
Я - студент университета, знаком с машинным обучением в рамках пройденного курса, есть интерес к современным кластерным технологиям, конкретно - к Apache Ignite. Возникла идея копнуть глубже, то есть немного разобраться с относительно не популярной библиотекой Apache Ignite Machine Learning. Под катом — история о том, как мне удалось запустить пример OneVsRestClassificationExample, сначала пример сам по себе, а потом его же на датасете MNIST database of handwritten digits. Ну и еще немного про производительность кластера из одного и двух домашних ПК. Весь код доступен в репозитории HandwrittenSVM.
История вопроса
Документация Apache Ignite описывает технологию как "distributed supercomputer for low-latency calculations, .. and machine learning". Захотелось это проверить — как кластер будет вести себя на относительно крупном датасете, особенно если в кластере несколько узлов. Изначально было интересно поработать с изображениями. Конкретно - с нейросетью, способной относить неизвестное изображение к одному из заранее известных классов. Выбираю один из классических алгоритмов классификации — алгоритм SVM (Solving Vector Machine).
Начинаю работу
Изучаю документацию Apache Ignite ML, нахожу там раздел multiclass classification, там говорится про мою задачу на примере Glass dataset из UCI Machine Learning Repository. В репозитории Apache Ignite нахожу готовый код примера OneVsRestClassificationExample. Остается клонировать и запустить. Раздел Getting Started обещает быстрый старт, ну я и пробую: клонирую, открываю, компилирую.
Но что-то идет не так.
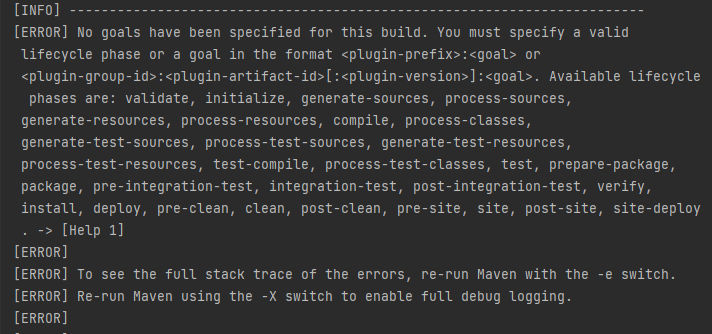
С Maven и IntelliJ IDEA работаю недавно, как справляться с подобными ошибками - непонятно. Начинаю гуглить в поисках решения или хотя бы товарищей по несчастью — попадается на глаза статья Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API. Отличает её от большинства статей то, что в её тексте есть ссылка на маленький репозиторий с кодом. Пробую клонировать/открыть в IntelliJ Idea, скомпилировать/выполнить, все запускается и работает, как обещано. Почему-то автор использует библиотеки из GRIDGAIN Community Edition - заменяю в файле pom.xml на то же самое из APACHE Ignite. Продолжающееся студенчество вырабатывает у меня устойчивую приязнь к Open Source-продуктам. Опять работает, вот с этого можно стартовать.
Делаю по образу и подобию свой собственный пустой проект, копирую туда пример OneVsRestClassificationExample, еще некоторые файлы из репозитория Apache Ignite и нужные зависимости в pom.xml. Оказалось, пример использует крошечный датасет 1987 года GLASS_IDENTIFICATION размером всего в 116 строк.Классификация выполняется быстро, в кластере с одним узлом на моем домашнем ПК занимает буквально пару секунд.

