
Привет! Меня зовут Семён Киреков, я Java-разработчик и тимлид в Центре Big Data @МТС Digital и Java-декан в МТС Тета — образовательном стартапе в рамках МТС. На митапе Росбанка и Jug.ru я рассказывал о том, как устроен метод Save в Spring Data JPA, почему он может вызвать лишний select, как решить эту проблему и при чем здесь доменные события Spring. Здесь я поделюсь этой информацией с вами.

Рассмотрим простую сущность Post. У нее есть id, который подставляется базой, и тайтл:
@Entity
@Table(name = "post")
@Setter
@Getter
public class Post {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
}Ещё у нас есть PostService, мы инжектим в него PostRepository, это обычный Spring Data JPA репозиторий. И есть метод changeTitle, который меняет название Post. Это метод Transactional; соответственно, весь метод — это одна транзакция. В ней мы передаем id, новый тайтл и вызываем метод save.
@Service
public class PostService {
private final PostRepository postRepository;
@Transactional
public void changeTitle(Long postId, String title) {
final var post = postRepository.findById(postId).orElseThrow();
post.setTitle(title);
postRepository.save(post);
}
}
Уверен, что в том или ином виде вы встречали такую операцию в проектах. Запустим этот код и включим логирование HQL. Нашли пост, проапдейтили — результаты ожидаемые, какие могут быть проблемы?
Hibernate: select post0_.id as id1_0_0_, post0_.description as descript2_0_0_, post0_.title as title3_0_0_ from post post0_ where post0_.id=? Hibernate: update post set description=?, title=? where id=?
Разберемся, как устроен метод save. EntityInformation.isNew определяет, что сущность является новой. Если да, вызываем persist, если нет — merge:
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}Жизненный цикл entity в JPA
Вспомним жизненный цикл сущности в контексте JPA:
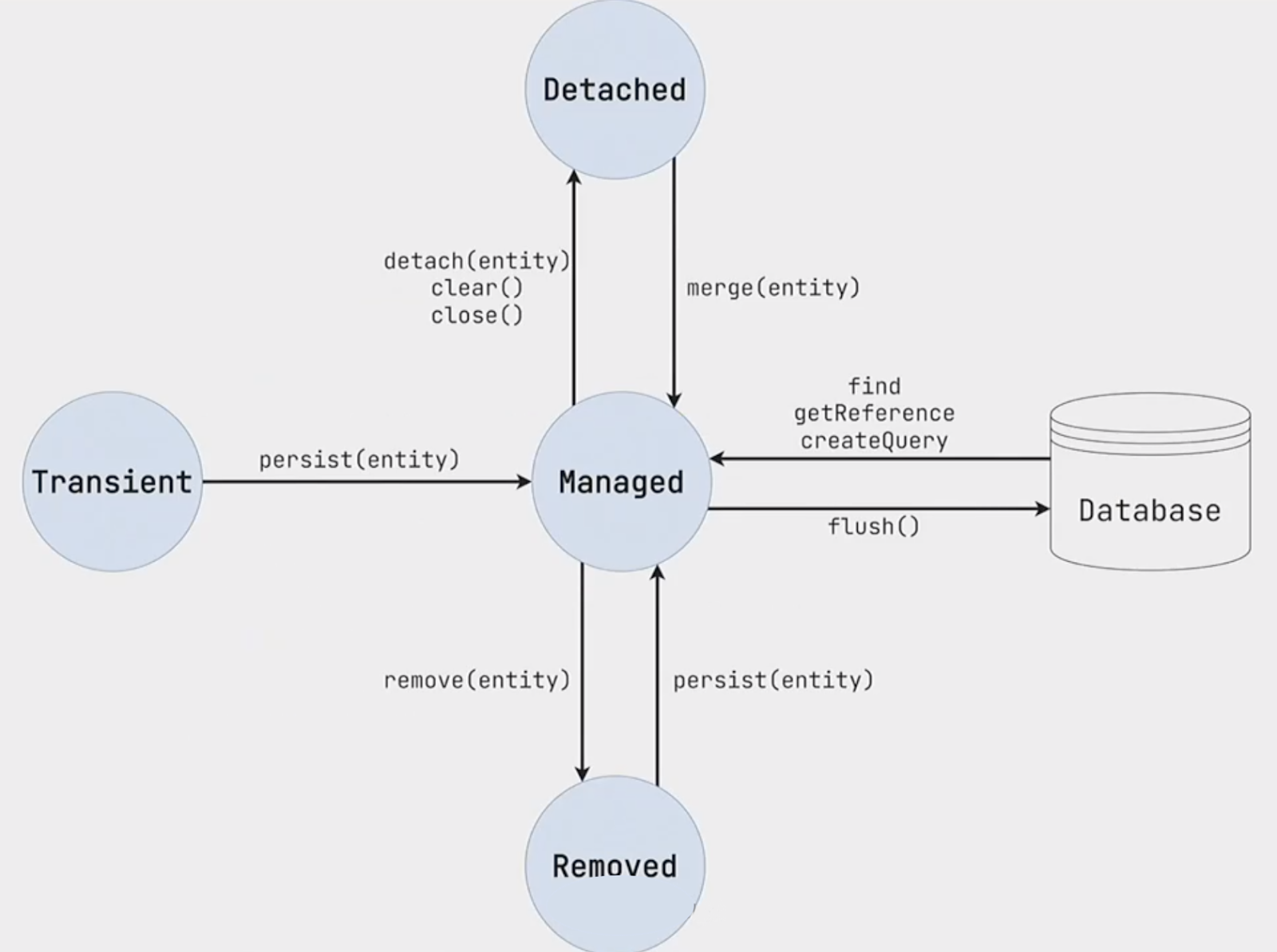
Когда вы создаете сущность через конструктор, она находится в состоянии Transient — это значит, что она не отслеживается через Hibernate. Состояние Managed означает, что все изменения сущности в рамках транзакции отслеживаются Hibernate и будут преобразованы в соответствующие HQL-запросы (update, insert, delete и так далее). В состояние Managed сущность попадает, если вы ее персистируете либо находите по id (find getReference). Важно заметить, что всё это происходит в рамках транзакции.
