

Классический сценарий использования большинства приложений, будь то веб или любое другое приложение с пользовательским интерфейсом: пользователь заходит в приложение, просматривает какую-то информацию, вводит свои данные, сохраняет. Весь сценарий состоит из потоков данных: либо идущих от сервера к пользователю – на чтение, либо от пользователя идущие на сервер – на запись.
Современные приложения работают со все большим количеством информации, и, понятно, что чем эффективнее подходы работы с потоками данных, тем эффективнее работа приложения в целом.
За пять предыдущих лет человечеством было произведено информации больше, чем за всю предшествующую историю (из них половина была произведена в нашем отделе УНП).
Проблематика
Существует класс приложений, в которых пользователи модифицируют исходные данные, но эти модификации должны применяться к основной системе только после согласования некоторой третьей стороной - руководителями/специалистами/сторонними организациями/другими уполномоченными пользователями. Также по итогам предварительного ознакомления с изменениями и ревью часто требуется внести некоторые корректировки, чтобы снова отправить на согласование, и после нескольких итераций изменения вступают в силу. Создается новая базовая модель, в которую также можно вносить изменения, которые необходимо согласовывать - процесс повторяется.
Мы занимались разработкой именно такой системы, и сегодня речь пойдет о новой версии реализации системы, которую мы разработали совместно со Skirgus.
Пару слов о первой и не совсем удачной реализации
В первой реализации системы использовался механизм, сохранявший все неутвержденные изменения в БД. Любая модификация любых данных записывалась в специальную таблицу в формате json. В json хранилась информация о сущности, которая изменилась, полях, которые изменились, их старые и новые значения. Отдельно создавались записи об удаленных и добавленных сущностях.
В первой реализации использовался NHibernate для работы с БД. При работе с измененной моделью все запросы к БД перехватывались, изменения извлекались из БД и накладывались на основную схему. При сохранении изменений, запросы также перехватывались, сравнивались модели до и после модификации, изменения сохранялись в виде json в таблице в БД.
Первая реализация работала чрезвычайно медленно, была подвержена большим количествам ошибок, которые было тяжело находить и исправлять. Зачастую исправления приходилось делать в хранимых json, гарантировать правильность работы системы после чего было затруднительно. Также подход сильно нагружал БД, что неоднократно приводило к отказу системы. Плюс были большие сложности с откатом изменений.
В данной статье предлагается вариант реализации системы иным образом. Подход напоминает механизм создания веток и Pull Request, применяемый при разработке в различных системах контроля версий, например, git. Решение основано на принципах CQS, шаблонах CQRS и Event Sourcing.
Приложение
Итак, приложение. Функционально устроено очень просто: пользователи, распределенные территориально, вводят информацию, отправляют в центральный узел – для анализа, аудита, принятия управленческих решений.
Коротко о предметке. Предметная модель представляет собой иерархическую структуру. Есть паспорт – некоторые данные, с которыми работают множество пользователей. Каждый видит свою часть общих данных, редактирует. В нашем случае добавляет объекты строительства, добавляет контрольные точки, ответственных, сроки, уточняет местоположение и т.д.
Паспорт, он же проект на схеме, – корень агрегации (aggregate root), содержащий все остальные данные. Паспорт содержит коллекцию сущностей результатов, каждый из который содержит коллекцию сущностей значений результатов, они в свою очередь содержат коллекции заказчиков, которые содержат объекты капитального строительства, которые строятся с достижением контрольных точек.
