

Только что мы представили новую версию поиска Y1. Она включает в себя комплекс технологических изменений. В том числе улучшения в ранжировании за счёт более глубокого применения трансформеров. Подробнее об этом направлении мой коллега Саша Готманов уже рассказывал в нашем блоге. В новой версии модель стала мощнее: количество параметров возросло в 4 раза. Но сегодня мы поговорим о других изменениях.
Когда человек вводит запрос в поисковик, он ищет информацию или способ решения своей задачи. Наша глобальная цель — помогать находить такие ответы, причём сразу в наиболее ёмком виде, чтобы сэкономить людям время. Этот тренд на ускорение решения пользовательских задач особенно заметен в последние годы. К примеру, теперь многие пользователи задают свои вопросы не текстом в поиске, а голосовому помощнику. И тут нам на помощь пришли огромные генеративные нейросети, которые способны перерабатывать, суммаризировать и представлять в ёмком виде тексты на естественном языке. Пожалуй, самой неожиданной особенностью таких сетей стала возможность быстро обучаться на всё новые задачи без необходимости собирать большие датасеты.
Сегодня мы поделимся опытом создания и внедрения технологии YaLM (Yet another Language Model), которая теперь готовит ответы для Поиска и Алисы. В этом мне помогут её создатели — Алексей Петров petrovlesha и Николай Зинов nzinov. Эта история основана на их докладе с Data Fest 2021 и описывает опыт внедрения модели в реальные продукты, поэтому будет полезна и другим специалистам в области NLP. Передаю слово Алексею и Николаю.
За последние три года трансформеры стали главной архитектурой нейросетей в задачах NLP. А в последнее время — так и не только в NLP. Модели становятся всё больше. Они решают всё новые задачи. Наверняка, если в ближайшем будущем вы захотите решить задачу с текстами, то будете использовать именно трансформеры. Самым ярким представителем этого тренда стала модель GPT-3. И, что примечательно, эта модель не только очень большая и очень умная — она еще умеет решать новые задачи без дополнительного обучения. Это так называемый Few-shot learning.
Именно этот подход мы применили в нашем семействе языковых моделей YaLM. Старшая из них насчитывает 13 млрд параметров, младшая — 1 млрд. Обучить и внедрить подобные гигантские модели — нетривиальная задача. Об этом и поговорим.
Как собирали датасет
Задача языкового моделирования формулируется достаточно просто. У вас есть какой-то текст, и вы заставляете модель его продолжить. Модель, обучаясь генерировать слово за словом, сначала запоминает, как устроен язык, а потом и еще какие-то реальные факты о внешнем мире. Для обучения модели, которая на это способна, требуется очень много разнообразных данных.
Самый простой способ получить тексты для обучения языковой модели — это взять какие-то хорошие тексты из Википедии, книг, новостей и подобных источников. К ним можно добавить открытые обсуждения из соцсетей и форумов, которые далеко не всегда высокого качества (с точки зрения языка), но зато из них модель узнает, как вообще поддерживать диалог.
К сожалению, таких чистых текстов не всегда много. Не больше нескольких сотен гигабайт. И они не покрывают полностью весь диапазон возможных тем. Чтобы решить эту проблему, к ним добавляются относительно грязные тексты, собранные из интернета. К слову, можно было бы учить модель вообще на всем интернете, но текстов в интернете так много, что модель не смогла бы их пройти даже один раз за несколько лет. Поэтому всё лишнее выбрасывается: всякие неестественные тексты, дубликаты, объявления о продаже и тому подобное.
Для этого мы используем комбинацию эвристических и машиннообученных методов и в результате фильтруем сырые тексты из интернета так, что в комбинации с чистыми источниками получаем несколько терабайтов текста, чего уже достаточно для моделей на миллиарды параметров.
Как обучали модель
После того, как мы собрали датасет, дело доходит до запуска обучения. При этом мы не хотим состариться, пока идёт обучение. Значит, задачу нужно распараллелить на достаточно большом кластере видеокарточек с хорошей сетью. К примеру, мы пользуемся кластером, состоящим из карточек NVIDIA Ampere.