Как я искал другой датасет
Хочется протестировать алгоритм на более крупном датасете. Встречаю статью Алексея Зиновьева под названием Apache Ignite ML: origins and development.
В статье есть отсылки к питоновскому пакету scikit-learn, поиск по этой теме приводит к туториалу Image Classification with MNIST Dataset. Туториал рассказывает, как с помощью scikit-learn загрузить датасет mnist_784, нарисовать на экране загруженное, обучить сеть на наборе из 60 тысяч рисунков и протестировать качество обучения еще на 10 тысячах.
Смотрю дальше, оказывается, что на kaggle.com выложен этот же датасет в удобном для обработки виде. Загружаю два CSV-файла: тестовый mnist_test.csv(17.46 MB, 10 тысяч рисунков) и обучающий mnist_train.csv(104.56 MB, 60 тысяч рисунков). Первая колонка в файле — метка класса изображения, далее следует рисунок размером 28 х 28 (то есть строка из 784 чисел от 0 до 255). Датасет содержит рукописные изображения арабских цифр, поэтому метка класса — число от 0 до 9.
Как заменить датасет
Задача по замене оказалась несложной — в примере OneVsRestClassificationExample используется enum MLSandboxDatasets, указывающий на расположение csv-файла в проекте. Там даже есть параметр, указывающий на наличие заголовка в файле; первая колонка файла — метка класса.Формат данных оказался тем же самым и добавление датасета свелось к добавлению строки
MNIST_TRAIN_DATASET("sampleData/mnist_train.csv", true, ",")Запускаю и смотрю на время работы
Инструкция из Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API, говорит о том, как запустить кластер Apache Ignite в минимально достаточной конфигурации. В конфиге узла данных config\default-config.xml выставляю в true параметр peerClassLoadingEnabled, указываю ip-адрес, запускаю узел данных. В конфиге своего приложения HandwrittenSVM.jar включаю клиентский режим: прописываю<property name="ClientMode" value="true"/>и тоже запускаю, все это в разных окнах одного Windows-хоста. Узел данных запускается ОК, но как только начинает работать jar, вылетает ошибка:
Failed to find class with given class loader for unmarshalling (make sure same
versions of all classes are available on all nodes or enable peer-class-loading)
[clsLdr=sun.misc.Launcher$AppClassLoader@55f96302, cls=org.apache.ignite.ml.
dataset.impl.cache.util.DatasetAffinityFunctionWrapper] Как мне победить этот DatasetAffinityFunctionWrapper, если никаких собственных классов я не создавал и peerClassLoadingEnabled включал? Спрашиваю в форуме Apache Ignite в Telegram, оперативно получаю ответ (спасибо за подсказку, @Thriftwy). Оказывается, чтобы запустить узел с поддержкой ML, надо скопировать папку optional\ignite-ml в папку libs. Теперь узел при старте видит плагин
[09:16:02] Configured plugins:
[09:16:02] ^-- ml-inference-plugin 1.0.0
[09:16:02] ^-- nullМой jar должен загрузить в кластер датасет `mnist_train.csv` из 60 тысяч изображений размером 104 МБ. Смотрю в диспетчере задач расход памяти узла данных во время того, как работает мой jar - впечатляет.

Загрузка не заканчивается - всё вылетает с ошибкой нехватки памяти. На моей машине установлены скромные 8 Гб оперативки,один узел не справляется с объёмами.

Приходится делить датасет на части размером 5, 8, 10, 12 и 15 тысяч записей. С датасетом в 15К компьютер тоже не справляется, те же ошибки, что и на полном датасете MNIST_TRAIN. Придется работать от 5 до 12.
Смотрю в код своего клиентского jar-приложения и вижу, что весь процесс делится на четыре задачи, из которых интересных две: fillCacheWith - заполнение кэша, trainer.fit - обучение сети. Фиксирую время System.currentTimeMillis() до и после вызова, перевожу в секунды и печатаю на экране. Запускаю на одном хосте один узел кластера и свой jar, фиксирую время работы для разных датасетов.
В распоряжении у меня есть ещё один компьютер, ровно с такими же скромными 8 Гб оперативной памяти. Соединяю две машины в локальную сеть, получаю кластер из двух узлов данных на двух хостах. Снова фиксирую время загрузки/обучения сети, запуская свой jar.

Итоги
Итоги оказались не совсем такими, каких я ждал.
Если кластер состоит из двух физических узлов, то загрузка данных туда происходит по сети и увеличение времени работы при добавлении узла объяснимо.
Разумно ожидать, что удвоение ресурсов кластера по памяти и ЦПУ увеличит возможности кластера, но этого как-то не видно. Если пример с 15К записей не помещается в память одного хоста, но в память двух он уже должен помещаться (она в два раза больше!). Но у меня не получилось. Если я увеличил ЦПУ, то обучение должно быть быстрее для тех данных, что помещаются в память. Но большой разницы опять нет.
Вполне возможно, я что-то сделал не так. Кажется в документации не хватает примера/туториала, демонстрирующего ускорение расчетов при увеличении ресурсов кластера.
Комментарии (4)

