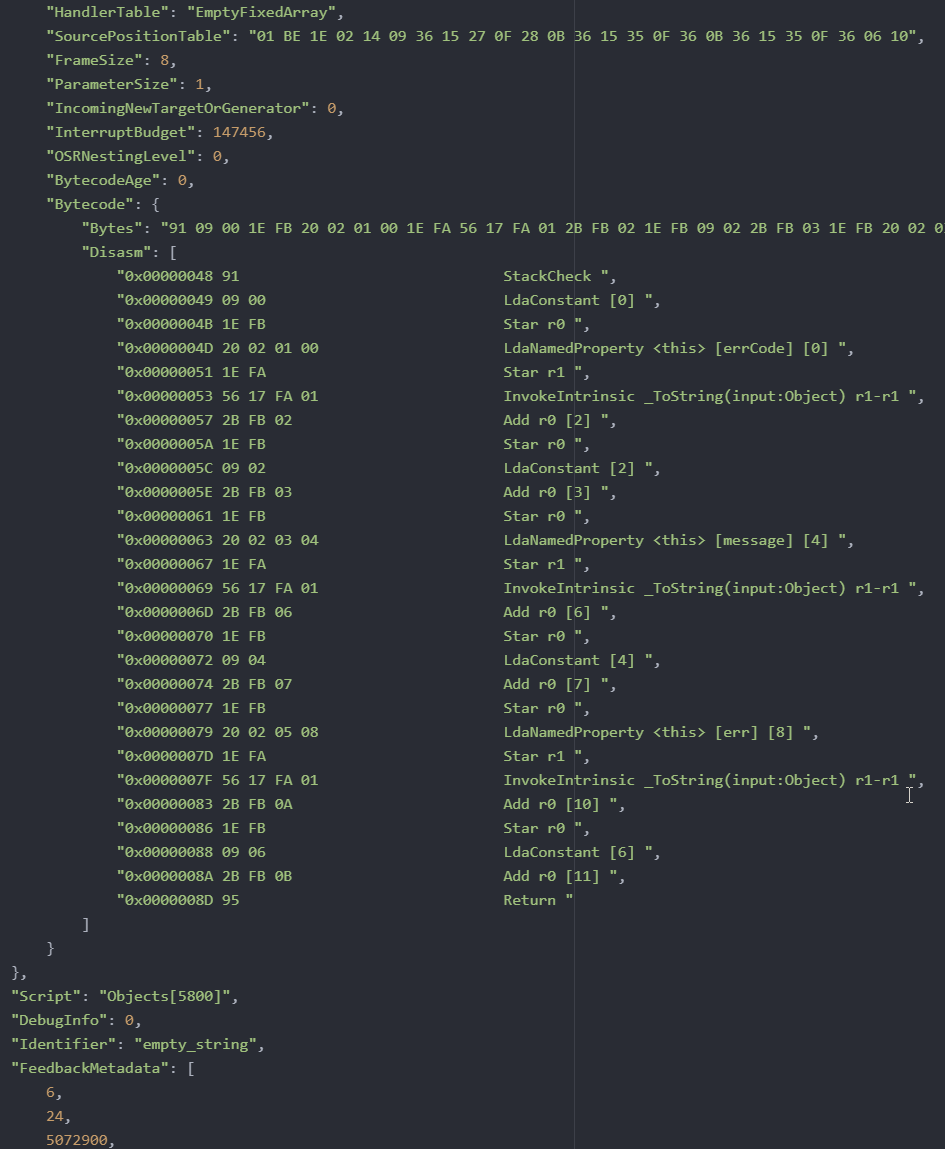
(Пример JSON-выхлопа первого варианта загрузчика. Как видно, он хоть и являлся структурированным, но был сильно неудобным при навигации по коду и данным)
Загрузчик для Ghidra № 2
На этом варианте мы и остановились. Как уже было сказано, он умеет грузить jsc-формат напрямую, разбирать и создавать структуры, делать перекрёстные ссылки, анализировать всё что нужно и как это нужно Гидре. Да и вообще, этот вариант нам нравился больше, так как у него был выше потенциал уже на старте. Единственный нюанс — такой загрузчик пришлось куда дольше писать. Но результат того стоит.
С вводными ознакомились, теперь пора углубиться в настоящий кошмар. И первым нас встречает загрузчик.