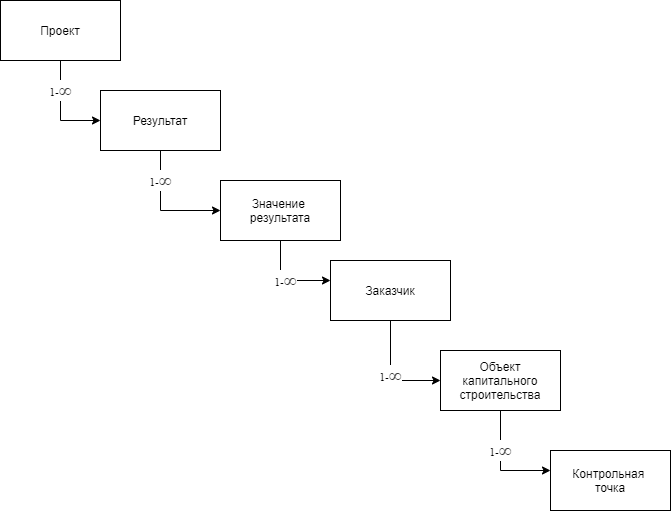
После изменения и внесения данных всеми пользователями утверждается весь паспорт. Все добавленные элементы становятся утвержденными. Начинается следующий этап. Снова вводятся данные, добавляются новые объекты, контрольные точки, меняются ответственные и т.д.
Так как это система документооборота, паспорт, являющийся документом, должен быть утвержден специальным органом. Все изменения, которые были добавлены разными пользователями в одном паспорте, утверждаются.
Все сущности, составляющие предметную модель, имеют срок жизни. Каждый раз, когда новый паспорт утверждается, создаются новые версии сущностей. Таким образом, наши сущности версионируемые.
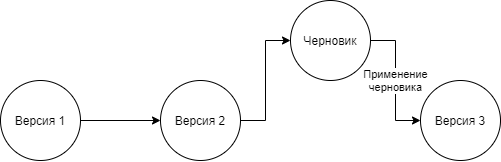
Для создания новой версии паспорта с утвержденными данными, которые ввели пользователи, создается черновик, на основе действующей (актуальной версии паспорта) - концепция напоминает процедуру создания ветки в git. Все изменения хранятся только в черновике. После его применения срок действия актуальной версии прекращается, начинается новая актуальная версия, созданная на основе черновика.
Основная работа происходит в черновике – разнообразные внутренние согласования, изменение/редактирование данных, ввод новых сущностей и т.д.
Проблема в том, что с черновиком работают большое количество пользователей, которые постоянно вносят изменения, что-то редактируют, сравнивают, удаляют и т.д. Ожидалось, что нагрузка со стороны пользователей будет очень высокой, и требовалось снизить по возможности нагрузку на БД, так как предыдущая система с похожей проблематикой не справлялась, хотя количество пользователей было меньше – главным образом из-за нагрузки на БД.
Схематично, процесс создания новой версии на основе черновика, можно представить так:
CQRS, Event Sourcing
Начало разработки проекта происходило в другом подразделении компании. Изначально была заложена неплохая архитектура – одно веб приложение, содержащее только пользовательский интерфейс, и одно приложение для доступа к данным, каждое из которых может горизонтально масштабироваться отдельно. Для доступа к данным, или для их изменения, часть приложения, содержащая пользовательский интерфейс, отправляет либо запросы на чтение, либо запросы на изменение данных. То есть архитектура системы изначально разделяла потоки чтения и записи - следовала принципу CQRS.
CQRS

Принцип CQS гласит, что метод должен быть либо командой, выполняющей какое-то действие, либо запросом, возвращающим данные, но не одновременно. Другими словами, задавание вопроса не должно менять ответ. Более формально возвращать значение можно только чистым (т.е. детерминированным и не имеющим побочных эффектов) методом.
Один из примеров применения принципа CQS в ООП – разделение методов чтения и записи свойств – getter/setter. Этому же принципу следует, например, IEnumerator в .net: отдельно метод перемещения в контейнере элементов, отдельно – свойство на чтение записи.
CQRS немного дополняет концепцию CQS в том, что для чтения и записи мы используем разные модели. CQS обычно рассматривается как принцип на микроуровне, как дизайн методов, а CQRS - на макроуровне, как архитектурный шаблон. Смысл CQRS в том, чтобы разделить потоки чтения и записи, рассматривать и оптимизировать их отдельно. Также для подсистем чтения и записи нужны отдельные архитектурные качества.
