
Привет, Хабр!
Сейчас многие проекты используют микросервисную архитектуру. Мы также не стали исключением и вот уже больше 2х лет мы стараемся строить ДБО для юридических лиц в банке с применением микросервисов.

Авторы статьи: ctimas и Alexey_Salaev
Наш проект — это ДБО для юридических лиц. Много разнообразных процессов под капотом и приятный минималистичный интерфейс. Но так было не всегда. Долгое время мы пользовались решением от подрядчика, но в один прекрасный день было принято решение развивать свой продукт.
Начиная проект, было много обсуждений: какой же подход выбрать? как строить нашу новую систему ДБО? Началось все с обсуждений “монолит vs микросервисы”: обсуждали возможные используемые языки программирования, спорили про фреймворки (“использовать ли spring cloud?”, “какой протокол выбрать для общения между микросервисами?”). Данные вопросы, как правило, имеют какое-то ограниченное количество ответов, и мы просто выбираем конкретные подходы и технологии в зависимости от потребностей и возможностей. А ответ на вопрос “Как же писать сами микросервисы?” был не совсем простым.
Многие могут сказать «А зачем разрабатывать общую концепцию архитектуры самого микросервиса? Есть архитектура предприятия и архитектура проекта, и общий вектор развития. Если поставить задачу команде, она ее выполнит, и микросервис будет написан и он будет выполнять свои задачи. Ведь в этом и есть суть микросервисов – независимость». И будут совершенно правы! Но с течением времени команд становятся больше, следовательно — растет количество микросервисов и сотрудников, a старожил меньше. Приходят новые разработчики, которым надо погружаться в проект, некоторые разработчики меняют команды. Также команды с течением времени перестают существовать, но их микросервисы продолжают жить, и в некоторых случаях их надо дорабатывать.
Разрабатывая общую концепцию архитектуры микросервиса, мы оставляем себе большой задел на будущее:
Все, кто работают с микросервисами, прекрасно знают их плюсы и минусы, одним из которых считается возможность быстро заменить старую реализацию на новую. Но насколько мелким должен быть микросервис, чтобы его можно было легко заменить? Где та граница, которая определяет размер микросервиса? Как не сделать мини монолит или наносервис? А еще всегда можно сразу идти в сторону функций, которые выполняют маленькую часть логики и строить бизнес процессы выстраивая очередность вызова таких функций…
Мы решили выделять микросервисы по бизнес доменам (например, микросервис рублевых платежей), а сами микросервисы строить согласно задачам этого домена.
Рассмотрим пример стандартного бизнес процесса для любого банка — “создание платежного поручения”

Можно увидеть, что вроде бы простой запрос клиента является достаточно большим набором операций. Данный сценарий является примерным, некоторые этапы опущены для упрощения, часть этапов происходят на уровне инфраструктурных компонентов и не доходят до основной бизнес-логики в продуктовом сервисе, другая часть операций работает асинхронно. В сухом остатке мы имеем процесс, который в один момент времени может использовать множество соседних сервисов, пользоваться функционалом разных библиотек, реализовывать какую-то логику внутри себя и сохранять данные в разнообразные хранилища.
Взглянув более пристально, можно увидеть, что бизнес-процесс достаточно линеен и в по мере своей работы ему потребуется или получить где-то какие-то данные или как-то обработать те данные, что у него есть, и для этого может потребоваться работа с внешними источниками данных (микросервисы, БД) или логики(библиотеки).

Некоторые микросервисы не подходят под данную концепцию, но количество таких микросервисов в общем процентном соотношении небольшое и составляет около 5%.
Взглянув на разные подходы к организации кода, мы решили попробовать подход “чистой архитектуры”, организовав код в наших микросервисах в виде слоев.
Касательно самой “чистой архитектуры” написана не одна книга, есть много статей и в интернетах и на хабре (статья 1, статья 2), не раз обсуждали ее плюсы и минусы.
Популярная диаграмма которую можно найти по этой теме, была нарисована Бобом Мартиным в его книге “Чистая архитектура”:

Здесь на круговой диаграмме слева в центре видно направление зависимостей между слоями, а скромно в правом углу видно направление потока исполнения.
У данного подхода, как, впрочем, и в любой технологии программирования, имеются плюсы и минусы. Но для нас положительных моментов намного больше, чем отрицательных при использовании данного подхода.
Мы перерисовали данную диаграмму, опираясь на наш сценарий.