Внутрянка загрузчика
Собственно, загрузчик занимается подготовительной работой для всех остальных компонентов плагина. Ему нужно сделать много всего:
- разобрать jsc-файл на структуры, которые будут затем использованы дизассемблером, анализатором, декомпилятором;
- отобразить пользователю плагина все те структуры, которые потребуются при реверс-инжиниринге: код, строки, числа, контексты, обработчики исключений и многое другое;
- переименовать все объекты, у которых есть названия, и у которых их нет (обычный код, обёрнутый в скобки);
- идентифицировать встроенные функции Node.js, которые вызываются исключительно по индексам.
На этом этапе в коде плагина пришлось создать множество Java-классов (структур), каждый для своего типа данных, чтобы совсем в них не запутаться. Наверное, на эту часть кода было потрачено больше всего времени.
Загруженный в Ghidra файл обычно выглядит как-то так:
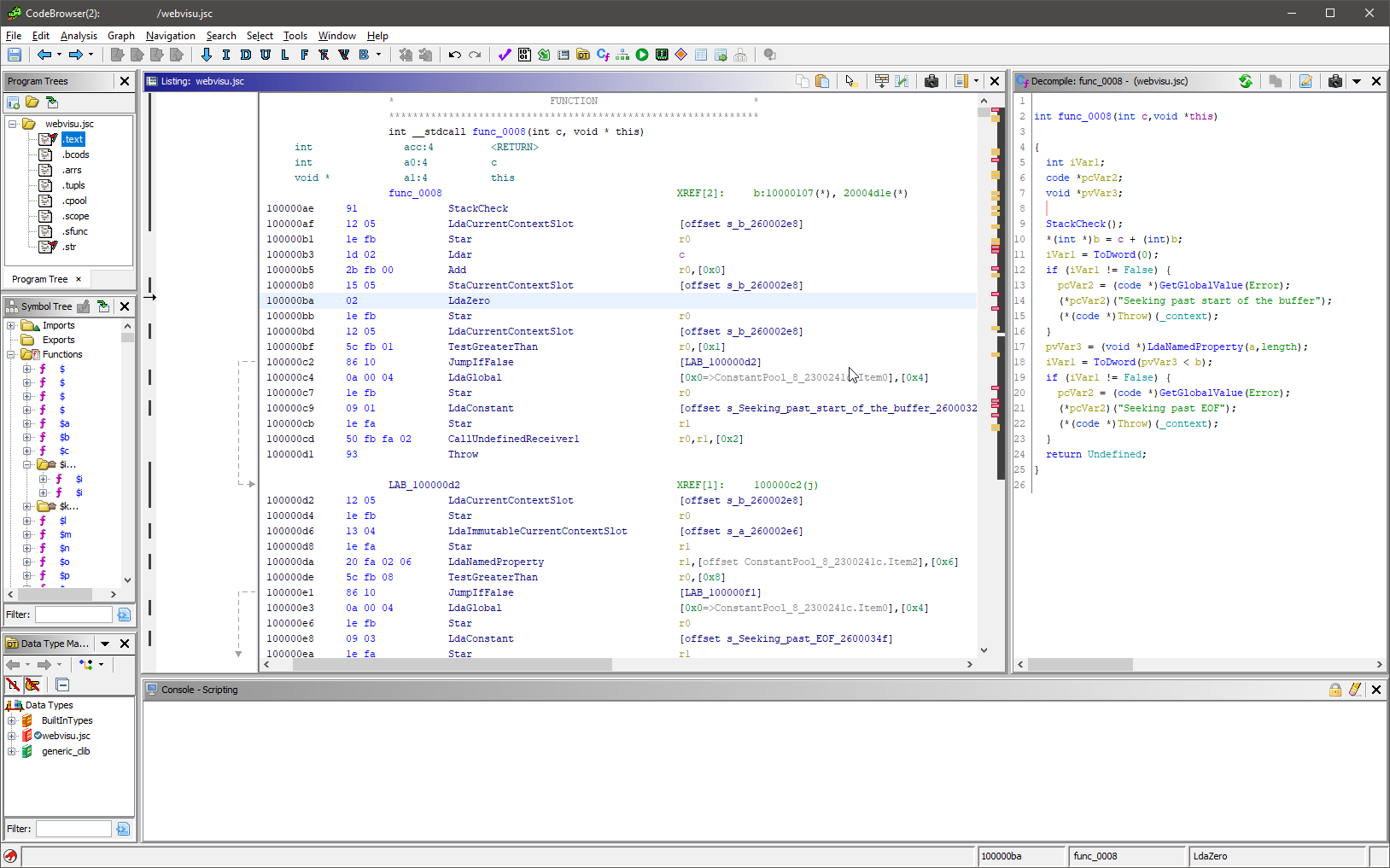
- Слева сверху видны сегменты. В jsc их нет, но нам пришлось создать их, чтобы сгруппировать сходные типы данных, и отделить их от кода.
