
Привет! Меня зовут Иван Пономарёв, я разработчик в Synthesized, преподаю в МФТИ и EEUAS. На этом митапе Росбанка и Jug.ru я расскажу о тестировании Kafka Streams и, в частности, об особенностях инструмента TopologyTestDriver. Этот доклад я подготовил совместно с Джоном Рослером (John Roesler), разработчиком из Confluent, коммитером и одним из продакт-менеджеров Apache Kafka.

Когда-то в одном из проектов у нас возникла задача. Мы собирали из разных источников данные. Источники характеризовались своими id и данными, которые они пересылают. Все уникальные источники, которые передали данные, нужно было собрать в одной базе; иначе говоря, сделать DISTINCT всех значений id. Уникальных источников было немного, а вот сообщений для анализа предостаточно.
На стороне базы данных дедуплицировать id источников можно разными способами. Либо с помощью upsert, либо можно проверять наличие уже существующих записей, или пытаться их вставить и ловить исключения. Однако какой из этих способов ни используй, получается слишком много записей в БД. Так что рассмотрим вариант с дедупликацией на стороне Kafka Streams, который способен дать хорошую пропускную способность. Передавать в базу мы будем дедуплицированные данные:
KStream<String, String> input =
...
final String STOP_VALUE = "!STOP!";
input.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.reduce((first, second) -> STOP_VALUE)
.toStream()
.filter((key, value) -> !STOP_VALUE.equals(value))
.to(...);Как это работает? Когда у нас появляются события, которые дедуплицируются, мы ставим reduce, который схлопывает предыдущее значение и текущее значение в некое магическое слово «STOP».

В примере выше значение A подвергается reduce, в local store кладется предыдущее значение, и A эмитится дальше. Потом приходит значение B, которое тоже подвергается reduce, сохраняется в local store и эмитится.
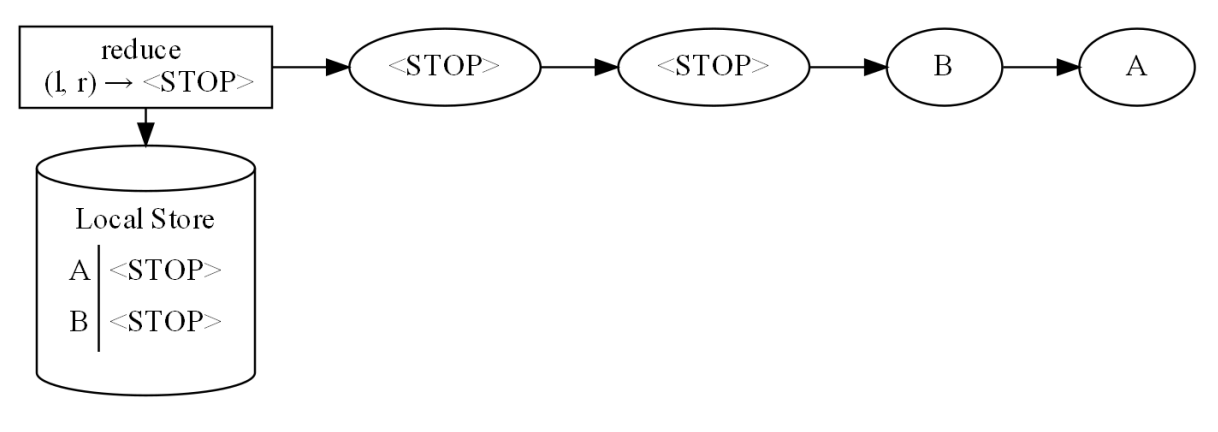
Если последующие значения A и B будут совпадать, то reduce будет выдавать STOP. Это значение мы можем отфильтровать и получить дедуплицированные результаты.
Простое, а главное, идиоматичное решение. Мы используем reduce и не создаем никаких дополнительных стораджей, что в Kafka Streams из-за отсутствия удобного API было бы довольно хлопотно.
Что умеет TopologyTestDriver
Чтобы проверить, как это работает, используем TopologyTestDriver. Это очень удобный фреймворк для тестирования приложений в Kafka Streams, который сам по себе тоже является частью Kafka Streams.
topologyTestDriver = new TopologyTestDriver(topology, config);
inputTopic = topologyTestDriver.createInputTopic(...);
outputTopic = topologyTestDriver.createOutputTopic(...);Для работы TopologyTestDriver не нужна Kafka, этот движок делает всё сам. Создадим новый TopologyTestDriver, куда передается config; связь с базой данных не обязательна. В InputTopic можно что-то положить, а в OutputTopic затем что-то прочитать.
В Kafka Streams 2.4 TopologyTestDriver превратился в полноценный фреймворк для тестирования. Вы можете легко дать ему, например, значения без ключей и потом их в таком формате прочитать. Если хотите пару ключ-значение, всё так же просто.
