

Всем привет! Меня зовут Степан Деревянченко. Я специализируюсь на алгоритмах анализа текстовых данных (Natural Language Processing – NLP).
Данная статья посвящена тому, как в отделе машинного обучения ЦФТ занимаются аналитикой ФИО клиентов, зачем это нужно, и каких результатов удалось достичь за время исследований в данной области.
Моё выступление с докладом об аналитике ФИО на CFT ML Meetup можно посмотреть здесь.
Что такое аналитика ФИО и зачем она нужна
В первую очередь более подробно опишу главную тему данной статьи — аналитику ФИО. Под термином «аналитика ФИО» подразумевается следующее:
- Определение корректности ФИО (нахождение ошибок и опечаток в ФИО, выявление некорректных ФИО);
- Исправление ошибок и опечаток в ФИО;
- Получение из ФИО дополнительной информации о клиенте (на данный момент это пол и национальность).
Аналитику ФИО можно рассматривать как процесс идентификации клиента: если ФИО клиента не прошло идентификацию, то это значит, что её не прошёл и сам клиент. Но это далеко не единственное её применение. Существует ещё несколько областей, в которых аналитика ФИО может быть полезна.
Например, данное направление деятельности является очень востребованным для любой компании, которой необходимо поддерживать корректную базу своих клиентов. Ошибки в базе могут появляться по следующим причинам:
- Клиент пытается обмануть компанию (например, использует ФИО знаменитости вместо своего или вообще пишет случайное словосочетание);
- Клиент случайно ошибся (опечатался) при введении своего ФИО;
- Произошла ошибка при распознавании ФИО одним из алгоритмов (ASR, OCR);
- Любое другое действие, повлекшее за собой ошибку в ФИО.
Кроме того, аналитику ФИО можно использовать для получения необходимой информации о человеке. Например, самостоятельно, не тревожа клиента, определить его пол, если нам это понадобится.
А ещё такие признаки, как национальность клиента, могут быть хоть и не совсем достоверными, но полезными для моделей машинного обучения, принимающих некоторые решения относительно клиента.
Таким образом, можно прийти к выводу, что аналитика ФИО является важной областью для исследования, включающей множество полезных применений на практике.
Какие ФИО мы анализируем
В мире существует большое число различных конструкций ФИО. Они могут быть разной длины, состоять из различных частей, зависеть от культуры. Для многих стран, а точнее национальностей, существуют собственные паттерны и тенденции в образовании ФИО, поэтому ФИО разных стран могут сильно отличаться друг от друга. Аналитика ФИО для определённой страны подразумевает глубокое погружение и изучение особенностей ФИО, характерных для нее. Поэтому создание алгоритмов для аналитики ФИО — трудоёмкий процесс, который невозможно глобализировать: приходится скрупулёзно подстраивать функционал под каждую новую страну. Этим объясняется то, что аналитика ФИО в ЦФТ распространяется только лишь на страны пользователи наших сервисов (Россия + часть стран СНГ).
Перейдём к описанию задач нашей аналитики ФИО и методов, которые мы используем для их решения.
Определение корректности ФИО
Самая базовая задача аналитики ФИО – определить, действительно ли перед нами ФИО, и если это так, то корректно ли оно. Разумеется, это можно делать и вручную, но это не всегда легко: любой человек без проблем определит, что Витек Шиномонтажка не является корректным ФИО, но вот ошибку в ФИО Оганджанян Солех Эдика Кызы сможет распознать далеко не каждый. Ну а когда нужно проверять многомиллионную базу клиентов на наличие ошибок или принимать решения по идентификации клиентов несколько тысяч раз в день, то вариант ручной проверки совсем отпадает и встаёт вопрос об автоматизации данной проверки.