Когда ваша модель влезает в память одной карточки, то просто вспоминаем стандартный способ распараллелить обучение. Так называемый Data parallelism.
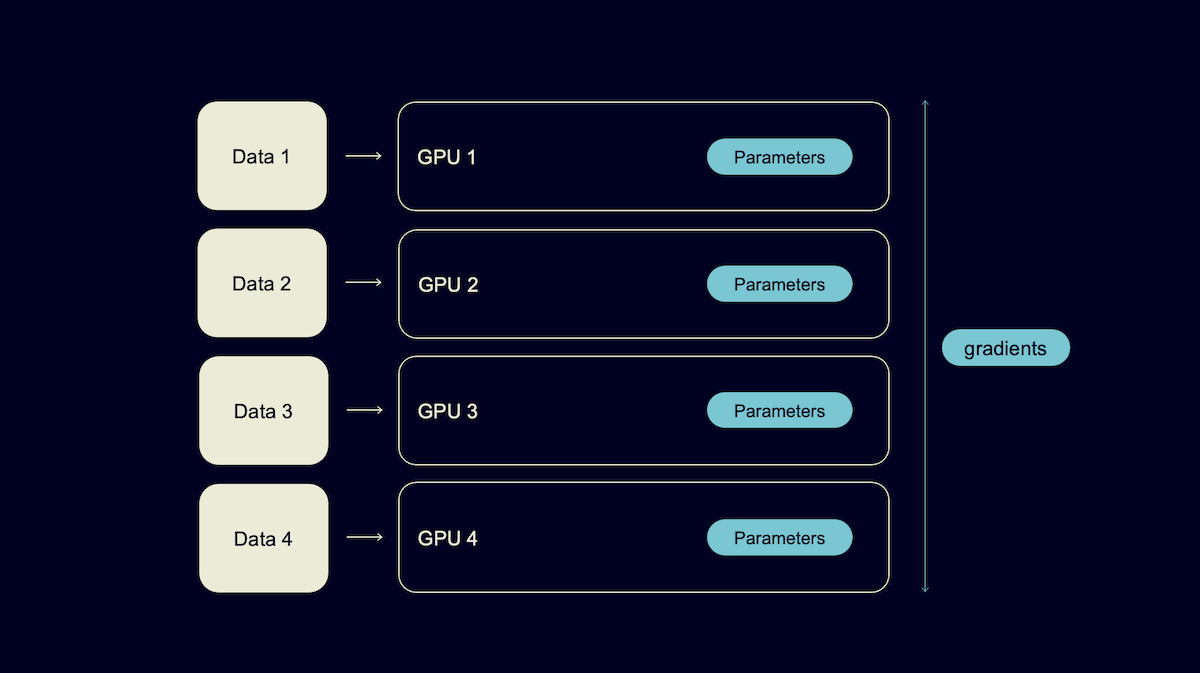
Каждая из карточек полностью прогоняет модель на своем куске данных. А между собой они обмениваются только градиентами для того, чтобы каждая карта могла получить у себя состояние модели, обновленное с учетом всех данных.
Но на больших моделях всё куда сложнее. Даже наша младшая модель на 1 млрд параметров во время обучения, когда нужно хранить не только параметры модели, но и градиенты и состояние оптимизатора, уже не умещается в памяти одной карточки. Её нужно распиливать. Для этого есть несколько различных техник. Наверное, самый интуитивный и понятный способ это Pipeline parallelism. Первая карточка применит несколько первых слоев модели. Полученный промежуточный результат перешлет второй карточке, которая хранит следующие слои модели и применяет их. И так далее.

Такой способ очень хорошо работает в случае, когда вам нужно просто применить модель, но во время обучения такое последовательное применение слоев вызывает простой вычислительных ресурсов, потому что карты с первыми слоями будут ждать, пока следующие карты завершат forward- и backward-проходы. Если модель у вас очень большая и распилена на большое число карточек, то простои могут очень сильно замедлить обучение.