Метод flush вызывается перед коммитом и генерирует стейтменты в зависимости от того, какие сущности вы затронули, какие поля поменяли. Также есть состояние Removed: если сущность переходит в него, то в конце транзакции будет сгенерирован delete. Состояние delete мы вызываем через remove, а обратно выводим через persist.
Теперь о Detached. Если сущность была у вас в состоянии Managed, а транзакция закрылась, сущность переходит в состояние Detached. Это значит, что у нее есть id, она когда-то отслеживалась, но теперь она не является частью какого-то persistent-контекста. Простой пример: вы закоммитили транзакцию с Post и передали в какой-то другой метод. Там уже этой транзакции не будет. Соответственно, она стала Detached. То есть в это состояние сущность попадает при завершении транзакции или при вызове метода detach (он практически не используется, но такая возможность есть). Если вам нужно совершить обратное действие, то вы вызываете merge. Например, когда в качестве параметра метода принимаете Post и хотите, чтобы он отслеживался транзакцией.
Что можно заключить по жизненному циклу сущности?
Dirty Checking, механизм, которые проверяет состояние сущности и генерирует нужные запросы, не требует вызов метода save.
Операция merge для PERSISTED сущности не влияет на конечный результат. При вызове save вызывается merge.
Получается, с @Transactional мы можем в нашем сервисе опустить save и ничего не изменится, апдейт сгенерируется:
final var post = postRepository.findById(postId).orElseThrow();
post.setTitle(title);
}Метод copyValues
Теперь рассмотрим исходный код Hibernate:
protected void entityIsPersistent(MergeEvent event, Map copyCache) {
LOG.trace( "Ignoring persistent instance" );
//TODO: check that entry.getIdentifier().equals(requestedId)
final Object entity = event.getEntity();
final EventSource source = event.getSession();
final EntityPersister persister = source.getEntityPersister( event.getEntityName(), entity );
( (MergeContext) copyCache ).put( entity, entity, true ); //before cascade! cascadeOnMerge( source, persister, entity, copyCache );
copyValues( persister, entity, entity, source, copyCache );
event.setResult( entity );
}Обратите внимание на метод copyValues. Hibernate достает базовые атрибуты сущности (entity), копирует их в свою память и затем вставляет в ту же самую Entity. Если у вас много атрибутов, это может затянуться. Кажется, что это странная операция, которая просто расходует циклы и ничего не делает.