Например, для записи хранилище должно быть в консистентом состоянии, для чтения достаточно согласованности в конечном счете. Для чтения важна расширяемость, тогда как для записи нам достаточно одного хранилища.
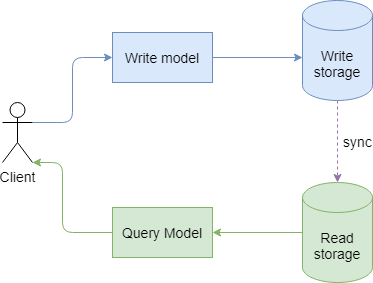
Для чтения и записи можно использовать отдельные хранилища. Например, все команды выполняются над мастер БД, все запросы на получение данных - над репликой. Синхронизация мастер БД и реплики происходит асинхронно. Тут мы имеем дело с таким понятием, как “согласованность в конечном счете” (eventual consistency). Если в момент выгрузки данных клиенту вы не перехватываете http запросы на модификации данных, вы и так имеете дело с eventually consistent системой.
Есть много интересных преимуществ следования этому принципу, на которых здесь останавливаться не будем.
Event sourcing
Следование этому принципу также дает возможность использования паттерна Event sourcing - когда любое изменение в данных сохраняются в виде лога изменений – о том, что произошло некоторое событие, и данных, связанных с этим событием. Например, добавили некоторый объект – событие, свойства объекта – данные связанные с этим событием.
Яркий аналог из жизни этого принципа – бухгалтерская книга. Любые изменения, происходящие в счетах, записываются в виде бухгалтерских проводок. Все правки вносятся также отдельными проводками. Event sourcing – это append only схема – любые изменения – это новые события, с которыми ассоциированы данные.
Также примером может служить ваш банковский счет. Вы же не думаете, что баланс вашего счета — это поле в БД? Скорее это итог всех транзакций, происходивших с вашим счетом с момента открытия счета.
Event sourcing дает такое множество интересных преимуществ и возможностей, о которых, возможно, стоит рассказать отдельно:
- более высокая скорость записи, так как данные только добавляются в единую таблицу, а последовательная скорость доступа жестких дисков выше.
- данные – не мутабельные (immutable). Все что произошло и записалось – уже не изменится. Система, на момент определенного события останется той же самой.
- простота отладки – мы можем легко вернуть состояние системы на момент происшествия какого-либо события, включить отладку, и понять, что происходило с системой на момент, когда произошло следующее событие.
- мы можем восстановить состояние системы на любой момент времени.
Версионирование на основе Event sourcing
Так как система уже была написана с использованием CQRS, логично было использовать Event sourcing для аудита всех изменений.
Не будем удалять, добавлять новые записи, апдейтить свойства сущностей, а лишь записывать в БД что произошло то или иное событие в таблицу Event Log. А весь паспорт будем держать в памяти и работать с объектами паспорта только в памяти. Весь паспорт будем хранить в Redis в виде одного документа, таким образом, доступ ко всем данным паспорта мы получаем за одно обращение к Redis в денормализованном виде. Данные, сохраненные в Redis, далее будем называть “кэш”.
Версионирование мы применяем не для всех сущностей в проекте, а только для тех, что составляют паспорт (именно для паспортов оно нам нужно). Обычно event sourcing рассматривается в контексте работы всей системы. В нашем случае мы его используем только для паспортов.
По аналогии с git, каждое событие - это новый коммит. А актуальная версия - ветка мастер, от которой мы создаем новую ветку - черновик. Создание новой версии происходит после слития ветки в мастер через механизм pull request.