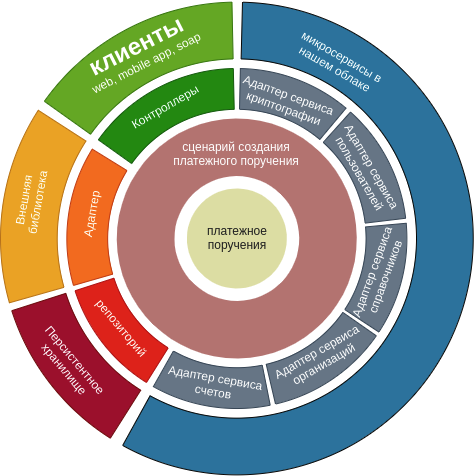
Естественно, на этой схеме отражается один сценарий. Часто бывает так, что микросервис по одной доменной сущности производит больше операций, но, справедливости ради, многие адаптеры могут использоваться повторно.
Для разделения микросервиса на слои можно использовать разные подходы, но мы выбрали деление на модули на уровне сборщика проекта. Реализация на уровне модулей обеспечивает более легкое визуальное восприятие проекта, а также обеспечивает еще один уровень защиты проектов от неправильного использования архитектурного стиля.
По опыту, мы заметили, что при погружении в проект новому разработчику, достаточно ознакомиться с теоретической частью и он уже может легко и быстро ориентироваться практически в любой микросервисе.
Для сборки наших микросервисов на Java мы используем Gradle, поэтому основные слои сформированы в виде набора его модулей:

Сейчас наш проект состоит из модулей, которые или реализуют контракты или используют их. Чтобы эти модули начали работать и решать задачи, нам нужно реализовать внедрение зависимостей и создать точку входа, которая будет запускать все наше приложение. И тут возникает интересный вопрос: в книге дядюшки Боба “Чистая архитектура” есть целые главы, которые рассказывают нам про детали, модели и фреймворки, но мы не строим свою архитектуру вокруг фреймворка или вокруг БД, мы используем их как один из компонентов…
Когда нам нужно сохранить сущность, мы обращаемся к БД, например, для того, чтобы наш сценарий получил в момент исполнения нужные ему реализации контрактов, мы используем фреймворк, который дает нашей архитектуре DI.
Встречаются задачи, когда нужно реализовать микросервис без БД или мы можем отказаться от DI, потому что задача слишком проста и ее быстрее решить в лоб. И если всю работу с БД мы будем осуществлять в модуле “repository”, то где же нам использовать фреймворк, чтобы он приготовил нам весь DI? Вариантов не так и много: либо мы добавляем зависимость в каждый модуль нашего приложения, либо постараемся выделить весь DI в виде отдельного модуля.
Мы выбрали подход с отдельным новым модулем и называем его или “infrastructure” или “application”.
Правда, при введении такого модуля немного нарушается тот принцип, согласно которому все зависимости мы направляем в центр к доменному слою, т.к. у него должен быть доступ до всех классов в приложении.
Добавить слой инфраструктуры в нашу луковицу в виде какого-то слоя не получится, просто нет для него там места, но тут можно взглянуть на все с другого ракурса, и получается, что у нас есть круг “Infrastructure” и на нем находится наша слоеная луковица. Для наглядности попробуем немного раздвинуть слои, чтобы было лучше видно:

Добавим новый модуль и посмотрим на дерево зависимостей от слоя инфраструктуры, чтобы увидеть итоговые зависимости между модулями:

Теперь осталось только добавить сам фреймворк DI. Мы у себя в проекте используем Spring, но это не является обязательным, можно взять любой фреймворк, который реализует DI (например — micronaut).
Как скомпоновать микросервис и где какая часть кода будет — мы уже определились, и стоит взглянуть на бизнес-сценарий еще раз, т.к. там есть еще один интересный момент.
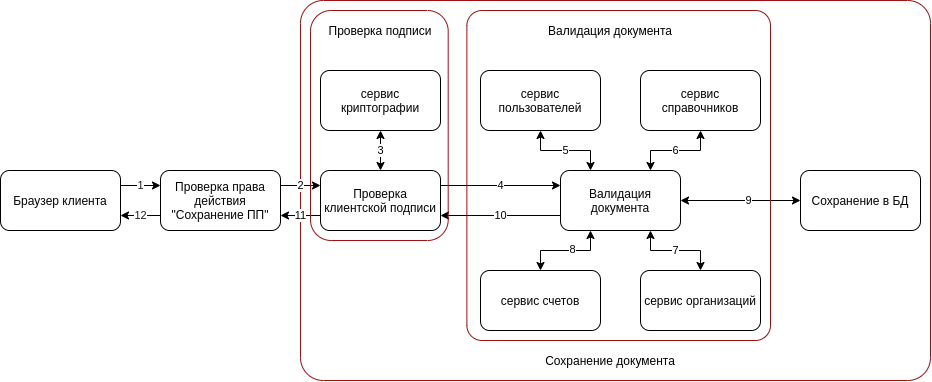
На схеме видно, что проверка права действия может выполняться не в основном сценарии. Это отдельная задача, которая не зависит от того, что будет дальше. Проверку подписи можно было бы вынести в отдельный микросервис, но тут возникает много противоречий при определении границы микросервиса, и мы решили просто добавить еще один слой в нашу архитектуру.