- Слева идёт список функций. В случае с файлом, изображённым на скриншоте выше, они все обфусцированные, поэтому имеют одинаковые имена. Но это никак не мешает плагину выстраивать перекрёстные ссылки.
- В центре скриншота виден дизассемблерный листинг. Вам в любом случае придётся с ним работать, так как декомпилятор не всесилен.
- Справа виден декомпилированный C-подобный листинг. Как видим, он значительно облегчает анализ jsc-приложения.
Дизассемблер
Собственно, для того чтобы весь загруженный набор байтов стал кодом, его нужно дизассемблировать. Фактически при создании плагина с помощью специального языка (SLEIGH) вы описываете порядок преобразования одних байтов в одни инструкции, а других — в другие.
С точки зрения особенностей написания процессорного модуля можно отметить следующее:
- Байт-код V8 интерпретируемый, что усложняет процесс реализации. Тем не менее во многих моментах нам очень помогали исходные коды других процессорных модулей, например виртуальной машины Java.
- • При реализации некоторых типов регистров (например, для работы с локальными переменными могут использоваться регистры с индексом от
0до0x7FFFFFFF-4) пришлось пойти на компромисс в виде максимально отображаемых в дизассемблере.
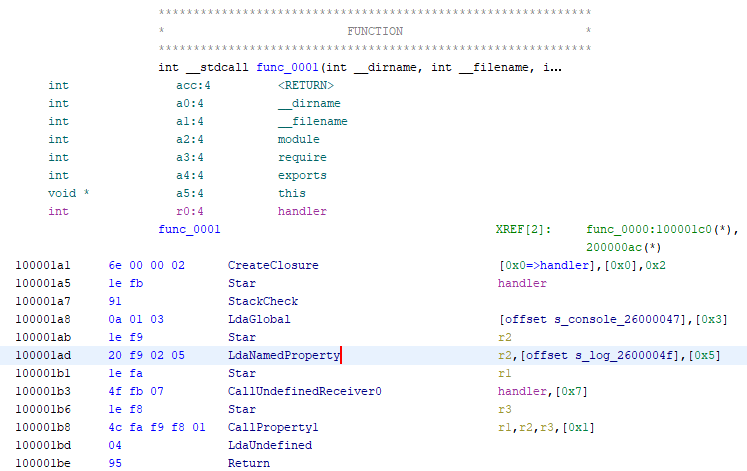
(Типичный дизазм V8)
Анализатор
Наверное, второй самой объёмной частью плагина после загрузчика является анализатор. Его основной задачей является наведение порядка после работы загрузчика. Он подразумевает:
- создание перекрёстных ссылок на код и данные (constant pool),
- отслеживание контекста исполнения (codeflow) программы,
- упрощение представления асинхронного кода,
- накопление информации для декомпилятора.
Создание ссылок и работа с constant pool
Если вы занимались реверс-инжинирингом Java-классов, то наверняка знаете, что самым главным объектом в каждом классе является constant pool. Вкратце, это что-то типа словаря, в котором по индексам в качестве ключей хранятся ссылки или значения в виде абсолютно любых объектов, например:
- строк, чисел, списков, кортежей и других примитивов;
- функций, областей видимости и других элементов кода.
