
Всем привет, меня зовут Дарья Пронина, я специалист по анализу данных и машинному обучению в отделе R&D в Lamoda. Я расскажу о том, что специалист по Data Science может подсмотреть у разработчиков, чтобы сделать свою работу эффективнее, production-процессы — устойчивее, а работу с разработчиками и дата инженерами — приятнее.
Из статьи вы узнаете, как хранить большие данные и поддерживать порядок в продакшн-процессе, а также зачем улучшать свои навыки программирования, если вы дата-сайентист.

Раскрыть эти темы помогут три героя:
Аркадий, дата-сайентист. Ему часто дают ответственные задачи, но ему не всегда хватает опыта, чтобы сделать их без ошибок.
Клава, опытная разработчица. Она часто использует лучшие практики в своей работе, поэтому у нее есть, что подсмотреть.
Никита, дата-инженер. Он всегда готов прийти на помощь Аркадию со своей экспертизой.
Как лучше хранить данные, если вы дата-сайентист
Обычно Аркадий работает с небольшими датасетами и хранит их в файлах от 50 до 100 Мб. Но с новым проектом к нему пришел большой набор данных, и Аркадий решил как обычно сложить его в csv-файл, который получился объемом 13 Гб. И здесь начинаются проблемы.
Такой файл сложно передать кому-то из коллег: вы будете очень долго ждать, пока он загрузится в Slack или Google Drive. А еще он может вообще не открыться на компьютере. Или формат такого файла плохо доходит до прода: объем данных растет с каждым днем и файл разрастается.
Что же можно с этим сделать? Посмотрим, как хранят файлы разработчики.
Они используют базы данных, оптимизированные под свои задачи и под тот объем данных, который у них есть.
Валидируют форматы данных при загрузке.
Поддерживают отказоустойчивость сервисов и баз данных, которые к ним подключены.
Заранее думают о возможностях масштабирования. То есть сразу прогнозируют, насколько объем данных вырастет через год, и нужно ли будет переделывать архитектуру с нуля, или у них будет возможность масштабироваться до нужного объема.
Конечно, дата-сайентистам не всегда нужно делать отказоустойчивые сервисы, но тем не менее, они могут подсмотреть некоторые штуки, которые облегчат работу.
Мы уже поняли, что сохранять все в csv-формате — не вариант. Такой файл не влезет в RAM среднестатистического компьютера, а скорость чтения явно превысит 2 минуты. В этом случае нет никакой оптимизации, валидации форматов, отказоустойчивости и масштабируемости.

Попробуем разделить этот файл по отдельным партициям. Например, найти колонку с маленькой вариативностью данных, по которой можно разделить их и сложить в отдельные файлы. После этого мы сможем обрабатывать отдельные файлы под необходимые задачи. Так мы решаем проблему масштабируемости, но размер файлов все равно остается большим.
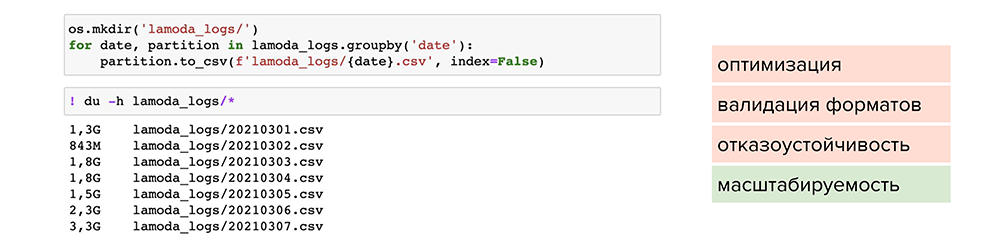
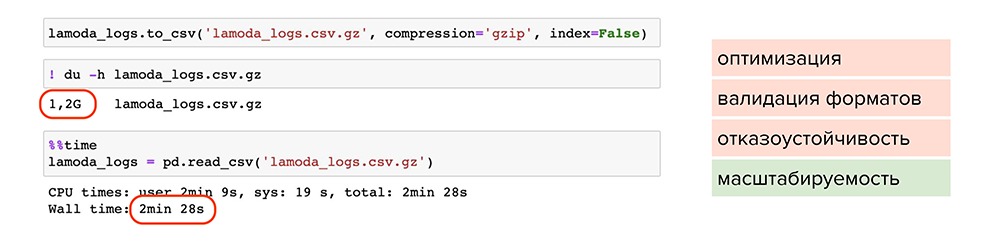
Теперь попробуем сжать файлы. Например, можно воспользоваться обычной утилитой сжатия для одного файла gzip. Она доступна в pandas, нужно лишь при сохранении указать ее в параметре compression, и файл станет весить 1,2 Гб вместо 13 Гб. Но читается он также 2 минуты. Делаем вывод, что такой способ мало подходит для оптимизации, хотя масштабируемость присутствует — файлы стали занимать меньше места на диске.