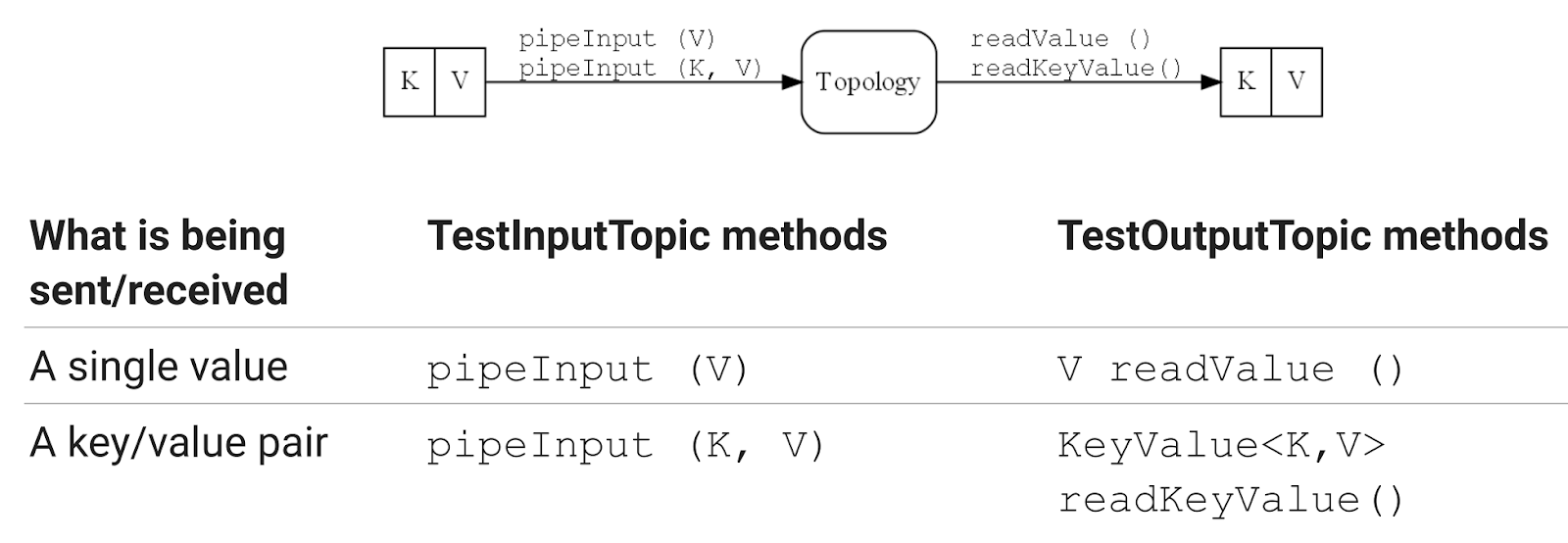
Поддерживаются и списки значений, и пары:

Если вы хотите работать уровне записей целиком, с заголовками, таймстампами и т.п., это тоже поддерживается. Вы легко можете передать и получить список записей в topology, а затем сделать assert с помощью своей любимой библиотеки.

Теперь протестируем, как это работает. Вот так будет выглядеть наша топология (да, у неё в названии спойлер):
private void wrongDistinctTopology(StreamsBuilder streamsBuilder) {
KStream<String, String> input =
streamsBuilder.stream(INPUT_TOPIC_WRONG, Consumed.with(Serdes.String(), Serdes.String()));
final String STOP_VALUE = "!STOP!";
input.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.reduce((first, second) -> STOP_VALUE)
.toStream()
.filter((key, value) -> !STOP_VALUE.equals(value))
.to(OUTPUT_TOPIC_WRONG, Produced.with(Serdes.String(), Serdes.String()));
}Код нашего теста очень простой: мы набиваем в inputTopic значения A, B и C, а в outputTopic должны получить соответствующие дедуплицированные значения:
@Test
void rightDistinctTopology() {
testTopology(inputTopicRight, outputTopicRight);
}
private void testTopology(TestInputTopic<String, String> inputTopic,
TestOutputTopic<String, String> outputTopic) {
inputTopic.pipeKeyValueList(
List.of("A", "B", "B", "A", "C")
.stream().map(e -> KeyValue.pair(e, e))
.collect(toList())
);
assertEquals(List.of("A", "B", "C"), outputTopic.readValuesToList());
}Тест прошел очень быстро, на выходе получили то, что ожидали:
Проблемы на проде
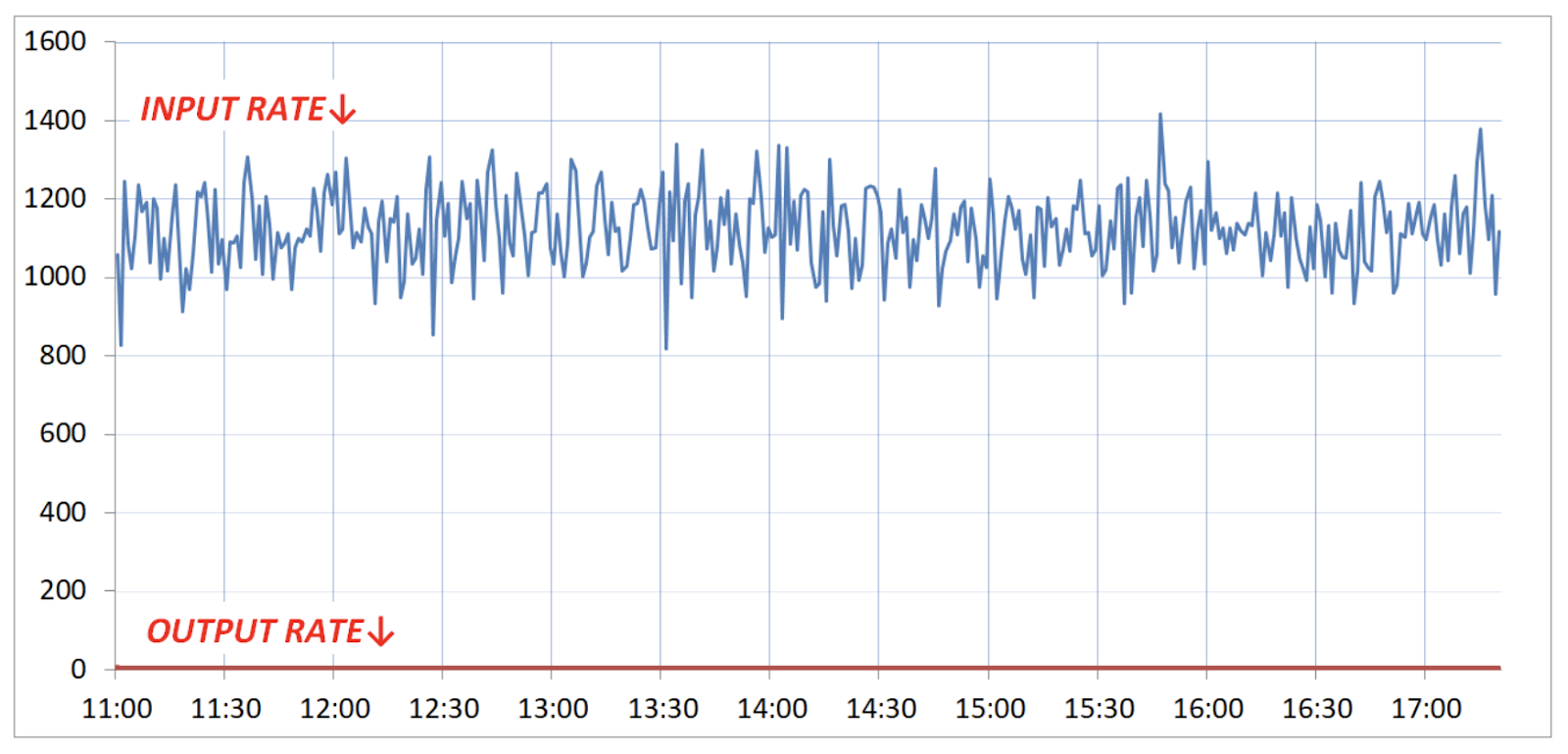
Мы отправили это в прод и посмотрели статистику. На входе обрабатывалось порядка тысячи запросов в секунду, а в базу данных не поступало ни одной записи. Таблица уникальных id осталась пустой. Мы, конечно, ставили целью разгрузить нашу базу данных, но не до такой степени :-)
Начали разбираться. Преимущество stream-приложений по сравнению с обычными в том, что мы можем сделать дамп в текстовый файл, локально прочитать тем же TopologyTestDriver и выполнить отладку. Но сделав это, я увидел на выходе записи, которых не было на проде. Таким образом, получалось, что TopologyTestDriver вел себя не так, как Kafka в кластере. При этом уже самый простой кластер из одной ноды Kafka в докере воспроизводил нашу проблему.