Схема версионирования
Поток записи:
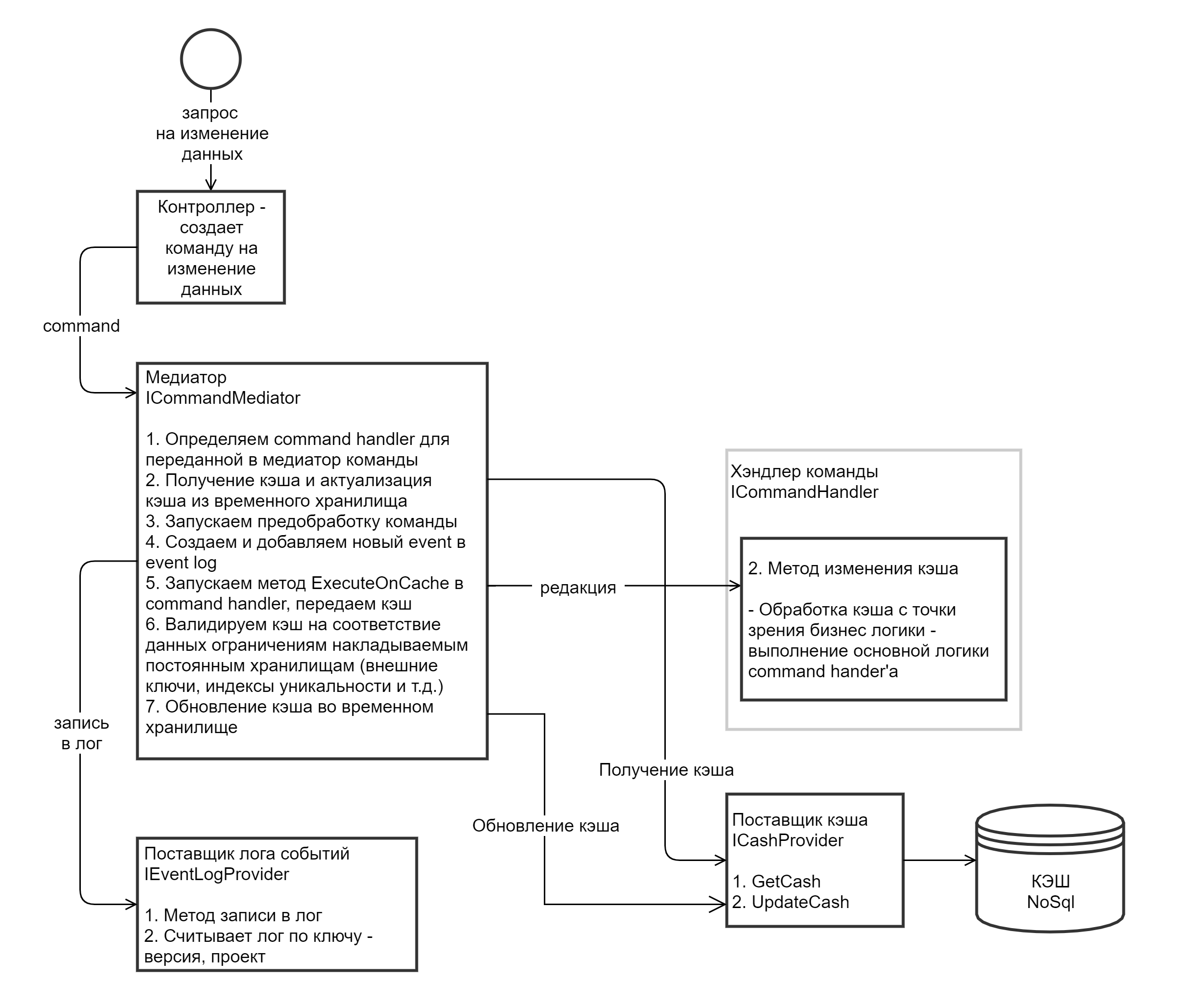
На контроллер поступает POST запрос на изменение данных. Например, необходимо создать новую контрольную точку (некоторая сущность внутри предметной модели) у объекта с идентификатором 5665, плюс, передаются параметры новой контрольной точки (тип, наименование, дата достижения и т.д.)