Попробуем улучшить результат. Например, можно использовать parquet — это специальный формат сжатия или, более умными словами, партиционированная бинарная колоночная сериализация для табличных данных. Он позволит работать с каждым типом данных в каждой колонке отдельно: например, сжимать числовые данные одним способом, текстовые или строковые данные — другим способом, и таким образом оптимизировать как хранение информации, так и чтение.
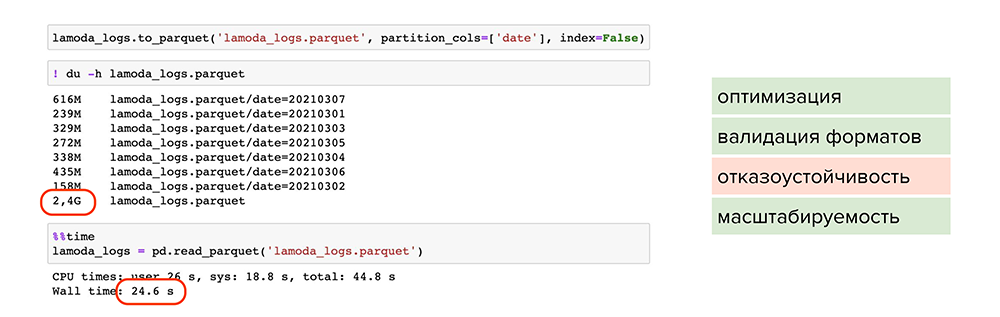
С применением parquet:
Большой объем данных стал весить 2,4 Гб и читаться за 24 секунды. Файлы оптимально сжаты, поделены на партиции и у каждого есть метаданные.
Происходит валидация форматов, поскольку parquet работает с каждым форматом колонки отдельно и проверяет их при записи. Вероятность записать ошибочные данные снижается.
Присутствует масштабируемость, поскольку мы пишем данные в разные партиции и сжимаем их.
Однако мы не победили один пункт — отказоустойчивость.
Чтобы покрыть все пункты, можно обратиться к специальным фреймворкам и базам данных. Например, подойдут ClickHouse или Hadoop, особенно, если это продакшн-решения или повторяющиеся истории.
Чтобы оптимизировать работу с данными, опытная разработчика Клава рекомендует Аркадию внимательно относиться к хранению данных, записывать их в оптимизированном формате вроде parquet и использовать партиционирование или специализированные базы данных.
Как поддерживать порядок в production-процессе
Аркадий работает над важной функциональностью и внезапно вспомнил, что оставил ошибку расчетов на продакшене. Немного подумав, он решается на быстрый фикс — никто об этом не узнает, а он сейчас все исправит и пойдет домой. Ночью запускаются очередные расчеты. Дата-инженер Никита просыпается от алерта, и не понимает, что сломалось: он не видит новых релизов, ищет проблемы в сторонних сервисах и базах данных. Вот из-за такой мелочи можно не только сломать сервис, но и лишить коллег сна.
Что можно сделать, чтобы Никита больше спал по ночам? Снова обратимся к опыту разработчиков.
Версионировать все
Версионирование изменений поможет другим командам быть в курсе того, что у вас происходит, а также не приведет к поломке зависимых процессов. И всегда есть спасительная возможность откатиться на более раннюю версию, если все и правда сломалось.
В Lamoda мы версионируем при любых изменениях (даже при самых маленьких):
Внутренние утилиты. Например, если мы вносим изменения во внутреннюю библиотеку, мы не можем знать наверняка, какими функциональностями из нее пользуются другие команды, поэтому обязательно ставим новую версию, чтобы ничего не сломать ни у себя, ни у других команд.
Spark-jobы при деплое. Это дает нам возможность ставить в известность дата-инженеров и проводить несколько этапов тестирования джоб перед выкаткой в прод.
Модели, обновляемые вручную. У нас есть проекты, где модель пересчитывается редко, поэтому их можно версионировать с помощью даты начала расчетов.
Результаты расчетов и предсказаний. Если что-то сломалось или мы сделали новую модель, мы можем сравнить текущие предсказания и предсказания, которые мы сделали в прошлом, чтобы понять, как это влияет на пользователей.