Когда merge становится проблемой для MANAGED entity? Если в рамках транзакции мы обновляем много записей, то для каждой entity будет вызван copyValues и общее время работы транзакции заменится на всё время этих повторов. Особенно это заметно, если в entity много длинных атрибутов.
Я задался вопросом: а зачем вообще нужен copyValues? Исходя из ответов, я решил, что это, видимо, костыль, который со временем стал фичей. Суть вот в чем: если вы достаете какую-то коллекцию, то в ней будут отношения one to many и вы можете добавить туда дочерние объекты. Если эти объекты находятся в состоянии Detached, то вызов copyValues заменит их на те же самые entity в состоянии Managed. Так Hibernate подменяет сущности. Непонятно в таком случае, зачем копировать все атрибуты, но, видимо, разработчикам и так показалось нормально.
Теперь приведу другой пример, тоже Post, но с id в виде UUID. Мы будем вставлять его на стороне клиента, то есть он не будет генерироваться базой:
@Entity
@Table(name = "post")
@Getter
@Setter
public class Post {
@Id
private UUID id;
private String title;
public static Post newPost() {
final var post = new Post();
post.setId(UUID.randomUUID());
return post;
}
}Мы хотим создать новый пост, а не обновлять его. Новый пост находится в состоянии Transient, то есть Hibernate его не отслеживает. Значит, нужно вызвать save. Что происходит в логах:
Hibernate: select post0_.id as id1_1_0_,
post0_.description as descript2_1_0_,
post0_.title as title3_1_0_
from post post0_ where post0_.id=?
Hibernate: insert into post (description, title, id) values (?, ?, ?)
Select будет у нас по тому же id, по которому мы сделали insert. То есть Hibernate делает select, а потом insert. Если поставить breakpoint, то мы увидим, что вызвался merge, а не persist:
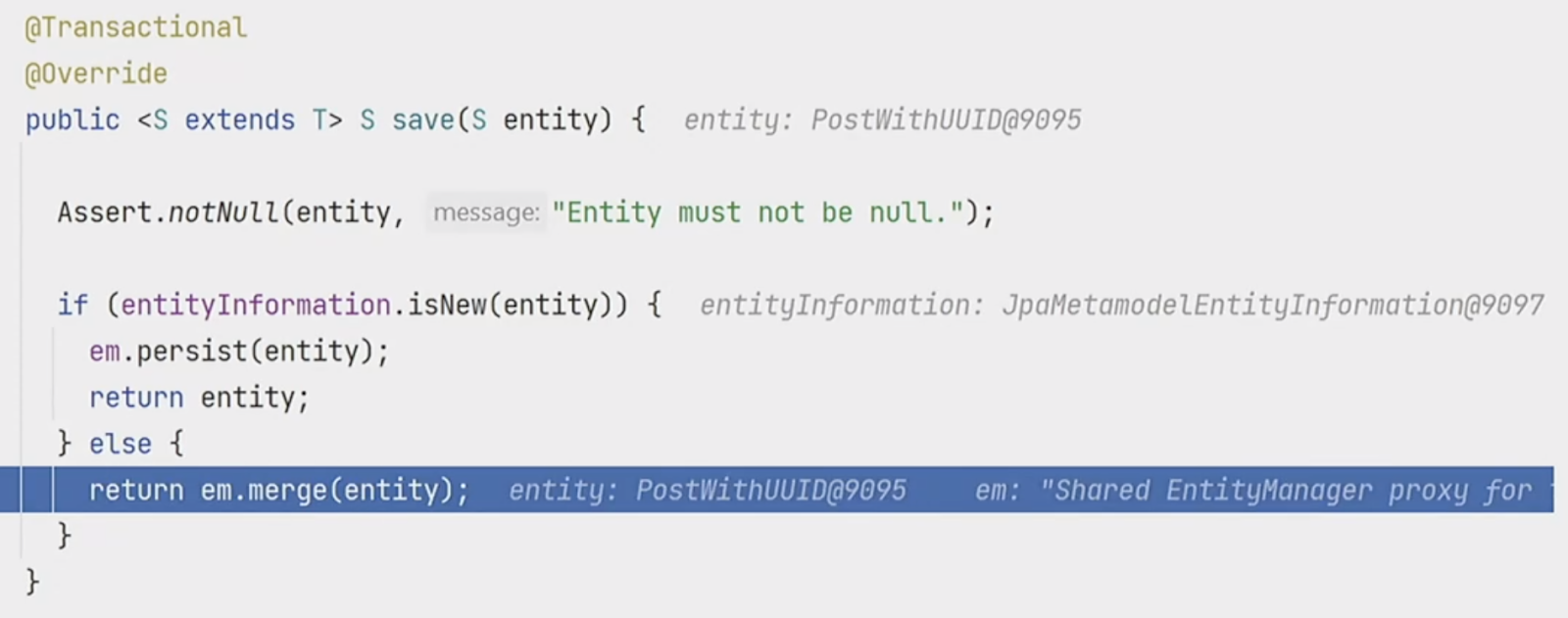
Как работает isNew
Стоит разобраться, как работает EntityInformation.isNew. Сначала Spring Data смотрит, есть ли в вашей entity аннотация version. Если ее нет либо там стоит примитив, мы переходим к родительскому классу. Если атрибут version есть, мы смотрим, равняется ли он null. Если равняется, то мы считаем, что имеем дело с новой сущностью, а не взятой из базы. У нас нет атрибута version, поэтому этот сценарий нам не подходит.
Далее Spring Data JPA смотрит, является ли id сущности примитивом.
public boolean isNew(T entity) {
ID id = getId(entity);
Class<ID> idType = getIdType();
if (!idType.isPrimitive()) {
return id == null;
}
if (id instanceof Number) {
return ((Number) id).longValue() == 0L;