Контроллер создает объект ICommand (ниже есть описание интерфейсов ICommand, IQuery, ICommandHandler, IQueryHandler), который инкапсулирует в себе всю необходимую информацию о новой контрольной точке
Контроллер отправляет объект ICommand в метод Send объекта ICommandMediator
ICommandMediator определяет command handler для переданной в медиатор команды
ICommandMediator получает и актуализирует кэш из временного хранилища
ICommandMediator запускает предобработку команды - метод PreProcess у ICommandHandler
ICommandMediator cоздает и добавляет новый event в event log
присваивает ей идентификатор,
прописывает автора изменения,
время наступления события,
идентификатор версии, для которой произошло события,
идентификатор предыдущего события, чтобы можно было восстановить хронологию,
тип события - в нашем случае добавление контрольной точки
данные ассоциированные с событием (сама команда)
и некоторую другую служебную информацию
Запускаем метод Execute в command handler, передаем кэш
Валидируем кэш на соответствие данных ограничениям накладываемым постоянным хранилищам (внешние ключи, индексы уникальности и т.д.)
Обновление кэша во временном хранилище
Запускаем метод Execute в command handler, передаем кэш
Валидируем кэш на соответствие данных ограничениям накладываемым постоянным хранилищам (внешние ключи, индексы уникальности и т.д.)
Обновление кэша во временном хранилище
Поток чтения:
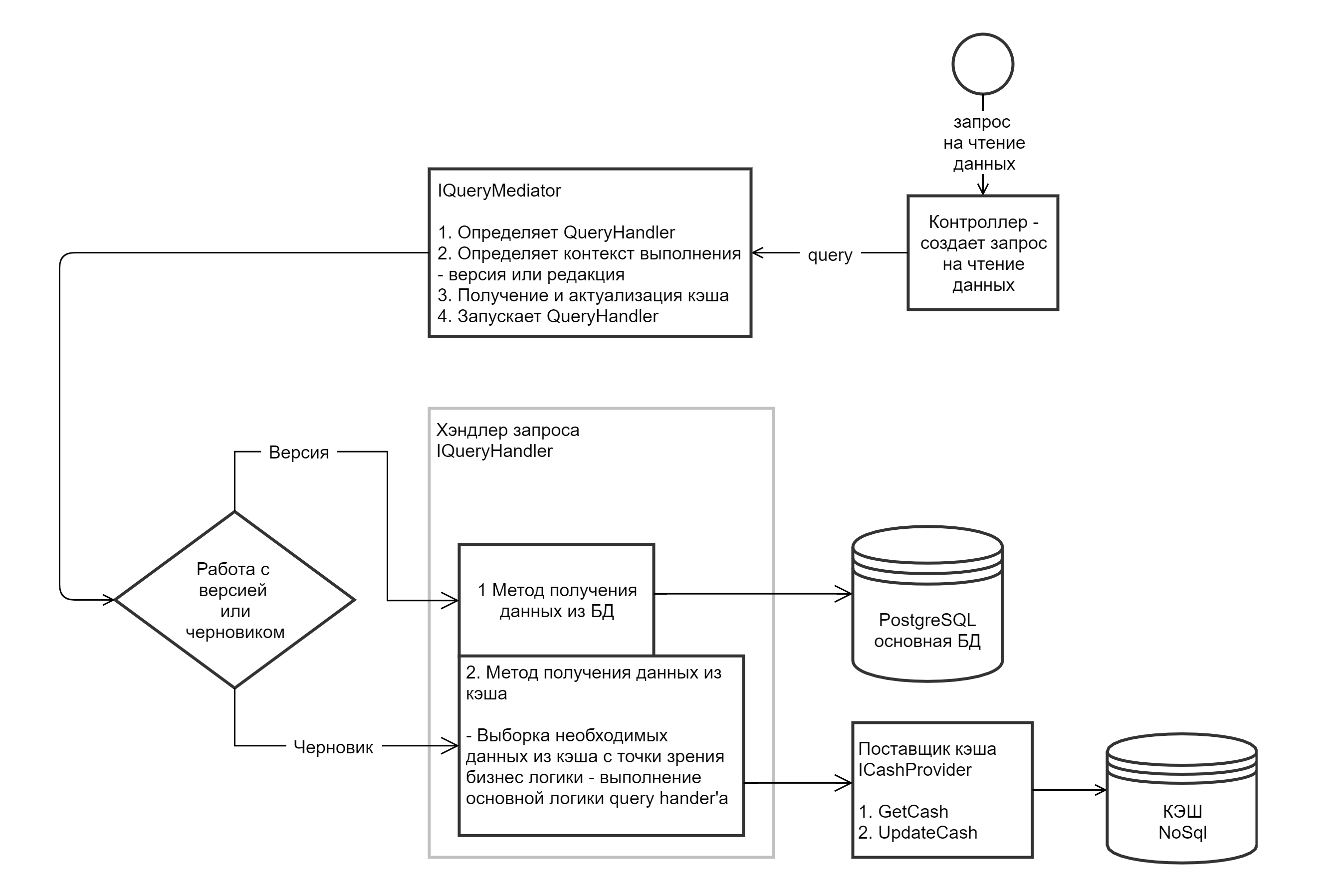
На контроллер поступает http запрос на получение данных
Контроллер создает объект IQuery
Контроллер отправляет объект IQuery в объект IQueryMediator
IQueryMediator находит подходящий IQueryHandler, которые может обработать запрос IQuery
IQueryMediator определяет контекст выполнения - черновик или версия в БД
Если контекст БД - запускает у IQueryHandler метод ExecuteOnDataBaseAsync - в нем прописывается необходимый код извлечения данных из БД
Если контекст выполнения кэш - запускет у IQueryHandler метод ExecuteOnCacheAsync