Зачем же нужен тестовый фреймворк, который, казалось бы, в таких простых ситуациях не способен выявить проблему? Мне пришлось разбираться в этом вопросе, спрашивать коллег, писать посты на тему и, в конце концов, мне довелось познакомиться с Джоном, соавтором этого доклада. Он как раз активно коммитил в TopologyTestDriver.
Джон объяснил, что Kafka Streams и TopologyTestDriver — это, по сути, две реализации одного интерфейса, с той разницей, что Kafka Streams — это фреймворк для потоковой обработки больших данных, а TopologyTestDriver — это быстрый, детерминированный тестовый фреймворк.
Kafka Streams спроектирован для работы при большой пропускной способности. Он использует связывание данных в пакеты, буферизацию, кеширование — всё это для поиска компромиссов с целью увеличения пропускной способности.
В TopologyTestDriver приоритеты другие. Здесь важно, чтобы тесты проходили быстро. TopologyTestDriver спроектирован для синхронной работы и немедленного получения результатов. Кеш здесь сбрасывается после каждого обновления — что нас в описанном выше случае и подвело.
Кеширование в Kafka Streams
Чтобы не перегружать RocksDB, используемый как локальное хранилище, и не создавать лишних сообщений дальше по конвейеру обработки, не каждый результат агрегирования подлежит немедленной передачи далее по конвейеру. Последовательные обновления агрегации по одинаковому ключу Kafka Streams объединяются in-memory.
Kafka Streams имеет множество различных настроек. По умолчанию максимально допустимый размер кеша max.bytes.buffering составляет 10 МБ, а период сброса commit.interval.ms — 30 секунд. Пока эти лимиты не достигнуты, значения из памяти уходить не будут. Соответственно, сброс или инвалидация кеша приведет к тому, что вы будете получать последний локально сохраненный результат.
Как на самом деле всё работало у нас в кластере
Прежде чем попасть в local store, результаты работы reduce накапливались в кеше, который сам решает, когда передавать данные дальше.