}
throw new IllegalArgumentException(
String.format("Unsupported primitive id type %s", idType)
);
}Если это null, сущность считается новой. Если это примитив и число — смотрим, равняется ли оно нулю. В противном случае вводится исключение, потому что остаются только типы char и boolean, ни один из которых не подходит под роль первичного ключа.
Обобщим алгоритм работы isNew в Spring Data JPA:
New, если атрибут @Version присутствует и равен null.
New, если ID равен null.
New, если ID примитив и равен 0.
Иначе — не является new.
Итак, дошли до четвертого пункта и вызвали метод merge. Вот его исходный код:
final PersistenceContext persistenceContext = source.getPersistenceContextInternal();
EntityEntry entry = persistenceContext.getEntry( entity );
if ( entry == null ) {
EntityPersister persister = source.getEntityPersister( event.getEntityName(), entity );
Serializable id = persister.getIdentifier( entity, source );
if ( id != null ) {
final EntityKey key = source.generateEntityKey( id, persister );
final Object managedEntity = persistenceContext.getEntity( key );
entry = persistenceContext.getEntry( managedEntity );
if ( entry != null ) {
entityState = EntityState.DETACHED;
}
}
}
if ( entityState == null ) {
entityState = EntityState.getEntityState( entity, event.getEntityName(), entry, source, false );
}Здесь нужно пояснить, как в принципе работает Hibernate. Когда вы выполняете операцию, он пытается установить, в каком состоянии находится сущность, с которой вы эту операцию выполняете. Hibernate должен понять, нужно ли сущность проапдейтить, удалить, заинсертить или сделать что-нибудь ещё.
Вернемся к коду. Сначала Hibernate пытается найти сущность по ссылке в PersistenceContext. Если мы никаких операций не выполняли, то там пусто и ничего не найдется. Если по ссылке не найти, он пытается найти по id. Если мы создали новый пост, там тоже ничего не будет. Последнее средство — вызов статического метода get EntityState.
final Serializable clonedIdentifier =
(Serializable) persister.getIdentifierType().deepCopy( id, source.getFactory() );
final Object result = source.get( entityName, clonedIdentifier );
source.getLoadQueryInfluencers().setInternalFetchProfile( previousFetchProfile );
if ( result == null ) {
entityIsTransient( event, copyCache );
}Вот фрагмент его большого исходного кода. В строчке с source.get и происходит дополнительный select. Hibernate таким образом смотрит, есть ли нужная строчка в базе. Если нет, то мы точно имеем дело с Transient.