Данные после выполнения ExecuteOnDataBaseAsync или ExecuteOnCacheAsync возвращаются в ответе контроллера.
Актуализация кэша:
Чтобы выполнить запрос над кэшем, его сначала необходимо актуализировать. Для этого по ключу извлекаем кэш из хранилища. В нашем случае это редис. Вместе с данными в кэше хранится идентификатор последнего события, на основе которого был создан кэш. В журнале событий извлекаем все новые события и выполняем команды над кэшем, которых еще нет. Таким образом, наш кэш актуализирован,т.е. мы получили данные на момент выполнения последнего события. Метод ExecuteOnCacheAsync у ICommandHandler выполняется каждый раз когда актуализируем кэш. Метод PreProcess выполняется единожды в момент самого первого выполнения команды.
Основные сущности, необходимые для работы версионирования:
IQuery:
public interface IQuery<TResponse, TCachedEntity>
where TCachedEntity : class
{
long VersionId { get; set; }
long ProjectId { get; set; }
}TResponse – тип ответа
IQueryHandler ():
public interface IQueryHandler<TQuery, TResponse, TCachedEntity>
: IQueryHandler
where TQuery : IQuery<TResponse, TCachedEntity>
where TCachedEntity : class
{
/// <summary>
/// Выполнение запроса на получение данных из кэша
/// </summary>
/// <param name="query">Запрос</param>
/// <param name="cachedEntity">Кэш</param>
Task<TResponse> ExecuteOnCacheAsync(
TQuery query,
TCachedEntity cachedEntity);
/// <summary>
/// Выполнение запроса на получение данных из базы данных
/// </summary>
/// <param name="query">Запрос</param>
Task<TResponse> ExecuteOnDataBaseAsync(TQuery query);
}TCachedEntity – класс, хранимый в кэше. В нашем случае паспорт проекта. Мы можем запросить данные для разных версий. В случае, если версия уже применена, запрос будет выполняться над БД. Если версия – черновик, запрос выполняется над объектом в кэше.
Выполнением запросов занимается так называемый QueryMediator. Его задача – для данного IQuery найти соответствующий IQueryHandler, получить текущее значение паспорта из кэша, и передать в метод Execute IQueryHandler’а IQuery и кэш проекта.