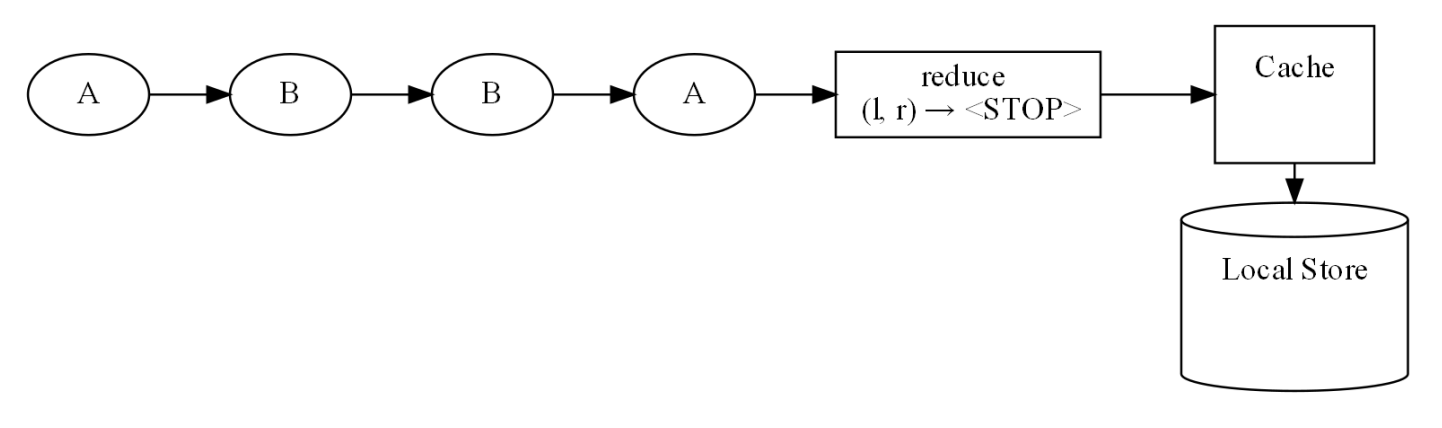
На вход попадает значение A, reduce пропускает его в кеш. Дальше значение не идет, на выходе мы его не видим. То же самое и с B. Затем дубли A и B подвергаются reduce со стоп-значением. Через 30 секунд в локальное хранилище передались только стоп-значения, они отфильтровались, и в итоге мы не получили ничего.
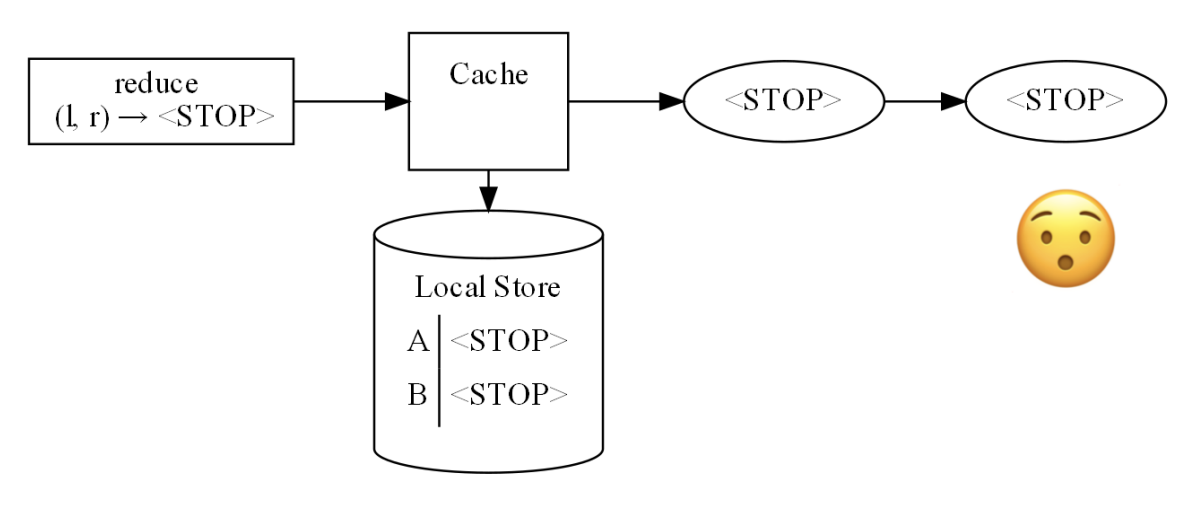
Это поведение не соответствует ожиданиям от TopologyTestDriver. Попробуем разобраться.
Сравниваем execution loop
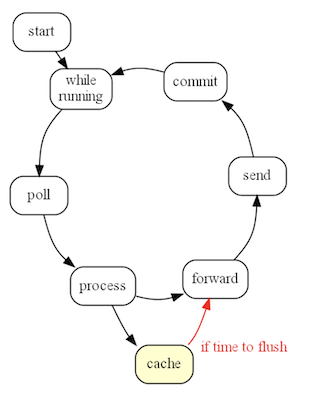
В Kafka Streams execution loop есть внутренний параллелизм, который задается через параметр max.thread, и внешний параллелизм, когда несколько worker’ов одновременно обрабатывают свои партиции. Цикл делает poll значений из Kafka, обрабатывает их, сохраняет в кеш, при достижении определенных лимитов отдает дальше по пайплайну только. Далее всё идет последовательно до коммита.
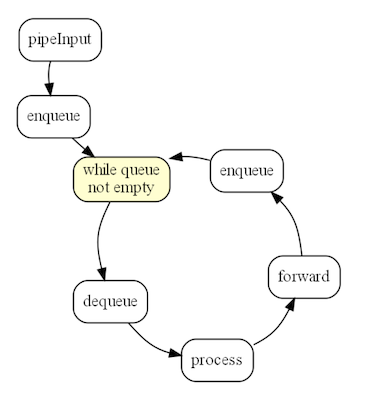
Рассмотрим теперь аналогичный цикл у TopologyTestDriver. Он работает по принципу event loop, хорошо знакомому фронтендерам, так как JavaScript движок именно так обрабатывает очередь событий в своем единственном потоке
У нас имеется очередь задач. Мы получили первую задачу, добавили ее в очередь и начинаем ее обрабатывать. Эта задача может породить еще несколько задач, которые попадут в конец этой очереди. Обработкой очереди занимается один поток, который кладет новые события в конец до тех пор, пока они не закончатся.