Эксперименты. Все зависит от проекта: где-то мы пишем свои названия для каждой новой модели, где-то мы все логируем датами. Здесь можно использовать классные сторонние решения, вроде DVC, но нам пока это не нужно.
Поддерживать документацию и оставлять комментарии
Как правило, для наших продакшн-расчетов мы оставляем краткие комментарии с важной информацией: откуда берутся данные, что происходит, какие технологии используются и куда сохраняются результаты. Это нужно, чтобы инженеры могли локализовать проблему и понять, в каких проектах нужно пересчитать результаты.
Дополнительный пункт в комментариях — критичность процесса. Он нужен, чтобы дата инженеры были в курсе, нужно ли вставать ночью и чинить расчет, или можно подождать до утра и чинить его в рабочее время.
Проводить несколько этапов тестирования кода
Наш процесс тестирования выглядит так:

Первый этап — локальная проверка на малом объеме данных. Например, когда мы дебажим функциональность, все изменения мы прогоняем на небольшом кусочке данных, чтобы меньше ждать.
На втором этапе обязательно прогоняем изменения на prod-объеме данных, чтобы понять, выдержит ли тот алгоритм, который мы придумали, нужный объем. Бывают ситуации, когда приходится пересматривать очень большую часть алгоритма, чтобы все работало оптимально. Только после этого, мы проводим код-ревью внутри команды.
После того как мы утвердили все изменения, делаем проверку на dev-стенде вместе с инженерами — это третий этап. Он нужен, чтобы мы вместе проверили все нужные переменные и сборки. При этом инженер участвует в оптимизации, смотрит за потреблением ресурсов, за временем работы и другими показателями. Только после этого мы выкатываем сборку в продакшн: пару дней мы держим функциональность и следим за ней на продакшене, а потом включаем ее на пользователей.
Теперь дата-инженер Никита больше спит по ночам: Аркадий начал версионировать все изменения, писать заметки к расчетам и выкатывать изменения в прод только после нескольких тестовых прогонов.
Зачем и как улучшать свои навыки программирования
Теперь копнем глубже: коснемся кода, который пишут дата-сайентисты. Несколько месяцев Аркадий работает над моделью и наконец добивается нужных результатов. Но заботиться о качестве кода нет времени: нужно строить новую модель для другого проекта. Тем временем код Аркадия:

Как правило, у дата-сайентиста в фокусе метрики качества моделей, а качество кода – это уже другой вопрос. Но в перспективе это несет множество проблем.
Итак, почему хорошее качество кода так важно?
Во-первых, разработчикам и другим дата-сайентистам очень сложно читать плохой код. Код должен быть написан последовательно, чтобы прослеживалась вся логика, как в хорошем рассказе.
Второй пункт вытекает из первого: плохой код сложно поддерживать и расширять. Если логику сложно понять, то ее запросто можно сломать, добавляя новую функциональность.
И третий пункт: с плохим кодом увеличивается время на тех-долги и растет time2market для новых фич. У нас даже есть такая шутка: если долгов по проекту становится много, то они превращаются в «техническую ипотеку», которую нужно «выплачивать» в каждом спринте.
В чем главные ошибки при написании кода
Теперь разберемся, чем именно может быть плох код дата-сайентиста, и из-за чего разработчики забивают себя фейспалмами при чтении кода. Причем нужно начать не с форматирования, а с более глубоких проблем. Разберем на примере:
Необоснованные try-except. Например, у вас есть функция, которая предсказывает результат по картинке, и вы хотите написать оберточную функцию, которая бы читала файл и потом делала предсказания.
Но в 1% случаев модель не отрабатывает и выдает ошибку. Разбираться с этим никто не хочет, потому что 1% – это немного, поэтому дата-сайентист поддается соблазну и делает try-except. На самом деле это значит, что в коде есть проблема, на которую вы закрываете глаза.
import numpy as np
from PIL import Image
from my_package import my_model
def predict_image(image_path):
image = Image.open(image_path)
data = np.asarray(image)
try:
my_model.predict(data)
except:
passВсе же лучше разобраться, что не так. Например, выяснилось, что некоторые скачанные картинки черно-белые, и они не в трех измерениях, а в двух. А модели нужны только цветные картинки в трех измерениях — оставляем соответствующий комментарий. Обязательно логируем ошибку, чтобы было понятно, на какой картинке сломалась модель. В случае непредвиденной ошибки лучше выйти из функции, потому что может возникнуть ситуация, когда все сломается и новых предсказаний не будет, а вы об этом даже не узнаете.