Другой подход, который активно развивает NVIDIA в своем фреймворке Megatron-LM, называется Tensor parallelism. Его идея состоит в том, чтобы распиливать модель не поперек слоев, а вдоль. Предположим, у нас есть какой-то большой слой (на картинке ниже для примера взят простой линейный слой — умножение на матрицу весов B). Давайте поместим его часть на одну карточку, другую часть — на другую карточку.

Промежуточные результаты, пришедшие с прошлого слоя, пересылаются на каждую из двух карточек. Затем каждая из карт применяет свою половину слоя (в данном примере умножает на часть матрицы). После этого результаты объединяются. В таком случае не возникает простоя карточек, но, как можно догадаться по обилию стрелочек на картинке, этот способ добавляет большое количество коммуникаций и синхронизаций между картами. И поэтому обычно его удобно применять в пределах одного хоста, где между картами происходит взаимодействие по быстрой шине, а не по сети.
Наконец, ещё один способ, который развивает Microsoft в своем фреймворке DeepSpeed, называется ZeRO. Его идея состоит в том, чтобы вернуться к исходному Data parallelism, где каждая карточка применяет модель целиком на своем куске данных. Но поскольку параметры модели не умещаются в память одной карты, то на каждой карте хранится лишь часть весов модели, а недостающие веса карта в фоне запрашивает с других карточек и забывает сразу после использования. То есть во время применения первого слоя, например, карта запрашивает второй слой с соседней карточки, применяет его и после удаляет для экономии места. Такой способ тоже лучше работает в пределах одного хоста, потому что требует большого числа взаимодействий между карточками.
Описанный метод с разделением параметров модели между несколькими карточками в терминологии исследователей из Microsoft называется ZeRO stage 3, а его «младшие братья» отличаются тем, что распределяются между картами не параметры модели, а только состояния оптимизатора или посчитанные при обратном проходе градиенты. Эти варианты проще реализуются и дают меньше накладных расходов на пересылку параметров туда-сюда, но, естественно, за это приходится платить меньшим максимальным размером модели.

На практике все эти способы хорошо комбинируются между собой. У себя мы именно так и поступаем. Причем под разные модели и разные наборы хостов используем разные комбинации. Простой совет: всегда пробуйте разные варианты! И не забывайте про важность выбора гиперпараметров, потому что большие модели очень чувствительны и при малейших отклонениях от хороших параметров начинают расходиться.
Ещё несколько слов про экономию ресурсов. Может показаться, что отличный способ сэкономить память и время — это хранить параметры и производить вычисления во float16. Но делайте это с большой осторожностью: некоторые параметры модели очень капризны и при уменьшении точности вызывают расхождение модели.
Наконец, поскольку мы используем в том числе Data parallelism, то обучение идет с большим батчем (т.е. с большим количеством примеров на каждом шаге). Из-за этого самый популярный в задачах NLP оптимизатор Adam работает плохо. Для такого обучения нужен оптимизатор, который хорошо умеет работать с большим батчем, например LAMB.
Если проделать все это, то у вас, как и у нас, получатся большие модельки. А дальше возникает вопрос: как же их применять?
Как применяли модели
Создание подзаголовков для объектных ответов
Говоря про применение таких генеративных моделей, в первую очередь хочется рассказать про тот самый Few-shot learning, на котором мы сделали акцент в самом начале. Лучше всего это показать на примере. В поиске Яндекса есть объектные ответы. У этих объектов есть длинные описания из Википедии. Задача состоит в том, чтобы сгенерировать для них краткие подзаголовки, которые помогут пользователям быстро сориентироваться, не вчитываясь в длинный текст.

Как бы такую задачу можно было решать раньше? К примеру, напишем какой-то набор регулярок, будем как-то парсить эти определения. Или давайте соберем большой датасет, разметим его вручную.
Но в случае если у вас есть большая генеративная модель, все, что вам нужно сделать, — это правильным образом написать входной текст для этой модели. Такой текст мы называем подводкой, и он состоит из следующих частей. Сначала мы пишем несколько примеров решения нашей задачи, которые мы написали вручную и разметили сами же. Например:
ТНТ — российский федеральный телеканал. По данным на 2019 год занимает седьмое место по популярности среди телеканалов России. Целевая аудитория телеканала — телезрители от 14 до 44 лет, ядро составляет молодёжь — зрители 18–30 лет.