Для автоматизации решения данной задачи в ЦФТ используют комбинацию из двух подходов: применение правил и языковое моделирование. Далее в этой статье мы разберём каждый из этих подходов более подробно, а вот здесь можно посмотреть видео доклада по этой тематике от участника нашей команды.
Подход на правилах
Базовым и очень простым подходом для решения задачи определения корректности ФИО является подход, основанный на правилах. Пишем большой набор необходимых проверок, а затем прогоняем ФИО через них. Ошибка при проверке = ошибка в ФИО.
Таких правил можно придумать огромное количество на все случаи жизни. Главное – слишком не увлекаться, ведь так можно потратить многие недели на создание новых, но уже не релевантных правил :)
Вот небольшой пример правил, которые целесообразно использовать на практике:
- Пол одной части ФИО отличается от пола другой части ФИО;
- Одна из частей ФИО находится не на своем месте;
- Страна в ФИО;
- Две одинаковые согласные в начале части ФИО;
- Недостаточно слов в ФИО;
- Слишком много слов в ФИО;
- Неверное окончание отчества.
Разумеется, можно придумывать более изощрённые правила. Главное, чтобы они хорошо справлялись со своей задачей и отлавливали ошибки.
Большим плюсом этого подхода является относительная простота его реализации. Обычно она просто заключается в написании множества if-ов… Огромного множества if-ов. Если у вас получился индусский код, не переживайте — так и должно быть.
Удобство данного подхода – возможность точечно покрыть какую-то ошибку. Если вдруг у клиентов обнаружилась тенденция одинаково ошибаться при введении ФИО, то мы быстренько пишем нужное правило и затыкаем брешь. И не нужно ждать, когда какая-нибудь модель ML/DL соизволит обучиться находить данную ошибку.
Очевидно, что подход для определения корректности ФИО на правилах не лишён и недостатков. Во-первых, невозможно написать объём правил, покрывающий все возможные ошибки. А спустя некоторое время придумывать новые правила ой как сложно.
А ещё, как известно, на каждое правило всегда найдётся исключение. А когда, казалось бы, никаких исключений быть не может, что-то или кто-то обязательно поможет их создать. Например, опечатавшиеся паспортисты. Думаете, не бывает отчества Владимировч? Паспортисты с вами поспорят.
Дополнительно стоит отметить, что всегда хочется не просто находить ошибки в ФИО, но и сразу исправлять их. К сожалению, не для каждой непройденной проверки можно реализовать автоматическое правило исправления. Но возможность исправить хоть что-то, несомненно, стоит отнести к плюсам этого подхода.
Давайте перейдём к разбору следующего подхода для определения корректности ФИО — языковому моделированию.
Языковые модели
Считаю полезным по ходу рассказа делать вставки с теорией по используемым моделям и методам, но не сильно увлекаясь этим делом. Кому-то это позволит вспомнить уже забытый материал, а кому-то – познакомиться с новым и лучше понять, о чём вообще идёт речь.
Токеном будем называть минимальную необходимую единицу языка, то есть ту, что нет смысла делить на более мелкие части. Например, для русского языка логично использовать в качестве токенов слова, а вот для «языка ФИО» токеном будут являться символы.
Задача языкового моделирования заключается в определении вероятности встретить некоторое слово после заданной последовательности слов. Можно переформулировать определение и сказать, что задача языкового моделирования заключается в назначении вероятности встретить некоторую последовательность слов в языке. На самом деле, эти определения эквивалентны и вытекают одно из другого:

Языковой моделью называется некоторая математическая модель, способная решать вышеупомянутую задачу языкового моделирования.
Сразу условимся пользоваться нейросетевыми моделями, тем самым мы отойдем от Марковского предположения, которое говорит, что каждый последующий токен последовательности зависит только лишь от конечного числа предыдущих.
Как уже было сказано, в качестве модели будем использовать нейронную сеть, а конкретно – RNN. Для решения данной задачи вполне подойдёт самая простая классическая архитектура нейросетевой языковой модели, состоящая последовательно из слоёв: Embeddings, Dropout, LSTM, Linear(Dense):

Обучаем языковую модель на корректной базе ФИО, и после этого, используя формулу усредненной вероятности,

можем оценивать вероятность новых ФИО.
Важный этап перед началом использования языковой модели – подбор трэшхолда (границы) вероятности, значения ниже которого означают, что перед нами некорректное ФИО.
Таким образом, алгоритм определения корректности ФИО с помощью обученной языковой модели выглядит следующим образом:
- Определяем усредненную вероятность слова;
- Если полученная вероятность выше установленного трэшхолда, значит ФИО корректное, в противном случае считаем ФИО некорректным.
Грубый пример с потолка, показывающий всю суть метода:

Данный подход определения корректности ФИО имеет ряд весомых плюсов. Теперь нам не нужно писать огромную кучу правил, ведь достаточно обучить одну нейронную сеть, которая будет решать поставленную задачу. К тому же не нужно тратить огромное число энергии на получение обучающего датасета для сети: большая база ФИО уже является этим самым датасетом.
Но и этот подход, к сожалению, не лишён существенных минусов. На практике языковые модели способны лишь отделять ФИО от явного мусора, но они не способны отделять корректные ФИО от ФИО с ошибками, так как любые ФИО будут получать довольно высокую вероятность от языковой модели.
В отличие от подхода, использующего правила, языковые модели неспособны исправлять ошибки: назначение вероятности ФИО — единственная их способность. Кроме того, проблемой для языковой модели может стать большое число национальностей, с ФИО которых приходится работать. В таком случае языковая модель может начать выдавать неестественные и бессмысленные вероятности для входящих последовательностей. Гораздо безопаснее использовать одну языковую модель для группы близких национальностей.
Исправление опечаток в ФИО
Ещё одним важным направлением нашей деятельности является исправление опечаток в ФИО. Опечатки — довольно популярная проблема анкет клиентов, с которой нужно ужесточено бороться. Очень хочется пресечь появление в базе, к примеру, вот таких вот ФИО:
- Дмитриева Свеетлана Алексеевна
- Петров Дмитрий Валерьвич
- Рыбин Тамара Юрьевна
- Протасов Иан Александрович
Для решения данной проблемы с хорошим качеством идеально подошли нейросетевые модели Seq2Seq with Attention, которые хорошо зарекомендовали себя в машинном переводе. Все потому, что задачу исправления опечаток можно свести к задаче перевода с языка с опечатками на корректный язык без опечаток.
Обсудим устройство и принцип работы модели Seq2Seq и ее качество исправления опечаток.
Seq2Seq with Attention
Seq2Seq (Sequence2Sequence) with Attention — SOTA для задач машинного перевода в дотрансформерную эпоху и, по сути, первое успешное применение нейросетей в данной области. Является усовершенствованием моделей Seq2Seq.
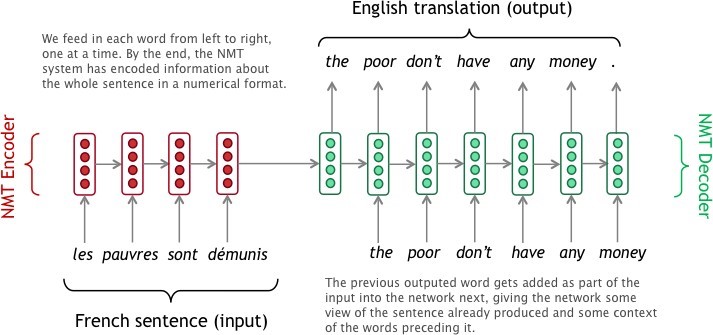
Классическая (Vanilla) Seq2Seq основана на архитектуре Encoder-Decoder, и суть её работы заключается в том, что энкодер последовательно сворачивает текст на исходном языке в вектор и передаёт этот вектор декодеру, а сам декодер последовательно разворачивает данное векторное представление обратно, но уже в текст на языке назначения.
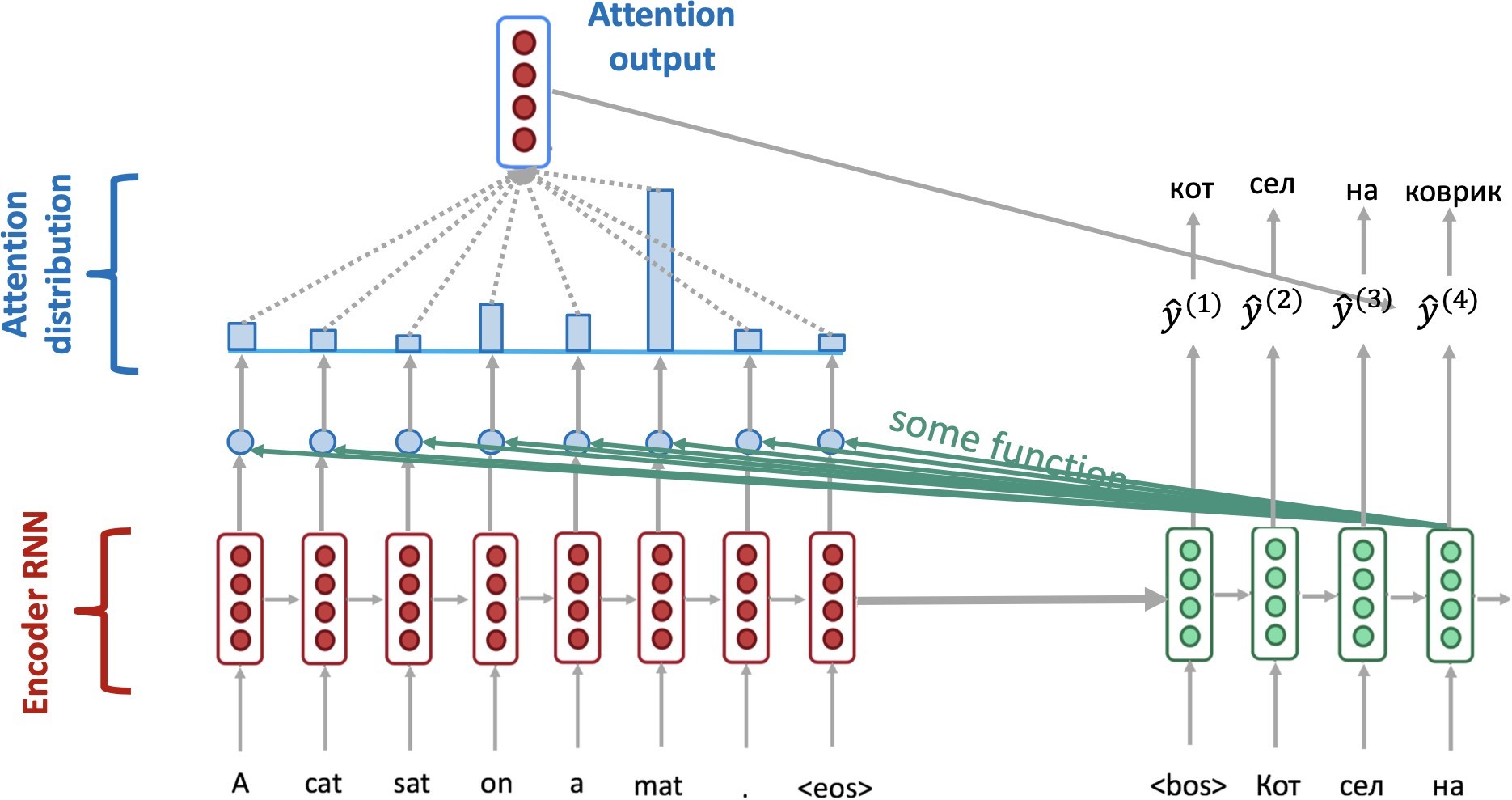
В модели же Seq2Seq with Attention в дополнение к энкодеру и декодеру используется модуль внимания (Attention). Суть его использования в том, что мы предоставляем Seq2Seq-сети более человеческие условия перевода и больше не заставляем запоминать предложение на исходном языке, а потом по памяти переводить, но разрешаем постоянно смотреть на него в процессе декодирования.
Сам Attention в этой архитектуре занимается тем, что при декодировании каждого нового токена оценивает важность всех токенов в тексте на исходном языке и подаёт эту информацию декодеру, чтобы обеспечить более корректное декодирование.
Стоит отметить, что на вход нашей Seq2Seq-сети снова, как и в случае языковых моделей, мы будем подавать символы, из которых состоит ФИО.
Перейдем к результатам использования Seq2Seq модели для решения задачи исправления опечаток в ФИО. Для оценки модели использовалась метрика accuracy, которая в данном случае измерялась как #(корректно отработанных ФИО) / #(ФИО), где корректно отработанным ФИО считается ФИО с верно исправленной опечаткой, если она в нем была, или неизмененное ФИО, если в нем не было опечатки.
Обученная модель показала на тестовой выборке accuracy=92%. Стоит отметить, что в тестовой выборке содержалось одинаковое число корректных ФИО и ФИО с опечатками.