Как только поток «съест» все события, процессинг остановится. В TopologyTestDriver мы можем точно определить этот момент, в отличие от реальной Kafka. Как я писал выше,все данные можно получить синхронным запросом в удобном формате. В реальном же кластере на Kafka мы можем вычитывать данные только через pull — это асинхронный запрос. В этом и есть основная разница.
TopologyTestDriver хорош тем, что он быстрый, синхронный и вскрывает кучу проблем — например, с сериализацией и с бизнес-логикой вообще. Но TopologyTestDriver не вскроет проблемы, характерные для распределенных систем, таких как Kafka Streams.
В чем не поможет TopologyTestDriver
TopologyTestDriver не подойдет для решения проблем с партицированием. Для него существует только один поток и одна партиция. Все данные с любыми ключами проходят через одну виртуальную партицию и обрабатываются в одном месте.

Представим, что в одном топике сообщение находится у нас в одной партиции, а в другом — в другой партиции, как сообщения B и C:
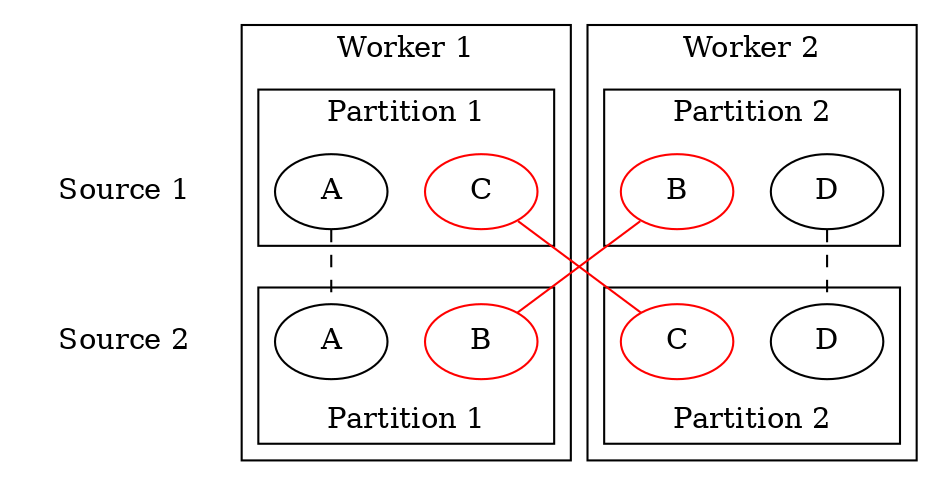
Если партиции разъедутся по разным воркерам, а мы делаем джойн по ключу, то партиции не соединятся. В кастомных алгоритмах партицирования TopologyTestDriver вам не поможет.
Kafka Streams любит создавать служебные топики, особенно для key-value хранилищ и репартицирования. При смене ключа сообщение может попасть в другую партицию, а значит, и другому воркеру. Чтобы сообщение все-таки пришло на свой воркер, создаются топики для репартицирования. Но в TopologyTestDriver топики проходят через один поток, и при переносе сообщения на другой воркер эффекта вы не увидите.
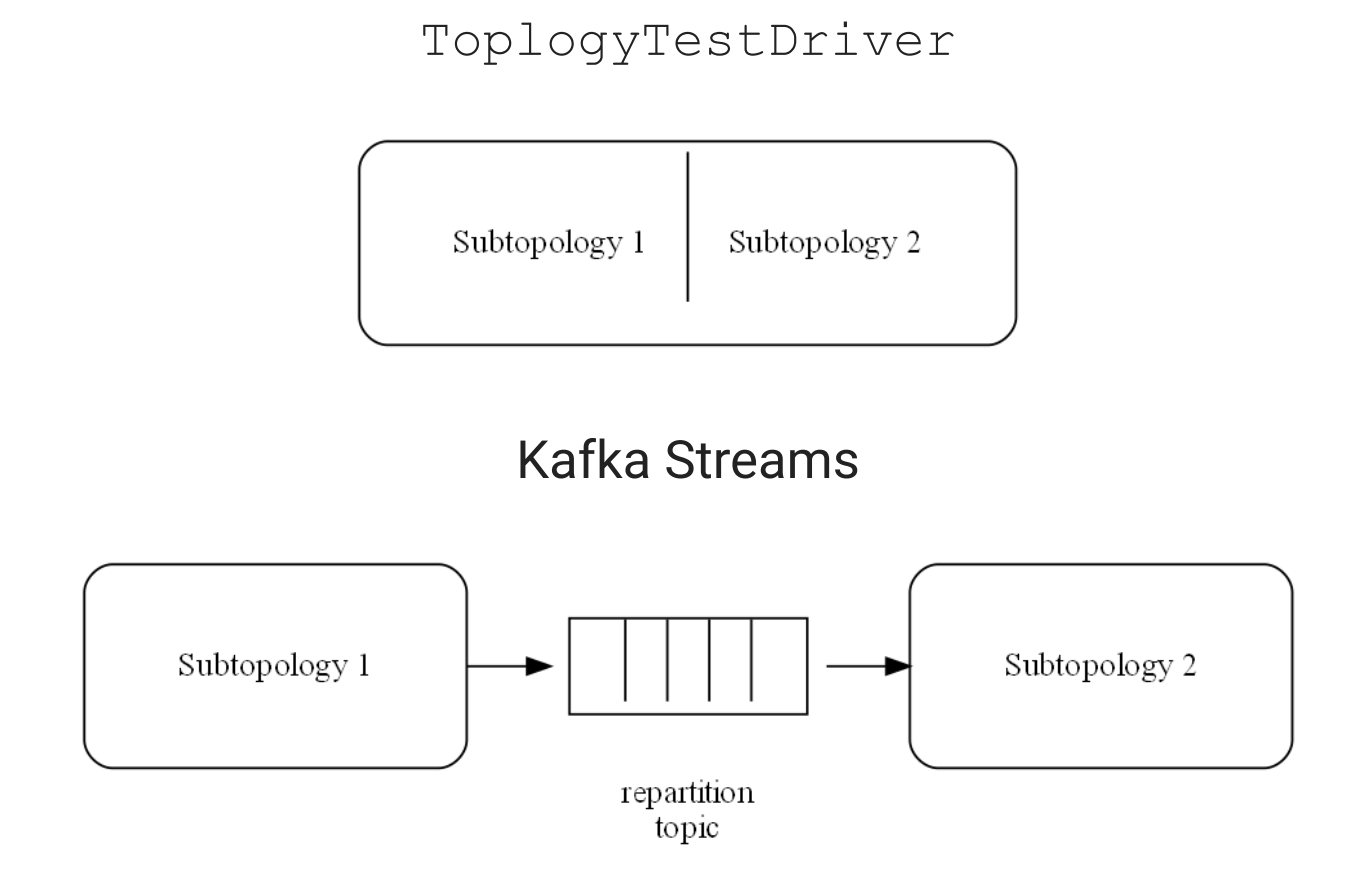
Вторая проблема — в том, что упорядочение внутри Kafka-стримов идет по штампу времени, а внутри TopologyTestDriver может идти по pipe input, то есть по добавлению данных в input. Соответственно, логика, зависящая от потокового времени, может вести себя по-разному. Последовательность, по которой события будут обрабатываться внутри наших map’ов, в TopologyTestDriver и Kafka Streams будет разной. Важно понимать это и на последовательность не опираться. Это еще один класс проблем, где TopologyTestDriver не поможет.
Обработка дублируемых сообщений
Вернемся к обработке дублируемых сообщений. На StackOverflow я нашел ответ на вопрос «How to handle duplicate messages using Kafka streaming DSL functions?». Этот ответ включен в официальный туториал, так что доверия заслуживает.