В отдельные слои необходимо выделять этапы, которые могут повторятся в нашем приложении, например — проверка подписи. Данная процедура может происходить при создании, изменении или при подписании документа. Многие основные сценарии сначала запускают более мелкие операции, а затем только основной сценарий. Поэтому нам проще выделить более мелкие операции в небольшие сценарии, разбитые по слоям, чтобы их было удобнее повторно использовать.
Такой подход позволяет упростить для понимания бизнес логику, а также со временем сформируется набор мелких бизнес-кирпичиков, которые можно использовать повторно.
Про код адаптеров, контроллеров и репозиториев особо нечего сказать, т.к. они достаточно простые. В адаптерах для другого микросервиса используется сгенерированный клиент из сваггера, спринговый RestTemplate или Grpc клиент. В репозитариях — одна из вариаций использования Hibernate или других ORM. Контроллеры будут подчиняться библиотеке, которую вы будете использовать.
В данной статье, мы хотели показать, зачем мы строим архитектуру микросервиса, какие подходы используем и как развиваемся. Наш проект молодой и находится только в самом начале своего пути, но уже сейчас мы можем выделить основные моменты его развития с точки зрения архитектуры самого микросервиса.
Мы строим многомодульные микросервисы, где к плюсам можно отнести:
Не обошлось, конечно, и без ложки дегтя. Например, самое очевидное связано с тем, что часто каждый модуль работает со своими небольшими моделями. К примеру, контроллере у вас будет описание рестовых моделей, а в репозитории будут сущности БД. В связи с чем приходится много мапить объекты между собой, но такие инструменты как “mapstruct” позволяют это делать быстро и надежно.
Также к минусам можно отнести то, что нужно постоянно контролировать других разработчиков, потому что есть соблазн сделать меньше работы, чем стоит. Например, переместить фреймворк немного дальше, чем один модуль, но это ведет к размыванию ответственности этого фреймворка во всей архитектуре, что в будущем может негативно сказаться на скорости доработок.
Данный подход к реализации микросервисов подходит для проектов с долгим сроком жизни и проектов со сложным поведением. Так как реализации всей инфраструктуры требует время, но в будущем это окупается стабильностью и быстрыми доработками.
Сейчас многие проекты используют микросервисную архитектуру. Мы также не стали исключением и вот уже больше 2х лет мы стараемся строить ДБО для юридических лиц в банке с применением микросервисов.
Авторы статьи: ctimas и Alexey_Salaev
Важность архитектуры микросервиса
Наш проект — это ДБО для юридических лиц. Много разнообразных процессов под капотом и приятный минималистичный интерфейс. Но так было не всегда. Долгое время мы пользовались решением от подрядчика, но в один прекрасный день было принято решение развивать свой продукт.
Начиная проект, было много обсуждений: какой же подход выбрать? как строить нашу новую систему ДБО? Началось все с обсуждений “монолит vs микросервисы”: обсуждали возможные используемые языки программирования, спорили про фреймворки (“использовать ли spring cloud?”, “какой протокол выбрать для общения между микросервисами?”). Данные вопросы, как правило, имеют какое-то ограниченное количество ответов, и мы просто выбираем конкретные подходы и технологии в зависимости от потребностей и возможностей. А ответ на вопрос “Как же писать сами микросервисы?” был не совсем простым.
Многие могут сказать «А зачем разрабатывать общую концепцию архитектуры самого микросервиса? Есть архитектура предприятия и архитектура проекта, и общий вектор развития. Если поставить задачу команде, она ее выполнит, и микросервис будет написан и он будет выполнять свои задачи. Ведь в этом и есть суть микросервисов – независимость». И будут совершенно правы! Но с течением времени команд становятся больше, следовательно — растет количество микросервисов и сотрудников, a старожил меньше. Приходят новые разработчики, которым надо погружаться в проект, некоторые разработчики меняют команды. Также команды с течением времени перестают существовать, но их микросервисы продолжают жить, и в некоторых случаях их надо дорабатывать.