Короче, ТНТ — это телеканал.
Дальше мы пишем уже не размеченный новый объект, например описание сайта Booking.com из Википедии. В конце пишем: «Короче, Booking.com — это...» Модель нас подхватывает и продолжает «… сайт бронирования отелей». И всё.
То есть все, что вам нужно, чтобы решить новую задачу на Few-shot, — это написать формулировку задачи на обычном русском естественном языке и/или дать несколько примеров решения задачи, в конце дописать интересующий вас пример — и всё. Модель продолжит текст без какого-либо дополнительного обучения, так как она уже достаточно много знает о структуре языка и устройстве мира. Если подводка удачно сформулирована, то продолжением текста будет искомый ответ.
Такой подход, на самом деле, хорошо переносится на довольно приличный набор задач. Вот пример реальных текстов из нашего шуточного генератора «пацанских цитат».

Другой наглядный пример потенциала Few-shot learning — это результаты нашей младшей модели с 1 млрд параметров в бенчмарке Russian SuperGLUE. Это лучший результат среди всех single-model-решений (Golden Transformer — это ансамбль из нескольких моделей), достичь которого удалось без дообучения на задачах бенчмарка.
Но у такого подхода есть очевидный минус: если вы написали плохую подводку, то ничего у вас работать не будет. При этом гарантированного способа написать хорошую подводку, к сожалению, сейчас не существует. Однако есть ряд советов, которые могут упростить работу с ними. Например, подводки лучше писать в стиле естественного текста на русском языке, без хитрой структуры, тегов и так далее. Кроме того, стоит обращать внимание на то, как именно выбираются примеры в подводку. Если в вашей задаче есть естественное разделение примеров на категории, то можно брать в подводку примеры из той же категории, что и тот, на котором вы применяете модель. Например, в задаче генерации коротких описаний, о которой шла речь выше, мы добавляли в подводку примеры описаний магазинов, если неразмеченным примером