Суть ответа в том, что мы не используем reduce, то есть не используем идиоматичный подход. По своему опыту знаю, что в Kafka идиоматичный подход не всегда будет лучшим. Можно, например, использовать foreign key join, это будет одна строчка кода, но она породит такую развесистую топологию, что лучше найти менее идиоматичный, но по факту более эффективный способ.
В решении ниже ValueTransformer пишет в local store, но при этом сразу выдает результат с оглядкой на кеш: если там есть повторы, значение съедается, если нет, то идет дальше. Получается, что хотя кеш еще не сбросился, значения в outputTopic уже видны.
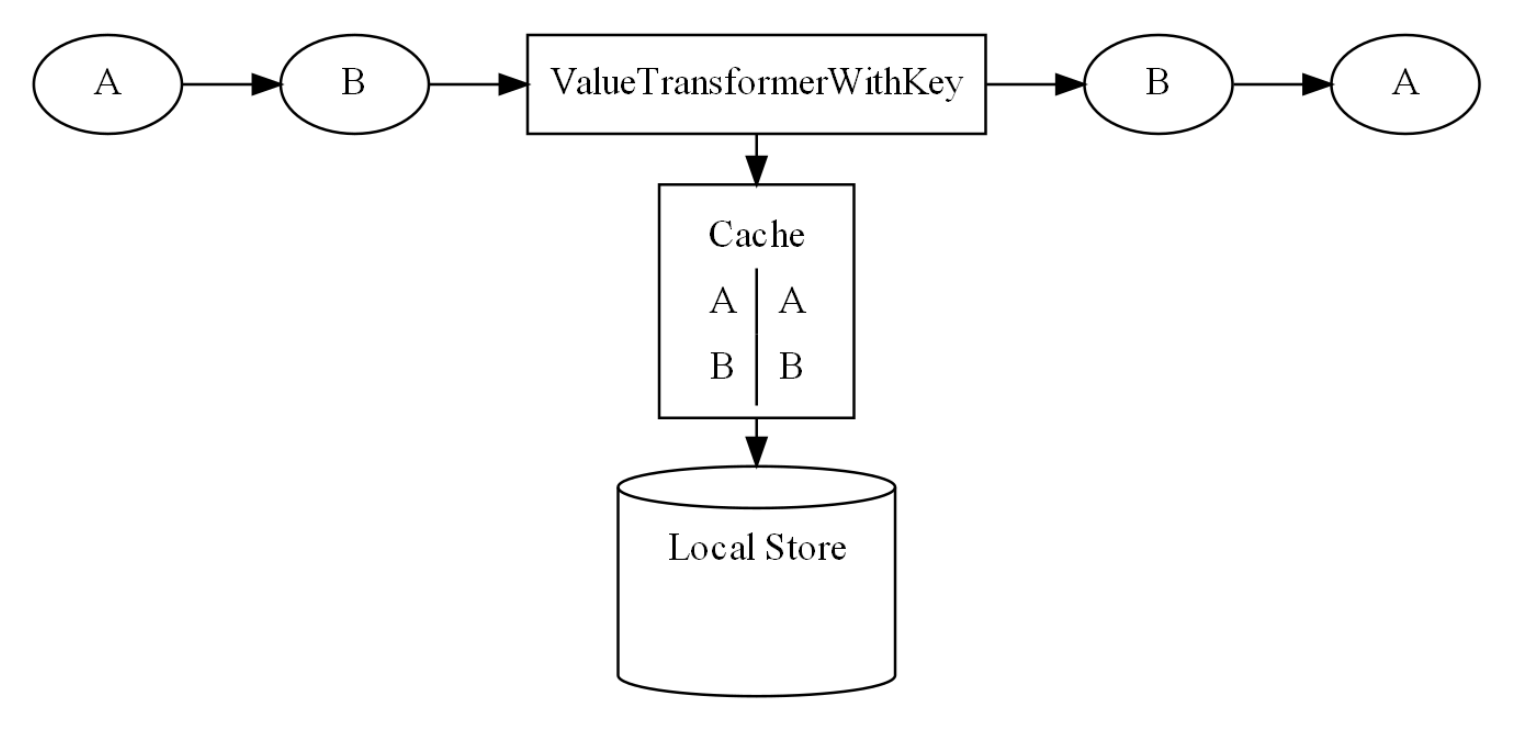
Тестируем топологию с ValueTransformer
Разберем, что будем тестировать. В rightDistinctTopology мы создали StoreBuilder:
private void rightDistinctTopology(StreamsBuilder streamsBuilder) {
KStream<String, String> input =
streamsBuilder.stream(INPUT_TOPIC_RIGHT, Consumed.with(Serdes.String(), Serdes.String()));
final Duration windowSize = Duration.ofMinutes(2);
final Duration retentionPeriod = windowSize;
final StoreBuilder<WindowStore<String, Long>> dedupStoreBuilder = Stores.windowStoreBuilder(
Stores.persistentWindowStore(DeduplicationTransformer.STORE_NAME,
retentionPeriod,
windowSize,
false
),
Serdes.String(),
Serdes.Long());
streamsBuilder.addStateStore(dedupStoreBuilder);C transformValues мы проверяем, появились ли эти данные в рамках временного окна или нет:
input
.transformValues(() -> new
DeduplicationTransformer<>(windowSize.toMillis(),
(key, value) -> key), DeduplicationTransformer.STORE_NAME)
.filter((k, v) -> v != null)
.to(OUTPUT_TOPIC_RIGHT, Produced.with(Serdes.String(),
Serdes.String()));Решение не так изящно, как в предыдущем тесте, но посмотрим, как это работает. Запустим тест. На TopologyTestDriver тест «зелёный» и для rightDistinctTopology, и для wrongDistinctTopology, что нам, конечно же, ни о чем не говорит. Надо писать интеграционный тест с «настоящим» кластером, и сделать это можно при помощи TestContainers.
Немного магии Spring автоматически предоставит нам соединение с кластером через объект KafkaProperties:
@TestConfiguration
public class TestAppContainerConfig implements ApplicationContextInitializer<ConfigurableApplicationContext> {