zaleslaw
01.09.2021 14:38+5Добрый день, @Demschwarz я один из авторов Ignite ML, хотел бы прокомментировать вашу статью.
Во-первых, вам огромное спасибо за то, что подробно зафиксировали свой опыт как пользователя от начала до конца - это очень ценно для разработчиков OSS проектов, чей глаз давно замылен, все настройки пророщены, тестовые кластера гоняются по много раз, а некоторые вещи кажутся очевидными и существуют только в голове.
Во - вторых, я хотел бы поделиться своей статьей непосредственно относящейся к исследованиям производительности отдельных алгоритмов ML на кластере из 1,2 или 4 машин в Amazon. Среди них есть и SVM, но там решается задача бинарной классификации.
Вот ссылка.
Сразу оговорюсь, это не какой-то официальный бенчмарк, а мое личное исследование.
В - третьих, вы безусловно правы, стартовое руководство, обещающее легкую прогулку, неполно и подходит, как мне кажется уже опытным пользователям Ignite, а не тем, кто например, только хочет попробовать машинное обучение.
В - четвертых, исходя из моего опыта, все это хорошо и стабильно работает, в том числе на довольно больших кэшах, когда у вас кластер с нодами, каждая из которых имеет много оперативки (кратно больше 8Gb, например 40Gb или 80Gb), и достаточный размер DataRegionConfiguration.maxSize - например 10Gb.
В - пятых, есть большая проблема с тем, как корректно делать бенчмарки для ML тренировки, это время сильно зависит от следующих вещей: значений гиперпараметров алгоритма, критерия остановки, количества партиций (в случае Ignite), настроек JVM и GC, количества машин (ведь мы хотим еще увидеть эффект масштабирования) и выделенной там RAM и CPU - ресурсов.
В - шестых, вы используете довольно нетривиальный способ загрузки данных, кладете данные в ресурсы и полагаетесь на механизм загрузки для мелких датасетов из примеров. Он там прост и не оптимален, конечно. На самом деле, есть продвинутые техники вливания данных в кэши и таблицы и они за рамками моих статей и в целом Apache Ignite ML исходит из того, что данные уже кто-то куда-то поместил и разместил и нам остается их только отпроцессить и построить модель на них.
В - седьмых, в моей статье, указанной выше я делюсь своими гипотезами о некоторых зависимостях между алгоритмом ML, количеством машин и временем тренировки в зависимости от количества доступной памяти и числа партиций (многомерный кубик такой получается). Все таки большинство алгоритмов демонстрируют ускорение вычислений в зависимости от числа машин, но есть и парочка алгоритмов, которые в силу своей природы и закона Амдала плохо распределяются и имеют ограниченный эффект по ускорению (благо, хоть не замедляются в десятки раз) при увеличении количества нод в кластере. Что характерно, кстати и для Apache Spark ML, и для H2O. Просто некоторые (но не SVM, конечно) алгоритмы весьма плохи для распределения.
В - восьмых, вы используете многоклассовую классификацию на основе OneVsRest - подхода. Я допускаю, что она реализована не оптимальным образом и где-то происходит некорректная дупликация данных и какой-то момент времени в памяти лежит много лишних копий данных, я если честно не тестировал на производительность данный подход, целью было - облегчить написание пользовательского кода.
Прочтя это, вы скажете, стоп, почему я не мог это прочесть в офф.доке и столько мучился? Я вас понимаю, сочувствую, но могу пока сказать, что это оборотная сторона OSS, и вы написав эту статью уже стали частью проекта и сообщества, спасибо вам за это.

Demschwarz Автор
06.09.2021 14:11+1Добрый день, @zaleslaw
Мощности моего кластера из домашних компов оказалось недостаточно, поэтому я по знакомству получил доступ к промышленным машинам - одна клиентская нода и четыре расчётные, на каждой 512 Гб оперативной памяти и DataRegionConfiguration.maxSize = 140G.
Провёл четыре теста, начал с одной клиентской и одной расчётной ноды. После взял две ноды, затем три, затем четыре. Тестировал я работу получившихся кластеров на полном датасете mnist_train.csv (60 тысяч рисунков). Кластер запускал заново перед каждым расчетом.
Время загрузки данных не измерял, время исполнения процесса mdl trainer.fit такое:
Одна серверная нода: 11.396 секунд
Две серверные ноды: 9,959 секунд
Три серверных ноды: 9,794 секунды
Четыре серверные ноды: 10.185 секунд
Опять странный результат. Посмотрел в Ignite Visor, тогда в кластере было четыре ноды
Два узла не содержат данных совсем, непонятно почему.

anonymous
Demschwarz Автор
Ignite Visor говорит мне о том, что данные именно партиционируются по нодам. Странная вещь, тем не менее