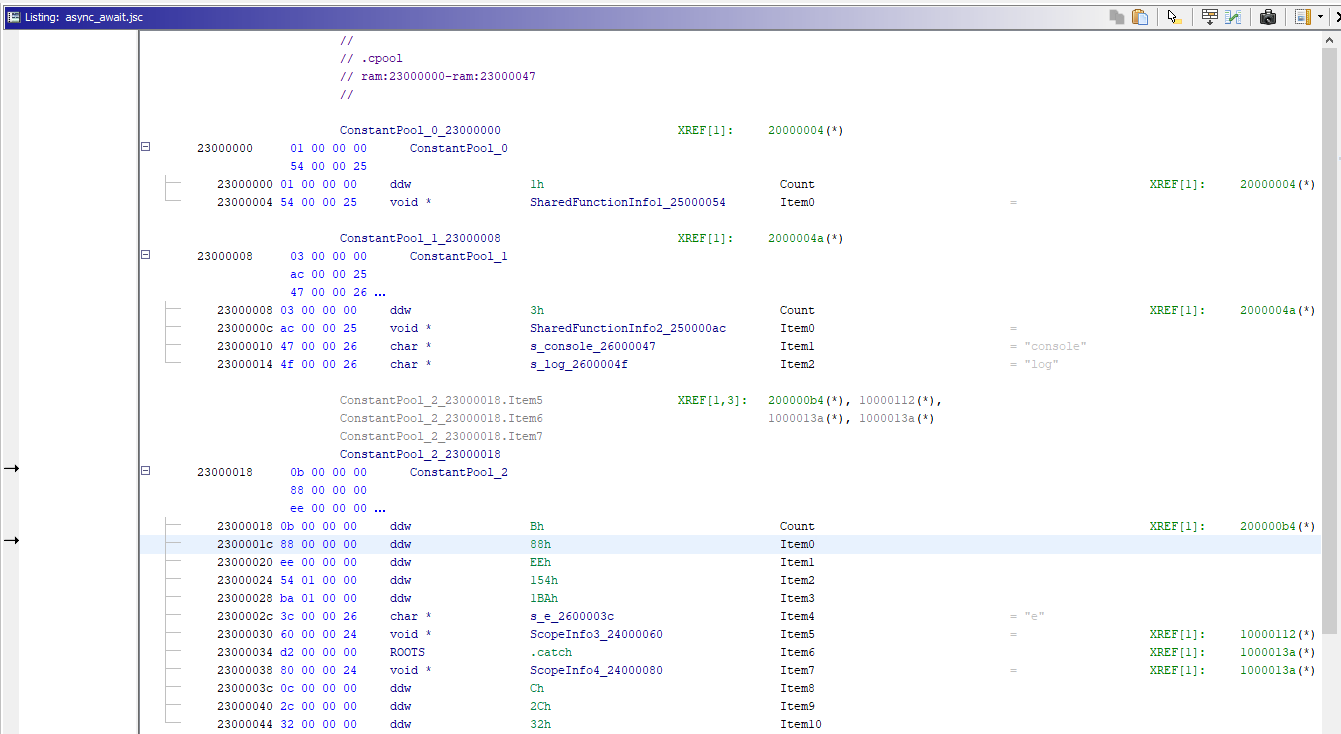
(Типичный constant pool. На скриншоте видны размеченные и аллоцированные загрузчиком элементы пула, а также ссылки на них. Можно заметить, что здесь хранятся данные практически любых типов)
Имея уже аллоцированные объекты и дизассемблерный листинг, анализатор проходится по каждой инструкции и, в зависимости от опкода, решает, что делать.
Из тех типов инструкций, что интересны анализатору, можно выделить следующие категории:
- имеют ссылки на constant pool,
- имеют ссылки на контекст исполнения или изменяют его,
- выполняют runtime-функции (встроенные).
Код для работы с первым типом инструкций достаточно объёмный, так как в constant pool может храниться практически всё. И на это всё нужно проставить ссылки. Но рассказать мы бы хотели только об одном из сложных случаев: SwitchOnSmiNoFeedback.
SwitchOnSmiNoFeedback
По названию может показаться, что это обычные свитчи, только для V8. В действительности это специальная конструкция для работы с асинхронным кодом, то есть с тем, который помечен с помощью ключевых слов await/async. Работает оно так:
- В инструкции
SwitchOnSmiNoFeedbackуказываются два индекса: первый — начальный индекс в constant pool, по которому лежат ссылки на функции, и второй — количество этих функций. - Сами функции представляют из себя автоматически сгенерированные пролог (тело, эпилог) для кода, который требуется исполнять асинхронно (делается обёртка в виде переключения контекста, его сохранения, выгрузки). В нашем плагине этот шаблонный код заменяется на NOP-инструкции (No OPeration).