Разрабатывая общую концепцию архитектуры микросервиса, мы оставляем себе большой задел на будущее:
- быстрое погружение новых разработчиков в проект;
- легкая смена команд разработчиками;
- универсальность: любой разработчик в рамках своих компетенций сможет в короткие сроки реализовать задачи в незнакомом миркосервисе.
Граница микросервиса
Все, кто работают с микросервисами, прекрасно знают их плюсы и минусы, одним из которых считается возможность быстро заменить старую реализацию на новую. Но насколько мелким должен быть микросервис, чтобы его можно было легко заменить? Где та граница, которая определяет размер микросервиса? Как не сделать мини монолит или наносервис? А еще всегда можно сразу идти в сторону функций, которые выполняют маленькую часть логики и строить бизнес процессы выстраивая очередность вызова таких функций…
Мы решили выделять микросервисы по бизнес доменам (например, микросервис рублевых платежей), а сами микросервисы строить согласно задачам этого домена.
Рассмотрим пример стандартного бизнес процесса для любого банка — “создание платежного поручения”
Можно увидеть, что вроде бы простой запрос клиента является достаточно большим набором операций. Данный сценарий является примерным, некоторые этапы опущены для упрощения, часть этапов происходят на уровне инфраструктурных компонентов и не доходят до основной бизнес-логики в продуктовом сервисе, другая часть операций работает асинхронно. В сухом остатке мы имеем процесс, который в один момент времени может использовать множество соседних сервисов, пользоваться функционалом разных библиотек, реализовывать какую-то логику внутри себя и сохранять данные в разнообразные хранилища.
Взглянув более пристально, можно увидеть, что бизнес-процесс достаточно линеен и в по мере своей работы ему потребуется или получить где-то какие-то данные или как-то обработать те данные, что у него есть, и для этого может потребоваться работа с внешними источниками данных (микросервисы, БД) или логики(библиотеки).
Некоторые микросервисы не подходят под данную концепцию, но количество таких микросервисов в общем процентном соотношении небольшое и составляет около 5%.
Чистая архитектура
Взглянув на разные подходы к организации кода, мы решили попробовать подход “чистой архитектуры”, организовав код в наших микросервисах в виде слоев.
Касательно самой “чистой архитектуры” написана не одна книга, есть много статей и в интернетах и на хабре (статья 1, статья 2), не раз обсуждали ее плюсы и минусы.
Популярная диаграмма которую можно найти по этой теме, была нарисована Бобом Мартиным в его книге “Чистая архитектура”:
Здесь на круговой диаграмме слева в центре видно направление зависимостей между слоями, а скромно в правом углу видно направление потока исполнения.
У данного подхода, как, впрочем, и в любой технологии программирования, имеются плюсы и минусы. Но для нас положительных моментов намного больше, чем отрицательных при использовании данного подхода.
Реализация “чистой архитектуры” в проекте
Мы перерисовали данную диаграмму, опираясь на наш сценарий.
Естественно, на этой схеме отражается один сценарий. Часто бывает так, что микросервис по одной доменной сущности производит больше операций, но, справедливости ради, многие адаптеры могут использоваться повторно.
Для разделения микросервиса на слои можно использовать разные подходы, но мы выбрали деление на модули на уровне сборщика проекта. Реализация на уровне модулей обеспечивает более легкое визуальное восприятие проекта, а также обеспечивает еще один уровень защиты проектов от неправильного использования архитектурного стиля.
По опыту, мы заметили, что при погружении в проект новому разработчику, достаточно ознакомиться с теоретической частью и он уже может легко и быстро ориентироваться практически в любой микросервисе.
Для сборки наших микросервисов на Java мы используем Gradle, поэтому основные слои сформированы в виде набора его модулей:
Сейчас наш проект состоит из модулей, которые или реализуют контракты или используют их. Чтобы эти модули начали работать и решать задачи, нам нужно реализовать внедрение зависимостей и создать точку входа, которая будет запускать все наше приложение. И тут возникает интересный вопрос: в книге дядюшки Боба “Чистая архитектура” есть целые главы, которые рассказывают нам про детали, модели и фреймворки, но мы не строим свою архитектуру вокруг фреймворка или вокруг БД, мы используем их как один из компонентов…
Когда нам нужно сохранить сущность, мы обращаемся к БД, например, для того, чтобы наш сценарий получил в момент исполнения нужные ему реализации контрактов, мы используем фреймворк, который дает нашей архитектуре DI.
Встречаются задачи, когда нужно реализовать микросервис без БД или мы можем отказаться от DI, потому что задача слишком проста и ее быстрее решить в лоб. И если всю работу с БД мы будем осуществлять в модуле “repository”, то где же нам использовать фреймворк, чтобы он приготовил нам весь DI? Вариантов не так и много: либо мы добавляем зависимость в каждый модуль нашего приложения, либо постараемся выделить весь DI в виде отдельного модуля.
