

Компания Cerebras два года назад представила свой первый процессор, размер которого был равен размеру кремниевой пластины. Площадь его составила 46 225 мм?, размеры — 220х220 мм, количество транзисторов — 1,2 трлн. Первый чип получил название WSE (Wafer Scale Engine) и производился по нормам 16-нм техпроцесса.
Что касается нового чипа, то он выполнен уже по нормам 7-нм техпроцесса. Площадь осталась той же, а вот транзисторов в два раза больше — теперь 2,6 трлн. Количество ядер тоже увеличилось более чем в два раза: 850 тысяч вместо 400 тысяч, как у предыдущей модели. Процессор предназначен для дата-центров, задач по обработке вычислений в области машинного обучения и искусственного интеллекта (AI).
Подробности создания и характеристики WSE-2
У чипа 40 ГБ встроенной памяти SRAM — на 22 ГБ больше, чем у предыдущей модели. Пропускная способность составляет 20 Пб/с. При этом энергопотребление чипа осталось на прежнем уровне — 15 кВт.

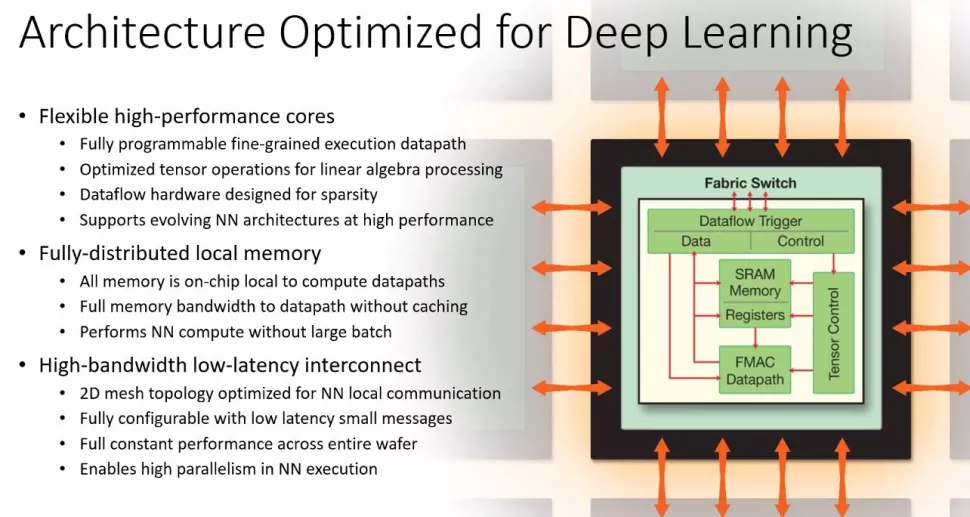
Отметим, что этот процессор — не концепт, а вполне себе рабочая система. Его создатели добиваются очень высокой производительности благодаря сшиванию штампов на кремниевой пластине посредством коммуникационной сети. Общая пропускная способность в итоге повышается до 220 Пб/с. Частота ядер — от 2,5-3 ГГц.
| Cerebras Wafer Scale Engine 2 | Cerebras Wafer Scale Engine | Nvidia A100 | |
| Process Node | TSMC 7nm | TSMC 16nm | TSMC 7nm N7 |
| AI Cores | 850,000 | 400,000 | 6,912 + 432 |
| Die Size | 46,255 mm2 | 46,255 mm2 | 826 mm2 |
| Transistors | 2.6 Trillion | 1.2 Trillion | 54 Billion |
| On-Chip SRAM Memory | 40 GB | 18 GB | 40 MB |
| Memory Bandwidth | 20 PB/s | 9 PB/s | 1,555 GB/s |
| Fabric Bandwidth | 220 Pb/s | 100 Pb/s | 600 GB/s |
| Power Consumption (System/Chip) | 20kW / 15kW | 20kW / 15kW | 250W (PCIe) / 400W (SXM) |
Чип сам по себе бесполезен, но компания специально для него разработала систему 15U, которая заточена исключительно под характеристики WSE-2. Система второго поколения почти ничем не отличается от системы первого. Блоки первого поколения ранее были отправлены заказчикам. Один из них установлен в Аргоннской национальной лаборатории министерства энергетики США. Она использует первую систему для научных целей — например, изучения черных дыр, а также для работы с медицинскими проблемами вроде анализа причин раковых заболеваний. Другим заказчиком стала Ливерморская национальная лаборатория.
В продажу чип и система для него поступят в третьем квартале 2021 года. Цена пока неизвестна.
Компания заявила, что компилятор легко масштабируется, так что проблем с использованием уже существующей экосистемы приложений нет. WSE-2 понимает стандартный код PyTorch и TensorFlow, который легко модифицируется с помощью специализированных программных инструментов и API-интерфейсов.
В чем уникальность такого процессора?
Именно в размере. Дело в том, что работать с одним большим чипом, площадь которого равна площади кремниевой пластины, очень сложно. Обычно микросхемы создают на круглых кремниевых пластинах диаметром 30,5 см. Из каждой можно изготовить 100 чипов.
Но далеко не все изготовленные чипы можно использовать, процент брака довольно велик. Проблема в процессе травления цепей в кремнии. Он настолько сложен, что не всегда проходит без ошибок и некоторые цепи в итоге просто не работают. Благодаря тому, что современные процессоры небольшие, процент ошибок невелик. Чем выше площадь чипа, тем больше вероятность получения дефектов, которые не позволят нормально использовать чип.
Большие процессоры пытались производить и ранее. Например, в 1980 году экс-сотрудник IBM Джин Амдал основал компанию Trilogy. Она получила целых $230 млн инвестиций, но в итоге так и не смогла выпустить готовый продукт, так что в 1985 году ее закрыли.
А вот у Cerebras, похоже, все получилось. Каким образом ей удалось достичь успеха, пока неясно, но, раз готовый продукт уже используется клиентами, значит, все хорошо. По словам представителей компании, WSE способен обучать системы AI в 100?1000 раз быстрее, чем существующее оборудование. Этого удалось достичь благодаря фильтрации нулевых данных ядрами SLAC (Sparse Linear Algebra Cores). Они оптимизированы для вычислений в векторном пространстве. Кроме того, разработчикам удалось создать технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение.


