Возьмём в качестве примера следующий код:
async function handler() {
try {
const a = await 9;
const b = await 10;
const c = await 11;
let d = await 12;
} catch (e) {
return 123;
}
return 666;
}
console.log(handler());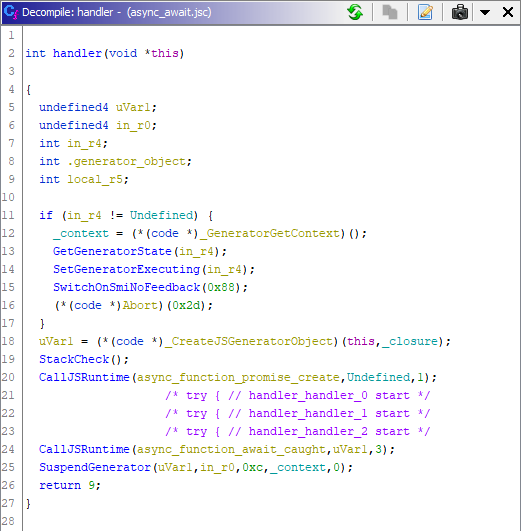
(Так обычно и выглядит функция с SwitchOnSmiNoFeedback без оптимизации)
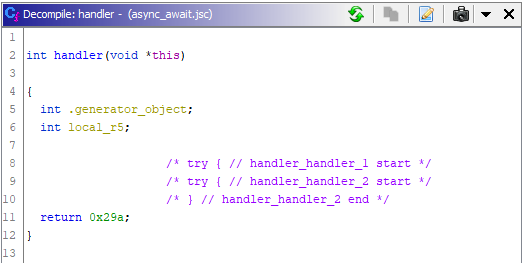
(А так с оптимизацией...)
Анализатор контекстов
Самой сложной частью оказалось слежение за контекстом исполнения. Дело в том, что в V8, как и в других языках программирования, есть области видимости переменных (констант, кода и т. д.). Обычно для их разделения используются фигурные скобки, отступы, двоеточия, другие элементы синтаксиса. Но как быть с кодом, который исполняется интерпретатором?
В случае V8 для этого были введены три специальных сущности:
- регистр контекста,
- значение глубины для обращения к контексту,
- сохранение контекста в стек контекстов (выгрузка из него).
Регистр контекста бывает как общий на функцию, так и создаваемый локально для какого-то участка кода, например для исключений. В этом регистре хранится условная ссылка на список переменных, доступных в данный момент (с их именами и модификаторами), а также ссылка на предыдущий доступный контекст, что даёт нам дерево областей видимости, которое мы можем обходить. К тому же значение регистра контекста можно сохранять в другие регистры, забирать из других регистров.
Глубина обращения к контексту — это не так сложно, если разобраться, как с ним работать. Глубина задаётся в качестве одного из операндов и указывает, на сколько уровней вверх по контексту мы должны подняться, чтобы забрать ту или иную переменную.
Runtime-функции
Основное, что здесь стоит отметить, это удаление (nop) из листинга обращений к функциям, также связанных со SwitchOnSmiNoFeedback, а именно async_function_promise_release, async_function_promise_create, promise_resolve. То есть плагин просто делает читаемость листинга декомпилятора выше.
Ссылки
GitHub: https://github.com/PositiveTechnologies/ghidra_nodejs/
Релизы: https://github.com/PositiveTechnologies/ghidra_nodejs/releases
Серьёзный разбор формата сериализации V8 движка в NodeJS: https://habr.com/ru/company/pt/blog/551540/
Недостатки
Конечно, они есть. Некоторые недостатки всплывают из-за ограничений Ghidra, другие — вследствие того, что проект делался под одну конкретную задачу (с которой отлично справился) и большого, полноформатного тестирования на сотнях семплов не было.
Релиз
Несмотря на то что публиковаться мы совершенно не планировали (проект закончился, отчёты сданы, сроки вышли), то количество сил, которое мы отдали этому проекту, мотивировало нас поделиться своим плагином с миром. Он масштабируется под другие версии, неплохо работает с теми файлами, которые мы в нём открывали, да и в целом его код написан достаточно грамотно (на наш взгляд).
Из вышесказанного следует и то, что исправления в плагин будут вноситься нами лишь по мере использования его на наших рабочих проектах. В остальное время будут фикситься совсем уж серьёзные баги, приводящие к полной неработоспособности плагина. Правда, мы будем очень рады пулл-реквестам с вашей стороны.
Ну и напоследок мне как автору данной статьи и соавтору плагина хотелось бы сказать большущее спасибо Сергею Федонину, Вячеславу Москвину, Наталье Тляповой за крутой проект.
— Спасибо за внимание
tzlom
Это декомпиляция в С или С-like? Почему функция из примера без оптимизации возвращает иной результат нежели с оптимизацией?
DrMefistO Автор
Функция без оптимизации не отображается гидрой корректно из-за SwitchOnSmiNoFeedback. А в оптимизированной версии условно корректно, поэтому так.