import numpy as np
from PIL import Image
from my_package import my_model
def predict_image(image_path):
image = Image.open(image_path)
data = np.asarray(image)
#images for my_model should have 3 dimensions
try:
my_model.predict(data)
except ValueError:
print('Incorrect number of dimensions for', image_path)
except:
print('Unexpected error!')
raiseВысокая сложность кода. Посмотрим на пример: здесь и dict, и маперы, и сортировка, и фильтры, еще все это в куче циклов, и вишенка на торте — комментарий #sorry.
def _calc_filter_stats_aggregate(buf, limit, min_value):
result = defaultdict(Counter)
actual_filter_types = set()
for stat_row in buf:
for filter_type in popular_filter_types:
if stat_row[filter_type] is None:
continue
actual_filter_types.add(filter_type)
for filter_value in stat_row[filter_type]:
result[filter_type].update({filter_value['filter_value']: filter_value['count']})
return dict(
chain(
*map(
dict.items,
[
{
y: sorted(
filter(
lambda z: z[1] >= min_value,
[(float(x[1]), int(x[0])) for x in result[y].items()] # sorry
),
key=lambda x: x[0],
reverse=True)[:limit]
} for y in actual_filter_types
]
)
)
)Конечно, так лучше не делать, потому что с каждой новой строчкой ваши коллеги видят очередной сюрприз, в котором нужно разобраться. Лучше писать код последовательно и не пытаться уместить все в одной строчке
Неинформативный нейминг переменных. Это наши любимые for i in, dataframe, dataset, result. Они не дают контекста происходящему или дают его неполностью.
for i in range(n):
for j in range(m):
for k in range(l):
temp_value = X[i][j][k] * 12.5
new_array[i][j][k] = temp_value + 150В примере ниже — более понятный вариант кода. Однобуквенные переменные изменены на более контекстные, например, row_index, column_index, normalized_pixel_values. Причем все константы вынесены в отдельную переменную. Подробнее про хороший нейминг можно почитать в статье World of Science.
PIXEL_NORMALIZATION_FACTOR = 12.5
PIXEL_OFFSET_FACTOR = 150
for row_index in range(row_count):
for column_index in range(column_count):
for color_channel_index in range(color_channel_count):
normalized_pixel_value = (
original_pixel_array[row_index][column_index][color_channel_index]
* PIXEL_NORMALIZATION_FACTOR
)
transformed_pixel_array[row_index][column_index][color_channel_index] = (
normalized_pixel_value + PIXEL_OFFSET_FACTOR
)Неучет крайних случаев (edge cases). Эта проблема больше знакома разработчикам и тестировщикам, нежели дата-сайентистам. Тем не менее, на нее тоже нужно обращать внимание. Чаще всего мы дебажимся на маленьком кусочке данных, который у нас есть, и делаем вид, что все хорошо — функция готова. Однако в продакшене может прийти новое значение, которое вы забыли обработать: ноль, пустая строка, null или пустой массив. Функция упадет: придется вставать в выходной день пораньше и чинить. По этой причине лучше сразу обрабатывать хотя бы популярные крайние случаи. На эту тему есть полезная статья на Медиуме.
Отступление от стандартов pep-8 и стандартов форматирования. Минус в том, что единых стандартов форматирования кода нет — есть только рекомендации. Отсюда и проблема: кому-то нравится переносить скобки одним способом, кому-то — другим. Однако решается этот момент просто: можно зафиксировать внутри команды четкие правила форматирования и следовать им.
Вот как выглядел бы пример кода функции, которая обрабатывает картинки, с плохим форматированием. В таком виде понять код гораздо сложнее, чем с наличием нужных отступов и переносов.
from my_package import my_model
import numpy as np
from PIL import Image
def predict_image(image_path):
image= Image.open(image_path)
data =np.asarray(image )
#images for my_model should have 3 dimentions
try: my_model.predict(data)
except ValueError: print("Incorrect number of dimentions for",image_path)
except: print('Unexpected error!')
raiseА вот так ее можно преобразовать в красивый, а главное — читабельный вид:
import numpy as np
from PIL import Image
from my_package import my_model
def predict_image(image_path):
image = Image.open(image_path)
data = np.asarray(image)
#images for my_model should have 3 dimensions
try:
my_model.predict(data)
except ValueError:
print('Incorrect number of dimensions for', image_path)
except:
print('Unexpected error!')
raise
Как избежать ошибок
Итак, как же дата-сайентист может улучшить качество кода? Начнем с быстрых улучшений. Самый простой вариант — использовать автоформаттеры:
Black поможет расставить все пробелы, скобки и вообще сделает ваш код ровным и красивым.
iSort помогает правильно сортировать импорты, что особенно важно в сложных модулях и утилитах.