cepera_ang
На минутку подумал, что такое дело можно будет у вас в облаке арендовать, даже загордился за российского провайдера :)
Железка однако весьма достойная, и когда о ней появилась первая информация, вызвала даже волну отрицания, что такое невозможно изготовить, а если возможно, то невозможно собрать в систему и охладить, а если и возможно, то всё равно никто не купит. Однако, клиентов хватает, судя по всему. Вот откуда дефицит чипов, если на каждый церебрас по целой пластине тратить :)
isden
Еще интересно сколько там пластин в мусор уходит, чтобы получить одну годную.
cepera_ang
Думаю нисколько, насколько я понимаю, там с запасом натыкано и ядер и интерконнектов и все дефектные просто отключаются и обходятся вокруг. Иначе вообще ни одного нереально было бы выпустить.
perfect_genius
Эдакий МультиКлет, получается.
napa3um
Интересно, возможна ли малварь (ну или не малварь), которая оживляет заблоченные на заводе ядра и биткоины на них майнит (пусть иногда с ошибками). Оверклокинг будет не по количеству мегагерц выше нормы, а по количеству ядер :).
amartology
Am0ralist
У амд с пластины около 30% брака при их чиплетах на 7 нм по статьям выходило. Если продумали систему, как отрубать бракованные ядра по одному-группами меньше чиплетов амд, то общий ущерб пластине будет сильно меньше. Видимо с хорошим запасом делают.
Ark1774
30% брака это на старте линии или на уже отлаженной? А то эти цифры значительно различаются.
Am0ralist
Статья была в общем, анализ какой-то. И там было: мол у АМД вот типа 30% брака на zen2, а у интела чуть ли не 75% для 28 ядерных. С другой стороны у амд чиплеты весьма активно сортируются и полубрак в младшие процы уходит по всем параметра (и по частотам ядер, и по потреблению, и по отключению ненужных ядер) — и не понятно поэтому насколько цифра изменится, если задача сделать те же апушки для приставок (где монолитные кристаллы в несколько раз больше габаритами и с большей точностью параметров нужны), там может и больше быть.
Но, если у обсуждаемых можно весьма гибко плохие места отключать от общей системы, то чем чёрт не шутит, могут и все пластины в итоге быть рабочими, просто на самом деле там может ядер процентов на 10 больше, например, да и параметры по частотам выбраны не максимально возможные на отсортированных ядрах, а какие-то не самые высокие.
ANIDEANI
На нём crysis хоть пойдёт?
Wingtiger
нет, только брутал дум кое-как