private final KafkaContainer kafkaContainer;
TestAppContainerConfig() {
kafkaContainer = new KafkaContainer();
kafkaContainer.start();
}
@Bean
public KafkaContainer kafka() {
return kafkaContainer;
}
@Override
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
TestPropertySourceUtils.addInlinedPropertiesToEnvironment(
configurableApplicationContext, "spring.kafka.bootstrap-servers=" + kafkaContainer.getBootstrapServers());
}
}
@SpringBootTest(classes = TestAppContainerConfig.class)
@ContextConfiguration(
initializers = TestAppContainerConfig.class)
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_CLASS)
public class TestTopologyKafkaContainers extends BaseTest {
@Autowired
private KafkaProperties properties;
@Test
public void wrongDistinctTopology() {
String servers = String.join(",", properties.getBootstrapServers());
System.out.printf("Kafka Container: %s%n", servers);
this.testDistinct(servers, TopologyConfiguration.INPUT_TOPIC_WRONG, TopologyConfiguration.OUTPUT_TOPIC_WRONG);
}Для теста нам нужно будет нагрузить данные и посмотреть, что будет на выходе. С первым действием проблем нет вообще, тут всё выглядит почти так же, как в случае TopologyTestDriver:
List.of("A", "B", "B", "A", "C")
.stream().map(e->new ProducerRecord<>(inputTopicName, e, e))
.forEach(producer::send);
producer.flush();А вот с чтением уже сложнее: чтение теперь асинхронное. Условимся, что если за 5 секунд всё получилось и никаких сообщений не пришло, делаем break, а если пришло, то add.
while (true) {
ConsumerRecords<String, String> records =
KafkaTestUtils.getRecords(consumer, 5000 /* timeout in ms */);
if (records.isEmpty()) break;
for (ConsumerRecord<String, String> rec : records) {
actual.add(rec.value());
}
}Проверим, что на выходе у нас A, B и C:
assertEquals(List.of("A", "B", "C"), actual);Запускаем тест. Он занимает гораздо больше времени (мы ждём старта Docker-контейнера, затем выполняем ожидание не менее пяти секунд для каждого из тестов), но в результате мы получаем разницу между rightDistinctTopology (зелёный тест) и wrongDistinctTopology (красный тест), что нам и было нужно. Но почему так долго? Все дело в ограниченности асинхронных тестов.
Проблемы асинхронных тестов
Когда наблюдение за тестируемой системой ограничивается лишь ожиданием какого-то выхода, на ряд вопросов по поводу этой системы надежно ответить не получится.