Проблема лишних select
Когда этот дополнительный select может стать проблемой? Например, в системах телеметрии, когда число записей в единицу времени значительно больше числа чтений. Здесь показатели должны быстро и часто обновляться, и получается, что select + insert увеличивает число запросов в два раза.
Один из способов решить эту проблему — использовать UUID Generator:
@Entity
@Table(name = "post_uuid")
@Getter
@Setter
public class PostWithUUID {
@Id
@GeneratedValue(generator = "UUID")
@GenericGenerator(
name = "UUID",
strategy = "org.hibernate.id.UUIDGenerator"
)
private UUID id;
private String title;
public static PostWithUUID newPost() {
return new PostWithUUID();
}
}Spring Data увидит, что id = null, сущность новая, и вызовет persist-корректор. Это работает, но с оговорками.
Мы теряем преимущества заранее определенного ID для equals/hashCode. Подробней о них можно почитать в статье Ultimate Guide to Implementing equals() and hashCode() with Hibernate.
Невозможно использовать EmbeddedUUID.
Второй пункт объясню подробней:
@Entity
@Table(name = "post")
@Getter
@Setter
public class Post {
@EmbeddedId
private PostID id;
private String title;
public static Post newPost() {
final var post = new Post ();
post.setId(new PostID(UUID.randomUUID()));
return post;
}
@Embeddable
@EqualsAndHashcode
@Getter @AllArgsConstructor @NoArgsConstructor
public static class PostID implements Serializable {
@Column(name = "id")
private UUID value;
}У нас есть Post, мы объявили класс PostID и поставили аннотацию EmbeddedID. Это позволяет нам оформлять запросы вот так:
public interface PostRepo extends JpaRepository<Post,
PostID> {
}В HQL-запросах вы можете оперировать не каким-нибудь абстрактным id, а PostID, имеющим семантический смысл. Если в своем приложении вы много работаете с id, то это поможет снизить количество возможных ошибок в коде.
Проблема в том, что здесь нельзя поставить generator — Hibernate его не воспримет. Это можно обойти с помощью интерфейса Persistable. Он не входит в JPA, это часть именно Spring Data. По сути, он представляет собой кастомную реализацию метода isNew:
@Entity
@Table(name = "post")
@Getter
@Setter
public class Post implements Persistable<Post.PostID> {
@Transient
private transient boolean isNew;
@EmbeddedId
private PostID id;
private String title;
public static Post newPost() {
final var post = new Post ();
post.setId(new PostID(UUID.randomUUID()));
post.setNew(true);
return post;
}
@Override
public boolean isNew() {
return isNew;
}
@Embeddable
@Getter @EqualsAndHashCode @AllArgsConstructor @NoArgsConstructor
public static class PostID implements Serializable {
@Column(name = "id")
private UUID value;
}
@PostLoad
@PrePersist
void trackNotNew() {
this.isNew = false;
}
}Когда сущность реализует метод Persistable, то логика, которую я описал выше, перестает работать. Вместо этого Spring Data JPA просто спрашивает у entity, новая она или нет. Если да — вызывается persist; если нет — merge. Здесь вы перекладываете на себя ответственность по определению того, новая сущность или нет.
Параметр isNew хранится в @Transient, потому что это не колонка. Поле isNew мы указываем как true, когда создаем пост. И очень важно выставить false в конце, иначе вы можете столкнуться с интересными эффектами.
Откуда вообще взялся метод save, если он такой проблемный и вроде бы даже не соответствует спецификации JPA?