был магазин и т. п. В случае если у вас есть какой-то датасет примеров, вы можете не выбирать из них фиксированную подводку, а на каждый неразмеченный новый запрос взять несколько наборов примеров. Применить модель с каждой из получившихся подводок и агрегировать результаты, например, голосованием — взять наиболее частый. Если считать подводку частью модели, то такой метод можно представить в виде ансамбля моделей, отличающихся лишь примерами в подводке.
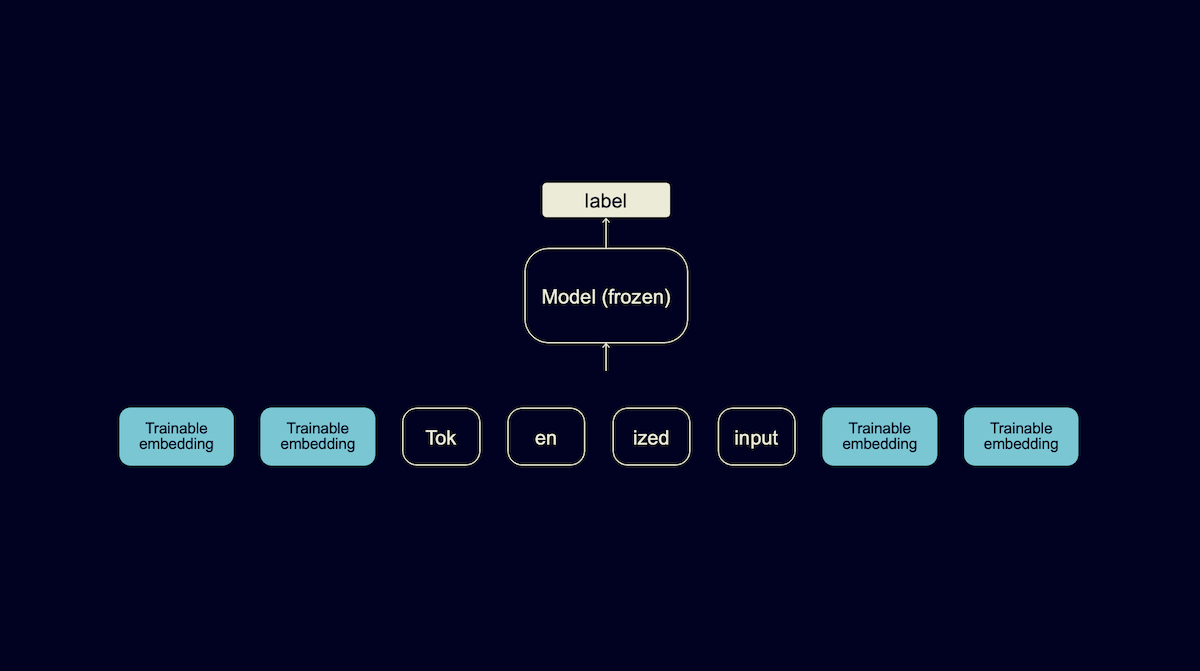
Кроме того, существует недавно предложенная техника, которая называется Prompt tuning или P-tuning. Она позволяет вообще не писать эти подводки руками. Напомню, что в трансформерах текст представляется в виде некоторого набора числовых эмбеддингов. Идея состоит в том, чтобы вместо текстовой подводки выучить на 30–40 примерах сразу её эмбеддинг, который и передавать модели. У такого эмбеддинга не будет текстового представления, но работать он может даже лучше.
Ранжирование сниппетов для быстрых ответов
Может прозвучать необычно, но генеративную модель необязательно использовать для генерации текста. Она может помочь и в задаче классификации. Если вы возьмете вероятности входных токенов из этой модели, то получите достаточно хорошие сильные фичи для последующих моделей. Расскажем на примере.
Сейчас поиск Яндекса показывает более 130 млн уникальных быстрых ответов в месяц. Это такой текст, который отвечает на запрос пользователя, он показывается в самом вверху выдачи. Этот же текст умеет зачитывать Алиса. Часть этих ответов получается из следующего механизма: на каждый запрос пользователя мы с каждого сайта берем какой-то короткий текстовый сниппет. А затем CatBoost выбирает лучшие из них.
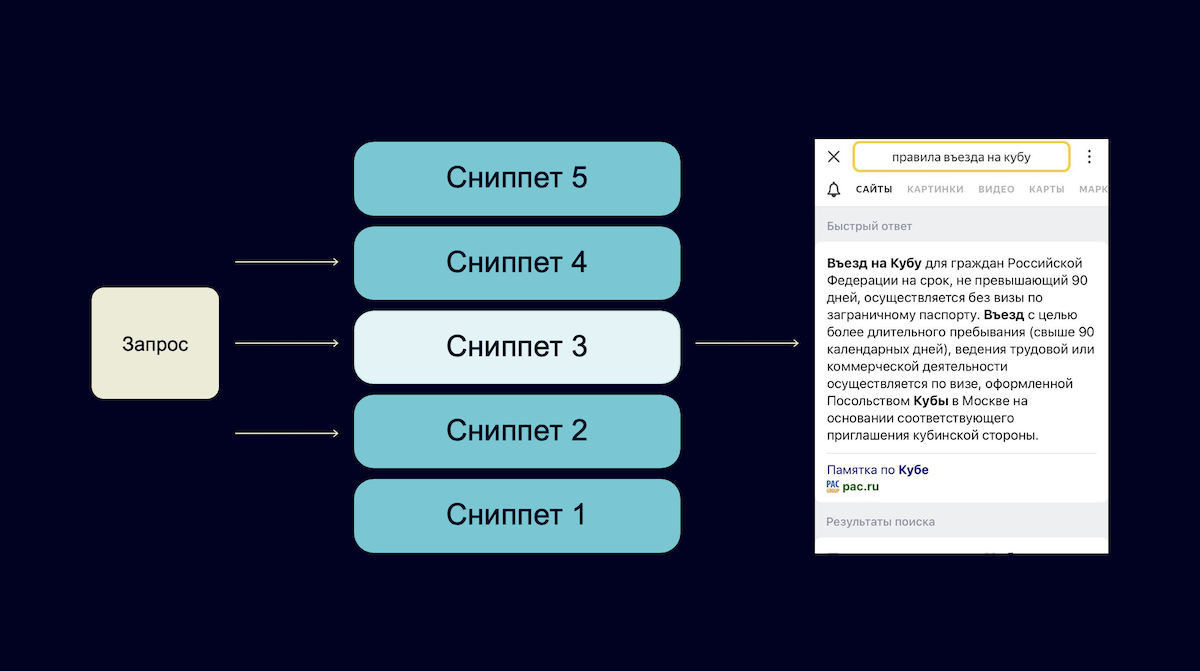
Теперь, в новой версии Поиска, в качестве одной из фич в этом классификаторе выступают вероятности слов из нашей генеративной модели YaLM. Это существенно повысило полезность таких ответов и сэкономило ещё больше времени пользователям.