Я предлагаю провести мысленный эксперимент. Представим, что у нас есть контракт, согласно которому, когда мы отправляем в систему «ping», нам должен возвращаться единственный ответ «pong». При этом мы можем только асинхронно опрашивать тестируемую систему. Мы запускаем тест, ждем две секунды — тест идет. Ждем три — тест всё еще идет. И только через четыре секунды мы получаем на экране нужный ответ.
Можно ли завершать тест? В условиях указано, что мы должны получить единственный ответ, поэтому ждем дальше. Пять секунд, шесть, семь — система «молчит», тест зеленый, и вроде можно завершать. Но на восьмой секунде мы получаем еще один ответ, а значит, контракт нарушен и тест неудачен.

Таким образом, прохождение теста зависит не от свойств тестируемой системы, а от заданных таймаутов. Это проблема любых асинхронных тестов. Автоматизаторам браузеров хорошо знакомы implicit waits, которые встроены, например, в Selenide: после того как действие выполнено, мы ждём появление нужного нам результата в течение 4 секунд. Значение «четыре секунды» имеет смысл для UI систем, так как это важный психологический барьер, то время, которое пользователь готов подождать отклика, прежде чем он будет считать, что система работает слишком медленно. В случае же с тестированием систем потоковой обработки мы не можем себе представить никакого «универсального значения таймаута», так как тут нет живого пользователя и всё слишком зависит от бизнес-контекста. Таким образом, мы вольны устанавливать таймауты произвольно, и, как показал наш мысленный эксперимент, это произвольным образом может повлиять на результаты теста.
Awaitility — частичное решение проблем с асинхронными тестами
Awaitility – это небольшая библиотека, призванная помочь с написанием асинхронных тестов. Суть Awaitility в том, что она часто-часто делает запросы на наличие изменений в течение, например, 10 секунд.
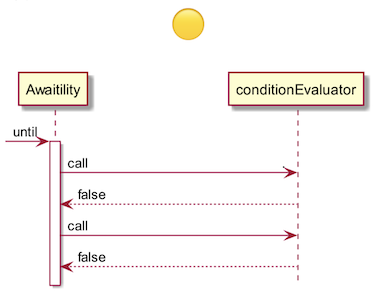
Как только в течение этого периода возвращается true, тест успешно заканчивается. Если нет, тест проваливается.

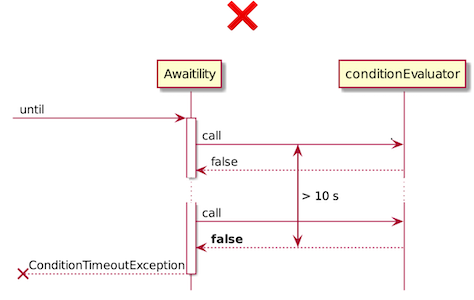
Awaitility удобна и имеет много настроек:
atLeast (не должно произойти раньше);
atMost (не должно произойти позже);
during (должно происходить на протяжении интервала);
период опроса: постоянный (1, 2, 3, 4…), Фибоначчи (1, 2, 3, 5…), экспоненциальный (1, 2, 4, 8…).
Однако Awaitility способна только ускорить асинхронные тесты, иногда очень сильно. Но фундаментальную проблему она не решает.
При этом Awaitility ставит нас на скользкую дорожку Concurrent Java Programming. Это означает, что с тестами придется заморочиться.
Поллинг надо запускать в параллельном треде.
Список полученных результатов должен быть thread-safe.
Запущенный тред должен поддерживать cooperative termination и быть готов к тому, что он может быть прерван Awaitility, как только Awaitility решит, что тест завершен.
Иначе говоря, не всякий Java-разработчик middle-уровня с таким справится. Чтобы корректно написать такой тест, требуется некоторая экспертиза в Java Concurrency. Вот код для поллинга:
List<String> actual = new CopyOnWriteArrayList<>();
ExecutorService service = Executors.newSingleThreadExecutor();
Future<?> consumingTask = service.submit(() -> {
while (!currentThread().isInterrupted()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> rec : records) {
actual.add(rec.value());
}
}
});А вот код проверки — действительно, благодаря Awaitility проверка сделалась приятнее (но и тут нужно не забывать про прерывание параллельного треда):
try {
Awaitility.await().atMost(5, SECONDS)
.until(() -> List.of("A", "B", "C").equals(actual));
} finally {
consumingTask.cancel(true);
service.awaitTermination(200, MILLISECONDS);
}Как мы видим, код довольно сложный. Зато, запустив эти тесты, мы увидим, что «зелёный» тест выполняется уже не 5 секунд, а сильно быстрее. Если тестов много, то в сумме это даст существенное ускорение.
Поэтому я горячо рекомендую Awaitility к использованию во всех асинхронных тестах.
Подведем итог
И TopologyTestDriver, и интеграционные тесты необходимы, одно не заменяет другое. Не стоит думать, что вас спасут только TestContainers. Пишите юнит-тесты на TopologyTestDriver. Если вы понимаете, что он не вскрывает проблему, пишите интеграционные тесты. Стоит знать и понимать ограничения как TopologyTestDriver, так и асинхронного тестирования.
Исходники тестов я выложил на Github. Пост по мотивам этого доклада есть на Confluent.io. Англоязычный вариант этого доклада, сделанный мной совместно с Джоном Рослером в конце 2020 года, доступен на Youtube. Также, пользуясь случаем, рекомендую русскоязычный чат по Kafka и комьюнити Confluent в слаке. Подписывайтесь на мой технический твиттер — @inponomarev.