Можно использовать линтеры — они подсвечивают ошибки в коде.
Flake8 подсвечивает ошибки форматирования, проверяет отсутствующие личные импорты и переменные, которые вы забыли обозначить, а также проверяет синтаксис функций и циклов.
Pylint проверяет сложность кода: уровни вложенности циклов, количество локальных переменных и похожие вещи, которые помогут сделать ваш код более легким и читаемым. Также в нем есть встроенный спелл-чекер, который помогает правильно писать названия переменных.
Mypy проверяет типы аргументов функции, и если вы указываете типизацию, он проверит, не запихнули ли вы случайно не ту переменную в вашу функцию.
Про линтеры можно почитать интересную статью Григория Петрова «Холиварный рассказ про линтеры».
Еще хороший вариант — использовать плагины для ноутбуков. Среди них есть и автоформатеры, и линтеры, хотя и не в полной функциональности. Но при этом они значительно улучшают и ускоряют работу дата-сайентиста. Подробнее можно почитать в статье “10 Jupyter Notebook Extensions Making My Lyfe Easier”.
И заключительный пункт: выносите модули из ноутбука. Если ваш jupyter notebook начал разрастаться и накапливать различные функции и классы, лучше вынести их в отдельные py-файлы. Их будет удобнее редактировать в ide с полным арсеналом линтеров и автоформаттеров. В ноутбуке можно оставить только визуализацию и выводы. А чтобы быстро подтягивать все изменения из py-файлов можно использовать autoreload:
%load_ext autoreload
%autoreload 2
from my_package import my_model
predictions = my_model.predict(data)Что нужно для улучшения навыков программирования
Best practices. Рекомендую книжку «Чистый код»: там такие есть и философские штуки, и примеры, как сделать код лучше.
Можно заглядывать в исходники библиотек, которыми вы пользуетесь каждый день: поскольку вы знакомы с их функциональностью, вам будет просто разобраться и в том, как они работают.
Также можно следить за известными специалистами на GitHub или Kaggle. Например, много полезного можно найти в аккаунтах с материалами к онлайн курсами по Data Science lazyprogrammer и Yorko. Или же посмотреть на открытые кернелы ребят из топа Kaggle — у них точно есть чему поучиться!
Советы старших товарищей. Например, организуйте код-ревью, где вы попросите опытного дата-сайентиста или разработчика отревьюить ваш пул-реквест и отметить, где вы сделали хорошо, а где нужно улучшить.
Другой формат — заменить one-to-one сессии или ретроспективы на совместный код-ревью. Например, вместе посмотреть и разобрать ваш командный репозиторий. Так можно обменяться мнениями и понять предпочтения коллег: например, кто-то любит писать код в классах, кто-то любит вынести лишнюю функцию. По итогу встречи можно зафиксировать формат, который удобен всем внутри команды.
Обмен опытом с DEV-командой. Не нужно стесняться просить помощи у соседних команд. Можно попросить разработчиков и дата инженеров провести тематические мастер-классы, например, на таких нам как раз рассказывали про линтеры. Также можно организовать совместные митапы по обмену опытом: вы можете рассказывать про машинное обучение, а вам — про хороший код. По итогам можно составлять совместную базу знаний, куда вы будете складывать полезные статьи, хорошие практики и ссылки на документацию.
Опытная разработчица Клава рекомендует Аркадию использовать автоформаттеры и линтеры, а также улучшать навыки написания кода через поиск лучших практик, обмена опытом и код-ревью.
Подведем итог: чему же дата-сайентист могут научиться у разработчиков?
хранить большие данные в оптимизированных форматах (parquet) или БД и использовать партицирование;
версионировать все изменения и проводить их через стандартный процесс тестирования;
оставлять комментарии к production-процессам для других команд;
совершенствовать свой код с помощью инструментов (линтеров, автоформаттеров), обмена опытом и детальных code review.
Если вы подсмотрели у разработчиков или других коллег еще что-то полезное, поделитесь своим опытом в комментариях.

mpakep
Это работает и в обратную сторону. Можно нахватать массу неэффективных подходов и ошибок. Главное это понимать что делаешь а подсмотрел ты или выдумал сам уже не важно.
Psychiatrist
Сразу видно, что ты не дата-сайнтист. Пост барышни, на самом деле, со скрытым (или не очень) мессаджем, который ТруЪ дата-сайнтисты должны распарсить.