Похожая аналогия для команд:
ICommand:
public interface ICommand<TCommandEntity, TResponse> : ICommand
where TCommandEntity : class
{
TCommandEntity CommandEntity { get; set; }
long VersionId { get; set; }
long ProjectId { get; set; }
}TCommandEntity – данные, ассоциированные с этой командой. Эти данные записываются в EventLog в БД.
ICommandHandler
public interface ICommandHandler<TCommandEntity, TResponse, TCachedEntity>
: ICommandHandler<TCachedEntity>
where TCommandEntity : class
{
/// <summary>
/// Предобработка команды, выполняется перед сохранением в лог команд
/// </summary>
Task PreProcess(
ICommand<TCommandEntity, TResponse> command,
CachedData<TCachedEntity> cachedData,
IDbTransaction transaction);
/// <summary>
/// Выполнение команды на изменение данных в кэше
/// </summary>
Task<TResponse> ExecuteOnCacheAsync(
ICommand<TCommandEntity, TResponse> command,
CachedData<TCachedEntity> cachedData,
long eventId,
IDbTransaction transaction);
}Метод PreProcess – вспомогательный, нужен для начальной инициализации данных. Так как все операции выполняются только над кэшем, при применении черновика нужно обеспечить сохранение связей между сущностями по внешним ключам. Для этого, в методе PreProcess заранее заполняются идентификаторы будущих сущностей – запросом к БД на получение идентификаторов из соответствующих сиквенсов, например:
select nextval(pg_get_serial_sequence('table', 'id')
запрос на получение идентификатора для будущей контрольной точки. При применении черновика, новая сущность заносится в БД с выданным идентификатором на этапе препроцессинга.
Метод ExecuteOnCacheAsync выполняет действие над объектом (паспортом) в кэше. При этом в БД заносится только информация о событии и параметрах этого события. Метод выполняется каждый раз когда актуализируется кэш.
Вся разработка сводится к модификациям обычного .net объекта с внутренними коллекциями напрямую в памяти. Нет ОРМ – он тут не нужен, объекты не связаны с сущностями в БД. Нет работы с БД вообще на этапе работы с черновиком. Весь паспорт хранится как единый документ – паспорт в этом случае является корнем агрегации (для тех кто знаком с DDD), документом (для тех кто не знаком), хранящимся в денормализованном виде. Широкий простор для использования NoSQL концепций.
Скорость разработки именно бэкэнд части увеличивается просто до предела. Что может быть проще чем модифицировать обычный объект? К примеру, так выглядит команда создания новой контрольной точки:
public async Task<long> ExecuteOnCacheAsync(
ICommand<WpCheckPointEditDto, long> command,
CachedData<WorkPlanProjectModel> cachedData,
long eventId,
IDbTransaction transaction)
{
var model = command.CommandEntity;
var newCheckPoint = new CheckPointsModel
{
Id = model.Id.Value,
Code = model.Code,
Characteristic = model.Characteristic,
Note = model.Comment,
ResponsibleExecutor = model.ResponsibleExecutor.Id,
EndDate = model.TargetDate,
Name = model.Name,
CustomerObjectId = model.WpObjectId,
IsNotActual = model.NotUsing,
ResultsKind = model.ResultKindId,
Document = model.FileId,
Link = model.Link,
DataSource = model.DataSource,
MetaId = model.Id.Value
};
cachedData.Data.CheckPoints.Add(newCheckPoint);
return model.Id.Value;
}Мы просто добавили в коллекцию CheckPoints паспорта новую контрольную точку. При этом сохранили в БД event и всю информацию о новой контрольной точке.
Название колонки | Значение | Примечание |
EventId | 3721 | Идентификатор события |
ProjectId | 8216732688 | Проект, для которой создана версия |
VersionId | 1540 | Версия в рамках проекта |
CreateDate | 2021-02-04 09:23:41.467400 | Дата события |
Command Designation | SaveCheckPoint | Код события |
Preceding EventId | 3720 | Идентификатор предыдущего события |
AuthorId | null | Автор события |
Command |
| Данные, ассоциированные с событием |
Проблемы и решения
В процессе разработки мы почему-то столкнулись с некоторыми проблемами:
Проблема 1: отсутствие DB constraints на этапе работы с черновиком, таких как внешние ключи, уникальность и т.д. За этим приходится следить отдельно. Также вытекающий отсюда минус - если модель черновика не консистентна, об этом мы узнаем только при применении черновика.