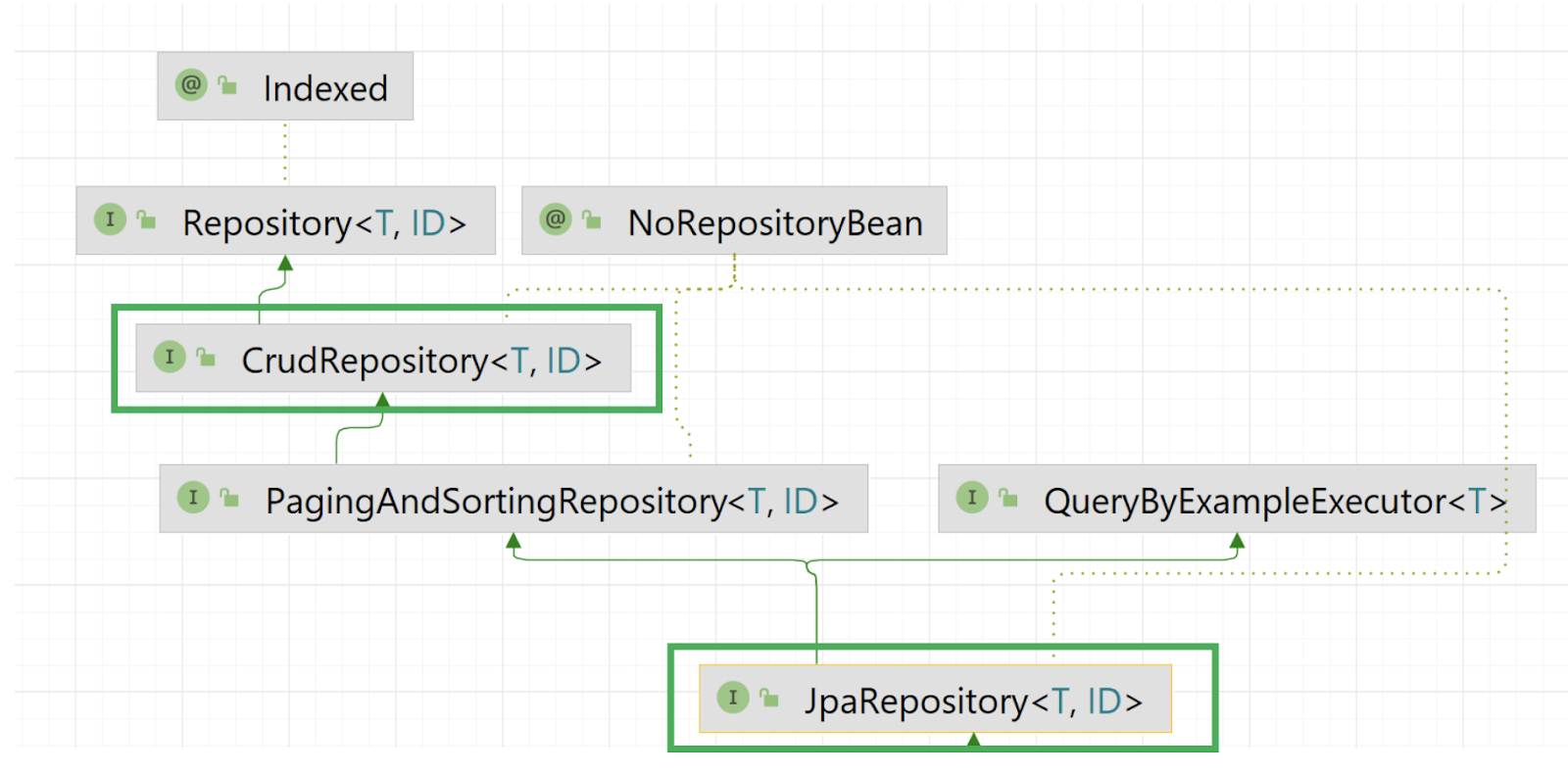
Все фреймворки Spring Data, включая JPA, наследуются от CrudRepository, где есть метод save. В большинстве фреймворков он имеет смысл. JPA здесь, скорее, исключение, но и в JPA у save есть смысл. По своей логике он является insert.
Представьте, что вы получаете некий бизнес-объект в качестве параметра метода и не знаете, есть ли он в базе или нет. Если нет, нужно его вставить, если есть — обновить. В любом случае в коде нужно будет сделать нечто вроде
If (select == null)
insert
else
updateПо сути, метод save инкапсулирует это в себе.