Генерация ответов для Алисы
Конечно, такие модели можно использовать и в классическом подходе Transfer Learning. Обычно это делается так: вы берете предобученный BERT, дообучаете его на каком-то своем датасете для своей задачи — и получаете какое-то качество. Такой подход хорошо работает, когда у вас есть достаточно много железа и большой датасет для обучения.
Мы применили этот подход для того, чтобы адаптировать наши модели к задаче поддержания диалога в Алисе. Напомним, что Алиса умеет не только делать полезные вещи, но и просто болтать. И эта задача хорошо формулируется в рамках языкового моделирования.
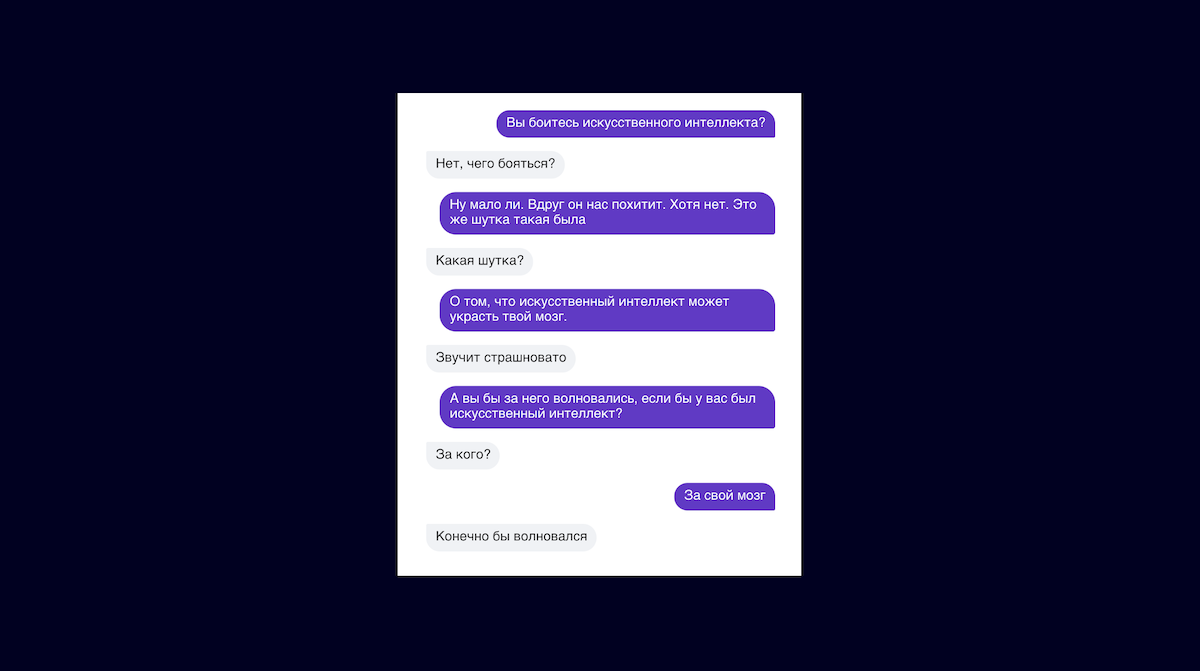
На вход модель получает контекст диалога, а на выходе она должна напечатать следующую реплику Алисы. Чтобы этого достичь, мы дообучили наши модели на датасете диалогов людей из соцсетей, а после этого дообучили их на специальном датасете ответов, которые написали редакторы специально для Алисы, чтобы обучить модель характеру персонажу.