Мы выбрали подход с отдельным новым модулем и называем его или “infrastructure” или “application”.
Правда, при введении такого модуля немного нарушается тот принцип, согласно которому все зависимости мы направляем в центр к доменному слою, т.к. у него должен быть доступ до всех классов в приложении.
Добавить слой инфраструктуры в нашу луковицу в виде какого-то слоя не получится, просто нет для него там места, но тут можно взглянуть на все с другого ракурса, и получается, что у нас есть круг “Infrastructure” и на нем находится наша слоеная луковица. Для наглядности попробуем немного раздвинуть слои, чтобы было лучше видно:
Добавим новый модуль и посмотрим на дерево зависимостей от слоя инфраструктуры, чтобы увидеть итоговые зависимости между модулями:
Теперь осталось только добавить сам фреймворк DI. Мы у себя в проекте используем Spring, но это не является обязательным, можно взять любой фреймворк, который реализует DI (например — micronaut).
Как скомпоновать микросервис и где какая часть кода будет — мы уже определились, и стоит взглянуть на бизнес-сценарий еще раз, т.к. там есть еще один интересный момент.
На схеме видно, что проверка права действия может выполняться не в основном сценарии. Это отдельная задача, которая не зависит от того, что будет дальше. Проверку подписи можно было бы вынести в отдельный микросервис, но тут возникает много противоречий при определении границы микросервиса, и мы решили просто добавить еще один слой в нашу архитектуру.
В отдельные слои необходимо выделять этапы, которые могут повторятся в нашем приложении, например — проверка подписи. Данная процедура может происходить при создании, изменении или при подписании документа. Многие основные сценарии сначала запускают более мелкие операции, а затем только основной сценарий. Поэтому нам проще выделить более мелкие операции в небольшие сценарии, разбитые по слоям, чтобы их было удобнее повторно использовать.
Такой подход позволяет упростить для понимания бизнес логику, а также со временем сформируется набор мелких бизнес-кирпичиков, которые можно использовать повторно.
Про код адаптеров, контроллеров и репозиториев особо нечего сказать, т.к. они достаточно простые. В адаптерах для другого микросервиса используется сгенерированный клиент из сваггера, спринговый RestTemplate или Grpc клиент. В репозитариях — одна из вариаций использования Hibernate или других ORM. Контроллеры будут подчиняться библиотеке, которую вы будете использовать.
Заключение
В данной статье, мы хотели показать, зачем мы строим архитектуру микросервиса, какие подходы используем и как развиваемся. Наш проект молодой и находится только в самом начале своего пути, но уже сейчас мы можем выделить основные моменты его развития с точки зрения архитектуры самого микросервиса.
Мы строим многомодульные микросервисы, где к плюсам можно отнести:
- однозадачность, каждый модуль решает только какую-то одну задачу, а значит не всегда нужно переписывать весь микросервис, чаще всего нужно просто дописать или иногда переписать какой-то один модуль, не затрагивая другие;
- простота, модули ограничены контекстом и использованием контрактов, что позволяет проще писать небольшие юнит-тесты для проверки логики;
- совместимость, в нашем проекте для внешнего Api, используется версионирование внутри микросервиса, каждая версия может быть представлена в виде отдельного модуля, что позволяет легко и просто переходить на новые реализации, сохраняя совместимость со старыми версиями;
- стабильность, после того, как все зависимости между модулями уже выстроены, сломать их достаточно сложно, потому что велика вероятность вообще сломать само дерево зависимостей.
Не обошлось, конечно, и без ложки дегтя. Например, самое очевидное связано с тем, что часто каждый модуль работает со своими небольшими моделями. К примеру, контроллере у вас будет описание рестовых моделей, а в репозитории будут сущности БД. В связи с чем приходится много мапить объекты между собой, но такие инструменты как “mapstruct” позволяют это делать быстро и надежно.
Также к минусам можно отнести то, что нужно постоянно контролировать других разработчиков, потому что есть соблазн сделать меньше работы, чем стоит. Например, переместить фреймворк немного дальше, чем один модуль, но это ведет к размыванию ответственности этого фреймворка во всей архитектуре, что в будущем может негативно сказаться на скорости доработок.
Данный подход к реализации микросервисов подходит для проектов с долгим сроком жизни и проектов со сложным поведением. Так как реализации всей инфраструктуры требует время, но в будущем это окупается стабильностью и быстрыми доработками.

feoktant
Сколько у вас классов в условном rabbitmq-client? На сколько практично выделять подобный код в отдельный гредл-модуль?