Hibernate Repository против лишних select
А что если метод save нам мешает? Представим, что мы не хотим лишних select и copyValues, нам нужно сэкономить время. Один из способов решения — Hibernate Repository. Он описан в статье The best Spring Data JpaRepository. Реализация есть в известной библиотеке Implementation: Hibernate Types.
public interface HibernateRepository<T> {
public interface HibernateRepository<T> {
<S extends T> S persist(S entity);
<S extends T> S merge(S entity);
}Мы объявляем интерфейс. Для простоты возьмем только два из многочисленных методов — persist и merge. Теперь объявляем имплементацию, которая делегирует вызовы EntityManager:
@Repository
class HibernateRepositoryImpl<T> implements HibernateRepository<T> {
@PersistenceContext
private EntityManager em;
@Override
public <S extends T> S persist(S entity) {
em.persist(entity);
return entity;
}
@Override
public <S extends T> S merge(S entity) {
return em.merge(entity);
}
}Затем расширяем наш репозиторий Post с помощью репозитория Hibernate:
public interface PostRepository
extends JpaRepository<Post, Long>,
HibernateRepository<Post> {
}Теперь мы можем явно вызывать persist и merge. Кажется, всё хорошо. Рассмотрим более реалистичный пример. Допустим, нам нужно отслеживать изменения в названии постов, а именно архивировать их в отдельную таблицу перед коммитом. Старые записи мы добавляем в архив, где аналитик может смотреть, как менялось название поста. В случае роллбэка нужно отправлять письмо команде поддержки — если, например, пользователь не смог поменять название поста. А после коммита — отправлять сообщение в Kafka.
Для всего этого отлично подходят доменные события — паттерн domain-driven дизайна, который в Spring реализован нативно.
@Entity
@Table(name = "post")
@Setter
@Getter
public class Post extends AbstractAggregateRoot<Post> {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
public void changeTitle(String title) {
this.title = title;
registerEvent(new PostNameChanged(id));
}
}От нашей сущности мы наследуем класс AbstractAggregateRoot. У него есть метод registerEvent.
public class AbstractAggregateRoot<A extends AbstractAggregateRoot<A>> {
private transient final @Transient List<Object> domainEvents = new ArrayList<>();
protected <T> T registerEvent(T event) {
Assert.notNull(event, "Domain event must not be null");
this.domainEvents.add(event);
return event;
}
@AfterDomainEventPublication
protected void clearDomainEvents() {
this.domainEvents.clear();
}
@DomainEvents
protected Collection<Object> domainEvents() {
return Collections.unmodifiableList(domainEvents);
}
}AggregateRoot хранит в себе объекты событий, складывает их в список. Метод domainEvents вызывается через Spring и выдает список событий, который мы зарегистрировали. AfterDomainEventPublication, соответственно, список очищает.
Перехватывать события мы можем с помощью TransactionalEventListener. Это обычный EventListener, с той разницей, что он может перехватывать события на определенном этапе транзакции. В данном случае перед коммитом и после него:
@TransactionalEventListener(phase = TransactionPhase.BEFORE_COMMIT)
public void archiveChanges(PostNameChanged postNameChanged) {
…
}
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void sendMessageToKafka(PostNameChanged postNameChanged) {
…
}Когда мы перехватываем перед коммитом, транзакция все еще активна. Если здесь бросить исключение, вся транзакция откатится. Если дальше вызывать методы persist, merge, то события не перехватятся:
@Transactional
public void changeTitle(Long postId, String title) {
final var post = postRepository.findById(postId).orElseThrow();
post.changeTitle(title);
}А если добавить метод, например, save, события перехватятся и не будут опубликованы.