Однако в рамках этого последнего дообучения мы заметили интересную вещь. Модель начинает выдавать гораздо более скучные ответы, чем те, на которые она была способна раньше. Проанализировав ситуацию, мы поняли, что датасет редакторских ответов Алисы составлен так, что хотя они и написаны в стиле Алисы, но покрывают не такой большой спектр тем и в целом не очень разнообразны и развернуты. Поэтому модель, обучаясь на них, учится точно так же отвечать без особого разнообразия и теряет весь тот интеллект, который она обрела на этапе предобучения.
Эта проблема является частным случаем более глобальной проблемы. Часто сложно или даже невозможно собрать идеальный датасет. Какой-то аспект задачи в нём отражен хорошо, но другие — слабо. И сильная модель, которая хорошо адаптируется к любым обучающим данным, может выучить все аспекты датасета, в том числе его слабые стороны. Проще говоря, неидеальный датасет отупляет модель. Как же с этим бороться?
Мы попробовали обучать модель не слишком сильно. Например, можно заморозить большую часть весов модели. В наших экспериментах хорошо себя показало замораживание всех весов, кроме обучаемых параметров в слоях layer norm, которых в модели на 10 млрд весов может быть всего порядка 10 тысяч, что является очень маленькой долей от всех параметров.
Оказалось, что если учить модель в таком режиме, то на нашем неидеальном датасете она достигает необходимого. Она учится говорить в стиле Алисы, но при этом не забывает про умение отвечать умно и интересно. Глобально это означает, что можно даже из неидеального датасета выжимать ровно то, что мы имели в виду при его составлении, не выучивая его недостатки. Понятно, что этот подход может не всегда работать, но он позволяет достичь хорошего качества на многих задачах, где важны те умения модели, которые она тренирует во время предобучения. Тогда на дообучении нужно лишь дать понять модели, какую задачу она должна решать, а не учить ее этой задаче с нуля.
Что дальше
Сейчас Поиск и Алиса экономят пользователям десятки тысяч часов в сутки за счёт одних только быстрых ответов. При создании многих из них мы уже используем генеративные модели YaLM. Но это лишь начало длинного пути. Мы продолжим работать не только над способами применения этой технологии в наших продуктах, но и над увеличением размеров моделей. Десятки и даже сотни миллиардов параметров — это явно не предел.
Ещё мы экспериментируем с поддержкой внешней информации в моделях. Обычная модель на трансформерах, когда получает в качестве префикса предложение «Москва — это столица», из своих весов вспоминает, что столица России — это Москва, и продолжает это предложение. Но это не единственный способ хранить знания о мире. Широко распространены различные базы знаний, например сборники текстов или вообще структурированные знания, представленные в виде графов. Мы хотим, чтобы модель доставала знания не из своих весов, а из этой внешней базы знаний.
Что ещё посмотреть про трансформеры
Другие доклады о применении трансформеров вы можете посмотреть в треке Яндекса на ods.ai или сразу на YouTube:
Костя Лахман: Удивительные трансформеры
Всеволод Светлов: Трансформерные модели для поисковой персонализации
Пётр Жижин и Степан Каргальцев: CTC-трансформер для распознавания речи




inkelyad
Ввел в поиске Яндекса 'трансформеры'. Как минимум на первых 10 страницах поисковой выдачи — ссылки только про соответствующую франшизу. И никаких запросов на уточнение или указание, что слово несколько смыслов имеет.
У вас упомянутая в статье возможность классификации — точно работает?
diogen4212
задумался, какие ещё смыслы могут быть в трансформерах и вспомнил только это.
inkelyad
Ctrl-F и поиск слова 'трансформер' по статье сверху. Поисковик по хорошему должен сказать, что у слова несколько значений, как википедия делает и спросить, какое именно значение ищется.