В целом, результат в 92% является весьма неплохим и позволяет использовать предикты сети в качестве рекомендаций исправления при вводе ФИО.
Подход исправления опечаток с помощью Seq2Seq-сети обладает не только хорошим качеством работы, но и другими преимуществами. Одно из них – возможность решения задачи отделения ФИО от мусора (то, чем занимаются языковые модели из предыдущего раздела). Для этого достаточно добавить в обучающую выборку большое количество словосочетаний, не относящихся к ФИО, имеющих одинаковый перевод, например «мусор». Обученная таким образом сеть будет решать сразу 2 задачи: исправление опечаток и определение сущностей, не являющихся ФИО.
Из минусов данного подхода следует отметить, что для обучения Seq2Seq сети требуется большое количество данных, которые для задачи исправления опечаток в ФИО собрать достаточно проблематично. Приходится использовать синтетические данные, что, очевидно, не очень хорошо.
Определение пола по ФИО
Весьма полезным умением на практике может быть определение пола человека по его ФИО. На первый взгляд, это простая задача и её можно решить, используя размеченный по полу список имён и окончания фамилии и отчества. Но не стоит забывать, что мы работаем с ФИО разных национальностей, в том числе и таких, где не всё так однозначно. Да и со списком имён всё не просто. Например, имя Миша, которое у большинства ассоциируется с мужчиной, на самом деле может быть как мужским, так и женским. Да и вообще сбор полного списка имён с верной разметкой по полу – задача очень трудоёмкая.
В идеале нам хотелось бы иметь модель, которая для каждого ФИО будет выдавать вероятность того, что оно мужское или женское. Тогда по стремлению этой вероятности к 50% мы сможем судить о том, что данное ФИО может принадлежать как мужчине, так и женщине, и отказываться от автоматического проставления пола.
Очевидно, что с данной задачей могут справиться модели-классификаторы машинного обучения, поэтому нами были опробованы два подхода: Наивный Байесовский классификатор (Naive Bayes) и сверточная нейронная сеть (CNN). Рассмотрим их чуть подробнее и оценим качество их работы.
Naive Bayes
Наивный байесовский классификатор — модель машинного обучения, основанная на применении теоремы Байеса и использующая наивное предположение о независимости признаков.
Стоит отметить, что данная модель, несмотря на своё не самое правдоподобное предположение о независимости, зачастую показывает очень хорошие результаты при решении различных задач классификации. В данном случае мы берём в качестве признаков фамилию, имя и патроним (отчество), которые, действительно, можно считать независимыми друг от друга. Поэтому ожидается, что Naive Bayes должен решать задачу определения пола по ФИО с приемлемым качеством.
Рассмотрим применение Наивного байесовского классификатора для решения конкретно нашей задачи. Вспоминаем теорему Байеса:

В нашем случае , где — фамилия, — имя, — патроним. Пусть — пол человека ( — мужской, — женский) Тогда задача определения пола сводится к нахождению
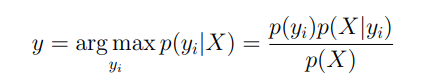
Понимаем, что знаменатель не зависит от , поэтому от него можно избавиться:

Вспоминаем про предположение о независимости и получаем окончательную формулу:

Где все необходимые вероятности легко считаются на основе частотности в обучающей выборке.
Результаты применения Наивного Байеса для решения задачи определения пола по ФИО оказались весьма впечатляющими: на тестовых данных модель показала F1-score равный 97%.
Единственная проблема данного подхода заключается в том, что он плохо обобщается на новые данные и не способен дать достоверное предсказание в случае, когда ФИО состоит из отсутствующих в базе фамилии, имени и патронима. Для решения этой проблемы и повышения и без того хорошей F-меры было решено привлечь нейронные сети.
CNN
В качестве нейронной сети взята архитектура из статьи Character-level Convolutional Networks for Text Classification 2015 года. В ту давнюю дотрансформерную эпоху эта архитектура являлась одним из мощнейших инструментов для классификации текстов.

Её удобство в применении к нашей задаче в том, что она использует символы в качестве входных данных, что является наилучшим и наиболее информативным для нейронной сети способом представить ФИО в качестве последовательности токенов.
Стоит отметить, что для бинарной классификации по полу достаточно использовать Small-вариацию сети из статьи. А ещё важно понимать, что статья создавалась для классификации достаточно больших объёмов текстов, коими не являются ФИО, поэтому для обеспечения работоспособности сети стоит уменьшить все ядра пуллинга с 3 до 2.
На практике данная архитектура показала действительно потрясающий результат: F1-score?99.9%. Это позволяет нам использовать ее для автоматической разметки ФИО по полу. Кроме того, для ФИО, которые могут принадлежать обоим полам, сеть дает вероятность близкую к 50%, что позволяет избежать ошибок и на таком тонком льду.
Определение национальности по ФИО
Перейдём к самому экзотическому направлению нашей аналитики ФИО – определению национальности человека. Эта задача не только является довольно интересной (во многом благодаря своей сложности и неоднозначности), но и необходима для решения важных практических задач. И как уже говорилось ранее, национальность человека может быть полезной фичей для моделей машинного обучения. Задача определения национальности является трудоёмкой, поэтому решалась нами по частям:
- Сначала мы научились определять те национальности, которые достаточно просто определить;
- Затем научились определять с хорошим качеством те национальности, которые были необходимы для корректной работы наших сервисов (таких национальностей 13);
- Уже после этого научились с неплохим качеством определять 48 разных национальностей просто, потому что можем
Мой рассказ не будет затрагивать эти этапы решения проблемы: я лишь поделюсь методами, которые можно использовать для ее эффективного и качественного решения.
Подход на признаках
Национальность некоторых ФИО можно определить исходя из их отличительных особенностей. Например, услышав фамилию, оканчивающуюся на «швили», многие из вас поймут, что речь идет о грузине или грузинке, а фамилия Акопян намекнет на армянское происхождение, благодаря характерному окончанию «ян».
Подход на признаках заключается в поиске паттернов в ФИО, присущих конкретной национальности, и назначении веса каждому паттерну в определении национальности человека. Например, окончание фамилии ян является весомым аргументом для того, чтобы полагать, что перед нами армянин, а вот дублирование буквы м в ФИО хоть и будет являться признаком азербайджанских ФИО, но уже не настолько весомым.
В целом, этот подход позволяет хорошо определять заданные национальности, почти не давая ложноположительных ответов, но его очевидный недостаток в том, что он позволяет определить только имеющие явно выраженные паттерны национальности. К сожалению, такими свойствами обладают ФИО далеко не всех национальностей.
Снова Naive Bayes
Для определения национальности ФИО без характерных паттернов было решено пойти тем же путем, что и при определении пола, и для начала рассмотреть качество работы Наивного байесовского классификатора. Вот тут всё оказалось совсем не так радужно, как при гендерной классификации. Метрика F-score(macro) = 56% хоть и не является отвратительным результатом при классификации на 13 классов, но, очевидно, слишком мала для использования модели в продакшене. Поэтому срочно потребовалась помощь нейронных сетей.
Снова нейронные сети
Изначально нам казалось, что и здесь сверточная нейронная сеть на символах окажется наилучшим решением, как и для уже рассмотренной задачи определения пола. Но от параллельных экспериментов на рекуррентных архитектурах мы всё же не отказались.
Результаты нас удивили. Оказалось, что для небольшого числа национальностей (меньше 9) лучшие результаты показывает сверточная архитектура, а вот для большего числа национальностей лучше работают рекуррентные сети. Это можно объяснить: суть сверточных сетей заключается в выявлении паттернов в данных, которые могут оказаться полезными для предсказания верного класса. То есть их идея очень похожа на идею подхода на признаках —только теперь мы не задаём признаки изначально, а сеть ищет их самостоятельно в процессе обучения. Среди малого числа национальностей сеть может уловить индивидуальные паттерны каждой национальности, а вот при увеличении числа национальностей паттерны начинают смешиваться, и сеть уже не может показать таких же высоких результатов.
Для классификации на 13 национальностей модели показали следующие результаты по macro F1-score:
- У CNN — 83 %
- У RNN — 87 %
Аналогично для классификации на 48 различных национальностей:
- У CNN — 77 %
- У RNN — 82 %
Стоит отметить, что под RNN в данной задаче подразумевается стандартная архитектура, состоящая из суперпозиции слоя эмбеддингов, дропаута, LSTM и нескольких полносвязных слоев.
По итогу мы пришли к выводу, что и для определения национальности по полу нейронные сети являются наилучшим решением. Небольшой прирост к качеству может дать использование связки RNN и модели, основанной на правилах.
Заключение
Ну вот я и описал основную деятельность в области аналитики ФИО в ЦФТ. Всем большое спасибо за внимание к моей статье. Очень надеюсь, что она оказалась для вас полезной, ну, или хотя бы интересной.


novosibirskaya
Это очень полезная статья и интереснейшее исследование. Спасибо Вам за проделанную работу и за такую публикацию