@Transactional
public void changeTitle(Long postId, String title) {
final var post = postRepository.findById(postId).orElseThrow();
post.changeTitle(title);
postRepository.save(post);
}Как подружить Hibernate и доменные события
Я знаю четыре способа, но расскажу про два наиболее полезных. Первый — это передача ApplicationEventPublisher в качестве параметра:
@Entity
@Table(name = "post")
@Setter
@Getter
public class Post {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
public void changeTitle(String title,
ApplicationEventPublisher eventPublisher) {
this.title = title;
eventPublisher.publishEvent(new PostNameChanged(id));
}
}Преимущество этого подхода — можно написать юнит-тесты на entity. Так вы создадите rich domain model по канонам domain driven дизайна. Недостаток — сервис, который обращается к entity, должен всегда инжектить ApplicationEventPublisher.
Второй способ — это статический DomainEventPublisher:
@Entity
@Table(name = "post")
@Setter
@Getter
public class Post {
@Id
@GeneratedValue(strategy = IDENTITY)
public Long id;
private String title;
public void changeTitle(String title) {
this.title = title;
DomainEventPublisher.publish(new PostNameChanged(id));
}
}Здесь мы объявляем обычный Spring Bean. В методе setEventPublisher записываем ApplicationEventPublisher в статическую переменную, и теперь она у нас доступна через статический метод publishEvent:
@Component
public class DomainEventPublisher {
private static volatile ApplicationEventPublisher publisher;
@Autowired
private void setEventPublisher(ApplicationEventPublisher eventPublisher) {
publisher = eventPublisher;
}
public static void publish(Object event) {
Assert.notNull(publisher, "ApplicationEventPublisher is null. Check the configuration");
publisher.publishEvent(event);
}
}Преимущество — нет необходимости явно инжектить ApplicationEventPublisher, потому что он инкапсулирован в одном месте. Недостаток — мы нарушаем принцип Inversion of Control: вроде бы используем Spring, но тут же от него отказываемся. Также у нас не будет возможности протестировать entity отдельно от Spring, потому что entity обращается напрямую в DomainEventPublisher, который связан со Spring.
Оценим оба варианта. Первый нам не подходит, потому что инжект bean в каждый сервис, работающий с entity, убивает все преимущества. Второй способ нарушает, казалось бы, нерушимый принцип инверсии контроля, но у меня есть аргументы за него.
В связке Spring + Hibernate маловероятно исчезновение Spring.
ApplicationEventPublisher — часть инфраструктуры, где не требуется полиморфность. Реализацию вам подсовывает Spring, и вы просто к ней обращаетесь.
Этот способ был описан в классической книге Implementing Domain-Driven Design. Да, это апелляция к авторитету, но из всех вариантов этот тоже был выбран не просто так.
Стоит ли всё это внедрять?
Краеугольный вопрос всего поста. Стоит, если вы обновляете много сущностей в транзакции или много атрибутов и вызов save может сыграть злую шутку из-за copyValues. Или если вы работаете над системой телеметрии с большим числом insert per second, и вам важно, чтобы каждый вызов save гарантированно создавал insert без дополнительных запросов.
Выводы
Метод save в Spring Data JPA может вызывать проблемы с производительностью.
Отказ от него в пользу явного persist/merge даст лучший контроль, но добавит сложности в виде low API.
Есть несколько способов применения доменных событий при отказе от save, выбирайте с умом.
Не полагайтесь слепо на абстракции, изучайте детали «под капотом».
В 99% реальных проектов вам это не понадобится, так как в большинстве случаев save покрывает все нужные кейсы.
Spring Data — прекрасный фреймворк и save в нем хорошо работает. Но ряд моментов нужно учитывать. Если в логах вдруг появились лишние select или транзакция стала работать дольше, чем хотелось, вы будете знать, куда копать, стоит ли заморачиваться или можно просто полагаться на абстракции.
Напоследок — ссылка на другие мои статьи. Надеюсь, вы найдете в них что-то полезное для себя.
Комментарии (2)

upagge
25.10.2022 19:33+2Просто любопытно, зачем было удалять запись доклада? При этом судя по верстке, предполагалось, что доклады будут доступны :)


StanislavL
> Так Hibernate подменяет сущности. Непонятно в таком случае, зачем копировать все атрибуты, но, видимо, разработчикам и так показалось нормально.
Это сделано похоже для того, чтобы в случае изменений данных в базе обновить на свежие значения. Ведь между detached и merge в базе могли много чего наменять. Там могли конечно заморочится с версией, но она есть не всегда.