Решение: добавили валидаторы, проверяющие те самые ограничения, накладываемые базой данных: внешние ключи, уникальность, которые запускаем после выполнения каждой команды до сохранения в кэше. Внутри себя валидатор генерируют исключения, в случае ошибок. Если произошло исключение будет выполнен откат транзакции, команда не сохранится в event log.
Проблема 2: Сложность исправления ошибочных данных - если данные хранятся просто в структурированном виде в БД, в виде обычных сущностей - ошибки в данных мы можем исправить, просто изменив данные в БД. Когда данных как таковых нет, а есть только события, которые формируют эти данные, сделать такие правки не получится. Нужно добавить новое событие, которое исправит некорректные данные.
Решение: По сути сделали 2 решения. Первое - инструмент последовательного отката событий из event log. Второе - редактор структуры проекта, в которой можно изменить любые сущности в проекте. Такое изменение проходит отдельной командой.
Проблема 3: Также есть вопросы, связанные с конкурентным доступом к кэшу, одновременным выполнением команд над паспортом разными пользователями и т.п. Проблема может возникнуть при одновременной попытке выполнить команду разными пользователями, и, скорее всего, даже на разных серваках. Т.е. оба исполнителя считают последнюю сохраненную команду и попытаются изменить объект в кэше. С точки зрения каждого конкретного исполнителя все норм. Версия сущности соответствует последнему eventId.
Решение: Решения пока в разработке. Хотим сделать лок на уровне редиса, чтобы если кто-то начал выполнять команду, другой пользователь мог начать обработку только после добавления нового ивента в eventLog.
Заключение
Мы получили схему версионирования, которую сложно осмыслить, легко поддерживать, и невозможно забыть и очень удобно разрабатывать.
В любой момент мы можем актуализировать объект паспорта, выполнив последовательно все команды из Event Log, все коллекции в полученном объекте записать в БД и получить новую действующую версию. 95% всей работы пользователей происходит в черновике, поэтому с точки зрения производительности тут значительный профит. Чтение данных также происходит из черновика, т.е. из объекта в кэше.
Так как в 90% случаев на чтение мы открываем именно черновик паспорта, который уже хранится в кэше в денормализованном виде, скорость открытия разделов паспорта также сильно ускоряется. При этом запросов к БД не происходит вообще, за исключением версий, не являющихся черновиком. Для них запросы выполняются к БД. В кэше всегда хранятся актуальные данные – любая команда модифицирует объект паспорта и обновляет кэш.
Работа с приложением практически полностью отвязана от БД – нагрузки на БД практически нет. Скорость разработки высокая за счет простоты концепции, и нет необходимости обеспечивать корректную работу ОРМ. Скорость работы приложения высокая за счет хранения данных в денормализованном виде и отсутствия необходимости маппинга данных из БД в объектную модель приложения.
Также концепция существенно увеличивает надежность и стабильность приложения. Мы можем восстановить состояние системы на любой момент времени и точно узнать, что с ней происходило, последовательно выполняя события из event log. Также, у нас есть полный аудит системы – мы точно знаем, что и когда с ней происходило.
vitesse
Спасибо за статью, было очень интересно почитать, вы очень подробно описали проект. Конечно у каждого проекта свои потребности, но ваши подходы и решения могут быть полезны начинающим архитекторам. Я бы даже сказал, что ваша статья лучше некоторых лекций и курсов, с которыми я сталкивался.
diasm Автор
vitesse, благодарю за лестный отзыв. Все верно, статья типа tutorial — т.е. одной из целью написания статьи было показать как можно применить подходы cqrs + event sourcing на практике на живом примере
Также планируется статья по мотивам доклада Грега Янга на тему cqrs + event sourcing с его личного одобрения